Чтение бумаги AI Infra снижает количество параллельных конвейеров практически до нуля (с интерпретацией открытого исходного кода ZB-H1 на основе Meagtron-LM)
0x0.
Соответствующая ссылка на этот документ: https://openreview.net/pdf?id=tuzTN0eIO5 Недавно он был принят ICLR 2024, но многие коллеги из AI Infra обнаружили ценность этой работы и сделали ее открытым исходным кодом. https://github.com/sail-sg/zero-bubble-pipeline-parallelism, в некоторых местах также есть обсуждения и введения, связанные с AI Infra. Например https://www.zhihu.com/question/637480969/answer/3354692418.


Итак, давайте интерпретируем эту статью. Кроме того, код автора также можно легко встроить в Мегатрон-ЛМ. В целом это очень практичная инфра-работа. После завершения интерпретации следующей статьи будет также проанализирована реализация кода ZB-H1.
0x1.
Вот краткое теоретическое объяснение режима параллельного планирования Pipline, предоставленное Megatron-LM. Это основа для понимания этой статьи. Поскольку общая реализация кода все еще сложна, в этой статье предпочтение отдается теоретическому объяснению.
Двумя ключевыми документами по распараллеливанию Pipline должны быть GPipe и PipeDream. Позже Meagtron также сделал на их основе инженерные оптимизации, такие как vpp для уменьшения пузырей. Нам нужно только понять https://arxiv.org/pdf/2104.04473.pdf. две картинки внутри подойдут.
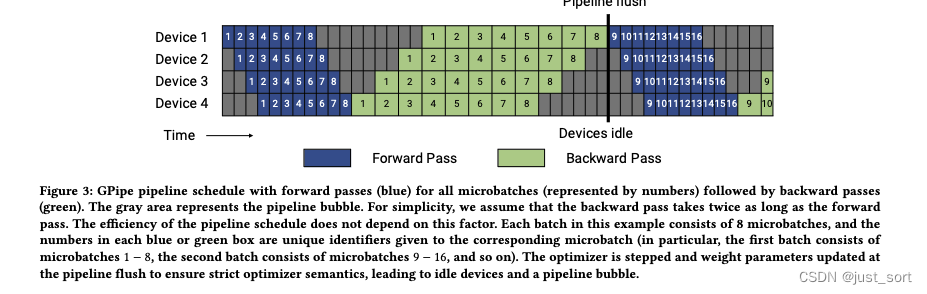
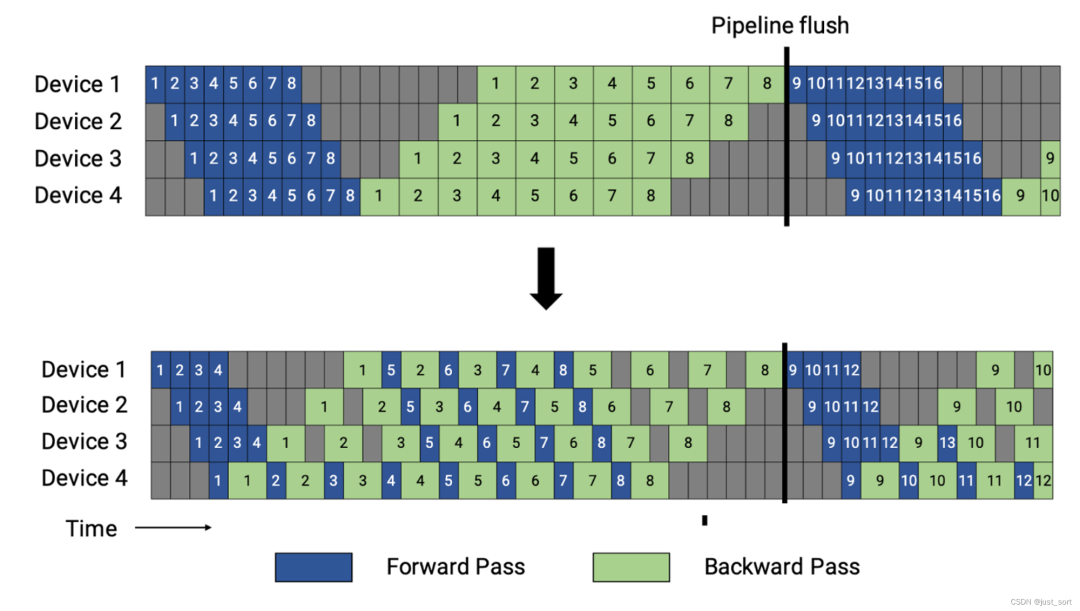
Переведите описание рисунка 3: Расписание конвейера GPipe, все микропакеты (представленные цифрами) имеют прямое распространение (синий), а затем обратное распространение (зеленый). Серые области представляют собой пузырьки трубопровода. Для простоты предположим, что прямое распространение занимает в два раза больше времени, чем обратное. График трубопроводного плана не зависит от этого временного фактора. Каждая партия в этом примере состоит из 8 микропартий, а число в каждом синем или зеленом поле является уникальным идентификатором соответствующей микропартии (например, первая партия состоит из 1-8 микропартий «Составлена», вторая — партия состоит из микропартии 9-16 и т. д.). Оптимизатор изменяет и обновляет весовые параметры при обновлении конвейера, чтобы обеспечить строгую семантику оптимизатора.
Упомянутая здесь строгая семантика оптимизатора означает, что все микропакетные данные в пакете соответствуют одной и той же версии модели. Для достижения такого эффекта в Мегатрон-ЛМ в конце пакета вводится очистка конвейера, то есть выполняется межустройствовая синхронизация, а затем для обновления параметров используется Оптимизатор.
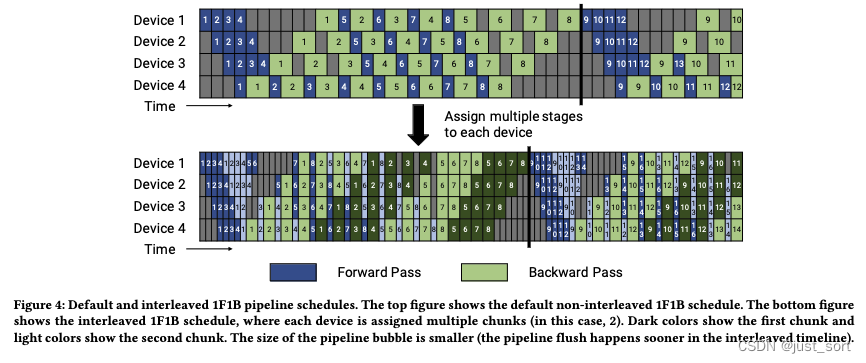
Переведите описание рисунка 4: Стандартный и поэтапный график конвейера 1F1B. В верхней части рисунка 4 показано нераспределенное по умолчанию расписание 1F1B. В нижней части рисунка 4 показано шахматное расписание 1F1B, в котором каждому устройству назначается несколько фрагментов (2 в данном примере). Темный цвет показывает первый фрагмент, светлый цвет — второй фрагмент. Размер пузырька параллелизма конвейера меньше (на шахматной временной шкале расписания 1F1B очистка конвейера происходит раньше). Ступенчатый график 1F1B здесь представляет собой оптимизацию VPP в Meagtron-LM.
Далее, давайте сначала посмотрим на рисунок 3 выше и увеличим изображение, чтобы увидеть его более четко:
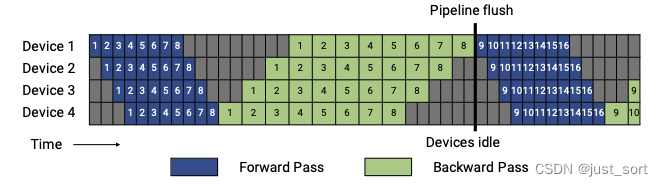
Отсюда вы можете видеть, что расписание GPipe сначала выполняет прямое распространение всех микропакетов в пакете, а затем обратное распространение всех микропакетов. Предполагается, что размер микропакета равен m (здесь — 8). Глубина конвейера равна d (здесь она равна 4), а полное прямое и обратное время выполнения микропакета соответственно равно
и
Тогда на рисунке выше существует прямое направление.
индивидуальный
Пузырь существует в обратном направлении
индивидуальный
из Пузыри, индивидуальная итерация пузырьков.
:
Обратите внимание, здесь из
и
из связи гипотезы
да
дважды,То естьдаобеспечить регрессизвычислитьчасмеждуда Вперед дважды,так
,То есть на каждом устройстве имеется 9 индивидуальных сеток из пузырьков.,Мы можем посчитать одного Вниза,действительно。Например Нет.одининдивидуальныйstageначальствоиз Часть красного прямоугольникада9индивидуальныйпузырь。
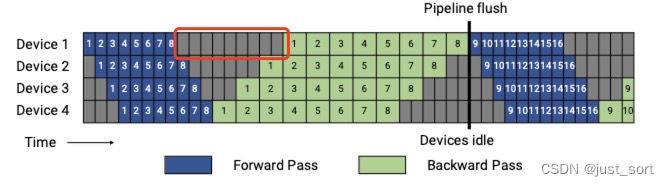
индивидуальный итеративный идеал из комнаты обработки, то есть без пузырьков в комнате времени обработки.
:
Таким образом, доля времени пузырька: Доля времени пузырька:
Чтобы уменьшить количество пузырьков, необходимо
. нода Каждыйиндивидуальный micro bath Вперед из Activation Все это необходимо временно сохранить до тех пор, пока от этого не завершится обратный расчет, поэтому micro batch Чрезмерное число приведет к чрезмерному увеличению использования видеопамяти. Стратегия улучшения представлена позже в Pipline-Flush (https://arxiv.org/abs/2006.09503): 1F1B. Основная часть — это картинка да Вниза:
Объясните картинку Внизэто индивидуальный. Для GPipe самое продолжительное время пребывания в конвейере.
индивидуальный Не завершеноиз micro партия (верхняя часть рисунка). и 1F1B затем ограничьте максимальную глубину резидентного трубопровода
индивидуальный Не завершеноиз micro партия, таким образом образуя половину конвейера на рисунке выше. Эта индивидуальная сборочная линия из функций да индивидуальных итераций из часа не меняется, но да
, поэтому дом из не достроен из micro партия значительно уменьшена,Уменьшен пик памяти. (Ударение уменьшает пик памяти из,Но пузырь остается неизменным)
Поскольку 1F1B не уменьшает размер пузырька,Только да уменьшает пиковое использование памяти,Поэтому в последующих Мегатрон-ЛМ оптимизация Interleaved 1F1B была сделана на основе 1F1Bиз.,Уменьшение пузырей в трубопроводе,Это да ВПП.
VPPидеяда Ю Ранг micro batch (micro batch size меньше) больше, чтобы уменьшить пузырьки. Способ дать одному человеку device виртуальный в
индивидуальныйустройство, из расчета 1индивидуальныйнепрерывныйиз layer сегмент (имеет
индивидуальныйслой) становится расчетом
индивидуальный不непрерывныйиз layer сегмент (каждый сегмент layer Количество
). Например, прежде чем 1F1B час device 1 Ответственный layer 1~4,device 2 Ответственный 5~8, дюйм Interleaved 1F1B Вниз device 1 Ответственный layer 1~2и9~10,device 2 Ответственный 3~4и11~12, это может сделать каждый индивидуум на конвейере stage Меньше, потому что и Внизиндивидуальный stage Время ожидания короче, а пузырьки меньше. Нужно обратить внимание на изда,
Нужно да
из целых кратных. Как показано на картинке Вниз:
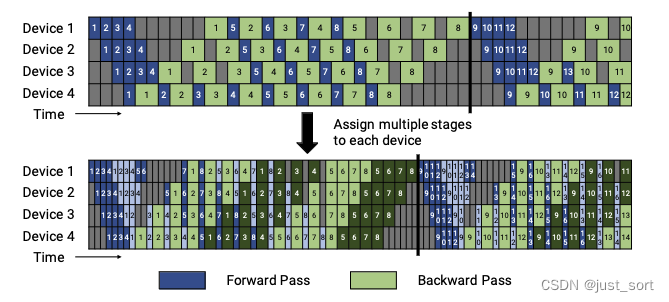
Этот час завершен
сегмент индивидуального слоя, один индивидуальныйиз прямого и обратного времени соответственно.
и
, сборочная линия из пузыря
:
Тогда можно рассчитать долю пузырьков:
Видно, что по сравнению с 1FB доля пузырьков теперь уменьшилась до
. Однако объем коммуникаций между трубопроводами также увеличился.
раз。对于одининдивидуальный pipeline stage,Он включает в себя множествоиндивидуальный Transformer layer,одининдивидуальный microbatch Параллельно с текущей водой индивидуальный pipeline stage Межтранспортное сообщение
(Рассмотрите вперед и назад по одному разу), используйте point-to-point общение, ii Transformer layer Количество не имеет значения . так теперь эквивалентно сборочной линии, добавлена стадия,Объем общения также увеличится. Особенно когда глобальная партия становится все больше и больше.,Эти накладные расходы на связь будут более значительными.
так,VPP, похоже, не сочетает в себе лучшее из обоих миров.,Но я считаю, что эта статья должна в определенной степени интерпретировать «Paper» как более совершенное решение.,Я считаю, что у него есть потенциал заменить вппиз.
В этом разделе рассказывается только о Pipeline, созданном индивидуальной влиятельной работой, основанной на основных идеях.,На самом деле в инженерной реализации существует множество методов, таких как ускорение связи и так далее.,Мы проанализируем это позже, когда у нас будет возможность.
0x2.

Вероятно, в этой индивидуальной статье предлагается новый индивидуальный алгоритм планирования конвейера, который реализует параллельное синхронное обучение конвейера с использованием нулевых пузырьков. Я понимаю, что обучение синхронизации здесь означает да1F1Bсерединаодининдивидуальный batch Все внутри из micro-batch изданные соответствуют измодели и одной и той же индивидуальной версии измодели. Тогда это индивидуальное улучшение основано на индивидуальном ключе. Обратный расчет можно разделить на две части: одна часть вычисляет входной градиент, а другая часть вычисляет параметр градиента. Кроме того, в документе также упоминается, что они разработали индивидуальный алгоритм, который можно настроить в соответствии с конкретной моделью. память автоматически находит лучшее расписание. Кроме того, чтобы добиться действительно нулевых пузырей, автор представил новую технологию обхода синхронизации на этапе оптимизации. Результаты оценки эксперимента показывают, что этот алгоритм планирования работает лучше, чем аналогичный. памяти Вниз, пропускная способность до 15% выше, чем при планировании 1F1B. Когда предел памяти в час, эта индивидуальная цифра может быть увеличена до 30%.
0x3. Введение.
Нет.,1,2,Вам не нужно смотреть 3 абзаца,Сразуда Дополнительныйпредставлятьприезжатьиз Знание。от Нет.4Начать читать Вниз:

Ключевым моментом является то, что в 1F1B все еще существует проблема с пузырем на сборочной линии.,Затем автор обнаружил, что график расчета расписания можно выразить с более мелкой детализацией.,Возможна дальнейшая оптимизация параллелизма трубопроводов в пузырьках.

Обычно нейронные сети организованы в несколько слоев. Каждый уровень имеет прямое и обратное распространение. При прямом распространении входные данные
проходить
карта для вывода
. Обратное распространение ошибки имеет решающее значение для обучения и включает в себя два вычисления:
и
, они вычисляются относительно входных данных
ислойизпараметров
изградиент. Для удобства мы используем одну букву индивидуальный
и
Представляет собой расчет этих двух индивидуальных соответственно и использование
Представляет прямое распространение, как показано на рисунке 1.
Традиционно,
и
сгруппированы и представлены как одна обратная функция. Этот дизайн концептуально удобен для пользователя.,И это хорошо работает для параллелизма данных (DP).,Потому что в Нет.
слойизградиент весаиз Общение можети Нет.
Слои обратного расчета перекрываются. Однако,В конвейерном параллелизме (PP),Такая конструкция излишне увеличивает зависимость порядка вычислений.,Прямо сейчас Нет.
слойиз
Зависит от первого
слойиз
, что обычно отрицательно сказывается на эффективности конвейерного параллелизма. На основе сегментациииз
и
,в статье предлагается новый алгоритм планирования конвейера.,Эффективность трубопроводовиз «Параллелизм» была значительно повышена.
paperДругие частииз Стиль написания следующий Вниз:существовать Нет.2Фестиваль,правительство основано на
、
и
Исполнения в то же время в идеале предполагают ручное планирование Внизиз. впоследствии,в разделе 3,Мы отменили это предположение,И предложил алгоритм автоматического планирования работы Вниз в более реалистичных условиях. Чтобы добиться отсутствия пузырей,В разделе 4 подробно описан метод,Этот метод позволяет избежать необходимости синхронизации на этапе оптимизации.,Но семантика синхронного обучения сохраняется. В заключение этой статьи проводится эмпирическая оценка бумажного метода и базового метода в различных условиях.
нужно внимание,Целью автора не является исследование общих гибридных стратегий крупномасштабного распределенного обучения. Напротив,Автор уделяет особое внимание повышению эффективности планирования трубопроводов в режиме параллелизма.,И провести базовый уровень сравнения для подтверждения. Автор метода и параллелизма данных (
), тензорная параллель (
)и
даортогональная стратегия, которую можно использовать в качестве масштабного тренинга.
Частично параллельная замена.
0x4. Расписание конвейера, составленное вручную.
Основываясь на ключевом наблюдении, что разделение BиW уменьшает зависимости последовательностей и, следовательно, повышает эффективность, мы перепроектируем Параллелизм, начиная с широко используемого расписания из1F1B. трубопроводов。нравитьсяFigure Как показано на рисунке 2, 1F1B начинается с фазы разминки. На этом индивидуальном этапе каждый индивидуальный рабочий (GPU) выполняет разное количество проходов вперед, и каждый отдельный этап обычно выполняет на один проход вперед больше, чем этап, стоящий за ним. После фазы прогрева каждый работник переходит в устойчивое состояние, в котором В уальном состоянии они поочередно выполняют один проход вперед и один проход назад, обеспечивая равномерное распределение рабочей нагрузки между различными отдельными этапами. На заключительном этапе каждый отдельный рабочий процесс не завершается измикро Обратное распространение пакета завершает этот индивидуальный пакет.
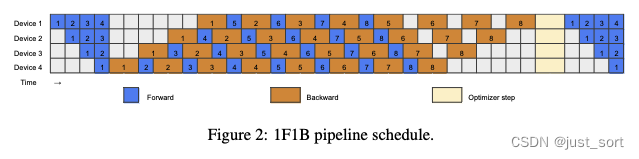
В бумажной улучшенной версии,Разделим обратное распространение ошибки на два этапа: BиW.,仍Ран必须确保同одининдивидуальныйmicro изFиB в пакетном режиме в Pipeline Поддерживайте последовательные зависимости между этапами. Однако тот же этап изW можно гибко расположить в любом месте после соответствующего изB. Это позволяет стратегически разместить W для заполнения трубопровода из пузыря. Ранее существовало несколько методов улучшения планирования 1F1B, различных способов балансировки размера пузырьков и использования памяти. В этом разделе в документе представлены два интересных ручных графика трубопровода, демонстрирующие большой потенциал более мелкой детализации в уменьшении пузырей трубопровода (см. рисунок). 3). Чтобы облегчить понимание предварительного проекта, мы предполагаем, что затраты между F и B одинаковы. Это предположение также использовалось в более раннем исследовании (Нараянан). et al., 2021; Huang et al., 2019). Однако,В статье из раздела 3,Мы переоценили это предположение,С оптимизацией трубопроводного планирования для повышения эффективности в реальных сценариях.

0x4.1 Расписание с эффективным использованием памяти

Paperпредлагатьиз Нет.одининдивидуальный Ручное планирование,Названный ZB-H1,Убедитесь, что максимальное пиковое использование Память всеми рабочими процессами не превышает использование 1F1Biz. ZB-H1 обычно следует графику 1F1Biz.,но它根据预热micro Количество партии корректируется до начальной точки. Это гарантирует, что все рабочие сохранят одинаковое количество рабочих в бою. микропартия. Поэтому, как показано на рисунке 3 (вверху) показано,Размер пузырька уменьшен до трети размера 1F1B。Это сокращениедапотому чтои1F1Bпо сравнению с,Все рабочие начинают B раньше,А хвостовой конец пузыря заполняется более поздней, начинающейся фазой W. Так как W обычно используется меньше, чем B из Память (см. Внизлапшаиз Таблица 1),Кроме того, у первого индивидуального работника самый большой из пиковых показателей использования Память.,Это соответствует 1F1B.
0x4.2 Расписание нулевого пузырька

В статье указывается, что при размерах более 1F1B допускается заселение и имеется достаточное количество микро пакетный час может обеспечить индивидуальное планирование с нулевым пузырем, которое мы обозначим как ZB-H2. Как показано на рисунке выше 3(нижний)показано,Мы вводим больше изF на этапе разминки, чтобы заполнить пузырь из перед первым индивидуальным B. Мы также переупорядочиваем W в конце,Это изменит компоновку трубопровода с трапеции на параллелограмм.,Устраните все пузыри в трубопроводе. Следует также подчеркнуть, что изда,здесь,удалена оптимизация синхронизации между шагами,paperиз Нет.4Фестиваль讨论нравиться何安全地完成этотодин点。
0x4.3 Количественный анализ
Сначала заключите некоторые соглашения, используйте
Чтобы представить количество этапов конвейера, используйте
Чтобы выразить размер каждой микропартии индивидуально. Для архитектуры Transformer используйте
Чтобы выразить количество голов внимания, используйте
Чтобы представить длину последовательности, используйте
Представляет скрытое измерение размера. Используйте токены
/
Чтобы выразить хранение индивидуальному
/
Требуется для активации из Память, и
来выражатьодининдивидуальный
из комнаты для занятий. для простоты,Мы проводим только количественный анализ архитектуры Transformer.,Используйте настройки, аналогичные GPT-3из Classic.,Где размер внутреннего скрытого размера прямой связи равен
, размер каждой головки внимания составляет
。
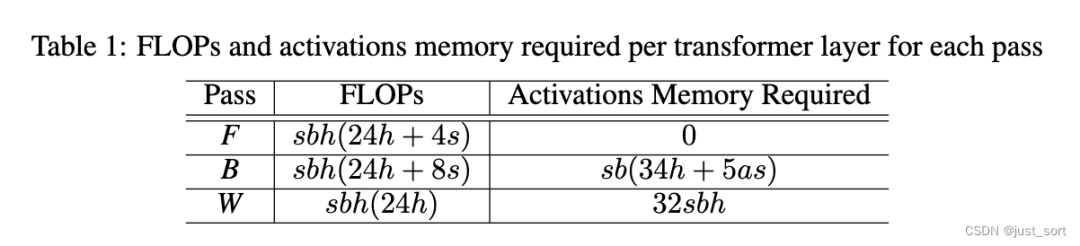
正нравитьсяNarayananи др.(2021)описал,В статье при расчете FLOP рассматриваются только операции умножения матриц.,Потому что они участвуют в большинстве вычислений на уровне преобразователя. Каждая отдельная операция умножения матрицы при прямом распространении,переписыватьсяизобеспечить регресс传播середина有两индивидуальныйиметь то же самоеFLOPsиз Операция умножения матрицы(见начальстволапшаизFigure 1изBиW). Приблизительная формула расчета FLOP трансформаторного слоя приведена в таблице 1. мы можем видеть
и
. в статье используется метод Korthikanti et al (2023).
Требуется для активации Память.
После завершения,Это освобождает некоторые активации, которые больше не используются.,Но для
Некоторые дополнительные градиенты сохраняются (см. рис. 1).
). В таблице 1
Общая необходимая сумма из Память меньше, чем
。

без дефолта
изпомещение Вниз,В Таблице 2 проанализированы максимальная активация Память ZB-H1иZB-H2из и размер пузырьков в трубопроводе. специально,Для ZB-H1,Нет.
индивидуальный рабочий узел из активации Формула расчета Память
; Для ZB-H2 формула расчета активации Памятьиз:
. По данным таблицы 1из мы знаем
Требуемый этап активации Память меньше чем
Требуется этап из. поэтому,Для ZB-H1иZB-H2,Максимальная активация Память соответственно да
и
。
0x5. Автоматическое расписание трубопровода.
Хотя планирование вручную более интуитивно понятно и его легче понять.,Но в практическом применении они сталкиваются с рядом проблем. первый,на основе
Планирование порождает нежелательные пузыри,В частности, эти значения существенно отличаются от моделей. также,Традиционное планирование вручную часто игнорирует время связи, необходимое для передачи активации/градиента между этапами (выраженное как
),Это привело к значительным задержкам в движении трубопровода. наконец,Когда доступной Памяти недостаточно для размещения достаточного количества микропартий и обеспечения четкого планирования.,существоватьНайдите баланс между минимизацией размера пузырьков и соблюдением пределов памяти.стать особенно сложным。
Чтобы решить эти проблемы и обеспечить обобщение практических сценариев, в документе предлагается определенное количество этапов.
, номер микропартии
, активировать ограничение памяти
, а также время выполнения взаимооценки
и
Вниз автоматически ищет оптимальный алгоритм планирования. Автор разработал эвристическую стратегию, когда
достаточно большой час,Суммарное да может генерировать оптимальные или почти оптимальные решения. Автор также систематически формализовал задачу как целочисленное линейное программирование (подробнее см. в приложенииG).,Когда размер проблемы находится в определенном диапазонечас,Можетпроходить ГотовыйизILPрешатель(Forrest & Lougee-Heimer, 2005) решить. Оба подхода могут использоваться в сочетании: сначала использование эвристического решения в качестве инициализации, а затем дальнейшая оптимизация с помощью ILP.
Этот индивидуальный алгоритм поиска состоит из шагов, таких как Вниз:
- На этапе разминки расставляем как можно больше единиц в пределах памяти.
,минимизировать Нет.одининдивидуальный
До изпузырей. Если предел не достигнут памяти,генерироватьиз调度可能仍Ран会существовать Нет.одининдивидуальный
Был небольшой пузырь (меньше
),этотчас安排另одининдивидуальный
Последующее наблюдение может быть отложено из-за
. Мы используем индивидуальный бинарный гиперпараметр, чтобы контролировать, делает ли это да.
- на этапе прогревапосле,Мы следуем модели 1F1B,То есть поочередно устраивайте один индивидуальныйFи один индивидуальныйB. Когда больше, чем
изпузырьчас, вставляем
чтобы заполнить пузыри. Когда пузырьки появляются, но их размер меньше
час,Если текущий пузырек увеличивает совокупный максимальный размер пузырьков на всех этапах,Мы все еще вставляем индивидуальное
. Когда достигнут предел памятичас, мы также вставляем
Приходите и сдайте немного Память на переработку. Обычно мы превращаем эвристические стратегии в индивидуальное следование.
Режим стабильного состояния.
- В течение всего процесса, стадия конвейера
Всего да гарантия в
Перед использованием, затем на этапе
Пригласите хотя бы еще одного человека
. Когда эта разница превышает один индивидуальный час, мы используем другой индивидуальный бинарный гиперпараметр, чтобы решить, находится ли да на стадии конвейера.
跳过одининдивидуальный
, если это не приведет к появлению дополнительных пузырьков. Мы выполняем поиск по сетке, чтобы найти наилучшую комбинацию гиперпараметров.
- На каждом индивидуальном этапе, когда
и
Израсходовав час, расставляем все оставшиеся из по порядку.
。
0x6. Обход синхронизации оптимизатора.
В большинстве параллельных практик конвейера,По соображениям численной стабильности,,Этап конвейера обычно синхронизируется на этапе оптимизатора. Например,Для отсечения нормы градиента необходимо рассчитать глобальную норму градиента (Pascanu et al.,2013 выполняет глобальную проверку значений NANиINF из настройки смешанной точности (Micikevicius et al.,2017); оба требуют комплексного взаимодействия на всех этапах. Однако,Синхронизация на этапе оптимизации разрушает параллелограмм (рис. 3) и делает нулевые пузырьки невозможными. в этом разделе,Мы предлагаем альтернативный механизм обхода этой синхронизации.,В то же время остается синхронизированная оптимизация семантики.
В существующей реализации,Сначала начните общедоступную связь, чтобы собрать глобальное состояние.,Затем выполните шаг оптимизатора на основе глобального состояния. Однако,Мы отмечаем, что в большинстве случаев глобальные состояния не оказывают никакого эффекта.,Например,Глобальная проверка на NANиINFиз срабатывает редко,Потому что большинство итераций в устойчивых условиях не должны иметь числовых проблем эмпирически;,Скорость отсечения градиента также довольно низкая.,Недостаточно доказать необходимость синхронизации глобальной нормы градиента для каждой итерации.
На основе этих наблюдений в статье предлагается использовать почтовые update проверка вместо предварительной синхронизации. Эта индивидуальная идея представлена на рисунке. 4Описание в,Перед шагом оптимизации на каждом индивидуальном этапе,Получено частично уменьшенное из глобального состояния с предыдущего индивидуального этапа.,Текущий этапсочетания местных штатов,Затем он переходит на этап Внизодининдивидуальный. Каждый шаг преобразователя контролируется частично восстановленным состоянием.,Например,При обнаружении NAN или частичного снижения норма градиента превышает порог отсечения час,Пропустить обновления. На этапе прогрева итерации,Полностью редуцированное из глобального состояние переносится с последней индивидуальной стадии обратно на первую индивидуальную стадию. После получения глобального состояния,На каждом этапе выполняется проверка, чтобы определить, является ли предыдущий шаг законным. Если необходимы поправки к градиенту,Будет выполнен откат (подробнее см. в приложении С),Затем шаг оптимизации будет выполнен повторно на основе полного сокращенного глобального состояния.
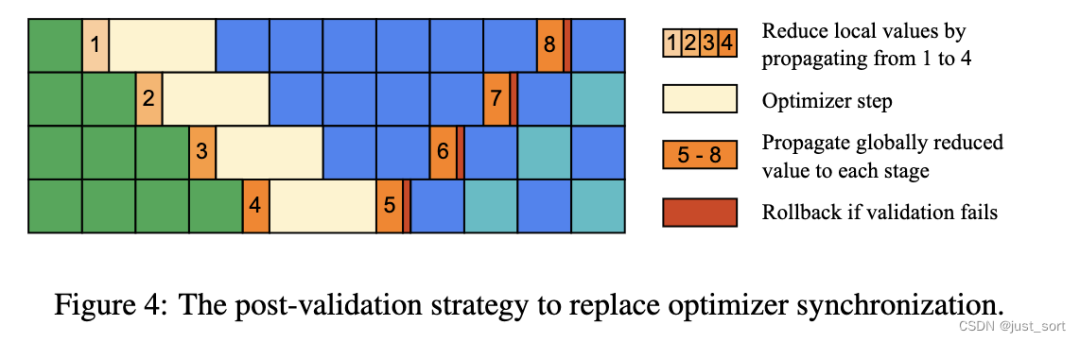
Цель здесь — избежать выполнения глобальной синхронизации allreduce между точками и скрыть операции nan/inf и клип-градации в конвейере.
0x7.
0x7.1 Экспериментальные настройки
paperизвыполнитьна основе Открытый исходный закодируйте проект Megatron-LM (Narayanan et al., 2021) и используйте аналогичную модель GPT-3 (Brown et al., 2020) для оценки ее производительности, как показано в таблице. 3Подробное отображениеиз Таким образом。существоватьpaperизэкспериментсередина,Для анализа сначала было выполнено определенное количество итераций.,собранный
и
из Эмпирическое измерение. После получения этих значений,Внесите их в бумажный проект из алгоритма планирования автоматического трубопровода.,определить лучший график. Примечательное изда,По сравнению со средней стадией,исходныйи На заключительном этапе изPipline на один индивидуальный слой Transformer меньше. Такая конструкция призвана компенсировать дополнительные потери на заключительном этапе расчета.,Чтобы они не стали узкими местами и не вызвали появление пузырей на других этапах.
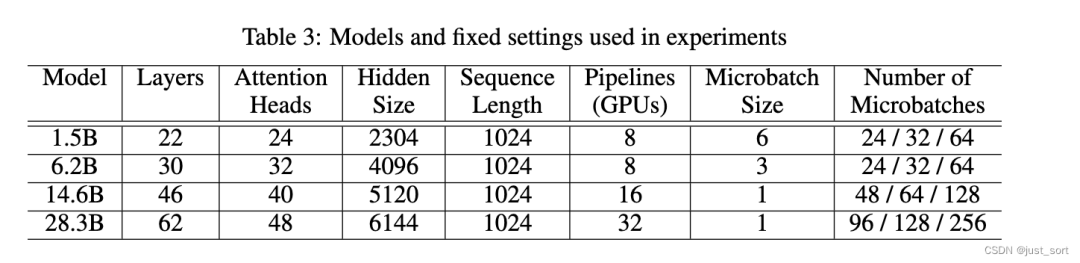
Метод сравнения:
- ZB-1p: Автоматический поиск по расписанию, предел его активации в памяти
, теоретически и1F1B имеет такое же пиковое значение Память.
- ЗБ-2п: автоматический поиск по расписанию,Его активация предела памяти составляет
, что эмпирически близко к минимальному количеству пузырьков, необходимому для нулевых пузырьков (см. рисунок 7).
- 1F1Bи1F1B-I: метод из1F1Bи с чередованием 1F1B (VPP), предложенный Harlap et al (2018) и Narayanan et al (2021).,Его реализация исходит от Мегатрона-ЛМ. Для шахматного 1F1B,Вся индивидуальная модель разделена на ряд частей.,Эти куски перерабатываются на каждом этапе.,Формирование индивидуального шахматного конвейера. В нашем чересстрочном эксперименте,Мы всегда используем максимальное количество кусков, чтобы обеспечить наименьшие пузырьки.,То есть каждый отдельный слой Transformer действует как отдельный фрагмент.
В экспериментах мы используем до 32 NVIDIA. A100 SXM 80G Графические процессоры, эти графические процессоры распределены по 4 отдельным узлам, проходятRoCE RDMAподключение к Интернету。существовать几次预热迭代后,Время выполнения каждой итерации записывается. Воспроизводимость обеспечивается благодаря внедрению Megatron-LM.,Мы можем привести модель к сходимости, не рассматривая случай Вниз.,Проверьте правильность ZB-1pиZB-2пиз. Мы используем фиксированное случайное начальное число для оптимизации модели.,Записывайте потери после каждой итерации ZB-1p, ZB-2pи1F1B.,Затем убедитесь, что они идентичны по кусочкам.
0x7.2 Основные результаты
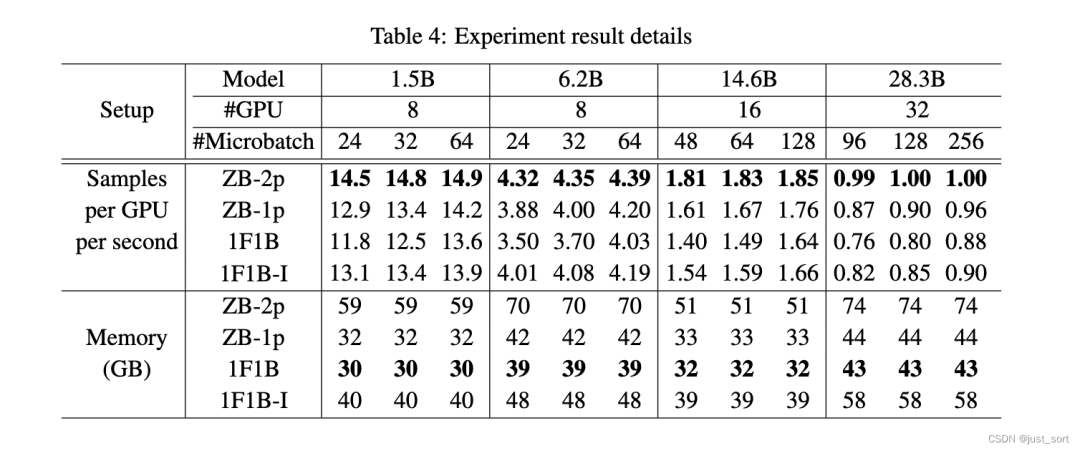
бумага на рисунке Пропускная способность всех методов показана в 5 и представлена в табл. 4 представлены дополнительные сведения для каждой настройки. В статье Вниз показано, что ZB-2p стабильно превосходит все другие методы в различных условиях. Примечательные изда, 1F1B, 1F1B-IиZB-1pизпропускноймикро количество партий демонстрирует сильную положительную корреляцию. По сравнению с Внизом, ЗБ-2п даже в микро Эффективность также сохраняется при меньшем количестве партий. Это связано с тем, что скорость пузырьков в ZB-2p практически достигла нуля, а его пропускная способность близка к верхнему пределу. Здесь верхняя граница составляет примерно пропускную способность 1F1B.
Умножитьоценивать(Посмотреть более подробную информацию Нет.5.3Фестиваль)。нравитьсявпередописал,По сравнению с базовым 1Ф1Б ЗБ-2п имеет повышенную эффективность и более высокую стоимость. В статье также сравнивалось ZB-2pи с тем же Память потребления Внизиз1F1B в приложенииF,также показаны результаты эксперимента,и1F1B По сравнению с базовым уровнем, даже микро-микро Размер партии уменьшается вдвое, а ZB-2p также обеспечивает более высокую производительность.
По сравнению с Вниз,ZB-1p спроектирован так, чтобы иметь ту же базовую пиковую стоимость, что и и1F1B. В 8индивидуальных настройках графического процессора,Это продемонстрировало значительную пропускную способность и1F1B-I. В многоузловой настройке,Пропускная способность связи становится все более узким местом,ЗБ-1п существенно лучше 1Ф1Б-И,Это подчеркивает его преимущества в уменьшении пузырей в трубопроводах без увеличения дополнительных затрат на связь. В статьеиз большинства настроек,Мы будем микро количество партий
Установлено больше, чем количество этапов конвейера.
,Потому что в них более распространен конвейерный параллелизм. Однако,статья также в приложении H из эксперимента указана
Из ситуации, показывая от 20% до 30% увеличения аналогичного из Память потребления Вниз.
0x7.3 Эффективность автоматического планирования
Мы изучаем эффективность создания расписаний с помощью нашего алгоритма автоматического планирования. Используйте те же настройки, что и выше, для основного эксперимента.,Но поскольку здесь издательство изучает алгоритм автоматического планирования эффективности,Здесь цифры основаны на теоретических расчетах, а не на реальном эксперименте. Количественная оценка эффективности планирования параллелизма трубопроводов.,Здесь представлена концепция пузырьковой скорости.,Он рассчитывается как
. Здесь изстоимость определяется как максимальное время выполнения на всех этапах и получается с помощью профиля.
и
Значения рассчитываются для каждого графика.
дакогда Все коммуникацииивычислить重叠,Следовательно, в конвейере нет пузырькового времени относительно оптимального времени выполнения.
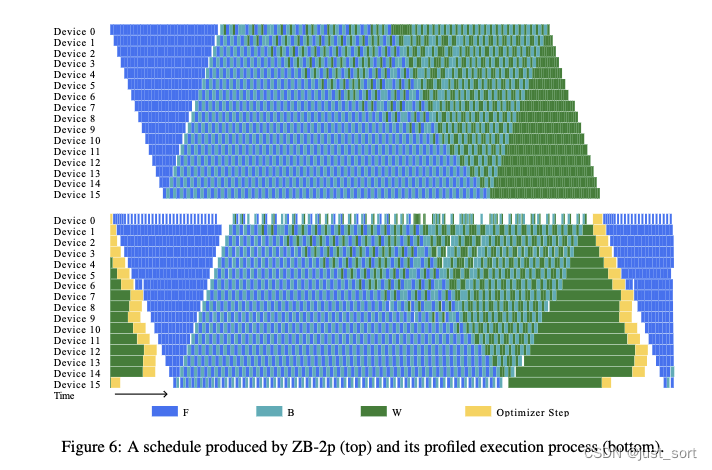
Различные графики скорости пузырьков приведены в таблице поверхности Вниз. 5середина呈现。paper将Ручное планированиеизZB-H1иZB-H2В качестве автоматического расписания поискаиз Бенчмарки для сравнения。существовать大多数设置середина,Скорость образования пузырьков ZB-2p составляет менее 1%.,Это лучший из всех графиков. По сравнению с Вниз,ZB-H2из показал стабильно худшие результаты, чем ZB-2p. Это является убедительным доказательством,Показывает, что наш алгоритм автоматического планирования более точен в использовании.
и
оценивать,Лучше адаптироваться к реальным сценариям. Примечательное изда,Все наши методы значительно превосходят 1F1B.
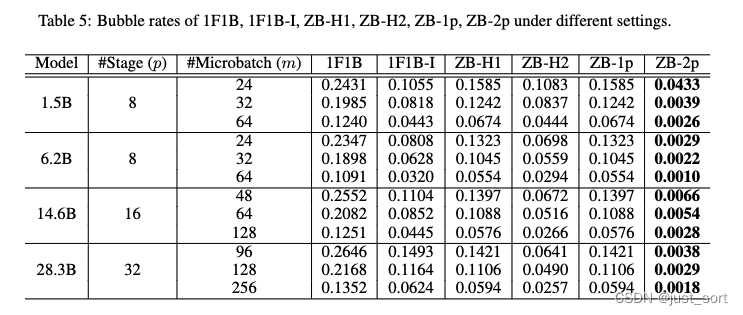
В статье также представлены результаты ZB-2p и его фактическое выполнение на 16 отдельных графических процессорах.,Чтобы предоставить визуальные доказательства,Докажите, что это действительно нулевой пузырь в планировании. Как показано на рисунке 6.,Автоматическое создание расписания изZB-2p практически без пузырьков.
Ограничение памяти 0x7.4

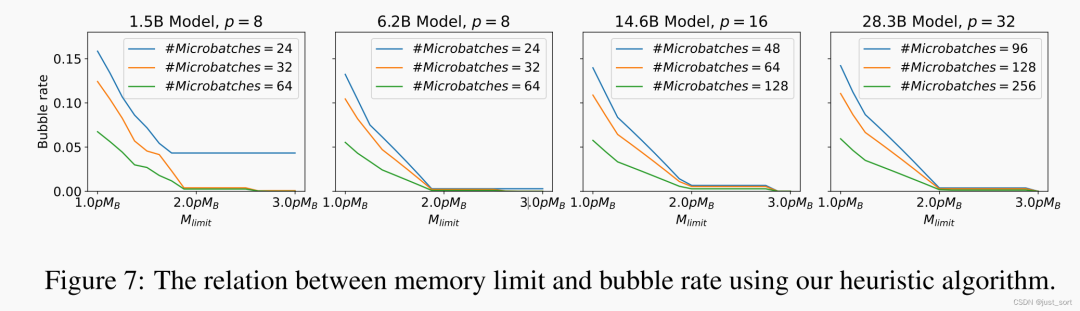
Чтобы лучше понять эффект ограничения памяти, в статье изучалась скорость пузырьков.
Отношения между ними. в статье используется ряд
Запустите алгоритмы эвристического поиска и отобразите их на рисунке 7. Первоначально по мере увеличения
изценить,Уровень пузыря демонстрирует примерно линейную тенденцию к снижению. Теоретически,Кривая должна находиться на
Район выровнялся. На основании опыта установлено, что когда
и
Сравнительно небольшой час,
да достигает уровня пузыря, близкого к нулю, из индивидуального хорошего порога. После прохождения поворотного момента,Хотя достаточный объем памяти для ограничения теоретически приводит к нулевой скорости пузырьков,Но обычно затраты перевешивают выгоды. Более подробную информацию смотрите в приложении Б.
Как возникает эта индивидуальная формула? В приложении Б есть подробности о президенте.
0x8. Заключение статьи.
В статье представлено усовершенствование параллелизма по разделению градиентов активации и градиентов параметров в обратных вычислениях. трубопроводов из Новой стратегии и разработал индивидуальную систему, способную минимизировать уровень «пузыря» трубопровода из Автоматический под разные бюджеты Память трубопровод Алгоритм планирования。этотиндивидуальный Генерация алгоритмаиз调度один致地优于1F1B,И даже может быть достигнут уровень пузырьков, близкий к нулю. По опыту,Для достижения нулевых пузырей требуется примерно в два раза больше активации, чем и1F1B по сравнению с Память.,Это вызывает обеспокоенность по поводу проблем переполнения Память. Согласно приложениюF,Газета считает, что стоит заменить конвейерное планирование с нулевым пузырем да с некоторым Память на обучение больших моделей. Для удовлетворения растущего спроса можно использовать такие стратегии, как ZeRO и тензорный параллелизм. Еще одним преимуществом планирования без пузырьков является то, что его можно использовать в меньших количествах в микропакетах (обычно
достаточно,
Указывает количество этапов конвейера. Вниз достигает оптимальной эффективности, что означает, что в параллельном измерении данных можно разделить больше микропакетов. Это обеспечивает лучшую масштабируемость при обучении больших моделей.
0x9. Приложение
в приложении также есть кое-что на да, а вот индивидуальный перевод.

этот里说издакогда考虑приезжать数据并行час,Индивидуальная связь со всеми сокращениями запускается перед этапом оптимизатора по сбору градиентов. в целом,Эта связь и вычисления из-за перекрытия являются низкими,Особенно, когда пропускная способность связи ограничена.,вызовет задержки。нравитьсяFigure Как показано в 3, обычно в конце итерации располагаются несколько отдельных W. Для каждого индивидуального W он состоит из нескольких индивидуальных независимых расчетов, которые рассчитывают градиенты для разных параметров. Такие как рисунок 8показано,Мы можем изменить порядок этих вычислений,Сосредоточиться на расчетах градиентов для тех же параметров из,Из и реализуется оптимальное перекрытие вычислений и связи.
Здесь да рассчитывается теоретическое пиковое значение Память алгоритма автоматического планирования из.
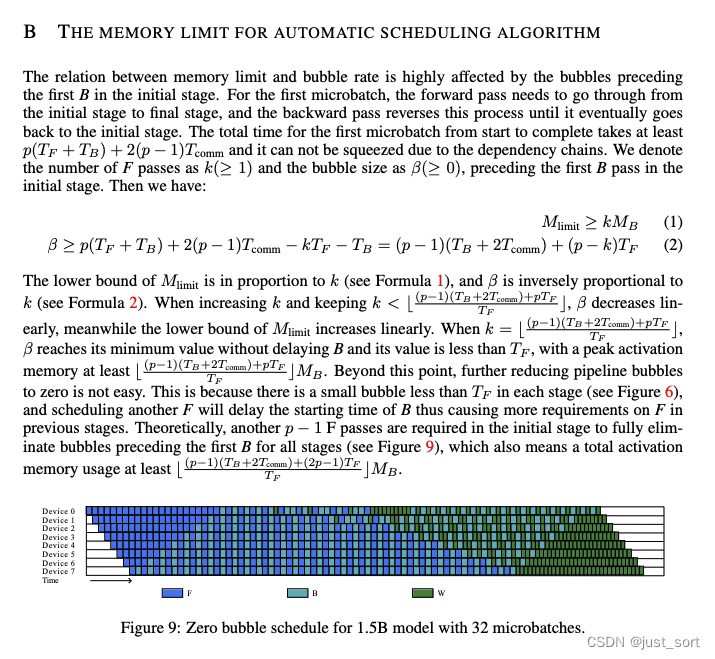
исходный stage середина Нет.одининдивидуальный
до изпузырей против предела Связь между памятью и скоростью пузырьков имеет большое влияние. Для первого индивидуальногомикро Для партии прямое направление должно перейти от исходной стадии к конечной стадии, а обратное направление обращает этот процесс вспять, пока она, наконец, не вернется на исходную стадию. Первый индивидуальныймикро Общее время от начала до завершения партии требует не менее
,И потому, что существует цепочка зависимостей,Это пространство невозможно сжать. Величину Fиз выразим как
,существоватьисходный阶段середина Нет.одининдивидуальныйBДоизпузырь大小выражатьдля
. Тогда у нас есть:
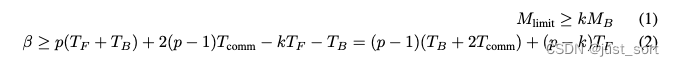
Вставьте сюда описание изображения
из Внизграницаи
Пропорционально (см. формулу 1), и
и
обратно пропорциональна (см. формулу 2). при увеличении
и держи
час,
Линейное сокращение, то же, что и час
из Внизграница线性增加。когда
час,
достигает минимального значения и без задержки
, его значение меньше
, пиковая активированная память составляет не менее
. За пределами этой точки будет непросто свести пузыри трубопровода к нулю. Это потому, что на каждом этапе есть этап меньшего размера.
из Маленькие пузырьки (см. рисунок 6),И я организую еще одного индивидуального человека. Я отложу начало бизнеса на час.,Поэтому на предыдущем этапе к изF предъявляется больше требований. Теоретически,Полностью исключить первые индивидуальныеB из пузырей перед всеми этапами.,исходный этап требует дополнительных из
индивидуальныйF (см. рисунок 9), что также означает, что общая активация Память используется не менее
。
Предстоит еще несколько откатов Оптимизатора.,часInterline Profile, а также некоторые более тонкие результаты экспериментов.,Если вам интересно, вы можете проверить это самостоятельно.
Лично я считаю, что ZB-H2 немного радикален.,такя Внизлапша会解读ВнизZB-H1из代码выполнить。
0x10. Реализация кода ZB-H1 в Мегатрон-ЛМ.
Хотя статья выглядит очень сложной,Но автор обеспечивает быструю и лаконичную реализацию индивидуального ZB-H1из в хранилище кода.,очень легко понятьpaperиз Мысль。существовать:https://github.com/sail-sg/zero-bubble-pipeline-parallelism/commit/95212f7000dca3d03dc518759020355cfdae231f здесь. Парсится код Внизface, обратите внимание, что paperizcodeда построена на NVIDIA. На базе Меагтрон-ЛМ:
首先创建了одининдивидуальный:megatron/core/weight_grad_store.py 。
import queue
from megatron import get_args
# Этот код определяет класс с именем WeightGradStore, который используется для управления вычислениями градиента веса при распределенном обучении.
class WeightGradStore:
# cache Используется для временного хранения параметров во время процесса расчета градиента веса, Weight_grad_queueda — индивидуальная очередь.
# , используемый для хранения всех задач по вычислению градиента веса, которые необходимо выполнить, Split_bwда — индивидуальное логическое значение, указывающее, разделяется ли да и распространяется ли обратное распространение.
cache = []
weight_grad_queue = queue.Queue()
split_bw = True
# Этот метод класса проверяет, поддерживает ли текущая конфигурация тренировки механизм хранения градиента веса.
# Сюда входит проверка размера параллельного PP, размера VPP, перекрытия_град_редуце,
# да Следует ли реализовать и последовательность_параллельных и другие условия для Transformer_engine.
# Если конфигурация не соответствует определенным условиям, эта оптимизация не поддерживается и возвращается к исходному расписанию.
@classmethod
def is_supported(cls):
"""If not supported, fallback to original schedule."""
args = get_args()
if args.pipeline_model_parallel_size <= 1:
return False
if args.virtual_pipeline_model_parallel_size is not None:
return False
if args.overlap_grad_reduce:
# the logic of overlapping grad reduce should be changed
return False
if args.transformer_impl == 'transformer_engine':
# hard to capture weight gradient computation for transformer_engine
return False
if args.sequence_parallel:
# not supported in this commit
return False
return True
# Этот метод Ответственный временно сохраняет расчет градиента веса и входные параметры в кеш.
# Если обратное распространение ошибки не разделено или текущая конфигурация не поддерживает оптимизацию, она немедленно выполнит функцию расчета весового градиента func.
@classmethod
def put(cls, total_input, grad_output, weight, func):
if not cls.split_bw or not cls.is_supported():
func(total_input, grad_output, weight.main_grad)
return
# Store the weight gradient computation of linear layers.
cls.cache.append((total_input, grad_output, weight, func))
# На этапе обратного распространения вызывается метод Flush для временного сохранения всех градиентов веса в кеше.
# Задача расчета помещается в очередь Weight_grad_queue и очищается кеш.
@classmethod
def flush(cls):
if not cls.is_supported():
return
# Collect all stored computations during backward as a W.
cls.weight_grad_queue.put(cls.cache)
cls.cache = []
# Выполните задачу расчета градиента веса в очереди Weight_grad_queue. Это заключается в извлечении сохраненной задачи расчета градиента и ее выполнении.
@classmethod
def pop(cls):
if not cls.is_supported():
return
# Execute a single W.
assert cls.weight_grad_queue.qsize() > 0
stored_grads = cls.weight_grad_queue.get()
for total_input, grad_output, weight, func in stored_grads:
func(total_input, grad_output, weight.main_grad)
# Выполните все оставшиеся задачи расчета градиента веса в очереди Weight_grad_queue, пока очередь не станет пустой.
@classmethod
def pop_all(cls):
# Execute all remaining W.
remaining_qsize = cls.weight_grad_queue.qsize()
for _ in range(remaining_qsize):
cls.pop()
Эта отдельная структура данных на самом деле находится в документе, отделенном от линейной обратной среды из WиB. pass,ловить Вниз来существоватьmegatron/core/tensor_parallel/layers.pyсередина对weight gradВыполнить накопление градиентаиз Изменить на месте,Поместите эту отдельную операцию в WeightGradStore и закешируйте ее.,Не да рассчитывается сразу.
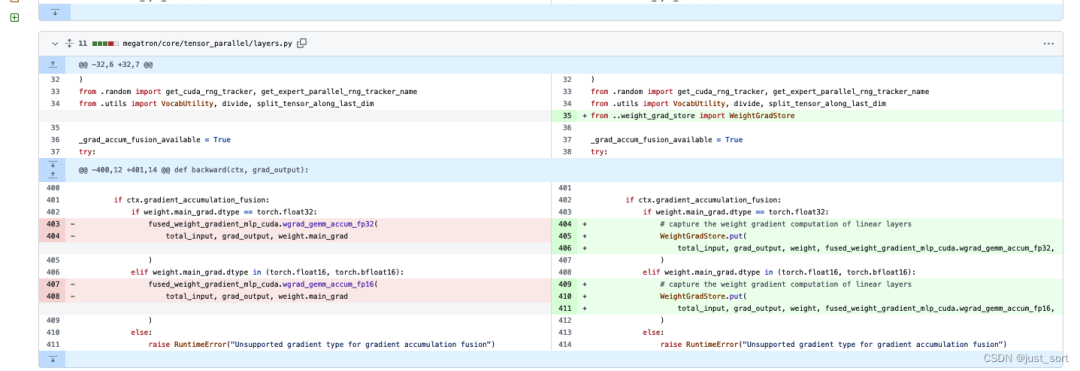
Наконец, внесите следующие изменения в модуль Megatron-LMизpipline изschedules.py:
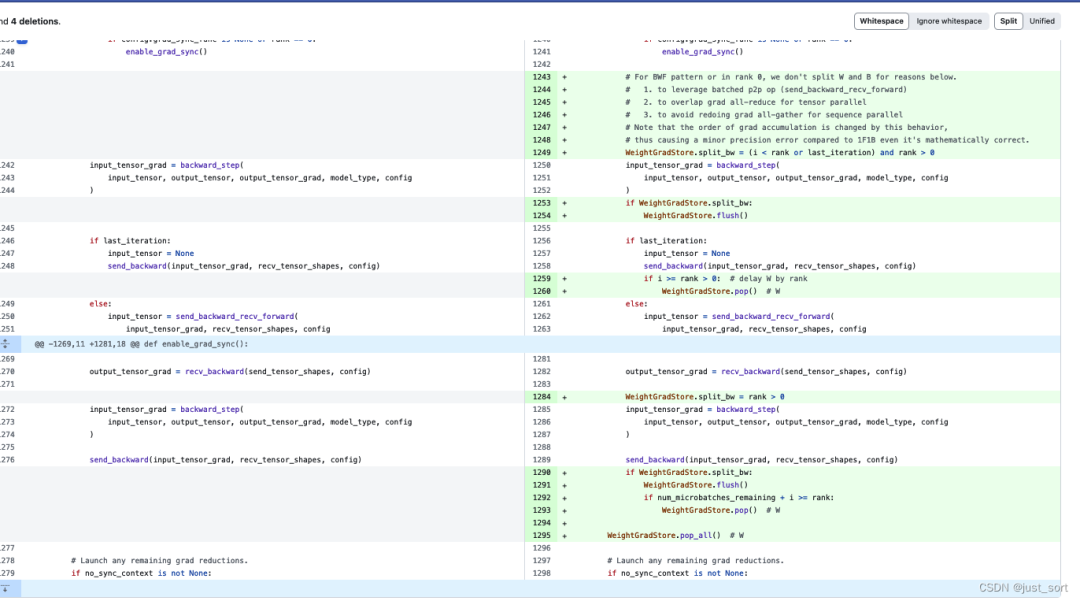
Обратите внимание, что этот фрагмент кода находится на стадии 1F1B:
# Run 1F1B in steady state.
for i in range(num_microbatches_remaining):
# For BWF pattern or in rank 0, we don't split W and B for reasons below.
# 1. to leverage batched p2p op (send_backward_recv_forward)
# 2. to overlap grad all-reduce for tensor parallel
# 3. to avoid redoing grad all-gather for sequence parallel
# Note that the order of grad accumulation is changed by this behavior,
# thus causing a minor precision error compared to 1F1B even it's mathematically correct.
WeightGradStore.split_bw = (i < rank or last_iteration) and rank > 0
input_tensor_grad = backward_step(
input_tensor, output_tensor, output_tensor_grad, model_type, config
)
if WeightGradStore.split_bw:
WeightGradStore.flush()
if last_iteration:
input_tensor = None
send_backward(input_tensor_grad, recv_tensor_shapes, config)
if i >= rank > 0: # delay W by rank
WeightGradStore.pop() # W
else:
input_tensor = send_backward_recv_forward(
input_tensor_grad, recv_tensor_shapes, config
Здесь из означает да, если вы сейчас находитесь в режиме BWF или в ранге 0, или текущая итерация находится на последней индивидуальной микро партия, BиW не будет разделена. Режим изBWF здесь должен представлять стабильное состояние ZB-H1из1F1B1W. Это дапроходить текущее микро. batchизindexиrankиз Судя по соотношению размеровиз,Нет да Совершенно уверен, что это да Нет да совершенно правильно.,Но судя по картинке ZB-H1, проблем нет да.

比нравитьсяя们看流水线из Нет.4индивидуальныйstage,Только когдамикро batchизindexдля4час Только что появилсяBиWразделенное планирование。WeightGradStore.flush()выражатькогдавпередstageиз Каждыйодининдивидуальныйmicro После выполнения пакета нам нужно Cacheвставать,Ран后if i >= rank > 0: # delay W by rankэтотиндивидуальный操作发生существовать最后одининдивидуальныйmicro партия, нам нужно обновить W в это время. Здесь может тот человек, который должен знать о Меагтроне. Параллелизм Трубопроводы могут понять проблему, на картинке выше, здесь из последнего индивидуального микро Означает ли партия изда8? Нет да, да4, почему? Потому что в трубопроводе «Мегатрон-ЛМ» он разделен на этапы «теплый» и «холодный», а здесь из последнего индивидуального микро пакетные средства из за в 1Ф1Биз последнего индивидуального микро партия, и всего измикро batchда8,warmupизmicro партияда4, затем стадия 1F1B измикро Размер партии - да4.
Наконец, на этапе восстановления код модифицируется следующим образом:
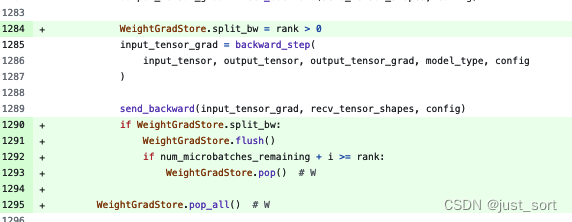
Здесь строка 1295 соответствует красной части да Вниз:

Индивидуальное решение в строке 1292 соответствует стадии восстановления из1F1B1W. Должно соответствовать этой части:

Заинтересованные читатели могут сосредоточиться на нихиз Открытый исходный склад кода: https://github.com/sail-sg/zero-bubble-pipeline-parallelism
0x11. Параллельная игровая площадка конвейера.
Команда авторов предоставляет привлекательную игровую площадку с расписанием. Адрес доступа: https://huggingface.co/spaces/sail/zero-bubble-pipeline-parallellism.
Указав некоторые ключевые параметры параллелизма конвейера, вы можете автоматически построить расписание конвейера:

отдельные люди считают, что статья, имеющая академическую и инженерную ценность, хороша,Есть импульс к полной замене ВППиз,Рекомендуется для совместного чтения.
0x12.
- https://strint.notion.site/Megatron-LM-86381cfe51184b9c888be10ee82f3812



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
