CM-UNet: семантическая сегментация изображений с использованием эффективного глобального контекстного моделирования архитектуры Mamba.

Из-за большого масштаба изображений и разнообразных целей современные методы семантической сегментации изображений дистанционного зондирования на основе сверточных нейронных сетей (CNN) и трансформаторов недостаточны для улавливания зависимостей на больших расстояниях или ограничены сложной вычислительной сложностью. В этой статье авторы предлагают CM-UNet, который состоит из кодера на основе CNN для извлечения локальных особенностей изображения и декодера на основе Mamba для агрегирования и интеграции глобальной информации, тем самым способствуя эффективной семантической сегментации изображений дистанционного зондирования. В частности, блок CSMamba представлен для создания базового декодера сегментации, который использует канальное и пространственное внимание в качестве условий активации обычной Mamba для улучшения взаимодействия функций и объединения глобальной и локальной информации. Кроме того, для дальнейшего уточнения функций, выводимых кодером CNN, используется модуль многомасштабной агрегации внимания (MSAA) для объединения функций разных масштабов. Интегрируя блок CSMamba и модуль MSAA, CM-UNet эффективно фиксирует зависимость от больших расстояний и многомасштабную глобальную контекстную информацию крупномасштабных изображений дистанционного зондирования. Экспериментальные результаты, полученные на трех эталонных наборах данных, показывают, что предлагаемый CM-UNet превосходит существующие методы по различным показателям производительности. Код доступен по адресу https://github.com/XiaoBuL/CM-UNet.
I Introduction
Семантическая сегментация изображений дистанционного зондирования включает классификацию пикселей крупномасштабных изображений дистанционного зондирования по различным категориям для улучшения анализа и интерпретации данных дистанционного зондирования (ДЗ). Эта крупномасштабная семантическая сегментация имеет решающее значение для автономного вождения [1], городского планирования [2], защиты окружающей среды [3] и многих других практических приложений.
С появлением глубокого обучения UNet[4] стала базовой магистральной сетью для задач сегментации. UNet известен своей симметричной U-образной архитектурой кодера-декодера и общими пропускающими соединениями, которые эффективно сохраняют ключевую пространственную информацию и объединяют функции на уровнях кодера и декодера для решения проблемы сегментации сложных структур. Однако в области дистанционного зондирования, где изображения часто содержат крупномасштабные сцены со значительными изменениями целей, архитектура UNet, построенная на основе сверточных нейронных сетей (CNN) [5] или Трансформеров [6], сталкивается с ограничениями.
Они могут не полностью отражать глобальный контекст или демонстрировать высокую вычислительную сложность, как показано на рисунках 1(a),(b). Поэтому крайне важно разработать более эффективную архитектуру, которая сможет собирать всеобъемлющую локальную и глобальную информацию.
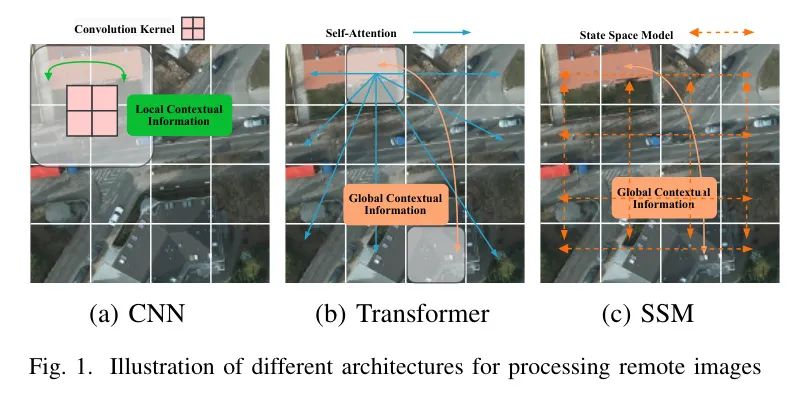
Недавние разработки привели к появлению инновационной архитектуры Mamba [7], которая превосходно справляется с эффективным сбором глобальной контекстной информации. Mamba предназначена для моделирования на больших расстояниях и известна своей вычислительной эффективностью, основанной на модели пространства состояний (SSM) [8]. Впоследствии Vision Mamba [9] и VMamba [10] расширили архитектуру Mamba до области компьютерного зрения и усовершенствовали механизм одностороннего сканирования Mamba. Учитывая эффективные возможности моделирования глобального контекста, архитектура Mamba очень подходит для обработки изображений дистанционного зондирования, как показано на рисунке 1 (c). PanMamba [11], RMamba [12], RS-Mamba [13] и RS3Mamba [14] исследуют методы применения Mamba для обработки изображений дистанционного зондирования. Эти методы либо заменяют сеть блоками Vision Mamba и обучают ее с нуля, либо напрямую применяют предварительно обученные блоки Vision Mamba. Однако они редко рассматривают возможность интеграции локальной и глобальной информации в изображения дистанционного зондирования, что может ограничить их способность полностью использовать функции, предоставляемые предварительно обученными моделями CNN.
В этой статье авторы предлагают CM-UNet, новую структуру для семантической сегментации изображений дистанционного зондирования. CM-UNet использует архитектуру Mamba для агрегирования многомасштабной информации от кодировщиков CNN. Он состоит из U-образной сети с кодером CNN для извлечения многомасштабной текстовой информации и декодера с блоками CSMamba, предназначенными для эффективного агрегирования семантической информации. Блок CSMamba использует блок Mamba для захвата долгосрочных зависимостей с линейной временной сложностью и использует внимание к каналу и пространству для выбора функций.
В качестве альтернативы:
- Авторы предлагают основанную на Mamba структуру под названием CM-UNet для эффективной интеграции локально-глобальной информации в семантическую сегментацию изображений дистанционного зондирования.
- Авторы разработали блок CSMamba для включения информации о каналах и пространственном внимании в блок Mamba для извлечения глобальной контекстной информации. Кроме того, авторы используют модуль многомасштабной агрегации внимания, чтобы помочь пропускать соединения и использовать потерю нескольких выходов для постепенного контроля семантической сегментации.
- Обширные эксперименты проводились с тремя известными публичными коллекциями данных дистанционного зондирования, а именно ISPRS Potsdam, ISPRS Vaihingen и CM-UNet.
II Methodology
Разработанная автором структура CM-UNet, показанная на рисунке 2(a), содержит три основных компонента: кодер на основе CNN, модуль MSAA и декодер на основе CSMamba. Кодировщик использует ResNet для извлечения многоуровневых функций, а модуль MSAA объединяет эти функции, заменяя исходные пропускные соединения UNet и расширяя возможности декодера.
В декодере CSMamba комбинация блоков CSMamba объединяет локальные текстовые функции для обеспечения комплексного понимания языка.
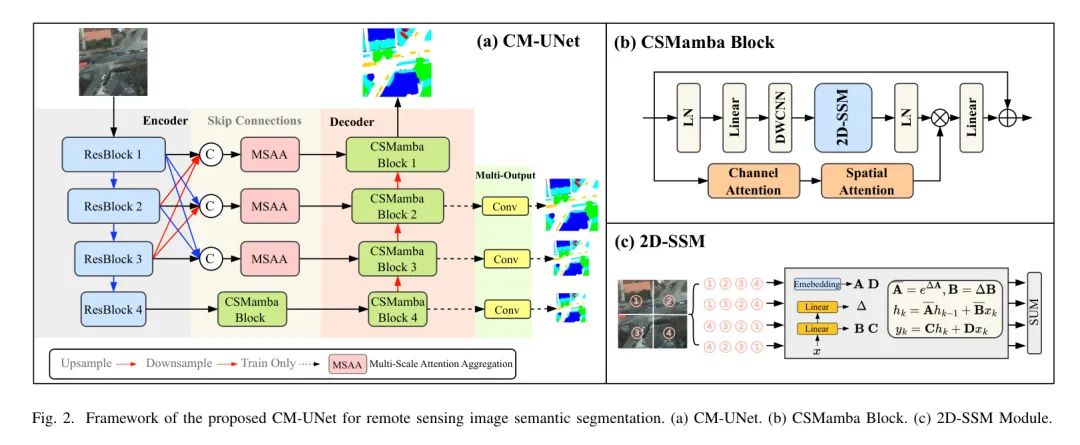
CSMamba Block
Крупномасштабная семантическая сегментация дистанционного зондирования выигрывает от тех моделей, которые могут интегрировать глобальные и локальные возможности обработки информации [15, 16]. Недавние достижения, в том числе архитектура Transformer [17, 18], использующая механизмы самообслуживания, показали значительную эффективность в различных задачах зрения. Однако эти модели часто сталкиваются с ограничениями по квадратичной временной сложности, что создает проблемы с масштабируемостью и эффективностью обработки крупномасштабных изображений дистанционного зондирования.
Это подчеркивает необходимость инновационных подходов к снижению вычислительных требований Transformer при сохранении его преимуществ.

Среди них DWConv представляет собой свертку глубины, CS относится к модулю канала и пространственного внимания, 2D-SSM — модуль 2D выборочного сканирования и представляет произведение Адамара. Исходная модель Mamba [7] обрабатывает одномерные данные посредством последовательного выборочного сканирования, которое подходит для задач НЛП, но бросает вызов беспричинным формам данных, таким как изображения.
Следуя [10], авторы представили модуль 2D-селективного сканирования (2D-SSM) для семантической сегментации изображений.
Как показано на рисунке 2.(c), 2D-SSM сглаживает элементы изображения в одномерную последовательность и сканирует в четырех направлениях: сверху слева в нижний правый угол, из нижнего правого в верхний левый, из верхнего правого в нижний левый и из нижнего нижнего угла. слева направо. Верхний правый. Этот подход фиксирует долгосрочные зависимости в каждом направлении с помощью выборочной модели в пространстве состояний.
Затем последовательности ориентации объединяются для восстановления 2D-структуры.
Multi-Scale Attention Aggregation.

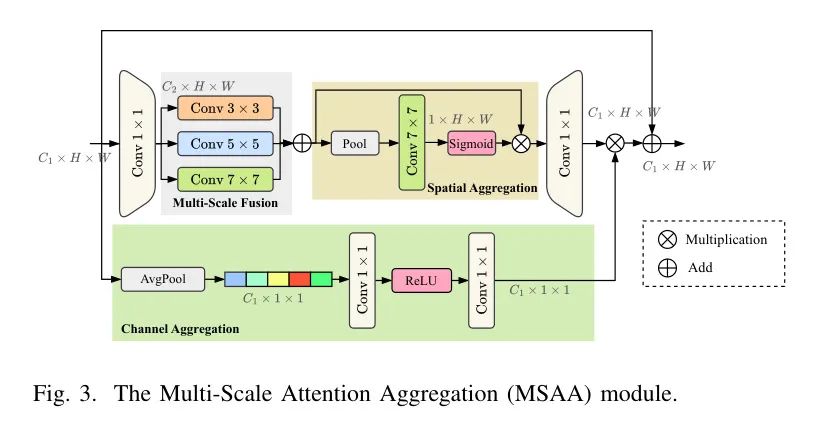
Между тем, агрегация каналов использует объединение глобальных средних значений, чтобы уменьшить размерность до , а затем генерирует карты внимания каналов посредством свертки и активации ReLU. Эта карта расширяется, чтобы соответствовать размерам входных данных, и объединяется с картой пространственного уточнения. Таким образом, MSAA улучшает пространственные и канальные характеристики на последующих уровнях сети. Благодаря включению модуля MSAA полученные карты объектов обогащаются уточненной пространственной и канальной информацией.
Multi-Output Supervision.
Чтобы эффективно контролировать декодер при постепенном создании карт семантической сегментации с изображениями дистанционного зондирования, наша архитектура CM-UNet включает промежуточный контроль в каждом блоке CSMamba. Это гарантирует, что каждый этап сети вносит свой вклад в окончательный результат сегментации, обеспечивая более уточненные и точные результаты. Промежуточный результат для блока CSMamba:

III Experiments
Datasets
Предлагаемый метод оценивается с использованием наборов данных сегментации дистанционного зондирования ISPRS Potsdam, ISPRS Fassingen и LoveDA [19]. В наборе данных ISPRS Potsdam 14 изображений используются для тестирования, а остальные 23 изображения (изображения исключены из-за ошибок в аннотациях) используются в учебных целях. Набор данных ISPRS Fassingen включает 12 фрагментов изображений для обучения и 4 фрагмента изображений для тестирования. Что касается набора данных LoveDA, то обучающий набор состоит из 1156 изображений, а тестовый набор дополнен 677 изображениями. В качестве показателей оценки автор использует средний балл F1 (mF1), среднее пересечение по объединению (mIoU) и общую точность (OA).
Implementation details
Все эксперименты автора проводились на одном графическом процессоре NVIDIA 3090 с использованием фреймворка PyTorch. Автор использует оптимизатор AdamW с базовой скоростью обучения 6e-4 и использует косинусную стратегию для регулировки скорости обучения. Следуя [15], для наборов данных Vaihinge, Potsdam и LoveDA изображения случайным образом обрезаются на блоки. В процессе обучения используются такие методы улучшения, как случайное масштабирование (), случайное вертикальное переворачивание, случайное горизонтальное переворот и случайное вращение, при этом период обучения устанавливается равным 100, а размер пакета равен 16. На этапе тестирования использовалось увеличение времени тестирования (TTA), такое как вертикальное и горизонтальное переворот.
Performance Comparison
Для сравнительного анализа авторы включают в качестве эталонов некоторые примечательные конкурирующие методы, в том числе DeepLabV3+[20], DANet[21], ABCNet[22], BANet[23], CMTFNet[16], UNetformer[15], ESDINet[24], BANet [23] и сегментатор [25]. В этих методах используются известные архитектуры кодировщиков, такие как R18 [26], VMamba [10] и Swin-Base [18].
Iii-C1 The ISPRS Potsdam dataset
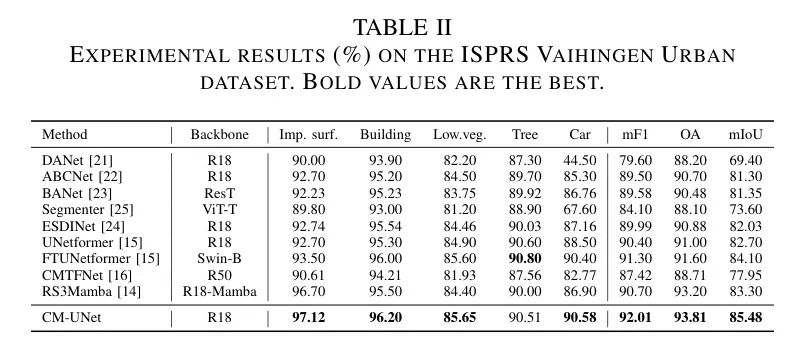
Как показано в таблице 1, CM-UNet превосходит другие конкурирующие методы на тестовом наборе ISPRS Potsdam. Он достигает 93,05% mF1, 91,86% OA и 87,21% mIoU, что на 0,25%, 0,56% и 0,41% выше, чем у UNetformer соответственно. Стоит отметить, что по сравнению с традиционными методами, такими как DANet и Segmenter, он улучшает индекс mIoU на 6,91% и 6,51% соответственно, что подчеркивает эффективность предварительно обученной магистральной сети ResNet и инновационной архитектуры в обучении пространственных объектов.
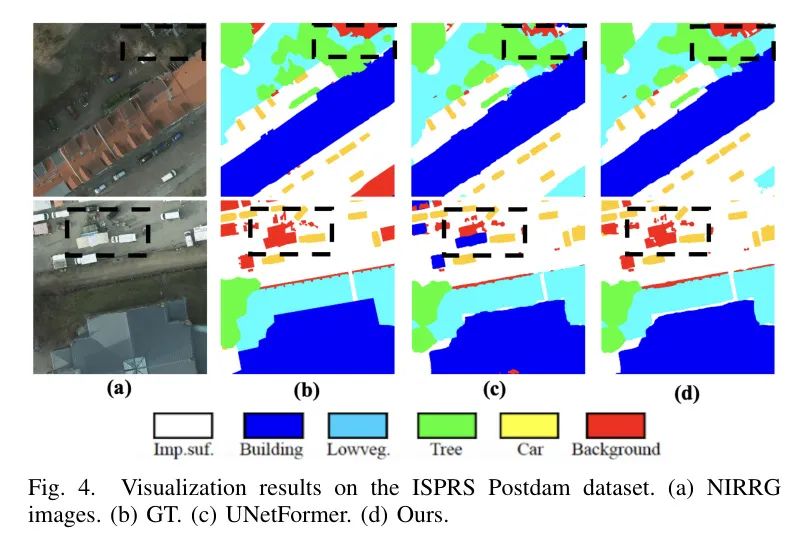
По сравнению с последними моделями, такими как ESDINet, UNetformer и CMTFNet, преимущества CM-UNet по множеству показателей еще раз демонстрируют ее гибкость и эффективность. Качественное сравнение на рисунке 4 дополнительно демонстрирует его превосходство над UNetformer, особенно в выделении более четких контуров зданий и уменьшении ложной сегментации.
Iii-C2 The ISPRS Vaihingen Dataset
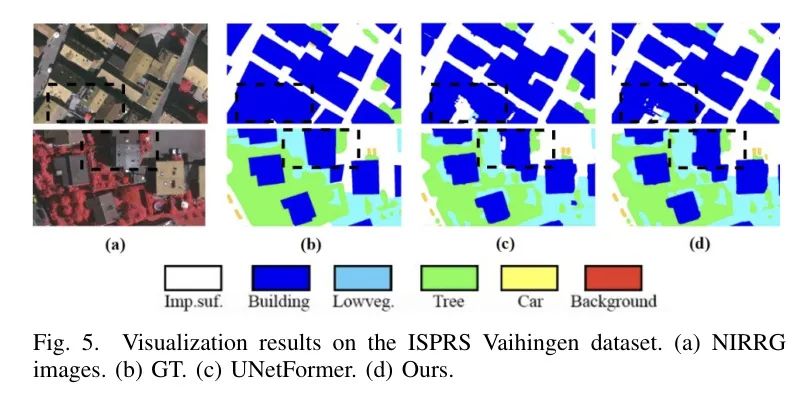
В таблице 2 представлены результаты экспериментов. CM-UNet достигла показателя 85,48% млн., превзойдя конкурентов на 2,78% и составив 16,08%. Его mF1 (92,01%) и ОА (93,81%) также показали хорошие результаты. В рейтинге F1 CM-UNet показывает хорошие результаты во многих категориях, особенно в категориях Imp.surf., Building, Low.weg. и Car. Он превосходит UNetFormer на 4,42% на Imp.surf. Это подчеркивает способность Мамбы захватывать нестандартные объекты и глобально-локальные отношения, которые имеют решающее значение в RS.
Визуализация, показанная на рисунке 5, подтверждает ее точность, особенно при выявлении аномальных образцов и тонких изменений, таких как затенение. Точные прогнозы CM-UNet в категориях серфинга и строительства подчеркивают его способность воспринимать глобальные долгосрочные факты и пространственные контекстуальные особенности.
Iv-C3 The LoveDA Dataset
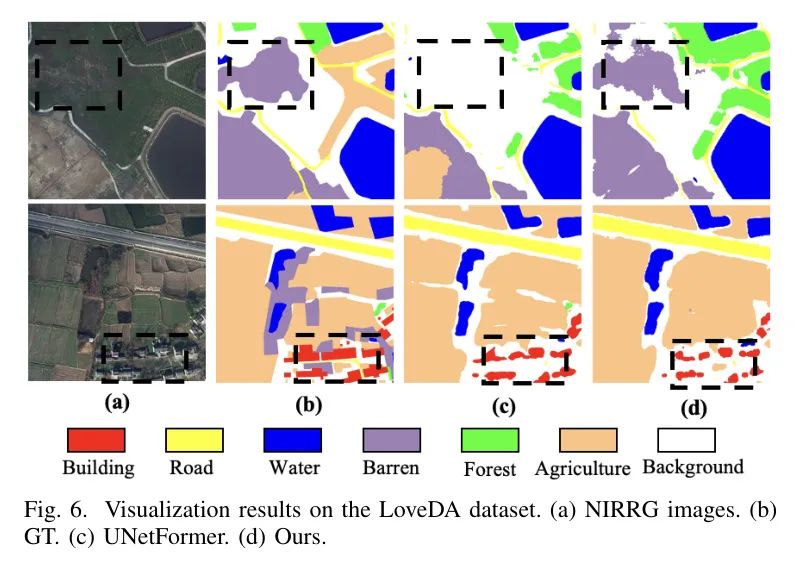
В таблице 3 показаны результаты набора данных LoveDA. Стоит отметить, что авторский метод достиг результативности, mIoU достиг 52,17%. Кроме того, CM-UNet превосходно работает в различных категориях, таких как фон, архитектура и дорога. Визуализация на рисунке 6 подчеркивает превосходство CM-UNet в определении классов земного покрова по сравнению с UNetFormer.
Он точно фиксирует края зданий, дороги и сельскохозяйственные территории, точно приближаясь к меткам GT даже в сложных городских сценах и сложных сельскохозяйственных условиях. Согласованность метода в различных категориях подчеркивает его более высокую точность классификации и расширенные возможности обнаружения границ, которые имеют решающее значение для точного картирования земного покрова. Эти результаты подтверждают эффективность CM-UNet на крупномасштабных изображениях дистанционного зондирования.
Further Analysis
Iv-D1 Effect of Model Architecture
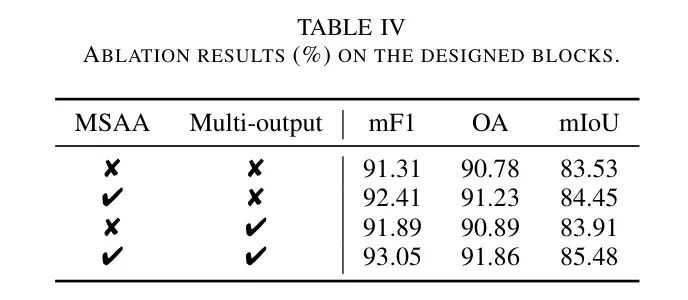
Результаты исследования абляции на разработанном модуле представлены в таблице 4. В частности, простое использование модуля Multi-Scale Attention Aggregation (MSAA) приносит улучшения, демонстрируя его эффективность при сборе контекстной информации в различных масштабах.
Аналогично, объединение стратегий с несколькими выходами еще больше повышает производительность сегментации, демонстрируя преимущества использования нескольких результатов прогнозирования. Примечательно, что совместное использование MSAA и модулей с несколькими выходами привело к наивысшему приросту по всем показателям, подчеркивая синергетический эффект этих архитектурных компонентов в улучшении способности модели различать сложные пространственные особенности и общую точность сегментации.
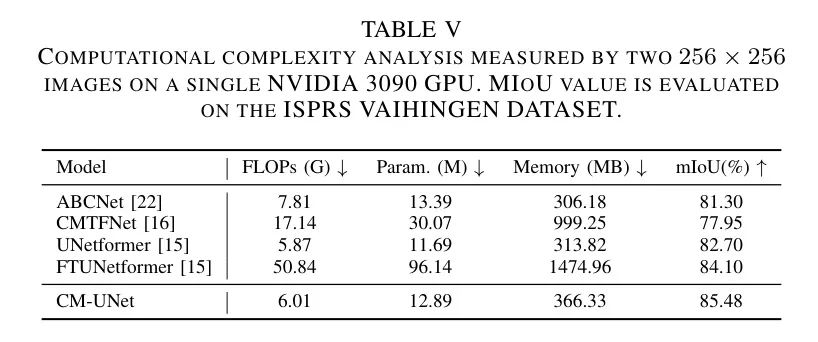
Iv-D2 Model Complexity
В таблице 5 показаны результаты сравнения сложности модели с использованием трех показателей (количество операций с плавающей запятой [FLOPs], количество параметров модели и использование памяти). Стоит отметить, что CM-UNet обеспечивает хороший баланс между этими тремя индикаторами, с меньшими значениями FLOP и количеством параметров, а также относительно небольшим объемом памяти.
Тем не менее, его результаты MIOU превосходят результаты других моделей, что подчеркивает выгодное соотношение цены и качества.
IV Conclusion
В этой статье авторы представляют CM-UNet, эффективную структуру, которая использует новейшую архитектуру Mamba для семантической сегментации дистанционного зондирования (RS). Авторский дизайн позволяет справиться со значительными целевыми изменениями в крупномасштабных изображениях дистанционного зондирования за счет применения новой структуры UNet.
Кодировщик использует ResNet для извлечения текстовой информации, а декодер использует блоки CSMamba для эффективного захвата глобальных зависимостей на больших расстояниях. Кроме того, авторы также интегрируют модуль многомасштабной агрегации внимания (MSAA) и усовершенствование нескольких выходов для дальнейшей поддержки многомасштабного обучения функциям. CM-UNet был проверен на трех наборах данных семантической сегментации дистанционного зондирования, и экспериментальные результаты демонстрируют преимущества авторского метода.
ссылка
[1].CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
