Большие данные. Flink Advanced (11): настройка и использование сервера истории Flink.
Flink History Использование конфигурации сервера
После отправки задачи Flink на основе автономного режима или режима Yarn, если выполнение задачи завершается сбоем, отменой или завершением, вы можете просмотреть статистику соответствующей задачи в веб-интерфейсе. Эта статистика очень важна для нас в производственной среде. и мы можем знать, что задача ненормальная. То, что произошло до зависания, позволяет легко обнаружить проблему.
Когда соответствующая задача отправляется в режиме автономного сеанса, у нас нет возможности проверить предыдущие запущенные задачи кластера после перезапуска кластера. Если задача отправляется в режиме предварительного задания, после выполнения задачи. завершена, соответствующая статистическая информация не будет сохранена. То же самое относится и к задачам Flink, работающим на основе Yarn. Это доставляет нам неудобства при просмотре статистики или параметров предыдущих заданий Flink. Flink предоставляет сервер истории для решения этой проблемы. Он может сохранять соответствующую статистику задачи после завершения выполнения задачи, чтобы облегчить анализ и обнаружение проблемы.
Сервер истории позволяет запрашивать статус и статистическую информацию журнала завершенных заданий, заархивированных JobManager. Завершенный архив задания загружается и сохраняется по определенному пути с помощью JobManager. Этот путь может быть локальной файловой системой, HDFS, H3 и т. д. Сервер истории может периодически сканировать этот путь, чтобы восстановить заархивированный журнал задач Flink, чтобы вы могли его просмотреть. соответствующий статус журнала задач Flink.
1. Настройка и проверка автономного сервера истории.
1. Конфигурация
Чтобы настроить службу сервера истории в автономном режиме, необходимо выбрать узел в качестве сервера истории. Этот узел может быть узлом JobManager/TaskManager или узлом вне автономного кластера. Здесь узел 4 выбран в качестве узла сервера истории Flink. Шаги по настройке службы HistoryServer в автономном режиме следующие:
1.1. Настройте flink-conf.yaml на узлах JM и TM.
Настройте файл flink-conf.yaml на узлах Flink Standalone JobManager и TaskManager и укажите путь, по которому Flink сможет завершить сохранение задачи. Здесь выберите каталог HDFS в качестве каталога сохранения журнала задач. Настройте файл $FLINK_HOME/conf/flink-conf.yaml на узлах node1, node2 и node3 и добавьте следующую конфигурацию.
#Flink Каталог хранения журналов после завершения задания
jobmanager.archive.fs.dir: hdfs://mycluster/flink/completed-jobs/Flink подключится к каталогу HDFS для хранения данных задачи на основе приведенной выше конфигурации, поэтому вам необходимо настроить переменную среды HADOOP_CLASSPATH в /etc/profile на узлах node1, node2 и node3.
#vim /etc/profile добавьте следующую конфигурацию
export HADOOP_CLASSPATH=`hadoop classpath`
#source /etc/profile Сделайте переменные среды эффективными
source /etc/profile1.2. Настройте flink-conf.yaml на узле History Server.
Настройте файл $FLINK_HOME/conf/flink-conf.yaml на узле node4, добавьте следующую конфигурацию и настройте HistoryServer.
#Flink History Server узел
historyserver.web.address: node4
#Flink History Server порт
historyserver.web.port: 8082
#Flink History Server Каталог задач восстановления
historyserver.archive.fs.dir: hdfs://mycluster/flink/completed-jobs/
#Flink History Server Интервал обновления каталога журнала задач мониторинга (миллисекунды)
historyserver.archive.fs.refresh-interval: 10000Flink подключится к каталогу HDFS для восстановления данных задачи на основе приведенной выше конфигурации. Требуется, чтобы конфигурация параметра «historyserver.archive.fs.dir» соответствовала настроенному пути параметра «jobmanager.archive.fs.dir». на каждом узле Flink. Кроме того, переменную среды HADOOP_CLASSPATH необходимо настроить в файле /etc/profile на узле node4.
# vim /etc/profile добавьте следующую конфигурацию
export HADOOP_CLASSPATH=`hadoop classpath`
#source /etc/profile Сделайте переменные среды эффективными
[root@node4 ~]# source /etc/profile1.3. Запустите сервер исторических журналов Flink.
Запустите сервер истории Flink на узле node4.
#запускатьFlink Сервер исторических журналов
[root@node4 ~]# cd /software/flink-1.16.0/bin/
[root@node4 bin]# ./historyserver.sh start2. Проверка
После запуска сервера истории вы можете получить доступ к странице службы журнала истории через https://node4:8082.

Мы можем проверить, может ли History Server правильно отображать статистику выполнения задач Flink, отправив задачи в автономный кластер. Шаги следующие:
2.1. Запустите автономный кластер.
[root@node1 ~]# cd /software/flink-1.16.0/bin/
[root@node1 bin]# ./start-cluster.sh2.2. Отправьте задачи.
Отправьте задачу в кластер Flink. Задача по-прежнему выбирает чтение данных порта Socket и подсчет WordCount в режиме реального времени. Сначала запустите службу сокетов на узле node5:
[root@node5 ~]# nc -lk 9999Отправьте задачи Flink на клиенте node4 (задачи Flink можно отправлять на любом узле), команда выглядит следующим образом:
[root@node4 ~]# cd /software/flink-1.16.0/bin/
[root@node4 bin]# ./flink run -m node1:8081 -c com.mashibing.flinkjava.code.chapter3.SocketWordCount /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jarПосле отправки задачи каталог hdfs://mycluster/flink/completed-jobs" пока не будет создан в HDFS. Информацию о задании можно увидеть в этом каталоге только тогда, когда кластер Flink останавливается, задача отменяется. , или задача не будет выполнена.
2.3. Отменить задачу и просмотреть журнал истории.
Введите некоторые данные в порт Socket 9999 на узле node5:
hello,a
hello,b
hello,c
hello,dЗатем отмените текущую задачу в Flink WebUI:
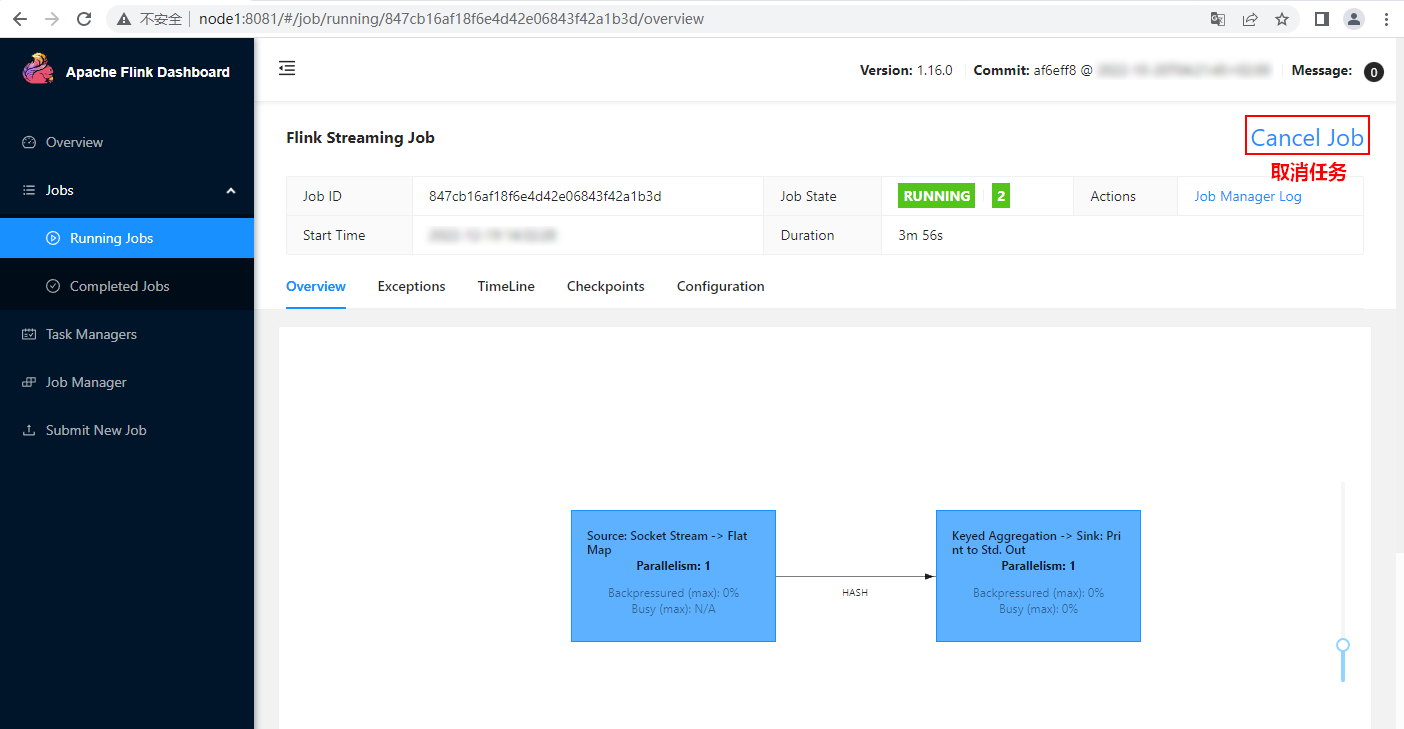
После отмены задачи вы можете увидеть информацию об отмене в каталоге «hdfs://mycluster/flink/completed-jobs»:
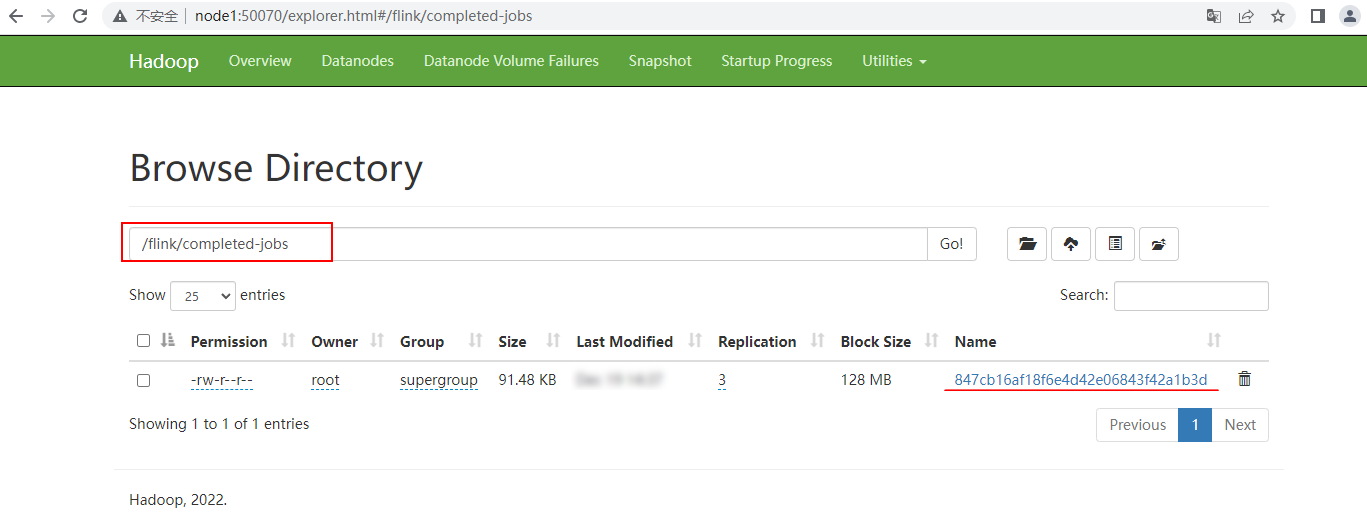
Когда задача отменена, вы также можете остановить кластер Flink. После перезапуска кластера Flink статистика предыдущей задачи не будет отображаться. Вы можете войти на сервер исторического журнала Flink, чтобы просмотреть статистику предыдущей задачи:
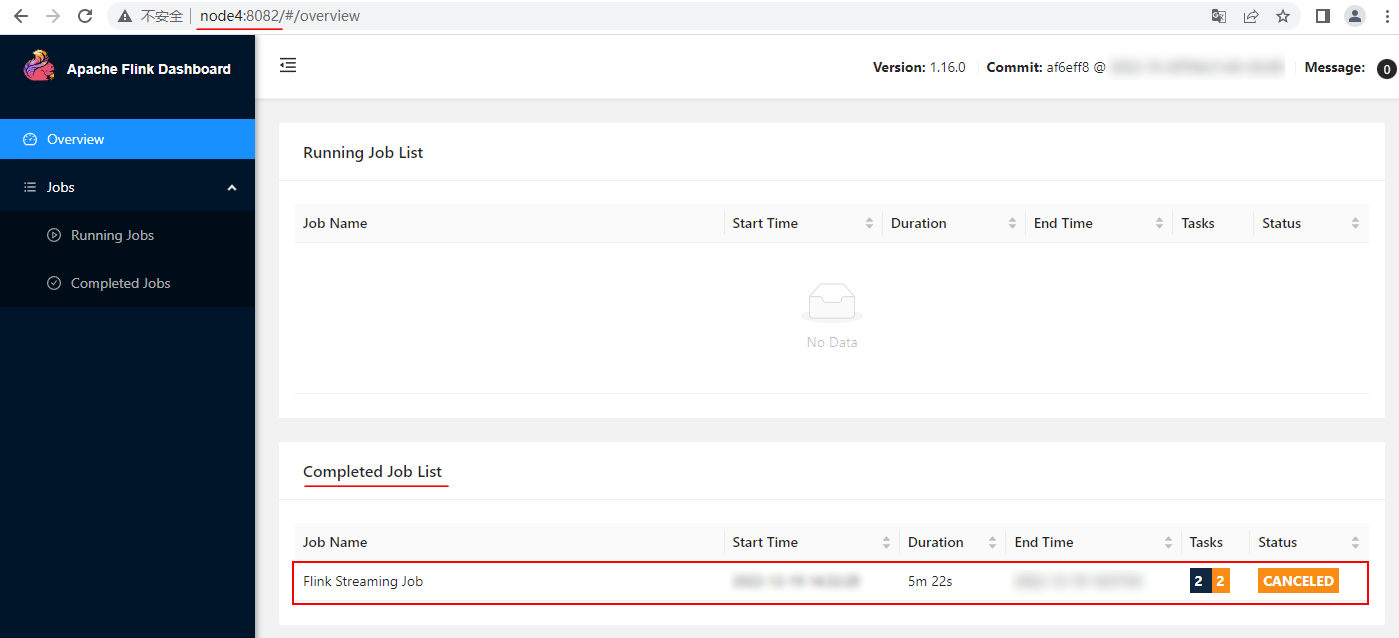
Примечание. После отмены задачи или остановки кластера Flink вам необходимо подождать небольшой период времени, прежде чем вы сможете просмотреть соответствующую отмененную задачу на сервере журнала истории Flink.
2. Настройка и проверка сервера истории пряжи.
1. Конфигурация
Когда Flink работает на основе Yarn, при остановке кластера, сформированного задачами Flink, статистику соответствующих задач нельзя увидеть. Вы также можете настроить History Server для просмотра статистики задач после остановки кластера Flink на основе Yarn.
Здесь node5 выбран в качестве сервера истории. Шаги по настройке службы HistoryServer путем запуска задачи Flink на основе Yarn следующие:
1.1. Настройте flink-conf.yaml на узле node5.
Настройте файл $FLINK_HOME/conf/flink-conf.yaml на узле node5 и, наконец, настройте следующие элементы конфигурации.
#Flink Каталог хранения журналов после завершения задания
jobmanager.archive.fs.dir: hdfs://mycluster/flink-yarn/completed-jobs/
#Flink History Адрес сервера
historyserver.web.address: node5
#HistroyServer WebUI Посетите порт
historyserver.web.port: 8082
#HistoryServerHistory Каталог информации о задаче восстановления службы журнала истории
historyserver.archive.fs.dir: hdfs://mycluster/flink-yarn/completed-jobs/
#Flink History Server Интервал обновления каталога журнала задач мониторинга (миллисекунды)
historyserver.archive.fs.refresh-interval: 10000Flink подключится к каталогу HDFS для хранения данных задачи на основе приведенной выше конфигурации, поэтому вам необходимо настроить переменную среды HADOOP_CLASSPATH в /etc/profile на узле node5.
#vim /etc/profile добавьте следующую конфигурацию
export HADOOP_CLASSPATH=`hadoop classpath`
#source /etc/profile Сделайте переменные среды эффективными
source /etc/profile1.2. Запустите сервер исторических журналов Flink и получите к нему доступ.
Запустите сервер истории Flink на узле node5.
#запускатьFlink Сервер исторических журналов
[root@node5 ~]# cd /software/flink-1.16.0/bin/
[root@node5 bin]# ./historyserver.sh startДоступ к адресу службы исторического журнала: https://node5:8082.
2. Проверка
Отправьте задачу Flink на основе Yarn на узле node5, чтобы проверить, может ли сервер истории нормально отображать статистику выполненной задачи Flink. Шаги следующие:
2.1. Отправьте задачи Flink в кластер Yarn.
Отправьте задачу Flink в кластер Yarn. Задача по-прежнему выбирает чтение данных порта Socket и подсчет WordCount в режиме реального времени. Запустите сервер сокетов на узле node5:
[root@node5 ~]# nc -lk 9999Отправьте задачу Flink в кластер Flink на узле node5. Команда выглядит следующим образом:
[root@node5 ~]# cd /software/flink-1.16.0/bin/
# представлять на рассмотрение Перелистывание задач
[root@node5 bin]#./flink run-application -t yarn-application -c com.lanson.flinkjava.code.chapter3.SocketWordCount /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jarПосле отправки задачи каталог hdfs://mycluster/flink/completed-jobs" пока не будет создан в HDFS. Информацию о задании можно увидеть в этом каталоге только тогда, когда кластер Flink останавливается, задача отменяется. , или задача не будет выполнена.
2.2. Отменить задачу и просмотреть журнал истории.
Введите некоторые данные в порт Socket 9999 на узле node5:
hello,a
hello,b
hello,c
hello,dЗатем войдите в веб-интерфейс Yarn (https://node1:8081), найдите отправленную задачу и отмените соответствующую задачу Flink:
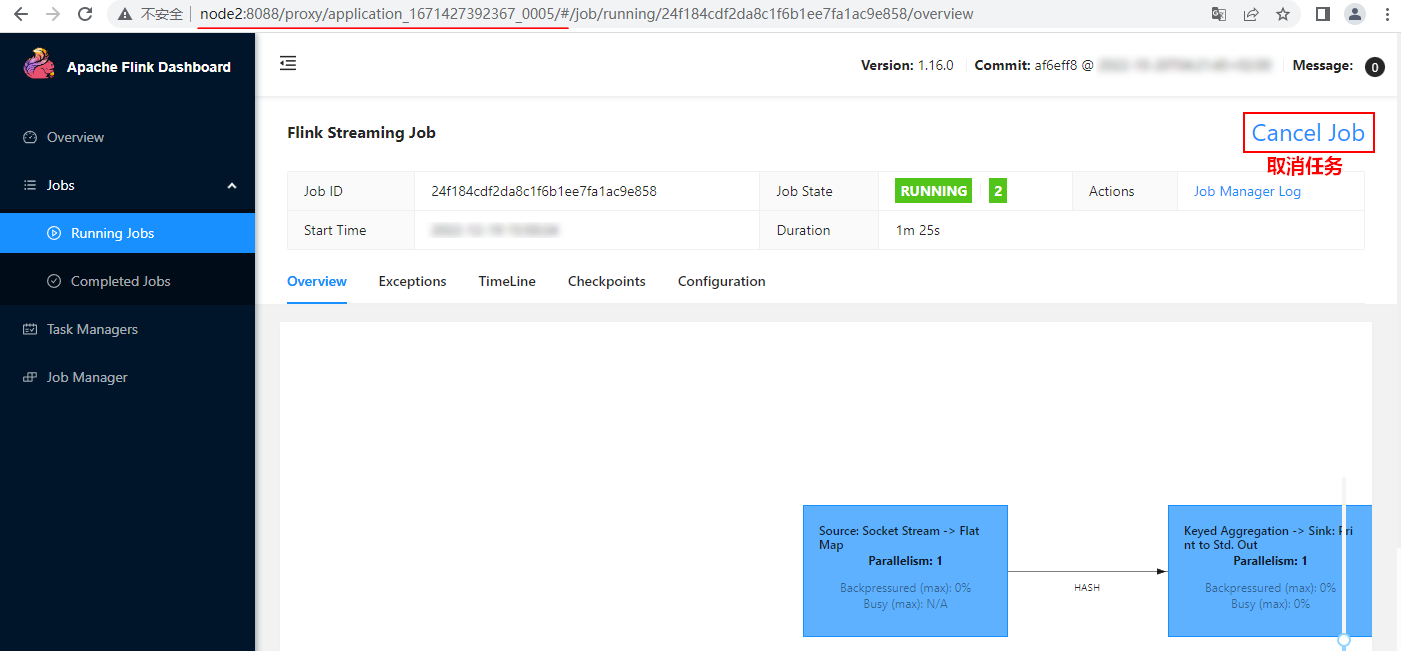
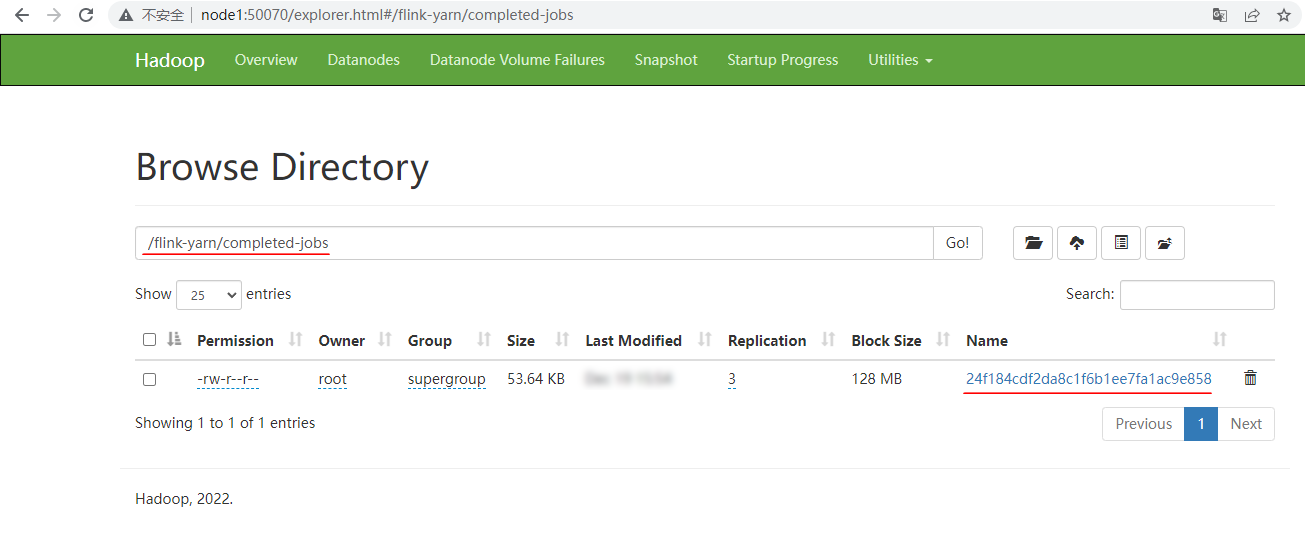
После отмены задачи вы можете увидеть информацию об отмене в каталоге «hdfs://mycluster/flink-yarn/completed-jobs»:
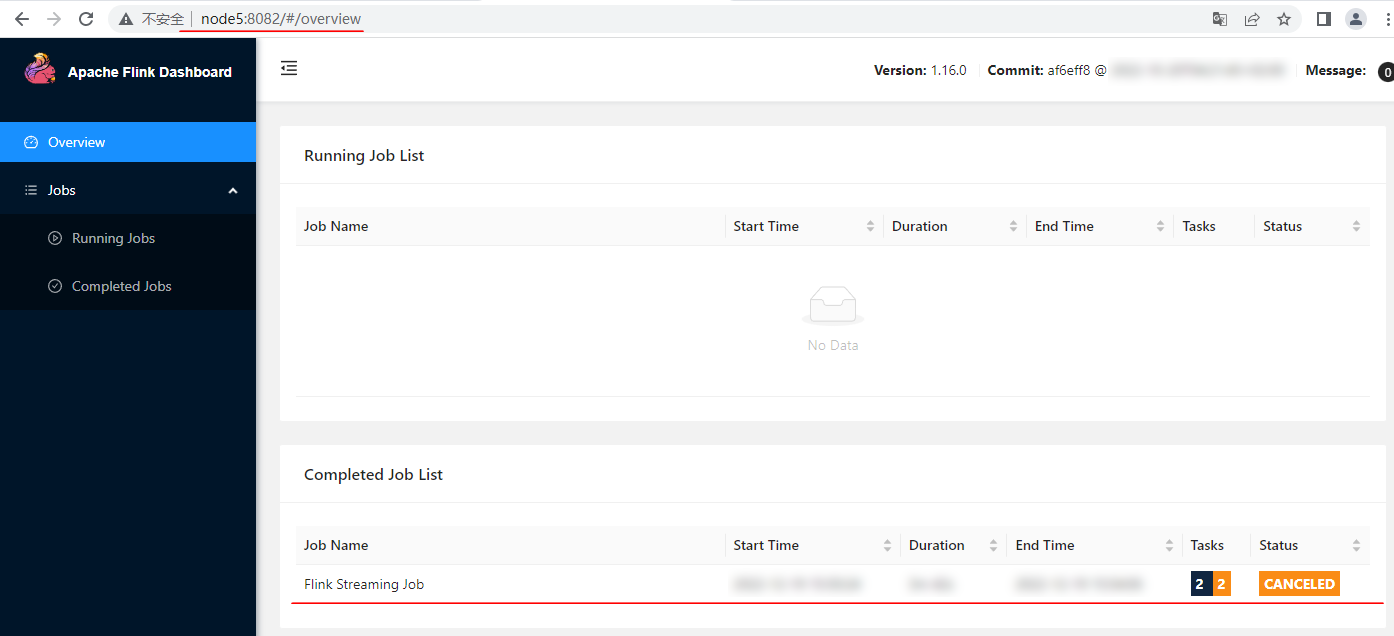
Войдите на сервер исторических журналов Flink, чтобы просмотреть статистику отмененных задач:
Примечание. После отмены задачи или остановки кластера Flink вам необходимо подождать небольшой период времени, прежде чем вы сможете просмотреть соответствующую отмененную задачу на сервере журнала истории Flink.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
