CFPFormer | Прекрасно интегрирует пирамиду функций и Transformer для значительного улучшения сегментации изображений и эффектов обнаружения целей!
Нажмите на карточку ниже, сосредоточьтесь на「Джижи Шутун」Официальный аккаунт

Пирамиды признаков широко используются в сверточных нейронных сетях (CNN) и преобразователях для таких задач, как сегментация медицинских изображений и обнаружение объектов. Однако существующие в настоящее время модели обычно ориентированы на преобразователь на стороне кодера для извлечения функций, а при тщательно разработанной архитектуре улучшения декодера могут принести дополнительный потенциал. Авторы предлагают CFPFormer, новый блок декодера, который объединяет пирамиду функций и Transformer. В частности, используя встраивание патчей, межуровневое объединение функций и механизмы гауссовского внимания, CFPFormer улучшает возможности извлечения функций, одновременно обеспечивая возможности обобщения для различных задач. Благодаря структуре Transformer и U-образным соединениям модель, представленная авторами, способна улавливать зависимости на больших расстояниях и эффективно повышать дискретизацию карт объектов. По сравнению с существующими методами модель авторов обеспечивает превосходную производительность при обнаружении небольших объектов. Авторы оценили CFPFormer на наборах данных сегментации медицинских изображений и тестах обнаружения объектов (VOC 2007, VOC2012, MS-COCO), продемонстрировав его эффективность и универсальность. Наша модель демонстрирует исключительно впечатляющую точность на наборе онлайн-тестов ACDC Post-2017-MICCAI-Challenge и хорошо работает с исходными настройками декодера набора данных сегментации нескольких органов Synapse.
1 Introduction
Появление методов глубокого обучения, особенно сверточных нейронных сетей (CNN), таких как U-Net [20], значительно продвинуло эту область за счет повышения точности и эффективности таких задач, как сегментация и анализ изображений. Это играет ключевую роль в современной медицине, помогая врачам в точной диагностике, планировании лечения и мониторинге заболеваний.
Однако по мере углубления и сжатия сетей они могут терять важную информацию высокой плотности из нижних слоев, что влияет на их способность улавливать мелкие детали и небольшие структуры на медицинских изображениях. Поэтому в предыдущих исследованиях использовались пропущенные соединения [11] для восстановления этой информации, которая появляется в виде простого сплайсинга, такого как TransUnet.
В то же время Трансформеры (трансформеры) показали отличные возможности по улавливанию зависимостей на больших расстояниях в различных областях, включая обработку естественного языка и обработку изображений [15, 3]. При обработке изображений фрагменты 2D-изображения с кодированием положения подаются в преобразователь в качестве входной последовательности, что позволяет ему эффективно моделировать зависимости на больших расстояниях по всему изображению [6].
Однако традиционные транспонированные сверточные слои, используемые на этапах повышения дискретизации и декодирования в архитектурах типа U-Net, часто с трудом улавливают плотные, локализованные элементы, что имеет решающее значение для точной сегментации глобального контекста и небольших структур в медицинских изображениях [30]. Это ограничение связано с фиксированным размером ядра и разреженным шаблоном соединений операций свертки, что может привести к невозможности эффективной интеграции многомасштабных функций и зависимостей на больших расстояниях [17, 21]. Более того, простая конкатенация функций в пропущенных соединениях может не оптимально объединить богатые представления, полученные в разных масштабах [22].
Принимая во внимание эти проблемы и признавая преимущества U-Net-подобной архитектуры и Transformer, автор исследования представляет новую архитектуру, называемую блоком Cross Feature Pyramid (CFP), в рамках структуры пирамиды функций. Блок CFP служит блоком декодирования и предназначен для восстановления информации высокой плотности, потерянной в процессе понижающей дискретизации. Сочетая встраивание фрагментов изображения и механизмы внимания, блоки CFP предназначены для извлечения информации на уровне пикселей из нижних слоев, тем самым расширяя способность модели захватывать мелкозернистые детали и небольшие структуры в задачах анализа медицинских изображений.
Ключевым аспектом архитектуры авторов является использование механизма гауссовского внимания в блоке CFP. Этот механизм внимания направлен на ослабление внимания внутри кривой, эффективно расставляя приоритеты для информации из соответствующих слоев, одновременно фильтруя шум и ненужные детали. Кроме того, блок CFP информирует механизм внимания о межуровневых функциях путем объединения карт функций с парами ключ-значение (KV). Это не только повышает производительность модели при обнаружении и сегментации небольших объектов, но также улучшает общее понимание модели сложных пространственных отношений на медицинских изображениях.
В этой работе авторы предлагают новый подход к решению ключевых проблем анализа медицинских изображений. Наша модель использует гауссово внимание к строкам и столбцам для эффективного выявления долгосрочных зависимостей без вычислительных затрат на внимание на уровне пикселей.
Центральное место в подходе авторов занимает архитектура Cross Feature Pyramid (CFP), которая обеспечивает гибкость для плавной интеграции с различными сетевыми архитектурами, такими как U-Net и CenterNet. Таким образом, этот универсальный подход хорошо подходит для различных приложений медицинской визуализации, которые будут продемонстрированы в последующих разделах.
В целом авторы предлагают:
- Потенциал Трансформера для эффективного декодирования деталей на большом расстоянии от кодирования Трансформатора.
- Авторы разлагают вычисления внимания на строки и столбцы с гауссовым затуханием. Новый метод точно улучшает декодированные карты объектов и обеспечивает лучшую производительность авторской модели.
- Путем введения функции рекодирования (FRE),Он заново собирает все выходные данные кодирования изображений.,и отрегулируйте его в соответствии со слоем декодера. CFPFormer раскрывает потенциальные приращения на основе модели декодера,и продемонстрировал впечатляющий рост.
2 Related Work
CNN-based Methods
Сверточные нейронные сети (CNN), такие как U-Net [20], были рабочей лошадкой для задач анализа медицинских изображений. Эти сети состоят из компонентов понижающей и повышающей дискретизации, которые работают вместе.
Компонент понижающей дискретизации постепенно уменьшает пространственное разрешение входного изображения посредством серии слоев свертки и объединения. На каждом уровне операции свертки используют обучаемые фильтры для извлечения локальных функций, таких как края, текстуры и узоры. Впоследствии операция объединения пространственно сжимает эти карты признаков, уменьшая их пространственный размер, расширяя восприимчивое поле и обеспечивая инвариантность к локальным переводам.
По мере того, как авторы углубляются в процесс понижения дискретизации, функции становятся более абстрактными, фиксируя семантические концепции высокого уровня, относящиеся к задаче. Однако эта абстракция достигается за счет потери мелких пространственных деталей и разрешения, которые имеют решающее значение для задач прогнозирования на уровне пикселей, таких как сегментация.
Компонент повышения дискретизации призван восстановить это потерянное пространственное разрешение и сгенерировать окончательный выходной прогноз. Он выполняет серию операций повышения дискретизации, обычно с использованием транспонированной свертки [29] или интерполяции, чтобы постепенно увеличивать пространственные размеры карты объектов. Пропуск соединений [11] в архитектуре U-Net соединит карты объектов в соответствующем слое понижающей дискретизации с объектами, подвергнутыми повышающей дискретизации. Эти пропускающие соединения обеспечивают слой повышающей дискретизации мелкозернистыми деталями из более ранних слоев, помогая точно локализовать и очертить границы.
Несмотря на свой успех, CNN имеют ограничения в улавливании долгосрочных зависимостей из-за их локальных рецептивных полей, что затрудняет их способность эффективно моделировать сложные пространственные отношения и глобальный контекст в медицинских изображениях. Чтобы решить эту проблему, используются такие методы, как дилатационная свертка [28], позволяющие увеличить рецептивное поле без увеличения вычислительных затрат.
Transformer-based Methods
Трансформатор [24], первоначально предложенный для задач преобразования последовательности в обработку естественного языка, стал мощной альтернативой для моделирования зависимостей на больших расстояниях в различных областях, включая анализ медицинских изображений. В отличие от сверточных нейронных сетей (CNN), которые работают в локальных окрестностях, Трансформеры используют механизм самообслуживания, который позволяет им фиксировать глобальные зависимости по всей входной последовательности.
Чтобы адаптировать Трансформеры к данным изображения, исследователи предложили различные стратегии. Общий подход, представленный в Vision Transformer (ViT) [6], заключается в разделении входного изображения на непересекающиеся фрагменты и обработке этих фрагментов как маркеров во входной последовательности. Кодирование положения включено в модель, чтобы сделать ее пространственно ориентированной и способной отличать различия от участков в разных местах изображения. Кодер Transformer обрабатывает входную последовательность и генерирует закодированное представление, содержащее пространственную и семантическую информацию.
Хотя чистые архитектуры Transformer хорошо справляются с фиксацией долгосрочных зависимостей, их применение в анализе медицинских изображений сталкивается с проблемами. Обычно они требуют значительных вычислительных ресурсов, что делает их менее практичными в приложениях с ограниченными ресурсами. Кроме того, присущее им отсутствие индуктивной предвзятости к пространственным данным может помешать им эффективно моделировать локальные взаимодействия и мелкие детали, которые имеют решающее значение в задачах медицинской визуализации.
Чтобы устранить эти ограничения, в недавних исследованиях были изучены гибридные архитектуры, сочетающие в себе преимущества CNN и Transformer. В этих моделях используется кодер CNN для извлечения иерархических функций из входного изображения, а затем сглаживания и проецирования этих функций в последовательность вложений в качестве входных данных для кодера Transformer. Кодер Transformer и декодер с повышающей дискретизацией фиксируют глобальные зависимости и генерируют выходные прогнозы. К таким методам относятся TransUNet [4] и CoTr [27].
Кроме того, в некоторых архитектурах чередуются уровни CNN и Transformer, что позволяет итеративно улучшать функции и прогнозы. Уровень CNN извлекает локальные объекты, за ним следует уровень Transformer для моделирования зависимостей на больших расстояниях, а затем уровень CNN для пространственной реконструкции и генерации выходных данных. Этот подход используется в таких моделях, как SwinUNet [2] и UNet [27], которые включают механизмы внимания для регулирования потока информации между компонентами CNN и Transformer, что позволяет модели адаптивно фокусироваться на задачах, соответствующих текущей задаче. Характеристики и зависимости.
Объединив взаимодополняющие преимущества CNN и Transformer, эти гибридные архитектуры призваны преодолеть ограничения отдельных архитектур и обеспечить более комплексное решение задач анализа медицинских изображений, которые требуют детального пространственного моделирования и понимания глобального контекста.
3 Method
Вот начало метода Раздела 3:
Preliminary
Архитектура авторской модели построена на структуре декодера. Таким образом, CFPFormer стремится укрепить связь между уровнями кодера и декодера, чтобы активировать потенциал функций кодирования. Ядром этой архитектуры является блок Cross Feature Pyramid (CFP), который включает в себя три ключевые инновации: гауссово внимание, перекодирование функций и межуровневую интеграцию функций. Эти компоненты предназначены для улучшения способности модели фиксировать сложные пространственные отношения, интегрировать информацию в разных масштабах и уменьшать потерю плотной информации во время масштабирования.
Network Architecture
Как показано на рисунке 1, внедрения функций магистральной сети передаются в качестве входных данных в блок Cross-Feature Pyramid (CFP) самого низкого уровня разрешения в иерархии пирамиды. Выходные данные этого блока затем подвергаются повышающей дискретизации и передаются следующему блоку CFP с более высоким уровнем разрешения в пирамиде. Этот процесс повторяется, постепенно продвигаясь вверх по пирамиде к уровням более высокого разрешения.
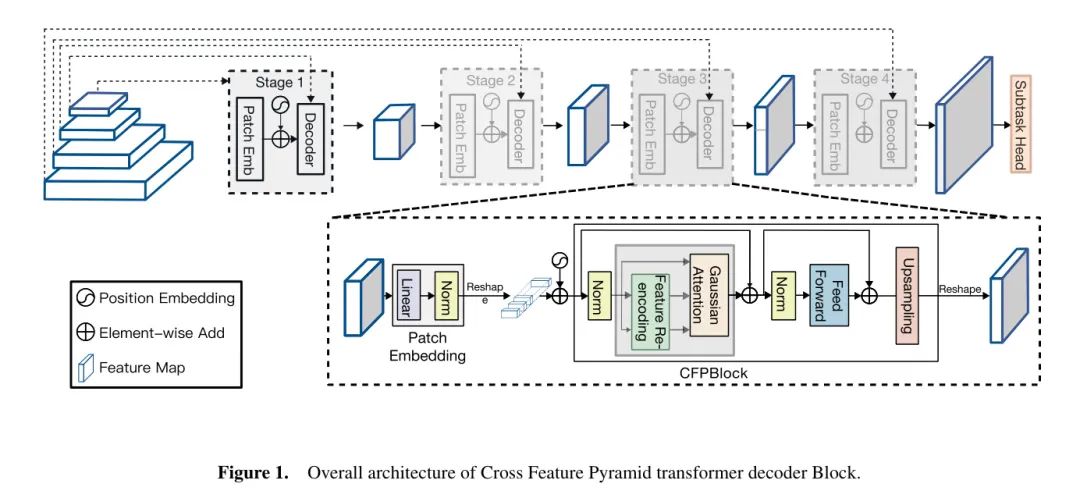
На каждом уровне пирамиды блок CFP получает функции с повышенной дискретизацией из предыдущего блока с более низким разрешением. Эти функции с повышенной дискретизацией сочетаются с функциями того же уровня разрешения магистральной сети, которые предоставляют пространственную информацию низкого уровня и улучшают зависимости на большом расстоянии для управления механизмом внимания в блоке CFP.
По мере того, как процесс декодирования поднимается по уровням пирамиды, объекты обрабатываются с помощью предложенного авторами метода Гаусса на основе маски затухания для расчета расстояния, а последующий результат представляет собой набор карт объектов с высоким разрешением, увеличенных до вершины пирамиды.
Эти карты функций затем могут быть дополнительно обработаны головками для конкретных задач для таких приложений, как сегментация изображений, обнаружение объектов или классификация.
Cross Feature Pyramid (CFP) Block
Гауссово внимание и вычисление осевого разложения. Блок CFP использует механизм внимания, называемый вниманием Гаусса, который локализует вычисление признаков в строках и столбцах пикселей. Из-за вычислительной нагрузки, налагаемой большинством визуальных преобразователей, авторы предлагают вычисления осевого разложения по гауссовскому распаду. Наш модуль эффективно разлагает внимание всех пикселей на внимание по строкам и внимание по столбцам.
Этот модуль сначала встраивает входные данные в
Линейная проекция на запрос (
),ключ(
) и значение (
) означает:
в
、
и
это обучаемая матрица проекции,
Представляет функции, извлеченные из кодировщика изображений.
Эти выражения затем изменяются и используются для расчета направления внимания по строкам и столбцам:
в
、
и
представляет собой матрицу, измененную для расчета внимания в направлении строки и направлении столбца,
— размерность ключевого вектора.
Инновационным аспектом блока CFP является использование механизма гауссовского внимания. В отличие от механизма внимания, придающего равную важность всем позициям рецептивного поля,Гауссово внимание снижает вес внимания в соответствии с кривой Гаусса.,Эффективно расставьте приоритеты для соответствующей информации о слоях,В то же время отфильтровывайте шум и ненужные детали.
Механизм гауссовского внимания генерирует двумерную маску ослабления на основе евклидова расстояния между пространственными местоположениями.
Чтобы достичь:
в
это обучаемый параметр, используемый для управления скоростью затухания.
Затем эта маска затухания применяется к показателю внимания, эффективно корректируя вес внимания с помощью гауссова затухания, как показано в уравнении 7.
Перезагрузка функций. Ключевым компонентом блока CFP является механизм перезагрузки функций.,Он направлен на использование информации с карт объектов низкого разрешения.,Улучшает способность Модели захватывать мелкие детали и небольшие структуры.
Чтобы объединить межуровневую информацию о функциях, ключ (K) в модуле повторного набора функций (FRE) и значение (V) Тензорные и кодирующие функции следующего уровня сети.
В сочетании следующим образом:
Рисунок 1: Общая архитектура блока декодера кросс-функционального пирамидального преобразования.
в
Patchembed — это слой, который разлагает объекты на встраивания изображений. Здесь автор принимает особенности слоя понижающей дискретизации, размер изображения
и
становиться
и
. В отличие от каскадных декодеров (например, TransUnet, PVT-CASCADE), которые напрямую объединяют сверточные слои повышающей дискретизации с функциями кодера, наша комбинация перекрестных функций позволяет механизму внимания более эффективно взаимодействовать с пространством низкого уровня в кодере.
Transformer [26], который предлагает использовать пространственную редукцию для соответствия размерам канала тензора KиV посредством линейной проекции.
Однако,Подход авторов представляет собой взаимодействие на этапе декодера.,Это позволяет модели лучше захватывать мелкие детали за счет использования гауссовского осевого внимания и структуры входных данных.,Как показано на рисунке 2.

4 Experiments
Мы проводим обширные эксперименты, чтобы оценить эффективность нашего метода на трех контрольных наборах данных.
Эти наборы данных включают в себя:
(1) Набор данных A, (2) Набор данных B и (3) Набор данных C.
Для справедливого сравнения авторы использовали стандартные показатели оценки, использованные в предыдущей работе.
Datasets
Чтобы оценить эффективность предложенного авторами метода CFPFormer, авторы провели эксперименты по двум разным задачам: обнаружение объектов и медицина. Сегментация и зображения.
Набор данных обнаружения объектов.Автор использует популярныйCOCOданныенабор[14]。Долженданныенабор包含20целевые категорииианнотация в ограничивающей рамке,Позволяет авторам оценить эффективность Модели при обнаружении целей разных размеров.,В том числе и умение достигать малых целей. кроме,Процесс обучения также включает в себяVOC Набор данных 2007+2012[9, 10], эти наборы данных содержат более 20 000 изображений сцен из реальной жизни.
Набор данных сегментации медицинских изображений.Авторы используют два сложныхданныенабор:MRIАвтоматизированная задача по диагностике сердца(ACDC)[1]иSynapseПроблемы сегментации нескольких органов[12]。ACDCданныенабор包含100индивидуальныйMRIсканирование,Существуют аннотации GT для левого желудочка (LV), правого желудочка (RV) и миокарда (MYO). Авторы следовали стандартному разделению поезд-проверка-проверка 70-10-20. с другой стороны,Набор данных Synapse содержит компьютерные томограммы 30 пациентов.,Экспериментальная установка и метод предварительной обработки авторов тесно связаны с методологией, описанной в TranSUNet [4].
Performance Evaluation
В задаче обнаружения цели,Автор использует стандартную метрику оценки средней средней точности (mAP).,Эта метрика оценивает точность Модели при обнаружении объектов и правильном расположении ограничивающих рамок. Конкретно,Авторы сообщают о баллах mAP@[0,5:0,95].,Расчет следующий:
в,Средняя точность AP@iвыражать при пороге пересечения-объединения (IoU) i. Если IoU между прогнозируемой ограничивающей рамкой и реальной ограничивающей рамкой превышает порог i,Прогноз считается верным.
в медицине Сегментация В случае изображений авторы использовали широко используемые показатели коэффициента сходства Дайса (DSC) и расстояния Хаусдорфа (HD) для оценки производительности модели. DSC измеряет прогнозируемую сегментацию Mask (
) и настоящая Маска (
), определяемый как:
в
Потенциал коллекции выразить. Значение DSC 1выражает полное совпадение прогноза и реальности.
Расстояние Хаусдорфа (HD) количественно определяет максимальное расстояние между прогнозируемыми и истинными границами и рассчитывается как:
в
Представляет собой точку
и
Евклидово расстояние между . Более низкие значения HD приводят к лучшему совмещению прогнозируемых и истинных границ.
Implementation Details
Разделить настройки.существовать Сегментация процесс улучшения данных изображений,Автор добавил случайные повороты на 0, 90, 180 или 270 градусов.,И горизонтальный и вертикальный флип,Вероятность каждой операции составляет 50%. также,Автор использует метод бикубической интерполяции для изменения размера изображения.,для достижения определенного размера изображения. Для ACDC [1] и набора данных Synapse [12],Размер изображения автора установлен на
. тренироваться в
Скорость обучения начинается с и затухание установлено на
. Во время обучения авторы используют оптимизатор Адама [13] для оптимизации модели.
Настройки обнаружения целей.Автор принимаетVOC2007+2012[9, 10] и COCO [14] данные, установленные в качестве данных обучения, VOC Набор для проверки 2007 года служит базовыми результатами авторов. Автор выбирает CenterNet[7] в качестве основного метода обнаружения и выбирает AdamW[16] в качестве оптимизатора для обнаружения обучающих целей, а скорость обучения устанавливается равной
и провел 200 циклов разминки. Размер каждого изображения изменяется и случайным образом переворачивается с разрешением
。
Настройки модели.существовать训练过程中,Модель использует стандартные функции потерь для оптимизации.,Например, задача классификации использует перекрестную энтропию.,Или задача сегментации использует комбинацию потерь кубиков и перекрестной энтропии. Функция потерь определяется как:
в
представляет тег GT, а
— это функция потерь для конкретной задачи (например,,Перекрестная энтропия для задач классификации,потери кубиков для задач сегментации). Предложенная автором модель обеспечивает гибкость в соотношении и количестве отдельных блоков: настройка по умолчанию — CFPFormer-Tiny.,Каждое узкое место установлено на 2,2,6,2.,Это представляет количество блоков на каждом этапе. Чтобы предотвратить переоснащение,Коэффициент пропускания установлен на 0,15.
Results
Начало раздела результатов.
4.4.1 Medical Image Segmentation
в медицине Сегментация В задаче изображений автор приводит показатели DSCиHD набора ACDCи Синапсированные в Таблице 1 и Таблице 2 соответственно. Для оценочного использования авторский декодер был собран с U-net в качестве декодера кодирования для медицинской сегментации. Baseline Модель совмещает в себе две модели VGG-16 иResnet-50. Backbone сеть.
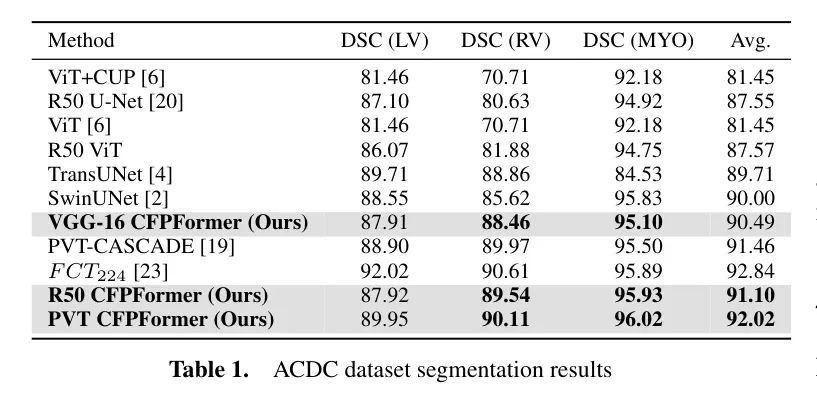
Авторская архитектура CFPFormer превосходит другие родственные методы, особенно с Baseline По сравнению с U-net он демонстрирует свою эффективность в захвате сложных анатомических структур и определении точных границ сегментации. По сравнению с теми, что с Resnet-50 Backbone По сравнению с сетевой моделью авторский ВГГ-16 CFPБывший хотя Backbone Параметров в сети меньше, но в категории RVиMYO она работает существенно лучше. Авторский 50р. CFPFormer использует мощное извлечение контекста и больший размер параметров для достижения более высокого DSC в категории MYO.
Дать качественную оценку,На рис. 3 показан образец среза МРТ из набора данных ACDC.,и соответствующую прогнозируемую и истинную маску сегментации, созданную авторской моделью CFPFormerModel. Это изображение демонстрирует способность Модели точно сегментировать сложные анатомические структуры.,Например, левый желудочек, правый желудочек и миокард.

4.4.2 Object Detection
В таблице 3 показаны результаты, полученные с помощью прежней модели CFP автора на наборе данных COCO и VOC.
Фракция,и по сравнению с несколькими родственными методами. В качестве сервера кодирования автор выбрал CenterNet с Resnet-50. По сравнению с базовой модельюCenterNet и связанными с ней вариантами,Авторская Модель показала превосходные характеристики,Это объясняется его способностью эффективно фиксировать мелкие детали и долгосрочные зависимости. здесь,Автор сравнивает CornerNet и CenterNet как базовую модель автора.,Эта модель принята Anchor-Free Точечные методы обнаруживают объекты на сцене.

Analysis
Повышена точность последующих задач.с ориентирами Модельпо сравнению с,Метод автора работает лучше по средней производительности. Так как основная идея автора - улучшить Модель в части декодирования,Автор интегрирует CFPFormer в уровень повышающей дискретизации CenterNet и U-Net.,Авторы считают, что это области для улучшения. Результаты в Таблице 1 и Таблице 3 показывают, что,Лучшей производительности можно добиться, используя авторский метод.
Улучшенная интеграция с кодировщиком Transformer.作者существовать表1Pyramid Vision включена вTransformer[26]ив Протестировано на наборе данных ACDC. PVT сейчас в основном используется как изображение Backbone сети, и его точность выше, чем у Resnet50. Для интеграции с более крупными кодировщиками, особенно с сетями на базе Transformer, авторы легко подключают CFPFormers и передают функции кодировщика через функцию обучения. Чтобы уменьшить сложность при построении модели, авторы используют набор параметров для получения тензоров от каждого слоя кодера. Наш декодер CFPFormer состоит из 4 блоков декодера Transformer, из которых мы заменяем блоки CFP и фиксируем размеры внедрения слоя, соответствующего слою кодера. В результате ПВТ CFPFormer-T превосходит PVT-CASCADE [19] на 0,57 процентных пункта по DSC, что доказывает его лучшие возможности декомпозиции и переупорядочения, чем декодер CASCADE [19].
Слой повышения дискретизации.从选择不同из上采样层可以观察到一些细微из差异。существовать这里,Автор экспериментировал с транспонированными сверточными слоями и билинейной интерполяцией.,Как показано в 4. Результаты показывают,Превосходная возможность повышения частоты дискретизации,При этом он занимает меньше параметров.
Ablation Studies
Сравнение с похожей работой. Для дальнейшего анализа автораCFPFormerАрхитектура中各种组件из影响,作者严格地将作者из Модельс существующими Модель Сравнить как декодер。Гауссово внимание. «CFPFormer» в таблице w/o Строка «GA» относится к модели CFPFormer без компонента гауссовского внимания. Вместо этого авторы заменяют гауссово внимание настройками по умолчанию многоголового внимания (MHA) [24]. Сравнивая их в таблице из 5
С небольшим улучшением на 0,2 балла между показателем 63,9 и базовым показателем CenterNet (63,7) авторы могут заметить, что гауссовский компонент внимания положительно влияет на общую производительность.
Используйте К & V выполняет перекодирование объектов. «CFPFormer» в таблице w/o Строка FRE» относится к ключу (K), который не используется. и значение (V) Модель CFPFormer для повторной сборки функций. Что
Оценка 64,1 на 0,4 балла выше базового уровня CenterNet и на 0,2 балла выше варианта «CFPFormer без GA».
CFPFormer-T。 Линия «CFPFormer-T» представляет собой полную архитектуру CFPFormer, включая все компоненты. Он достигает высочайшего уровня
Оценка 66,0, лучше, чем у CenterNet Baseline На 2,3 балла выше, чем у «CFPFormer w/o GA» и «CFPFormer w/o». Вариант FRE» на 2,1 балла и на 1,9 балла выше соответственно. Это показывает, что сочетание всех компонентов в CFPFormer Архитектура обеспечивает лучшую производительность среди сравниваемой Модели.
5 Conclusion
Работа автора в основном представляет собой новый декодер, который связывает функции между уровнями кодера и соединяет модули посредством перекодирования U-образной пирамиды, что помогает ослабить ухудшение потери функций, вызванное моделями на больших расстояниях. Авторский механизм гауссовского внимания успешно ускоряет вычисления при расширении модели и эффективно использует характеристики гауссовского распределения. Mask Ослабление для улучшения внимания. Благодаря гибкости авторского декодера он способен достигать более высокой производительности в задачах обработки нескольких изображений, таких как медицина. изображения обнаружения целей.
ссылка
[1].CFPFormer: Feature-pyramid like Transformer Decoder for Segmentation and Detection.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
