Crowd LookALike и идеи для создания крауд-майнинга
Crowd LookALike — это заданная исходная популяция, а затем используются технические средства для поиска групп пользователей, похожих на исходную популяцию. Crowd LookALike часто используется в рекламе. Например, если клиент предоставляет ценную группу людей, с помощью рекламной платформы LookALike можно найти больше потенциальных ценных пользователей для рекламы. Ниже представлены несколько распространенных решений реализации LookALike.
Расчет сходства выполняется на основе пользовательских векторов. Используйте портретные данные, данные о поведении, данные о потреблении и т. д. для построения вектора признаков для каждого пользователя. Процесс построения основан на кодировании данных, нормализации данных и других средствах. Предполагая, что у пользователя есть 1000 тегов, можно построить массив длиной 1000. Значение каждого бита в массиве представляет значение соответствующего тега. Массив можно рассматривать как вектор пользователя. Вычислив векторное расстояние между каждым пользователем в исходной популяции и другими пользователями, не являющимися исходной популяцией, можно построить целевую популяцию, найдя ТОП-пользователей, ближайших к каждому пользователю. Методы расчета расстояний между векторами включают евклидово расстояние, расстояние Чебышева, расстояние Манхэттена и т. д., которые можно выбирать в соответствии с характеристиками бизнеса. Вектор пользователя также может быть реализован посредством встраивания в глубокое обучение. На рис. 5-26 показан основной процесс поиска толп LookALike на основе векторов.
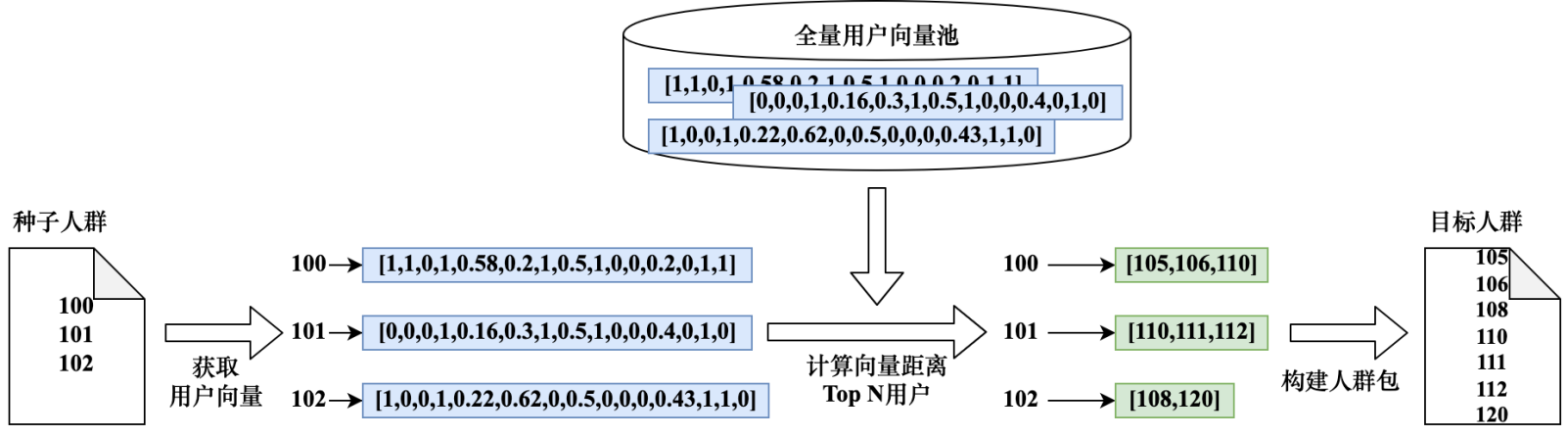
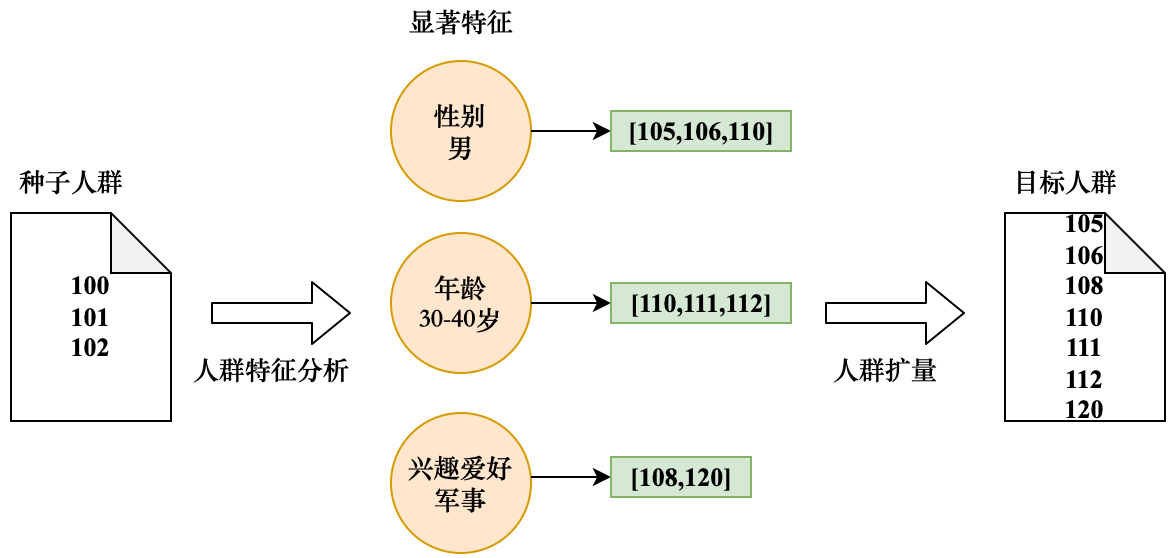
Рассчитайте аналогичные популяции на основе распределения признаков популяции семян. Используйте портретные данные для анализа характеристик семенной популяции и выясните ее основные характеристики этикетки. Например, этикеточные характеристики семенной популяции, как правило, следующие: мужской пол, возраст от 30 до 40 лет, хобби – военное. В качестве целевой группы были выбраны дети в возрасте от 40 лет, не относящиеся к группе семян. Целью этого метода является анализ профиля популяции семян и выяснение основных характеристик. Здесь основные характеристики распределения популяции семян можно найти путем сравнения TGI с крупномасштабными пользователями (активными ежедневно или ежемесячно). ). Процесс расчета похожих групп на основе распределения признаков показан на рисунке 5-27.
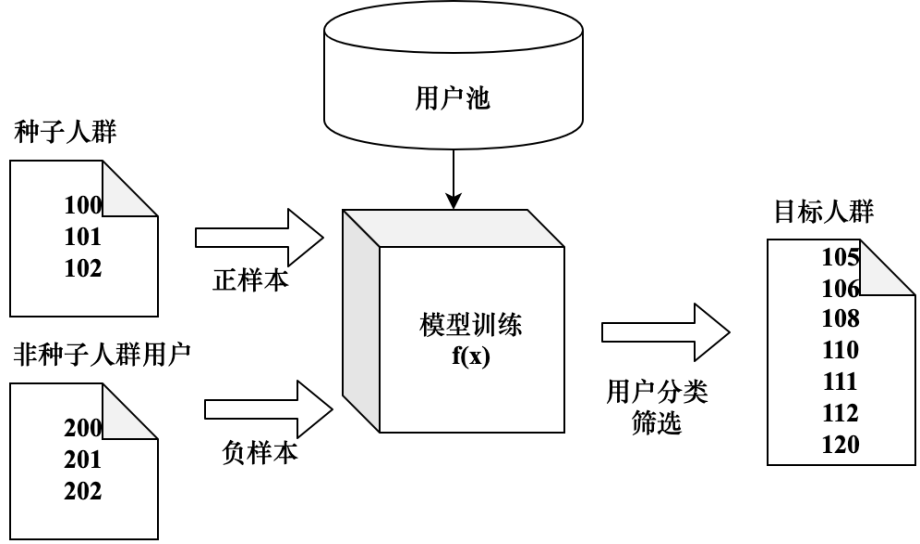
Вычислите похожие группы людей на основе алгоритмов классификации. Рассматривайте исходную популяцию как положительные образцы, а другие популяции, не являющиеся семенами (или другие популяции), как отрицательные выборки. Используйте модель обучающей классификации для расчета пользователей, соответствующих условиям, и создания целевой популяции. Вычисление похожих групп с помощью алгоритмов классификации также является распространенным решением реализации CrowdLookALike в отрасли. На рис. 5-28 показан основной процесс реализации. Модель классификации может использовать традиционные методы машинного обучения или глубокого обучения. В настоящее время также существуют практические решения для использования социальных сетей для проведения LookALike среди групп, использования дружеских отношений для поиска друзей нескольких степеней всех пользователей в исходной группе и построения целевой группы.
Анализ толпы заключается в определении целей оптимизации, использовании возможностей алгоритмов для поиска пользователей, соответствующих требованиям, и создании толпы. Группа правил находит пользователей, которые соответствуют требованиям, посредством «описанных» условий фильтрации, в то время как группа майнеров использует алгоритмы, чтобы лучше соответствовать характеристикам пользователей и более точно находить целевых пользователей на основе целей оптимизации бизнеса.
В сценарии игрового бизнеса, чтобы продвигать определенную игру-стрелялку, необходимо найти группу пользователей, которые готовы загрузить игру. Ориентация на эту группу во время продвижения игры может увеличить количество показов игры и охват сообщений. В ходе определенного мероприятия по раздаче подарков для пополнения баланса, чтобы увеличить количество пользователей пополнения баланса, участвующих в этом мероприятии, можно обнаружить группы пользователей с сильным желанием пополнить счет и использовать их в качестве ключевых целей рекламы при продвижении мероприятия. Некоторому большому V автору, чтобы помочь ему быстро увеличить количество поклонников, необходимо найти потенциальных пользователей, которым интересен пользователь и его произведения. Все приведенные выше примеры имеют конкретные цели оптимизации для крауд-майнинга: объем загрузки игры, количество пополнений и количество следующих пользователей. Инженер-алгоритмист выбирает подходящую модель для крауд-майнинга на основе этой цели.
Идея крауд-майнинга заключается в том, чтобы сначала найти обучающие образцы (начальную толпу), а затем расширить сид-толпу с помощью идеи LookALike. Разница между этим методом и толпой LookALike заключается в том, что результаты крауд-майнинга могут включать пользовательские данные в начальную толпу. Если взять в качестве примера вышеупомянутую деятельность по раздаче подарков для пополнения счета, то для того, чтобы определить группу пользователей с сильным желанием пополнить счет, первым шагом является поиск начальной группы пользователей, которые недавно пополнили счет, и пользователей, которые недавно сделали это. покупки в приложении можно рассматривать как начальную толпу; второй шаг — расширение на основе начальной толпы. Идея реализации аналогична толпе LookALike. Целевую толпу можно рассчитать через векторное расстояние между пользователями, извлекая ключевые характеристики. исходную толпу и использование алгоритмов классификации.
Эта статья взята из книги «Портреты пользователей: построение платформ и бизнес-практика». При перепечатке указывайте источник.




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
