Было потеряно огромное количество данных в 240 триллионов, достаточное для обучения 18 GPT-4! 23 учреждения по всему миру объединяют усилия, чтобы обнародовать секреты уборки
Редактор: Редакционный отдел
【Шин Джиген Введение】Пришло время поставитьданныеScale Вниз! Лама 3 раскрывает этот ужасный факт: увеличение объема данных с 2Т до 15Т может творить чудеса, поэтому, если вы хотите перейти с GPT-3 на GPT-4, модели следующего поколения потребуется как минимум 150Т данных. К счастью, недавно команда удалила данные 240T из CommonCrawl — теперь недостатка в данных нет, но есть ли у вас карта?
Пришло время уменьшить данные!
Сегодня эта проблема актуальна.
Цинь Юйцзя, врач из Университета Цинхуа, заявил, что Llama 3 раскрывает суровую и пессимистическую реальность: без изменения архитектуры модели, если объем данных увеличить с 2 триллионов (2T) до 15 триллионов (15T), можно добиться чудес .

Это означает, что в долгосрочной перспективе возможности развития базовой модели могут принадлежать только крупным компаниям.
Учитывая предельный эффект закона Скальнга, если мы хотим увидеть эволюцию от уровня GPT-3 до уровня GPT-4 в модели следующего поколения, нам необходимо очистить как минимум на 10 порядков больше данных (например, 150T).
Совсем недавно пришла хорошая новость!
Команда DCLM очистила 240Т данных из CommonCrawl.

Адрес статьи: https://arxiv.org/abs/2406.11794.
Очевидно, это приносит хорошие новости сторонникам Закона о масштабировании — недостатка в данных нет, однако есть ли у вас карта?
Эра пост-масштабного закона: не увеличивайте масштабы, а стремитесь к уменьшению
Да, увеличение размера данных важно, но не менее важно и то, как его уменьшить и улучшить качество каждой единицы данных.
Интеллектуальность модели достигается за счет сжатия данных; в свою очередь, модель также переопределяет способ организации данных.
Цинь Юйцзя резюмировал содержание следующих документов и дал очень полное и общее резюме.

Адрес статьи: https://arxiv.org/abs/2405.20541

Адрес статьи: https://arxiv.org/abs/2406.14491.

Адрес проекта: https://azure.microsoft.com/en-us/products/phi-3.
DeepSeekMath::https://arxiv.org/abs/2402.03300
DeepSeek-Coder-V2:https://arxiv.org/abs/2406.11931
Во-первых, самый простой способ — использовать модель для фильтрации зашумленных данных:
(1) PbP использует сложность небольших моделей для фильтрации данных, тем самым получая данные, которые могут значительно улучшить производительность и скорость сходимости больших моделей;
(2) DeepSeek использует fastText для очистки высококачественных данных и достигает отличных результатов в сценариях математики и кодирования;
(3) DCLM провела более детальное исследование абляции и обнаружила, что fastText работает лучше по сравнению с внедрением BGE, недоумением и т. д.
Все без исключения исследования имеют схожие результаты: «чистые данные + маленькая модель» могут значительно приблизиться к эффекту «грязные данные + большая модель».
с этой точки зрения,Увеличить масштаб модели,По сути, это позволяет нам увидеть верхний предел возможностей Модели по «грязным» данным.
То есть,Большая модель автоматизирует процесс шумоподавления, используя больше избыточных параметров во время тренироваться.,Но если вы заранее выполните шумоподавление данных,На самом деле количество требуемых параметров невелико.
Тот же вывод можно сделать,Хорошо отшлифована большая модель с точной настройкой данных.,Это не значит, что эффект от тренироваться Модель будет лучше.
Причина в том, что не будет большой разницы между эффектами «чистые данные + большая модель» и «грязные данные + большая модель».
В целом, в эпоху до появления Закона о масштабировании мы делали упор на масштабирование вверх, то есть стремление к верхнему пределу интеллекта модели после сжатия данных, в эпоху после принятия Закона о масштабировании необходимо конкурировать с масштабированием вниз, то есть с уменьшением масштаба; заключается в том, кто может обучить более «рентабельной» модели.
Текущий основной метод сокращения данных — это шумоподавление данных на основе модели.
недавно,Есть также некоторые исследования, которые начали использовать обученную Модель, чтобы переписать предварительнотренированные модели. Этот процесс требует внимания,Избегайте создания модели ложной информации во время процесса переписывания.,В то же время необходимо эффективно устранять присущий данным данные шум.
Успех Фи-2/Фи-3 также подтвердил это: если претренированный уровень может быть обработан машинами, то очень легко победить большую Модель с помощью маленькой.
Однако текущие методы по-прежнему направлены на улучшение качества одной точки данных, но в будущем более важным направлением исследований станет дедупликация и объединение нескольких точек данных на семантическом уровне.
Это сложно, но сокращение масштабов очень много значит.
Давайте взглянем на эту статью от команды DCLM.
Тест DataComp-LM (DCLM)
Для того, чтобы справиться с различными задачами, тренированные,Исследователи представляют DataComp-LM (DCLM),Это «первый ориентир» в управлении языком.

Портал: https://www.datacomp.ai/dclm/
В ДЦЛМ,Предложили совершенно новый набор тренироваться и алгоритм управления данными.,Затем, используя фиксированный метод,тренироваться Модельк Оцениватьданныенабор。
Измеряя эффективность полученной Модели при выполнении последующих задач, исследователи могут количественно оценить сильные и слабые стороны соответствующего набора тренироваться.
Затем, чтобы реализовать DCLM, исследователи разработали комплексную экспериментальную испытательную платформу, включающую несколько важных компонентов.
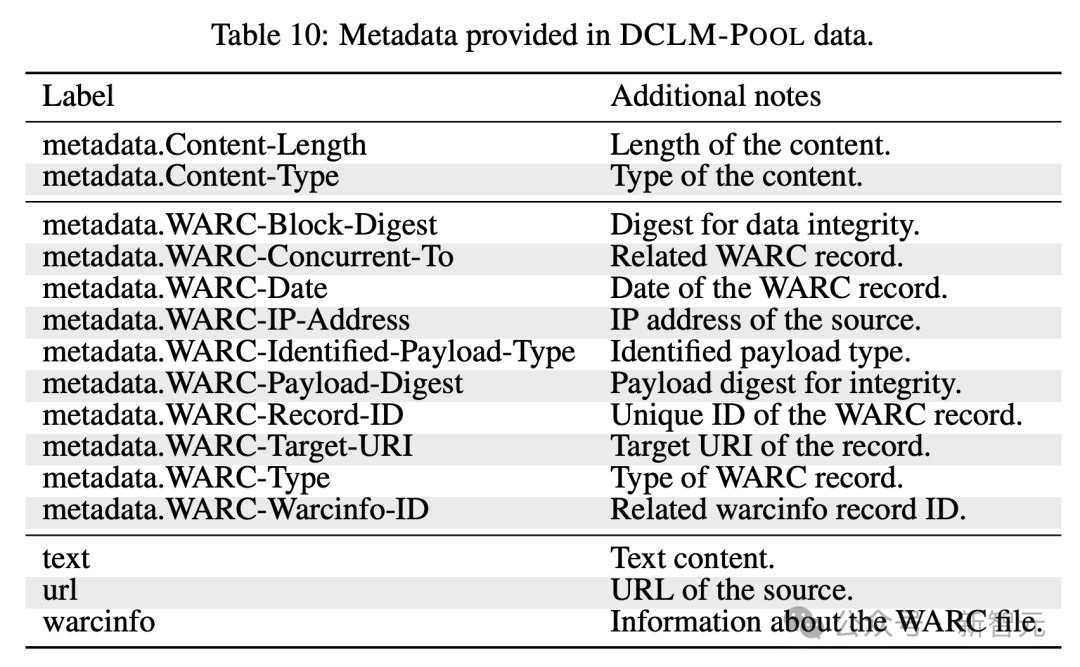
Одним из ключевых компонентов является крупнейший языковой корпус Модельтренироваться DCLM-POOL.
Это набор данных размером 240T, полученный с нефильтрованного краулера Common Crawl и охватывающий все данные до 2023 года.
В частности, DCLM-POOL содержит 200 миллиардов документов (370 ТБ после сжатия gzip), в результате чего получается 240 триллионов токенов GPT-NeoX.
По имеющимся данным, для получения такого огромного количества данных текст повторно извлекается из HTML с помощью архитектуры resiliparse, которая отличается от исходного метода предварительной обработки Common Crawl.
также,Когда обучать язык AI Модель,Иногда данные, используемые для тест Модель, случайно смешиваются с тренированными. Это похоже на то, как студент магистратуры просматривает контрольную работу перед экзаменом.,Это может привести к неточным результатам.
Однако влияние этих образцов на производительность последующей обработки остается во многом неясным для исследователей отрасли.
Чтобы люди могли лучше понять эту проблему, исследователи не стали очищать данные, а выпустили инструмент «обеззараживания данных».
этот инструмент,Позволяет участникам проверять свои собственные тестовые наборы и обучать наборы.,Есть ли какое-либо совпадение?,и представить соответствующие отчеты.
Для тех моделей ИИ, которые работают лучше всего, исследователи специально проверяют, не «обманывают ли они».
такой же,Исследователи статьи также использовали этот инструмент,Применяется в DCLM-POOL,Оценивать данные о том, влияет ли загрязнение на Модель.
LLM с различными параметрами может быть PKed
Чтобы обеспечить доступность DCLM для исследователей с различными вычислительными ресурсами и способствовать исследованию тенденций закона масштабирования, исследователи создали различные уровни конкуренции, охватывающие три порядка масштаба вычислений (таблица 1).
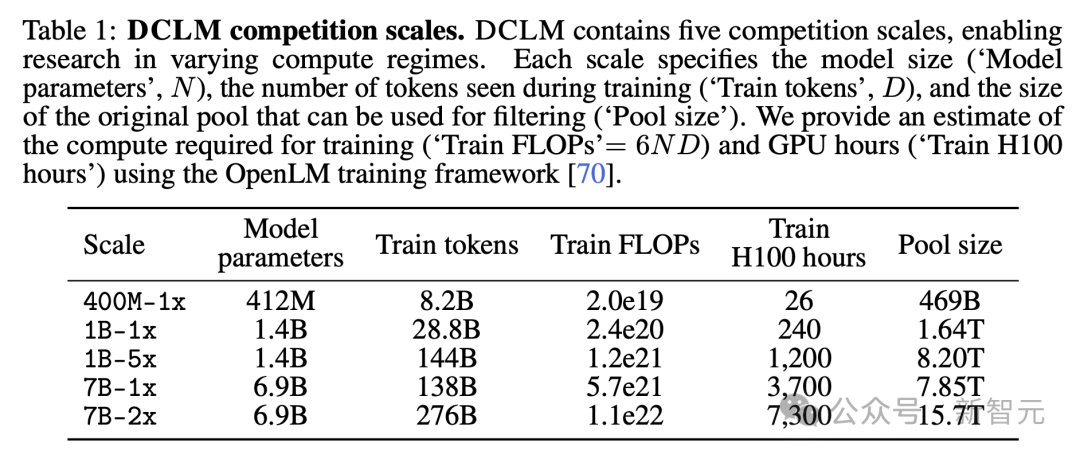
Каждый уровень (т. е. 400M-1x, 1B-1x, 1B-5x, 7B-1x и 7B-2x) определяет количество параметров модели и множитель Шиншиллы.
Например, в 7B-1x 7B означает, что модель имеет 7 миллиардов параметров, а 1x — это множитель Шиншиллы.
Количество токенов тренироваться за уровень = 20 × количество параметров × множитель Шиншиллы. Среди них распределение вычислительных ресурсов, соответствующее множителю 1x, близко к оптимальному уровню, обнаруженному в исследовании Hoffmann et al.
Существует проблема с организацией такого многопараметрического масштабного соревнования - при увеличении масштаба вычислений может измениться ранжирование методов сортировки данных.
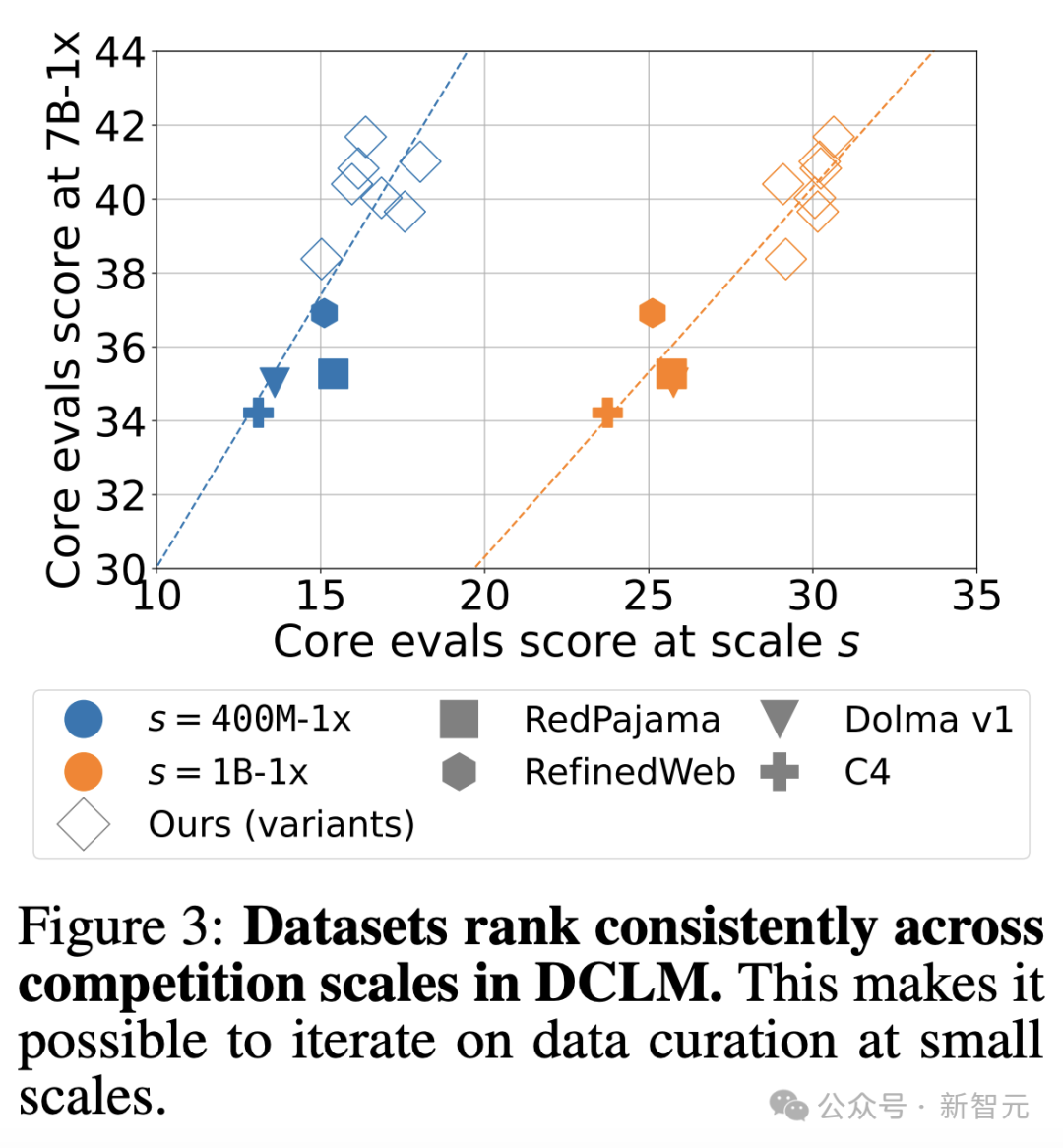
Исходя из этого, исследователи сравнили эффективность 10 методов при разных масштабах параметров (400M-1x, 1B-1x и 7B-1x).
Было обнаружено, что существует высокая корреляция между результатами для малых параметров (400M-1x, 1B-1x) и больших параметров (7B-1x).
Два главных трека
После того, как участники выберут шкалу параметров, они выбирают один из двух эталонных треков: фильтрацию и смешивание.
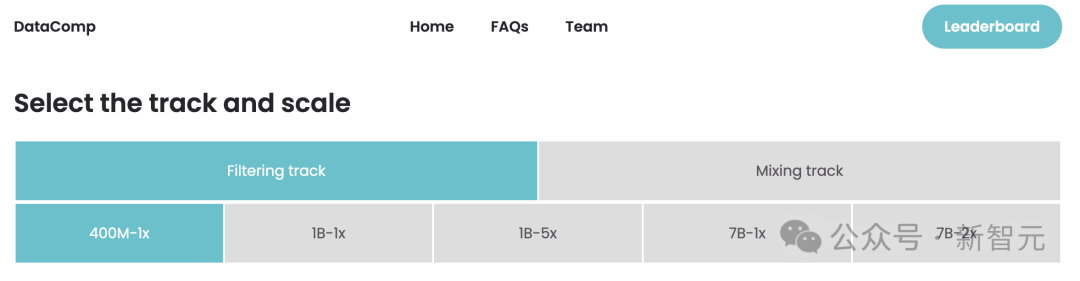
1) В фильтр-дорожке,Участники предложили алгоритмы отбора тренированных из резерва кандидатов. Существует пять пулов данных разного размера.,Соответствующие (табл. 1) различные масштабы расчета,Эти пулы представляют собой случайные подмножества документов DCLM-POOL. Исследователи ограничивают размер первоначального пула в зависимости от масштаба параметров.,для моделирования ограничений реального мира.
2) В гибридном треке участникам разрешено свободно комбинировать данные из нескольких источников для создания лучшего «рецепта». Например, они могут синтезировать документы данных из DCLM-POOL, пользовательских данных, переполнения стека и Википедии.
тренироваться
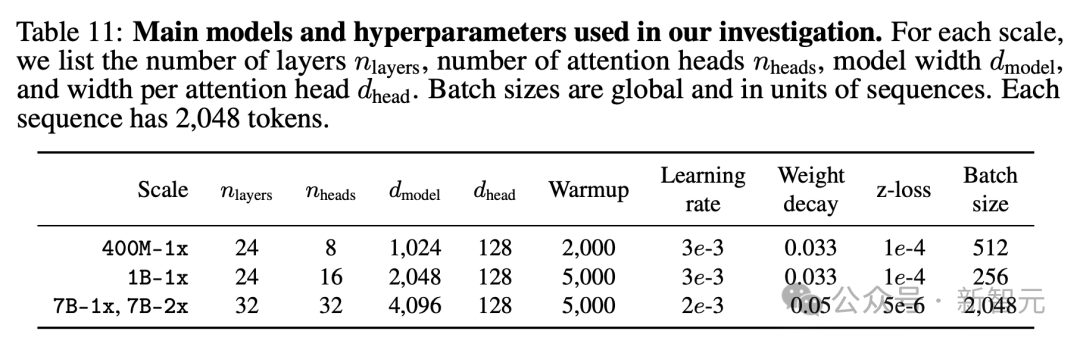
Чтобы изучить эффект вмешательства набора данных индивидуально, исследователи также зафиксировали сценарий тренироваться для каждой шкалы параметров.
На основе предыдущих экспериментов по удалению модели архитектуры и тренироваться.,Они приняли модель TransformerModel, предназначенную только для декодера (например.,GPT-2,Llama),Модель реализована в OpenLM.
Гиперпараметры модели подробно описаны в таблице ниже.
Оценивать
Полный изученный пакет «Оценивать» основан на LLM-Foundry и содержит 53 последующих задачи, подходящих для базовой «Модели Оценивать» (т. е. не требует тонкой настройки).
От вопросов и ответов до открытых генеративных форматов, рассматриваются различные области, включая программирование, знание учебников и рассуждения, основанные на здравом смысле.
В алгоритме Оцениваемой сортировки основное внимание уделяется трем показателям производительности:
1. Точность MMLU на 5 выстрелов
2. Точность центра CORE
3. ПОВЫШЕННАЯ точность центра
Создавайте высококачественные наборы данных с помощью DCLM
Следующий,Давайте посмотрим, как исследователи используют DCLM для построения качественных тренированданных наборов.,Весь процесс показан на рисунке 4 ниже.

Во-первых, исследователи оценили несколько известных наборов данных в Таблице 2 и обнаружили, что RefinedWeb показал лучшие результаты по основным и дополнительным метрикам по шкале 7B-1x.
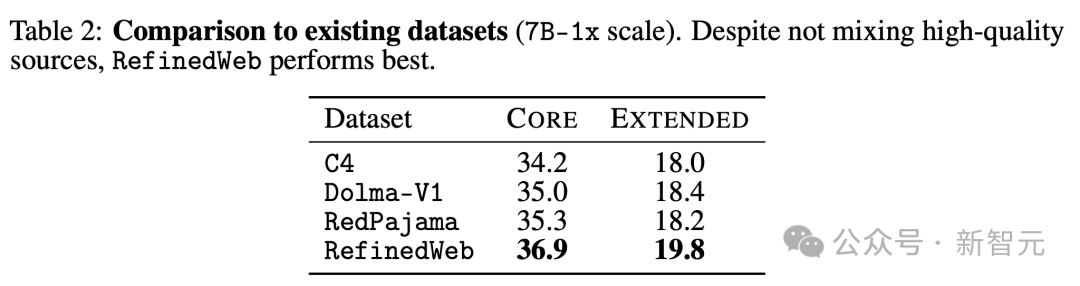
Интересно, что RefinedWeb полностью отфильтровывает данные Common Crawl.
RefinedWeb использует следующий конвейер фильтрации: Общий Crawlизвлечение текста、Эвристический выбор данных、повторитьданныесодержаниеудалить.

извлечение текста
извлечение текста — это обычный этап ранней обработки, используемый для извлечения контента из необработанного HTML.
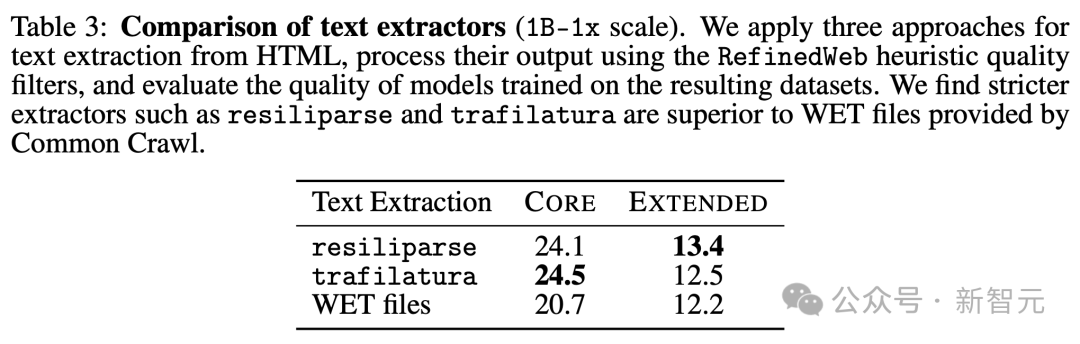
Чтобы понять влияние этого шага, исследователи сравнили три типа текстовые методы: resiliparse, trafilatura (используется RefinedWeb) и Common. WET-файлы, предоставленные Crawl, содержащие предварительно извлеченный текст.
Тогда для каждого извлечения текст РЕЗУЛЬТАТЫ Применение эвристики RefinedWeb Качественная фильтрацияустройство。

В Таблице 3 исследователи обнаружили, что и резилипарс, и трафилатура улучшают показатели CORE как минимум на 2,5 по сравнению с экстракцией WET.
Это важно, поскольку большинство наборов данных с открытым исходным кодом, включая C4, RedPajama и Dolma-V1, используют извлечение WET, что может частично объяснить их низкую производительность в Таблице 2.
Хотя resiliparse и trafilatura схожи по производительности последующих задач, resiliparse работает в 8 раз быстрее и поэтому лучше подходит для крупномасштабной обработки.
Поэтому, как упоминалось выше, исследователи в конце концов решили принять стратегию резилипарса.
Дедупликация данных
Наборы данных веб-сканера обычно содержат множество повторяющихся или почти повторяющихся строк данных.
Удаление этих дубликатов из набора тренироваться преследует двойную цель.,Можно уменьшить объем памяти LLM для повышения производительности.,Это также может увеличить разнообразие данных.
Для дедупликации исследователи использовали алгоритм MinHash (как часть конвейера массива суффиксов) и почти повторяющийся фильтр Блума (модифицированная схема точной дедупликации документов и абзацев).
Было обнаружено, что оба метода одинаково хорошо работают в нисходящем направлении.
По шкале параметров 7B-2x разница находится в пределах 0,2 процентных пункта CORE. Однако модифицированный фильтр Блума легче масштабируется до наборов данных объемом 10 ТБ.

Качественная фильтрация
В литературе показано,Используйте обучаемую модель в качестве качественной фильтрации.,Может привести к дальнейшим улучшениям.
Исследователи сравнили несколько методов фильтрации на основе моделей:
1. Используйте показатели PageRank для фильтрации и сохранения документов на основе вероятности их ссылок на другие документы;
2. Семантическая дедупликация (SemDedup), удаляющая документы со схожим информационным содержанием;
3. Линейный классификатор, основанный на предварительно тренированном встраивании текста BGE;
4. AskLLM, который предлагает большую языковую модель, чтобы проверить, полезен ли документ;
5. Фильтрация недоумений. Следуйте CCNet, чтобы сохранить последовательности с низким уровнем недоумения.
6. Средний логарифм Top-k: усредняет логарифмы модели top-k всех слов в документе, чтобы оценить, насколько уверенно модель показывает правильные слова в пределах k разумных диапазонов выбора;
7. Бинарный классификатор fastText, используемый для определения качества данных.
Сравнив различные методы, представленные в Таблице 4, исследователи обнаружили, что фильтрация на основе fastText превосходит все другие методы.
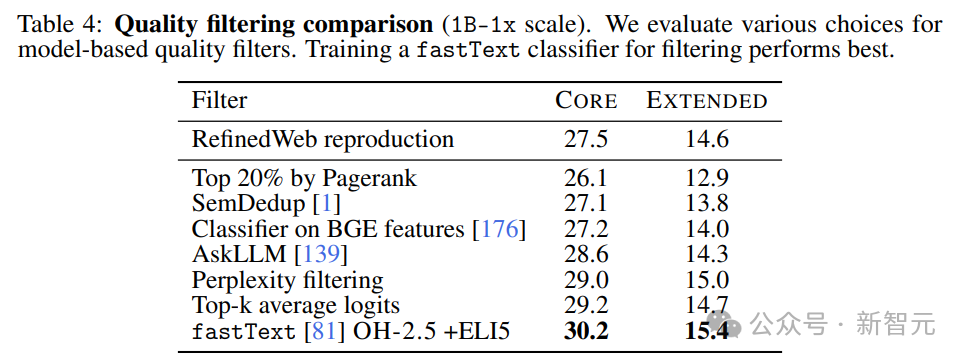
Чтобы лучше понять ограничение fastText,Исследователи тренироваться предложили несколько вариантов,Изучите различные варианты справочных данных, пространств признаков и порогов фильтрации.,Как показано в Таблице 5.
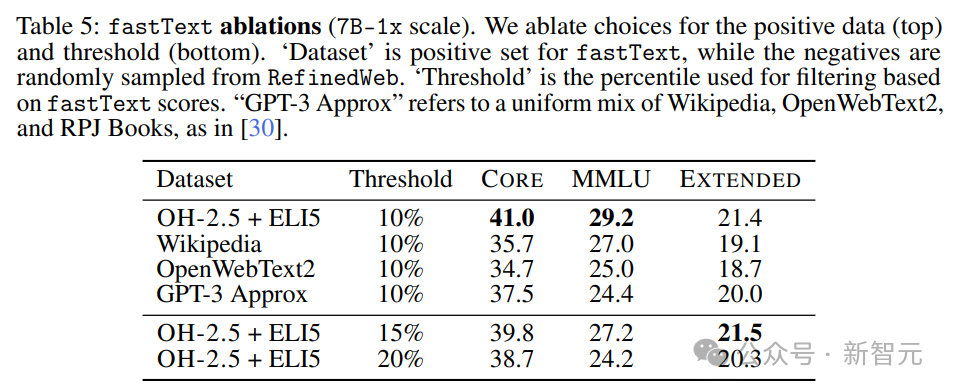
Исследователи обнаружили, что при контроле других гиперпараметров метод fastText OH-2.5+ELI5 улучшил CORE на 3,5 процентных пункта по сравнению с традиционными вариантами.
Итак, будет ли использование данных OH-2.5 для фильтрации препятствовать получению дополнительных выгод от корректировки команд?
Исследователи обнаружили, что это не так.
смешивание данных
Обычной практикой в отрасли является объединение Common Crawl с другими источниками высококачественных данных, такими как Wikipedia, arXiv, Stack Exchange и peS2o.
Добавляйте высококачественные источники только в Common. Crawlизтренироватьсянабор,Каковы потенциальные преимущества??
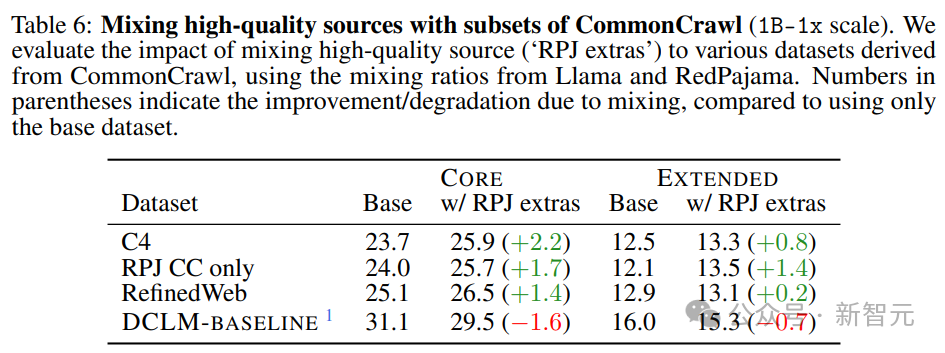
Исследователи сравнили Модель из 100% отфильтрованных данных CC с Моделью, использующей смешанное соотношение тренироваться Llama1 и Red Pajama.
Результаты в Таблице 6 показывают, что смешивание улучшает менее эффективное подмножество CC, однако в случае высокопроизводительной фильтрации смешивание может быть контрпродуктивным;
Очистка данных
впоследствии,Исследователи проанализировали,Проверить наличие предварительного загрязнения без Оценивать,Повлияет ли это на результаты? Они сосредоточены на MMLU.
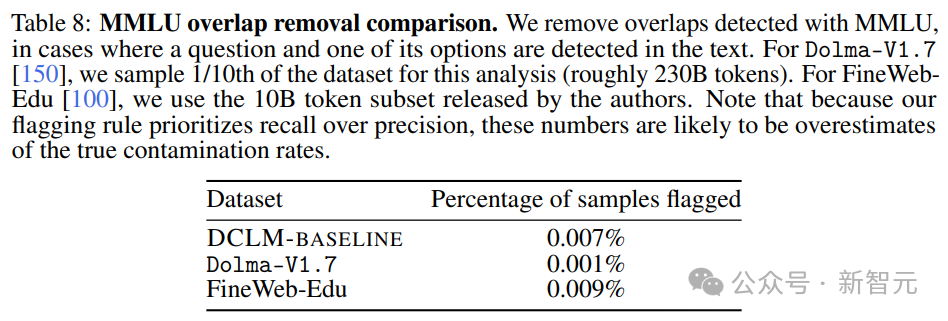
В качестве эксперимента исследователи также попытались обнаружить и устранить проблемы в MMLU, существовавшие в DCLM-BASELINE.
Результаты представлены в таблице 7 – удаление загрязненных образцов не приводит к снижению производительности модели.
Видно, что улучшение производительности MMLU не вызвано увеличением MMLU в наборе данных.

Применение описанных выше стратегий удаления к Dolma-V1.7 и FineWeb-Edu показывает, что статистика загрязнения DLCM-BASELINE примерно аналогична другим высокопроизводительным наборам данных.
Расширьте триллионы токенов
Наконец, исследователи протестировали производительность набора данных в тесте DCLM в более широком масштабе параметров (триллионы токенов).
с этой целью,Обеспечить широкую доступность модели тренирования.,Они также построили 4.1T. Набор данных токена объединяет 3,8T DCLM-BASELINE с данными StarCoder и ProofPile2, включая математические задачи и задачи по кодированию.
После получения набора данных,На его основе исследователи построили модель параметра 7B.,использовал2.5T токен и гиперпараметры того же размера, что и максимальные параметры соревнования.
в,Также была принята специальная стратегия тренироваться.,Состоит из двух ступеней охлаждения (при токене 200В и 270В) и «модельный суп» (модельный суп).
после,Исследователи использовали метод непрерывного претренирования.,Добавьте еще 100 млрд токенов в тот же дистрибутив.,Увеличена длина контекста с 2048 до 8192.
В таблице 9,Показывает, что новая Модель превосходит все 7BМодели тренироваться в публичном наборе тренироваться.,И близко к тренироватьсятокену с более закрытым исходным кодом Модель,Такие как «Лама-8Б», «Мистраль-7Б» и «Гемма-7Б».
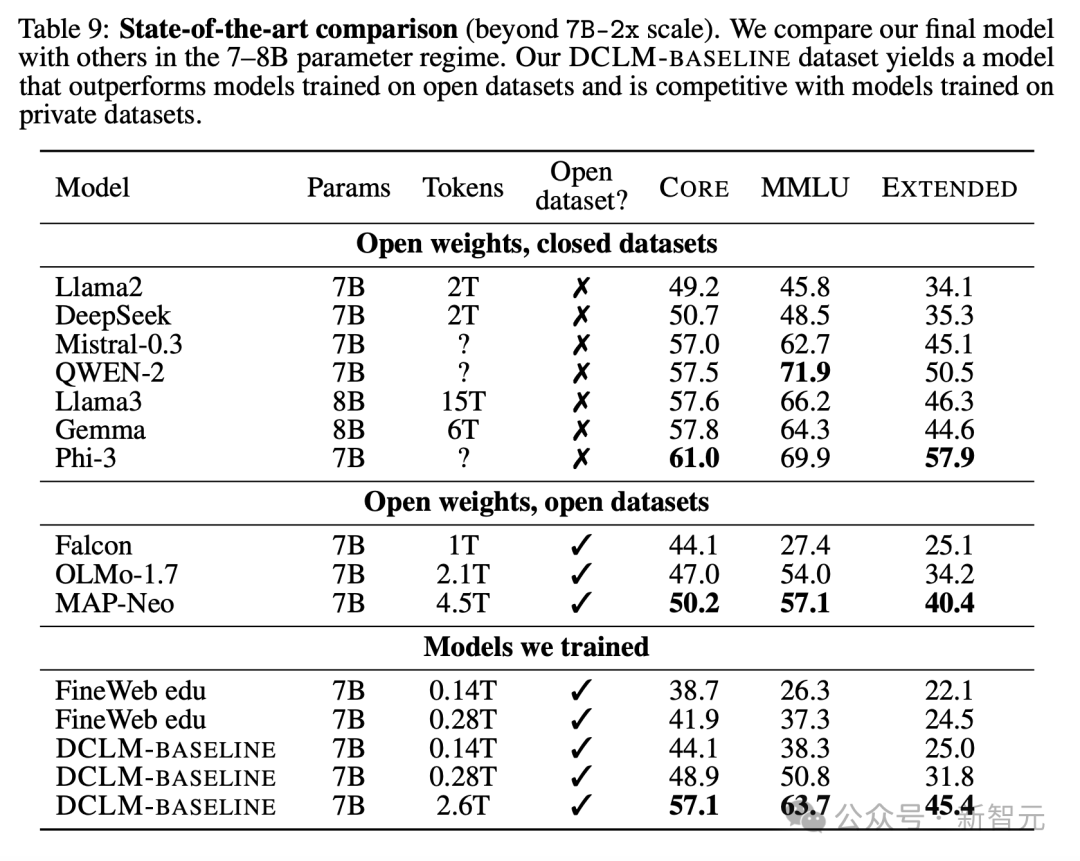
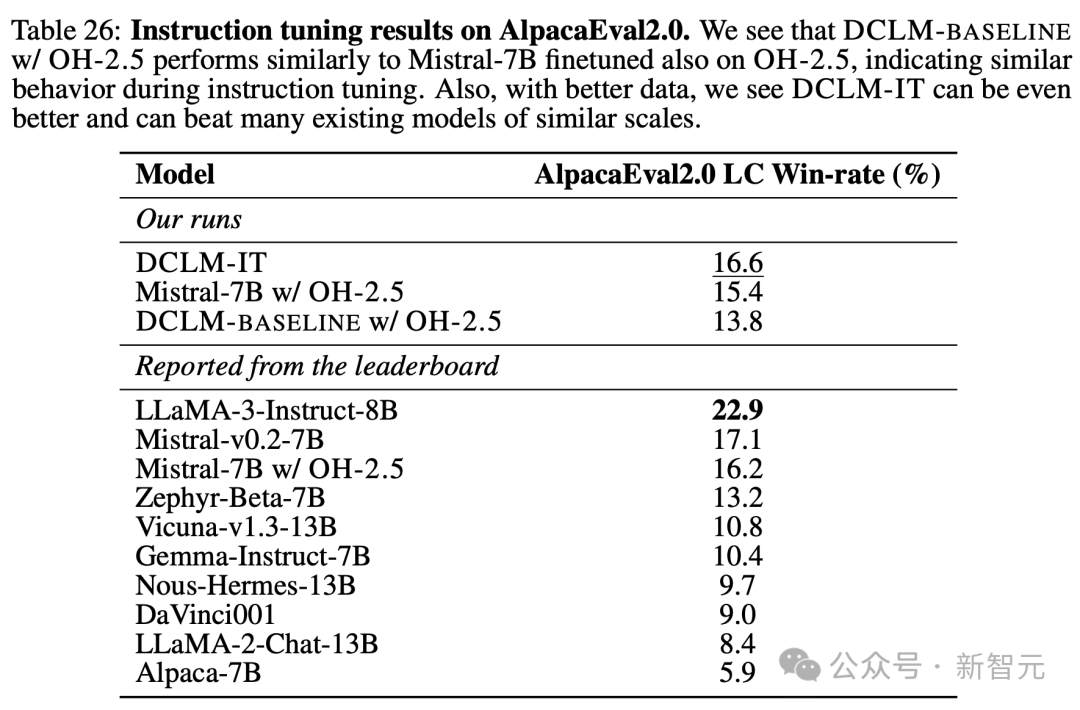
Кроме того, из таблицы 26 видно, что новая модель также демонстрирует высокие результаты при точной настройке инструкций.
После точной настройки инструкций на общедоступном наборе ИТ-данных модель исследователей сохранила большую часть базовой производительности и достигла показателя побед 16,6 в AlpacaEval2.0 LC, превзойдя Gemma-Instruct (10,4) и приблизившись к производительности Mistral-Strong на v0. .2-7B (17.1) и Лама3-Инструкт (22.9).
ограничение
Из-за ограничений вычислительных ресурсов исследователи могут удалять размеры конструкции только индивидуально и не могут протестировать все методы в более крупных масштабах параметров.
Кроме того, существует множество неисследованных вариантов DCLM-BASELINE.
Например,Важно более подробно понять влияние дедупликации шардинга.,И в фильтре тренироваться Модель,Будь то архитектура или тренированные,Есть много других способов.
В большинстве экспериментов в исследовании также использовался только один токенизатор (GPT-NeoX), а другие токенизаторы могут лучше работать в многоязычных задачах или в математических задачах.
Еще одним ограничением является то, что в статье невозможно полностью изучить различия между сериями, вызванные разными случайными начальными числами.
Хотя Модель 7B на DCLM-BASELINE конкурентоспособна по пониманию общеязыкового языка «Оценивать», их текущие показатели в коде и математике далеки от идеала.
Исследователи заявили, что на следующем этапе они продолжат проверять, можно ли расширить модель до более крупного масштаба параметров.
Ссылки:
https://arxiv.org/abs/2406.11794v3
https://x.com/TsingYoga/status/1804728355239199181



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
