Большое обновление NVIDIA TensorRT 10.0! Двойной скачок в удобстве использования и производительности, а также более мощная поддержка моделей искусственного интеллекта!
Кажется, вчера мы еще обсуждали новые возможности версии NVIDIA TensorRT 8.5, но на этой неделе NVIDIA выпустила новую версию TensorRT 10.0. Это также крупное обновление версии. Давайте посмотрим на обновленные функции.
Обновление TensorRT 10.0, совершенно новый опыт для разработчиков
Выпуск TensorRT 10.0,Это обеспечивает более удобный вход для разработчиков. Благодаря обновленным метапакетам Debian и RPM,Установка библиотеки TensorRT теперь стала проще простого. Просто простая команда,нравитьсяapt-get install tensorrtилиpip install tensorrt,Вы можете легко установить все связанные библиотеки C++ или Python.
Стоит отметить, что в TensorRT 10.0 также представлен новый API Debug Tensors. Этот API позволяет разработчикам помечать определенные тензоры как тензоры отладки во время сборки, что упрощает отслеживание и выявление проблем на графике. Всякий раз, когда значения этих тензоров изменяются во время выполнения, система автоматически вызывает определяемую пользователем функцию обратного вызова, которая подробно сообщает значение, тип и размеры тензора.
Парсер ONNX Кроме того, Тензор РТ 10.0 также был обновлен.,Были добавлены новые инструменты, которые помогут разработчикам быстро идентифицировать неподдерживаемые узлы в случае сбоя вызова. Эти отчеты об ошибках содержат подробную информацию об имени узла, типе и причине сбоя.,Даже локальный стек функций(нравиться果节点位于ONNXв локальной функции)。проходитьparse、getNbErrorsиgetErrorравная функция,Разработчики могут легко запрашивать и обрабатывать эти сообщения об ошибках.
Для разработчиков Windows TensorRT 10.0 также приносит значительные преимущества. Новая версия не только улучшает совместимость версий и совместимость оборудования, но также оптимизирует механизм снижения веса и стабильный конвейер распространения, поднимая опыт разработки на платформе Windows на более высокий уровень.
TensorRT 10.0 имеет серьезное обновление
TensorRT Версия 10.0 содержит множество привлекательных обновлений функций. Среди них к основным показателям производительности можно отнести блок поддержки Количественная. оценкаиз Количественная оценка только веса INT4 (WoQ) и улучшены параметры распределения Память. Эти новые функции не только повышают производительность, но и делают развертывание больших моделей более гибким.
Количественная оценка только веса INT4 (WoQ)
TensorRT 10.0 теперь поддерживает сжатие веса с использованием INT4 — функции, которая не зависит от аппаратной архитектуры и имеет широкую применимость. Когда пропускная способность памяти становится узким местом производительности операций GEMM или ресурсы памяти графического процессора ограничены, технология WoQ может сыграть огромную роль. В WoQ веса GEMM квантуются с точностью до INT4, в то время как входные данные и вычислительные операции GEMM поддерживаются с высокой точностью. Ядро WoQ TensorRT считывает 4-битные веса из памяти и деквантует их перед выполнением высокоточных вычислений скалярного произведения.
Кроме того, технология блочного квантования обеспечивает более высокую степень детализации шкалы квантования. Он делит тензор на фрагменты фиксированного размера по одному измерению и определяет коэффициент масштабирования для каждого фрагмента. Таким образом, все элементы в блоке могут иметь общий масштабный коэффициент, что еще больше повышает гибкость и точность квантования.
Распределение памяти во время выполнения
TensorRT 10.0 также улучшает Распределение. памяти во время выполненияиз功能。проходитьcreateExecutionContextфункция,Пользователь может указать стратегию выделения устройства контекста выполнения Память. Метод назначения для управления пользователями,TensorRT предоставляет дополнительные API,чтобы запросить необходимый размер на основе фактической входной формы,Это позволяет более детально управлять ресурсами Память.
Облегченные двигатели и потоковая передача веса
Чтобы решить проблемы развертывания больших моделей, TensorRT 10.0Представлен двигатель для снижения веса.,Эта функция может достигать до99%из引擎尺寸压缩。проходить使用新标志REFIT_IDENTICAL,Разработчик TensorRT может выполнять оптимизацию, предполагая, что движок будет модернизирован с теми же весами, которые были указаны во время сборки. Эта функция значительно уменьшает размер механизма сериализации.,Упростите развертывание и распространение.
В то же время TensorRT 10.0 также поддерживает функцию распределения веса. Эта функция позволяет передавать веса сети из памяти хоста в память устройства во время работы сети, а не помещать их все в память устройства сразу при загрузке механизма. Это позволяет моделям с весом, превышающим доступную память графического процессора, работать плавно, хотя и с немного увеличенной задержкой. Следует отметить, что эта функция поддерживает только строго типизированные сети.
В целом, обновления функций TensorRT 10.0 предоставляют пользователям более гибкое и эффективное решение для развертывания моделей, особенно при работе с большими моделями и ограниченными ресурсами памяти графического процессора.
Оптимизатор модели NVIDIA TensorRT 0.11
NVIDIA TensorRT 10.0 представляет новую комплексную библиотеку — оптимизатор моделей NVIDIA TensorRT. Этот оптимизатор специально разработан для оптимизации после обучения и циклического обучения моделей глубокого обучения. Он охватывает квантование, разрежение, дистилляцию и другие технологии, направленные на упрощение структуры модели, чтобы компилятор мог более эффективно повысить скорость вывода модели.
Этот оптимизатор способен имитировать квантованную контрольную точку для моделей PyTorch и ONNX, развернутых в TensorRT или TensorRT-LLM. С помощью Python API Model Optimizer пользователи могут легко воспользоваться преимуществами технологии оптимизации среды выполнения и компилятора TensorRT для ускорения вывода модели.
Стоит отметить, что NVIDIA TensorRT Model Optimizer имеет открытый исходный код и бесплатен, и пользователи могут легко получить его через NVIDIA PyPI. Для получения дополнительной информации см. общедоступную информацию об использовании оптимизатора моделей NVIDIA TensorRT для повышения производительности генеративного вывода ИИ.
Количественная оценка после обучения (PTQ)
В модели технология сжатия, Количественная оценка после обучения (PTQ) — один из популярных методов уменьшения занятости Память и ускорения вывода. Только с другой поддержкой нет данных Количественная оценка (WoQ) или Количественная на основе технологии инструментарий оценки по сравнению с моделью Оптимизатор обеспечивает включение INT8 SmoothQuant и INT4 Расширенные алгоритмы калибровки, включая AWQ. Если вы используете точность FP8 или более низкую (например, INT8 или INT4) в TensorRT-LLM, то модель вам уже нравится в фоновом режиме. Optimizer Эффект оптимизации PTQ.
Тренинг количественной осведомленности (QAT)
также,Тренинг количественной осведомленности (QAT) позволяет полностью раскрыть потенциал ускорения 4-битного вывода, не влияя на точность Модели. QAT работает путем расчета коэффициента масштабирования во время обучения и преобразования смоделированного Количественного значения. Потеря качества включена в процесс тонкой настройки, что делает нейронную сеть более подходящей для Количественных задач. качество более адаптируемо. Модель Процесс QAT Optimizer включает NVIDIA Не Мо, Мегатрон-ЛМ и объятия Face Trainer Тесная интеграция с основными платформами обучения, включая API, предоставляет разработчикам множество вариантов использования возможностей платформы NVIDIA в разных платформах.
методы разреженности
методы разреженности уменьшает размер Модели за счет выборочного поощрения нулевых значений в параметрах Модели, которые можно игнорировать при хранении и расчете. В эталонном тесте вывода MLPerf v4.0 TensorRT-LLM использует модель Оптимизатор после обучения методам разреженности,в NVIDIA Лама бегает по H100 2 Модель 70B обеспечивает дополнительное ускорение до 1,3 раза за счет квантования FP8.
Nsight Разработчик глубокого обучения
В TensorRT 10.0 добавлена новая поддержка анализа и создания механизмов для Nsight Deep Learning Designer 2024.1 (версия раннего доступа). Nsight Deep Learning Designer — это интегрированная среда разработки, специально разработанная для проектирования глубоких нейронных сетей (DNN).
Во время оптимизации модели нам необходимо найти тонкий баланс между скоростью и точностью. Nsight Deep Learning Designer помогает нам настраивать модели для достижения целей производительности и полностью использовать ресурсы графического процессора, обеспечивая интуитивно понятную диагностику производительности сети.
Кроме того, этот инструмент позволяет нам выполнять визуальную проверку моделей TensorRT ONNX. Пользователи могут на лету настраивать графики модели и отдельных операторов, чтобы оптимизировать процесс вывода.
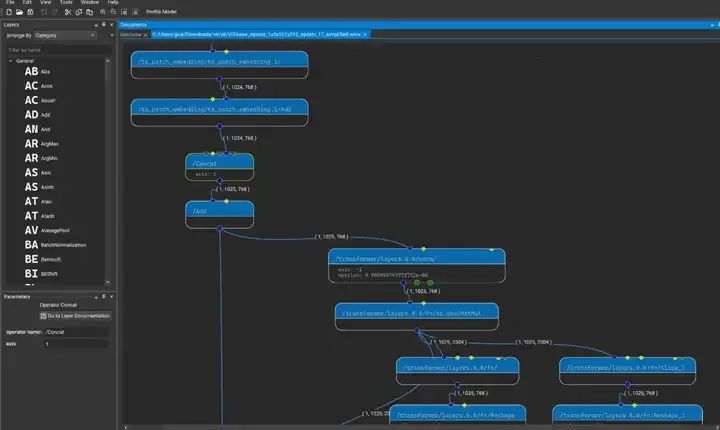
Nsight Deep Learning Designer 2024.1 визуализирует модели TensorRT 10.0 для проверки и управления процессами вывода в реальном времени.
Стоит отметить, что Nsight Deep Learning Designer предоставляется бесплатно, что позволяет каждому легко проектировать и оптимизировать модели глубокого обучения.
Обновление NVIDIA TensorRT-LLM 0.10 поддерживает больше моделей искусственного интеллекта
NVIDIA TensorRT-LLM, эта библиотека с открытым исходным кодом, специально разработана для оптимизации вывода модели большого языка (LLM). Он предоставляет простой в использовании API Python, который включает в себя новейшие технологии вывода LLM, такие как FP8 и INT4 AWQ, при этом гарантируя, что точность вывода не будет нарушена. Версия 0.10 TensorRT-LLM, запуск которой ожидается в конце мая, будет поддерживать новые модели искусственного интеллекта, такие как Meta Llama 3, Google CodeGemma, Google RecurrentGemma и Microsoft Phi-3.
Кроме того, в новой версии добавлена поддержка FP8 для Hybrid Experts (MoE), что еще больше повышает производительность и гибкость модели. Его среда выполнения C++ и серверная часть NVIDIA Triton теперь поддерживают модель кодировщика-декодера и могут обрабатывать пакетные данные «на лету». Стоит отметить, что механизм удаления веса, представленный в TensorRT 10.0, также будет применяться в TensorRT-LLM, что, несомненно, предоставит пользователям более эффективный и удобный опыт вывода.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
