Byte предлагает LLaVA-OneVision: первую крупномасштабную модель с открытым исходным кодом, которая преодолевает узкое место в производительности мультимодальных моделей!

Авторы представляют LLaVA-OneVision, серию больших мультимодальных моделей (LMM) с открытым исходным кодом, интегрированных на основе идей из серии блогов LLaVA-NeXT. Экспериментальные результаты автора показывают, что LLaVA-OneVision является первой одиночной моделью, которая может одновременно преодолевать узкие места в производительности трех важных сцен компьютерного зрения (одно изображение, несколько изображений и видеосцены) открытых LMM. Примечательно, что конструкция LLaVA-OneVision позволяет эффективно переносить обучение между различными модальностями/сценариями, что приводит к появлению новых возможностей. В частности, он демонстрирует хорошее понимание видео и возможности работы с разными сценариями посредством переноса задач из изображений в видео. https://llava-vl.github.io/blog/llava-onevision
1 Introduction
Одно из основных стремлений искусственного интеллекта — создание универсальных помощников с крупномасштабными моделями визуального языка [67]. LLaVA-OneVision — это модель с открытым исходным кодом, предназначенная для продвижения исследований по созданию крупномасштабных помощников по визуальному языку (LLaVA) [83], которые могут адаптироваться к различным инструкциям для выполнения различных задач компьютерного зрения в реальных условиях. В качестве экономичного и эффективного подхода он часто реализуется путем подключения визуального кодировщика к крупномасштабной языковой модели (LLM).
Первая модель LLaVA [83] продемонстрировала впечатляющие возможности мультимодального чата, иногда демонстрируя поведение, подобное GPT-4V, при первом просмотре ранее невиданных изображений и указаний. LLaVA-1.5 [81] значительно расширяет и улучшает возможности за счет интеграции более академически значимых данных инструкций для достижения оптимальной производительности в десятках тестов при эффективном использовании данных. LLaVA-NeXT [82] унаследовал эту функцию и еще больше расширяет границы производительности за счет трех ключевых технологий: AnyRes для обработки изображений с высоким разрешением, масштабирования высококачественных командных данных и использования лучшего открытого LLM, доступного на тот момент.
LLaVA-NeXT предоставляет расширяемый и масштабируемый прототип, который облегчает многочисленные параллельные исследования, о которых сообщалось в серии блогов LLaVA-NeXT [82, 168, 65, 64, 68]:
https://llava-vl.github.io/blog/
* «Видеоблог» [168] показывает, что модель LLaVA-NeXT, обученная только на изображениях, удивительно эффективно справляется с видеозадачами с нулевыми модальными преобразованиями благодаря конструкции AnyRes, которая интегрирует любые визуальные сигналы, потребляемые как последовательность изображений. *"Блог Stronger" [65] демонстрирует успешную реализацию этой экономически эффективной стратегии. Просто увеличив масштаб LLM, он достиг производительности, сравнимой с GPT-4V в некоторых тестах.
*Блог Ablation [64] суммирует эмпирические исследования автора, выходящие за рамки самих данных визуальных инструкций, включая выбор архитектуры (LLM и масштабирование визуальных кодировщиков), визуального представления (разрешение и #токены) в стремлении к успеху масштабирования данных). и стратегии обучения (обучаемые модули и высококачественные данные) и т. д. *В блоге Interweaving [68] описаны стратегии расширения и улучшения возможностей в новых сценариях, включая многоизображение, многокадровое (видео) и многопросмотровое (3D), при сохранении производительности одного изображения.
Эти исследования проводятся в рамках фиксированного вычислительного бюджета и призваны предоставить некоторую полезную информацию в ходе проекта, а не расширять границы производительности. В ходе этого процесса автор также накопил и систематизировал большой объем качественных данных обучения с января по июнь. Объединив эти идеи и проводя эксперименты с вновь накопленными большими наборами данных, авторы представляют LLaVA-OneVision. Авторы использовали существующие вычислительные мощности для реализации новой модели без чрезмерного снижения риска отдельных компонентов. Это оставляет авторам возможность продолжать совершенствовать возможности путем добавления данных и масштабирования модели, см. подробный график разработки в части A. В частности, в статье автора представлены следующие сведения:
- Масштабная мультимодальная модель. Авторы разработали LLaVA-OneVision,Это семейство открытых крупномасштабных мультимодальных моделей (LMM).,Улучшены границы производительности для открытых LMM в трех важных визуальных настройках, включая одно изображение, несколько изображений и видео.
- Новые возможности миграции задач. Авторский дизайн иданных представлений позволяет мигрировать задачи по различным сценариям.,Это обеспечивает простой способ создания новых новых возможностей. в частности,LLaVA-OneVision демонстрирует мощные возможности понимания видео на изображениях посредством передачи задач.
- Открытый исходный код. Двигаться к созданию автором универсального визуального помощника,Автор делает общедоступными следующие активы: сгенерированные мультимодальные инструкции данные,кодовая база,Модель предварительно обученных весов,и пример визуального чата.
2 Related Work
Новейшие адаптивные языковые модели (LM), такие как GPT-4V [109], GPT-4o [110], Gemini [131] и Claude-3.5 [3], продемонстрировали выдающуюся производительность в различных визуальных сценариях, включая одно изображение, несколько изображений. изображения и настройки видео. В открытой исследовательской области существующие исследования обычно разрабатывают модели отдельно для каждого отдельного сценария. В частности, большинство исследований сосредоточено на ограничениях производительности в сценариях с одним изображением, и лишь несколько новых статей начинают изучать сценарии с несколькими изображениями [70, 47]. Хотя видео LM хорошо справляются с пониманием видео, часто за это приходится платить качеством изображения [72, 76]. Редко можно найти одну модель с открытым исходным кодом, которая одновременно демонстрирует превосходную производительность при работе с крупномасштабными данными изображений. LLaVA-OneVision стремится продемонстрировать современную производительность, одновременно демонстрируя способность раскрывать интересные новые функции посредством межсценарной миграции и композиции задач.
Насколько известно автору, LLaVA-NeXT-Interleave [68] была первой моделью, сообщившей о хорошей производительности во всех трех сценариях, а LLaVA-OneVision унаследовала ее рецепт обучения и данные для повышения производительности. Другие универсальные открытые LM с потенциально превосходными характеристиками включают VILA. [77],IntentLM-XComposer-2.5 [161]. Однако их результаты не были тщательно оценены и опубликованы; авторы будут сравнивать их экспериментально; Помимо преимуществ создания системы с множеством возможностей, LLaVA-OneVision также извлекает выгоду из крупномасштабных высококачественных обучающих данных, включая знания о синтезе моделей и новую коллекцию данных настройки инструкций по разнообразию. В первом случае авторы унаследовали все данные обучения знаниям из [64]. В последнем случае мотивация автора исходит из ФЛАН. [136, 88, 144]. Процесс сбора данных с помощью Idefics2 [63] и Кембрий-1 [133] В то же время, но автор акцентирует внимание «на» — это небольшая подборка наиболее тщательно отобранных коллекций данных. Был сделан аналогичный вывод: настройка данных с помощью большого количества визуальных инструкций может значительно повысить производительность. Для всестороннего обзора выбора конструкции LM авторы могут сослаться на некоторые недавние исследования.
3 Modeling
Network Architecture
Архитектура этой модели наследует минималистский дизайн серии LLaVA с двумя основными целями: (i) эффективное использование возможностей предварительного обучения LLM и визуальных моделей и (ii) достижение высокой масштабируемости с точки зрения данных и моделей. Архитектура сети показана на рисунке 1.
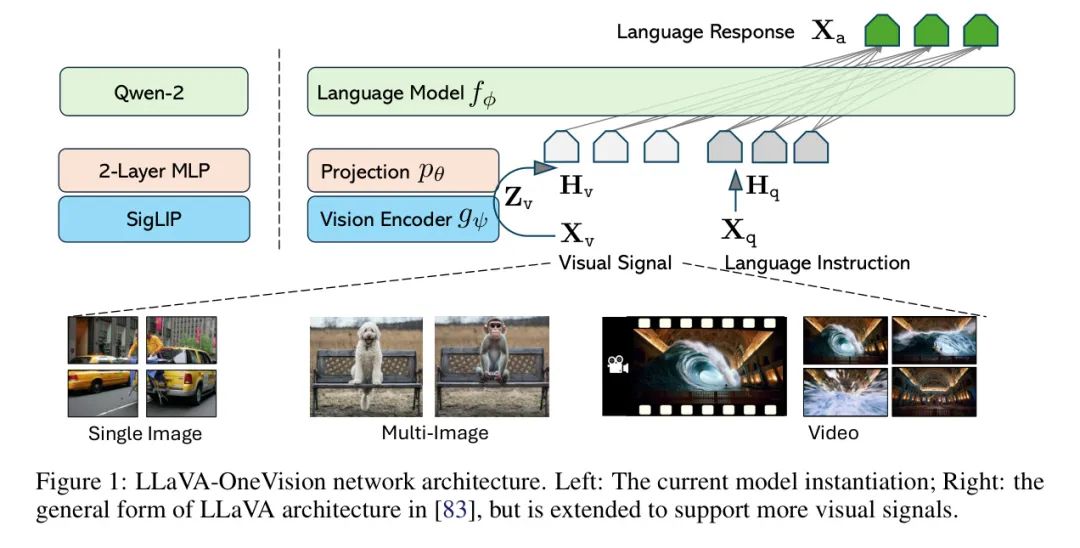
- LLM (Языковая модель). Выбор автора Квен-2 [147] Магистр права как автор Параметризация Модели, поскольку она обеспечивает различные размеры Модели и демонстрирует сильные языковые возможности среди общедоступных в настоящее время предварительно обученных весов.
- Визуальный кодер. Автор рассматривает SigLIP [157] как визуальный кодировщик Параметризация Модели введет изображение. закодированы как визуальные особенности . В экспериментах автора учитывались особенности сетки до и после последнего слоя Трансформера.
- проектор. Автор рассматривает 2-х слойный МЛП. Параметризованная модель [81] отображает особенности изображения в пространство встраивания языка и получает серию визуальных токенов. 。
Выбор модели основан на экспериментальном наблюдении автора о том, что более мощные LLM обычно обладают более сильными мультимодальными возможностями во внешних средах, в то время как SigLIP имеет более высокую производительность LMM в открытых визуальных кодировщиках.
Предлагаемая стратегия Higher AnyRes может служить гибкой структурой визуального представления, подходящей для представления нескольких изображений и видео. Оптимальную конфигурацию по производительности и стоимости можно соответствующим образом скорректировать. Авторы изображают конфигурацию на рисунке 3 и подробно описаны в разделе C.1. И предоставляет следующие расширенные стратегии кодирования:

- одно изображение. Авторы рассматривают возможность использования большей максимальной пространственной конфигурации (a, b) для представления одного изображения, чтобы сохранить исходное разрешение изображения без масштабирования. Кроме того, авторы намеренно присваивают каждому изображению большое количество визуальных маркеров, создавая тем самым более длинные последовательности с эффективным представлением зрительных сигналов. Это основано на наблюдении, что существует большая доля изображений с большим количеством качественных обучающих образцов и разнообразными инструкциями. Используя долговременные последовательности изображений, имитирующие видеоизображения, авторы могут облегчить плавную передачу возможностей между изображениями и пониманием видео [168; 64]。
- несколько изображений. Только разрешение базового изображения учитывается и вводится в визуальный кодер для получения карты признаков, что устраняет необходимость многоблочной обрезки изображений с высоким разрешением и тем самым экономит вычислительные ресурсы [68].
- видео. Каждый кадр в видео масштабируется до разрешения базового изображения.,и обрабатывается с помощью визуального кодировщика для создания карт объектов. Билинейная интерполяция используется для уменьшения количества токенов.,За счет уменьшения количества маркеров на кадр,Позволяет учитывать больше кадров. Эмпирические данные показывают,Это обеспечивает лучший компромисс между вычислительными затратами и производительностью [168].
Эти конфигурации представления предназначены для обеспечения передачи мощности в экспериментах с фиксированными вычислительными бюджетами. По мере увеличения вычислительных ресурсов количество маркеров на изображение или кадр можно увеличивать на этапах обучения и вывода соответственно для повышения производительности.
4 Data
В области мультимодального обучения распространена концепция «качество важнее количества». Причина, по которой этот принцип важен, заключается в том, что большой объем знаний хранится в предварительно обученных LLM (языковых моделях) и визуальных преобразователях (ViT). Хотя крайне важно накопить сбалансированные, разнообразные и высококачественные обучающие данные в конце цикла обучения LMM (языковой модели), важным аспектом, который часто упускается из виду, является то, что модель может подвергаться новым, высокоэффективным воздействиям. качественные данные в любое время. качественные данные для дальнейшего получения знаний. В этом разделе авторы обсуждают источники данных и стратегии для высококачественного обучения знаниям и настройки визуальных инструкций.
High-Quality Knowledge
Большие общедоступные текстовые данные изображений обычно имеют низкое качество, что делает расширение данных для мультимодального предварительного обучения менее эффективным. Поэтому рекомендуется сосредоточиться на качественном усвоении знаний, когда вычислительный бюджет ограничен. Этот подход признает, что предварительно прошедшие обучение LLM и ViTs уже имеют большую базу знаний, и направлен на совершенствование и расширение этой базы знаний с помощью тщательно отобранных данных. Уделение внимания качеству данных может максимизировать эффективность вычислений.
Авторы рассматривают три основные категории для получения данных для качественного усвоения знаний:
- Затем подробно опишите данные. ЛЛа ВА-NeXT-34B [82] Потому что это в Открытом исходный кодLMMsИзвестен своей мощной способностью подробно описывать。Автор использует это Модельдля следующихданные Установить создание нового описания:COCO118K,BLIP558KиCC3M,Всего 3,5 млн образцов. Это можно рассматривать как простую попытку самосовершенствования ИИ.,Данные обучения генерируются самостоятельно более ранней версией Модели.
- Документация/OCRданные. Автор использовал подмножество чтения текста из набора данных UREader.,Всего 100 тыс. образцов,Легко доступен через рендеринг PDF. Автор использует этот текст для чтения данных и комбинации SynDOG EN/CN.,Форма документа/OCRданные,Всего 1,1 млн образцов.
- Китайский и языковые данные. Автор использует оригинальный ShareGPT4V. [20] изображений и использование Azure GPT-4V, предоставляемый API, генерирует 92 тыс. подробных описаний данных на китайском языке для улучшения возможностей модели на китайском языке. Поскольку автор использует много подробных описаний данных, автор также стремится сбалансировать навыки понимания языка Модели. Автор из набора Эво-Инструктированные В [16] собрано 143 тыс. образцов.
Стоит отметить, что почти все качественные данные знаний являются синтетическими (99,8%). Это связано с высокой стоимостью и ограничениями авторских прав на сбор крупномасштабных высококачественных полевых данных. Напротив, синтетические данные легко масштабируются. Автор считает, что по мере совершенствования моделей ИИ обучение на крупномасштабных синтетических данных становится тенденцией.
Visual Instruction Tuning Data
Настройка визуальных команд [83] относится к способности LMM понимать и выполнять визуальные команды. Эти инструкции могут быть в языковой форме в сочетании с визуальными носителями, такими как изображения и видео, и LMM будет обрабатывать их и следовать им для выполнения задач или предоставления ответов. Это включает в себя сочетание визуального понимания с обработкой естественного языка для интерпретации инструкций и выполнения требуемого ответа.
Сбор и организация данных. Как упоминалось ранее [81, 133, 63], данные настройки визуальных инструкций имеют решающее значение для возможностей LMM. Поэтому поддержание сбора высококачественных наборов данных имеет решающее значение и приносит пользу сообществу. Авторы начали со сбора большого количества наборов данных по настройке инструкций из различных исходных источников с несбалансированными пропорциями данных для каждой категории данных. Кроме того, авторы также используют некоторые новые подмножества из классификаций наборов данных «Котел» [63] и «Кембрий» [133].
Авторы классифицировали данные по трем уровням классификации: визуальный, инструктирующий и ответный.
- Визуальный ввод. Рассмотрим три визуальных сценария: одно изображение、несколько изображенийивидео,Просмотр как визуальный ввод в мультимодальных последовательностях.
- языковые инструкции。Эти инструкции часто приходят в форме вопросов.,Определите задачи, которые необходимо выполнить при обработке визуального ввода.。Автор будетданные Разделены на пять основных категорий:_Общие вопросы и ответы(General QA), «Общее оптическое распознавание символов (Общее OCR)", "Документ/Диаграмма/Экран (Док/Диаграмма/Экран)", "Математические рассуждения (Математика) Рассуждение и язык. Эти инструкции определяют набор навыков, которыми может овладеть обученный LMM. Авторы используют классификацию задач, чтобы помочь сохранить и поддерживать сбалансированное распределение навыков.
- Языковой ответ. Ответы не просто отвечают на запросы пользователей,Также определяет поведение модели. В общих чертах его можно разделить на свободную и фиксированную форму.
Данные в свободной форме обычно аннотируются расширенными моделями, такими как GPT-4V/o и Gemini, а данные фиксированной формы извлекаются из академических наборов данных, таких как VQAv2, GQA и Visual Genome. Для данных в свободной форме авторы сохраняют оригинальные ответы. Но для данных фиксированного формата авторы вручную просматривают содержимое и вносят необходимые исправления в форматы вопросов и ответов. Авторы придерживаются стратегии подсказок LLaVA-1.5 для данных с множественным выбором, данных с короткими ответами и данных для конкретных задач (таких как оптическое распознавание символов). Этот шаг имеет решающее значение для управления поведением модели, чтобы правильно сбалансировать производительность контроля качества, возможности общения и навыки рассуждения в более сложных задачах, а также предотвратить потенциальные конфликты между различными источниками данных. Подробная информация, классификация и советы автора по форматированию для каждого собранного набора данных перечислены в Приложении E.
Авторы разделили данные инструкций на две отдельные группы: одну для сценариев с одним изображением, а другую для всех визуальных сценариев. Это разделение основано на выводах авторов из более ранних исследований взаимосвязи между моделями изображений и видео: более сильные модели изображений лучше подходят для задач с несколькими изображениями и видео. Кроме того, количество и качество набора обучающих данных значительно выше для данных с одним изображением по сравнению с задачами с видео и несколькими изображениями.
Данные одного изображения. Поскольку данные одного изображения имеют решающее значение для мультимодальных возможностей, авторы специально собрали большой набор данных одного изображения для обучения модели. Авторы выбрали и построили сбалансированный набор из собранных источников данных, в результате чего в общей сложности получилось 3,2 миллиона образцов. Общее распределение данных одного изображения показано на рисунке 4 вместе с подробными сведениями о сборе данных и пошаговой презентацией, а также в Приложении E.1.
Данные OneVision. В дополнение к этапу обучения с одним изображением авторы дополнительно настраивают модель, используя смесь данных видео, изображений и нескольких изображений. Авторы представили в общей сложности 1,6 миллиона выборок смешанных данных, включая более 5,6 миллиона данных изображений из [68], 3,5 миллиона видеоданных, собранных в рамках этого проекта, и 8 миллионов отдельных образцов изображений. Стоит отметить, что на этом этапе авторы не вводили новые данные одного изображения, а отбирали высококачественные и сбалансированные части из предыдущих данных одного изображения, таких как Как указано в [68]. Распределение данных и дополнительная информация представлены в Приложении E.2.
5 Training Strategies
Чтобы LLM могла выполнять мультимодальные функции, авторы определили три ключевые функции и систематически разделили их на три различных этапа обучения для исследований абляции. Как и большинство существующих исследований, предыдущие модели LLaVA в основном исследовали настройку инструкций с одним изображением. Однако другим частям уделяется меньше внимания, поэтому этому будет уделено основное внимание в этом разделе.
Авторы проводят модельное обучение по принципу учебного плана, где поэтапно рассматриваются цели обучения и примеры возрастающей сложности. Учитывая фиксированный вычислительный бюджет, эта стратегия помогает разбить процесс обучения на этапы и оперативно создавать предварительно обученные веса, которые можно использовать для дальнейших экспериментальных проб и ошибок.
- _Этап 1: Выравнивание языка и изображения_: Цель состоит в том, чтобы полностью привести визуальные особенности в соответствие с векторным пространством слов LLM.
- _Фаза 1 с половиной: Качественное обучение знаниям_: Нахождение баланса между эффективностью вычислений и внедрением новых знаний в LLM,Автор рекомендует учитывать качественные знания для обучения в LLM. Конфигурация обучения остается соответствующей методу, использованному на втором этапе.,чтобы обеспечить последовательность,и позволяет Модели легко интегрировать новую информацию. * _Этап 2: Настройка инструкций по зрению_: дать возможность LMM решать разнообразный набор задач по зрению.,Автор организовал данные руководства по различным группам.,Эти группы описаны в разделе 4.2.2. Модель выполняет упражнения в каждом подходе по порядку.
В частности, процесс настройки визуальных инструкций можно разделить на два этапа: _Обучение с одним изображением_: модель сначала обучается на 3,2 миллионах инструкций с одним изображением, поэтому она имеет высокую производительность в сценарии с одним изображением в соответствии с различными инструкциями для выполнения визуальных задач. . _Визуальное обучение_: Затем модель обучается на наборе видео, отдельных изображениях и смеси данных из нескольких изображений. На этом этапе модель расширяет свои возможности от сценариев с одним изображением до разнообразных сценариев. Он учится выполнять задачи в соответствии с инструкциями в каждом новом сценарии и распространяет полученные знания между сценариями, что приводит к появлению новых возможностей. Обратите внимание, что на этапе после обучения обучение OneVision в рамках предложения, вероятно, является самым простым и экономичным способом позволить LLM достичь возможностей понимания нескольких изображений и видео.
Краткое описание стратегий обучения представлено в Таблице 1. Авторы постепенно обучают модель обработке длинных последовательностей. В процессе обучения максимальное разрешение изображения и количество визуальных токенов будут постепенно увеличиваться. На первом этапе базовое изображение представляется как изображение с 729 токенами. На втором и третьем этапах с использованием AnyRes имеется до 5x и 10x визуальных токенов соответственно. Что касается обучаемого модуля, то первый этап обновляет только проектор, а остальные этапы обновляют всю модель. Стоит отметить, что скорость обучения визуального кодировщика в 5 раз меньше, чем у LLM.
6 Experimental Results
Авторы используют LMMs-Eval [160] для выполнения стандартизированной и воспроизводимой оценки модели LLaVA-OneVision во всех тестах. Чтобы провести справедливое сравнение с ведущими LMM, авторы в основном сообщают результаты в оригинальной статье. Когда результатов не было, авторы загружали модель в LMMs-Eval и оценивали ее с использованием согласованных настроек. Если не указано иное, все результаты автора сообщаются с использованием жадного декодирования и настроек «0 кадров».
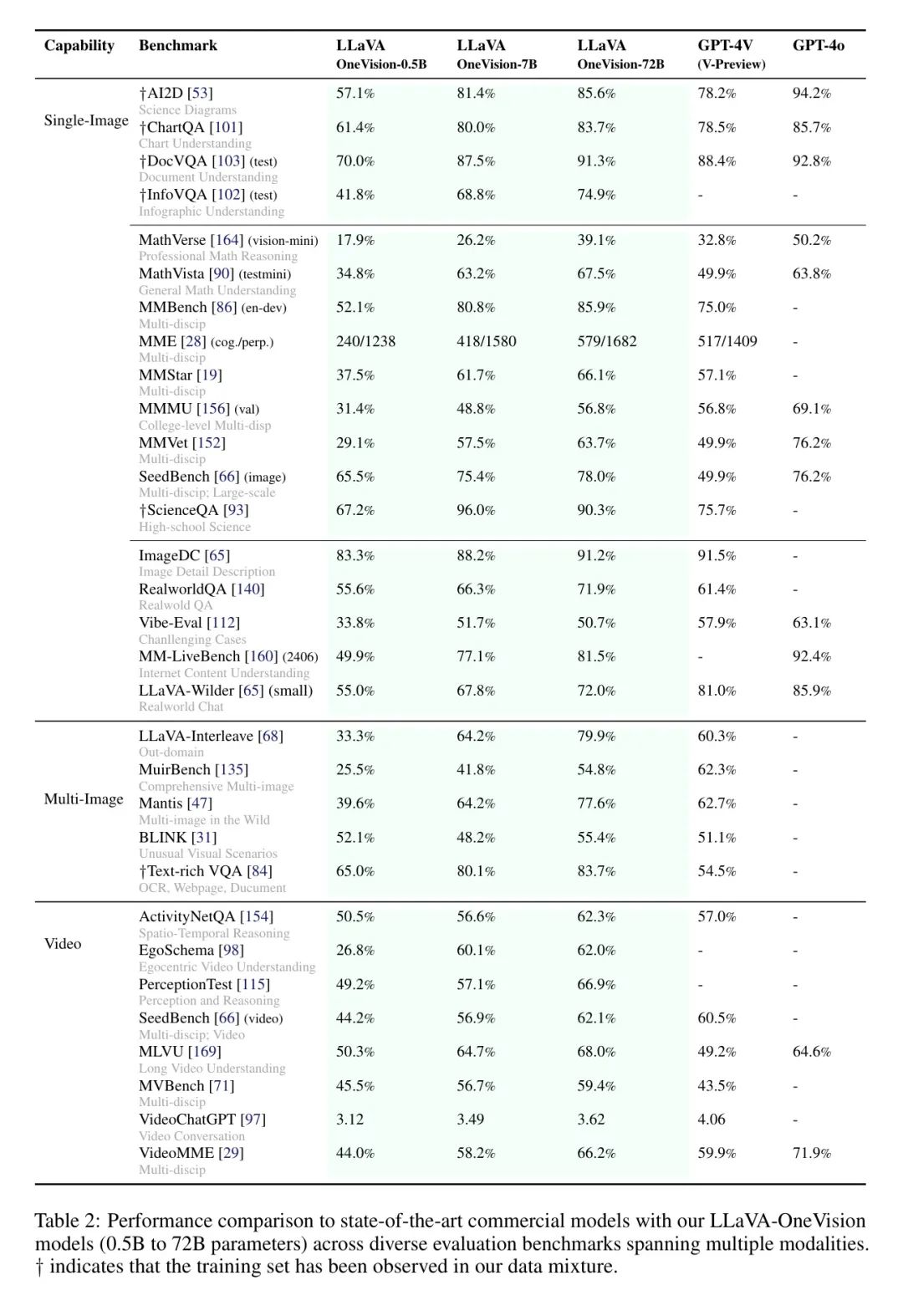
Чтобы продемонстрировать общность и эффективность разработанной парадигмы, авторы проводят комплексную оценку модели LLaVA-OneVision в различных модальностях (включая тесты с одним изображением, несколькими изображениями и видео) в таблице 2. В Таблице 3, Таблице 4 и Таблице 5 показаны подробные результаты каждого метода соответственно. Автор использует _LLaVA-OV (SI)_ или _LLaVA-OV_ представляет предварительно обученные веса Модели после обучения на этапе одного изображения и этапе OneVision. Доступны три размера модели (0,5B, 7B и 72B) для размещения приложений конечного устройства в облачных службах с различной производительностью и пропускной способностью транзакций. Результат GPT-4V и GPT-4o как ссылка. Самая большая авторская модельLLaVA-OneVision-72B превосходит GPT-4V и GPT-4o по большинству тестов. Это показывает proposed recipe По сути, предоставляя многообещающий путь для дальнейшего масштабирования. Однако в сложных задачах, таких как сцены визуальных диалогов, все еще существует относительно большой пробел, который авторы оставляют для будущих исследований более мощного LLM, большего объема обучающих данных и лучшего обучения предпочтениям.
Single-Image Benchmarks
Чтобы проверить производительность задачи с одним изображением в реальных сценариях, авторы рассмотрели комплексную серию тестов изображений в Таблице 3. Он разделен на три категории:
(1) Понимание диаграмм, изображений и документов. В качестве визуального доминирующего формата для структурированных данных OCR авторы оценивают результаты в тестах AI2D [54], ChartQA [101], DocVQA [103] и InfVQA [102]. Хотя текущие модели с открытым исходным кодом, такие как InternVL [22] и Cambrian [133], имеют производительность, сравнимую с коммерческими моделями, LaVAVeOneVision превосходит GPT-4V [109] и постепенно приближается к уровню производительности GPT-4o [110].
(2) Восприятие и междисциплинарное мышление. Включив сценарии визуального восприятия, авторы раскрывают потенциал модели для решения более сложных и сложных задач рассуждения. В частности, авторы используют тесты восприятия, включая MME [150], MMBench [86] и MMVet [153], а также тесты вывода, включая MathVerse [164], MathVista [90] и тест MMMU [156]. LLAVA-OneVision значительно превосходит GPT-4V в различных тестах и находится на одном уровне с GPT-4o в MathVista. Это еще раз подтверждает превосходство авторов в задачах зрительного восприятия и рассуждения.
(3) Понимание реального мира и визуальный ответ на вопросы. Авторы считают общую оценку LLM в полевых условиях наиболее важным показателем, выходящим за рамки лабораторных условий. Для проверки возможностей модели в реальных сценариях авторы использовали несколько широко распространенных тестов, включая RealworldQA [140], Vibe-Eval [111], MM-LiveBench [160] и LLAVA-Bench-Wilder [65]. Хотя модель авторов имеет возможности для улучшения по сравнению с GPT-4V и GPT-4o, она обеспечивает конкурентоспособную производительность по сравнению с моделями с открытым исходным кодом с аналогичными размерами параметров. Примечательно, что модель авторов хорошо показала себя на MM-LiveBench [160], тесте реального интернет-контента в реальном времени, демонстрируя обширные знания модели и сильные возможности обобщения.
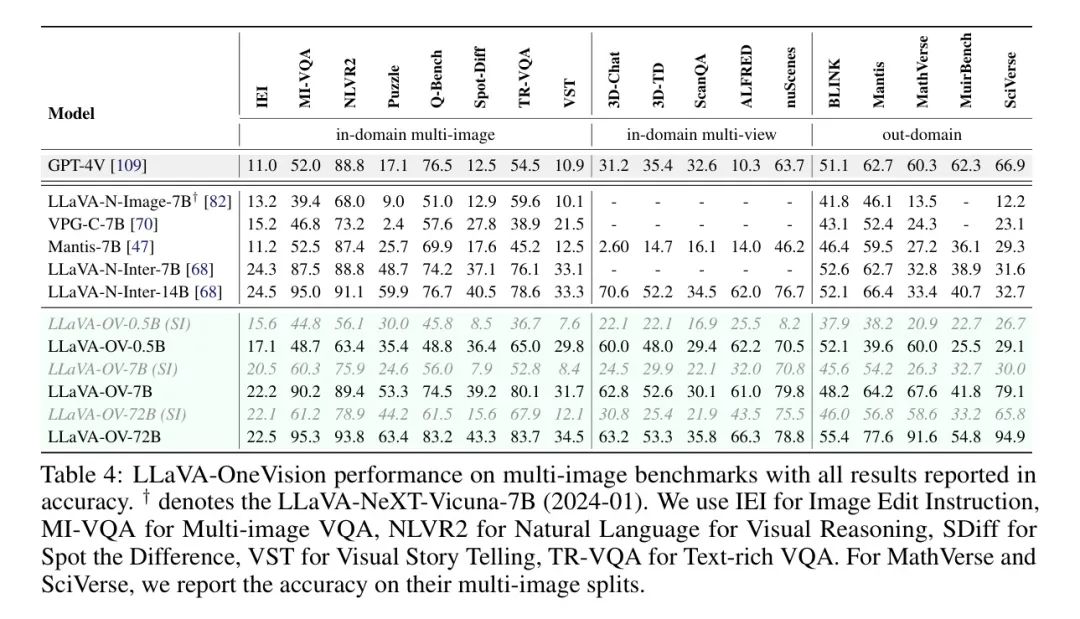
Multi-Image Benchmarks
Авторы далее оценивают LLaVA-OneVision в режиме чередования нескольких изображений, когда пользователи могут задавать вопросы по нескольким изображениям. В частности, автор проводит комплексную оценку разнообразных подзадач LLaVA-Interleave Bench [68], таких как «Найди отличия» [45], «Инструкция по редактированию изображения» (IEI) [68], «Визуальные истории лекций» (Visual Storytelling (VST)). [40]), визуальный ответ на вопрос с насыщенным текстом (Text-rich VQA (TR-VQA) [85]), визуальный ответ на вопрос с несколькими изображениями (Multi-image VQA (MI-VQA) [117]), Raven Puzzle [24], Q-Bench (QB) [138] и NLVR2 [125]. Авторы также используют для оценки несколько тестов с несколькими представлениями, которые представляют 3D-среды с несколькими точками зрения, включая 3D-чат и декомпозицию задач (3D-TD) от 3D-LLM [38], ScanQA [5], ALFRED [122], и nuScenes VQA [9]. Авторы называют эти наборы данных внутридоменными оценками, поскольку они включают часть своих обучающих данных.
Кроме того, мы выполняем оценку различных задач, выходящих за пределы предметной области, что показывает способность нашего метода к обобщению. К ним относятся сегментация нескольких изображений математического теста качества MathVerse [164] и научного теста качества SciVerse [34], теста восприятия нескольких изображений BLINK [31], MMMU-(Multi-Image) [156], содержащего все мультиизображения. -image QA и MuirBench [135] решают 12 разнообразных задач с несколькими изображениями.
Как показано в таблице 4, LLaVA-OneVision (SI) значительно превосходит существующие многоизображительные LMM по всем тестам. После дальнейших настроек с использованием нескольких изображений и видеоданных LLaVA-OneVision продемонстрировал значительные улучшения в некоторых аспектах с очевидными преимуществами в конкретных областях по сравнению с GPT-4V. Это подчеркивает его высокую производительность в сложных задачах, таких как анализ нескольких изображений, выявление различий и понимание трехмерной среды. Кроме того, авторы наблюдают устойчивое улучшение производительности после фазы обучения с одним изображением, что более очевидно в тестах просмотра, в которых отсутствуют данные с одним изображением. Это демонстрирует важность авторской парадигмы единого изображения для наделения LMM комплексными визуальными возможностями.
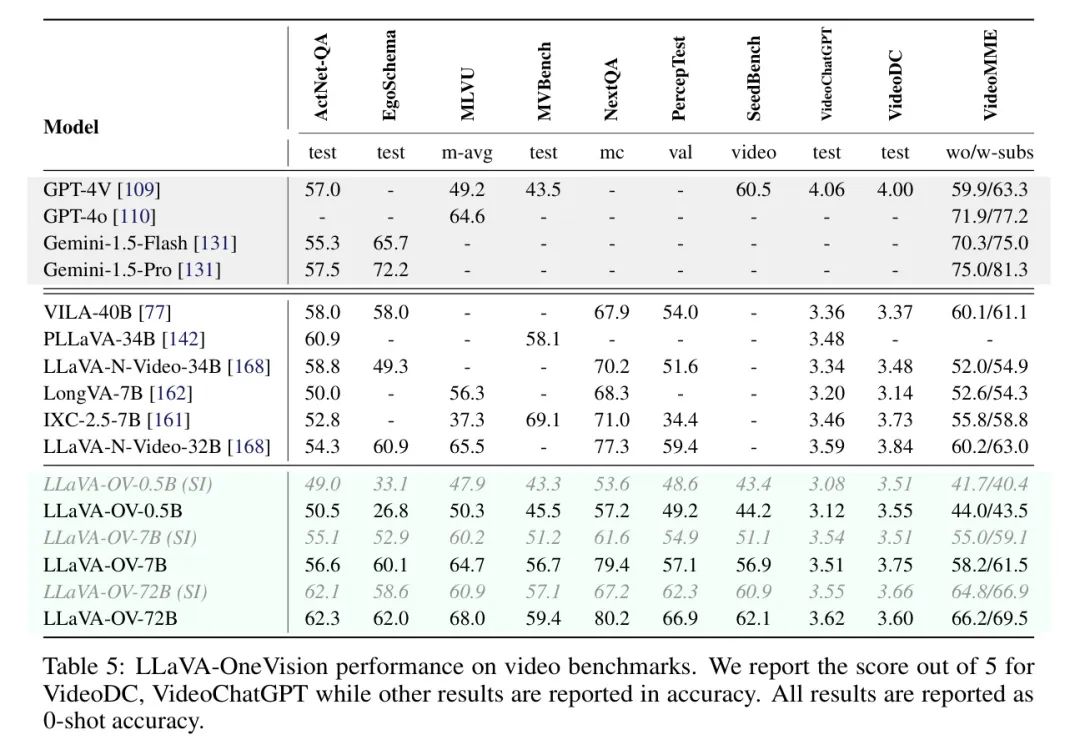
Video Benchmarks
Видео также является распространенным способом создания моделей мира, которые отражают динамическую природу реального мира, который динамически меняется с течением времени. Авторы провели эксперименты с несколькими тестами видео с открытым исходным кодом и множественным выбором. К ним относятся, среди прочего, система квантовых ответов на вопросы сети активности (ActivityNet-QA), которая содержит пары ответов на вопросы, связанные с действиями, из набора данных ActivityNet, EgoSchema, MLVU, которая фокусируется на понимании длинных видео, а также VideoMME [29] и NeXTQA [141] и другие. .
Как показано в таблице 5, LaVa-OneVision работает одинаково хорошо или лучше на гораздо более крупных LLM, чем предыдущие модели с большим языком. Преимущества LaVa-OneVision особенно очевидны в сложных тестах, таких как EgoSchema и VideoMME. Даже по сравнению с продвинутой коммерческой моделью GPT-4V он конкурентоспособен по тестам ActivityNet-QA, MLVU и VideoMME. Среди разделов LaVa-OV разница в производительности наименьшая в PerceptionTest с минимальным улучшением в 0,5 процентных пункта при масштабировании LLM с 0,5B до 7B. Это улучшение по сравнению с другими наборами данных как минимум на 5 процентных пунктов. Слабые успехи в PerceptionTest позволяют предположить, что перцептивные способности LaVa-OV могут в основном зависеть от его модуля зрения, что подтверждает недавние выводы таких исследователей, как Qiao et al. Стоит отметить, что для наборов данных, требующих сложного вывода (например, EgoSchema), больший LLM значительно повышает производительность.
Автор раскроет все общедоступные наборы данных, используемые автором. Эти изображения и данные были опубликованы для научных исследований; авторы включили их и преобразовали в форматы для использования в своих исследованиях. Однако некоторые авторские источники данных и пользовательские данные, а также данные, полученные с помощью сервиса Azure OpenAI, не могут быть опубликованы напрямую из-за политик компании. Авторы предоставят файлы YAML с точными данными для окончательного сценария многократного использования, а также предоставят многоразовые экспериментальные сценарии с использованием полностью общедоступных данных, журналов обучения и окончательных предварительно обученных весов.
ссылка
[1].LLaVA-OneVision: Easy Visual Task Transfer.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
