Больше, чем просто понимание: как ИИ меняет интерпретацию видео?
С тех пор, как Сора взорвал область генерации видео, исследования и применения в мультимодальных областях, таких как видео, достигли значительного прогресса, и это стало будущей тенденцией развития больших моделей искусственного интеллекта.

С другой стороны, создание видеороликов с использованием ИИ также требует, чтобы ИИ мог понимать контент в видео, чтобы он мог эффективно генерировать результаты для различного контента. Таким образом, понимание видео ИИ стало еще одной важной областью, подобной умному мозгу, анализирующему тайны визуального мира.
В этой статье в основном представлены две важные модели понимания видео, а именно GPT4Video и MiniGPT4-Video.
GPT4Video
Первая модель называется моделью GPT4Video, которая обучена Tencent AI LAB на основе большой модели. Она имеет два основных преимущества:
1) Он демонстрирует впечатляющие возможности как в понимании видео, так и в создании сцен. Например, GPT4Video превосходит Valley на 11,8% в задаче видеоответов на вопросы и на 2,3% превосходит NExt-GPT в задаче преобразования текста в видео.
2) Расширение возможностей LLM/MLLM для создания видео без необходимости дополнительных параметров обучения и возможность гибкого подключения к нескольким моделям для создания видео.
Отображение эффектов
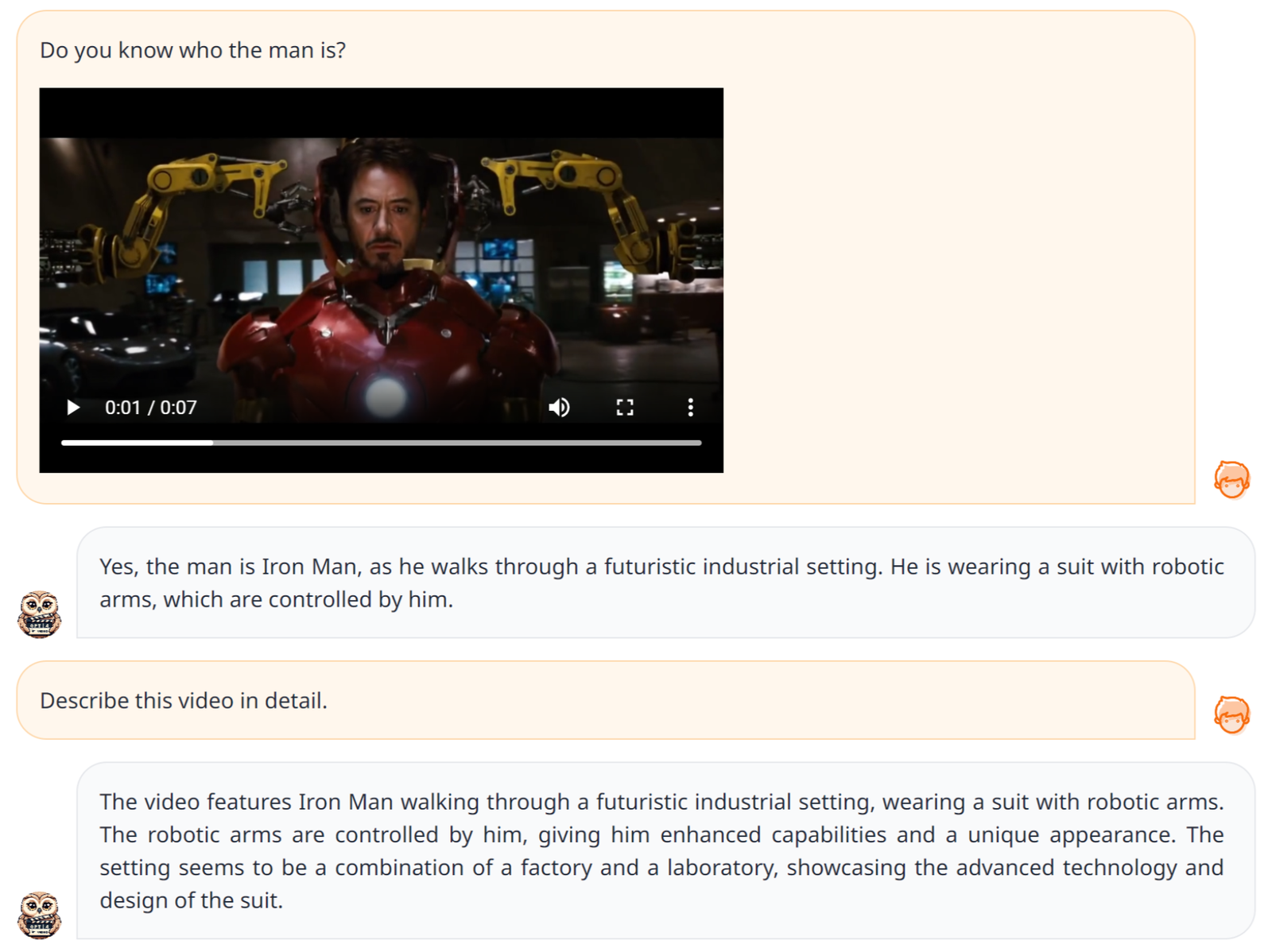
Загрузите видео с Железным Человеком и пусть оно описывает содержание видео:
AI: В видео Железный Человек носит костюм с роботизированными руками и идет по индустриальной среде будущего. Он управляет роботизированными руками, что придает ему расширенные способности и уникальный внешний вид. Окружающая среда выглядит как смесь фабрики и лаборатории, демонстрируя передовые технологии и дизайн костюма.
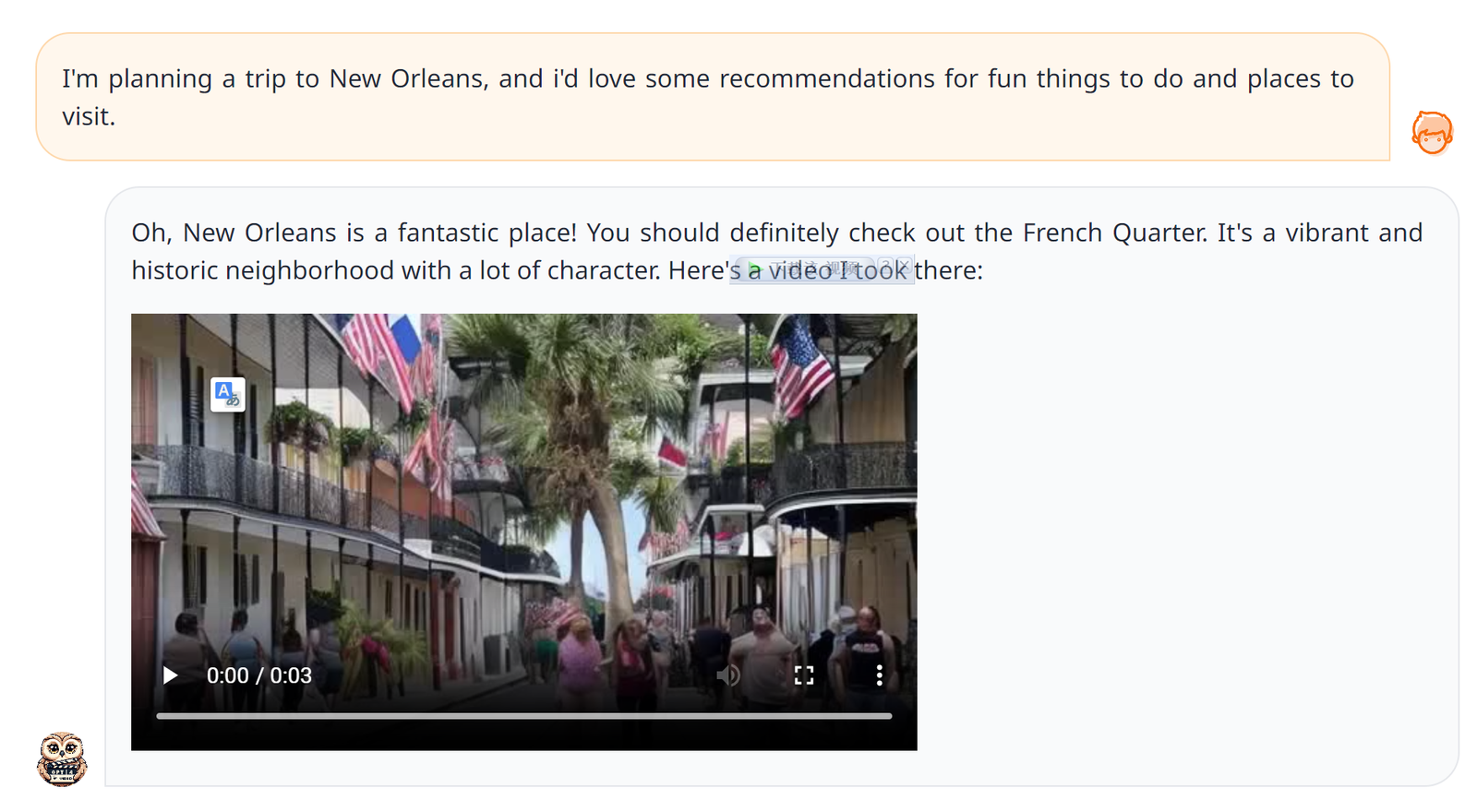
Если во время путешествия вам нужны планы поездок, вы можете напрямую позволить ему создавать соответствующие видео:
Новый Орлеан – такое прекрасное место! Вам обязательно стоит заглянуть во Французский квартал. Это яркий, исторический и характерный район. Вот видео, которое я там снял:
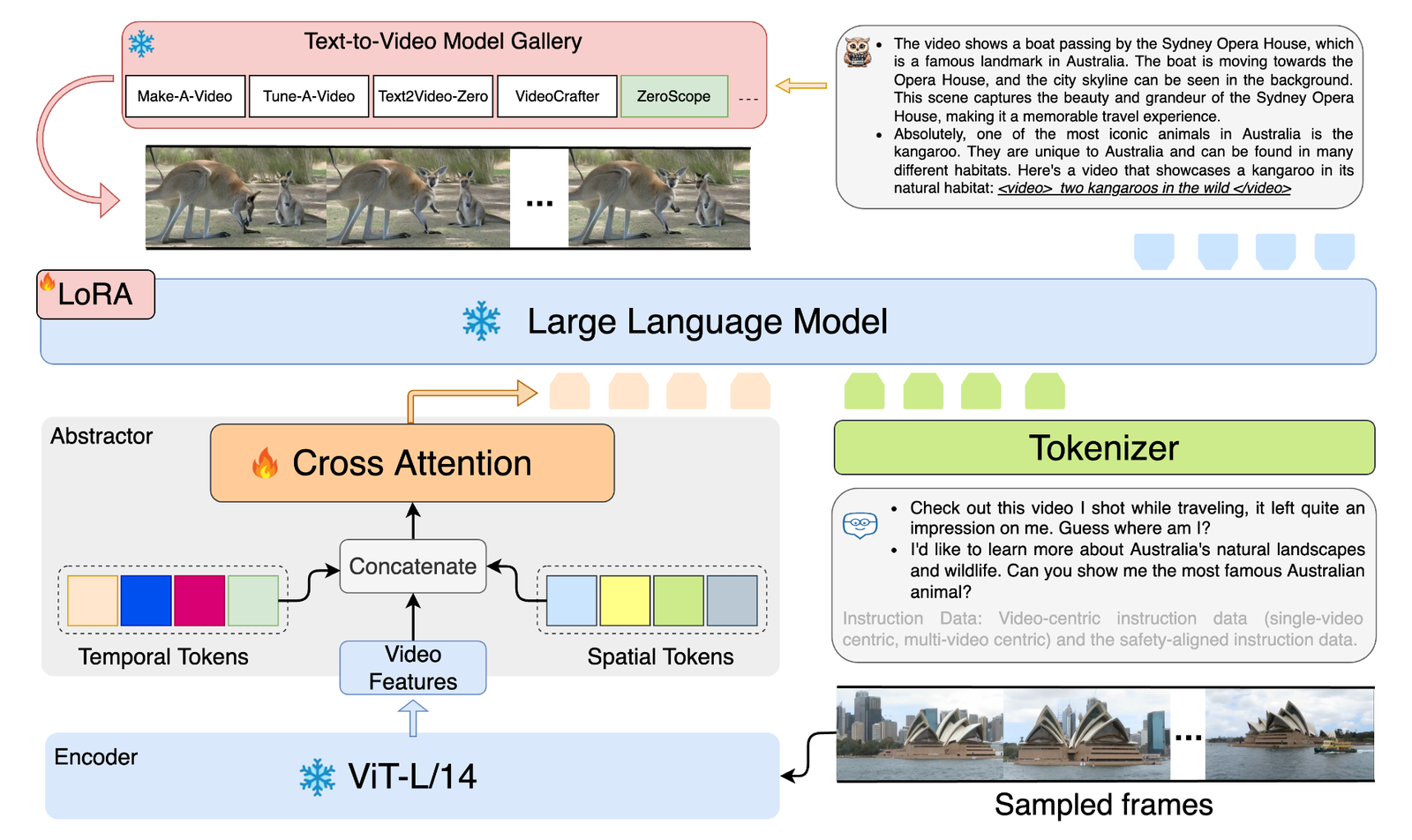
технические детали
Модель в основном состоит из трех различных модулей:
- Этап кодирования видео: модуль кодирования видео использует замороженную модель ViT-L/14 для захвата исходных функций видео.
- Вывод LLM для большой модели. Ядро GPT4Video основано на замороженной модели LLaMA и эффективно настроено с помощью LoRA. LLM обучается с использованием пользовательских видеоориентированных и надежно согласованных данных, что позволяет ему понимать видео и генерировать соответствующие видеоподсказки.
- Генерация видео. Подсказки, сгенерированные LLM, затем используются в качестве текстового ввода в галерее моделей преобразования текста в видео и могут быть сгенерированы напрямую без тонкой настройки.
Модель MiniGPT4-Видео
Вторая модель позволяет развернуть ее самостоятельно и получить бесплатно. В то же время он достиг последних результатов в понимании видео с помощью искусственного интеллекта.
локальное развертывание
В репозитории github minigpt4-video приведены подробные инструкции по развертыванию:
- Клонировать код репозитория
git clone https://github.com/Vision-CAIR/MiniGPT4-video.git
cd MiniGPT4-video- Установите и активируйте среду
conda env create -f environment.yml- Запустить код
# Llama2
python minigpt4_video_demo.py --ckpt path_to_video_checkpoint --cfg-path test_configs/llama2_test_config.yaml
# Mistral
python minigpt4_video_demo.py --ckpt path_to_video_checkpoint --cfg-path test_configs/mistral_test_config.yamlОтображение эффектов
Официальный представитель развернул соответствующую демонстрацию кода. Если вам интересно, вы можете попробовать:
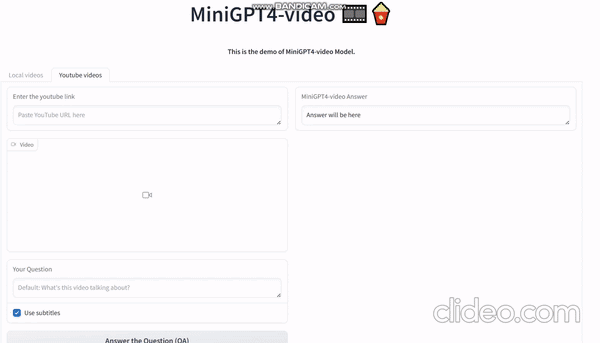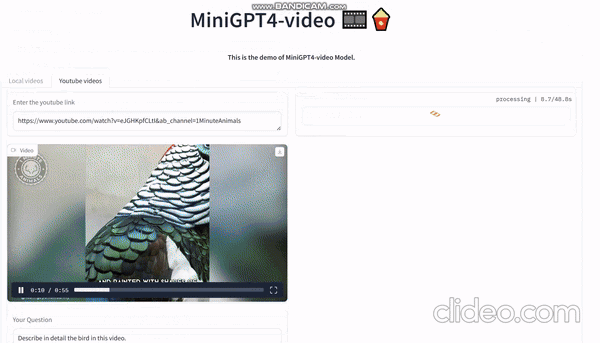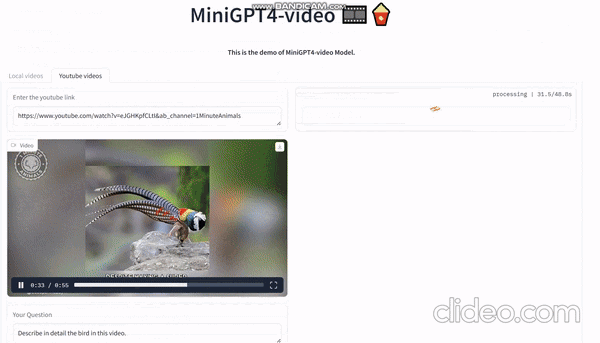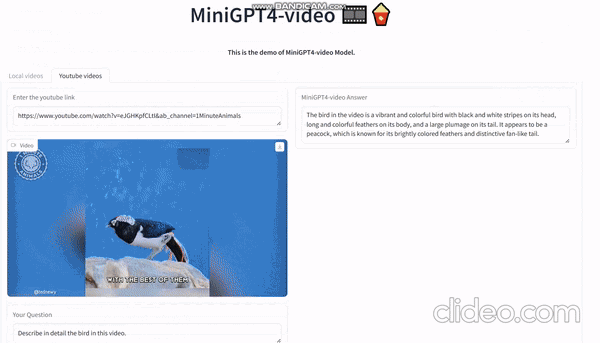
Судя по официальной демонстрации, вы можете напрямую ввести любое видео на YouTube, а затем попросить его описать видео. Он может описывать содержимое экрана на основе видео:
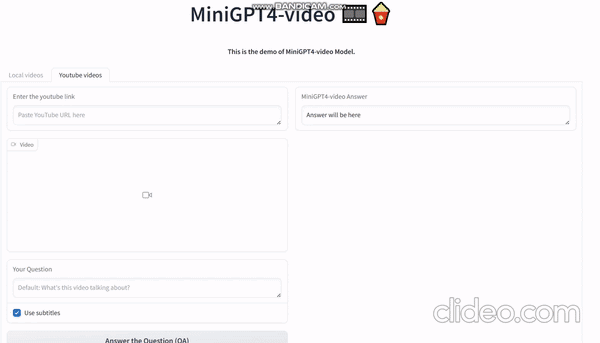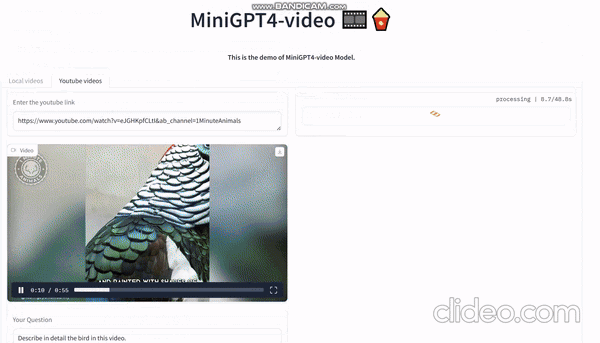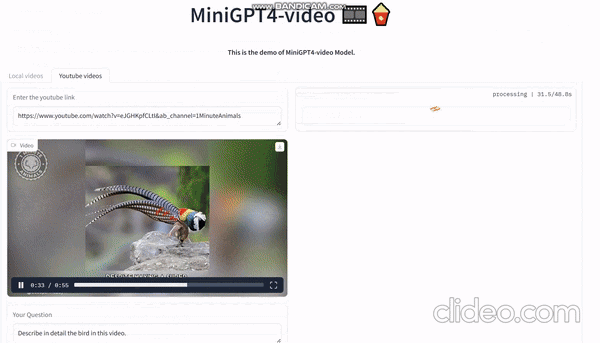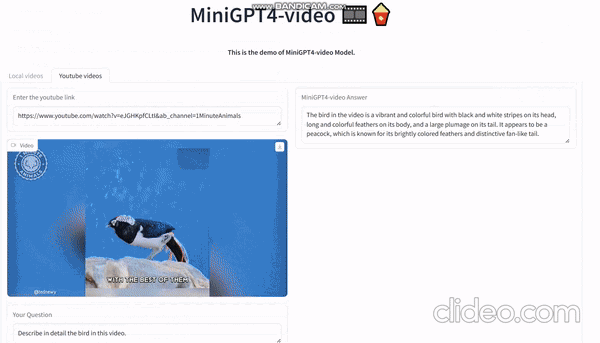
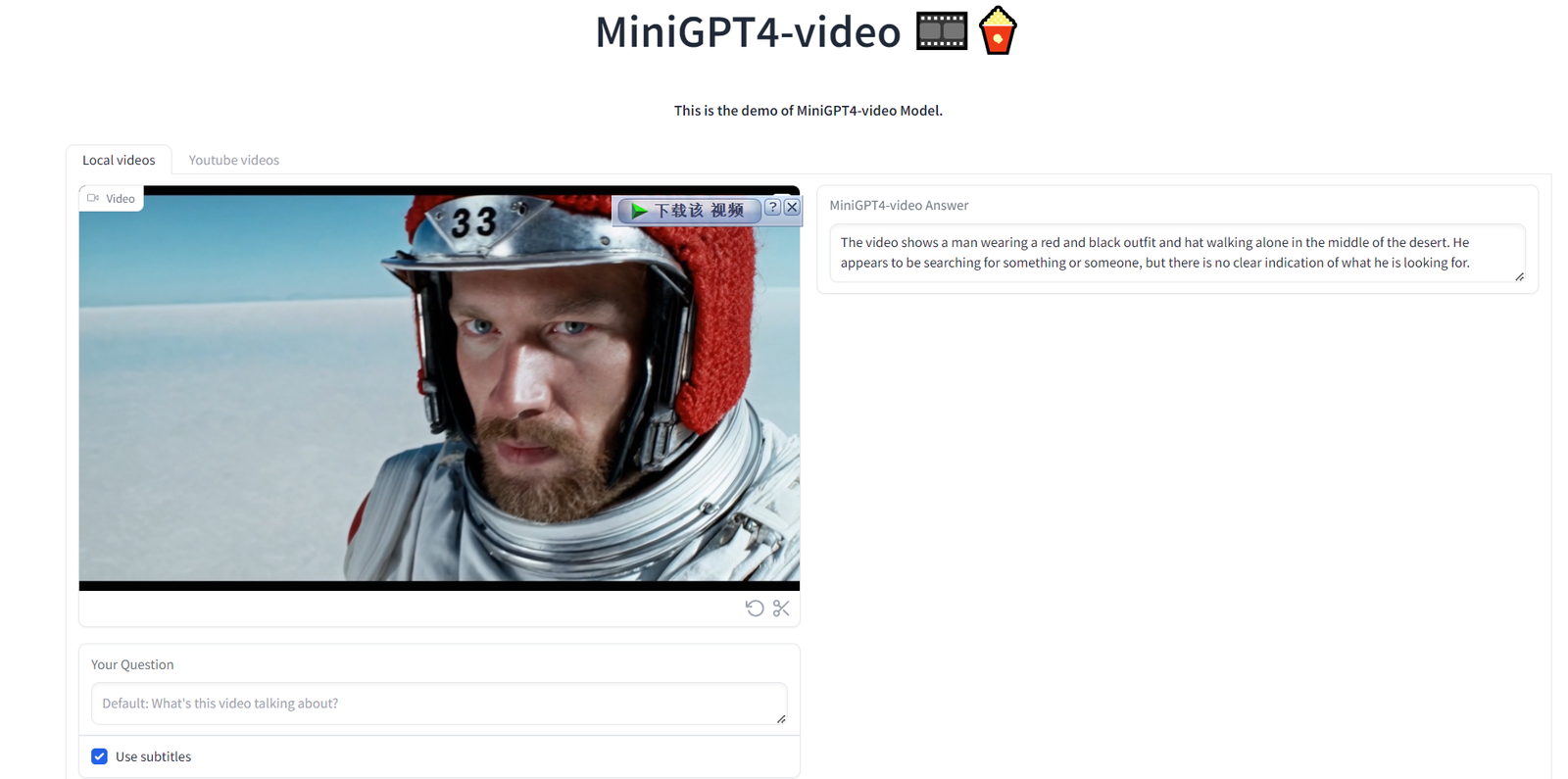
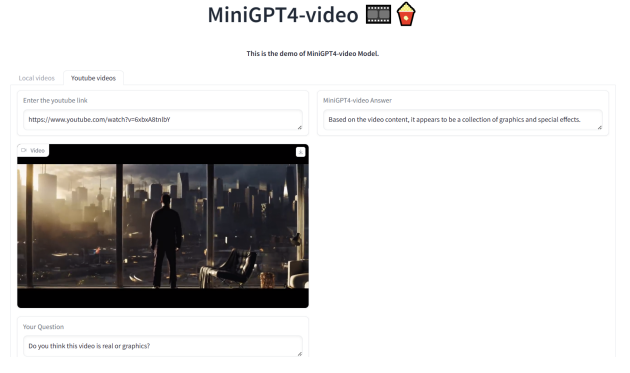
Видео, сгенерированное sora, загружено сюда и дайте ему разобрать:
На видео видно, как мужчина в красно-черной одежде и шляпе идет один посреди пустыни. Он как будто ищет что-то или кого-то, но нет четкого указания на то, что он ищет.
Мы также можем загрузить видео Bulgari и позволить ИИ помочь нам подобрать заголовок или слоган, что действительно выглядит немного блефом.
Испытайте чудеса света, одно чудо за раз.
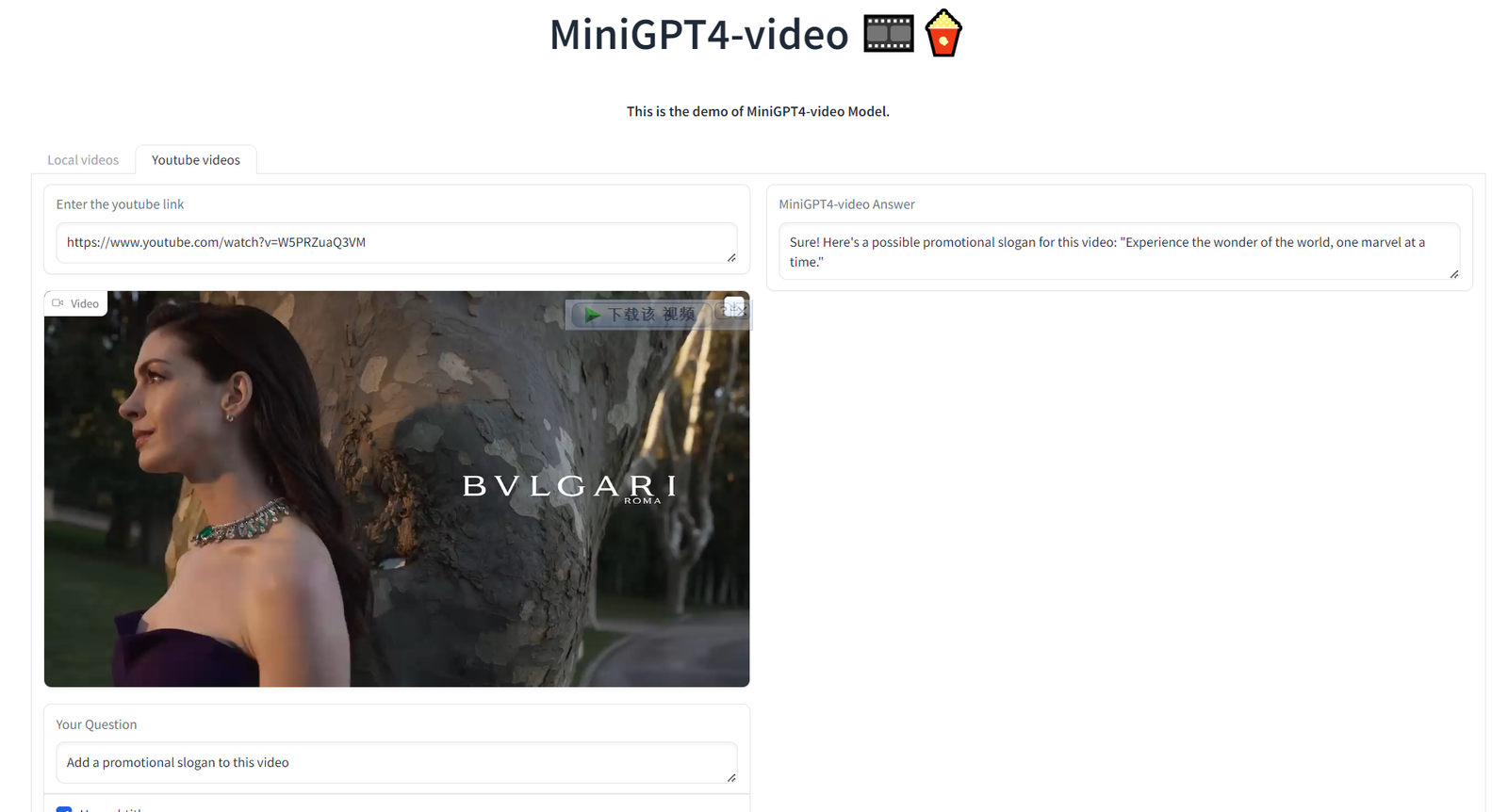
Даже некоторые технологии, использованные в видео, можно узнать:
Судя по содержанию видео, оно представляет собой набор графики и спецэффектов.
С точки зрения представления рекламного креатива, по сравнению с VideoChatGPT, рекламные слоганы, генерируемые MiniGPT4-Video, более детальны, а контент гораздо ярче:
Название: Солнце светит тебе в лицо Сцена: Красивый пляж и человек со светлой кожей. Появилась бутылка мольстюнера, и человек нанес ее на кожу, и она почувствовала прохладу и освежающее ощущение, подчеркивая название продукта и ключевые ингредиенты.....

технические детали
Краткое описание некоторых методов модели:
- MiniGPT4-Video основан на MiniGPT-v2, который отлично справляется с преобразованием визуальных функций в пространство LLM для отдельных изображений и достигает хороших результатов в различных тестах изображения и текста.
- Модель объединяет каждые четыре соседних визуальных токена в один, чтобы уменьшить потерю информации, а также включает субтитры, что улучшает способность модели понимать видеоконтент.
Метод обучения:
- Используйте крупномасштабное предварительное обучение пары изображение-текст и предварительное обучение пары видео-текст, которые используются для адаптации модели к видеоконтенту.
- Модель использует линейный слой на этапе предварительного обучения для сопоставления визуальных функций с текстовым пространством LLM, а также использует визуальный кодировщик EVA-CLIP и технологию LoRA для детальной настройки.
В частности, обучение состоит из трех этапов:
- Предварительное обучение выравниванию изображения и текста. Первым шагом является использование модели EVA-Clip для предварительного обучения, чтобы позволить модели понять изображение и соответствующее ему описание.
- Предварительная тренировка выравнивания видеотекста. Поскольку видео представляет собой объединение нескольких кадров изображения, его можно сконструировать в покадровые изображения плюс текст и ввести в последующие слои модели.
- Тонкая настройка видеоответов на вопросы: точная настройка больших моделей (LLM) с использованием некоторых высококачественных наборов данных вопросов и ответов.
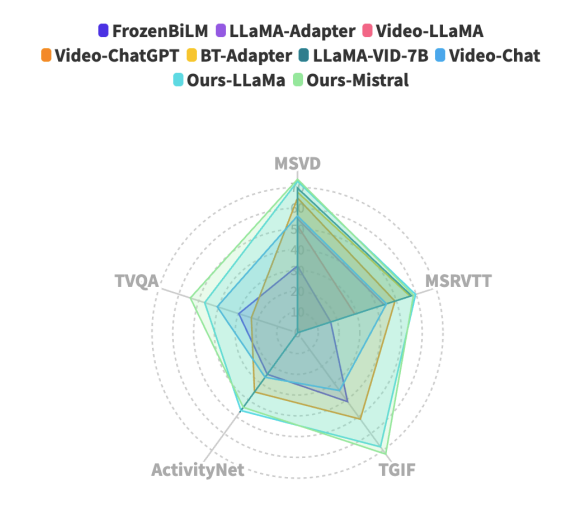
MiniGPT4-Video хорошо работает в нескольких тестах видео, включая MSVD, MSRVTT, TGIF и TVQA, достигая значительного улучшения производительности в этих тестах.
В целом, эта модель продемонстрировала потенциал для первоначального захвата видеоконтента, но ей еще предстоит пройти долгий путь, чтобы достичь удивительного уровня ChatGPT.
Выше — все содержание этого выпуска. Меня зовут Лев. Увидимся в следующем выпуске~.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
