ConvNeXt V2: Адаптация к самостоятельному обучению, чтобы сделать CNN «снова мощной»?
Привет! Сегодня я хотел бы поделиться с вами относительно новым документом по компьютерному зрению под названием «ConvNeXt V2: совместное проектирование и масштабирование ConvNets с маскированными автоэнкодерами». Эта статья была опубликована совместно исследователями из Корейского института передовых наук и технологий (KAIST), Meta AI и Нью-Йоркского университета. Ссылки на статью и код приведены ниже.
Проще говоря, эта статья улучшает новую модель сверточной нейронной сети (ConvNeXt V2). Путем объединения структуры самоконтролируемого обучения и дальнейшего добавления новых архитектурных улучшений было достигнуто хорошее улучшение производительности при выполнении различных задач визуального распознавания. Давайте рассмотрим основное содержание и нововведения этой статьи~
Адрес статьи: (Нажмите в конце статьи, чтобы прочитать исходный текст для прямого доступа)
https://arxiv.org/abs/2301.00808
Адрес кода GitHub:
https://github.com/facebookresearch/ConvNeXt-V2
MMPreTrain Обеспечивает предварительно обученное ConvNeXt v2 Модель,Можетсуществовать Дополнительную информацию можно найти здесь:https://mmpretrain.readthedocs.io/en/latest/papers/convnext_v2.html
Обзор ConvNeXt
Прежде чем представить ConvNeXt V2, давайте сделаем краткий обзор ConvNeXt: ConvNeXt также является работой Meta AI. Его мотивацией является переосмысление пространства проектирования, проверка ограничений чистых сверточных нейронных сетей (ConvNet) и исследование чистых сверточных нейронных сетей. нейронные сети Производительность, которую сеть может достичь в задачах компьютерного зрения. Хотя «Трансформеры» превзошли сверточные нейронные сети во многих задачах в области компьютерного зрения, в статье ConvNeXt утверждается, что сверточные нейронные сети обладают естественными свойствами индуктивного смещения, поэтому существует еще большой потенциал, который можно использовать.
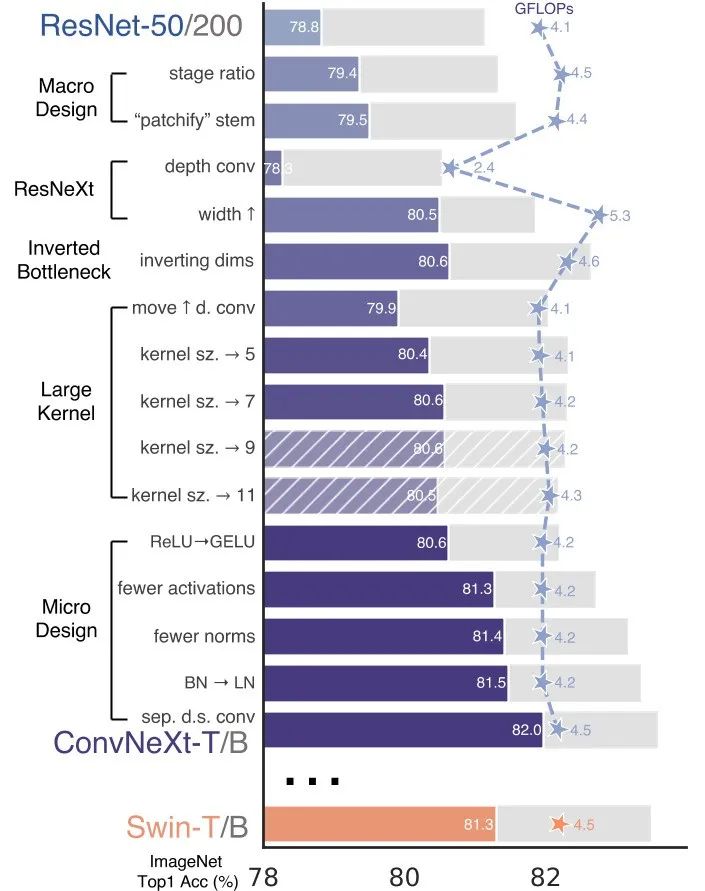
Постепенно модернизируя стандарт ResNet, автор протестировал ряд проектных решений и обнаружил полезные ключевые компоненты. Наконец, он предложил серию чистых сверточных нейронных сетей под названием ConvNeXt и оценил их на нескольких задачах машинного зрения. Они достигают точности и масштабируемости, сравнимых с Vision. Трансформатор, сохраняя при этом простоту и эффективность стандартных сверточных нейронных сетей.
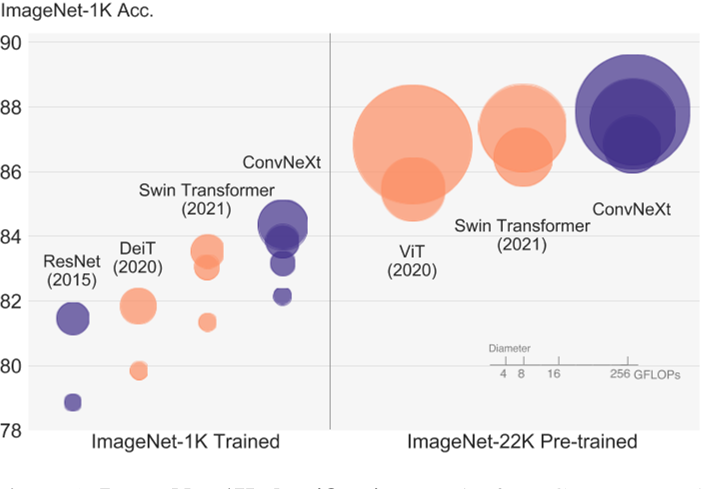
Проще говоря, ConvNeXt сравнивает и анализирует сверточные нейронные сети и Transformer как на макро-, так и на микроуровне. На макроуровне автор обнаружил некоторые фреймворки и технологии, которые могут стабилизировать работу в сверточных сетях, такие как ResNeXt, обратное узкое место, большое ядро свертки и т. д. Эти макрокорректировки помогают улучшить производительность сверточных сетей. На микроуровне авторы также рассмотрели различные варианты проектирования с точки зрения функций активации и слоев нормализации, например замену BatchNorm на LayerNorm. В итоге автор предложил серию чисто сверточных нейросетевых моделей. Конкретные попытки показаны на рисунке ниже. В одном предложении, как сделать Transformer или Swin-Transformer, я также попробовал внести соответствующие коррективы в ConvNeXt:
ConvNeXt V2
ConvNeXt V2 основан на современных ConvNets и добавляет результаты методов самоконтролируемого обучения. В ConvNeXt V2 добавлены две инновации (структура и метод) на основе ConvNeXt: полностью сверточный маскированный автокодировщик (FCMAE) и глобальная нормализация ответа (GRN).
Эта методика самоконтролируемого обучения и архитектурно улучшенное совместное проектирование (совместное проектирование) работают вместе для создания нового семейства моделей ConvNeXt V2, которое значительно повышает эффективность различных тестов распознавания, включая классификацию ImageNet, обнаружение COCO и сегментацию ADE20K. Улучшенная производительность. чистые ConvNets.
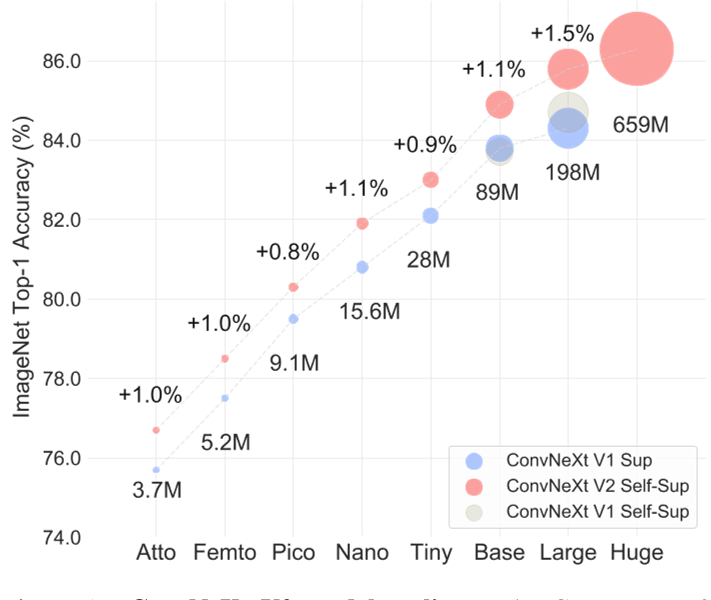
В то же время автор также предоставляет на GitHub предварительно обученные модели ConvNeXt V2 различных размеров: от эффективной модели Atto с параметрами 3,7 млн до модели Huge с 650 млн. Как показано на рисунке ниже, он также демонстрирует мощные возможности масштабирования модели (Scaling), упомянутые в названии статьи, то есть производительность ConvNeXt V2 постоянно улучшается по сравнению с базовым уровнем контролируемого обучения (ConvNeXt V1) всех моделей. размеры.
Как упоминалось ранее, ConvNeXt V2 имеет два основных нововведения: во-первых, он предлагает структуру полностью сверточного маскированного автокодировщика (FCMAE), во-вторых, он предлагает уровень нормализации глобального ответа (GRN);
Давайте кратко рассмотрим их принципы и эффекты соответственно и посмотрим на дальнейшие улучшения новой структуры обучения (структуры обучения) и структурного улучшения (улучшения архитектуры) после их одновременного рассмотрения (совместное проектирование).
Полностью сверточный маскированный автоэнкодер (FCMAE)
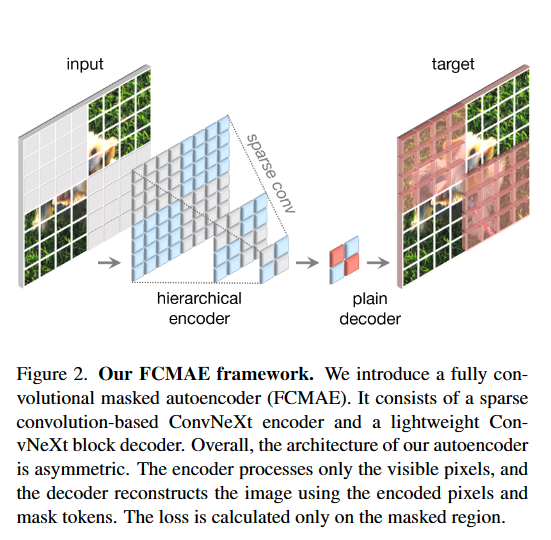
Полностью сверточный маскированный автоэнкодер (FCMAE)рамкада Сверточная нейронная сеть на основе самоконтролируемого обучениеметод,Было задумано создать случайную маску для некоторых областей входного изображения.,Тогда пусть Модель попробует восстановить пройденную часть. Это может заставить Модель изучить глобальные и локальные особенности изображения.,Тем самым улучшая его способность к обобщению.
Платформа FCMAE имеет два преимущества по сравнению с традиционной платформой маскированного автоэнкодера (MAE): во-первых, она использует полностью сверточную структуру вместо использования полностью связного слоя для генерации масок и восстановления изображений, что может уменьшить параметры. Уменьшается объем и объем вычислений. сохраняя при этом пространственную информацию, он использует стратегию многомасштабной маскировки вместо использования маски фиксированного размера, что может повысить способность модели воспринимать особенности разных масштабов.
В следующей таблице показан пошаговый процесс поиска оптимального декодера в FCMAE в эксперименте:
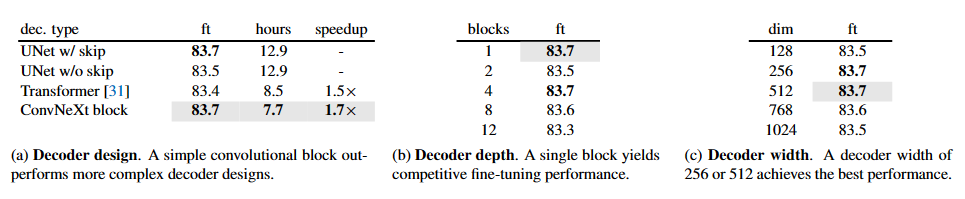
Table 1. MAE decoder ablation experiments with ConvNeXt-Base on ImageNet-1K. We report fine-tuning (ft) accuracy (%). The pretraining schedule is 800 epochs. In the decoder design exploration, the wall-clock time is benchmarked on a 256-core TPU-v3 pod using JAX. The speedup is relative to the UNet decoder baseline. Our final design choices employed in the paper are marked in gray .
В этих экспериментах исследователи сравнивали разные декодеры, при этом критерием оценки служила точность на заключительном этапе тонкой настройки. В таблице приведены результаты экспериментов с использованием ConvNeXt-Base, включая точность с использованием разных типов декодеров. Наконец, авторы выбрали оптимальный декодер, который будет использоваться в сочетании с FCMAE для обучения окончательной модели ConvNeXt V2.
Нормализация глобального ответа (GRN)
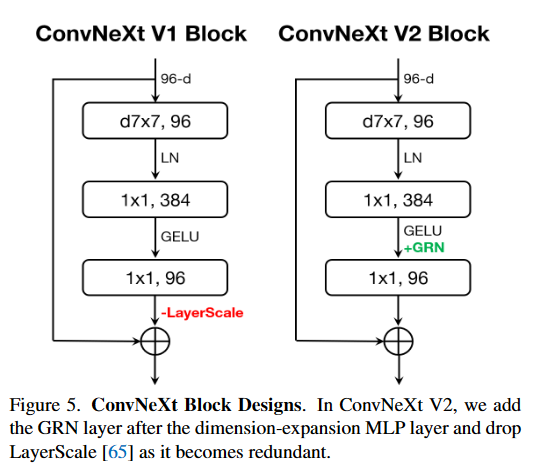
Нормализация глобального ответа (GRN) — это новый уровень сверточной нейронной сети, который нормализует карту признаков на каждом канале, тем самым усиливая конкуренцию признаков между каналами. ГРН По сравнению с традиционным слоем пакетной нормализации (BN), этот слой имеет два преимущества: во-первых, он не требует дополнительных параметров, поскольку он только нормализует карту объектов, во-вторых, он может обрабатывать любой размер; партия, в то время как BN слой должен быть основан на batch Динамическая настройка параметров размера требует большого объема вычислений.
Реализация уровня GRN очень проста: требуется всего три строки кода и не нужно изучать параметры. В частности, слой GRN можно разделить на три этапа: глобальное агрегирование объектов, нормализация объектов и калибровка объектов. На этапе глобального агрегирования признаков мы используем норму L2 для агрегирования карт признаков на каждом канале и получения агрегированного вектора. На этапе нормализации признаков мы нормализуем агрегированные векторы, используя стандартную функцию нормализации деления. На этапе калибровки объектов мы используем нормализованные векторы для калибровки исходных карт объектов. Весь слой GRN с вычислительной точки зрения очень мал, поэтому его можно легко добавить в сверточную нейронную сеть, тем самым усиливая конкуренцию признаков и улучшая производительность модели.
Автор нашел ConvNeXt V1 Модель имеет характерную проблему коллапса, то есть между существующими каналами имеются избыточные активации (мертвые или насыщенные нейроны). Для решения этой проблемы автор вводит новый метод нормализации: Нормализация. глобального ответа (GRN) слой, действующий на каждый patch функции для содействия разнообразию функций и решения проблемы коллапса функций.
В частности, на рисунке ниже показаны результаты авторской визуализации карты активации каждого функционального канала. На каждом изображении выбрано 64 канала, что наглядно доказывает, что ConvNeXt V1 имеет проблему схлопывания функций, а также демонстрирует, что ConvNeXt V2 с использованием GRN облегчает эту проблему.

"We visualize the activation map for each feature channel in small squares. For clarity, we display 64 channels in each visualization. The ConvNeXt V1 model suffers from a feature collapse issue, which is characterized by the presence of redundant activations (dead or saturated neurons) across channels. To fix this problem, we introduce a new method to promote feature diversity during training: the global response normalization (GRN) layer. This technique is applied to high-dimensional features in every block, leading to the development of the ConvNeXt V2 architecture."
В то же время для дальнейшей проверки GRN Эффект от использования ConvNeXt-Base Модель провела серию экспериментов по абляции, чтобы изучить, как использовать Нормализацию. глобального ответа (GRN) технология для увеличения разнообразия моделей, тем самым улучшая Модельизпроизводительность.

Table 2. GRN ablations with ConvNeXt-Base. We report fine-tuning accuracy on ImageNet-1K. Our final proposal is marked in gray .
В таблице показаны различные экспериментальные ситуации, включая различные методы нормализации признаков, методы взвешивания признаков и эффект от использования GRN на этапах предварительного обучения и точной настройки. Результаты экспериментов показывают, что GRN может эффективно улучшить производительность модели, особенно на этапе предварительного обучения. В то же время GRN также дает лучшие результаты по сравнению с другими методами нормализации общих признаков.
Co-design Matters
Поскольку и FCMAE, и GRN могут принести определенную степень улучшения, какие результаты они дадут при совместном использовании? Это то, что покажут эксперименты, связанные с «совместным проектированием», описанные в статье.
В частности, как показано в следующей таблице: В ходе экспериментов авторы обнаружили, что использование структуры FCMAE оказывает ограниченное влияние на качество обучения представлений без изменения структуры модели. Аналогично, новый уровень GRN оказывает довольно незначительное влияние на производительность в контролируемых условиях. Однако сочетание этих двух факторов привело к значительному улучшению производительности точной настройки. Это подтверждает ранее упомянутую идею о том, что и модель, и структуру обучения следует рассматривать вместе, особенно когда речь идет об обучении с самоконтролем.
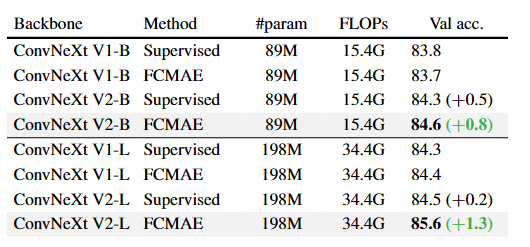
Table 3. Co-design matters. When the architecture and the learning framework are co-designed and used together, masked image pre-training becomes effective for ConvNeXt. We report the finetuning performance from 800 epoch FCMAE pre-trained models. The relative improvement is bigger with a larger model.
Результаты эксперимента
В экспериментах модель ConvNeXt V2 с использованием структуры FCMAE и слоев GRN продемонстрировала значительное улучшение производительности при выполнении различных задач, включая классификацию ImageNet, обнаружение COCO и сегментацию ADE20K.
Первый — необходимый результат на ImageNet-1k:
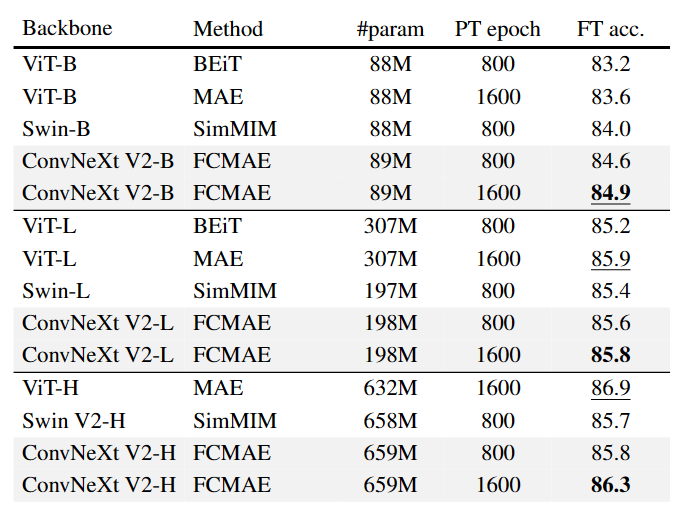
Table 4. Comparisons with previous masked image modeling approaches. The pre-training data is the IN-1K training set. All self-supervised methods are benchmarked by the end-to-end finetuning performance with an image size of 224. We underline the highest accuracy for each model size and bold our best results.
Как показано в таблице выше: ConvNeXt V2 + FCMAE превосходит Swin Transformer, предварительно обученный с помощью SimMIM, при всех размерах модели. В то же время, по сравнению с ViT, предварительно обученным с помощью MAE, ConvNeXt V2 работает аналогично в больших модельных системах и использует гораздо меньше параметров (198M против 307M). Однако в более крупной модельной системе ConvNeXt V2 немного отстает от других методов. Авторы полагают, что это может быть связано с тем, что огромная модель ViT может получить больше пользы от предварительной подготовки с самоконтролем.
В статье также представлены результаты промежуточной тонкой настройки ImageNet-22K: Процесс обучения промежуточной тонкой настройке включает три этапа: 1. Предварительное обучение FCMAE 2. Тонкая настройка ImageNet-22K 3. Тонкая настройка ImageNet1K; Результаты показаны в таблице ниже:
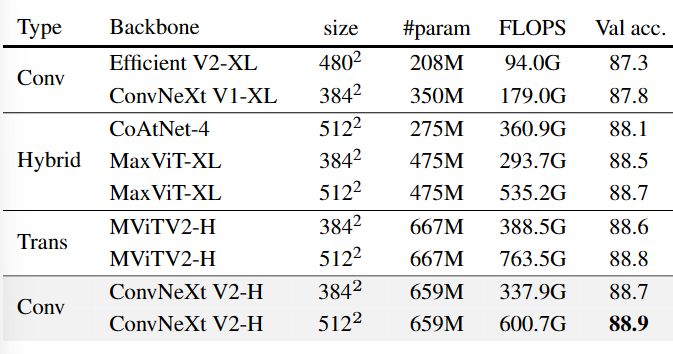
Table 5. ImageNet-1K fine-tuning results using IN-21K labels. The ConvNeXt V2 Huge model equipped with the FCMAE pretraining outperforms other architectures and sets a new state-of-the-art accuracy of 88.9% among methods using public data only.
В то же время предварительно обученный ConvNeXt V2 используется в качестве магистрали для подключения Mask R-CNN для обнаружения головных целей и сегментации экземпляров на COCO в сочетании с Upper-Net для семантической сегментации на ADE20k, ConvNeXt V2 также показывает отличные результаты.
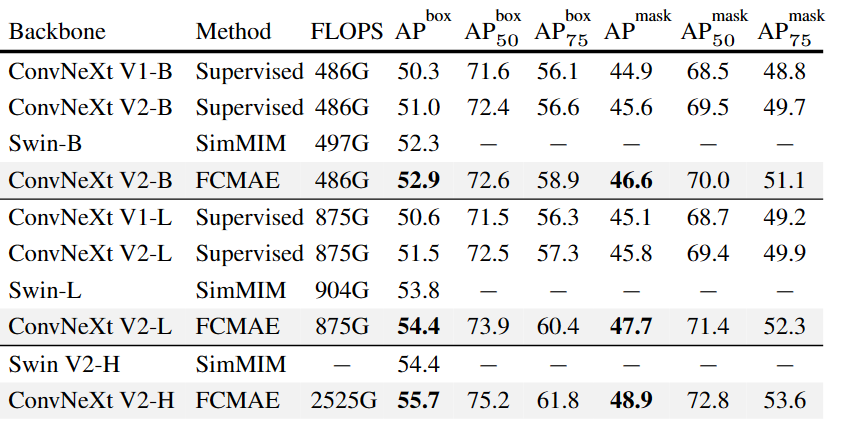
Table 6. COCO object detection and instance segmentation results using Mask-RCNN. FLOPS are calculated with image size (1280, 800). All COCO fine-tuning experiments rely on ImageNet-1K pre-trained models.
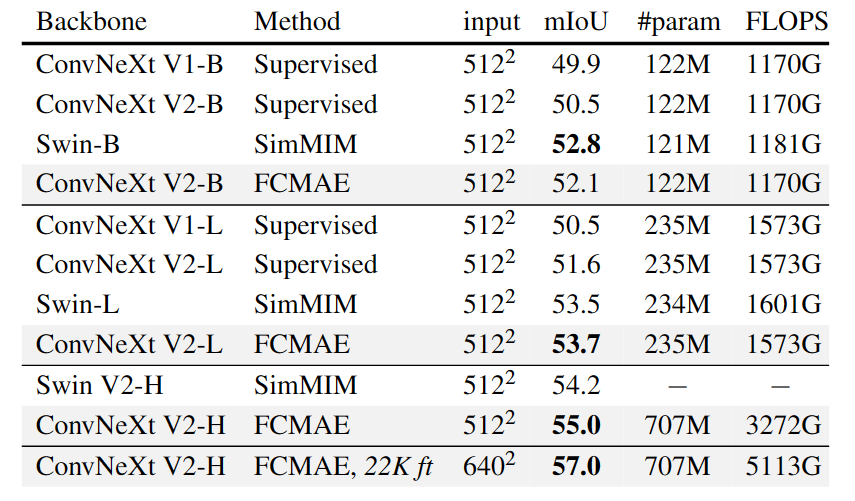
Table 7. ADE20K semantic segmentation results using UPerNet. FLOPS are based on input sizes of (2048, 512) or (2560, 640). All ADE20K fine-tuning experiments rely on ImageNet-1K pre-trained model except FCMAE,22K ft, in which case the ImageNet-1K pre-training is followed by ImageNet-22K supervised fine-tuning.
Резюме статьи
Таким образом, ConvNeXt V2 знакомит нас со средой самоконтролируемого обучения FCMAE, адаптированной к сверточным сетям для улучшения возможностей обучения представлению и масштабируемости ConvNets.
в то же время,В статье также предлагается технология Нормализации глобального ответа (GRN).,Чтобы решить проблему свертывания функций, которая может возникнуть при непосредственном обучении ConvNeXtModel с помощью маскированного ввода.
Кроме того, документ показывает нам большее улучшение, достигнутое благодаря совместному проектированию (совместному проектированию) FCMAE и GRN, подтверждая идею о том, что и модель, и структуру обучения следует рассматривать вместе.
Наконец, ConvNeXt V2 — это ConvNet среди преобразователей зрения. Я также с нетерпением жду его дальнейших применений и производительности. Сможет ли он действительно сделать CNN «снова мощным»?
Если вы заинтересованы в дополнительных исследованиях о том, как адаптировать самообучение к сверточным сетям, настоятельно рекомендуется посмотреть материалы SparK в сообществе OpenMMLab:
будущая работа
существовать Эта статьябумагаизбудущая В работе автор предлагает некоторые дальнейшие направления исследований. Во-первых, автор заявил, что дальнейшее исследование может GRN Слои спроектированы и настроены так, чтобы лучше соответствовать конкретным наборам данных и моделям.
Во-вторых, авторы предлагают изучить, как структуру FCMAE можно применить к другим задачам, таким как классификация видео или распознавание лиц. Более того, авторы считают, что FCMAE можно сравнить с другими формами методов самоконтроля, чтобы найти наилучшую комбинацию.
Наконец, авторы рекомендуют применять FCMAE к более крупным моделям и более сложным наборам данных для дальнейшей проверки его эффективности.
MMPreTrain
MMPreTrain — это набор инструментов для обучения предварительно обученных моделей, запущенный командой OpenMMLab. Он предоставляет множество часто используемых предварительно обученных моделей, включая предварительно обученные модели для общих задач, таких как классификация, обнаружение, сегментация и т. д., а также поддерживает предварительное обучение на пользовательских наборах данных. MMPreTrain также предоставляет часто используемые методы и методы в процессе обучения, такие как улучшение данных, корректировка скорости обучения и ослабление веса, чтобы облегчить пользователям обучение и отладку модели. MMPreTrain можно использовать для легкого обучения и переноса обучения предварительно обученных моделей, и это очень практичный инструмент.

Представленная на этот раз ConvNeXt v2 сочетает в себе методы самоконтролируемого обучения и архитектурные улучшения, что значительно повышает производительность чистых сетей ConvNet по различным критериям распознавания, включая классификацию ImageNet, обнаружение COCO и сегментацию ADE20K.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
