Cigna Life Insurance унифицирует практику стека технологий OLAP на основе Apache Doris
Автор: Группа исследований и разработок платформы больших данных Cigna
В настоящее время такие технологические приложения, как большие данные, искусственный интеллект и облачные вычисления, способствуют развитию страховых технологий и ускоряют процесс цифровизации страховой отрасли. На этом фоне Cigna продолжает изучать способы интеграции и расширения разнообразных данных, чтобы дать возможность агентам получать более подробные сведения о пользователях, а также интегрировать интеллектуальный анализ по всей бизнес-цепочке для достижения всестороннего понимания пользователей, продуктов и стратегий сценариев. итерация по замкнутому циклу. В этой статье подробно описывается исследовательский путь Cigna в построении инфраструктуры больших данных, от начала до онлайн-отчетности, специальных Предоставляемые аналитические услуги OLAP двигатель, постепенно разработанный на основе Apache Dorisпостроенединыйхранилище данных реального времени,Проводить Набор Архитектуры реализует анализ в реальном времени и интеграцию множества данных в различных сферах бизнеса единый менеджмент,В конечном итоге цель по сокращению издержек и увеличению доходов в страховом бизнесе будет достигнута.
В условиях стремительного роста глобального объема данных своевременность и точность данных становятся все более важными для предприятий, позволяющих совершенствовать свою деятельность. Мы надеемся использовать данные для быстрого понимания поведения клиентов, выявления проблем клиентов и эффективного подбора продуктов и услуг, которые нужны пользователям, чтобы достичь таких целей, как усовершенствованный бизнес-маркетинг и расширение границ страхования.
Поскольку бизнес продолжает расширяться, а сценарии анализа становятся все более диверсифицированными, требования бизнес-аналитиков становятся более сложными. Хранилища данных должны не только иметь возможность быстро разрабатывать отчеты о данных, но также должны интегрировать потоковую и пакетную обработку, озеро и хранилище. интеграция и разнообразные типы данных. Унификация анализа и управления. При построении инфраструктуры больших данных эти интегрированные и унифицированные функции приобретают решающее значение. На этом фоне архитектура хранилища данных постоянно модернизировалась и улучшалась. С самого начала она только поддерживалась. BI От архитектуры отчетов и экранов больших данных первого поколения до архитектуры второго поколения, использующей множество систем и компонентов для предоставления услуг обработки данных, до сегодняшнего нового поколения унифицированных хранилищ данных в реальном времени. ,проходить Apache Doris Набор компонентов реализует упрощение архитектуры, унификацию стека технологий, унифицированное управление и анализ данных.,Не только повышает эффективность обработки данных,И удовлетворить более разнообразные потребности в анализе данных.
В этой статье будет подробно описано, как Cigna унифицировала хранилище, вычисления и экспорт запросов на основе Apache Doris во время процесса итерации и обновления архитектуры хранилища данных, как удовлетворить требования своевременности записи и как выполнять перечисление с высоким уровнем параллелизма и Корреляция таблиц в таких сценариях, как достижение чрезвычайно высокой производительности запросов, оказание помощи в эффективном написании и запросе потенциальных клиентов, высокочастотное обновление информации об удержании клиентов, последовательный доступ к данным сценария обслуживания и т. д., дальнейшее преобразование потенциальных клиентов в частный домен. возможности для бизнеса, расширяющие возможности предприятий в сфере операций, услуг, маркетинга и т. д. Универсальные возможности.
Архитектура 1.0: Многокомпонентное хранилище данных квазиреального времени
Первоначальным бизнес-требованием является использование хранилища данных для размещения трех типов бизнес-сценариев: запросов политики самообслуживания для конечных пользователей, отчетов многомерного анализа для бизнес-аналитиков и информационных панелей данных в реальном времени для менеджеров. Хранилище данных должно обеспечивать унифицированное хранилище бизнес-данных и эффективные возможности запросов для поддержки эффективного бизнес-анализа и принятия решений. Оно также должно поддерживать обратную запись данных для осуществления бизнес-операций с замкнутым циклом.
- Запрос на политику самообслуживания: пользователь направляет Cigna Investment APP Согласно политике ID Самостоятельный запрос договора страхования,Или выполните индивидуальные фильтрационные запросы по различным параметрам (например, срок покрытия, категория страхования, сумма претензии).,Просмотр информации в течение срока действия вашего полиса.
- Многомерный анализ отчетов: на основе потребностей бизнеса,Бизнес-аналитики разрабатывают подробные данные, отчеты по показателям.,Получите деловую информацию о страховых полисах с точки зрения инноваций в продуктах, тарифах, мошенничестве с претензиями и т. д.,И соответственно поддерживать корректировку бизнес-стратегии.
- Панель инструментов: в основном используется в определенном банковском канале.、На большом экране филиала в режиме реального времени суммируются показатели и другие данные, а также отображаются популярные виды страхования.、ежедневные продажи、Общая сумма выплат по видам страхования и пропорциям、Исторические тенденции увеличения страховых выплат и другая информация отображаются на большом экране в режиме реального времени.
На раннем этапе бизнеса требования к сервисам данных были относительно простыми, в основном для повышения своевременности данных отчетов. Поэтому в процессе построения хранилища данных мы использовали типовые. Lambda Архитектура, проводит две ссылки для сбора данных в режиме реального времени и в автономном режиме соответственно.、Вычисления и хранение данных: хранилище данных в основном использует широкую табличную модель для сравнения данных индикаторов.、Запрос и анализ подробных данных.
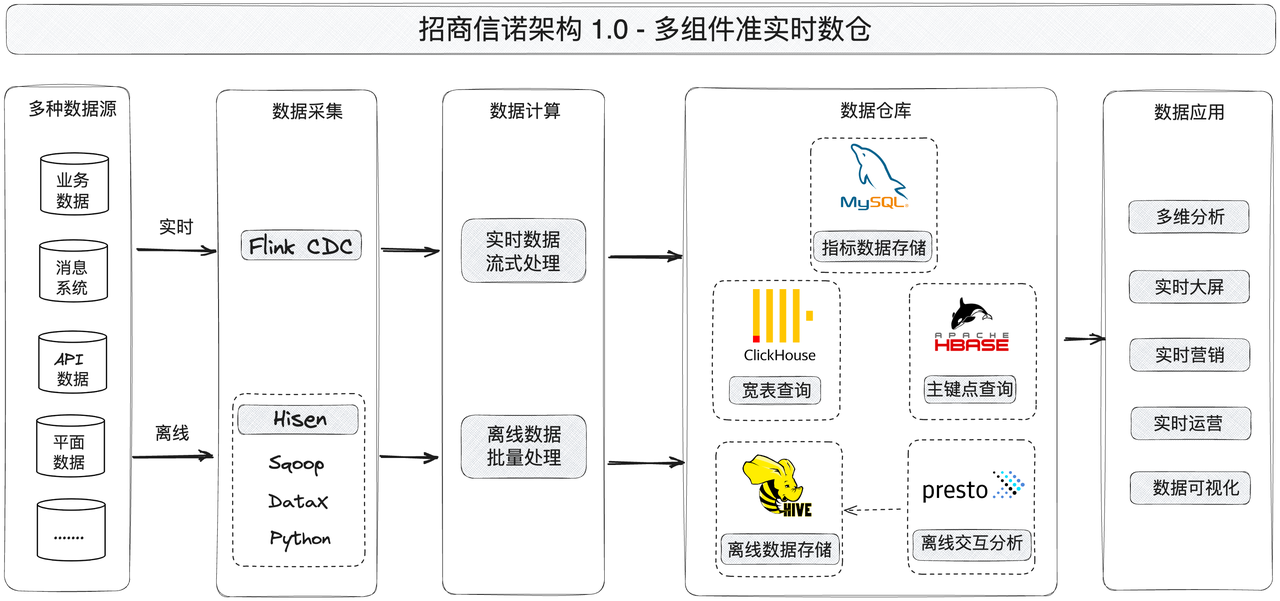
Как видно из диаграммы архитектуры, FlinkCDC отвечает за сбор данных в реальном времени, а наши собственные инструменты Hisen (включая Sqoop, DataX и Python) отвечают за сбор данных в автономном режиме. После сбора исходных данных данные в реальном времени рассчитываются с помощью Flink, а автономные данные передаются в Hive для пакетной обработки. Наконец, они импортируются в различные компоненты OLAP (включая Presto, Clickhouse, HBase и MySQL). OLAP предоставляет услуги по работе с данными для бизнеса верхнего уровня. Каждый компонент играет различную роль в архитектуре.
MySQL
В соответствии с потребностями бизнеса он в основном используется для хранения данных индикаторов после расчета данных. В настоящее время объем данных таблиц хранилища данных превысил десятки миллионов, но хранилище MySQL имеет ограничения и подвержено таким проблемам, как длительное время выполнения и ошибки возврата системы.
Clickhouse
Clickhouse хорошо работает при чтении данных из одной таблицы, но имеет низкую производительность при объединении больших таблиц. Поскольку бизнес-сценарии увеличиваются, а объем данных в реальном времени продолжает накладываться и обновляться, Clickhouse имеет определенные ограничения в удовлетворении новых потребностей бизнеса:
- Чтобы сократить повторный расчет показателей, необходимо ввести звездообразную схему для многотабличного объединения и высококонкурентного запроса, которую Clickhouse не поддерживает;
- При изменении содержания политики данные необходимо обновлять и записывать в режиме реального времени. Однако в Clickhouse отсутствует поддержка транзакций в реальном времени. При изменении данных необходимо заново создавать широкие таблицы, чтобы перезаписать старые данные. в требованиях своевременности обновления данных;
HBase
В основном используется для запроса первичного ключа, чтения основных данных о статусе пользователя из MySQL и Hive, включая баллы клиентов, время страхования и накопленную сумму страхования. Поскольку HBase не поддерживает вторичные индексы, чтение данных непервичного ключа ограничено и не может соответствовать сценариям связанных запросов. В то же время HBase не поддерживает запросы операторов SQL.
Presto
Из-за ограничений сценария вышеупомянутых компонентов при запросе данных мы также представили Presto в качестве механизма запросов к автономным данным для проведения интерактивного анализа данных в Hive и предоставления услуг отчетности для вышестоящего конца.
После запуска Data Warehouse 1.0 оно использовалось более чем в 10 филиалах и было разработано большое количество больших экранов данных и BI-отчетов. С постоянным расширением масштабов бизнеса такие сценарии, как маркетинг, операции и обслуживание клиентов, предъявляют более высокие требования к записи данных и производительности запросов. Однако архитектура версии 1.0, которая использует четыре компонента для предоставления услуг передачи данных, сталкивается с некоторыми проблемами в реальном бизнесе. . Чтобы избежать таких проблем, как увеличение затрат на эксплуатацию и техническое обслуживание, а также увеличение затрат на обучение персонала, занимающегося исследованиями и разработками, из-за слишком большого количества архитектурных компонентов, а также обеспечить согласованность данных из нескольких источников в офлайн-каналах и каналах реального времени, мы решили приступить к реализации итеративный путь обновлений архитектуры.
Требования к компонентам и выбор системы
Для удовлетворения потребностей бизнеса нам необходимо «разгрузить» архитектуру и максимально сократить процесс обработки данных. Архитектура 1.0 неизбежно снизит производительность и своевременность хранения и анализа данных из-за таких проблем, как слишком большое количество компонентов и избыточность каналов. Поэтому мы надеемся найти систему OLAP, которая сможет охватить большинство бизнес-сценариев, снизить затраты на разработку, эксплуатацию, обслуживание и использование, вызванные сложными стеками технологий, а также максимизировать производительность архитектуры. Конкретные требования заключаются в следующем:
- Производительность импорта: он имеет возможность записи и обновления в реальном времени, а также поддерживает высокопроизводительную запись больших данных.
- Производительность запросов: предоставляет службы запросов для многомерных данных и данных транзакций с возможностью высокопроизводительных запросов в реальном времени для больших данных.
- Гибкий многомерный анализ и возможности самообслуживания запросов: поддержка индекса первичного ключа может быть предоставлена не только для выполнения точечных и диапазонных запросов.,Он также может выполнять многомерный поиск и анализ.,Предоставляет запросы на ассоциации таблиц для миллиардов данных.,Реализуйте гибкий и динамичный анализ бизнес-данных с детализацией и свертыванием.
- Упрощение архитектуры платформы данных: необходим компонент с мощными комплексными возможностями для замены текущей избыточной архитектуры для удовлетворения потребностей чтения и записи данных в режиме реального времени и в автономном режиме, высокой производительности запросов в различных сценариях, а также простоты и удобства в использовании. используйте запросы операторов SQL.
Исходя из этого, мы приступили к выбору системы, сравнили популярные компоненты на рынке с существующими архитектурами по многим аспектам и оценили, соответствуют ли они потребностям бизнес-стороны в компонентах. Наконец, мы заперли Apache Doris среди множества OLAP. Конкретные причины таковы. следующее:
- Поддерживает запись в реальном времени с малой задержкой: поддерживать FlinkCDC Высокая пропускная способность записи больших объемов данных, предоставление внешних служб данных в реальном времени; поддержка слияния модели таблицы первичных ключей во время записи, реализация микропакетной высокочастотной записи в реальном времени; Upsert и Insert Перезапись обеспечивает эффективное обновление данных.
- Убедитесь, что данные последовательны и упорядочены: поддерживать Label Механизм и транзакционный импорт, гарантирующий, что процесс написания Exactly Once Семантика; поддержка модели первичного ключа Sequence Настройки столбца обеспечивают порядок при импорте данных.
- Отличная производительность запросов: Doris поддерживать Rollup Предварительно агрегированные и материализованные представления обеспечивают ускорение обработки запросов, что позволяет сократить количество вызовов виртуальных функций и сократить число вызовов виртуальных функций; Cache Мисс поддержка инвертированного индекса для ускорения текстовых занятий;、Обычное числовое значение、Полнотекстовый поиск или запрос диапазона, например типа даты.
- Поддержка запроса точки с высоким параллелизмом: поддерживать Раздельная и ковшовая обрезка,проходить Partition Разделение и установка времени Bucket Количественно фильтровать несущественные данные, чтобы уменьшить необходимость сканирования базовых данных и, кроме того, обеспечить быстрое позиционирование запросов; Doris 2.0 В версию также добавлен ряд оптимизаций, таких как формат хранения строк, перечисление коротких путей и операторы предварительной обработки, чтобы еще больше повысить эффективность выполнения перечисления и снизить SQL накладные расходы на анализ.
- Поддерживает несколько моделей данных: поддерживатьзвездная схема,Удовлетворение потребностей связанных запросов к таблицам данных миллиардного уровня поддерживает агрегирование больших и широких таблиц;,Обеспечивает чрезвычайно высокую производительность запросов к одной таблице и возможности многомерного анализа.
- Простая архитектура, простота эксплуатации и обслуживания, простота расширения и высокая доступность: Doris FE Узел отвечает за управление метаданными и несколькими копиями, BE Узлы отвечают за хранение данных и выполнение задач. Это делает Архитектуру простой в развертывании и настройке и в то же время простой в эксплуатации и обслуживании; Doris Возможность добавления и удаления узлов одним щелчком мыши, автоматическое завершение копирования и балансировка нагрузки между узлами, легкое расширение, а также при выходе из строя одного узла, Дорис; Он по-прежнему может поддерживать стабильную работу кластера и соответствовать нашим требованиям к высокой доступности сервисов и высокой надежности данных.

Из сравнительной таблицы мы также видим, что независимо от сценария в реальном времени или в автономном режиме Apache Doris обладает наиболее сбалансированными и превосходными комплексными возможностями и может поддерживать запросы самообслуживания, возможности анализа OLAP в реальном времени и в автономном режиме, высокий уровень параллелизма. ассоциация запросов и таблиц и т. д. Сценарии запросов и отличная производительность при написании, высокая доступность, простота использования и т. д. Это компонент, который может удовлетворить несколько бизнес-сценариев.
Архитектура 2.0: унифицированный стек технологий на базе Apache Doris.

Два поколения архитектуры хранилищ данных в основном различаются с точки зрения хранения, вычислений, запросов и анализа. Версия 1.0 использует несколько компонентов для совместного создания механизма анализа OLAP. На этапе расширения бизнеса постепенно возникают такие проблемы, как избыточность архитектуры хранилища, задержка данных и чрезмерные затраты на обслуживание. Версия архитектуры 2.0 основана на обновлении и преобразовании Apache Doris, замене четырех компонентов Presto, MySQL, HBase и Clickhouse и переносе данных в Apache Doris для предоставления унифицированных служб внешних запросов.
новый Архитектуране только достигнутоУнификация стека технологий,Это также снижает затраты на разработку, хранение, эксплуатацию и обслуживание и т. д.,Достигнуто дальнейшее улучшение бизнес-данных. Система на базе Apache Doris может поддерживать обработку задач как в режиме онлайн, так и в автономном режиме.,выполнитьЕдиное хранилище данных;Может соответствовать различным сценарияманализ данных Служить,Поддержка Высокопроизводительный интерактивный анализ и точечный запрос с высокой степенью параллелизма,выполнитьУнификация бизнес-анализа。
01 Повысьте эффективность анализа данных
проходить Doris Чрезвычайно высокая производительность анализа для C В сценарии точечного запроса конечных пользователей с высоким уровнем параллелизма QPS Он может достигать тысяч или десятков тысяч и обеспечивать ответ на уровне миллисекунд на запросы сотен миллионов или миллиардов данных; использовать Doris Богатые методы импорта данных и эффективные возможности записи обеспечивают задержку записи второго уровня и позволяют использовать Unique Key Объединение при записи для дальнейшего повышения производительности запросов на этапах параллельного чтения и записи. Кроме того, мы также используем Doris Горячие и холодные уровни хранят огромные объемы исторических «холодных» данных на дешевых носителях, что снижает стоимость хранения исторических данных и повышает эффективность запросов к «горячим» данным.
02 Сокращение различных затрат и затрат
По сравнению с исходной архитектурой новая архитектура вдвое сократила количество основных компонентов, значительно упростила архитектуру платформы и значительно снизила затраты на эксплуатацию и обслуживание. Кроме того, Апач Doris Это устраняет необходимость в различных компонентах для выполнения служб хранения и запроса данных, сокращая бизнес-нагрузки в режиме реального времени и в автономном режиме, а также снижая затраты на услуги хранения данных; API предоставлено извне Служить Нет необходимости объединятьв реальном времении Офлайн-данные,включить службы передачи данных API Стоимость разработки на момент интеграции снижается до 50 %;
03 Обеспечьте высокую доступность услуг передачи данных
потому что хранилище данных Дорис Архитектура для хранения, вычислений и услуг,Общий план аварийного восстановления платформы легко реализовать.,Больше не нужно беспокоиться о потере данных, вызванной несколькими компонентами.、Проблемы, вызванные повторением。Что еще более важно, Дорис Встроенная межкластерная репликация. CCR функция, которая может обеспечить синхронизацию таблиц базы данных между кластерами за считанные секунды или минуты.,Когда сбой системы приводит к прерыванию или убыткам бизнеса,Можем быстро восстановить из резервной копии.
Два основных механизма функции CCR межкластерной репликации Doris удовлетворяют нашим требованиям к доступности системных сервисов и обеспечивают высокую доступность сервисов передачи данных, а именно:
- Binlog Механизм: при изменении данных этот механизм может автоматически записывать операции изменения данных и строить возрастающую последовательность для каждой операции. LogID обеспечивает отслеживаемость и упорядоченность данных.
- Механизм сохранения: после сбоя системы или возникновения чрезвычайной ситуации.,Этот механизм может сохранять данные на диске, чтобы обеспечить надежность и согласованность данных.
Доходы и практика страхования передового бизнеса
В настоящее время хранилище данных реального времени на основе унифицированного стека технологий Apache Doris было запущено в третьем квартале 2022 года и введено в производственную среду. Оно используется для поддержки возможностей эффективного анализа больших данных OLAP и поддерживает больше сценариев, связанных с бизнесом. платформа. Что касается бизнес-операций, масштабы продаж также постоянно расширяются и в настоящее время достигли 100 миллионов уровней. С дальнейшим внедрением функций Apache Doris доходы первичного бизнеса, поддерживаемые хранилищами данных, также продолжают расти.
- Эффективное отслеживание потенциальных клиентов: На данный момент мы запустили отслеживание продаж и эффективности 30 + Благодаря применению новых сценариев бизнес-персонал может точно и быстро получать оценки страховок клиентов, справочные данные прямых трансляций, справочные данные о корпоративной микродеятельности, страхование без страхования и т. д. через официальные веб-сайты, приложения, торговые центры, общедоступные учетные записи, мини- программы и другие каналы, основанные на траектории продаж, данных и методах. Apache Doris Многомерный анализ используется для преобразования потенциальных клиентов и, в конечном итоге, для достижения точного контакта с клиентами, эффективного выявления мотивации клиентов и своевременного выполнения заказов.
- Информация об удержании клиентов часто обновляется: Запущены новые категории конверсии клиентов и старые категории обслуживания клиентов. 20 + Применение новых сценариев и плавное развитие бизнес-сценариев неотделимы от способности платформы данных высокочастотно обновлять сохраняемую клиентом информацию. Apache Doris Регулярный анализ данных старых клиентов может эффективно исследовать потребности страхового бизнеса клиентов на разных этапах, обнаруживать пробелы в защите старых клиентов, расширять границы страхования старых клиентов и дополнительно увеличивать операционный доход бизнеса.
- Последовательный доступ к данным бизнес-сценариев: С точки зрения обслуживания клиентов мы более Обеспечить клиентам стабильный опыт и услуги быстрого реагирования. В настоящее время мы онлайн 20 + Новый сценарий применения соответствующего опыта обслуживания позволяет избежать асимметрии информации и несогласованности данных, а также гарантирует, что данные каждого звена продаж могут быть согласованными и унифицированными при андеррайтинге, претензиях, консультациях по обслуживанию клиентов, центре участников и других процессах.
планы на будущее
Внедрение Apache Doris играет решающую роль в упрощении архитектуры хранилища данных реального времени и повышении производительности. В настоящее время мы заменили несколько компонентов Presto, Clickhouse, MySQL и HBase на основе Apache Doris, чтобы унифицировать стек технологий OLAP, сократить различные затраты и повысить производительность импорта и запросов.
В то же время мы также планируем и дальше развивать Doris На уровне пакетной обработки (Batch Layer), объединяющий автономную пакетную обработку данных в Doris продолжить, решить Lambda Проблема перекрытия затрат и несовместимости архитектур в режиме реального времени и в автономном режиме заключается в том, чтобы по-настоящему реализовать унификацию архитектуры в вычислениях,хранении и анализе. При этом мы продолжим играть Doris Преимущества единого,использовать Multi-Catalog Обеспечьте свободный обмен данными между озерами и хранилищами, обеспечьте бесперебойные и чрезвычайно быстрые услуги анализа в озерах данных и нескольких гетерогенных хранилищах и станьте более полной, открытой и унифицированной экосистемой технологий больших данных.
Большое спасибо SelectDB Команда всегда была увлечена нашими технологиями. На данный момент хранилище данных Cigna больше не ограничивается простыми сценариями создания отчетов. Набор Архитектуры поддерживает множество различных сценариев. данных, которые обеспечивают запись и запрос данных в режиме реального времени и в автономном режиме, а также обеспечивают маркетинг продуктов, операции с клиентами, C Дуаньхэ B Обеспечьте ценность данных для терминалов и других предприятий, позволяя сотрудникам страховых компаний более эффективно получать данные, более точно прогнозировать потребности клиентов и расширять возможности для предприятий.
В будущем мы продолжим участвовать в создании сообщества Apache Doris и вносить свой вклад в создание хранилищ данных в реальном времени и практические приложения страховой отрасли. Мы надеемся, что Apache Doris будет продолжать расти и развиваться и вносить свой вклад в создание хранилищ данных в реальном времени. базовое программное обеспечение!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
