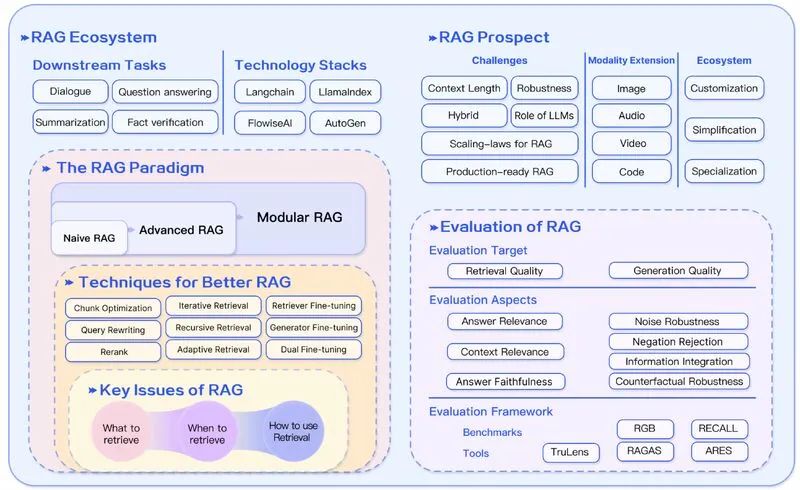
Большая модельная серия – интерпретация RAG
RAG — самая популярная архитектура прикладных систем на основе LLM в 2023 году. Существует множество продуктов, почти полностью построенных на RAG: от службы вопросов и ответов, сочетающей в себе поисковую систему и LLM, до тысяч приложений для обмена данными. Многие считают RAG и Agent двумя основными архитектурами для приложений больших моделей, но что такое RAG? Какие конкретные технологии использует RAG?
1. Что такое РАГ?
RAG, или Retrival Augmentation Generation, предоставляет LLM информацию, полученную из определенных источников данных, и корректирует сгенерированные ответы на основе этого. RAG — это, по сути, приглашение Search + LLM, которое отвечает на запросы с помощью большой модели и использует информацию, найденную алгоритмом поиска, в качестве контекста для большой модели. И запрос, и полученный контекст вводятся в подсказки, отправляемые в LLM.
Доступ к встроенным поисковым системам можно получить через Faiss Для достижения этой цели область поиска векторов стала стимулом для RAG. как сосновая шишка такизвекторданные Библиотеки могут быть созданы с открытым исходным кодом.поискиндекс,Добавлено дополнительное место для хранения ввода текста.,Также были добавлены некоторые другие инструменты. О библиотеке векторных данных,Можно обратиться кИнтерпретация векторных баз данных。
Среда разработки, ориентированная на RAG, для конвейеров и приложений на основе LLM существует два наиболее известных инструмента с открытым исходным кодом — LangChain и LlamaIndex, которые были созданы в октябре и ноябре 2022 года соответственно. С появлением ChatGPT они также будут запущены в 2023 году. получил массовое распространение в 2016 году. LlamaIndex и LangChain — замечательные проекты с открытым исходным кодом, которые очень быстро растут.
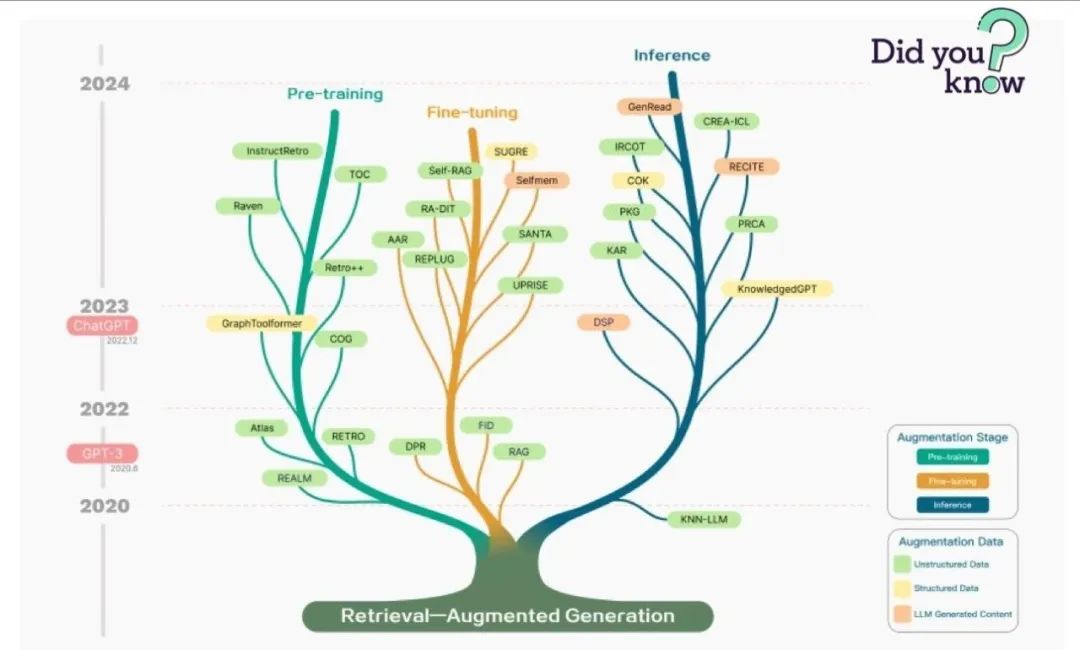
2. Базовая технология RAG.
Отправной точкой системы RAG обычно является корпус текстовых документов, который выглядит просто следующим образом: разбейте текст на фрагменты, затем встройте эти фрагменты в модели векторного кодера и преобразователя, проиндексируйте все эти векторы и, наконец, создайте подсказки LLM. которые сообщают модели ответить на запрос пользователя, учитывая контекст, найденный на этапе поиска. Во время выполнения мы используем ту же модель кодировщика для завершения векторизации пользовательского запроса, затем выполняем поиск по индексу этого вектора запроса, находим первые k результатов, извлекаем соответствующий текстовый блок из базы данных и предоставляем приглашение LLM. как контекст.
На платформе OpenAI слово-подсказка Prompt может быть таким:
def question_answering(context, query):
prompt = f""" my query text...
"""
response = get_completion(instruction, prompt, model="gpt-3.5-turbo")
answer = response.choices[0].message["content"]
return answerДля получения дополнительной информации о словах-подсказках и их разработке см. OpenAI. из Подскажите инженерное руководство Word иИнтерпретация оперативного инжиниринга。
Очевидно, что хотя OpenAI является лидером на рынке LLM, существует множество альтернатив, таких как Claude от Anthroic, а также более мелкие, но мощные модели, ставшие популярными в последнее время, такие как Mistral, Phi-2 от Microsoft и множество вариантов с открытым исходным кодом. Например, Llama2, OpenLLaMA, Falcon и т. д. можно использовать для разработки крупных моделей изделий для RAG.
3. Передовые технологии в РАГ
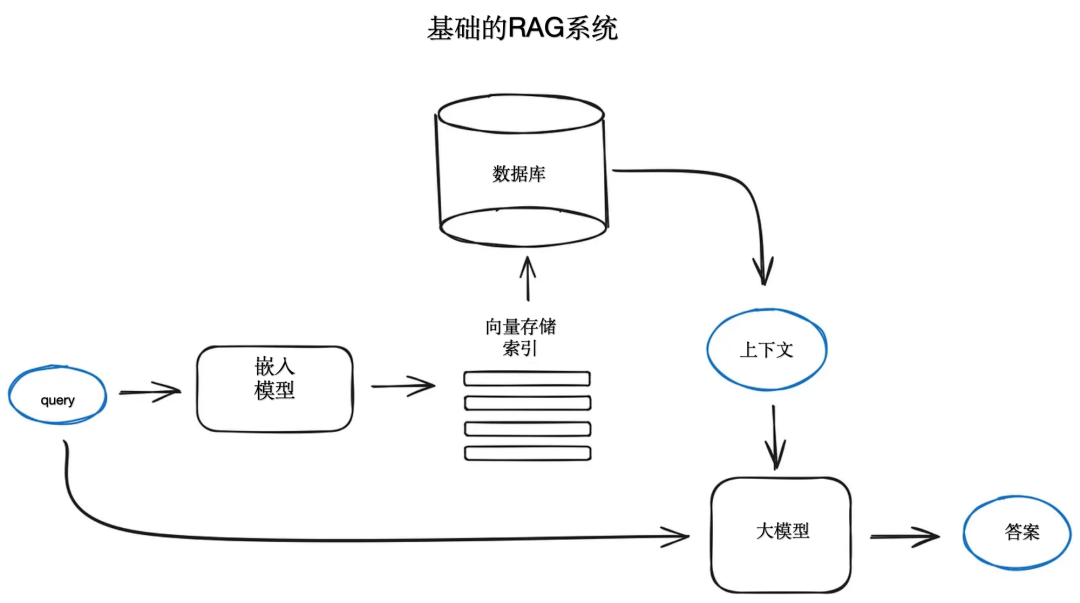
Хотя не все передовые методы в системах RAG можно легко представить на диаграмме, имеет смысл дать схему, описывающую основные шаги и алгоритмы.
3.1. Блокировка и векторизация.
Сначала создается векторный индекс для представления содержимого нашего документа, а затем во время выполнения мы ищем ближайшую семантику, соответствующую минимальному расстоянию между всеми этими векторами и вектором запроса.
Поскольку модель преобразователя имеет фиксированную длину входной последовательности, даже если окно входного контекста велико, вектор из одного или нескольких предложений может лучше представить их семантическое значение, чем вектор, усредненный по нескольким страницам текста, поэтому данные разбиваются на части. Это значимая технология. Разделите исходный документ на куски определенного размера, не теряя при этом их смысла, т. е. разбейте текст на предложения или абзацы вместо того, чтобы разбивать предложение на две части. Более того, уже существуют различные реализации текстовых разделителей, способные выполнить эту задачу. Например, в LlamaIndex NodeParser предоставляет некоторые расширенные параметры, такие как определение собственного разделителя текста, метаданных, отношений между узлами и блоками и т. д.
Размер блока данных — это параметр, который необходимо учитывать. Он зависит от используемой модели внедрения и емкости ее токенов. Стандартные модели кодирования преобразователя, такие как преобразователь предложений BERT, могут использовать только до 512 токенов, что адаптируется OpenAI. 002 может обрабатывать более длинные последовательности, такие как токены 8191, но компромиссом здесь является достаточный контекст, чтобы позволить LLM рассуждать, и достаточно конкретные текстовые вложения для эффективного выполнения поиска.
Следующим шагом является выбор модели для встраивания выбранных блоков. Опять же, существует множество подходов, таких как модели, оптимизированные для поиска ( bge-large Или Е5 серия), МТЕБ Рейтинги могут обновлятьсяизнекоторая информация о методе。О фрагментировании документаивекторшаги по адаптациииз Комплексная реализация,Можно конкретно упомянутьhttps://docs.llamaindex.ai/en/latest/moduleguides/loading/ingestionpipeline/root.html#。
2. Индекс поиска
Ключевой частью приложений больших моделей для RAG является индекс, используемый для поиска, в котором хранится векторизованный контент, полученный ранее. Конечно, запросы всегда сначала векторизуются, и то же самое касается k верхних плиток. Самая простая реализация использует плоский индекс, вычисляя расстояние между вектором запроса и всеми векторами блоков и просматривая его.
Подходящий поисковый индекс, оптимизированный для эффективного поиска в масштабе более десяти тысяч элементов, требует векторного индекса, реализованного с помощью faiss, nmslib или annoy с использованием некоторого приближенного подхода к ближайшему соседу, такого как алгоритмы кластеризации, дерева или HNSW. Существуют также управляемые решения, такие как ElasticSearch и векторные базы данных, которые управляют конвейером приема данных.
В зависимости от выбора индекса потребности в данных и поиске также могут хранить метаданные с векторами, а затем использовать фильтры метаданных для поиска информации в пределах определенных дат или источников данных. LlamaIndex поддерживает множество индексов векторного хранения, а также другие более простые реализации индексов, такие как индексы списков, индексы деревьев и индексы ключевых таблиц.
Если у вас много документов, вам необходимо иметь возможность эффективно выполнять поиск по ним, находить соответствующую информацию и объединять ее в ответ со ссылками на источники. Для больших баз данных эффективным подходом является создание двух индексов: один из сводок, а другой — из блоков документов, а затем поиск в два этапа: сначала фильтрация соответствующих документов по сводкам, а затем поиск по связанным группам.
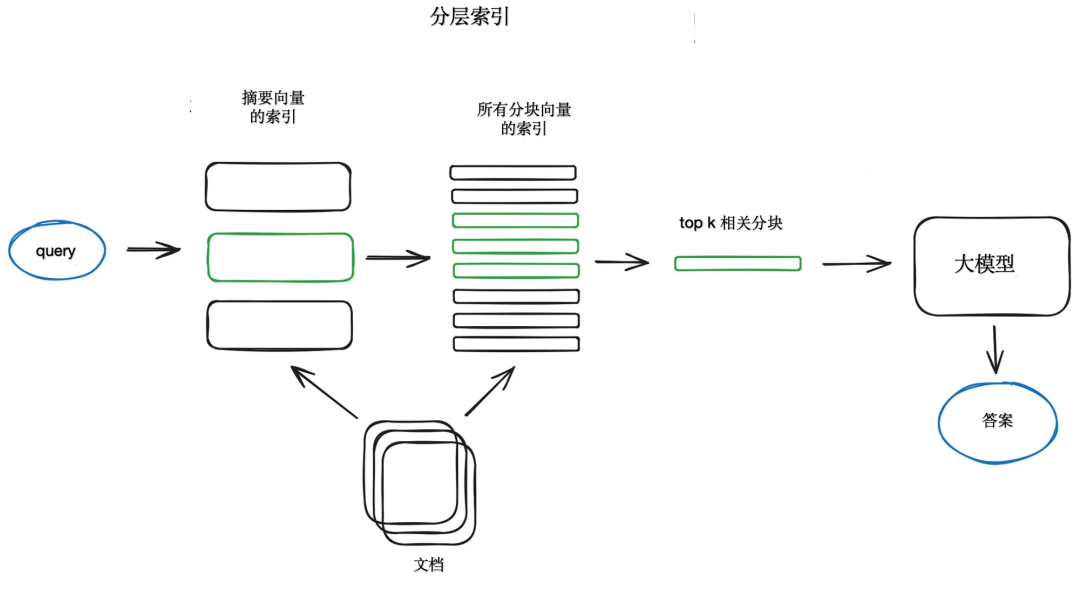
Другой подход состоит в том, чтобы попросить LLM сгенерировать вопрос для каждого блока и встроить эти вопросы в векторы, выполнить поиск запроса по индексу вектора этого вопроса во время выполнения (заменив вектор блока вектором вопроса в индексе), а затем направить к необработанные текстовые фрагменты и отправлять их в качестве контекста для LLM, чтобы получить ответ. Такой подход повышает качество поиска за счет более высокого семантического сходства запросов и гипотетических вопросов по сравнению с реальными блоками. Существует также подход обратной логики, называемый HyDE, который требует, чтобы LLM генерировал гипотетический ответ на заданный запрос, а затем использовал его векторы и векторы запроса для улучшения качества поиска.
Чтобы получить более мелкие фрагменты для лучшего качества поиска, добавьте в LLM окружающий контекст. Существует два варианта: один — извлечение окна предложения, которое расширяет контекстное предложение за предложением вокруг извлеченных меньших фрагментов, а другой — поиск родительского документа, который рекурсивно разбивает документ на несколько более крупных родительских фрагментов, содержащих более мелкие фрагменты подблоков. .
В схеме поиска окна предложений каждое предложение в документе встраивается индивидуально, что обеспечивает высокую точность контекстного поиска по косинусному расстоянию. После получения наиболее релевантного отдельного предложения, чтобы лучше понять найденный контекст, окно контекста расширяется до k предложений до и после полученных предложений, а затем этот расширенный контекст отправляется в LLM.
Извлечение родительского документа очень похоже на извлечение из окна предложения в том смысле, что оно ищет более подробную информацию, а затем расширяет контекстное окно перед предоставлением контекста LLM для вывода. Документы разбиваются на более мелкие части, которые ссылаются на более крупные родительские части. В частности, документы разбиваются на иерархию блоков, а затем в индекс отправляются наименьшие конечные блоки. Во время извлечения выбираются меньшие фрагменты, а затем, если более n фрагментов среди первых k извлеченных фрагментов связаны с одним и тем же родительским узлом (более крупный фрагмент), контекст, предоставленный LLM, заменяется этим родительским узлом. Обратите внимание, что поиск выполняется только в индексе дочернего узла.
Также существует относительно старая идея брать лучшие результаты современных семантических или векторных поисков и объединять их в единый алгоритм поиска, такой как tf-idf или BM25. Единственный трюк здесь — правильно объединить полученные результаты с разными показателями сходства. Эту проблему обычно решают с помощью алгоритма взаимного слияния рангов (RRF), который переупорядочивает полученные результаты для получения окончательного результата.
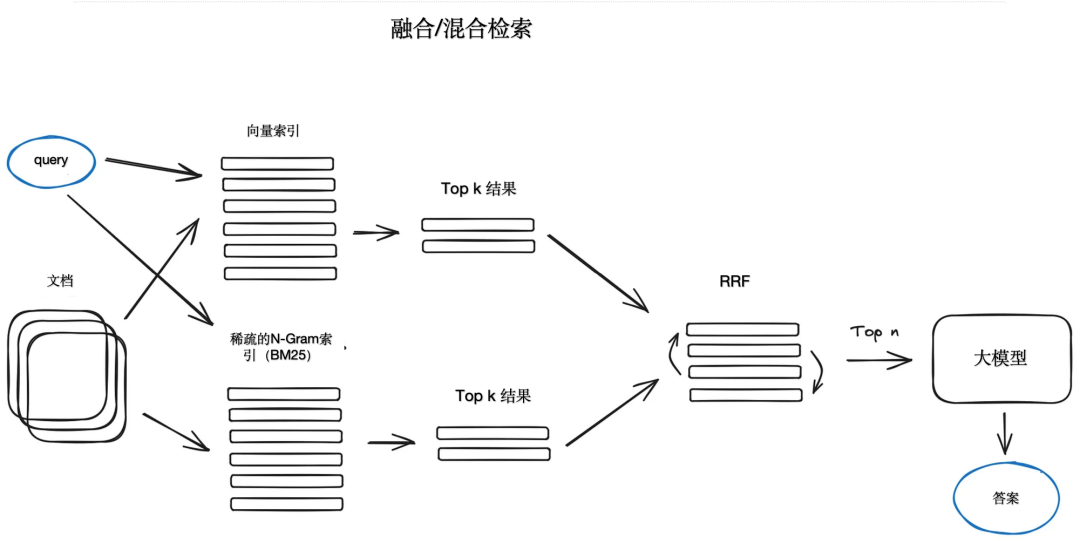
В LangChain это реализовано в интегрированном классе ретривера, например, векторном индексе Фейсса и ретривере на основе BM25, и использует RRF для переупорядочения. В LlamaIndex это делается очень похоже.
Гибридный или объединенный поиск обычно сочетает в себе два взаимодополняющих алгоритма поиска для обеспечения лучших результатов поиска с учетом семантического сходства и совпадений ключевых слов между запросом и сохраненными документами.
3.3. Переранжирование и фильтрация.
После получения результатов поиска вам необходимо изменить их порядок с помощью фильтрации. LlamaIndex предоставляет множество доступных процедур постобработки для фильтрации результатов на основе оценок сходства, ключевых слов, метаданных или использования других моделей для изменения порядка результатов, таких как перекрестные кодировщики на основе преобразователей предложений, на основе метаданных (например, дат) и давности. ) связное переупорядочение и т. д. Это последний шаг перед предоставлением полученного контекста LLM для получения результирующего ответа.
3.4. преобразование запроса
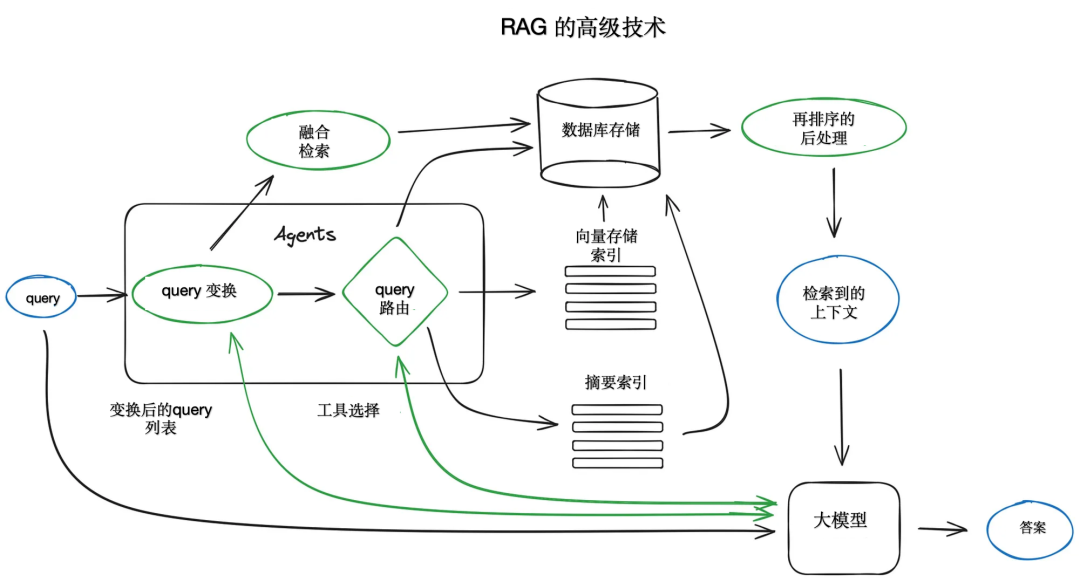
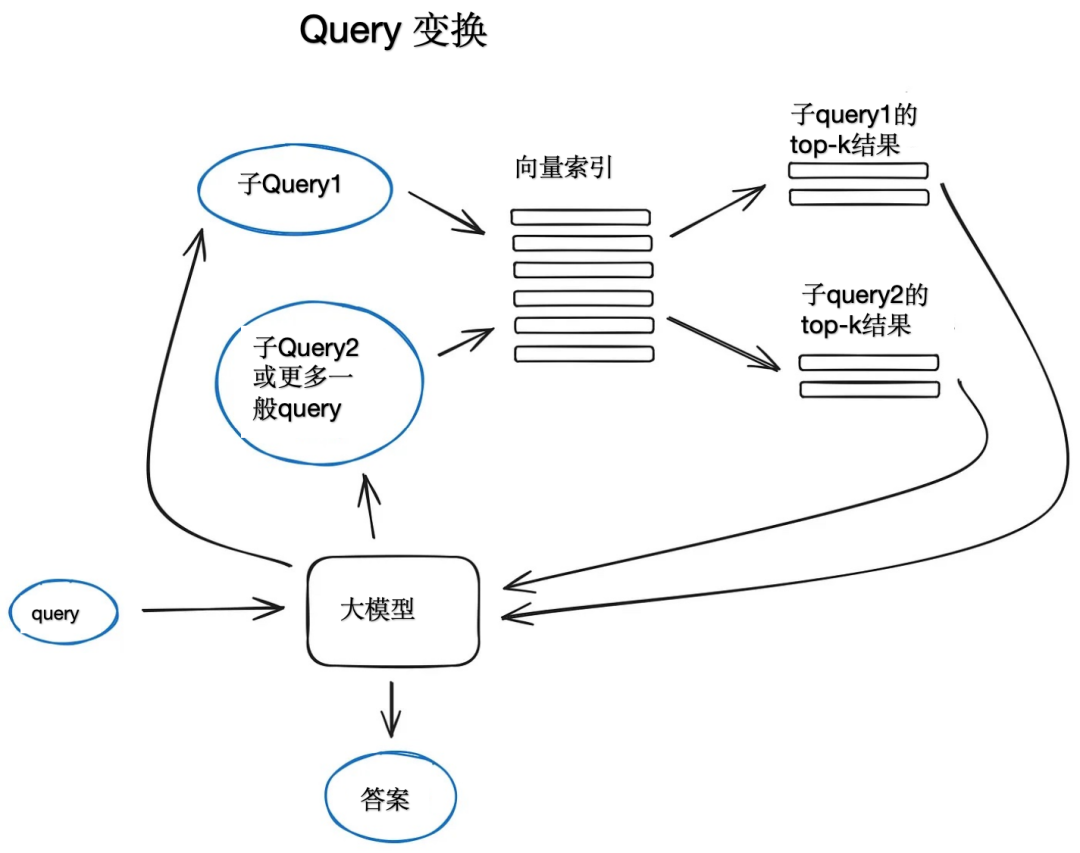
Преобразование запросов — это семейство методов, которые используют LLM в качестве механизма вывода для изменения пользовательского ввода для улучшения качества поиска. Существует множество различных методов на выбор.
Если запрос сложный, LLM может разбить его на несколько подзапросов. Например, если вы спросите «У чего больше звезд на Github, Langchain или LlamaIndex?», то вряд ли вы найдете прямое сравнение в корпусе. Имеет смысл разбить вопрос на два подзапроса, при условии, что там больше Simple и LlamaIndex. поиск более конкретной информации, например: «Сколько звезд у Langchain на Github?», «Сколько звезд у Llammaindex на Github». Они будут выполняться параллельно, а затем полученный контекст будет объединен в приглашении, чтобы LLM синтезирует окончательный ответ на первоначальный запрос. В Langchain как средство поиска нескольких запросов и в Llammaindex как механизм запросов подвопросов.
Подсказка отступить подсказка) используйте LLM Создает более общий запрос, для которого извлекается более общий контекст или контекст более высокого уровня, чтобы ответ на исходный запрос мог быть основан на этом контексте. Кроме того, выполняется извлечение исходного запроса, и на последнем этапе генерации ответа предоставляются два контекста для LLM。LangChain Существует эталонная реализация https://github.com/langchain-ai/langchain/blob/master/cookbook/stepback-qa.ipynb. перезапись запроса использует LLM Переформулируйте первоначальный запрос, чтобы повысить эффективность поиска. Лангчейн и LlamaIndex реализуются, но LlamaIndex Эталонная реализация более мощнаяhttps://llamahub.ai/l/llamapacks-fusionretriever-query_rewrite。
Если для генерации ответа используются несколько источников, либо из-за сложности исходного запроса необходимо выполнить несколько подзапросов, а затем полученный контекст объединить в один ответ, либо один запрос находится в нескольких документах. Соответствующий контекст, способный точно обратная ссылка. Эту задачу цитирования можно вставить в запрос и попросить LLM предоставить идентификатор используемого источника, а затем сопоставить сгенерированную часть ответа с исходным текстовым блоком в индексе. Llammaindex обеспечивает эффективное нечеткое сопоставление на основе этой ситуации. .
3.5. Механизм чата.
Важной особенностью построения системы RAG, которая может запускаться несколько раз в одном запросе, является логика чата, учитывающая контекст разговора, как в LLM Как классические чат-боты, устаревшие. Это необходимо для поддержки дополнительных вопросов, повторяющихся референтов и произвольных пользовательских команд, связанных с контекстом предыдущего высказывания. Технология сжатия запросов может учитывать как контекст чата, так и запросы пользователей. Существует несколько способов добиться сжатия контекста, один из которых популярный и относительно простой. ContextChatEngine, который сначала извлекает контекст, соответствующий запросу пользователя, а затем отправляет его вместе с историей чата из кэша в ЛЛМ, пусть LLM Помните о предыдущем контексте при создании следующего ответа.
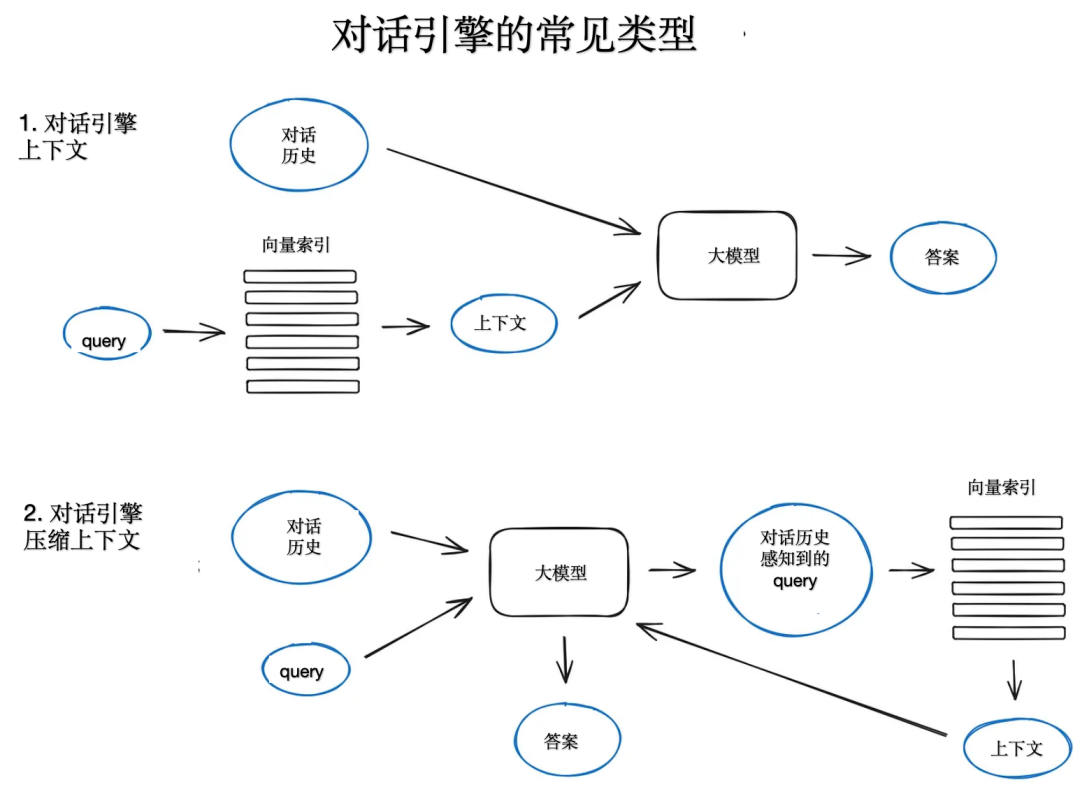
Более сложная реализация CondensePlusContextMode, существует При каждом взаимодействии история чата и последнее сообщение сжимаются в новый из запроса, а затем в этот запрос вводится индекс, полученный из контекста передается в LLM вместе с исходным сообщением пользователя для генерации ответа.
3.6. маршрутизация запросов
Маршрутизация запросов — это этап принятия решений на основе LLM, заключающийся в принятии решения о том, что делать дальше с учетом запроса пользователя. Варианты обычно заключаются в том, чтобы суммировать, выполнить поиск по некоторому индексу данных или попробовать несколько разных маршрутов, а затем объединить их результаты в один ответ.
Запросмаршрутизация также может использоваться для выбора индекса.,или изданные более широкие изданные хранилища,Куда отправлять запросы пользователей,Например,Классическое векторное хранилище и библиотека графических данных или библиотека реляционных данных. верно Для хранения нескольких документов,Очень классической ситуацией является сводный индекс и другой индекс вектора блока документа.
Определение маршрута запроса включает в себя настройку вариантов выбора, которые он может сделать. Маршрутизация осуществляется через LLM Вызванный для выполнения, он возвращает результаты в заранее определенном формате для маршрутизации запросов к заданному индексу. Если используется прокси, запрос перенаправляется к подцепям или даже к другим прокси, как показано в сценарии прокси с несколькими документами ниже. Лама Индекс и LangChain Оба поддерживают маршрутизацию запросов.
3.7. Агент в РАГ
Агенты существуют почти с момента выпуска первого API LLM, и идея заключалась в том, чтобы предоставить LLM, способный рассуждать с набором инструментов и задач, которые необходимо выполнить. Эти инструменты могут включать в себя некоторые детерминированные функции, такие как любые функции кода или внешние API или даже другие агенты, и именно эта идея цепочки LLM и является источником LangChain.
Сами по себе агенты — это огромная тема, OpenAI Помощник в основном реализовал много вещей вокруг LLM Необходимые инструменты, возможно, самое важное — вызовы функций API. Последний обеспечивает перевод естественного языка в запросы к внешним инструментам или базам данных. API вызвана функция. существовать LlamaIndex Среди них есть один OpenAIAgent класс сочетает в себе эту логику высокого уровня с ChatEngine и QueryEngine В сочетании с существованием он обеспечивает функцию чата на основе знаний и контекста, а также несколько вызовов одновременно. OpenAI Функциональные возможности, это действительно приводит к использованию интеллектуальных агентов.
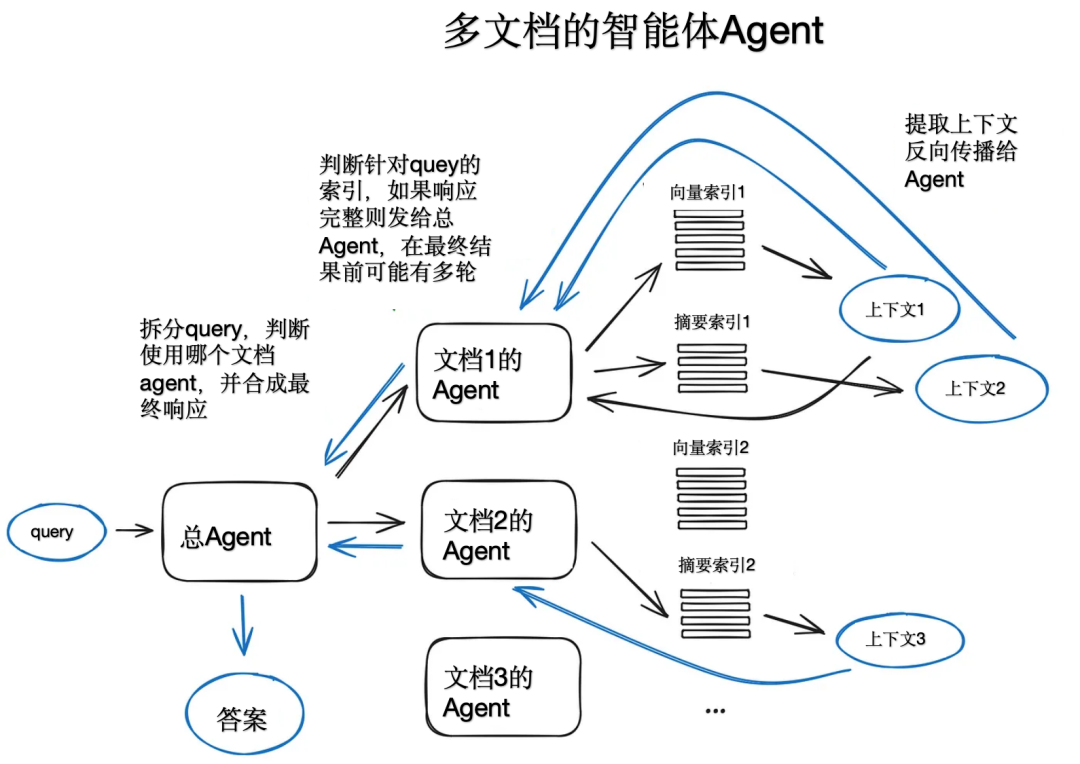
Если взять в качестве примера многодокументный агент, агент (OpenAIAgent) будет инициализирован для каждого документа. , способный к обобщению документов и классический QA механизм, а также главный общий агент, ответственный за маршрутизацию запроса к агенту документа и синтез окончательного ответа. Каждый агент документа имеет два инструмента: вектор хранит сводные индексы индексов и решает, какой инструмент использовать, на основе запроса маршрутизации. Архитектура состоит из большого количества решений, принимаемых каждым соответствующим агентом. Преимущество этого подхода заключается в возможности сравнивать различные решения или объекты, которые отличаются от документов и их сводок, а также от классических сводок отдельных документов и контроля качества. Механизм описан в разделе , который в основном охватывает наиболее распространенные случаи использования чата с наборами документации.
Эта схема немного медленная из-за множества итераций вперед и назад с использованием внутреннего LLM. На всякий случай вызовы LLM оптимизированы по скорости, выполняя самую длинную операцию поиска в конвейере RAG. Поэтому для крупных многодокументных хранилищ схему можно несколько упростить, чтобы сделать ее масштабируемой.
3.8. Синтез ответов.
Состав ответа любой RAG сборочная линии Последним шагом является генерация ответа на основе извлечения всех контекстов исходного запроса пользователя. Самый простой способ — объединить все контексты выборки (выше некоторого порога релевантности) с запросом и предоставить его Магистр права. Однако существуют и другие, более сложные варианты, включающие несколько LLM Вызывается для уточнения полученного контекста и получения более точных ответов. Основными методами синтеза ответа являются:
- Итеративно уточняйте ответ, отправляя полученный контекст в LLM блок за блоком;
- Обобщить полученное из контекста, чтобы оно соответствовало подсказке;
- Генерируйте несколько ответов на основе разных блоков контекста.,Затем подключите его к резюме.
О синтезе ответиз Подробнее,Можно обратиться кв документациииз Примерhttps://docs.llamaindex.ai/en/stable/moduleguides/querying/responsesynthesizers/root.html。
4. Кодер, ориентированный на RAG, и точная настройка большой модели.
Некоторая тонкая настройка моделей глубокого обучения, задействованных в конвейере RAG, кодировщика преобразователя, который отвечает за качество внедрения, тем самым улучшая качество извлечения контекста, и LLM, который отвечает за использование предоставленного контекста для ответа на запросы пользователей. Высококачественные LLM, такие как GPT-4, можно использовать для создания высококачественных синтетических наборов данных. Но всегда следует отметить, что использование модели с открытым исходным кодом, обученной на большом наборе данных, и быстрая ее настройка с использованием небольшого синтетического набора данных могут ослабить общие возможности модели.
Новая версия кодировщика-трансформера весьма эффективна для оптимизации поиска, а bge-large-en-v1.5 по-прежнему может значительно улучшить качество поиска даже в среде ноутбука.
4.1 Точная настройка энкодера
Старый добрый вариант — иметь кросс-энкодер. Если вы не полностью доверяете базовому кодировщику,Кросс-кодер может изменить порядок полученных результатов. Он работает путем передачи каждого из k верхних извлеченных текстовых блоков запроса чередующемуся кодировщику.,разделенный знаком,Затемверноэто продолжаетсятонкая настройка,Соответствующий выход блока равен 1.,Не актуальноиз Выход блока0。Этот процесс корректировки Можно обратиться кhttps://docs.llamaindex.ai/en/latest/examples/finetuning/crossencoderfinetuning/crossencoderfinetuning.html#。
4.2 Точная настройка больших моделей
Недавно OpenAI начал предоставлять API для тонкой настройки LLM, а у LlamaIndex есть руководство по тонкой настройке GPT-3.5-turbo в настройке RAG для «извлечения» некоторых знаний о GPT-4. Основная идея состоит в том, чтобы получить документ, использовать GPT-3.5-turbo для генерации ряда вопросов, а затем использовать GPT-4 для генерации ответов на эти вопросы на основе содержимого документа. То есть построить конвейер RAG на основе GPT4. , а затем сравните GPT с набором данных пары вопрос-ответ -3,5-турбо для точной настройки. Оценка конвейера RAG первоначально показала, что точно настроенная модель GPT 3.5-turbo лучше исходной модели использует предоставленный контекст для генерации ответов.
в бумаге RA-DIT: Meta AI Research В расширенной оптимизации поиска с использованием двух инструкций существует более сложный метод, который предлагает одновременную оптимизацию тройки существующих запросов, контекста и ответа. LLM и ретривер (двойной кодер в оригинальной статье) изтехнология. Эту технологию использовала тонкая настройка API и Модель Llama2 с открытым исходным кодом для тонкой настройки OpenAI LLM (в оригинальной бумаге) , что привело к увеличению показателей наукоемких задач примерно на 5%. (с использованием RAG из Llama265B по сравнению с) ,А задача рассуждения, основанная на здравом смысле, увеличилась на несколько процентных пунктов. Детали реализации,Можно обратиться кhttps://docs.llamaindex.ai/en/stable/examples/finetuning/knowledge/finetuneretrievalaug.html#fine-tuning-with-retrieval-augmentation。
5. Оценка эффективности, ориентированная на RAG
Оценка производительности системы, метрики включают общую корреляцию ответов、Отслеживаемость ответов、Достоверность и поиск, а также контекстная релевантность и многое другое.
Структура Рагаса, использующая достоверность и актуальность ответов как RAG Поисковая часть генерирует ответы на основе показателей качества и классической точности контекста. Система оценки Truelens Рекомендуется использовать контекстную корреляцию между поиском и запросом, отслеживаемость ответа и корреляцию с ответом на запрос, а также использовать эти три показателя в качестве RAG системаиз Тройка оценки производительности。в,Ключевой и наиболее контролируемый показатель извлекается из контекстной релевантности.,Во-вторых, это релевантность и прослеживаемость ответов.
LangChain Существует очень продвинутая система оценки. LangSmith, который может реализовывать собственные оценщики, а также отслеживать RAG сборочная линезировать текущий статус, чтобы сделать систему более прозрачной. И существуютLlamaIndex Существует пакет rag_evaluatoriz, который предоставляет простой инструмент для оценки систем RAG с использованием общедоступного набора данных.
6. Резюме
RAG Помимо актуальности и достоверности ответов, основной задачей системы является скорость. Однако есть много других вещей, которые следует учитывать, например, поиск через Интернет. RAG, глубоко интегрированный с архитектурой агента, и о LLM Долговременная память из некоторых способов и средств. Несмотря на это, R.A.G. Он по-прежнему имеет широкий спектр применения. Когда мы используем RAG для посадки, Я надеюсь, что технологии, упомянутые в этой статье, могут быть полезны каждому.
[Справочные материалы и сопутствующая литература]
- https://docs.llamaindex.ai/en/stable/apireference/servicecontext/nodeparser.html
- https://huggingface.co/spaces/mteb/leaderboard
- https://huggingface.co/BAAI/bge-large-en-v1.5
- https://huggingface.co/intfloat/multilingual-e5-large
- http://boston.lti.cs.cmu.edu/luyug/HyDE/HyDE.pdf
- https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf
- https://python.langchain.com/docs/modules/dataconnection/retrievers/MultiQueryRetriever
- https://docs.llamaindex.ai/en/stable/examples/queryengine/subquestionqueryengine.html
- https://github.com/langchain-ai/langchain/blob/master/cookbook/stepback-qa.ipynb
- https://docs.ragas.io/en/latest/index.html
- https://arxiv.org/pdf/2310.01352.pdf
- https://github.com/truera/trulens/tree/main
- https://docs.smith.langchain.com/
- https://github.com/run-llama/llama-
- hub/tree/dac193254456df699b4c73dd98cdbab3d1dc89b0/llamahub/llamapacks/rag_evaluator



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
