Большие данные NiFi (2): архитектура NiFi
Ни Фи архитектура
1. Основные концепции NiFi
Базовая концепция дизайна NiFi — это потоковое программирование (FBP), а приложение представляет собой сеть, состоящую из процессоров и разъемов. Данные поступают в узел, который обрабатывает данные и направляет данные в другие последующие узлы для обработки на основе различных результатов обработки. Это одна из причин, почему процесс NiFi легче визуализировать. Ниже приведены некоторые концепции NiFi:
Терминология Ни Фи | описывать |
|---|---|
FlowFile | FlowFile — это объект, передаваемый между системами. FlowFile имеет атрибут и контент. Атрибут атрибута — это пара ключ-значение, связанная с данными, а содержимое контента — это поток байтов, связанный с самими данными. |
FlowFile Processor | Процессор — это модуль, который фактически обрабатывает данные. Процессор отвечает за создание, получение, отправку, преобразование, маршрутизацию, разделение, слияние и обработку FlowFile. Процессор не имеет доступа к дополнительным свойствам и содержимому FlowFile, а также может отправлять или откатывать отправленные задачи. |
Connection | Соединение используется для соединения процессоров. Каждое соединение действует как очередь, поэтому разные процессоры могут обмениваться данными с разной скоростью. Эта очередь может динамически регулировать приоритет, а также устанавливать верхний предел нагрузки для реализации механизма противодавления. Соединение обычно подключается к одному или нескольким отношениям процессора, что позволяет маршрутизировать данные в соответствии с различными результатами обработки данных процессором. Когда FlowFile отправляется в Связь, он добавляется в соответствующую очередь CONnect. |
Flow Controllers | Отвечает за поддержание планирования между процессорами, управление потоками, используемыми всеми процессами, и их распределение. |
Process Group | Группа процессоров, группа процессоров и соответствующие им соединения образуют группу процессов. Эта группа процессоров получает данные через входной порт и отправляет данные через выходной порт. Группы процессов могут объединять другие компоненты для создания новых комбинаций. |
Если говорить в приведенной выше таблице, то FlowFile — это данные, передаваемые между различными узлами; FlowFile Processor — это модуль обработки данных; Connection — это очередь между каждым модулем обработки; FlowFile — это планирование сложных процессов; Его можно инкапсулировать в группу процессов, и разные группы используются для представления иерархических отношений различных процессов.
Этот шаблон проектирования дает множество преимуществ, помогая NiFi стать эффективной платформой для создания мощных и масштабируемых потоков данных, в том числе:
- Подходит для визуального создания и управления процессором.
- Асинхронный характер обеспечивает очень высокую пропускную способность и естественную буферизацию даже при колебаниях обработки и трафика.
- Предоставьте модель с высоким уровнем параллелизма, чтобы разработчикам не приходилось беспокоиться о том, как реализовать сложный параллелизм.
- Облегчает разработку высококонвергентных и слабосвязанных компонентов, позволяет повторно использовать эти компоненты в других средах и помогает в модульном тестировании.
- Соединение с ограниченными ресурсами делает ключевые функции, такие как противодавление и сброс давления, очень естественными и интуитивно понятными.
- Обработка ошибок выполнена очень хорошо, а не грубо.
- Точки, в которых данные входят в систему и выходят из нее, а также то, как они проходят, легко понять и легко отслеживать.
два、Ни Фи Архитектура
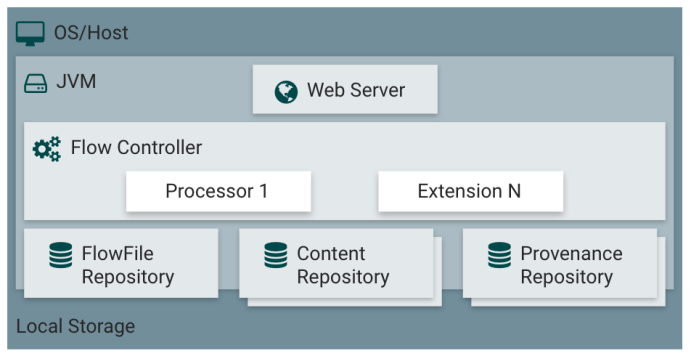
NiFi разработан на основе Java, поэтому работает на JVM. Расположение основных компонентов NiFi в JVM показано выше:
- Веб-сервер:
Целью веб-сервера является размещение API управления и контроля NiFi на основе http.
- Контроллер потока:
Контроллер потока — это мозг NiFi, который выполняет определенные операции. Он отвечает за выделение исполняемых потоков процессору из пула ресурсов потоков, а также за другие операции по управлению ресурсами и планированию.
- Расширения:
В NiFi существуют различные процессоры и расширения. Эти расширения также работают в JVM.
- FlowFile Repository (репозиторий FlowFile):
Репозиторий FlowFile отвечает за сохранение состояния FlowFile в текущем активном потоке. Реализация FlowFile Repository является подключаемой (несколько вариантов, настраиваемых, и вы даже можете реализовать ее самостоятельно). Реализация по умолчанию использует технологию журнала упреждающей записи для записи в указанный каталог диска.
- Репозиторий контента:
Репозиторий контента отвечает за сохранение фактического байтового содержимого FlowFile в текущем активном потоке. Его функциональная реализация является подключаемой. Подход по умолчанию представляет собой довольно простой механизм, который хранит данные содержимого в файловой системе. Можно указать несколько путей хранения, поэтому различные физические пути можно комбинировать, чтобы избежать достижения предела хранилища одного физического раздела.
- Репозиторий Provenance (исходная база данных):
В исходном репозитории хранятся все исходные данные о событиях. Кроме того, эта функция является подключаемой и по умолчанию может храниться в одном или нескольких физических разделах. Данные о событиях по каждому пути индексируются и могут быть запрошены.
3. Кластерная архитектура NiFi
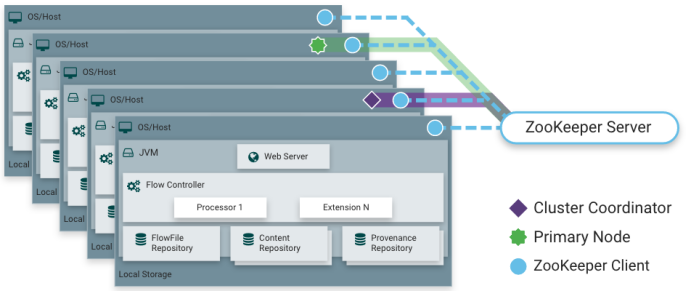
Начиная с версии NiFi 1.0, NiFi использует режим кластера Zero-Master. Каждый узел в кластере NiFi выполняет одну и ту же задачу с данными, но каждый узел работает с другим набором данных.
- zookeeper Client:
NiFi полагается на Zookeeper для координации различных узлов и отвечает за аварийное переключение и выбор узлов NiFi. Zookeeper, на который полагается NiFi, может быть встроенным Zookeeper, поставляемым с NiFi, или кластером Zookeeper, установленным пользователем. При создании кластера NiFi версия Zookeeper должна быть версии 3.5 или выше при использовании кластера Zookeeper, установленного пользователем.
- Координатор Кластера-Координатор Кластера:
Apache ZooKeeper выбирает один из узлов в качестве координатора кластера, а аварийное переключение выполняется автоматически ZooKeeper. Все узлы кластера передают координатору кластера информацию о пульсе и состоянии. Координатор кластера отвечает за отключение и подключение узлов.
- Первичный узел Node-Master:
В каждом кластере есть главный узел, который также выбирается ZooKeeper. Главный узел предназначен для выполнения задач с одним узлом. Этот тип задач не подходит для компонентов, работающих в кластере. Например: чтение файла с одним узлом. Если каждый узел читает файл данных, это приведет к повторному чтению. в этом случае вы можете настроить главный узел для указания выполнения с определенного узла. Когда главный узел зависает, Zookeeper также перевыбирает главный узел.
Кроме того, мы можем взаимодействовать с кластером NiFi через пользовательский интерфейс любого узла в кластере, и любые внесенные изменения реплицируются на все узлы в кластере.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
