Большие ядра свертки очень полезны | LSKNet + DiffusionDet — более совершенная и мощная модель обнаружения целей

В области анализа изображений воздушного пространства обнаружение объектов играет ключевую роль и оказывает значительное влияние на такие области, как дистанционное зондирование, городское планирование и управление стихийными бедствиями. Трансформатор — это структура нейронной сети для обработки данных последовательности, которая может эффективно улавливать зависимости во входных данных на больших расстояниях. CNN — это сверточная нейронная сеть, которая может эффективно извлекать особенности изображений и использоваться для таких задач, как обнаружение объектов. В этом исследовании рассматриваются проблемы, присущие этой области, в частности обнаружение небольших объектов, управление плотными элементами и рассмотрение различных направлений. Автор использует большую сеть выборочного ядра (LSKNet) в качестве магистральной сети и DiffusionDet. Head Комбинированная модель обнаружения объектов тщательно оценивается и эмпирически анализируется с использованием набора данных iSAID. Подход авторов включает внедрение новых методов и проведение обширных исследований абляции. В этих исследованиях критически оцениваются различные аспекты, такие как функции потерь, методы граничной регрессии и стратегии классификации, для повышения точности моделей обнаружения объектов. В этой статье подробно описывается, как использовать LSKNet. Магистральная сеть и DiffusionDet Head В сочетании с экспериментальными приложениями это комбинация, специально разработанная для решения конкретных задач обнаружения объектов на изображениях воздушного пространства. Результаты этого исследования демонстрируют значительное улучшение производительности модели, особенно с точки зрения точности и компромисса по времени. Предлагаемая модель достигает средней средней точности (MAP) около 45,7%, что является значительным улучшением, превосходя модель RCNN на 4,7% в том же наборе данных. Это достижение подчеркивает эффективность предлагаемых модификаций и устанавливает новый стандарт в пространственном анализе изображений, закладывая основу для более точных и эффективных методов обнаружения объектов. 代码:https://github.com/SashaMatsun/LSKDiffDet
1 Introduction
Обнаружение объектов на аэрофотоснимках стало динамичной и важной областью исследований, направленной на идентификацию и локализацию объектов на изображениях высокого разрешения, снятых с помощью воздушных платформ, таких как спутники, дроны или самолеты. Эта технология находит применение во многих областях, включая, помимо прочего, городское планирование, точное земледелие, борьбу со стихийными бедствиями и военное наблюдение.
Интеграция передовых методов машинного обучения, в частности глубокого обучения и сверточных нейронных сетей, позволяет этим моделям обнаружения объектов эффективно обрабатывать большие наборы данных аэрофотоснимков и идентифицировать конкретные объекты, такие как транспортные средства, здания и растительность. Однако эта область сталкивается с рядом проблем, таких как обработка изображений с различным разрешением, управление окклюзиями, необходимость больших и точно аннотированных наборов обучающих данных и обработка изображений с высоким разрешением в реальном времени.
Решение этих проблем имеет решающее значение для раскрытия всего потенциала аэрофотосъемки для обнаружения объектов, тем самым способствуя более эффективному принятию решений на основе данных в различных областях.
В этой статье авторы представляют ряд инновационных разработок, которые значительно продвинули область анализа аэрофотоснимков. Комплексный и многогранный подход автора включает введение новой архитектуры Backbone, включение моделей диффузии и применение различных функций потерь. Кроме того, авторы исследуют влияние различных функций активации и оптимизации гиперпараметров на достижение оптимальной производительности. Вместе эти элементы представляют собой шаг вперед в области анализа аэрофотоснимков, как подробно описано ниже:
Авторы объединяют большие свертки ядра и пространственный выбор ядра с функциональной пирамидальной сетью (FPN), чтобы создать мощный и эффективный рабочий процесс для анализа аэрофотоснимков. Этот инновационный дизайн значительно улучшает извлечение признаков и представление аэрофотоснимков. Авторы применили адаптируемость модели диффузии (DiffusionDet) к аэрофотосъемке с пользовательскими модификациями, что привело к значительному повышению точности обнаружения объектов в сложных аэрофотосценах.
Авторы представляют инновационную и усовершенствованную архитектуру модели, которая значительно повышает точность анализа аэрофотоснимков. Эти модификации привели к созданию более мощной и эффективной модели, адаптированной для сценариев аэрофотосъемки. Автор проводит обширные эксперименты для оценки влияния различных функций активации на производительность авторской модели. Это исследование выявило наиболее эффективные функции активации, улучшающие общую производительность и надежность модели.
Чтобы решить распространенную проблему дисбаланса классов, авторы разработали взвешенную функцию фокусных потерь и исследовали адаптируемость других функций потерь для граничной регрессии. Этот метод эффективно решает проблему дисбаланса классов, одновременно повышая точность модели. Авторы подробно анализируют влияние гиперпараметров и методов постобработки и настраивают их для оптимизации результатов. Этот тщательный процесс оптимизации гарантирует, что предложенная авторами модель достигнет максимальной производительности в области комплексного анализа аэрофотоснимков. Работа авторов представляет широкую и инновационную методологию анализа аэрофотоснимков, обеспечивающую превосходную производительность и превосходящую существующие методы. Одним из ключевых аспектов подхода авторов является эффективность использования ресурсов.
Несмотря на использование ограниченного количества графических процессоров и меньшего количества итераций, наша модель обеспечивает значительное улучшение точности и надежности. Такое эффективное использование вычислительных ресурсов подчеркивает преимущества модели авторов с точки зрения эффективности и устойчивости, что делает ее более энергоэффективным решением для анализа аэрофотоснимков. Тщательно рассматривая все аспекты проектирования и оптимизации моделей, исследование авторов устанавливает новый стандарт для достижения превосходной производительности при анализе высотных изображений с меньшим воздействием на окружающую среду.
2 Dataset
В этой работе авторы используют исправленную версию набора данных экземплярной сегментации в аэрофотоснимках (iSAID), комплексного набора данных, разработанного специально для задач обнаружения объектов и сегментации экземпляров на аэрофотоснимках. Набор данных содержит аэрофотоснимки высокого разрешения из различных источников, включая спутники и беспилотные летательные аппараты (БПЛА). Этот набор данных охватывает широкий спектр сценариев, таких как городская, сельская и естественная среда, обеспечивая прочную основу для обучения и оценки моделей обнаружения и сегментации объектов.
Исходный набор данных iSAID содержит 15 категорий и в общей сложности 655 451 экземпляр объекта, которые принадлежат 2806 изображениям высокого разрешения. Изображения в наборе данных iSAID такие же, как и в наборе данных DOTA-v1.0, в основном из Google Earth.
Некоторые изображения были сняты спутником JL-1, которым управляет Китайский центр спутниковых данных и приложений по ресурсам, тогда как другие были сняты спутником GF-2, которым управляет Китайский центр спутниковых данных и приложений по ресурсам. В исследовании автора использовалась исправленная версия набора данных iSAID, включающая 28 029 изображений. Эти изображения получены путем разделения исходного набора данных на участки размером 800×800. Такое разделение привело к существенному увеличению количества экземпляров в обучающей подгруппе, достигнув 704 428. Увеличение количества экземпляров во многом можно объяснить совпадением патчей наборов данных. Использование этого подхода пакетной обработки дает два ключевых преимущества: во-первых, он значительно увеличивает разнообразие и сложность обучающих данных, тем самым повышая надежность модели в различных сценариях аэрофотосъемки.
Во-вторых, это позволяет модели подвергаться воздействию различных случаев и контекстов, что дает ей более широкие возможности обобщения на различных аэрофотоснимках. Это ключ к улучшению способности модели к обобщению на различных аэрофотоснимках. Важно отметить, что, несмотря на разделение и увеличение, авторы тщательно сохраняли разделение между обучающим, проверочным и тестовым наборами, гарантируя отсутствие утечки данных между ними. Такое тщательное разграничение обеспечивает целостность и надежность процесса оценки автора.
Хотя набор данных iSAID очень богат, он ставит перед разработчиками и практиками ряд проблем в области обнаружения воздушных объектов. Решение этих проблем требует разработки более совершенных и мощных моделей машинного обучения, которые смогут справиться с уникальными сложностями аэрофотоснимков. Эти проблемы включают в себя:
- Разнообразие размеров предметов: Аэрофотоснимки содержат объекты разных размеров.,От больших зданий до небольших транспортных средств,Из-за этого Модель затрудняется точно идентифицировать и сегментировать экземпляры.
- Окклюзия: Объекты на аэрофотоснимках часто частично закрыты другими объектами или природными объектами, что затрудняет их сегментацию и обнаружение.
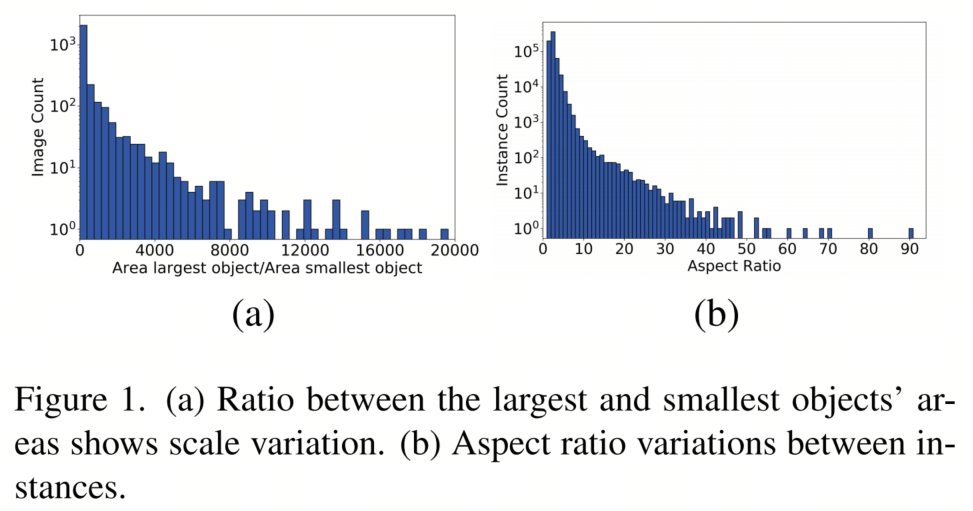
- Пропорциональные изменения: dataConcentrate содержит функции с разными масштабами и aspect ratio изображения,Это влияет на производительность модели, обученной на этом типе данных.,Как показано на рисунке 1.
- Сложный фон: Аэрофотоснимки часто имеют сложный и загроможденный фон, из-за чего Модели сложно отличить объект от его окружения.
- Освещение и погодные условия: Изменения освещения и атмосферных условий могут повлиять на видимость и внешний вид объектов на аэрофотоснимках, создавая дополнительные проблемы для обнаружения и сегментации объектов. Модель.
3 Related Works
Аэрофотосъемка и обнаружение объектов стали незаменимыми инструментами в различных приложениях, обеспечивающими глубокое понимание земных явлений и деятельности человека. Появление технологий дистанционного зондирования, включая снимки со спутников и дронов, произвело революцию в методах наблюдения и анализа для крупномасштабных эколого-географических исследований. Аэрофотосъемка помогает получать данные высокого разрешения на обширных территориях, что ценно для решения таких разнообразных задач, как классификация землепользования, реагирование на стихийные бедствия и мониторинг окружающей среды. В этом контексте обнаружение объектов на аэрофотоснимках имеет решающее значение для извлечения полезной информации из этих больших объемов данных, помогая идентифицировать и локализовать различные объекты и особенности.
В последние годы точность и эффективность алгоритмов обнаружения объектов на основе глубокого обучения при анализе аэрофотоснимков были значительно улучшены. Сочетание аэрофотосъемки и обнаружения объектов оказало глубокое влияние на многие области и внесло важный вклад в решение глобальных проблем. Одноэтапные модели обнаружения объектов получили широкое внимание благодаря своей эффективности и результативности. Эти модели объединяют задачи локализации и классификации объектов в единую плавную сеть, сокращая время вывода. Типичным примером является платформа You Only Look Once (YOLO), которая сегментирует входное изображение в сеточную систему и прогнозирует ограничивающие рамки и вероятности классов для каждой ячейки сетки. Аналогичным образом, одноступенчатый многообъектный детектор (SSD), предложенный Лю и др., использует многомасштабные карты признаков для эффективной обработки объектов различных размеров. Эти одноэтапные модели хорошо работают в различных реальных сценариях.
Напротив, двухэтапные модели обнаружения объектов обычно включают сеть предложений регионов и сеть классификации. На первом этапе создаются области-кандидаты для объектов, а на втором этапе эти области классифицируются по конкретным категориям объектов. Семейство региональных сверточных сетей (R-CNN) является типичным примером двухэтапной модели. Модель R-CNN использует выборочный поиск для генерации предложений по регионам, которые затем классифицируются через CNN. Последующие модели, такие как Fast R-CNN и Faster R-CNN, повысили эффективность и точность исходной модели R-CNN за счет таких инноваций, как объединение рентабельности инвестиций и сети предложений регионов.
Последние достижения в области обнаружения объектов на аэрофотоснимках быстро развиваются благодаря появлению крупномасштабных наборов данных аэрофотоснимков, таких как DOTA и xView. Эти наборы данных позволяют целенаправленно обучать и оценивать модели обнаружения объектов, адаптированные к воздушным условиям. Аэрофотоснимки часто создают уникальные проблемы, включая значительные различия в размерах объектов, загроможденный фон и разнообразные углы обзора. Для решения этих проблем были разработаны некоторые специализированные модели, такие как сети предложений ориентированных регионов (ORPN), которые могут обнаруживать объекты независимо от их ориентации.
Сеть высокого разрешения (HRNet) эффективно управляет объектами разных размеров, поддерживая карты объектов высокого разрешения по всей модели. Кроме того, детектор объектов адаптивного размера (ASOD) адаптируется к объектам разных размеров, регулируя воспринимающее поле и масштаб привязки. Эти достижения значительно улучшают обнаружение объектов на аэрофотоснимках, повышая точность и эффективность анализа данных.
4 Methodology
В этом разделе автор объясняет технические сложности подхода, использованного для построения авторской модели.
Model Architecture
4.1.1 LSKNet
Структура модели авторов аналогична общей архитектуре модели, такой как рассмотренная в [25], и состоит из повторяющихся блоков со схожей структурой. Ключевое новшество подхода авторов заключается в интеграции механизма Large Selective Kernel (LSK) в каждый блок Backbone.
Эта интеграция имеет решающее значение для расширения возможностей модели по извлечению признаков, поскольку она обеспечивает более широкую контекстуальную область.
Большие сверточные слои ядра. Эти сверточные слои реализованы как серия точечных сверточных слоев. Эти свертки используют постепенно увеличивающиеся размеры ядра и скорость расширения. Такая конфигурация позволяет быстро расширить рецептивное поле, как описано в [7, 23]. Основные преимущества этой структуры двояки: во-первых, она помогает извлечь множество функций, охватывающих различные контекстуальные области. Во-вторых, оно обеспечивает лучшую эффективность, чем одно большое ядро с таким же рецептивным полем.
Например, для входа с 64 каналами один с
Механизм продолжения структуры требует всего 11,3 тыс. параметров. Для сравнения, один сверточный слой размером 29 требует 60,4 тыс. параметров.
Пространственный выбор ядра. Согласно [15], этот процесс динамически выбирает ядра, подходящие для различных объектов, на основе извлеченных функций. Изначально фичи из ядер разного размера склеиваются в фичу размера
карта объектов. Затем для каждого канала рассчитываются средние и максимальные значения и интегрируются в
в дескрипторе функции. Затем применяются сверточный слой и сигмовидная функция активации для преобразования этих дескрипторов объектов в
Пространственная карта внимания. Конечным результатом работы этого модуля является объединение входных карт объектов и поэлементного произведения карты пространственного внимания.
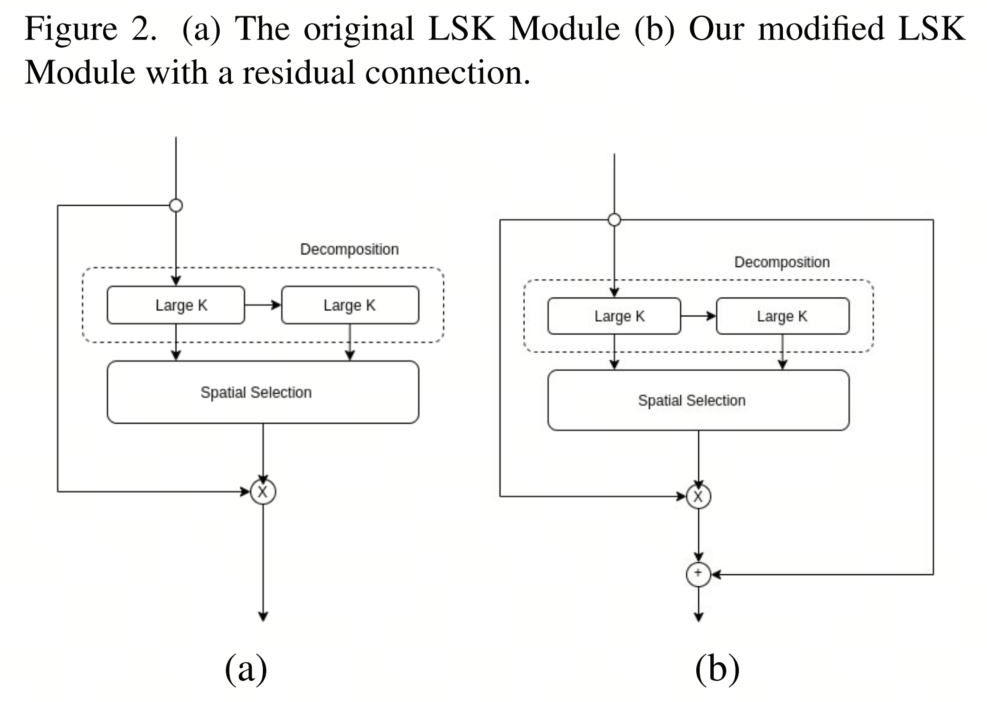
Наконец, авторы строят сеть пирамидных объектов, используя серию блоков понижающей выборки, каждый из которых содержит серию блоков большого выборочного ядра. Эта конфигурация гарантирует, что конечный результат магистральной сети будет состоять из нескольких карт объектов разного разрешения, созданных путем прохождения входных данных через разное количество блоков. В качестве инновационной модификации авторы также вводят остаточную связь параллельно с операцией пространственной фильтрации. Это дополнение позволяет сохранить и передать функции, которые могли быть отфильтрованы предыдущим блоком LSK. На рисунке 2 представлена авторская модификация блока ЛСК по сравнению с исходным блоком.
4.1.2 DiffusionDet
В качестве авторской модели автор выбирает DiffusionDet Head [2]. DiffusionDet — это новая платформа, которая рассматривает обнаружение объектов как процесс диффузии шумоподавления, переходя от шумовых блоков к реальным объектам. На этапе обучения кадры объектов распространяются от основных кадров к случайному распределению, и модель учится, как обратить этот процесс вспять.
На этапе вывода модель постепенно оптимизирует набор случайно сгенерированных блоков для получения окончательного результата. Всесторонняя оценка стандартных тестов, включая MS-COCO и LVIS, демонстрирует превосходные характеристики DiffusionDet на ряде признанных детекторов. Эта работа раскрывает два ключевых момента в области обнаружения объектов:
- Во-первых, хотя случайные блоки значительно отличаются от предопределенных привязок или обучающих запросов, они все же могут служить действительными кандидатами на объекты.
- Во-вторых, обнаружение объектов как репрезентативная задача восприятия может быть решено с помощью генеративных методов.
Модели диффузии требуют нескольких прогонов
Выборки данных генерируются на этапе вывода, что требует многократного применения к исходному изображению. Справляться с приложением на каждом этапе
В случае невозможности вычислений на необработанных изображениях модель делится на кодировщик изображений и декодер обнаружения. Кодер изображения извлекает высокоуровневые функции из необработанного входного изображения, а декодер обнаружения использует эти функции для уточнения прогнозов ограничивающего прямоугольника из зашумленных блоков.
Вдохновленный Sparse R-CNN, декодер обнаружения получает блоки предложений, вырезает объекты RoI из карты объектов и отправляет их в головку обнаружения для регрессии и классификации ограничивающего прямоугольника. Основные различия между DiffusionDet и Sparse R-CNN заключаются в использовании случайных блоков вместо изученных блоков, входных требованиях и головках детектора, которые используют общие параметры на разных этапах для повторного использования на этапе итеративной выборки.
Авторы выбрали эту модель из-за ее преимуществ при обработке зашумленных изображений и фокусировке на небольших целях. В аэрофотоснимках эти две проблемы являются основными проблемами, поэтому авторы считают, что они могут подойти для этой задачи. Автор заменил сеть Swin TransformerBackbone по умолчанию на модифицированную авторскую сеть LSKNetBackbone и инициализировал модель, используя предварительно обученные веса из набора данных COCO.
Augmentations
Увеличение данных — ключевой метод повышения производительности моделей машинного обучения, особенно при анализе аэрофотоснимков. Этот процесс включает в себя создание новых обучающих выборок на существующих изображениях путем применения ряда преобразований. Эти преобразования включают вращение, масштабирование, переворачивание и изменение цвета, что значительно увеличивает разнообразие набора обучающих данных. Это, в свою очередь, дает модели лучшие возможности обобщения новых, ранее неизвестных данных.
Исследования автора сосредоточены на двух основных методах увеличения данных: переворачивании и альбументации. Переворот — это простой, но эффективный метод создания новых обучающих экземпляров путем зеркального отражения исходных изображений по горизонтали или вертикали. Этот подход помогает диверсифицировать набор данных и играет ключевую роль в снижении риска переобучения.
Альбументации — это библиотека дополнения данных, разработанная специально для задач компьютерного зрения. Эта библиотека предоставляет полный набор преобразований изображений, предназначенных для расширения возможностей обобщения модели. Эти преобразования включают в себя геометрические операции, такие как вращение, перемещение, масштабирование, переворот, а также фотометрические настройки, такие как изменение яркости, контрастности и баланса.
Применение этих методов дополнения данных особенно полезно при работе с аэрофотоснимками, которые представляют собой уникальные проблемы. Эти проблемы включают изменчивость размера и разрешения, геометрические искажения, разнообразные условия окружающей среды и сезонные изменения. Благодаря использованию переворота и альбументации авторская модель машинного обучения лучше приспособлена для адаптации и точной интерпретации сложных особенностей аэрофотоснимков.
Loss Functions
Выбор функции потерь является ключевым аспектом в обнаружении объектов, который фундаментально определяет процесс обучения. В общем, функции потерь при обнаружении объектов можно разделить на две категории: потери регрессии ограничивающей рамки и потери классификации. Потери регрессии ограничивающей рамки измеряют сходство между предсказанными и фактическими рамками, принимая во внимание такие свойства, как форма, ориентация, соотношение сторон и межосевое расстояние. Для этого используются различные функции потерь или их линейные комбинации.
Объединение пересечений и взаимное непересечение (IOU): Это широко используемый показатель для оценки точности моделей обнаружения объектов. Убыток IOU определяется как:
GIOU:_Это расширение IOU, GIOU рассматривает минимальную выпуклую оболочку, содержащую блок GT и блок прогнозирования. Он более надежен, чем долговая расписка, поскольку учитывает форму и ориентацию ящиков, тем самым уменьшая влияние смещенных ящиков на окончательную величину потерь.
CIOU: CIOU еще больше расширяет GIOU, принимая во внимание соотношение сторон и межосевое расстояние между коробкой GT и прогнозируемой коробкой. Эта интеграция улучшает сходимость и точность позиционирования и особенно полезна для объектов с разными соотношениями сторон.
Плавная потеря L1: это вариант потери L1. Плавная потеря L1 менее чувствительна к выбросам. Он применяет плавное приближение к абсолютной функции, переходя от потерь L1 к потерям L2 вблизи начала координат. Такой подход приводит к более стабильному процессу обучения и смягчает влияние зашумленных выборок.
(4)。
Для задач классификации подходят различные функции потерь, среди которых особый интерес представляет потеря фокуса. Фокальная потеря работает путем введения поправочного коэффициента, который уменьшает вклад простых экземпляров и фокусируется на более сложных, неправильно классифицированных экземплярах.
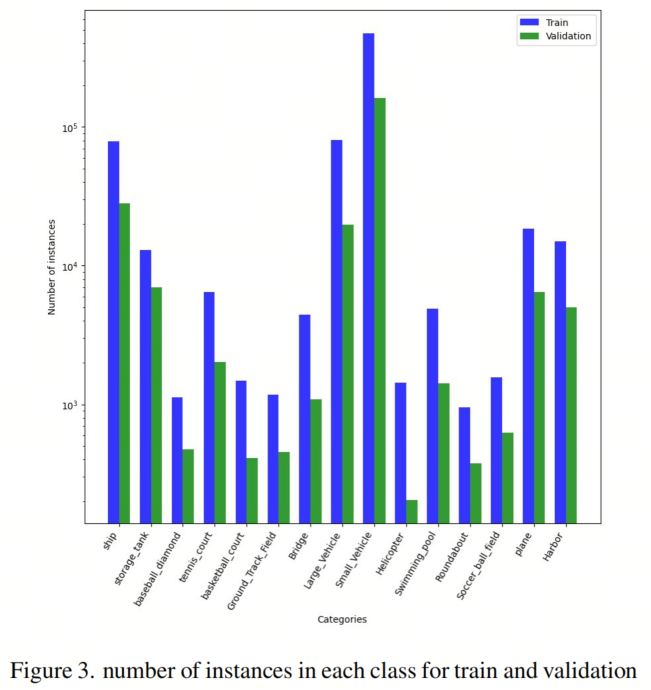
Как показано на рисунке 3, значительный дисбаланс классов может ограничить эффективность потери фокуса. Чтобы решить эту проблему, автор реализовал взвешенную потерю фокуса, которая сочетает в себе принципы потери фокуса с классификационными весами. Этот подход присваивает каждому классу разные веса, позволяя модели отдавать приоритет меньшим классам или классам с более высокими затратами на ошибочную классификацию.
Этот подход может улучшить общую производительность, особенно при решении проблем дисбаланса классов. Уравнение 6 отображает взвешенную потерю фокуса, где
– это весовой коэффициент целевой категории, который для простоты рассчитывается как обратное отношение количества образцов в каждой категории к общему количеству образцов.
Activation Function
Функции активации имеют решающее значение в нейронных сетях, внося нелинейность и позволяя модели изучать сложные закономерности на основе входных данных. В этой статье обсуждаются три расширенные функции активации: Mish, Hardswish и Gaussian Error Linear Units (GELU), каждая из которых привносит уникальные преимущества в возможности обучения модели.
Mish: Mish — это инновационная саморегулируемая функция активации, которая превосходит традиционные функции, такие как ReLU, Leaky Лучшая производительность с ReLU и Swish. Он придает такие свойства, как плавность и немонотонность, способствуя усилению градиентного потока и ускорению сходимости. Функция Миша определяется следующим образом:
Эта функция эффективно способствует более глубокому извлечению признаков и улучшению динамики обучения.
Hardswish: Будучи эффективной в вычислительном отношении альтернативой функции активации Swish, Hardswish снижает вычислительные затраты, обеспечивая при этом сопоставимую производительность. Он находит применение в облегченных моделях, таких как MobileNetV3 и EfficientNet, которые предназначены для достижения низкой вычислительной сложности при сохранении высокой точности. Хардсвиш определяется следующим образом:
Основным преимуществом Hardswish является его эффективность, особенно в средах с ограниченными ресурсами.
Линейная единица гауссовой ошибки (GELU) определяется следующим образом:
GELU основан на функции ошибок Гаусса и применяется в различных моделях, включая BERT и GPT, особенно в задачах обработки естественного языка. Характеристики GELU следующие:
GELU известен тем, что способствует более детальным и вероятностным преобразованиям признаков, что помогает улучшить общую выразительность и производительность модели.
Hyper-parameters
Существует множество гиперпараметров, которые можно настроить для повышения производительности. Автор провел исследование абляции этих гиперпараметров, чтобы изучить влияние каждого гиперпараметра. Эти гиперпараметры включают:
- Скорость обучения: Размер шагов, предпринимаемых во время оптимизации градиентного спуска, определяется скоростью обучения. Это ключевой гиперпараметр,Это влияет на скорость сходимости и Модельпроизводительности. Слишком большая скорость обучения может привести к расхождению.,Слишком маленькая скорость обучения может привести к медленной сходимости.
- Количество ящиков для предложений: Относится к обнаружению объектов Модельсередина,Количество ограничивающих рамок кандидатов, созданных сетью предложений регионов (RPN). Это гиперпараметр,Это влияет на компромисс между отзывом и вычислительной сложностью.
- Соотношение сторон: — это различные масштабы ячеек привязки, используемые при обнаружении объектов. Модель. Они помогают Модели обнаруживать объекты разных форм и размеров.
- Количество тренировочных раундов (эпох) — это количество раз, когда весь набор обучающих данных обрабатывается во время обучения. Большее количество эпох может привести к лучшему обучению, но слишком длительное время обучения может увеличить риск переобучения. Выбор оптимального количества раундов зависит от конкретной задачи и набора данных.
- размер партии (партия size) — количество обучающих выборок, для которых градиент рассчитывается за один шаг оптимизации. Большие размеры пакетов могут привести к более стабильным оценкам градиента, но могут потребовать больше памяти и вычислительных ресурсов.
- Количество изображений в пакете (изображений per batch) — количество изображений, используемых в каждом пакете во время обучения. Этот гиперпараметр связан с размером пакета и влияет на требования к памяти и стабильность оценок градиента.
5 Experiment Setup
Чтобы полностью понять влияние каждой модификации нашей модели, мы использовали систематический подход в наших экспериментах, изменяя только одну переменную за раз. Этот систематический процесс позволил авторам выделить и изучить конкретное влияние каждого изменения. Первоначальное внимание авторов сосредоточено на архитектуре модели. Авторы рассматривают LSKNet как комбинацию Backbone и DiffusionDet Head. Авторы провели пять различных экспериментов, чтобы оценить разницу между изменением позвоночника и головы. В каждом эксперименте авторы меняли только позвоночник или голову.
В частности, автор использовал ResNet и LSKNet в качестве Backbone и скопировал эту конфигурацию для Faster RCNN. Кроме того, Swin Transformer используется в качестве Backbone в сочетании с DiffusionDet, и авторы использовали эту конфигурацию в пятом эксперименте. Для всех последующих экспериментов автор унифицировал архитектуру, используя LSKNet в качестве Backbone и DiffusionDet в качестве Head. Эта конфигурация модели включает GeLU в качестве функции активации и использует фокусную потерю и GIOU в качестве функции потерь. По умолчанию модель также использует немаксимальное подавление (NMS) и соотношение сторон по умолчанию [0,5, 2, 4].
Гиперпараметры установлены следующим образом: размер пакета = 512, количество изображений в пакете = 3, скорость обучения = 0,00005, количество полей предложений = 300 и максимальное количество итераций — 100000.
Авторы осознают влияние повышенной сложности модели из-за ограниченных рабочих аппаратных ресурсов авторов, в частности, ограничений использования одного графического процессора (с 24 ГБ памяти). Это аппаратное ограничение влияет на количество изображений в пакете, количество итераций и другие аспекты, которые могут повысить производительность.
Каждая модификация основана на целях улучшения производительности:
- Функция активации: Миш был выбран для решения проблемы исчезающего градиента.,Известно, что повышает точность модели.,особенно глубокосетьсередина。Hard Swish, известный своей вычислительной эффективностью, в некоторых задачах показал аналогичную или немного лучшую точность, чем ReLU.
- Модификация архитектуры: Автор добавил блок глубиной 32 в начало последовательности Модель. Это расширение предназначено для улучшения обнаружения объектов меньшего размера.,Используйте карты объектов высокого разрешения. также,Чтобы предотвратить возможную потерю важных функций из-за пространственного выбора.,Авторы пытаются использовать остаточные соединения непосредственно из нефильтрованной карты объектов на выходные данные блока LSK.
- Функция потерь: CIOU выбирается для учета перекрытия, соотношения сторон и межцентрового расстояния между прогнозируемыми и наземными блоками истинности. Взвешенный фокус Lossпроходитьсосредоточиться — Более сложный пример устранения классового дисбаланса. Гладкая L1 Потери вводятся для уменьшения влияния выбросов и могут повысить производительность регрессии. Дополнительная эмпирическая настройка гиперпараметров выполняется на основе конкретных свойств и ожидаемых результатов набора данных.
- Соотношение сторона: скорректировано до [0,25, 0.75, 2, 4], чтобы лучше адаптироваться к концентрации данных aspect ratios существенные изменения.
- Дополнительные предложения: Увеличение до 700 с целью повышения точности за счет предоставления более широкой области оценки.
- Больше изображений в партии: количество увеличено с 3 до 4,Чтобы предоставить более полные данные в качестве алгоритма,Расширьте возможности обучения и обобщения.
- Мягкое немаксимальное подавление (Soft NMS): в качестве альтернативы традиционному NMS оно уменьшает количество перекрывающихся блоков вместо их отбрасывания, потенциально сохраняя более точные прогнозы в сценах с близко расположенными или частично перекрытыми объектами.
6 Results & Discussion
В этом разделе результаты каждого эксперимента разделены на,Приводятся последствия этих результатов. Следует отметить, что,Все эксперименты представляют собой всего лишь одну модификацию базовой Модели (состоящей из LSKNet и DiffusionDet).,В качестве ссылки для сравнения производительности.
Model Architectures and Their Impact
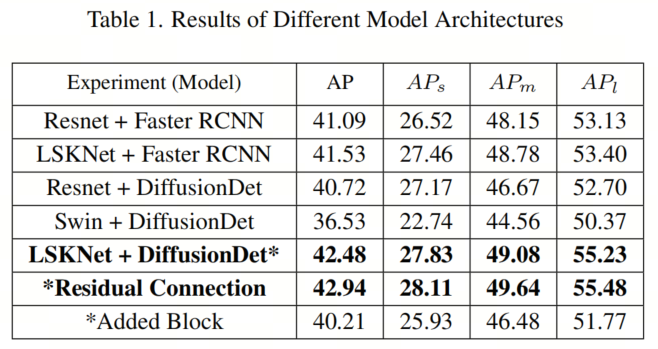
В таблице 1 представлены результаты различных архитектур моделей. Сочетание LSKNet в качестве магистрали с DiffusionDet Head дало наилучшие результаты, улучшив mAP примерно на 1,8% по сравнению с базовой моделью Diffusion с использованием ResNetBackbone. Включение остаточных соединений повышает производительность почти на 0,5%, вероятно, из-за способности сохранять исходные функции изображения перед более глубоким извлечением функций.
Однако, наоборот, добавление нового блока со случайными начальными параметрами вместо использования предварительно обученных весов, как в других блоках, привело к снижению производительности, что указывает на проблемы адаптации этих новых весов в общей магистрали.
Effects of Loss and Activation Functions
Как показано в Таблице 2, использование различных потерь и функций активации в эксперименте в целом улучшило mAP, за исключением взвешенной потери фокуса. Замена GIOU на CIOU немного повышает точность, но требует больше времени для сходимости. Взвешенная потеря фокуса работает плохо, возможно, из-за несбалансированного или чрезмерного веса классов.
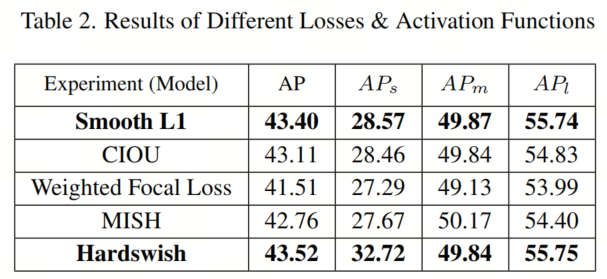
Среди функций активации Hardswish превосходно обнаруживает более мелкие объекты, что имеет решающее значение для повышения точности.
Hyperparameter Tuning and Its Effectiveness
В таблице 3 отражены результаты настройки гиперпараметров, показывающие, что более индивидуальные настройки могут привести к повышению производительности. Изменение соотношения сторон, по-видимому, имеет значительные преимущества для средних и крупных объектов. Наиболее эффектной единственной модификацией является увеличение количества блоков предложений, что увеличивает mAP модели до 44,71%.
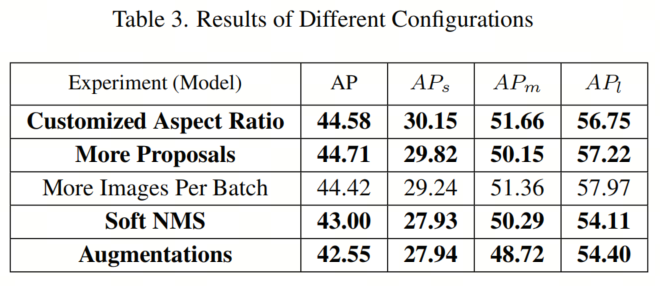
Увеличение количества изображений в пакете также демонстрирует улучшение, хотя иногда это связано с ограничениями памяти графического процессора, которые иногда могут вызывать сбои. Как программная NMS, так и дополнения демонстрируют потенциал улучшения производительности модели.
The Best Model and Its Superior Performance
В процессе поиска лучшей конфигурации модели авторы одну за другой комбинировали различные модификации для повышения производительности. Лучшая модель, представленная в Таблице 4, учитывает эти изменения. Он сочетает в себе DiffusionDet с LSKNetBackbone и добавляет дополнительные остаточные соединения, функцию активации Hardswish, сглаживание L1, Focal Loss и GIOU.
Кроме того, он включает в себя настраиваемые соотношения сторон, дополнительные предложения и улучшения, а также Soft NMS в качестве технологии постобработки. Лучшая модель показала потрясающие результаты на тестовом наборе, особенно среднюю среднюю точность (mAP) 45,7%, что является выдающимся достижением в предыдущей литературе и отчетах. В таблице 4 подробно описаны показатели производительности для каждой категории и объектов различных размеров в тестовых и проверочных наборах.

Как показано на рисунке 4, авторы демонстрируют влияние лучшей модели на случайные изображения набора данных. Результаты показывают, что модель способна точно обнаруживать объекты, особенно более мелкие объекты, которые представляют трудность для базовой модели.
Observations
Результатом наших тщательных экспериментов стала модель, которая значительно улучшает обнаружение объектов на аэрофотоснимках и установила новый эталон производительности. Примечательно, что модель авторов в условиях ограничений одного графического процессора и ограниченного числа итераций является конкурентоспособной по сравнению с современными моделями, которые используют 8 графических процессоров и 180 000 итераций.

Это достижение подчеркивает энергоэффективность и потенциал масштабируемости модели авторов. Несмотря на целенаправленные изменения в архитектуре модели, функциях потерь, функциях активации и гиперпараметрах, а также в рамках аппаратных ограничений, эти модификации значительно улучшают анализ аэрофотоснимков. Эти результаты показывают, что модель авторов может добиться дальнейших значительных улучшений в этой области после доступа к более мощным вычислительным ресурсам.
7 Conclusion
В этом исследовании авторы представили ряд инновационных усовершенствований, которые значительно улучшают хорошие результаты анализа аэрофотоснимков. Подход автора предполагает разработку мощной и сложной магистральной сети, которая объединяет свертки больших ядер, пространственный выбор ядра и сети пирамид функций. Эта магистраль дополнительно усовершенствована, и авторы разработали модель адаптивной диффузии специально для сложности аэрофотоснимков, тем самым улучшая эффект обнаружения и классификации объектов. Предложенные авторами усовершенствования архитектуры модели делают ее более мощным и эффективным инструментом анализа аэрофотоснимков. Авторы провели обширное исследование различных функций активации, в конечном итоге определив наиболее эффективный вариант для конкретного применения авторов.
Чтобы решить повсеместную проблему дисбаланса классов, авторы формулируют взвешенную функцию фокусных потерь и исследуют адаптируемость других функций потерь в граничной регрессии. Всесторонняя проверка авторов и точная настройка гиперпараметров и методов постобработки привели к значительным улучшениям модели оптимизации. Эти усилия привели к значительному увеличению средней средней точности (mAP), достигнув значения mAP 45,7% в наборе тестовых данных. Этот комплексный подход представляет собой важный шаг на пути к повышению точности и надежности анализа аэрофотоснимков.
8 Limitations & Future Work
В этом исследовании было обнаружено несколько ограничений, которые повлияли на способность авторов достичь более высоких показателей производительности. Основным ограничением является объем памяти графического процессора, который ограничивает возможности авторов увеличивать количество изображений в пакете. Это ограничение особенно очевидно, поскольку наши лучшие модели продемонстрировали потенциал повышения точности при больших размерах пакетов, но мы также часто сталкивались с переполнением памяти или сбоями системы.
Другая проблема заключается в том, что в наборе данных COCO нет предварительно обученных весов LSKNet. Эксперименты автора показывают, что предварительно обученные веса COCO обычно превосходят веса ImageNet в задачах обнаружения объектов. Автор частично облегчил эту проблему, используя предварительно обученные веса COCO для DiffusionDet Head, но это привело к несогласованному распределению веса между Backbone и Head. Несмотря на усилия автора по точной настройке модели на COCO, прогресс автора был ограничен из-за нехватки времени и частых сбоев графического процессора.
В дальнейшем работа авторов направлена на устранение этих ограничений. Главные цели авторов — получение графических процессоров большей производительности и увеличение времени обучения на наборе данных COCO. Авторы ожидают, что предоставление большего количества изображений в одном пакете значительно улучшит производительность модели и еще больше продвинет область анализа аэрофотоснимков.
ссылка
[1]. Innovative Horizons in Aerial Imagery: LSKNet Meets DiffusionDet for Advanced Object Detection.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
