Большие модели реконструируют роботов: как Google Deepmind определяет будущее воплощенного интеллекта
За последний год череда крупномасштабных прорывных моделей изменила область исследований в области робототехники.
После того, как самые продвинутые крупные модели стали «мозгами» воплощенных роботов для восприятия мира, эволюция роботов продвинулась далеко за пределы воображения.
В июле Google DeepMind объявила о запуске RT-2: первой в мире модели «видение-язык-действие» (VLA) для управления роботами.
Просто дайте ей команду типа разговора, и она сможет идентифицировать Свифт среди кучи картинок и подарить ей баночку с «счастливой водой».

Он даже может мыслить проактивно, совершая многоэтапный логический скачок от «выбора животного для вымирания» до схватывания пластикового динозавра на столе.

существовать RT-2 После этого Гугл DeepMind предложил снова Q-Transformer,В мире роботов тоже есть свои Transformer 。Q-Transformer Это позволяет роботам избавиться от зависимости от высококачественных демонстрационных данных и лучше накапливать опыт, полагаясь на независимое «мышление».
RT-2 Всего через два месяца после его выпуска появился еще один робот. ImageNet время. Google DeepMind Запущен совместно с другими учреждениями Открыть набор данных X-варианта,Изменен предыдущий метод настройки Модели конкретно под каждую задачу и робота.,Объедините знания из разных дисциплин,Был создан новый способ обучения генерального робота.
Представьте, что вы просите своих роботов-помощников делать простые вещи, например: «Убрать мой дом» или «Приготовить нам вкусную и полезную еду». Такие задачи, как уборка дома или приготовление пищи, легки для людей, но нелегки для роботов, которые требуют глубокого понимания мира.
Основываясь на многолетних исследованиях в области роботов-трансформеров, Google недавно объявила о серии исследовательских достижений в области роботов: AutoRT, SARA-RT и RT-Trajectory, которые могут помочь роботам быстрее принимать решения и лучше понимать ситуации, в которых они находятся. окружающей среды может лучше помочь вам в выполнении ваших задач.
Google считает, что запуск таких результатов исследований, как AutoRT, SARA-RT и RT-Trajectory, может улучшить сбор данных, скорость и возможности обобщения реальных роботов.
Далее давайте рассмотрим эти важные исследования.
AutoRT: используйте большие модели для лучшего обучения роботов
AutoRT объединяет большую базовую модель (например, большую языковую модель (LLM) или визуальную языковую модель (VLM)) с моделью управления роботом (RT-1 или RT-2) для создания робота, который можно развертывать в новых средах. для сбора обучающих данных системы. AutoRT может одновременно управлять несколькими роботами, оснащенными видеокамерами и рабочими органами, для выполнения разнообразных задач в различных средах.
В частности, согласно данным AutoRT, каждый робот будет использовать модель визуального языка (VLM), чтобы «осматриваться» и понимать окружающую среду и объекты в пределах прямой видимости. Далее большая языковая модель предложит для нее ряд творческих задач, таких как «поставить закуски на стол» и сыграть роль лица, принимающего решения, выбирая задачи для выполнения роботом.
Исследователи провели обширную семимесячную оценку AutoRT в реальном мире. Эксперименты доказали, что система AutoRT может безопасно координировать работу до 20 роботов одновременно, а всего — до 52 роботов. Направляя роботов для выполнения различных задач в различных офисных зданиях, исследователи собрали разнообразный набор данных, охватывающий 77 000 испытаний роботов с 6650 уникальными задачами.
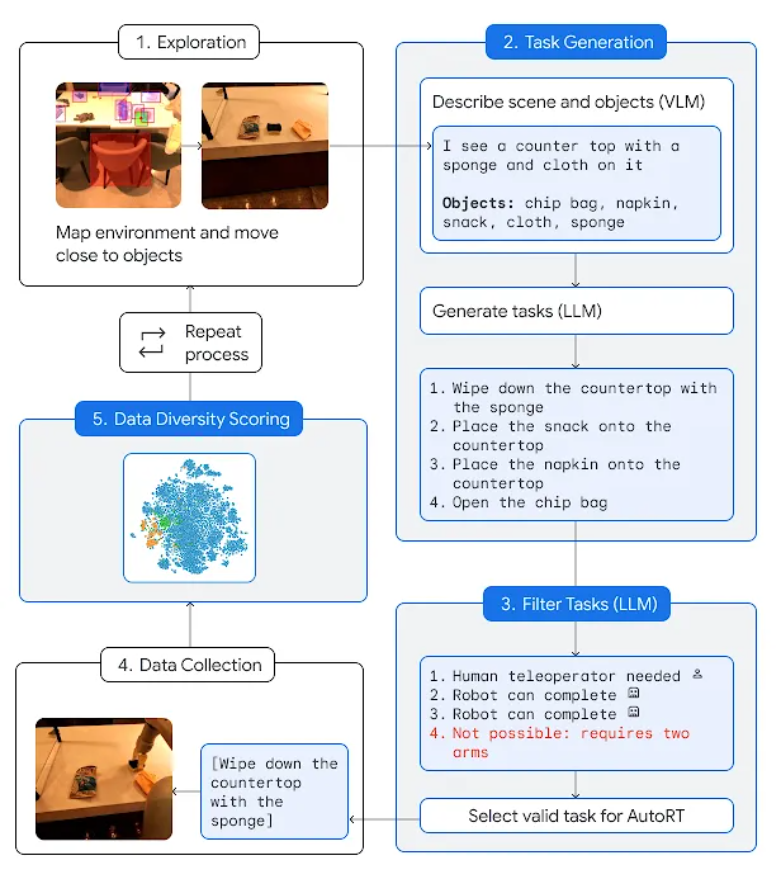
На рисунке выше представлен процесс работы системы AutoRT: (1) Автономный колесный робот находит локацию с несколькими объектами. (2) VLM описывает сцены и объекты для LLM. (3) LLM предлагает различные рабочие задачи для робота и решает, какие задачи робот может выполнять самостоятельно, какие задачи требуют дистанционного управления человеком, какие задачи выполнить невозможно, а затем делает выбор. (4) Робот пытается выбрать задачи, которые необходимо выполнить, собирает экспериментальные данные и оценивает разнообразие и свежесть данных. Робот будет продолжать повторять этот процесс.
AutoRT имеет потенциал для использования больших базовых моделей, которые имеют решающее значение для понимания роботами человеческих инструкций в реальных приложениях. Собирая более полные данные экспериментального обучения и более разнообразные данные, AutoRT может расширить возможности обучения роботов и внести улучшения в обучение роботов в реальных условиях.
Прежде чем роботы смогут быть интегрированы в нашу повседневную жизнь, необходимо обеспечить их безопасность, что требует от исследователей ответственного подхода к разработке и проведения углубленных исследований безопасности роботов.
Хотя сейчас AutoRT — это всего лишь система сбора данных, воспринимайте ее как раннюю стадию появления автономных роботов в реальном мире. Он оснащен ограждениями безопасности, одно из которых представляет собой набор ключевых слов, ориентированных на безопасность, которые определяют основные правила, которым робот должен следовать, когда робот принимает решения на основе LLM.
Эти правила были частично вдохновлены «Три законами робототехники» Айзека Азимова, наиболее важным из которых является то, что роботы «не должны причинять вред людям». Правила безопасности также требуют, чтобы роботы не выполняли задачи, связанные с людьми, животными, острыми предметами или электроприборами.
Только работа над подсказками не может полностью гарантировать безопасность роботов в практическом применении. Таким образом, система AutoRT также включает в себя ряд практических мер безопасности, которые представляют собой классическую конструкцию робототехники. Например, коллаборативные роботы запрограммированы на автоматическую остановку, если силы на их суставах превышают заданный порог, а все роботы с автономным управлением могут быть ограничены линией прямой видимости человека-контролера с помощью физического переключателя деактивации.
SARA-RT: робот-трансформер (RT) становится быстрее и экономичнее
Другой результат, SARA-RT, преобразует модель робота-трансформера (RT) в более эффективную версию.
Архитектура нейронной сети RT, разработанная командой Google, использовалась в новейших системах управления роботами, включая модель RT-2. Лучшая модель SARA-RT-2 на 10,6% точнее и на 14% быстрее, чем модель RT-2, если учитывать краткую историю изображений. Google заявляет, что это первый масштабируемый механизм внимания, который увеличивает вычислительную мощность без ущерба для качества.
Несмотря на то, что Трансформеры мощные, их возможности могут быть ограничены вычислительными требованиями, что замедляет принятие решений. Трансформер в основном опирается на модуль внимания квадратичной сложности. Это означает, что если входные данные для модели RT удваиваются (например, снабжая робота большим количеством датчиков или с более высоким разрешением), вычислительные ресурсы, необходимые для обработки этих входных данных, увеличиваются в четыре раза, что приводит к замедлению принятия решений.
SARA-RT использует новый метод точной настройки модели, называемый «повышенным обучением», для повышения эффективности модели. Повышение квалификации преобразует квадратичную сложность в чисто линейную, что значительно снижает вычислительные требования. Такое преобразование не только повышает скорость исходной модели, но и сохраняет ее качество.
Google надеется, что многие исследователи и практики будут использовать эту практическую систему в робототехнике и других областях. Поскольку SARA предоставляет общий метод ускорения работы Трансформаторов без необходимости дорогостоящего предварительного обучения, этот подход имеет потенциал для масштабирования технологии Трансформаторов. SARA-RT не требует какого-либо дополнительного кодирования, поскольку доступны различные линейные варианты с открытым исходным кодом.
Когда SARA-RT применяется к модели SOTA RT-2 с миллиардом параметров, это позволяет быстрее принимать решения и повышать производительность при выполнении различных роботизированных задач:

Модель САРА-РТ-2 для манипуляционных задач. Движения робота обусловлены изображениями и текстовыми инструкциями.
Благодаря прочной теоретической основе SARA-RT может применяться к различным моделям трансформаторов. Например, применение SARA-RT к преобразователю облака точек, который обрабатывает пространственные данные с камеры глубины робота, может увеличить скорость более чем вдвое.
RT-Trajectory: Помощь роботам в обобщении
Люди могут интуитивно понять и научиться мыть стол, но роботам нужно множество возможных способов перевода инструкций в реальные физические действия.
Традиционно обучение роботизированных рук основано на сопоставлении абстрактного естественного языка (протрите стол) с конкретными действиями (закрыть захват, движение влево, движение вправо), что затрудняет обобщение модели на новые задачи. Напротив, модель RT-траектории позволяет модели RT понять, «как» выполняется задача, интерпретируя конкретные действия робота (например, в видео или эскизе).
Модель RT-Trajectory может автоматически добавлять визуальные контуры для описания движений робота в обучающих видеороликах. RT-Trajectory накладывает каждое видео в наборе обучающих данных на двумерный эскиз траектории захвата, пока рука робота выполняет задачу. Эти траектории в виде изображений RGB предоставляют модели низкоуровневые практические визуальные подсказки для изучения стратегий управления роботом.
При тестировании на 41 задаче, не встречавшейся в обучающих данных, робот-манипулятор, управляемый RT-Trajectory, более чем вдвое увеличил производительность существующей модели SOTA RT: уровень успеха выполнения задач достиг 63% по сравнению с RT-2. всего 29%.
Система настолько универсальна, что «РТ-Траектория» также может создавать траектории, наблюдая за демонстрацией человеком необходимых задач, и даже принимает нарисованные от руки эскизы. Более того, он может в любой момент адаптироваться к различным роботизированным платформам.
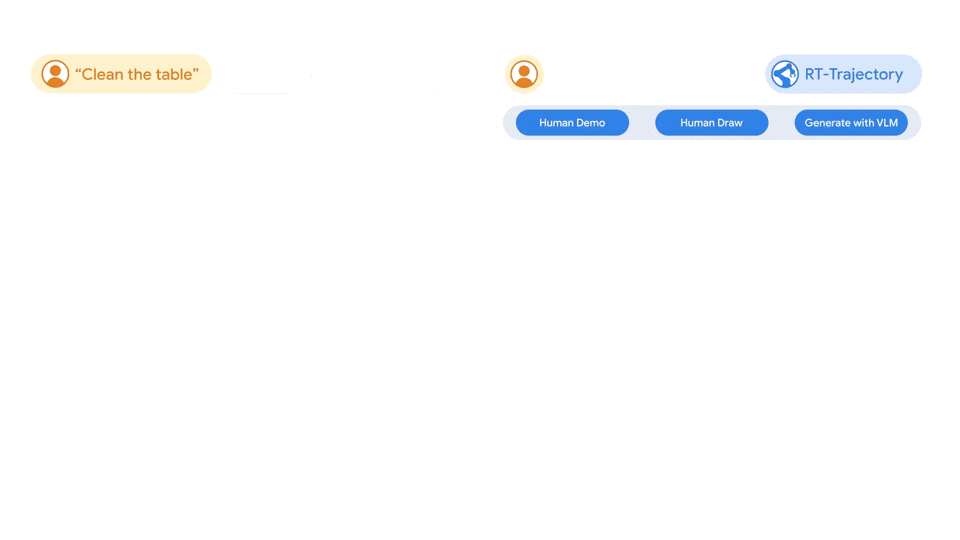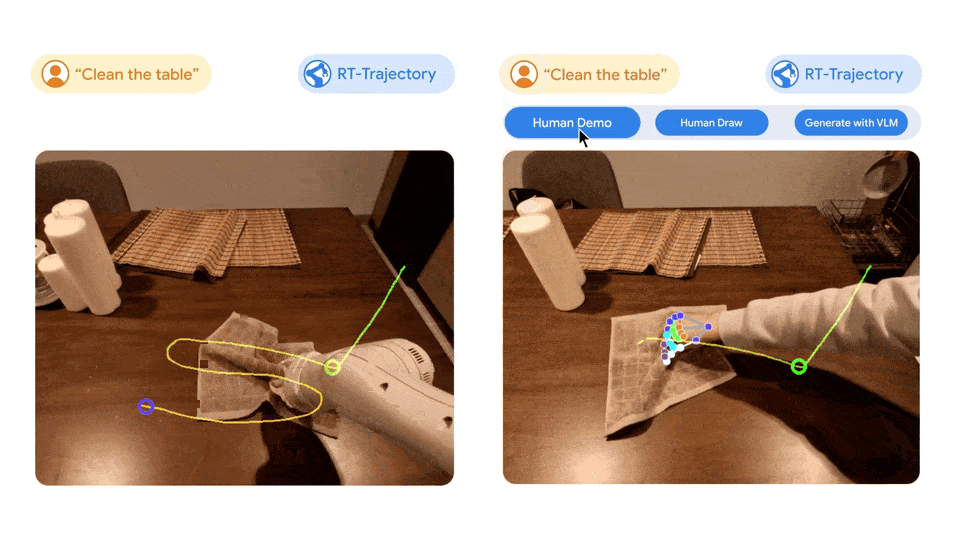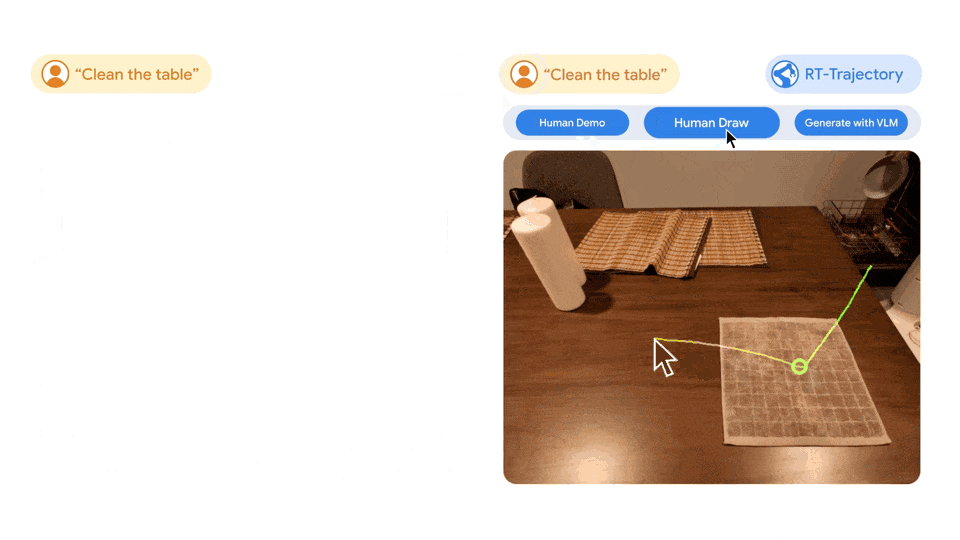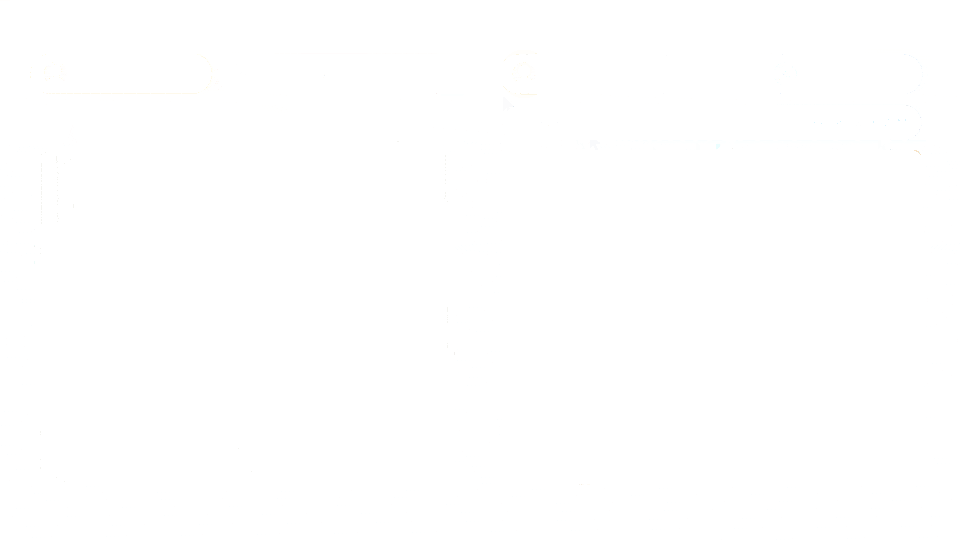
Слева: обучение с использованием только наборов данных на естественном языке. RT Робот, управляемый моделью, был расстроен при выполнении новой задачи по уборке стола и был RT Робот, управляемый траекторной моделью, проходит 2D После обучения на том же наборе данных с увеличением траектории траектория вытирания была успешно спланирована и выполнена. Справа: Хорошо обученный RT После получения нового задания (очистка таблицы) модель траектории может быть создана различными способами самостоятельно с помощью человека или с использованием визуальных языковых моделей. 2D траектория.
Траектории RT используют обширную информацию о движении робота, которая присутствует во всех наборах данных роботов, но в настоящее время используется недостаточно. RT-Trajectory не только представляет собой еще один шаг на пути к созданию роботов, которые будут эффективно и точно двигаться для выполнения новых задач, но также позволяет извлекать знания из существующих наборов данных.
© THE END
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.
Публикуйте статьи или ищите освещение: content@jiqizhixin.com



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
