Большие данные: введение в Trino и решения для сценариев ETL
Введение
Первоначально Presto был создан в Facebook, чтобы заполнить пробел между запросами в реальном времени и обработкой ETL в Facebook в то время. Основная цель Presto — предоставление интерактивных запросов, которые мы часто называем специальными запросами. Многие компании используют его в качестве механизма вычислений OLAP. Однако, поскольку в последние годы бизнес-сценарии становятся все более и более сложными, в дополнение к сценариям интерактивных запросов многим компаниям также требуется пакетная обработка, однако Presto, как вычислительный механизм MPP, использует базу данных архитектуры MPP для обработки больших объемов данных; наборы данных. Это очень сложная проблема, поэтому общий подход заключается в написании адаптера во внешнем интерфейсе для предварительной обработки SQL. Если это мгновенный запрос, используйте Presto, в противном случае используйте Spark. Эта обработка может в определенной степени решить нашу проблему, но два вычислительных механизма и предыдущая предварительная обработка SQL значительно увеличивают сложность нашей системы.
Чтобы решить эту проблему, PrestoDB запустила такие проекты, как Presto Unlimited и Presto on Spark. О них можно узнать в статьях Presto on Spark: поддержка мгновенных запросов и пакетной обработки и Presto on Spark: расширение Presto. Детали Искры. Сегодня мы поговорим о дороге ETL Trino (PrestoSQL), еще одной ветки Presto. В течение последних шести месяцев сообщество Trino разрабатывало поддержку ETL под кодовым названием Tardigrade, модифицируя код Trino для поддержки ETL.
Что такое проект Тихоходка
Что людям нравится в использовании Trino, так это то, что он быстро выполняет запросы и может решать бизнес-задачи с помощью интуитивно понятных сообщений об ошибках, интерактивного взаимодействия и объединенных запросов. Большой давней проблемой является то, что Trino очень сложно настраивать, настраивать и управлять им для длительных рабочих нагрузок ETL. Вот некоторые проблемы, с которыми вам придется столкнуться:
- Надежное время выполнения. Запросы, которые выполняются часами, могут завершиться неудачей, а их перезапуск с нуля приводит к потере ресурсов и усложняет соблюдение требований ко времени выполнения.
- Экономичный изкластер: для выполнения запроса нам нужен кластер распределенной памяти уровня TB Trino;
- Параллелизм: несколько независимых клиентов могут отправлять запросы одновременно. Некоторые из этих запросов, возможно, придется прекратить и перезапустить через определенный период времени из-за нехватки доступных ресурсов в какой-то момент, что делает время завершения задания более непредсказуемым.
Чтобы решить вышеуказанные проблемы, нам может потребоваться помощь команды экспертов, но для большинства пользователей это невозможно. Цель проекта Tardigrade — предоставить «нестандартное» решение вышеуказанных проблем. Сообщество разработало новую отказоустойчивую архитектуру выполнения, которая позволяет нам реализовать расширенное планирование с учетом ресурсов и детализированные повторные попытки. Вот результаты проекта Tardigrade:
- Когда при длительно выполняющихся запросах возникают сбои, нам не нужно запускать их заново.
- Когда запросам требуется больше памяти, чем доступно в данный момент в кластере, они все равно могут успешно выполняться;
- Когда одновременно отправляется несколько запросов, они могут справедливо распределять ресурсы и работать стабильно.
Trino выполняет всю тяжелую работу за кулисами по распределению, настройке и поддержке обработки запросов. Вместо того, чтобы тратить время на настройку кластера Trino в соответствии с потребностями нашей рабочей нагрузки или реорганизацию рабочей нагрузки в соответствии с возможностями нашего кластера Trino, мы можем потратить время на анализ и предоставление бизнес-ценности.
Tardigrade проектпринцип Введение
Trino — это вычислительная машина без сохранения состояния, поэтому для реализации ETL требуется множество модификаций Trino. С точки зрения реализации между Trino и PrestoDB есть некоторые различия. Чтобы поддерживать как ETL, так и запросы в реальном времени, PrestoDB на ранней стадии разработал проект под кодовым названием Presto Unlimited. Он в основном делил таблицу на сегменты. данные в каждом сегменте были независимыми, поэтому их можно вычислить независимо, если вычисление данных одного сегмента не удалось, просто повторите вычисление, связанное с данными сегмента. Эту часть принципа можно найти в разделе Presto в Spark: Поддержка. мгновенный запрос и пакетная обработка, а также Presto в Spark: пройти Spark для расширения Presto и других статей. Хотя Presto Unlimited решает некоторые проблемы, он не решает полностью проблему отказоустойчивости и не улучшает изоляцию и управление ресурсами. Для реализации этих функций, несомненно, потребуется множество модификаций Presto, и эти задачи на самом деле реализованы аналогичным образом в других движках (таких как Spark, Flink и другие вычислительные движки), а затем реализовать их в Presto — это немного заново изобрести велосипед; PrestoDB Сообщество представило Presto в Spark, который представляет собой интеграцию Presto и Spark. Он использует компилятор/оценку Presto в качестве библиотеки классов и использует RDD API Spark для управления встроенной оценкой Presto. реализация аналогична тому, как Google решил встроить запрос F1 в свою структуру MapReduce.
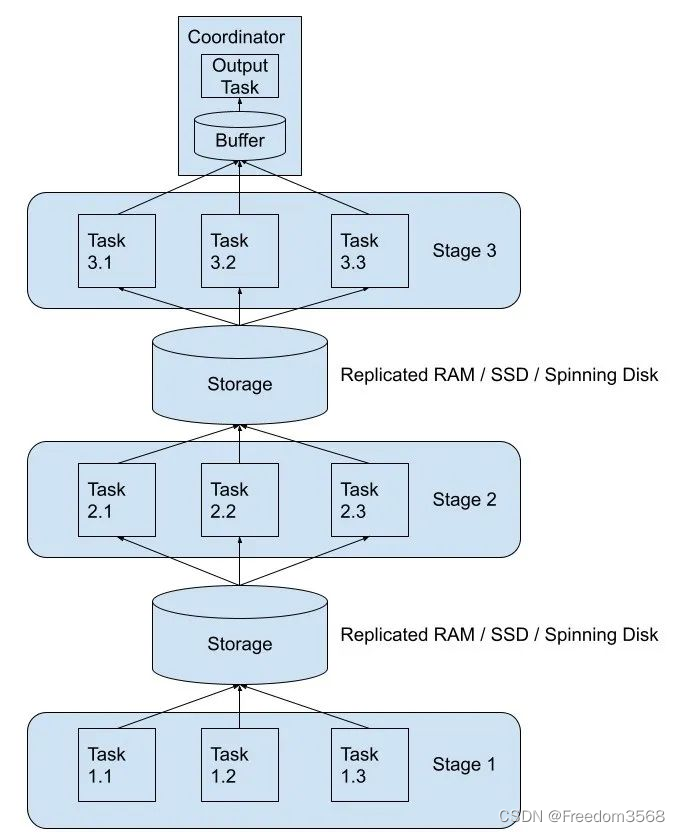
Но, глядя на Trino, идея его реализации отличается от описанной выше. Tardigrade Trino, похоже, реализует основные функции, такие как отказоустойчивость, повтор запроса/задачи и перемешивание непосредственно в Trino. Trino записывает данные восходящего этапа в случайном порядке на диск. Это поддерживает запись данных в AWS A3, Google Cloud Storage, Azure Blob Storage и локальное хранилище файлов (это для тестирования). .



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
