Что такое Стар Рокс? Одна статья для понимания (рекомендуется собрать)
Привет, я Вуконг.
В области анализа данных в режиме реального времени в отечественных базах данных постепенно появился проект с открытым исходным кодом. StarRocks,Эта аналитическая библиотека данных меняет наше представление об обработке данных в реальном времени.
Что за продукт представляет собой StarRocks? Какую позицию вы занимаете в экосистеме больших данных? Какие особенности есть? Как спектакль?
Пристегните ремни, обмен знаниями в базе данных отключен.
1. Что такое StarRocks?
StarRocks — это проект Linux Foundation. Это новое поколение чрезвычайно быстрой полнофункциональной базы данных MPP, использующей протокол с открытым исходным кодом Apache 2.0. Он имеет простую архитектуру, использует комплексный механизм векторизации и оснащен недавно разработанным оптимизатором CBO для достижения скорости выполнения запросов менее секунды, особенно запросов, связанных с несколькими таблицами. StarRocks также поддерживает современные материализованные представления для дальнейшего ускорения запросов.
2. Позиционирование StarRocks в экосистеме данных
Поскольку объем данных увеличивается, а требования продолжают расти, первоначальная экосистема больших данных с Hadoop в качестве ядра не может удовлетворить потребности предприятий с точки зрения производительности, эффективности, сложности в эксплуатации и обслуживании, а также гибкости, с которыми сталкиваются базы данных OLAP. Постоянно растущие проблемы возникают все больше и больше, и трудно иметь базу данных, которая может адаптироваться к большинству предприятий. В настоящее время существуют сложенные приложения с несколькими стеками технологий, такие как Hive, Druid, CK, ES, Presto. и т. д. Хотя это может решить проблему, разработка и стоимость и сложность эксплуатации и обслуживания также увеличиваются.
В качестве аналитической базы данных с архитектурой MPP StarRocks может поддерживать объемы данных уровня PB, имеет гибкий метод моделирования и может создавать чрезвычайно быстрый и унифицированный уровень анализа с помощью таких методов оптимизации, как механизмы векторизации, материализованные представления, растровые индексы и разреженные индексы. .Система хранения данных.
В общей экосистеме больших данных:
- С точки зрения приложений верхнего уровня StarRocks совместим с протоколом MySQL и может плавно подключаться к различным инструментам бизнес-аналитики с открытым исходным кодом или коммерческим, таким как Tableau, FineBI, SmartBI, Superset и т. д.;
- сеанс синхронизации данных, StarRocks Можно получить из Oceanbase Подождите, пока транзакционные данные проведут бизнес-данные. CloudCanal Подождите, пока инструмент сбора данных напишет StarRocks。
- середина ETL Работу можно выполнить в вычислительной машине, например, с помощью Flink или Spark。StarRocks Соответствующий Flink Connector и Spark Connector。
- Также можно использовать ELT режим, загруженный в данные StarRocks После этого используйте StarRocks из Материализованного просмотра в режиме реального времени Join Умение проводить моделирование данных. существовать StarRocks Вы можете выбирать из множества моделей данных, таких как предварительное агрегирование, широкая таблица, высокая гибкость, модель звезды/снежинки.
- В то же время вы можете использовать Iceberg、Hive、Hudi Внешняя функция создает интегрированную архитектуру озера и склада. данные Озеро содержит ценные данные, которые могут попасть в него. StarRocks Связать Запрос пока; StarRocks Скрытая ценность носителя данных невелика. Изданные данные также могут поступать в озеро данных недорогим способом.
После серии моделирования данные в StarRocks могут использоваться в различных сценариях потребления, таких как бизнес-отчеты, мониторинг показателей в реальном времени, интеллектуальный многомерный анализ, выбор группы клиентов и бизнес-аналитика самообслуживания.
3. Архитектура и функциональные характеристики.
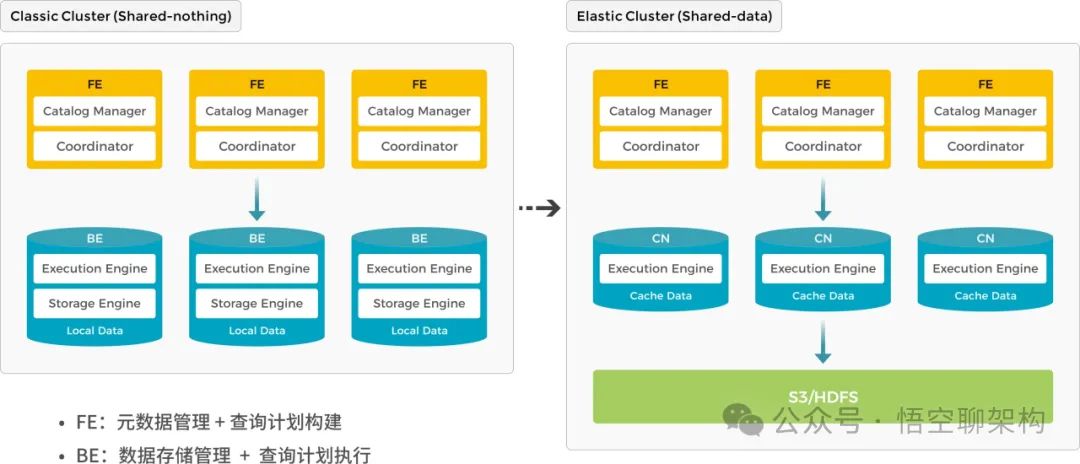
Архитектурный дизайн StarRocks объединяет идеи дизайна базы данных MPP и распределенных систем и имеет минималистские архитектурные характеристики. Вся система состоит из интерфейсных узлов (FE) и внутренних узлов (BE и CN). Такая конструкция упрощает развертывание и обслуживание StarRocks, одновременно повышая надежность и масштабируемость системы.
- механизм векторизации:StarRocks использовать векторизованный движок Запрос,Сократите количество обращений к данным за счет параллельного выполнения.,Значительно улучшена скорость обработки данных.
- CBO (оптимизатор затрат):StarRocks использовать CBO Грамотный выбор наилучшего плана выполнения, оптимизация Запроспроизводительности с точной оценкой затрат.
- Высокий параллельный запрос:путем оптимизации Запрос Планированиеи Распределение ресурсов,Убедитесь, что при одновременном доступе к нему нескольких пользователей,Система может работать стабильно и быстро реагировать на каждый запрос.
- Гибкое моделирование данных:Позволяет пользователям создавать сложныеизданные Модель,Например, модель звезды и модель снежинки. Эта гибкость поддерживает сложные изданные процессы анализа.,Повышение организационной эффективности данныхизи Запроса.
- Интеллектуальные материализованные представления:Пользователи могут заранее определитьихранилищесложныйиз Запросрезультат,путем предварительной полимеризацииданныеулучшать Запросскорость、уменьшатьхранилищерасходы。StarRocks Как синхронные, так и асинхронные материализованные представления поддерживают интеллектуальную и прозрачную перезапись, которую можно гибко создавать и удалять по требованию без изменений во время работы. SQL,Автоматически перезаписывать,Большой опыт и опыт.
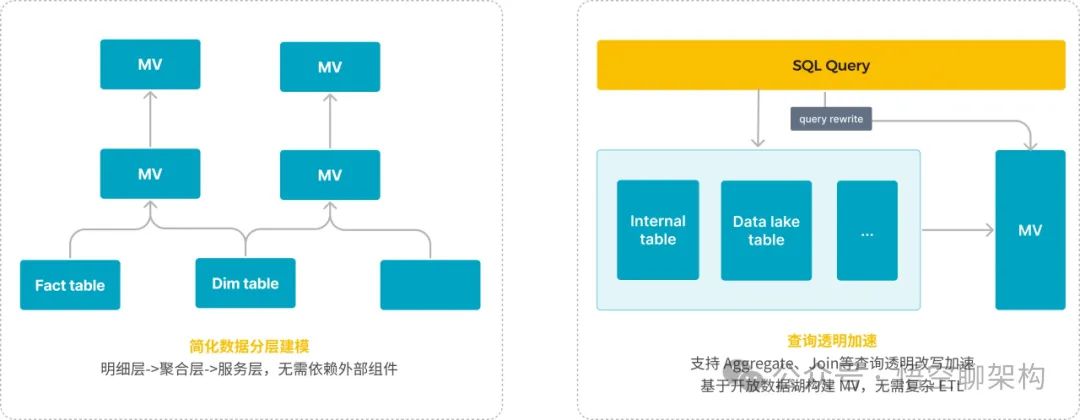
- Интегрированные возможности озер и складов:комбинированныйданныеозероизгибкостьиданныескладиз Аналитические навыки,Обеспечивает единую изданную платформу,Упрощенное хранение, обработка и анализ данных,Нет необходимости переносить данные между разными системами.
- Разделение хранения и расчета:StarRocks3.0 Знакомство с версией Разделение хранения и расчета Архитектура,Реализуйте полное разделение вычислительных и хранилищ.,Вычислительные узлы могут достигать динамического расширения и сжатия за считанные секунды. Добейтесь более гибкого совместного использования, эластичности ресурсов и изоляции ресурсов.,В целом производительность связана с экономией и расчетами.
- совместимость:поставлять MySQL Интерфейс протокола, стандарты поддержки SQL синтаксис, пользователи могут пройти MySQL Удобный анализ Запросов на стороне клиента StarRocks серединаизданные
Эти функции делают StarRocks отличным средством обработки и анализа данных, а также обеспечивают эффективную поддержку многопользовательского режима и управления ресурсами.
4. Сравнительный тест производительности
Тест производительности сценария с одним столом SSB: StarRocks, ClickHouse и Druid
По 13 запросам стандартного набора тестовых данных общая производительность запросов StarRocks в 2,1 раза выше, чем у ClickHouse, и в 8,7 раза выше, чем у Apache Druid.
После включения Bitmap Index в StarRocks общая производительность запросов в 1,3 раза выше, чем при его отключении. На данный момент общая производительность запросов в 2,8 раза выше, чем у ClickHouse, и в 11,4 раза выше, чем у Apache Druid.
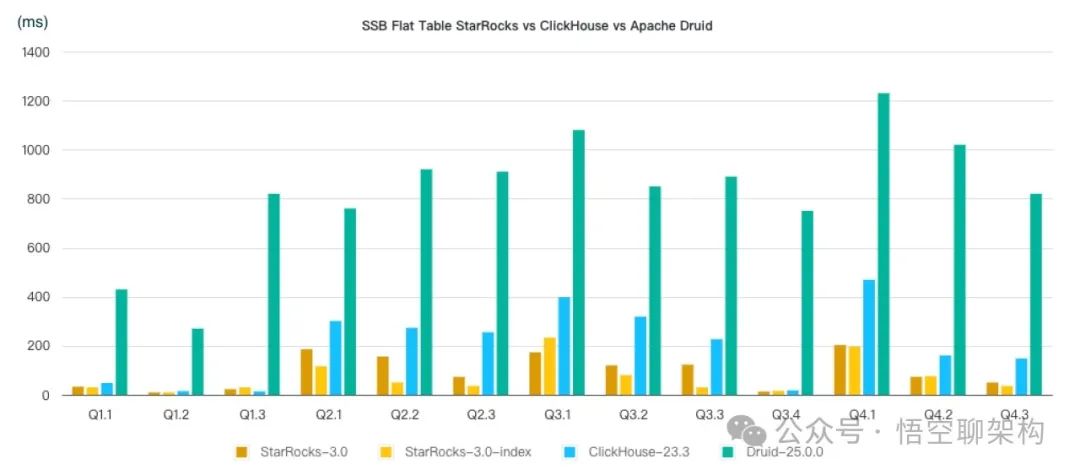
“использовать 3x16core 64GB Хост облака памяти, в 6 Был протестирован масштаб данных в миллиарды строк. Источник: https://docs.starrocks.io/zh/docs/benchmarking/SSB_Benchmarking/
Тест TPC-H: таблицы Hive StarRocks и запросы Trino
Сравнительное тестирование проводилось на наборе данных масштаба TPC-H 100G. Общее время запроса к локальному хранилищу StarRocks составило 17 с, общее время запроса к таблице StarRocks Hive — 92 с, а общее время запроса Trino — 187 с.
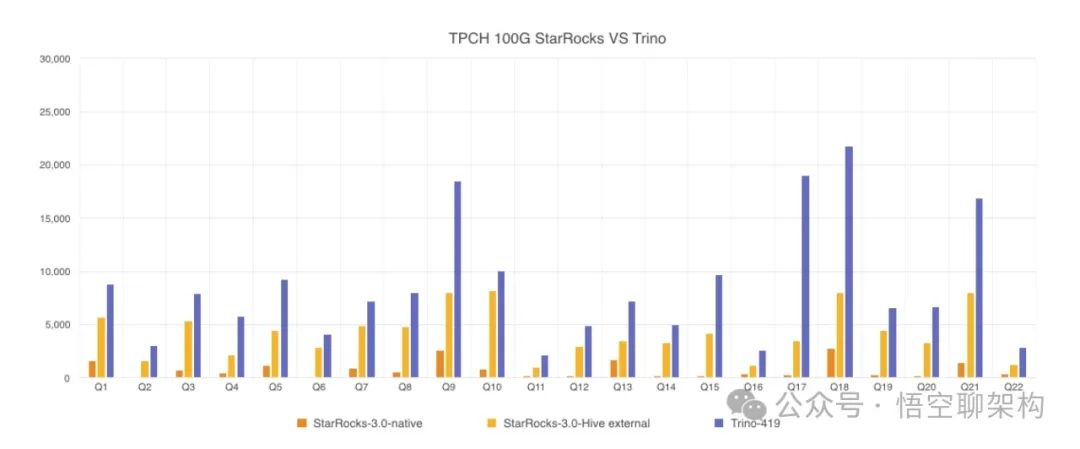
“Должентест Содержит 8 таблицу, объем данных можно установить из 1 GB~3 TB Нет, подожди. Источник: https://docs.starrocks.io/zh/docs/benchmarking/TPC-H_Benchmarking/
Тест производительности TPC-DS: StarRocks против Trino
Используя для тестирования набор данных TPC-DS1TB, StarRocks и Trino запросили одну и ту же копию данных файла Parquet, хранящегося в формате таблицы Apache Iceberg. Общее время ответа на запрос StarRocks было в 5,54 раза быстрее, чем у Trino.
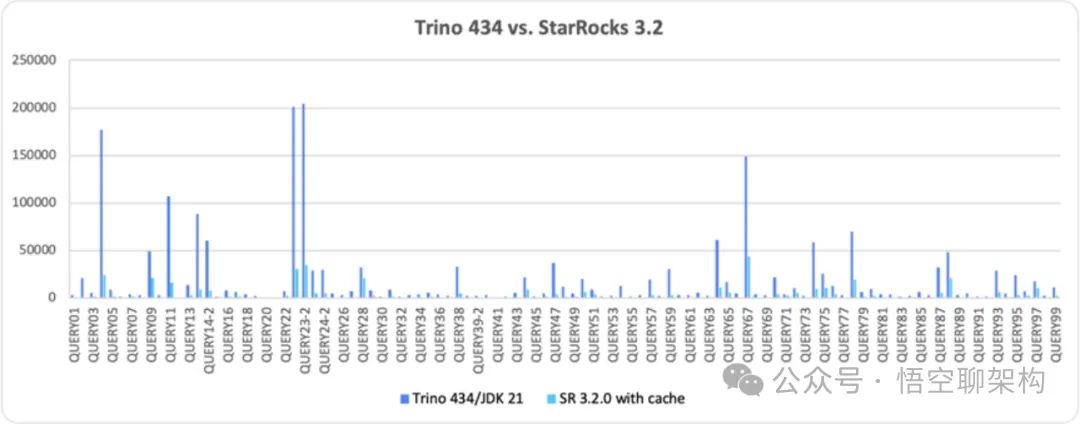
“источник:https://mp.weixin.qq.com/s/kEqyRO_aOnOnsROXllwA2g
5. Является ли StarRocks лучшим решением для анализа данных?
В сложной и постоянно меняющейся области анализа данных маловероятно, что существует универсальное решение. StarRocks действительно превосходит других в некоторых областях, например в скорости запросов, особенно при работе с большими наборами данных.
Однако не всем предприятиям требуется такая высокая производительность в режиме реального времени. Для некоторых предприятий может быть достаточно пакетной обработки или анализа в режиме, близком к реальному времени. Если вы работаете с небольшими наборами данных или простыми запросами, это может быть излишним. Но для компаний, которым необходимо принимать бизнес-решения и получать информацию посредством анализа в режиме реального времени, StarRocks может быть лучшим решением. Что касается выбора StarRocks, он должен основываться на техническом сравнении и тестировании собственных потребностей, а также потребностей компании. ресурсы и долгосрочная стратегия. Углубленная оценка.
“ссылка: https://zhuanlan.zhihu.com/p/532302941 https://docs.starrocks.io/docs/introduction/StarRocks_intro/ https://mp.weixin.qq.com/s/kEqyRO_aOnOnsROXllwA2



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
