Большие данные Python PySpark (2) Установка PySpark
Установка PySpark
- 1. Очистите библиотеку PyPi, указатель пакетов Python. Все пакеты Python можно загрузить отсюда, включая pyspark.

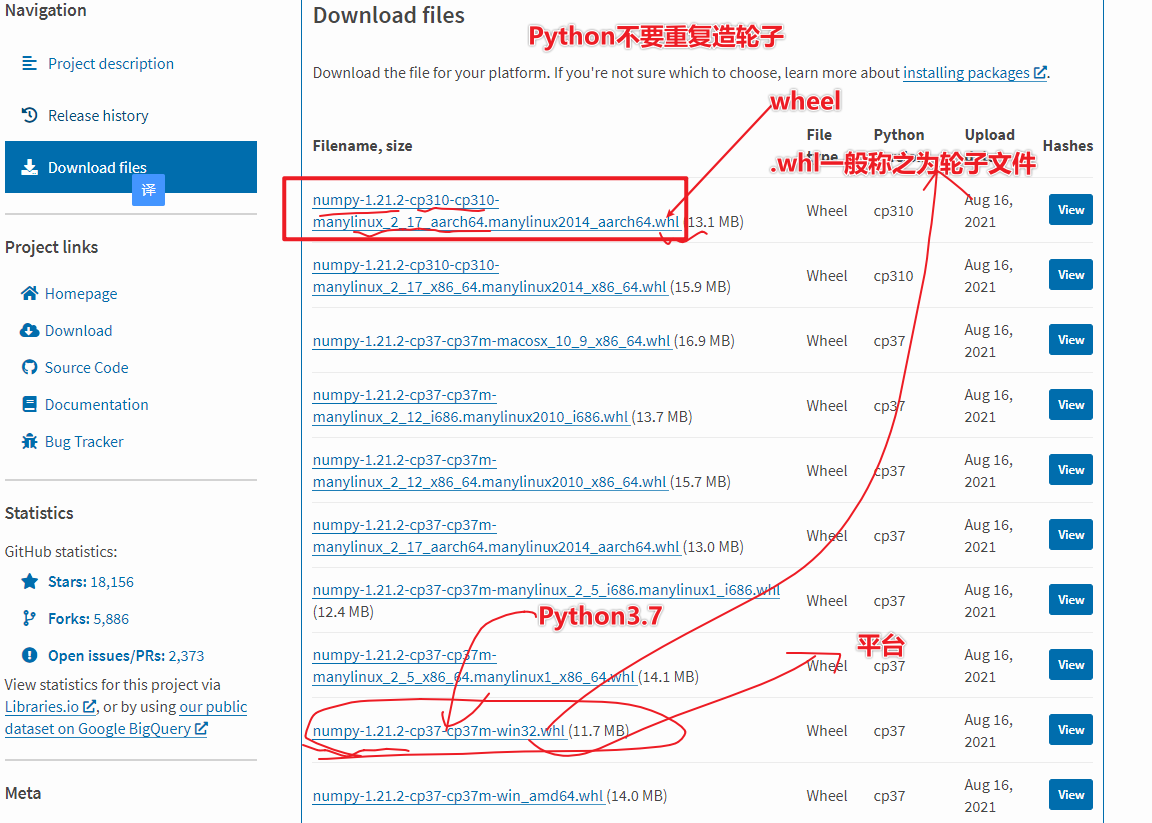
- 2. Почему PySpark постепенно становится мейнстримом?
- http://spark.apache.org/releases/spark-release-3-0-0.html
- Python is now the most widely used language on Spark. PySpark has more than 5 million monthly downloads on PyPI, the Python Package Index.
- Не забудьте использовать конкретную версию при установке определенной версии, pip install pyspark2.4.5.
- Для локальной установки используйте pip install pyspark, чтобы установить последнюю версию по умолчанию.
PySpark Vs Spark
Python как основной язык разработки для Spark
Установка PySpark
1-Как установить PySpark?
- Сначала установите anconda и установите pyspark на основе anaconda.
- anaconda — это среда обработки данных. Если вы устанавливаете anaconda, вам не нужно устанавливать python. В нее интегрировано более 180 инструментов обработки данных.
- Примечание. anaconda аналогична cdh и может решить проблему зависимости версии установочного пакета.
Установка Анаконды для Linux
2-Как установить анаконду?
- Перейдите на официальный сайт anaconda, чтобы скачать необходимые файлы для системы Linux Anaconda3-2021.05-Linux-x86_64.sh.
- Загрузите в Linux и выполните установку sh Anaconda3-2021.05-Linux-x86_64.sh или bash Anaconda3-2021.05-Linux-x86_64.sh
- Непосредственно перейдите к следующему шагу и завершите.
- Конфигурация переменных среды,Справочные учебные материалы
3-У Анаконды много программного обеспечения
- Интерактивный Python IPython имеет очевидные преимущества перед собственным Python с точки зрения автодополнения кода и выделения ключевых слов.
- Jupyter Notebook: интерактивная платформа для интерактивного кодирования, запускаемая веб-приложениями (веб-платформа).
- 180+ наборов инструментов
- В чем разница между кондой и пипом?
- И conda, и pip устанавливают пакет Python
- список conda может отображать информацию о версии пакета
- conda может создать независимую среду песочницы, чтобы избежать конфликтов версий и добиться независимости от среды.
- conda create -n pyspark_env python==3.8.8
4-Conda можно использовать для создания виртуальной среды в Anaconda.
- Здесь есть много способов установить pyspark.
- (Мастер) Первый метод: установить напрямую pip install pyspark
- (Мастер) Второй метод: используйте виртуальную среду для установки pyspark_env, pip install pyspark
- Третий способ: Загрузите соответствующий пакет на PyPi и установите его.
5-Как просмотреть виртуальную среду, созданную Conda?
- conda env list
- conda create -n pyspark_env python==3.8.8
- pip install pyspark
Установка PySpark
- 1-Использовать установку базовой среды
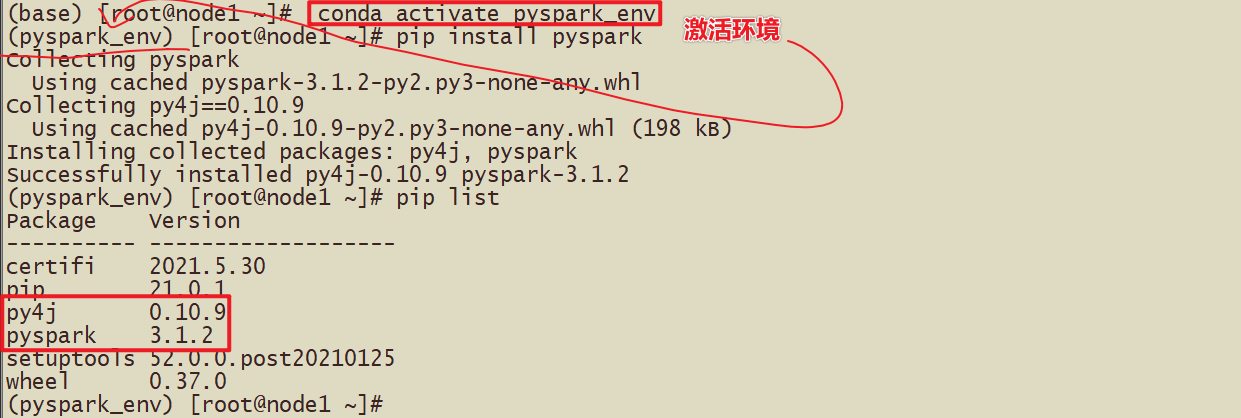
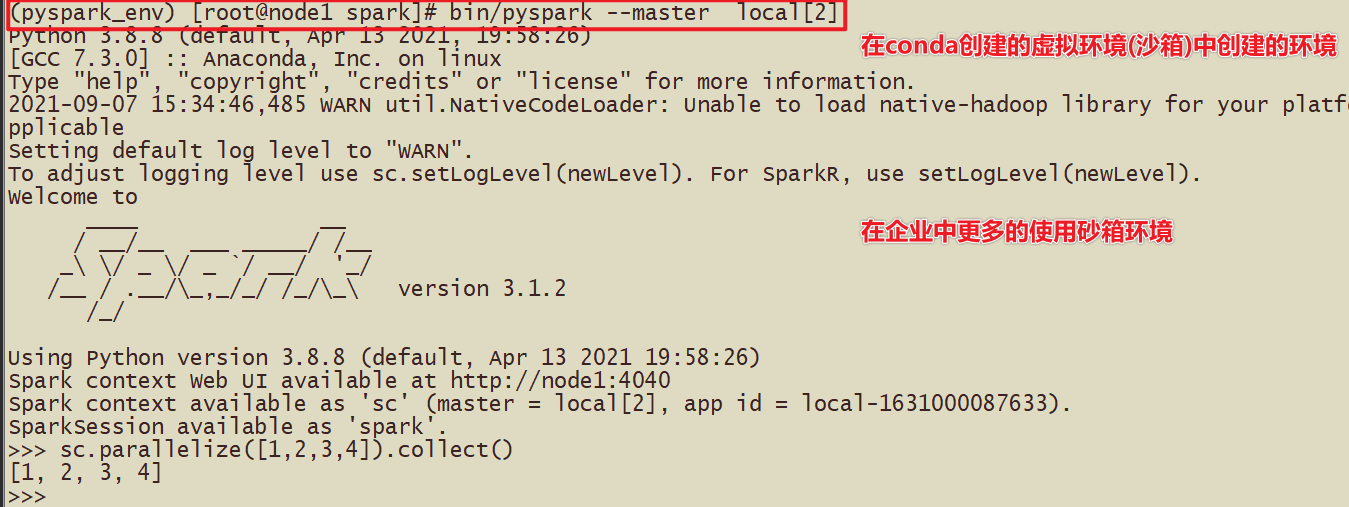
- 2-Установите, используя метод pyspark_env.
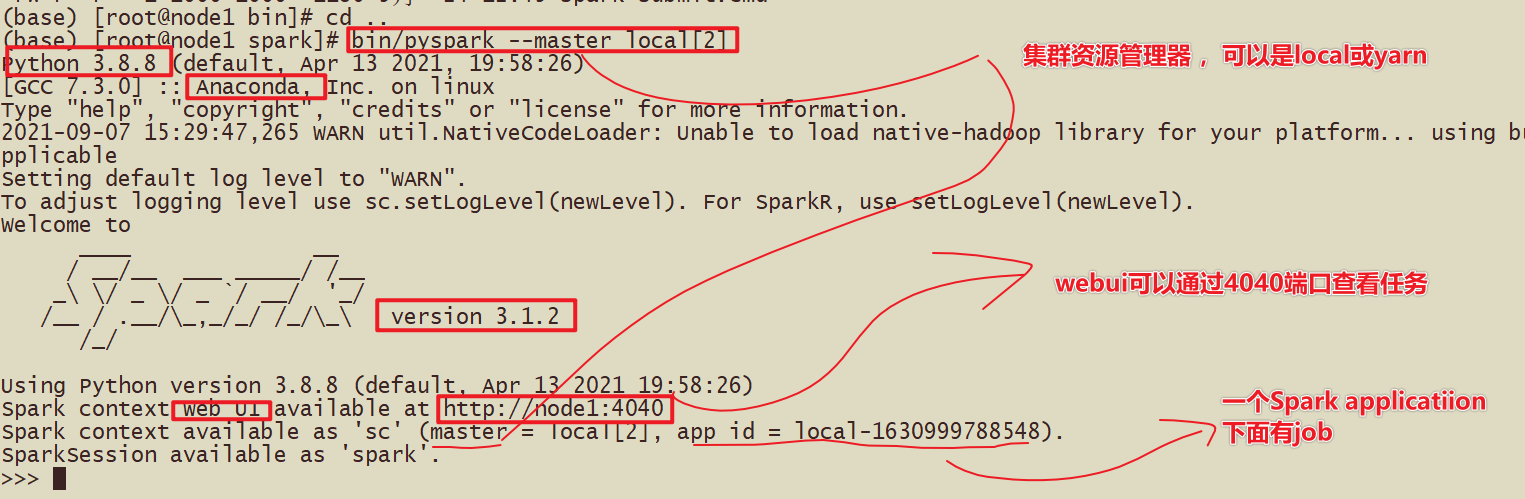
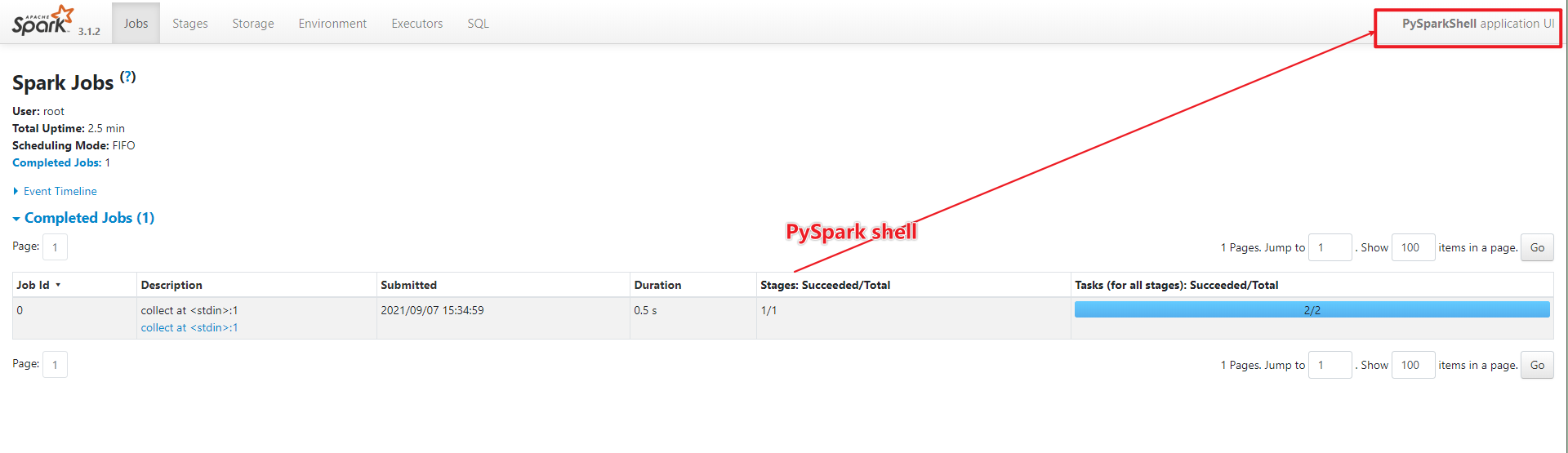
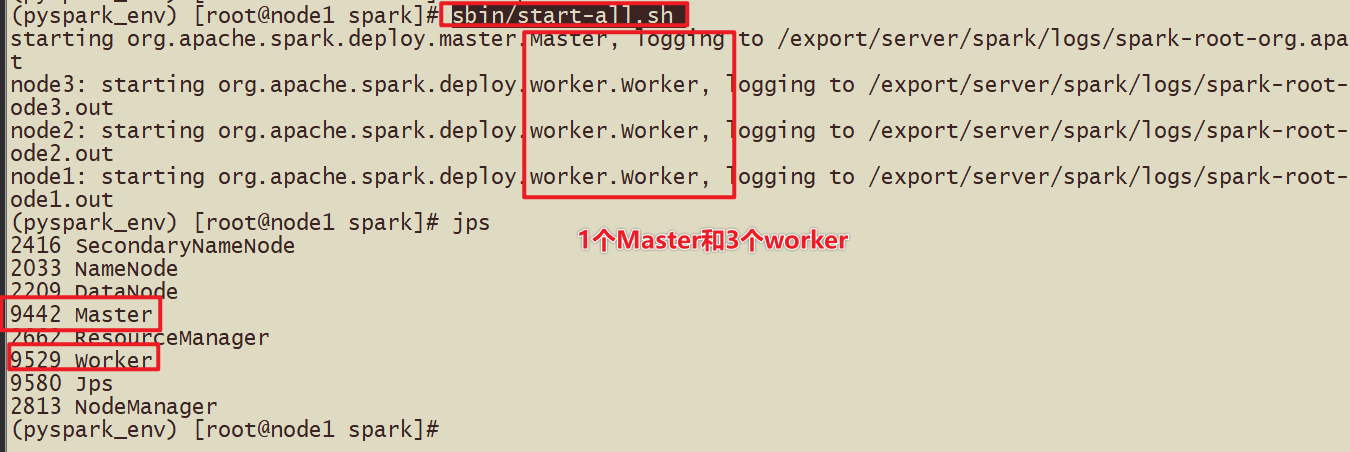
- Посмотреть результаты запуска
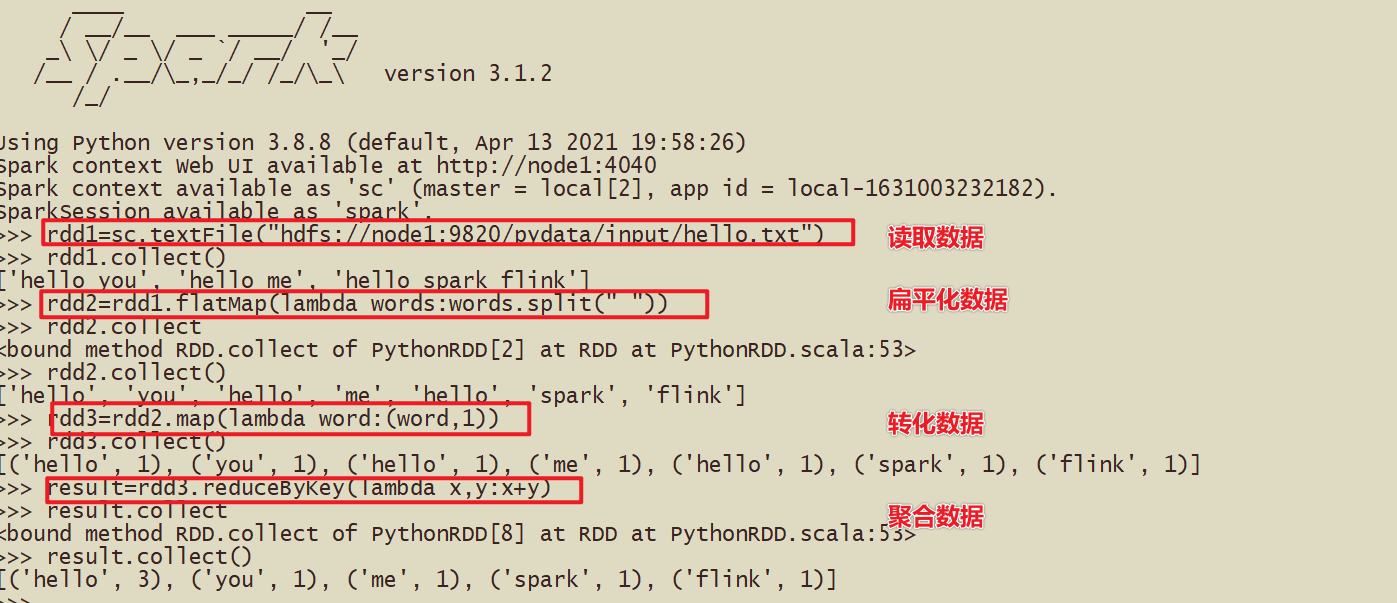
- Простая демонстрация кода
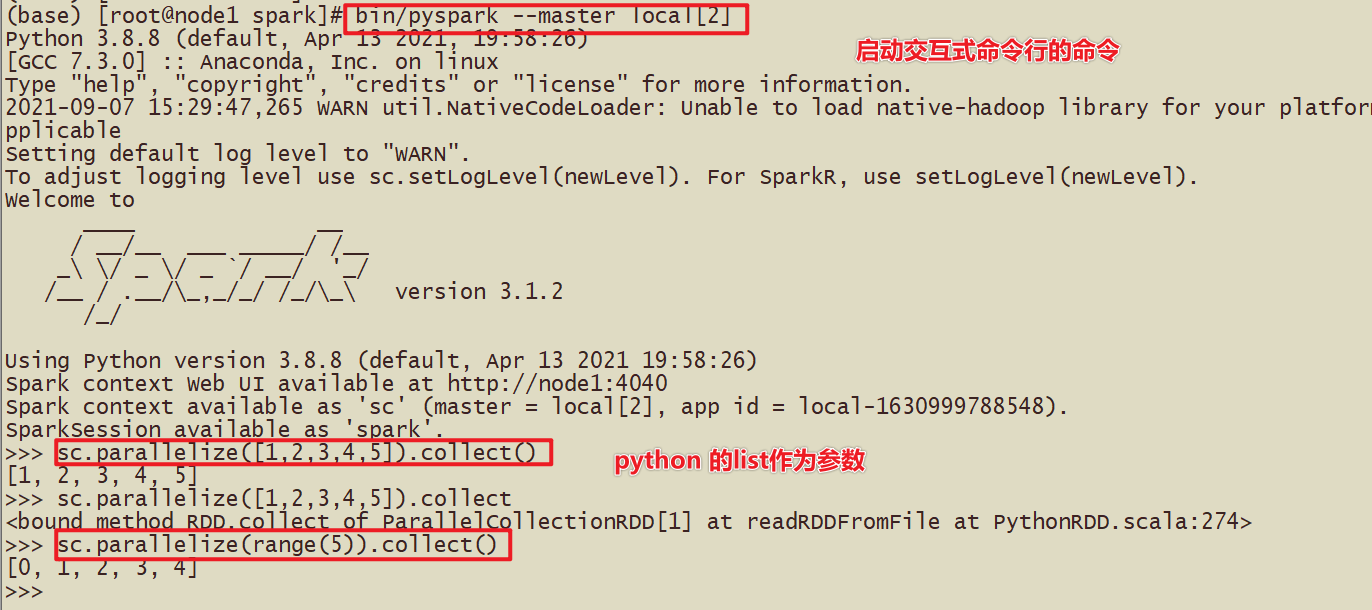
- Дополнение в виртуальной среде
- webui
- Уведомление:
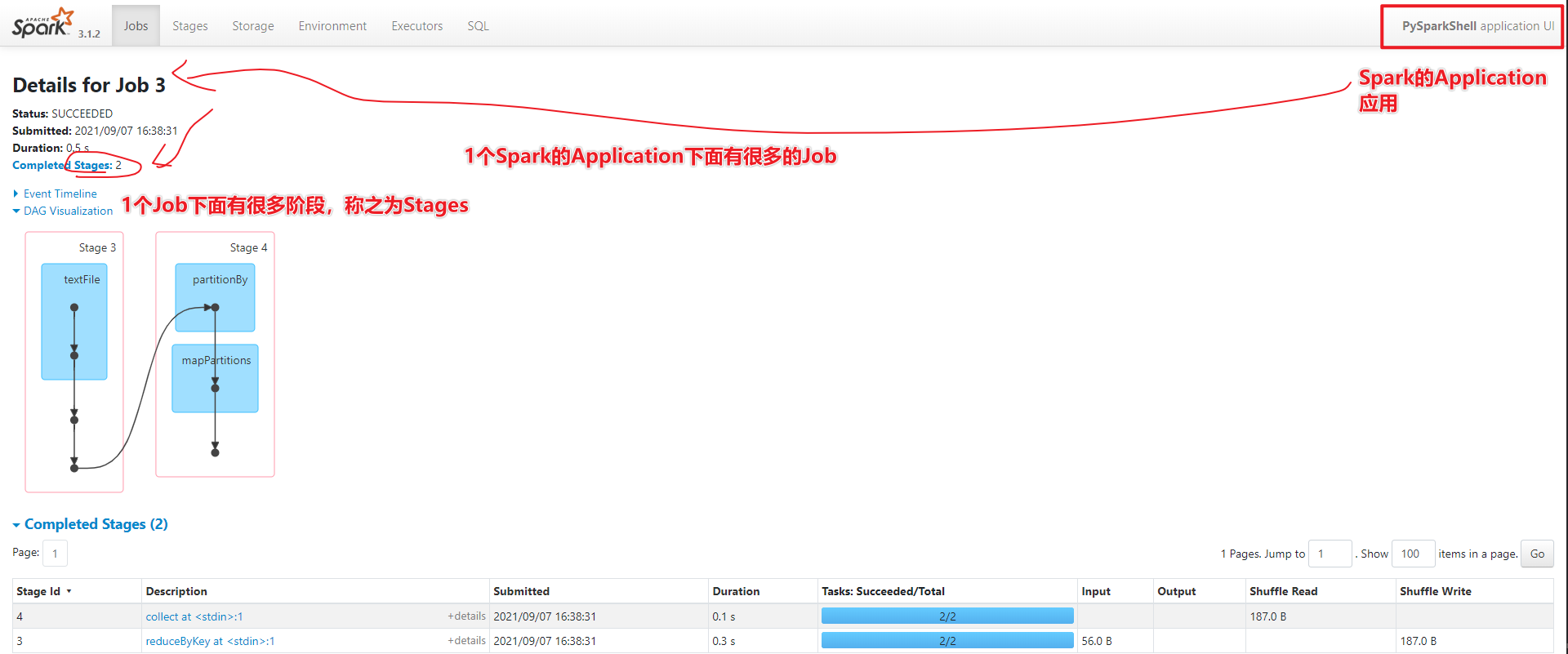
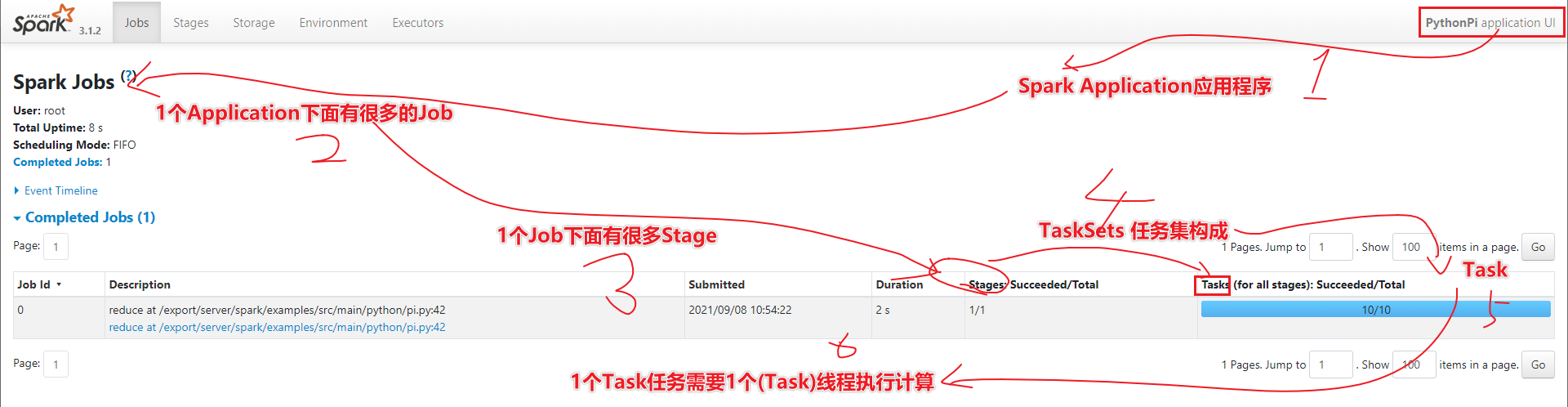
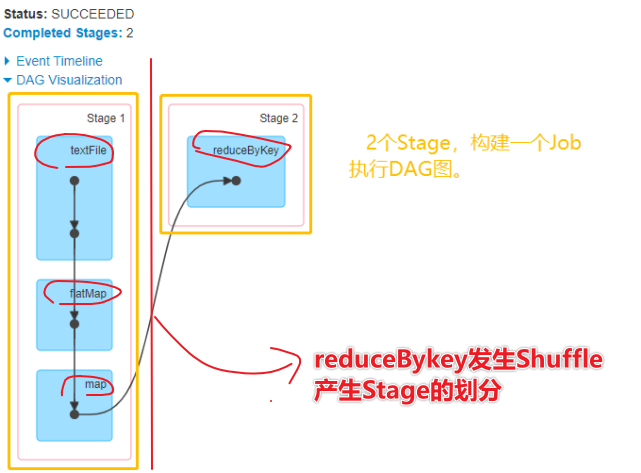
- По запросу 1-1 Spark есть много вакансий.
- В разделе 2-1 Jobs много этапов.
Настройки среды Jupyter
Страница мониторинга
- Порт 4040
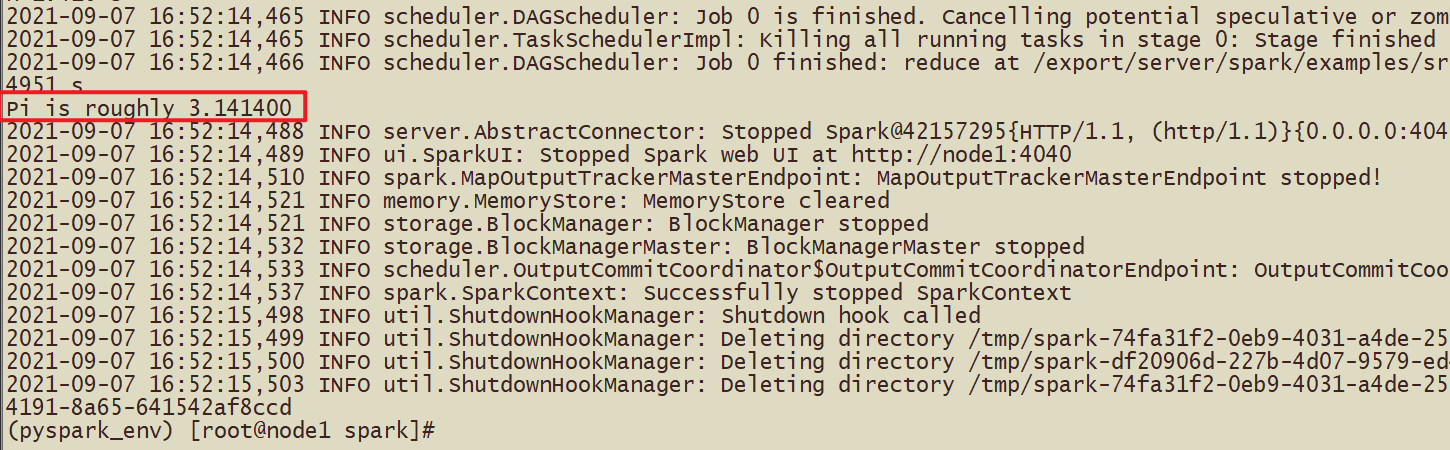
бегущее пи
Обзор возможностей Hadoop
hadoop jar xxxx.jar 100
yarn jar xxxx.jar 1000
Выполнение задачи мистера
В Spark также есть соответствующий код для отправки задач.
spark-submit Отправьте код расчета для числа Пи */examples/src/main/python/pi.py*
Отправленная команда:
bin/spark-submit --master local[2] /export/server/spark/examples/src/main/python/pi.py 10 или
# Для решения числа Пи на основе метода Монте-Карло требуется параметр 10 или количество раз, представленное 100.
bin/spark-submit \
--master local[2] \
/export/server/spark/examples/src/main/python/pi.py \
10
Метод Монте-Карло для решения ПИ
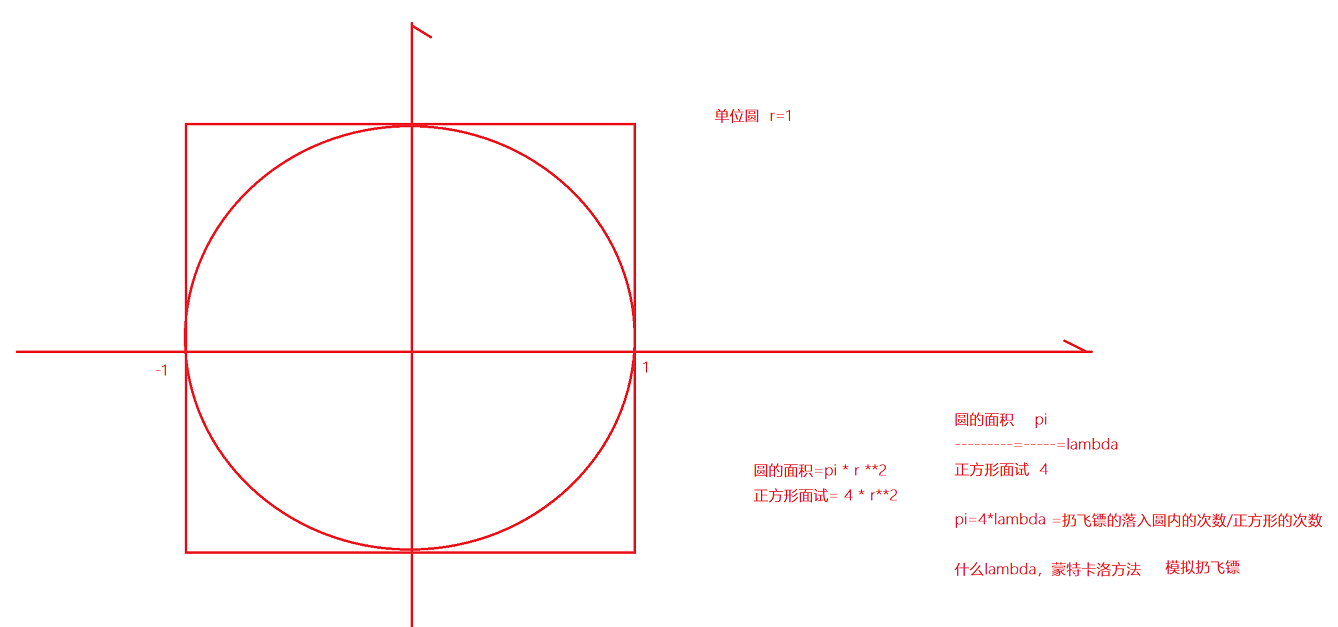
Используемый способ метания дротиков в крайнем случае можно разделить на количество попаданий дротика в круг на количество попаданий дротика в квадрат.
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 10 10
Первые 10, используемые в задачах отправки Hadoop, представляют задачу карты, а вторые 10 представляют количество бросков для каждой задачи карты.
Значение параметра 10, отправленного с помощью spark-submit, — это количество бросков.
Простой py-код
def pi(times): # раз означает, сколько раз он попадет в квадрат x_time = 0 for i in range(times): # Сколько попадает в круг x = random.random() y = random.random() if x * x + y * y <= 1: x_time += 1 return x_time / times * 4.0
print(pi(10000000))#3.1410412Настройка среды — автономная
- Завершена настройка локальной среды Spark.
- Завершено создание локальной среды PySpark Spark.
- Полная отправка задачи искровой отправки на основе PySpark.
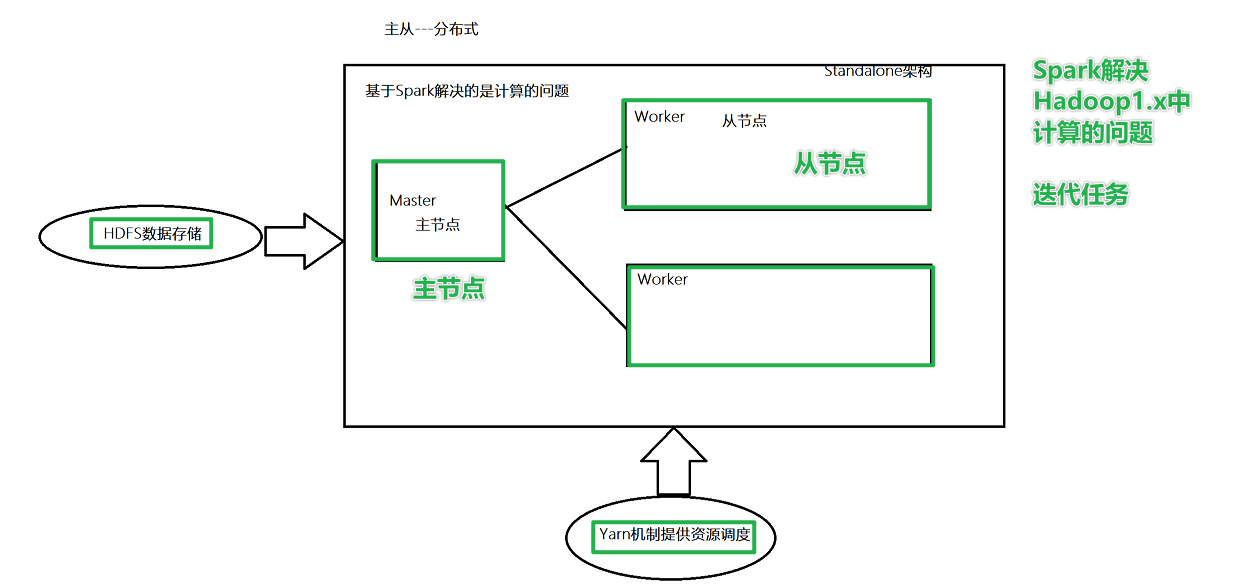
Автономная архитектура
- Если вы измените конфигурацию,Как изменить?
- 1-Установите, кто является главным узлом, а кто — подчиненным узлом.
- узел1 — главный узел, узел1, узел2, узел3 — подчиненные узлы.
- 2- необходимо объявить в файле конфигурации,
- Какой узел является главным узлом, имя хоста и номер порта главного узла (связь)
- Какой узел является подчиненным узлом, имя хоста и номер порта подчиненного узла
- 3-Феномен: введите искровую оболочку или pyspark.,Порт 4040Отображение webui откроется,Но как только интерактивная командная строка закроется,Wenui недоступен,Сервер исторического журнала Spark необходим для просмотра ранее отправленных задач.
ролевой анализ
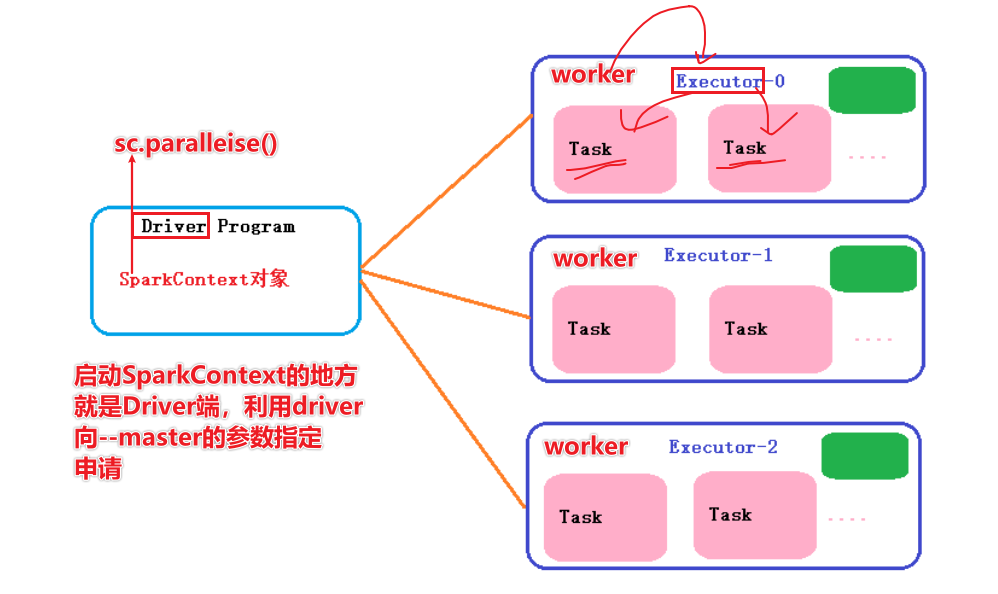
Главная роль, узел управления, Запустите процесс с именем Master, *Существует только один главный процесс*(HAкроме шаблона) Роль работника, Рабочий узел, запустите именованный Рабочий процесс., Рабочий процесс**** минимум 1, До неограниченного**** Главный процесс отвечает за управление ресурсами. И когда программа запущена, Создайте драйвер-менеджер для текущей программы. Драйвер: Драйверы, которые используют SparkCONtext для подачи заявки на ресурсы, называются драйверами. Они сообщают, сколько процессора или памяти требуется для задачи. Рабочий процесс отвечает за выполнение работы, Сообщить о статусе Мастеру, И следуйте инструкциям программы Драйвер и создайте Исполнителя для работы. В Работнике есть Исполнитель, и Исполнитель фактически выполняет работу.
Кластерное планирование
Кто Мастер, а кто Работник? узел1: мастер/работник узел2: раб/работник узел3: раб/работник
Установите Python3 для каждой машины
Процесс установки
- 1-Обзор файла конфигурации
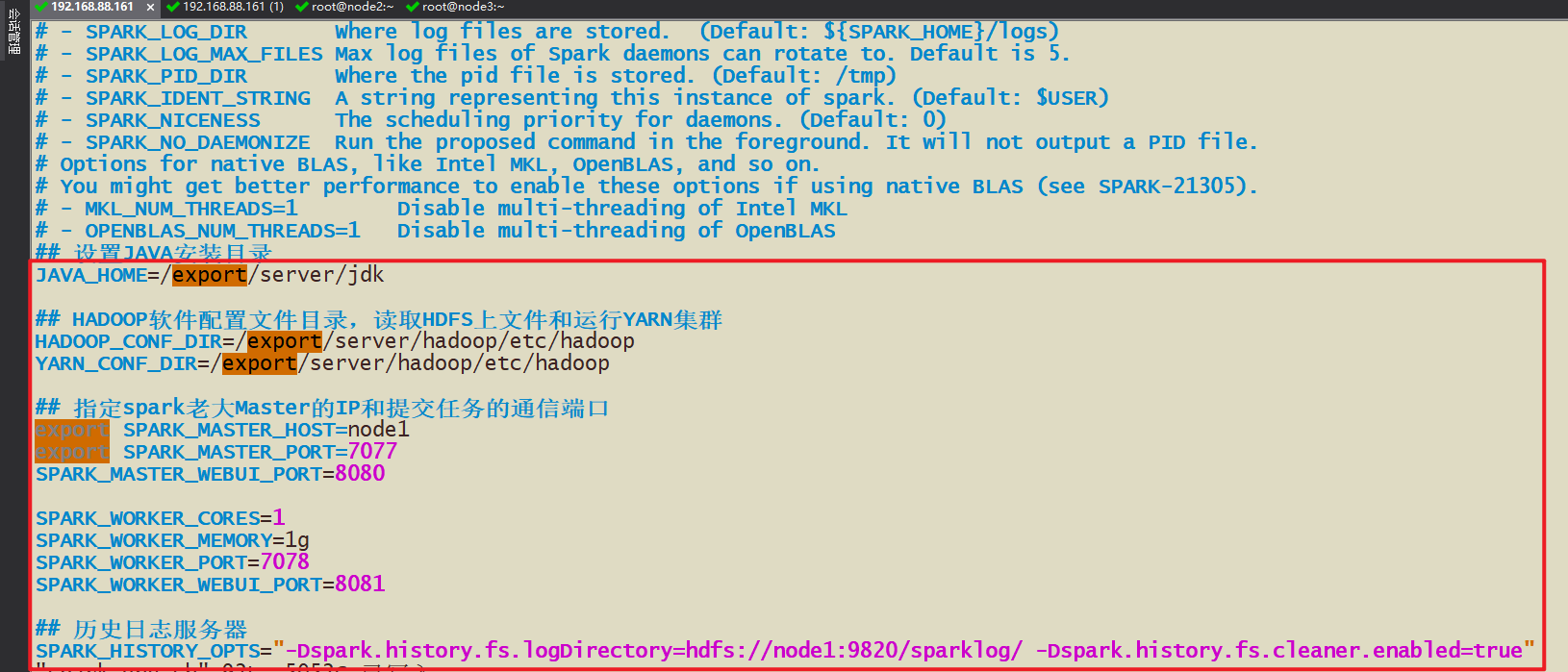
- spark-env.sh Конфигурация главного узла и подчиненного узла, а также сервера исторических журналов
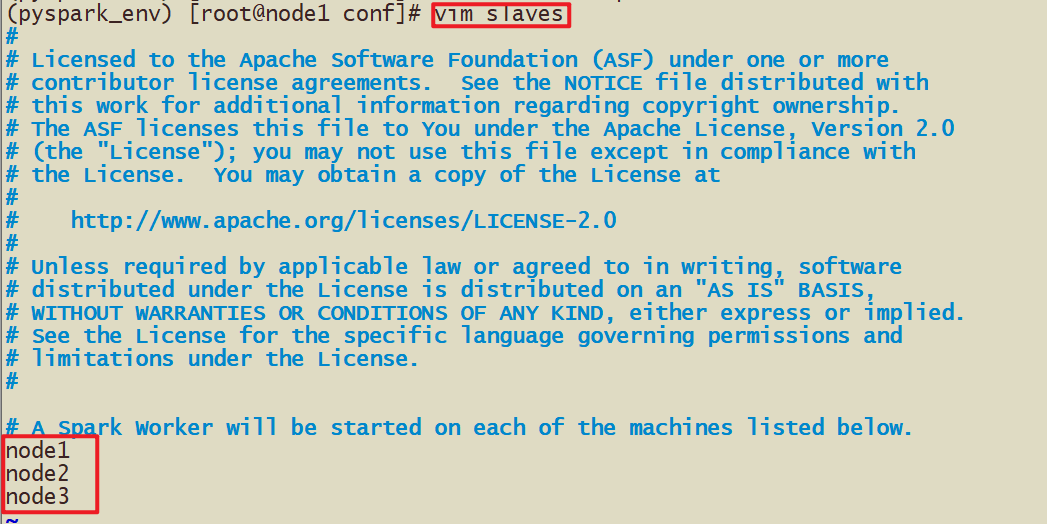
- рабочие из списка узлов
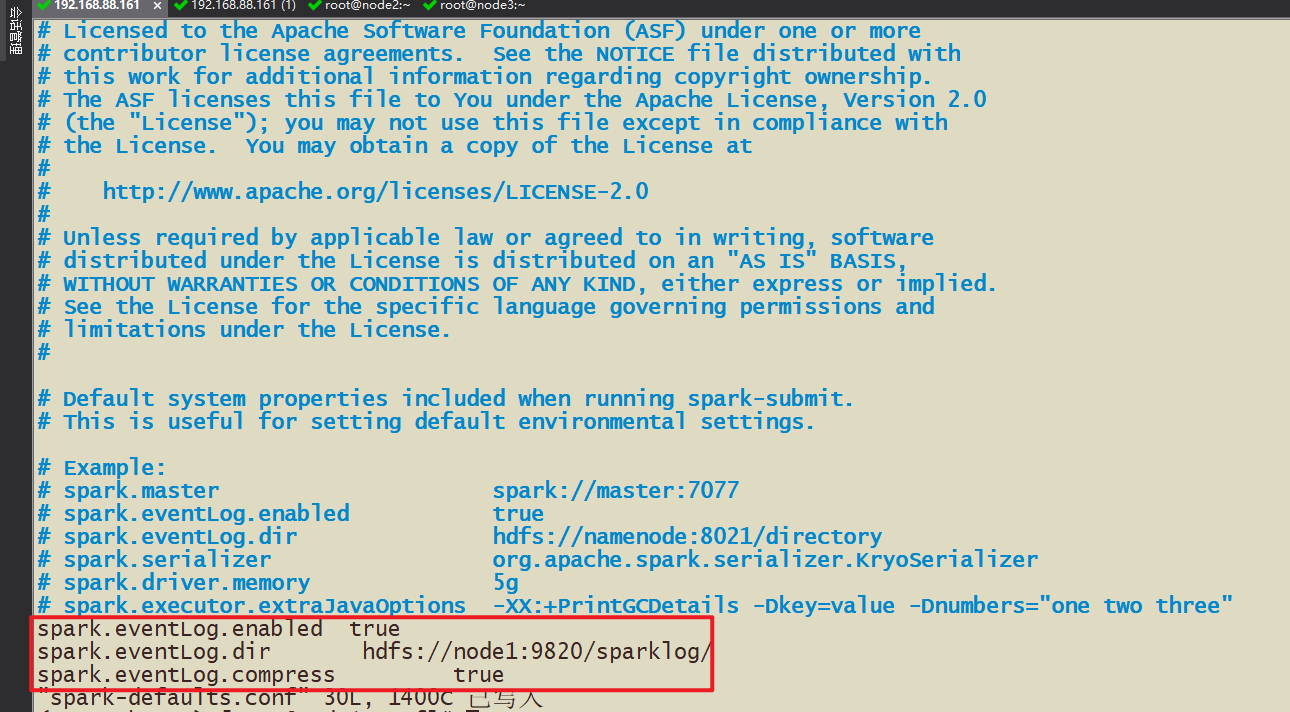
- Spark-default.conf Spark Framework запускается по умолчанию Конфигурация,Здесь вы можете установить, включен ли сервер исторических журналов.,Есть ли сжатие и т. д., записанные в этом файле конфигурации?
- 2-Процесс установки
- 2-1 Изменить подчиненный узел Файл конфигурации рабочих
- 2-2 Измените файл конфигурации spark-env.sh.
- hdfs dfs -mkdir -p /sparklog/
- 2-3 Измените файл конфигурации spark-default.conf.
- 2-4 Уровень отображения журнала конфигурации (опущено)
тест
WebUi
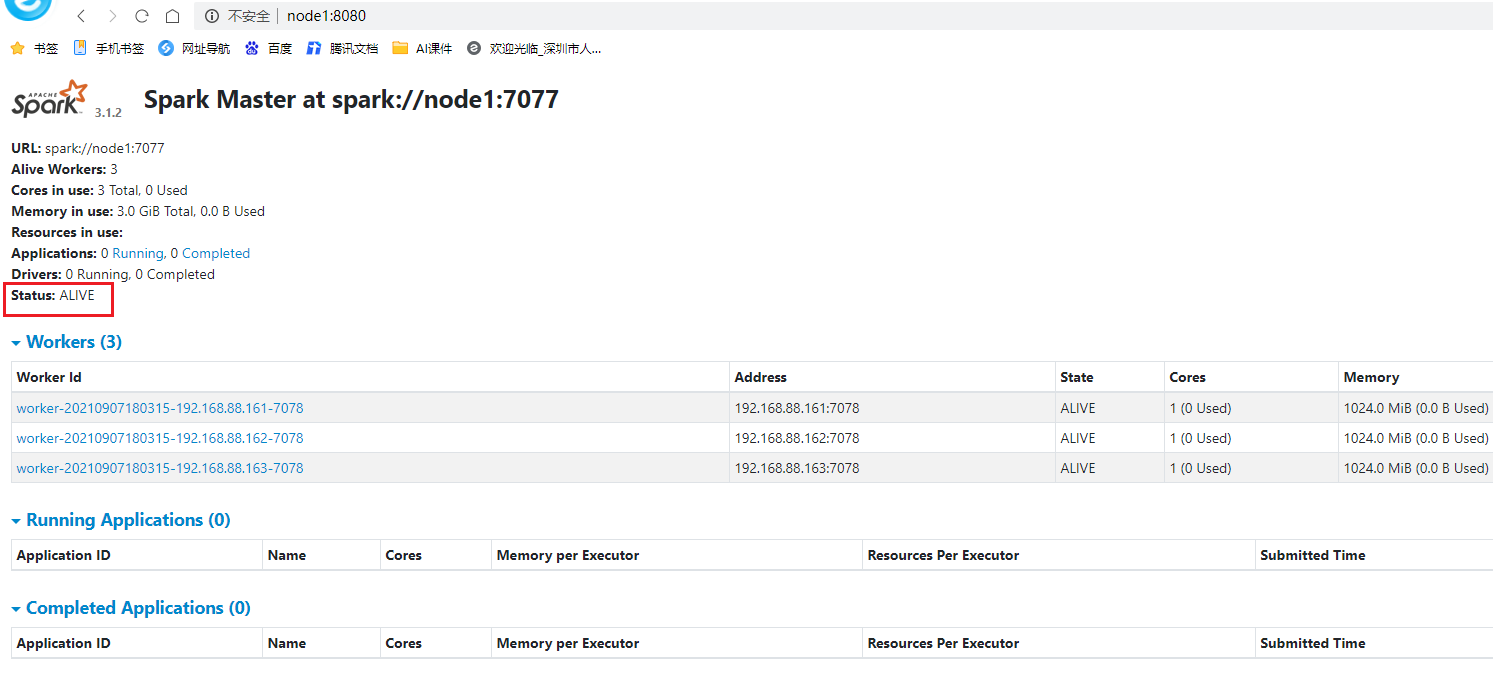
(1)Spark-shell
bin/spark-shell --master spark://node1:7077
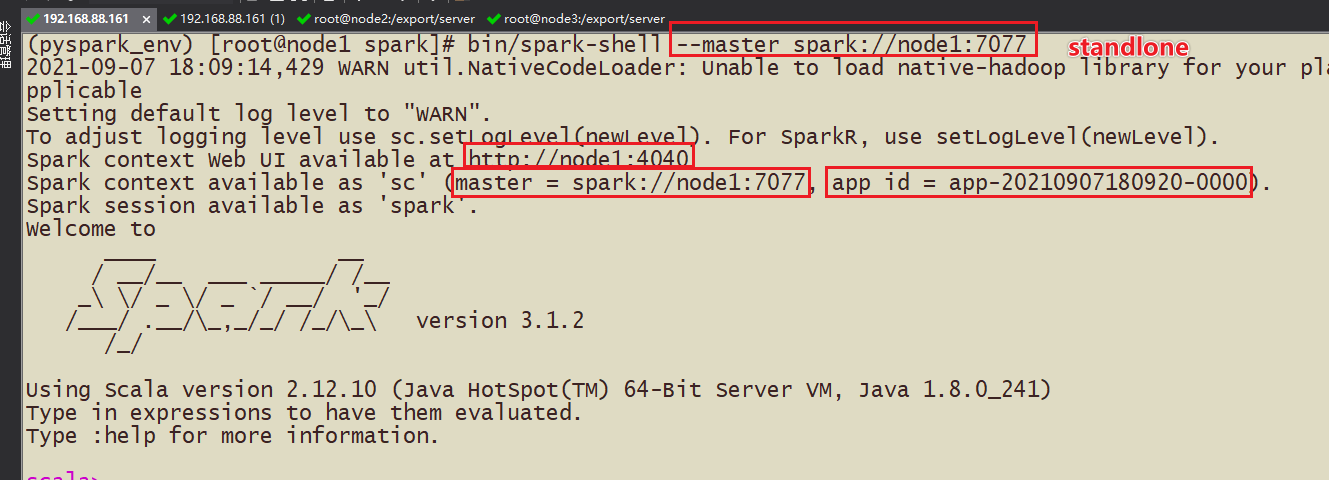
(2)pyspark
Предварительное условие: Anaconda должна быть установлена на всех трех компьютерах, а также должен быть установлен пакет PySpark3.1.2.
шаг:
Если вы используете crt для загрузки файлов, обычно используйте команду rz, yum install -y lrzsz
1- Подготовьте анаконду на 3 виртуальных машинах
2-Установить anaconda, sh anaconda.sh
3. Установите pyspark. Обратите внимание, что переменные среды не обязательно настраиваются. Вы также можете перейти непосредственно в папку.
4-тест
Вызов: bin/pyspark --master spark://node1:7077
(3)spark-submit
#Скрипт на основе Standalone
#driver применяется к ресурсам задания диспетчеру ресурсов кластера --master.
#Процесс выполнения вычислений находится в воркере У воркера много исполнителей (процессов), и под одним исполнителем находится множество задач (потоков).
bin/spark-submit \
--master spark://node1:7077 \
--driver-memory 512m \
--executor-memory 512m \
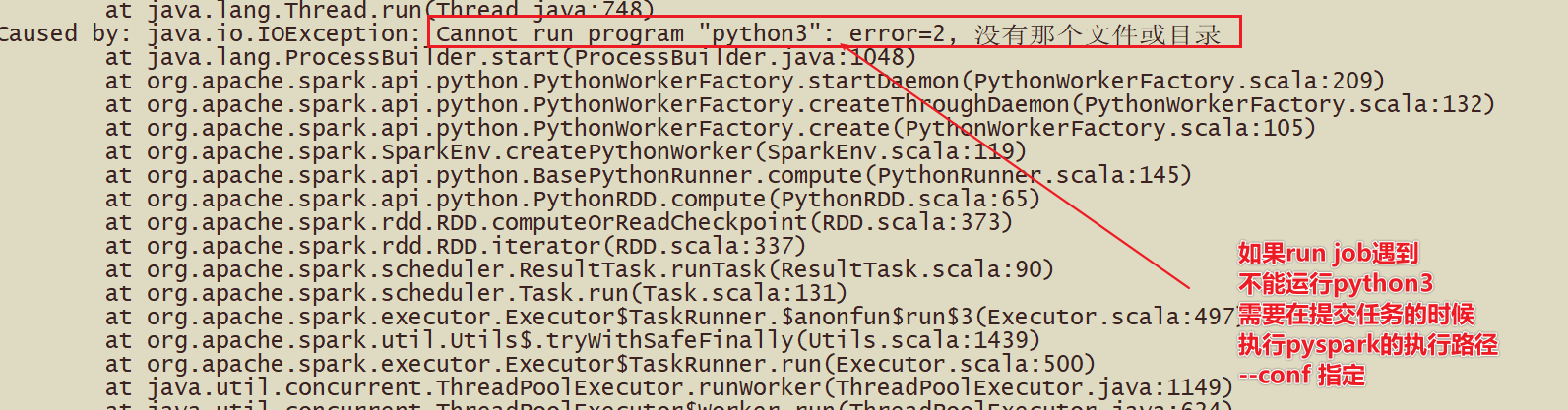
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/server/spark/examples/src/main/python/pi.py \
10*полныйАрхитектура приложения Spark
- Два основных драйвера и исполнителя
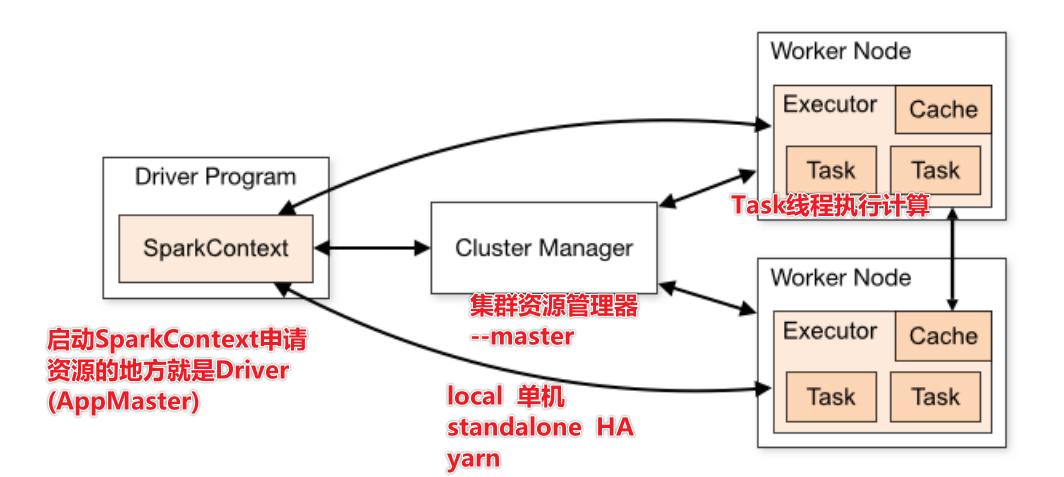
- От первоначального представления до окончательного выполнения расчета пользовательская программа должна пройти следующие этапы:
1) Когда пользовательская программа создает SparkContext, вновь созданный экземпляр SparkContext будет подключен к ClusterManager. Менеджер кластера выделит вычислительные ресурсы для этой отправки и запустит Исполнителя на основе информации о процессоре и памяти, установленной при отправке пользователем. 2) Драйвер разделит пользовательскую программу на разные этапы выполнения. Каждый этап выполнения состоит из набора одинаковых задач. Эти задачи действуют на разные разделы обрабатываемых данных. После завершения разделения этапов и создания Задания Водитель отправляет Задание Исполнителю; 3) После получения Задачи Исполнитель загрузит зависимости времени выполнения Задачи. После подготовки среды выполнения Задачи он начнет выполнение Задачи и сообщит Водителю о статусе выполнения Задачи; 4) Драйвер будет обрабатывать различные обновления статуса в зависимости от статуса выполнения полученной задачи. Задачи делятся на два типа: одна — Задача «Перетасовать карту», которая перетасовывает данные и сохраняет перетасованные результаты в файловую систему узла, где расположен Исполнитель, другая — Задача «Результат», отвечающая за генерацию данных результата; ; 5) Драйвер будет непрерывно вызывать Задачи, отправлять Задачи на исполнение Исполнителю и останавливаться, когда все Задачи выполняются корректно или лимит времени выполнения превышен, а выполнение по-прежнему не удалось;
Настройка среды Автономная HA
- Обзор: автономный режим независимого развертывания Spark использует структуры Master и Worker для подачи заявок на ресурсы и выполнения вычислений.
- Вопрос: Если что-то пойдет не так с Мастером и весь кластер Spark не сможет работать, что делать?
- Решение. При использовании главного и резервного узлов необходимы главный узел и резервный узел. При выборе ZK в случае выхода из строя главного узла резервный узел может взять на себя управление главным узлом и продолжить выполнение вычислений.
Высокая доступность высокой доступности
- Схема архитектуры
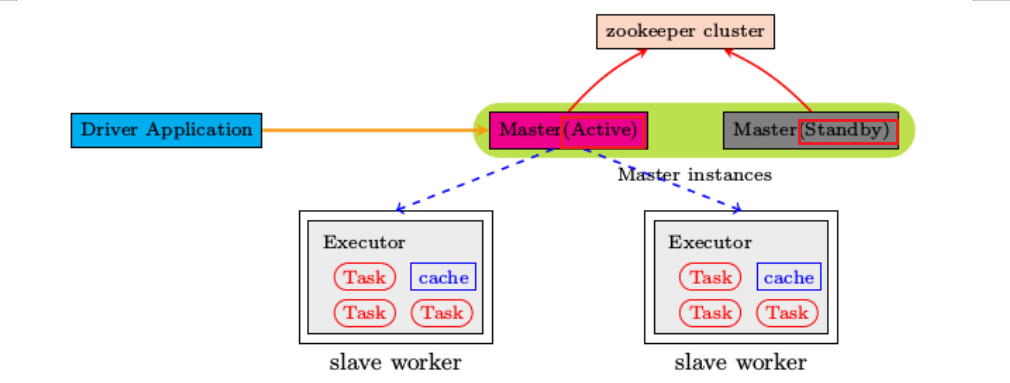
Реализация высокой доступности на базе Zookeeper
- Как реализовать Конфигурацию HA?
- 1-Вам необходимо изменить IP-адрес или хост главного устройства в spark-env.sh и закомментировать его, поскольку это зависит от выбора zk.
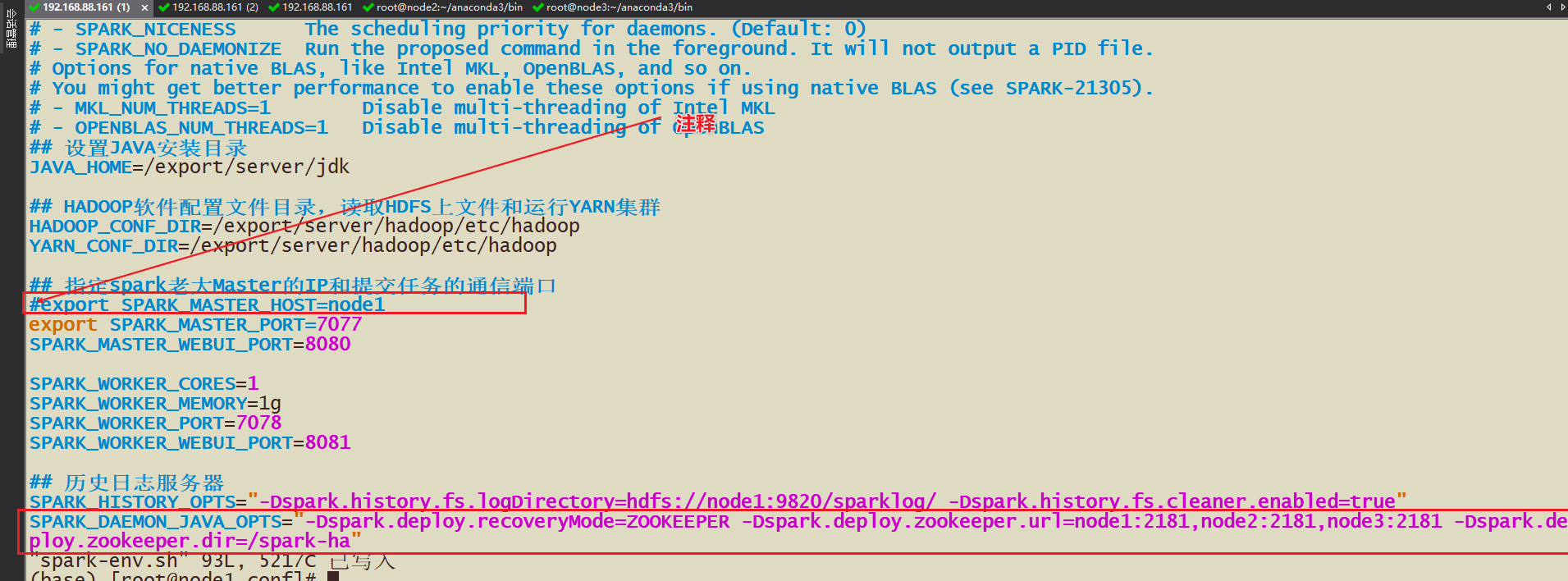
- 2-Запуск zk, статус zkServer.sh
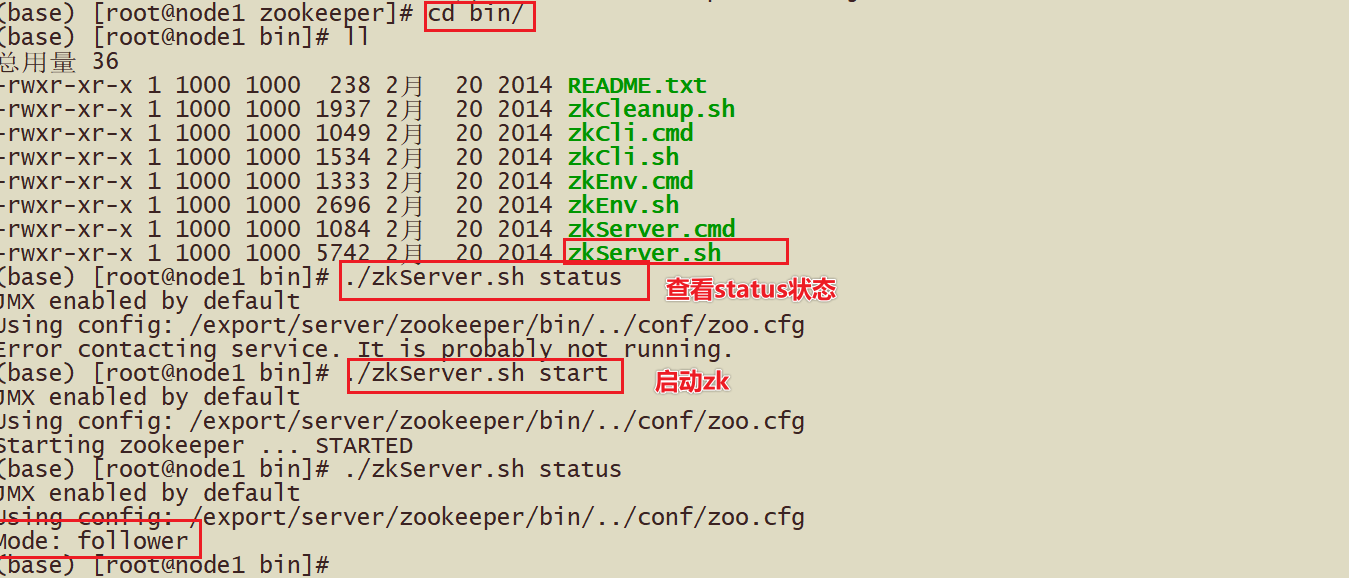
- 3-Необходимо запустить мастер-команду узла2 на исходной основе start-master.sh.
- 4. Перезапустите автономный кластер Spark, а затем выполните задачу.
- sbin/stop-all.sh
- sbin/start-all.sh
- webUI
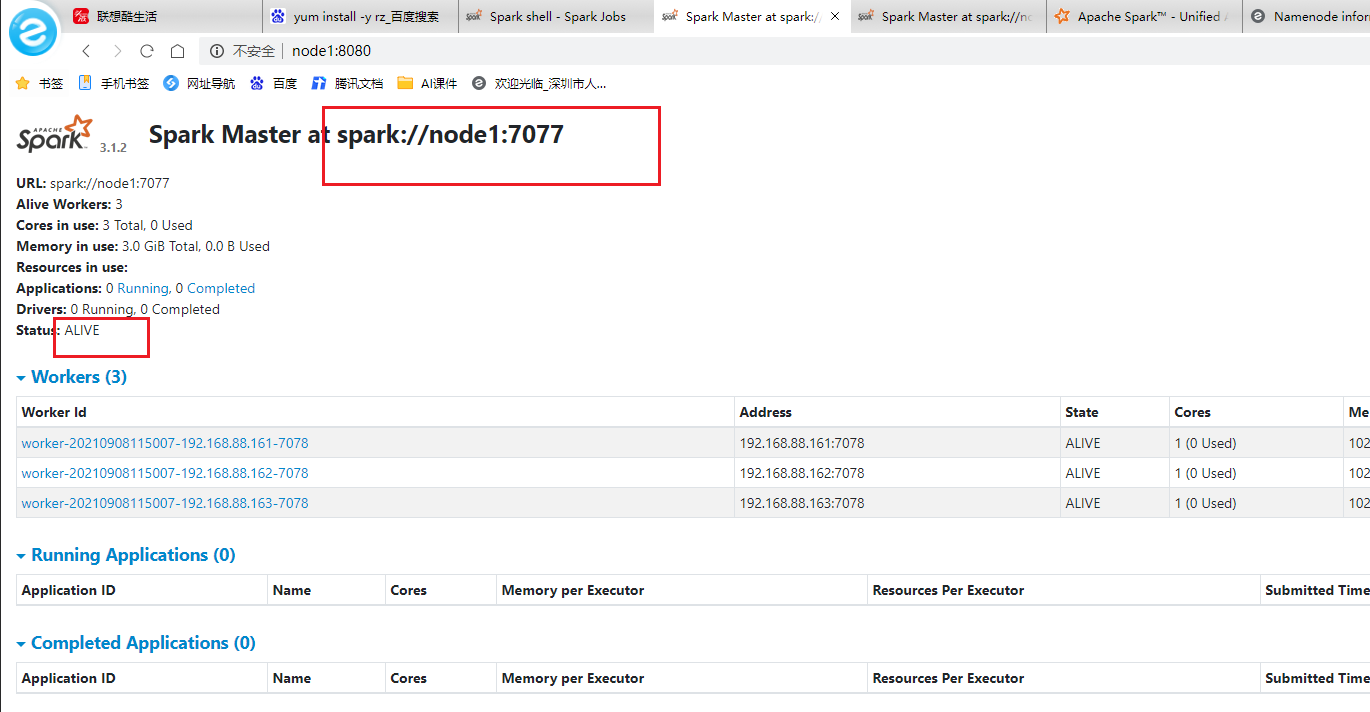
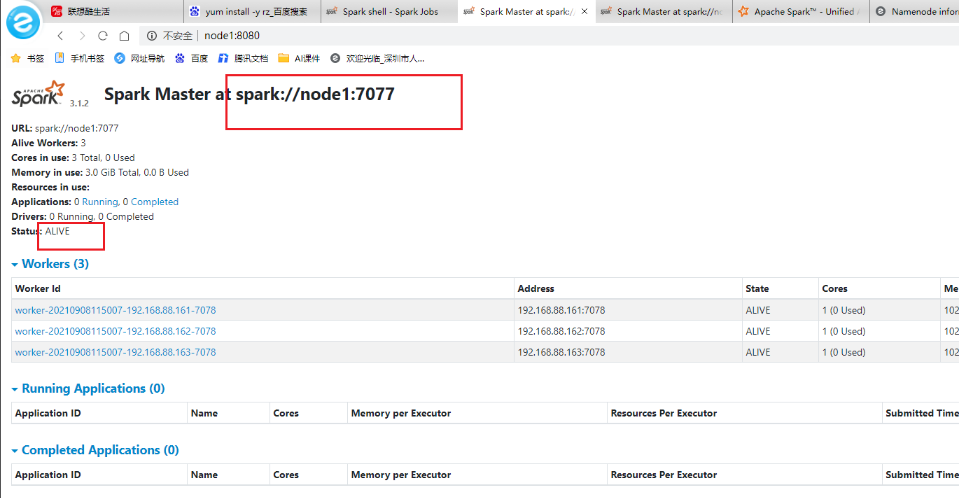
запустить тест
spark-shell
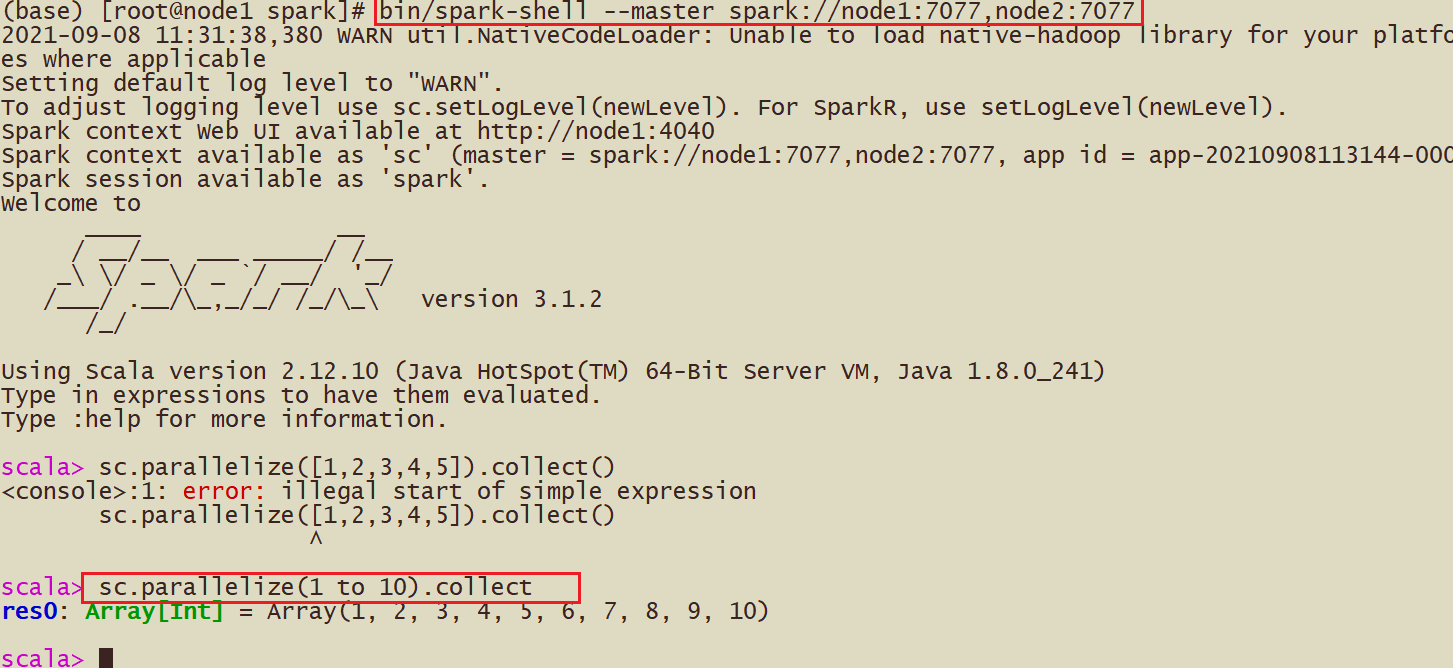
pyspark
- bin/pyspark --master spark://node1:7077,node2:7077
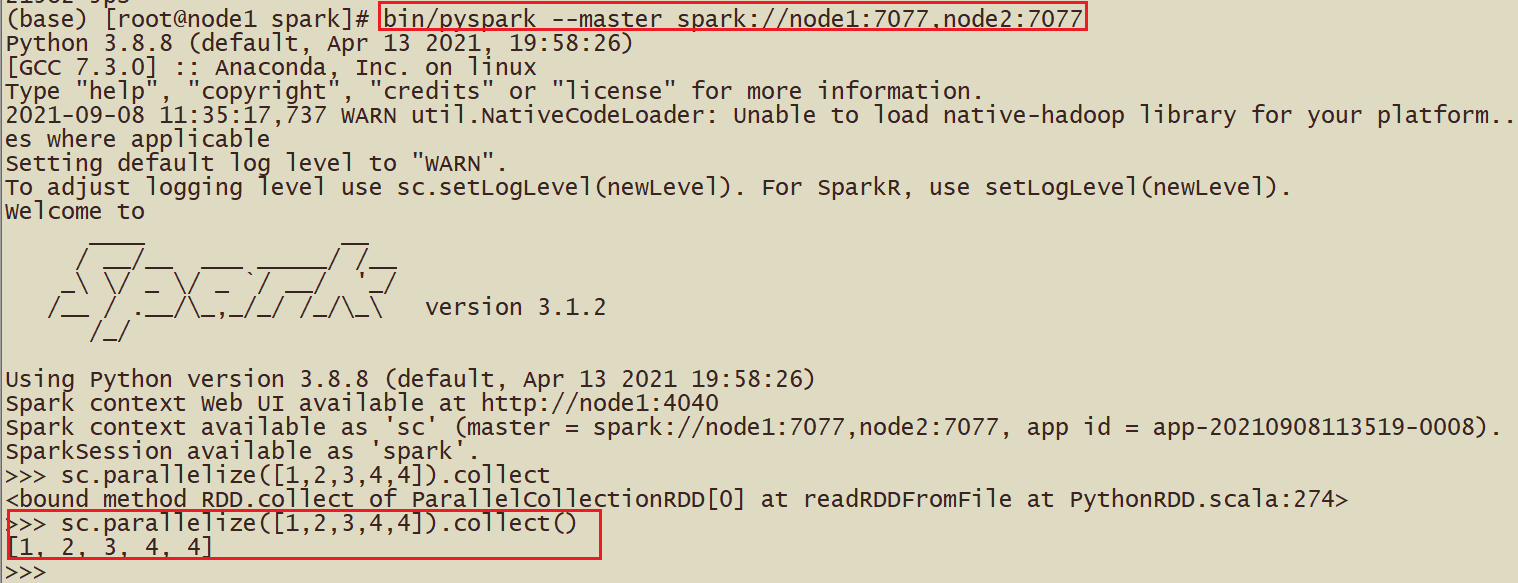
Искра-отправка #Скрипт на основе StandaloneHA бен/искра-отправка –master spark://node1:7077,node2:7077 –conf «spark.pyspark.driver.python=/root/anaconda3/bin/python3» –conf «spark.pyspark.python=/root/anaconda3/bin/python3» /export/server/spark/examples/src/main/python/pi.py 10
- тест: В настоящее время узел 1 является главным узлом, а узел 2 — резервным главным узлом. В настоящее время узел 1. Завершите главный процесс, а затем посмотрите, сможет ли хозяин узла node2 взять на себя роль мастера узла 1 и стать активным мастером.

- Если один мастер-нод выйдет из строя, запуск другого мастера займет 1-2 минуты.
- полный



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
