Conv-LoRA официально здесь | Вы, наконец, можете заморозить исходные веса модели, а затем обучать любые подзадачи, значительно уменьшая обучаемые параметры

Существующие методы адаптации домена (DA) обычно включают предварительное обучение в исходном домене и тонкую настройку в целевом домене. Для многоцелевой адаптации домена оснащение каждого целевого домена выделенной/независимой сетью тонкой настройки и сохранение параметров всех предварительно обученных моделей обходится очень дорого. Чтобы устранить это ограничение, авторы предлагают сверточную адаптацию низкого ранга (ConvLoRA). ConvLoRA замораживает веса предварительно обученных моделей, добавляет обучаемые матрицы разложения низкого ранга к сверточным слоям и осуществляет обратное распространение градиентов через эти матрицы, тем самым значительно сокращая количество обучаемых параметров. Для дальнейшего улучшения адаптивности авторы используют адаптивную пакетную нормализацию (AdaBN), которая вычисляет статистику работы для конкретной цели, и используют ее с ConvLoRA. При тестировании на сегментацию набора данных Калгари-Кампинас, содержащего изображения МРТ головного мозга, ConvLoRA имеет меньше обучаемых параметров и работает лучше, чем или на одном уровне с большими независимыми точно настроенными сетями (общая базовая модель имеет менее 0,9 обучаемых параметров) %). ConvLoRA прост, но эффективен и может применяться к любой архитектуре, основанной на глубоком обучении, с использованием сверточных и пакетных слоев нормализации.
1 Introduction
Глубокие нейронные сети (DNN) достигли высочайшей производительности, когда обучающий и тестовый наборы имеют одинаковое распределение. Однако сдвиг домена, то есть изменение распределения данных между обучающим набором (исходный домен) и тестовым набором (целевой домен), может значительно снизить способность к обобщению. Эта проблема особенно остра в многоцентровых медицинских исследованиях, где разные центры визуализации используют разные сканеры, протоколы и группы пациентов.
Адаптация неконтролируемой области (UDA) направлена на обобщение больших моделей, предварительно обученных на крупномасштабных исходных областях, на немаркированные целевые области, тем самым устраняя необходимость в дорогостоящих аннотациях данных. Обычно это достигается путем тонкой настройки, при которой модель, предварительно обученная в исходном домене, адаптируется к целевому домену. Однако основным недостатком точной настройки является то, что она генерирует специальную модель для каждого целевого домена с теми же параметрами, что и исходная предварительно обученная модель. Следовательно, для нескольких целевых доменов потребуется несколько выделенных моделей с тем же количеством параметров, что и исходная предварительно обученная модель.
Таким образом, метод UDA можно эффективно использовать для одноцелевого DA для обучения одной модели для конкретного целевого домена. Напротив, в многоцелевом DA (MTDA) цель состоит в том, чтобы адаптироваться к множеству неразмеченных целевых доменов. MTDA имеет более широкое применение в реальных сценариях. Однако обучение независимых моделей для каждого целевого домена с теми же обучаемыми параметрами, что и исходная модель, непрактично и затратно.
Эффективная точная настройка параметров (PEFT) зарекомендовала себя как стратегия точной настройки больших языковых моделей (LLM). В отличие от традиционного метода тонкой настройки, он сохраняет большую часть параметров модели в замороженном состоянии, при этом количество корректируемых параметров значительно сокращается, обычно не более 5% от общего числа параметров. Это не только обеспечивает эффективное обучение, но и ускоряет обновления. PEFT также превосходит полную точную настройку, особенно в сценариях с небольшим объемом данных, улучшая возможности обобщения.
В области медицинской визуализации лишь несколько методов используют эффективное обучение передаче параметров на основе адаптера в архитектуре на основе трансформатора. Эти исследования направлены на достижение эффективного переноса параметров из естественных изображений в медицинские изображения. Насколько известно авторам, применение обучения с эффективным переносом параметров в медицинской визуализации в контексте адаптации домена без учителя (UDA) и в сверточных нейронных сетях (CNN) с использованием методов на основе адаптера еще не изучалось.
Выявив этот пробел в исследованиях, авторы предлагают новый адаптивный метод сегментации медицинских изображений с эффективными параметрами (MT UDA), который эффективен в вычислительном отношении и при этом требует мало памяти.
первый,Автор предложил сверточную низкоранговую адаптацию (ConvLoRA).,Как адаптированная версия низкоранговой доменной адаптации (LoRA) на больших языках Модель (LLM). ConvLoRA специально разработан для приложений в сверточных нейронных сетях (CNN).,Предлагается новый подход к проблеме адаптации предметной области данных изображений. Автор не создает Модель, специально настроенную для нескольких целевых доменов.,Каждая Модель имеет такое же количество параметров, что и базовая Модель.,Вместо этого несколькоConvLoRA Adapter Внедрите базовую модель, предварительно обученную в исходном домене, и адаптируйте только параметры ConvLoRA, заморозив при этом все остальные параметры. Этот подход обеспечивает более быстрое обновление за счет адаптации лишь к небольшому набору параметров, специфичных для предметной области.
Во-вторых,Авторы дополнительно смягчают сдвиги предметной области, вызванные статистическими различиями в средних значениях и дисперсии между исходными и целевыми данными.,Без необходимости дополнительных доводок и вычислительных ресурсов. Автор не использует Пакетную нормализацию (BN).,Вместо этого используйте адаптивную пакетную нормализацию (AdaBN).,Он вычисляет среднее значение и дисперсию для конкретной целевой партии.,Вместо использования статистики из данных исходного домена.
Вклад авторов можно резюмировать следующим образом:
- Вдохновленный недавним прогрессом в области крупномасштабных языков Модель (LLM),Авторы предлагают новый многоцелевой метод неконтролируемой доменной адаптации (UDA).,В этом методе используется адаптер ConvLoRA с эффективным параметром, предложенный автором, LoRA. впервые [4] Применительно к сверточным нейронным сетям (CNN),Особенно в контексте UDA в сфере сегментации медицинских изображений.
- Автор показывает, что предложенный автором UDA Pipeline значительно снижает параметры обучения более чем на 99%, а также достигает конкурентоспособных показателей по точности сегментации по сравнению с другими методами.
- ConvLoRA универсален, гибок и легко интегрируется с архитектурами на основе CNN, что значительно снижает затраты на обучение и одновременно повышает адаптивность.
2 Related Work
Неконтролируемая адаптация домена (UDA) В некоторых исследованиях использовались методы состязательного обучения, такие как CycleGAN. и обучение предметно-инвариантным функциям для адаптации моделей сегментации. Хуанг и др. [14] Предлагается метод сопоставления послойных активаций между доменами.
UDA в сегментации медицинских изображений Состязательная сеть для сегментации черепно-мозговых травм была предложена в [15]. Кушибар и др. [16] показали, что точная настройка только последнего слоя CNN повышает производительность. Однако ему не хватает сравнения с другими методами DA. Хотя последний уровень CNN был точно настроен, основное внимание в этой работе было больше на обучении процесса выбора случаев, чем на адаптации [17]. Путем адаптации низкоуровневых слоев достигается кросс-модальный DA для сегментации изображений МРТ и КТ сердца. Для сегментации черепа была выполнена точная настройка ранних слоев U-Net.
Пакетная нормализация (BN) Чанг и др. [19] показали, что неконтролируемая точная настройка слоев BN в целевой области может улучшить возможности адаптации. AdaBN улучшает возможности обобщения, вычисляя скользящее среднее и дисперсию BN в целевой области. Адаптация во время тестирования смягчает дрейф домена за счет пересчета статистики выполнения для текущих входных данных теста.
Эффективная точная настройка параметров (PEFT) Существует две основные стратегии PEFT:
- Добавьте слои адаптера и настройте только эти слои адаптера;
- Оптимизируйте какую-либо форму активации. Даже для использования в небольшой сети Adapter Это также может вызвать задержки в рассуждениях.идополнительные вычислительные затраты。LoRAМинимизируйте задержку за счет разложения предварительно обученных весов на более мелкие матрицы.,Только подстроить эти матрицы,Тем самым уменьшая использование памяти.
3 Method
На рис. 1 показан обзор архитектуры авторов. Авторы интегрируют ConvLoRA и AdaBN в модель UDAS, которая включает в себя 2D U-Net с дополнительной головкой ранней сегментации (ESH). ESH состоит из трех сверточных слоев, за каждым из которых следует слой BN. Авторы внедряют ConvLoRA в кодирующую часть модели UDAS (см. рисунок 1(c)) и выполняют адаптацию посредством самообучения, используя окончательные предсказания сети в качестве псевдометок.
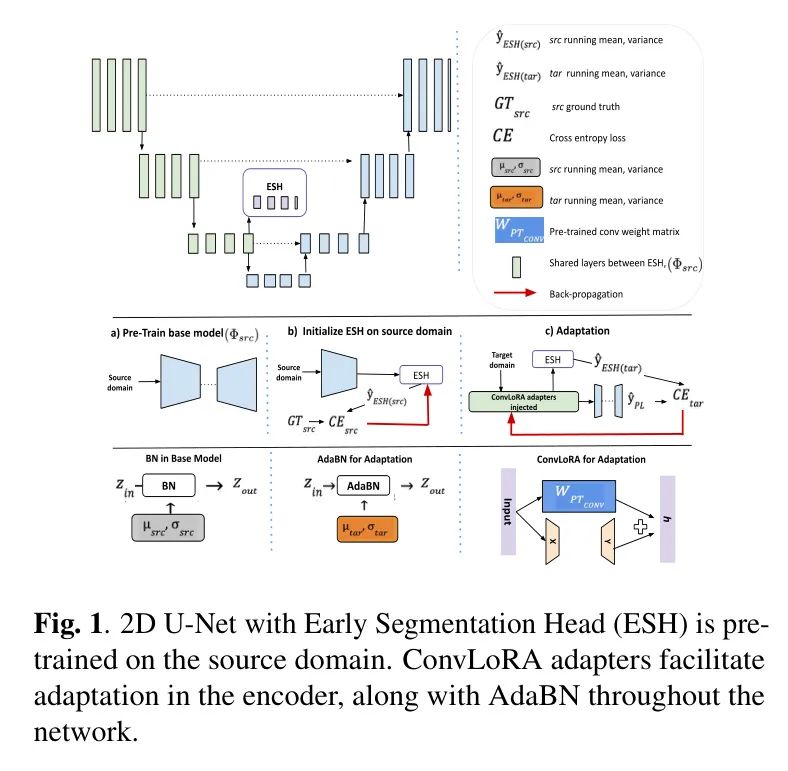
ConvLoRA
Автор предлагает новый ConvLoRA Adapter , который является расширением LoRA [4] для UDA с эффективными параметрами (адаптация неконтролируемой области) сверточных нейронных сетей (CNN). Для предварительно обученной весовой матрицы сверточного слоя , ConvLoRA представляет свои обновления с помощью разложения низкого ранга: , где и представляет собой матрицу низкого ранга с рангом r<<min(m,n)
Во время обучения,
заморожен и не получает обновлений градиента, в то время как
и
Содержит обучаемые параметры.
и
Оба умножаются на входные данные, а соответствующие выходные векторы суммируются по координатам. Таким образом, прямое распространение работает следующим образом:
в
это вход,
Инициализируется случайным распределением Гаусса в начале обучения.
Установите на ноль.
Adaptive Batch Normalization (AdaBN)
в этой работе,Автор использует AdaBN,вместо БН. Хотя BN использует пакетную статистику для нормализации вывода активации.,Но использование статистики исходного домена для нормализации целевого домена может привести к неправильной классификации. AdaBN вычисляет среднее и дисперсию партии для конкретной целевой области [10]. Стандартизируйте каждый уровень по соответствующему домену,Это гарантирует, что данные, полученные каждым слоем, поступают из одинакового распределения.
ConvLoRA and AdaBN based UDA
Baseline настраивать
заключается в использовании только помеченных данных исходного поля
обученная сеть. Цель автора — использовать эффективный по параметрам неконтролируемый способ
Адаптируйтесь к немаркированным целевым данным вне дистрибутива.
. как
В качестве базовой архитектуры автор использует архитектуру U-Net. В качестве базовой линии автор принимает метод, предложенный в [28].
Заголовок раннего разделения (ESH) На этапе адаптации, как показано на рисунке 1, после кодера размещается небольшая CNN, называемая ESH. Автор сравнивает выходные данные ESH на исходном домене с реальными. Mask Перекрестная потеря энтропии между инициализацией ESH. Затем, в процессе адаптации, изображения целевого домена передаются в
и ЭШ. от
Выходные данные сегментации используются в качестве псевдометки (
) для улучшения прогнозирования ESH. На этом этапе, помимо совместного использования между двумя сетями
Помимо кодера,
и Все веса в ESH заморожены. Поскольку энкодер
и ESH распределяется между ними, поэтому улучшение ESH также принесет пользу
。
приспособление В предложенной автором схеме приспособление помимо параметров ConvLoRA и Пакетная нормализация (BN) скользящее среднее и скользящая дисперсия слоя, сеть Все параметры (
) заморожены. Автор интегрировал адаптер ConvLoRA в
часть кодера. хотя
ИESH оба обрабатывают изображения целевого домена так же, как и [28], но авторы ограничивают их использование адаптером ConvLoRA. Градиентное обновление параметров.
Таким образом, у автора есть единственный
в то же время,Уменьшено количество параметров ConvLoRA, специфичных для домена. Для дальнейшего смягчения сдвигов домена эффективным с точки зрения параметров способом.,Автор использовал скользящее среднее и скользящую дисперсию целевого домена, рассчитанные с помощью AdaBN. Обновите статистику исходного домена, рассчитав данные статистики пакетного запуска по целевому объекту. Адаптировать скользящее среднее и дисперсию с помощью AdaBN очень просто.,Это облегчает безпараметрическую настройку без дополнительных параметров и компонентов.,Потому что эти статистические данные не являются обучаемыми параметрами.
4 Experimental Setup
Авторы оценили ConvLoRA на наборе данных Калгари-Кампинас (CC359), наборе данных объемной визуализации мозга различных производителей (GE, Philips, Siemens), магнитно-резонансной томографии (МР) с различной напряженностью поля (1,5, 3). Он содержит шесть различных доменов и 359 объемов трехмерных МРТ-изображений головного мозга, в основном ориентированных на задачу рассечения черепа. исходная модель
Предварительное обучение выполняется на GE в 3 (исходный домен) с использованием деления 80:10:10. в процессе адаптации,Из обучающего набора для каждого целевого домена случайным образом выбираются только 10 изображений.,И выполните вывод на соответствующем официальном тестовом наборе. Предварительная обработка заключается в удалении черных срезов и мин-максном масштабировании.,Все изображения уменьшены до 256.
256 разрешение.
исходная модель (
) с использованием размера пакета 32,Обучение в течение 100 Эпох со скоростью обучения 0,001.,И используйте оптимизатор Адама, оптимизированный по перекрестным энтропийным потерям. ESH тренировался в течение 20 эпох.,Тогда воспользуйтесь авторским методом адаптации,Этот метод обучался всего 5 эпох со скоростью обучения 0,0001. При использовании ConvLoRA,Автор размещает ранг настроек как
, учитывая, что исходный вес ядра равен 3. Surface Dice Score (SDS) используется для оценки эффективности сегментации изображений. Этот показатель более информативен, чем объемный показатель Dice, поскольку он подчеркивает контуры мозга, а не внутренний объем, и широко используется в методах исследования CC359.
Поток обработки находится на Python Реализовано в версии 3.8.17 с использованием библиотеки с открытым исходным кодом PyTorch. 2.0.1. Все эксперименты проводились с установленной операционной системой Ubuntu 20.04.6. LTS、CUDA 11.6иNVIDIA GeForce RTX 3090 выполняется на настольном компьютере с графическим процессором, всего 62 ГБ ОЗУ.
исходная модельотносится только к источникуданные Основы обучения Модель(
),Должен Модель На целевом домене не было выполнено ни одной операции.приспособление。самообучениеМетод использует псевдометки целевого домена для итеративного улучшения.Модельпроизводительность。UDASотносится к автору Baseline метод,Он используется только через псевдотеги.самообучение Приходитьприспособлениесетьначальный слой。UDAS ConvLoRA(ConvLoRA),Для честного сравнения с UDAS,Автор внедрил ConvLoRA только в начальный слой.
Авторская модель: ConvLoRA. + AdaBN, построенный на UDAS - Однако,Автор не ограничивает адаптацию только начальным слоем. Напротив,Автор ConvLoRAприспособлениеEncoder часть всей сети,и поставь ESH после энкодера. также,Автор использует AdaBN для интеграции скользящего среднего и дисперсии целевой области.,Для усиления эффекта приспособления.
Results and Analysis
Таблица 1 показывает, что авторский метод ConvLoRA+AdaBN обеспечивает лучшую производительность, чем все другие методы, имея при этом значительно меньше обучаемых параметров. По сравнению с базовым методом (UDAS), ConvLoRA (UDAS ConvLoRA) работает лучше в четырех из пяти целевых областей.
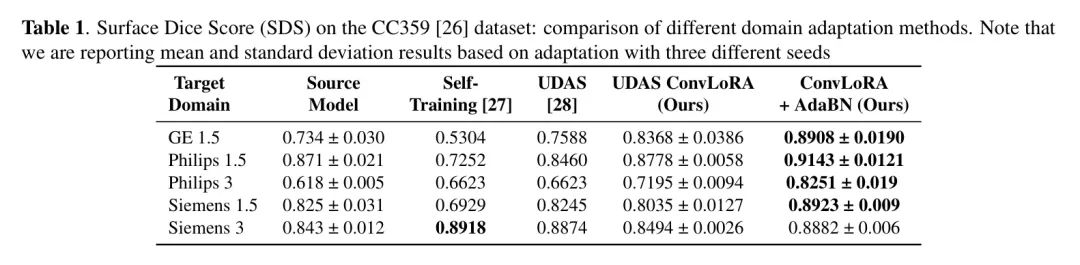
Хотя в области Сименс 1.5,По сравнению с УДАС,ConvLoRA немного снизился на SDS (всего 0,2%),Но стоит отметить, что,Авторское приспособление достигалось при значительно уменьшенных обучаемых параметрах.,от 14 160 (UDAS) уменьшено всего до 3,954 – значительное снижение на 72,07%. Когда автор принимает ConvLoRA (ConvLoRA + AdaBN), ConvLoRA также обеспечивает более высокую точность на Siemens 1.5.
Используемая авторами архитектура U-Net имеет 24,3 миллиона параметров. Приняв предложенный автором метод приспособления на основе ConvLoRA в кодировщике,Обучаемые параметры уменьшены до 57 714.,Снижение на 99,80%. также,Когда автор будетConvLoRA Adapter Используется вместе с AdaBN (сокращенно UDAS). ConvLoRA+AdaBN), он еще больше улучшает возможности Моделиприспособления, и без каких-либо дополнительных параметров производительность превосходит все другие методы, как показано в Таблице 1. Таким образом, как независимые от автора ConvLoRA Adapter , или комбинация ConvLoRA и AdaBN, не только демонстрирует выдающиеся показатели эффективности параметров, но и достигает конкурентоспособных результатов по сравнению с другими методами.

Качественные результаты на рисунке 2 показывают, что авторский многокритериальный метод адаптации домена без надзора (с использованием ConvLoRA + AdaBN, последний столбец) наиболее похож на основную истину (второй столбец). При этом в качественном сравнении авторы также вышли за рамки работ UDAS.
Ablations
Чтобы идентифицировать блоки, подверженные дрейфу домена, авторы представили ConvLoRA. Adapter Интегрируйтесь в различные части сети и оцените их производительность, как показано в Таблице 2. с базовым уровнем (УДАС) разные,Авторы обнаружили, что сдвиги доменов не ограничиваются начальным слоем. Авторы оценилиприспособление БН в кодировщике,Но никакого улучшения производительности обнаружено не было. Оценить ConvLoRA по всей сети,Автор принял объединенную сеть,Но использование ConvLoRA в декодере производительность не увеличило.
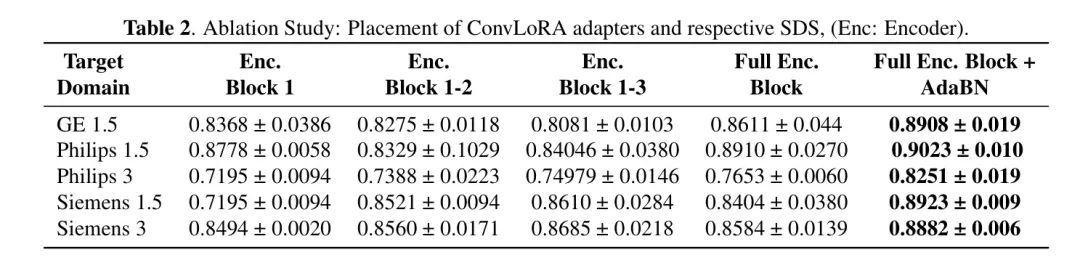
Как показано в Таблице 2,С помощью ConvLoRAприспособление всего блока кодера,Наилучшие результаты были получены авторами. В авторском адаптационном эксперименте,Авторы протестировали различную продолжительность тренировок.,От 5 Эпохи до 20 Эпохи. Оптимальное приспособление происходит только в течение 5 Эпох.,Больше, чем эта эпоха,Переобучение приведет к снижению производительности.
5 Conclusion
В этой работе мы предлагаем эффективный ConvLoRA с нашими новыми параметрами. Adapter Решение проблемы неконтролируемого машинного перевода при сегментации медицинских изображений. проблема UDA, Adapter специально разработан дляCNNнастраиватьзапланировано。Далее автор проходит черезConvLoRAиAdaBN结合Приходить提升производительность。
Результаты экспериментов показывают,ConvLoRA является более точным и вычислительно эффективным, чем предыдущие современные методы. Уменьшив параметры Модели более чем на 99%, автор,производительность остается конкурентоспособной по сравнению с другими методами сегментации UDA. Будущая работа авторов будет сосредоточена на тестировании способности ConvLoRA к обобщению других наборов медицинских изображений.
ссылка
[1].ConvLora and Adabn based Domain Adaptation via Self-Training.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
