Будут ли снижаться возможности мультимодальных больших моделей, если они станут сложными? Новое исследование: универсальное экспертное разрешение конфликтов МО+
Точная настройка может сделать общие большие модели более подходящими для конкретных отраслевых приложений.
Но теперь исследователи обнаружили:
При выполнении «тонкой настройки многозадачных инструкций» на большой мультимодальной модели большая модель может «учиться больше и делать больше ошибок», поскольку конфликты между различными задачами приводят к снижению способности к обобщению.
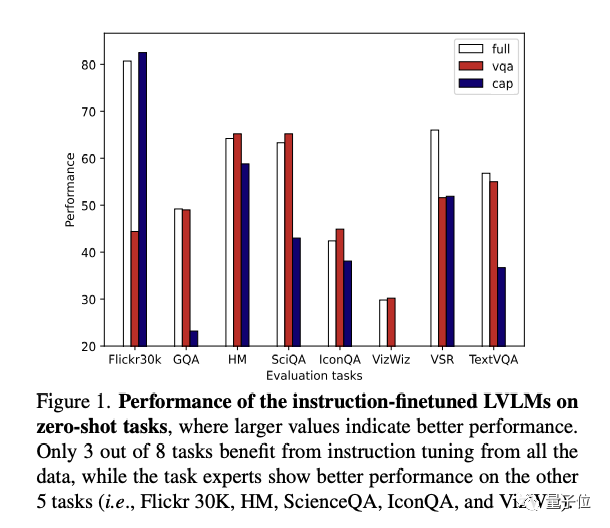
△Точная настройка мультимодальных инструкций приводит к конфликтам задач
Например, мультимодальная задача ответа на вопросы может потребовать, чтобы ответы были как можно более краткими и точными, в то время как задача понимания документа, в свою очередь, может потребовать как можно более подробного описания больших моделей.
Точная настройка распределения данных для различных инструкций последующих задач совершенно различна, что затрудняет достижение оптимальной производительности большой модели при выполнении нескольких последующих задач.
Как решить эту проблему?
Совместная исследовательская группа из Гонконгского университета науки и технологий, Южного университета науки и технологий и лаборатории Ноева ковчега Huawei, вдохновленная большой моделью Mixtral-8×7B с открытым исходным кодом MoE (Mixed Expert Model), предложила использовать разреженные экспертные модели. для повышения эффективности обобщения последующих задач. Лучшие и более понятные мультимодальные большие модели.

Давайте посмотрим на конкретные детали.
Точная настройка мультимодальных инструкций приводит к конфликтам задач
Чтобы проверить влияние различных типов данных задачи на производительность модели при точной настройке мультимодальных инструкций, исследователи разделили данные следующим образом:
- VQA (визуальный ответ на вопрос): VQAv2, OKVQA, A-OKVQA, OCRVQA,
- Субтитры (описание изображения): COCO Caption, Web CapFilt, TextCaps,
- Полный (все данные): VQA, субтитры, LLaVA-150k, VQG (визуальная генерация вопросов на основе данных VQA).
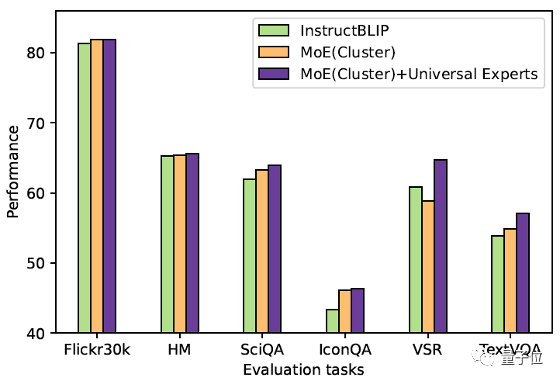
На основе приведенных выше данных исследователи использовали LoRA для тонкой настройки InstructBLIP, получили 3 экспертные модели и использовали их в других данных (описание изображения Flickr30k, GQA/SciQA/IconQA/TextVQA и другие различные типы визуальных вопросов и ответов, HM/VSR и другие задачи мультимодальной классификации или вывода) для нулевого тестирования и оценки.
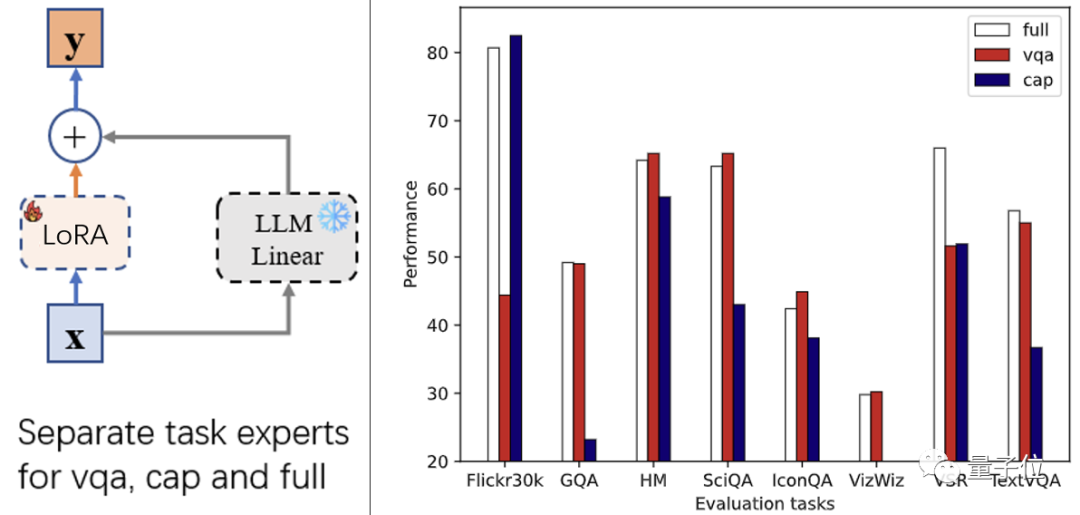
Как видно из рисунка выше (справа), при точной настройке инструкций не использование полных данных дает наилучшие результаты. Напротив, только три последующие задачи (GQA, VSR, TextVQA) работают лучше всего с экспертами по полным данным.
Это показывает,Для большинства задач,данные для внедрения других задач в процессе тонкой настройки инструкций,Наоборот, это уменьшит Модельпроизводительность,Точная настройка мультимодальных инструкций приводит к конфликтам задач。
С другой стороны, в эксперименте было замечено, что две экспертные модели, VQA и Captioning, показали лучшую производительность, чем все эксперты, в своих соответствующих задачах. Кажется, что этот метод решает проблему конфликтов задач, но имеет следующие ограничения:
- Знания, полученные в ходе различных учебных задач, не могут быть переданы экспертам по задачам;
- Данные обучения необходимо разделить искусственно, что сложно осуществить, когда существует множество типов данных обучения;
- Когда приходит новая задача, люди должны решить, какого эксперта по задачам использовать.
Чтобы решить вышеуказанные ограничения, исследовательская группа предложила использовать разреженную экспертную модель (MoE), в которой разные эксперты решают разные задачи, а метод разделения данных предназначен для передачи аналогичных задач одному и тому же эксперту.
Разреженная экспертная мультимодальная большая модель на основе кластеризации инструкций
Разделение данных с помощью кластеризации инструкций

В большой модели визуального языка (LVLM),Эта статья определяетКоманда для ввода всего текста,Как показано выше (слева), текст C1-C4.
Эти инструкции описывают цель и требования задачи. Поэтому автор использует Kmeans для группировки всех инструкций по 64 категориям.
Как показано на рисунке выше (справа),Информация о кластеризации инструкций может эффективно представлять тип задачи данных. Это экономит затраты на разделение данных вручную.。
Гибридная экспертная маршрутизация LoRA на основе информации о кластеризации инструкций
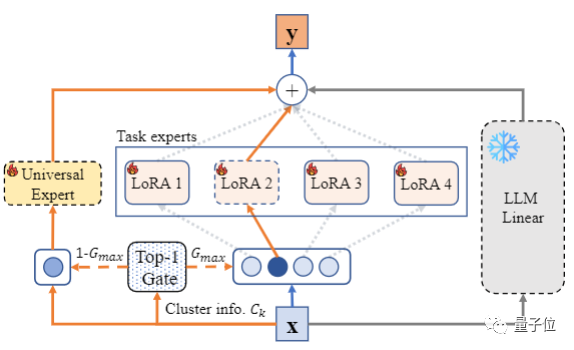
Подобно предыдущему эксперту задач, выходные данные модели на этом уровне также генерируются замороженным линейным слоем LLM и точно настроенным LoRA.
Разница в том, что информация о кластеризации данных используется для маршрутизации гибридного LoRA. В частности, для входных данных модели информация о ее маршрутизации может быть рассчитана следующим образом:
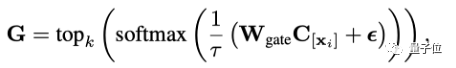
Среди них функция topk() (рассматривая случай k=1) сохраняет неизменными первые k крупнейших элементов и устанавливает остальные в 0. C — это встроенное представление обучаемой категории, а C[xi] представляет собой кластер инструкций, соответствующих до xi. Представление класса, Wgate — линейный параметр маршрута.
Эксперты общего профиля улучшают обобщение модели
Эксперименты показали, что вышеупомянутые эксперты LoRA по кластеризации инструкций действительно облегчают проблему конфликтов задач, но поскольку эксперт может видеть только часть задач, обобщение всей модели на последующие задачи сокращается.
поэтому,Исследовательская группа предложила использоватьглавный экспертот всехданные Обобщающая способность обучения инструкциям。
В отличие от MoE, в дополнение к эксперту задачи, выбранному через top1, этот метод также постоянно активирует общего эксперта, так что этот эксперт обучается на основе всех данных инструкций.
Таким образом, выходные данные модели на этом уровне представляют собой взвешенную сумму исходного замороженного параметра W LLM, эксперта задачи We и общего эксперта Wu.
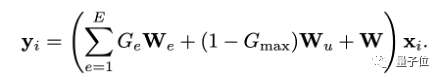
При такой конструкции сотрудничество между экспертами по задачам и экспертами общего профиля не только повышает производительность модели при выполнении задач, аналогичных обучающему набору, но также обеспечивает способность модели к обобщению для новых задач.
Результаты экспериментов
В этом документе рассматриваются экспериментальные сценарии InstructBLIP (использование данных, критерии оценки, детали обучения), выполняется точная настройка инструкций на 13 наборах обучающих данных (включая VQA, субтитры, VQG и т. д.) и оценивается 11 наборов тестовых данных (обучающие данные). set Нет перекрытия с набором тестовых данных).
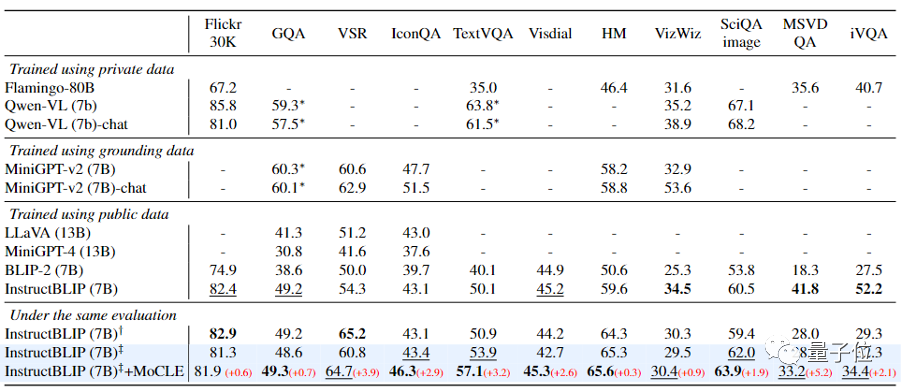
Как показано в таблице выше, после внедрения метода (MoCLE), предложенного в этой статье, InstructBLIP улучшил все последующие задачи по сравнению с базовой моделью. Среди них особенно очевидно улучшение в VSR, IconQA, TextVQA и MSVD-QA. .
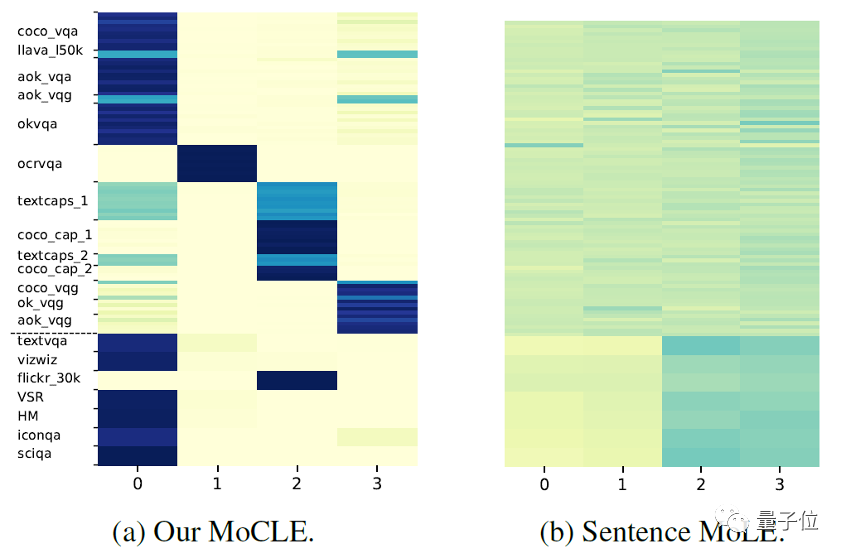
На рисунке выше показаны результаты маршрутизации определенного уровня гибридных экспертов LLM LoRA при различных данных. Верхняя и нижняя пунктирные линии — это данные обучения и тестирования соответственно. (a) и (b) показывают результаты использования информации о кластеризации инструкций и среднего представления токена инструкций в качестве маршрутизации соответственно.
Видно, что при использовании маршрутизации информации кластеризации команд данные делятся между экспертами.。Например, эксперты0В основном отвечает заVQAСвязанные задачи,Эксперт 2 в основном отвечает за задачи, связанные с субтитрами.,Эффективно добиться экспертной дифференциации. с другой стороны,При использовании среднего представления токена инструкции в качестве условия,Активация экспертов аналогична для разных задач.,Никакой дифференциации не произошло.
Исследовательская группа считает, что сочетание разреженной экспертной мультимодальной большой модели + общего экспертного модуля смягчает конфликт между задачами и обеспечивает способность обобщения разреженной модели к задаче, позволяя мультимодальной большой модели более эффективно адаптироваться. Различные приложения в перерабатывающей промышленности.
Это первая работа, объединяющая LoRA и разреженные экспертные модели (MoE) в тонкой настройке инструкций мультимодальной большой модели для облегчения конфликтов задач и поддержания возможностей обобщения модели. Эта работа подтвердила свою эффективность в решении сложных последующих задач и открыла новые возможности для применения и развития мультимодальных больших моделей.
Бумажная ссылка: https://arxiv.org/abs/2312.12379
— над —



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
