«Carnival Viewing» Исследование склада на проточном озере Oceanus, гибкий план сокращения затрат
В ходе онлайн-трансляции карнавала разработчиков Tencent Global Digital Ecology Conference 2024 года я наблюдал за представлением Tencent Cloud Stream Computing Oceanus для создания потокового склада на озере и записал заметки.
фон
В последние годы с ускоренным развитием цифровизации у предприятий возникает все более острая потребность в обработке и анализе данных в режиме реального времени. Данные в режиме реального времени стали ключевым элементом стимулирования бизнес-инноваций и повышения конкурентоспособности. Однако традиционные методы пакетной обработки имеют такие проблемы, как низкая своевременность, разрозненность данных и трудности с расширением, и не могут удовлетворить насущные потребности современных предприятий в аналитике в реальном времени.
Океанус - Исследование склада проточного озера
Потоковые вычисления Oceanus — это инструмент анализа в реальном времени для экосистемы продуктов больших данных. Это платформа анализа больших данных корпоративного уровня, построенная на Apache Flink. Она обладает характеристиками комплексной разработки, плавного подключения и суб-подключения. Вторая задержка, низкая стоимость, безопасность и стабильность.
Потоковые вычисления Oceanus направлены на максимальное повышение ценности корпоративных данных и ускорение процесса цифровизации предприятий в режиме реального времени. Это может помочь предприятиям собирать, обрабатывать и анализировать огромные объемы данных в режиме реального времени. Это позволяет быстро реагировать на бизнес-решения, повышает операционную эффективность и открывает новые возможности роста.
Традиционно пользователи выбирают архитектуру Lambda для построения связей для анализа данных. Лямбда-архитектура — относительно стабильная архитектура для потоковой и пакетной обработки данных. Пусть офлайн-данные и данные в реальном времени проходят отдельную обработку ссылок. Данные офлайн-ссылок обычно хранятся в механизмах автономной обработки, таких как Hive, а Spark используется для многоуровневого преобразования данных. Данные ссылки реального времени будут обрабатываться отдельно, и обычно используется многоуровневая ссылка Flink+Kafka в реальном времени. Окончательные данные будут записаны в онлайн-базу данных и хранилище данных. Эта архитектура может обеспечить задержку второго уровня базы данных, но есть и некоторые проблемы. Такая связь недостаточно гибкая, Kafka не может сохранять данные в течение длительного времени и не может осуществлять анализ и интеллектуальный анализ данных. Стоимость такого соединения относительно высока, и upsert-kafka использует локальное хранилище состояний. Данные в реальном времени и автономные данные модели архитектуры Lambda используют отдельные ссылки, что удваивает объем хранилища данных. Логику вычислений в реальном времени и автономного хранения также необходимо разрабатывать отдельно.
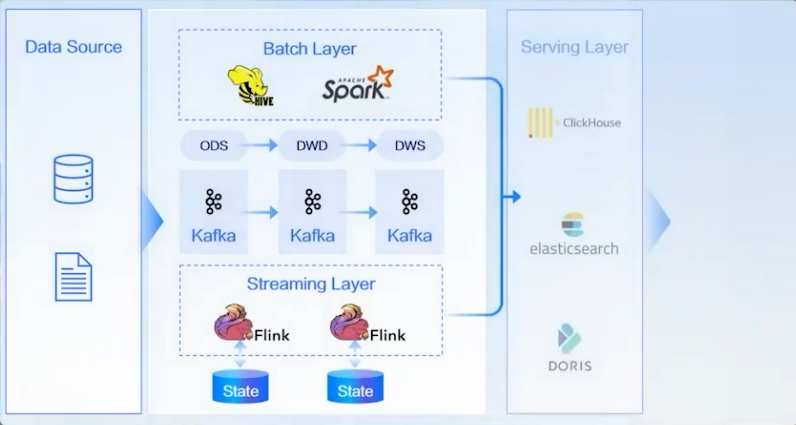
Oceanus объединяет ссылки в реальном времени и оффлайн. Унифицированное хранилище данных отвечает следующим двум требованиям: во-первых, автономное чтение данных из хранилища данных и анализ требований OLAP; во-вторых, записанные данные могут создавать полный журнал изменений, совместимый с Flink, который можно подключить к заданиям Flink для дальнейшей потоковой обработки. Tencent запустила Streaming lceberg, решение для потокового хранения данных на озере, основанное на экосистеме lceberg.
Основные моменты:
- Устранение разрозненности данных: устранение барьеров хранения данных, унифицированное хранение данных в автономном режиме и в режиме реального времени, а также избежание повторного хранения данных.
- Упрощенная эксплуатация и обслуживание. Благодаря унифицированному механизму хранения данных и вычислений упрощается управление эксплуатацией и обслуживанием системы.
- Полный журнал изменений. Создайте полный журнал изменений, позволяющий механизмам потоковой обработки, таким как Flink, поэтапно обрабатывать данные.
- Эффективные обновления. Основанный на механизме хранения LSM Tree, он поддерживает эффективные обновления первичного ключа и частичные обновления столбцов.
- Совместимость с экосистемой lceberg: пользователи могут легко переносить существующие задания запросов lceberg.
- Поддерживает несколько механизмов запросов: Spark SQL, Trino/Presto и другие механизмы запросов.
- Оптимизация больших таблиц: улучшите скорость записи данных.
- Кодирование сжатия и оптимизация разделов: уменьшите объем памяти и улучшите производительность запросов.
Сценарии применения:
- игра
- путешествовать
- обучать
- Электронная коммерция
Ниже приведен сценарий анализа данных транзакций заказов в режиме реального времени в индустрии электронной коммерции.

Гибкий план снижения затрат Oceanus
Болевые точки, с которыми сталкиваются предприятия:
- Сложное управление ресурсами. Гибкие задания приводят к бесполезной трате ресурсов, и пользователям обычно требуется много времени для оптимизации заданий и достижения более эффективного управления ресурсами.
- Сложное управление эксплуатацией и обслуживанием. Управление эксплуатацией и обслуживанием платформы Flink является громоздким и сложным. Мониторинг ресурсов, сигналы тревоги о заданиях, исследование журналов, события заданий и оптимизация производительности требуют профессионального и технического персонала для эксплуатации и обслуживания.
- Сложность эластичного расширения. Трудно эластично расширяться в зависимости от деловой нагрузки, и она не может удовлетворить потребности быстрого роста бизнеса.
Учитывая вышеизложенные болевые точки, Oceanus запустила новый гибкий план снижения затрат.
- Поддерживает эластичную усадку и гибко использует ресурсы в сочетании с расширением и сокращением рабочих мест.
- Низкая стоимость: гибкий кластер годовой и ежемесячной подписки.
- Возможности кластера и платформы: автоматическое расширение и сжатие, эластичное масштабирование, мелкозернистые ресурсы.
- Экспертные ресурсы и настройка заданий: настройка ресурсов на уровне оператора, настройка экспертных заданий.
- Мониторинг времени выполнения, мониторинг индикаторов и мониторинг событий
- Интеллектуальные сигналы тревоги, сигналы тревоги индикаторов и сигналы тревоги событий
- Аномальный диагноз: быстрая диагностика одним щелчком мыши и диагностика черного окна
- Поддержка быстрого отката: поддержка управления снимками и восстановление заданий из снимков.
- Журнал: поддерживает экземпляр, время, поиск по ключевым словам.
Подвести итог
На карнавале разработчиков глобальной цифровой экосистемы Tencent 2024 года я узнал много «черных» технологий, обогатил свои знания, стимулировал исследования и размышления о технологиях, а также получил много ценного опыта и идей. Я очень благодарен Tencent за карнавал. Надеюсь, он будет становиться все лучше и лучше. Мы будем поддерживать дух открытости и совместимости, учиться друг у друга, обсуждать и сотрудничать. ну давай же!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
