CALF: эффективная кросс-модальная система тонкой настройки LLM для долгосрочного прогнозирования временных рядов
Глубокое обучение добилось значительного прогресса в области многомерного прогнозирования временных рядов (MTSF). Хотя большинство существующих методов полагаются на ввод одномодальных временных рядов для обучения, недавние методы прогнозирования кросс-модальных временных рядов, основанные на больших языковых моделях (LLM), продемонстрировали отличную производительность в условиях ограниченных данных. Однако существующие методы MTSF на основе LLM часто игнорируют различия в распределении между входными текстовыми и временными рядами, что приводит к неоптимальной производительности.
В этой статье представлена статья Университета Цинхуа.и Исследовательская работа по прогнозированию временных рядов, проведенная Шэньчжэньским университетом。Исследователи предложили новый кросс-модальный большой язык Модельтонкая настройкарамка (CALF), целью которого является уменьшение разницы в распределении между текстом и данными временных рядов.CALF В основном он включает в себя целевую ветвь временных рядов и ветвь источника текста. Благодаря модулю кросс-модального сопоставления достигается потеря регуляризации функций и потеря согласованности вывода, эффективное согласование между двумя модальностями. Экспериментальные результаты показывают, что CALF Он обеспечивает высочайшую производительность как в долгосрочных, так и в краткосрочных задачах прогнозирования, а также демонстрирует превосходные возможности с малым количеством и нулевыми шагами, аналогичные большим языковым моделям.
Этот метод достигается за счет кросс-модального выравнивания данных временных рядов и текстовых данных.,Значительно улучшена производительность прогнозов,И предлагает новые идеи для прогнозирования временных рядов.иметод。Предложение структуры CALF не только расширяет применение больших языковых моделей для прогнозирования временных рядов, но также демонстрирует потенциал для достижения эффективного прогнозирования при низкой вычислительной сложности.Эта исследовательская работа закладывает основу для будущих исследований во многих областях.данные Предоставляет важную информацию для динамического моделирования временных явлений реального мира.。

【Название статьи】CALF: Aligning LLMs for Time Series Forecasting via Cross-modal Fine-Tuning
[Бумажный адрес]https://arxiv.org/pdf/2403.07300
[Исходный код бумаги]https://github.com/Hank0626/CALF
Обзор бумаги
Существующие методы прогнозирования временных рядов достигли значительного прогресса в обработке многомерного прогнозирования временных рядов (MTSF). Традиционные методы прогнозирования одномодальных временных рядов обычно полагаются только на ввод временных рядов для обучения. Хотя эти методы достигли определенного успеха, они также сталкиваются с проблемами переобучения из-за ограниченности обучающих данных, что ограничивает их практическое применение.
В последние годы в область прогнозирования временных рядов были введены модели больших языков (LLM), чтобы облегчить вышеупомянутые проблемы благодаря их мощным возможностям контекстного моделирования. Хотя существующие методы, основанные на LLM, демонстрируют превосходство в прогнозировании временных рядов, они часто игнорируют различия в распределении между входными текстовыми данными и временными рядами (как показано на рисунке ниже), что приводит к неоптимальной производительности.
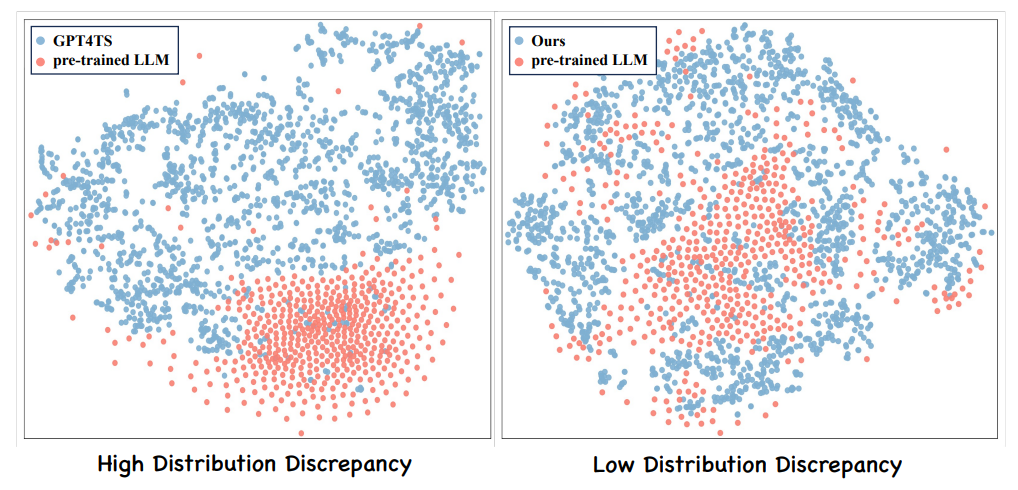
Чтобы решить эту проблему, в этой статье предлагается новая кросс-модальная система тонкой настройки LLM (CALF), позволяющая повысить производительность прогнозирования временных рядов за счет уменьшения разницы в распределении между текстовыми данными и данными временных рядов.
Конкретно,Рамка CALF состоит из двух основных частей: целевой ветви времени, которая обрабатывает ввод временных рядов, и ветви источника текста, которая обрабатывает ввод текста.。Чтобы уменьшить эти дваиндивидуальный Различия в распределении между филиалами,Исследователи разработали модуль кросс-модального сопоставления(Cross-modal Match модуль), потеря регуляризации признака (Feature Regulariztion потери) и согласованность вывода (Выход Consistency Потеря) потеря.
- Извлечение модуля кросс-модального сопоставления с помощью встраивания основного слова и механизма перекрестного внимания.,Обеспечьте согласованное распределение временных рядов и текстовых вводов.
- Потеря регуляризации функций оптимизирует обновления веса модели путем выравнивания функций промежуточного слоя.
- Потеря согласованности Результат обеспечивает согласованность выходных представлений текста и временных рядов, что позволяет делать более эффективные прогнозы.
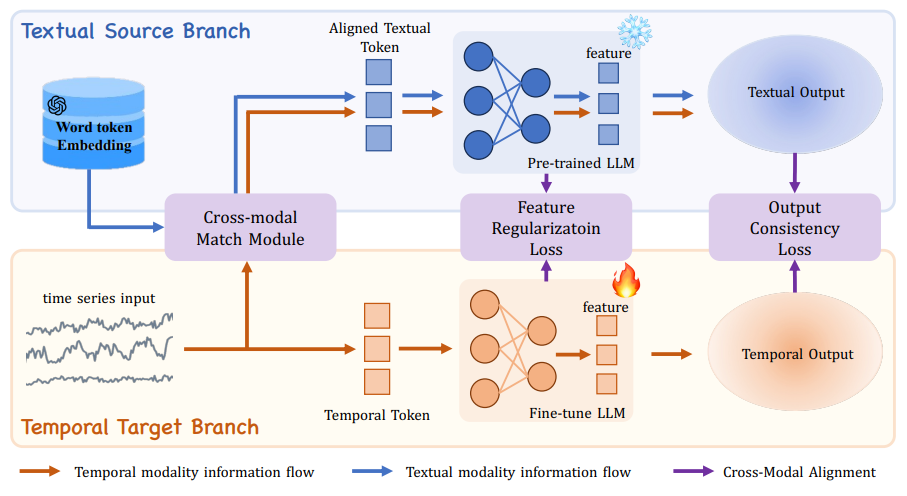
Концептуальная иллюстрация методов кросс-модальной тонкой настройки
Основные положения этой статьи включают в себя:
- предложил новый кросс-модальный LLM тонкая настройкарамка (CALF), через модуль кросс-модального согласования, потеря регуляризации функциии Потеря согласованности результаты, уменьшить разницу в распределении между текстом и данными временных рядов, повысить производительность прогнозирования временных рядов.
- Предлагается разновидность кросс-модальной тонкой. технология настройки, включая модуль кросс-модального сопоставления, потеря регуляризации функциии Потеря согласованности результат, всестороннее согласование данных текста и временных рядов на входном, функциональном и выходном уровнях.
- Валидность Проверено обширными экспериментами CALF на наборе множественных индивидуальных долгосрочных и краткосрочных временных рядов данных,Продемонстрировано значительное улучшение вычислительной эффективности при прогнозировании производительности.,Он особенно хорошо работает с точки зрения возможностей обучения с малой выборкой и с нулевой выборкой.
Введение модели
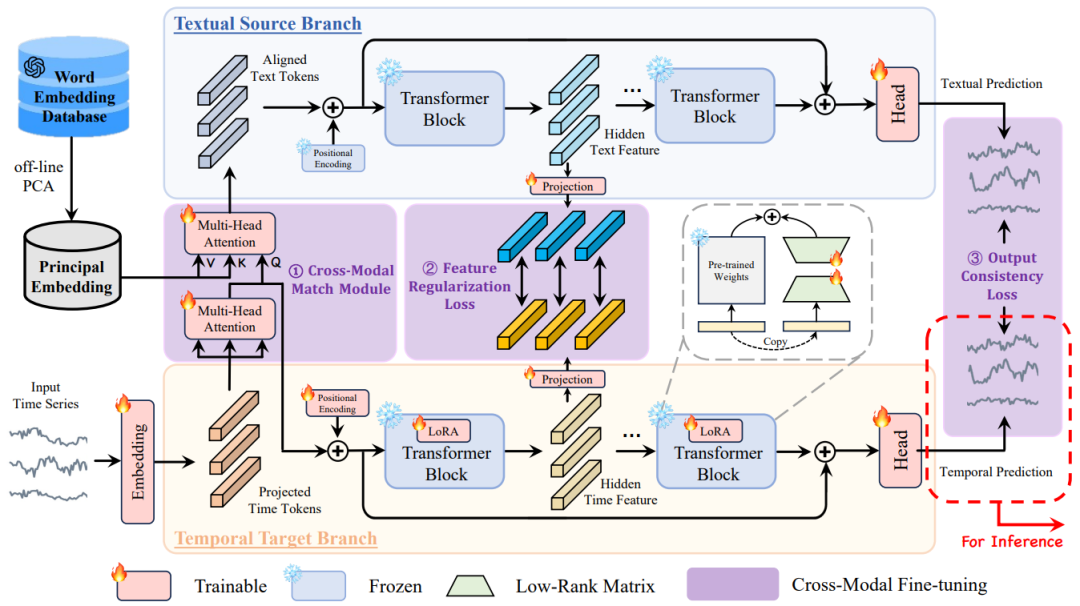
Диаграмма структуры кросс-модальной тонкой настройки, предложенная в этой статье.
Целью этой статьи является использование кросс-модальной технологии точной настройки для решения проблемы адаптации предметной области применения LLM к задачам прогнозирования временных рядов, чтобы язык и временные ряды могли быть лучше согласованы, тем самым улучшая точность и способность к обобщению моделей прогнозирования временных рядов. .
Общая структура модели показана на рисунке выше. Предлагаемый CALF состоит из двух ветвей: ветви текстового исходного домена и временной ветви целевого домена. Обе ветви состоят из нескольких слоев предварительно обученных моделей GPT2. Разница в том, что входные данные ветки исходного домена текста представляют собой текстовые модальные данные, а входные данные временного целевого домена — данные временных рядов. Чтобы согласовать входные данные двух ветвей, в этой статье предлагаются три соответствующих модуля для продвижения. Выравнивание текста под разными углами синхронизации. Эти три модуля будут представлены отдельно ниже.
01. Модуль межмодального сопоставления
Исследователи подверглись LLM Вдохновленный соответствующей работой, обратите внимание, что LLM Слой внедрения текста на самом деле содержит богатые token знание корреляций между,Например, угол между векторами может представлять сходство соответствующей семантики. с этой целью,Знание уровня внедрения LLM может помочь в обучении прогнозированию времени и лучшей зависимости от контекста.Конкретно,Учитывая многомерный временной ряд
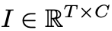
В качестве входных данных эта статья сначала передает его через уровень внедрения и многоголовочный механизм самообслуживания для получения отображенного вывода:
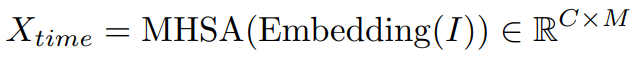
После этого рассмотрим
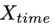
Внедрение словаря слоев с помощью этой модальности статьи
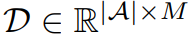
Выполните сопоставление выравнивания. Принимая во внимание размер словаря

Обычно очень большой, например 50257 в GPT2. Следовательно, прямое использование перекрестного внимания для выравнивания текста и временных модальностей приведет к значительным вычислительным затратам. Чтобы добиться эффективного выравнивания, исследователи предложили сначала использовать анализ главных компонентов, чтобы уменьшить количество статей в словаре исходного языка и получить более компактное словарное представление.
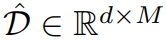
,Прямо сейчас:
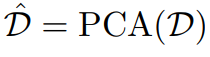
в
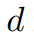
это определяемый человеком гиперпараметр, который удовлетворяет
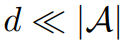
. После получения уменьшенного по размерности словаря в этой статье используется перекрестное внимание для выравнивания входных данных текстовых и временных модальностей:
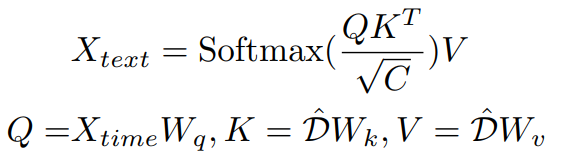
02. Потеря регуляризации функций
Предварительно обученные веса в LLM основаны на исходных данных модальности текста. Чтобы более эффективно адаптировать эти предварительно обученные веса к данным временных рядов, в этой статье выходные данные каждого промежуточного слоя в ветви целевого домена временных рядов выравниваются с выходными данными ветви домена источника текста. С помощью потери регуляризации объектов этот процесс выравнивания может сопоставить промежуточные объекты между двумя ветвями, тем самым более эффективно управляя градиентом каждого промежуточного слоя и достигая лучших обновлений веса.
Формально говоря, учитывая текстовую исходную ветвь домена и временную целевую ветвь домена,
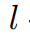
Выход трансформаторного модуля
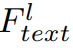
и
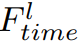
, потеря регуляризации признаков в этой статье определяется как:
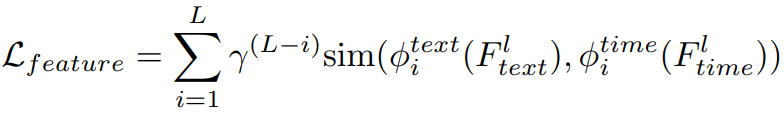
в
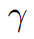
— это гиперпараметр, который контролирует важность каждого слоя, а sim представляет собой меру сходства объектов, например
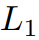
Сходство. Кроме того, ссылаясь на соответствующую работу по контрастному обучению, в этой статье вводится дополнительный уровень отображения при расчете потерь.
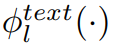
и
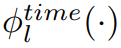
отобразить промежуточные характеристики двух модальностей в общее пространство репрезентации.
03
Потеря согласованности вывода
На основе потери регуляризации функций,Эта статья также обеспечивает согласованность семантического контекста между модальностью текста и модальностью времени. с этой целью,В этой статье далее предлагается потеря согласованности результатов.,Обеспечивая эффективное распределение результатов,Это устраняет различия в пространствах представления разных модальностей.
В частности, учитывая выходные данные текстовой исходной ветки и временной целевой ветки соответственно
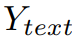
и
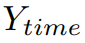
, потеря согласованности выходного сигнала определяется как:
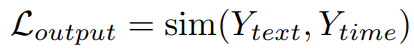
в,sim для данной меры сходства признаков.
04. Эффективное обучение параметров
Чтобы избежать катастрофического забывания при точной настройке последующих задач и повысить эффективность обучения, в этой статье используется технология обучения с эффективными параметрами для точной настройки предварительно обученного LLM.
В частности, для временной целевой ветви домена в этой статье представлен LoRA и точная настройка веса кодирования положения. В целом, общие потери во время обучения — это контролируемые потери.
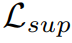
, потеря регуляризации функции
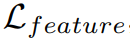
и Потеря согласованности вывода
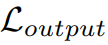
Взвешенная сумма:
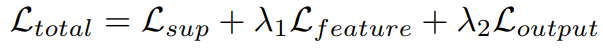
На этапе вывода в этой статье в качестве конечного результата используются выходные данные временной ветви целевой области.
Результаты экспериментов
Долгосрочный прогноз:сравнивал на основе LLM Модель прогнозирования временных рядов, Transformer Модель, CNN Модельи MLP Модель. Входная длина фиксирована на 96, результат {96, 192, 336, 720} средний. Как видно из таблицы ниже, Модель, предложенная в этой статье, позволила добиться значительных улучшений как по показателям MSE, так и по MAE.

Краткосрочный прогноз:По сравнению с предыдущим SOTA метод TimesNet Есть значительное улучшение.
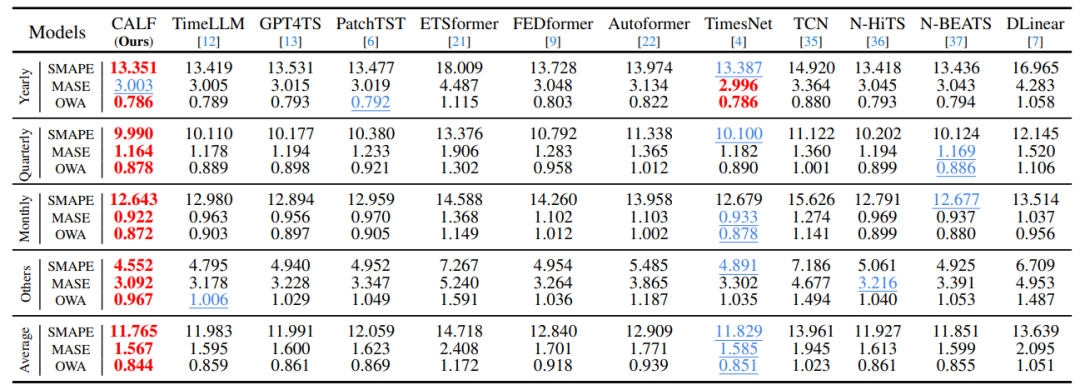
Прогноз с малой выборкой/нулевой выборкой:CALF Превосходит другие базовые показатели, метод, подчеркивая его надежность в условиях обучения с небольшим количеством участников. и GPT4TSиPatchTST Для сравнения, этот бумажный метод соответственно достиг среднего 8%и9% сокращение, чем GPT4TSиPatchTST выше 4%и9% . Это показывает CALF Значительно расширяет возможности модели эффективно переносить обучение между различными областями.


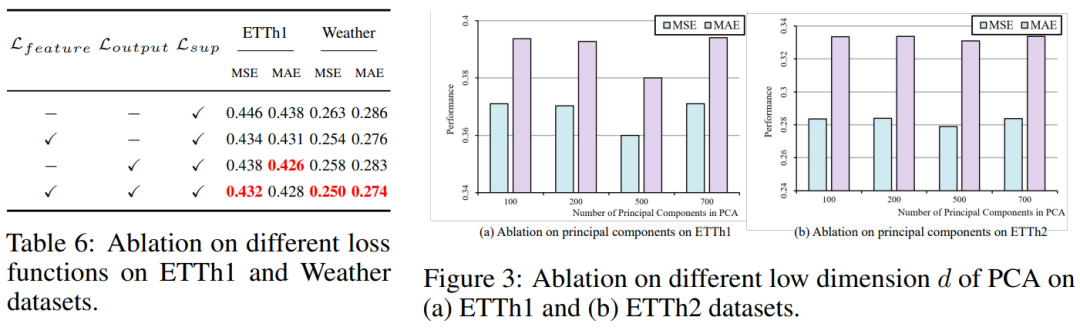
тонкая настройка lossиPCA Уменьшение размерности ablation анализировать:
Исследователь также объяснил структуру с точки зрения теории вероятностей. Подробности см. в Приложении B оригинальной статьи.
Подвести итог
В этой статье представлен эффективный кросс-модальный метод долгосрочного прогнозирования временных рядов. LLM тонкая настройкарамка(CALF)。CALF С помощью модуля кросс-модального сопоставления потеря регуляризации функциии Потеря согласованности результаты, уменьшают разницу в распределении между текстом и данными временных рядов, значительно повышают производительность прогнозирования временных рядов. По сравнению с предыдущим методом одномодального прогнозирования временных рядов, CALF Рамка использует данные текста и временных рядов посредством всестороннего выравнивания и хорошо работает с точки зрения вычислительной эффективности при прогнозировании данных в нескольких отдельных наборах данных временных рядов, особенно с точки зрения возможностей обучения с несколькими и нулевыми кадрами. ТЕЛЕНОК Это предложение представляет собой новый и эффективный инструмент для прогнозирования временных рядов и, как ожидается, получит широкое распространение в практических приложениях.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
