[Большая модель вертикальной области CSIG 2023] Как в эпоху больших моделей завершить унификацию оптического распознавания символов в области интеллектуальной обработки документов IDP?
С 28 по 31 декабря 2023 года в Гуанчжоу, Китай, прошла 19-я конференция молодых ученых CSIG, организованная Китайским обществом изображения и графики. Конференция привлекла экспертов и молодых ученых из академических и деловых кругов и была ориентирована на международные академические границы В соответствии с национальными стратегическими потребностями сосредоточить внимание на новейших передовых технологиях и Горячие области: совместно обсуждайте передовые проблемы в области графической графики и делитесь последними результатами исследований и инновационными идеями. На специальной сессии, посвященной большим моделям в вертикальных полях, доктор Дин Кай, заместитель генерального директора и старший инженер Hehe. Нас возглавил отдел информационных интеллектуальных технологических платформ. Представляем доклад по теме «Размышление и исследование больших моделей изображений документов».
В этой статье основное внимание будет уделено следующим вопросам, а в тематическом отчете будут представлены проблемы исследования и глубокие размышления в области интеллектуальной обработки изображений документов в эпоху больших моделей:
- Какое вдохновение может привнести представительная большая модель GPT4-V Gemini в исследования и разработку технических решений в области IDP?
- Можем ли мы извлечь уроки из преимуществ больших моделей и предложить единую модель OCR с хорошей точностью и сильным обобщением?
- Может ли LLM лучше сочетаться с механизмами анализа распознавания документов для решения основных проблем в области ВПЛ?
1. Унифицированная модель оптического распознавания символов на уровне пикселей: UPOCR.
UPOCR — это единая модель OCR на уровне пикселей, предложенная Объединенной лабораторией анализа, распознавания и понимания изображений документов Hehe Information-South China University в декабре 2023 года. Архитектура кодера-декодера UPOCR на основе визуального преобразователя (ViT),Преобразуйте разнообразные задачи оптического распознавания символов в парадигму преобразования изображений в изображения.,и представили обучаемые подсказки к задачам,Поместите общее представление объекта, извлеченное кодировщиком, в пространство для конкретной задачи.,Сообщите о задаче декодера. Эксперименты показывают,Модели могут иметь функции моделирования для разных задач.,Способен одновременно достичьтекст Стереть、текстразделениеивмешиватьсятекст Обнаружение равного уровня пикселейOCRЗадача。
1.1. Почему предлагается УПЦР?
В настоящее время область общего распознавания символов (OCR) сталкивается с рядом серьезных проблем, которые фактически ограничивают ее широкое применение в различных областях применения.
- Фрагментация моделей, ориентированных на конкретные задачи. Хотя в полевых исследованиях OCR появилось множество моделей, ориентированных на конкретные задачи, каждая модель оптимизирована только для конкретной области. Модель слишком фрагментирована и сложна для совместного использования между различными задачами. Универсальность сцены сильно ограничена.
- Отсутствие интерфейсов: некоторые существующие общие модели полагаются на конкретные интерфейсы или механизмы декодирования, такие как VQGAN.,Эта зависимость ограничивает гибкость и адаптируемость модели в пиксельном пространстве.,Сложно связывать разные задачи.
- Проблемы оптического распознавания символов на уровне пикселей. Современные модели по-прежнему сталкиваются с проблемами при создании текстовых последовательностей на уровне пикселей. Это связано с тем, что генерация текста включает не только семантическое понимание, но также требует учета деталей на уровне пикселей. Улучшение способности модели генерировать текст на уровне пикселей по-прежнему остается важным направлением исследований.
1.2. Что такое УПЦР?
UPOCR — это общая модель OCR, в которой используется команда AAAI Южно-Китайского технологического университета. 2024в принятых статьяхViTEraserв качестве магистральной сети,В то же время для самостоятельного предварительного обучения используется SegMIM, метод предварительного обучения изображений документов с самоконтролем, основанный на карте сегментации MIMи.,затем объединитетекст Стереть、текстразделениеивмешиватьсятекст Тестирование и т. д.3другой Задача Подскажите слова, чтобы продолжитьединыйтренироваться。
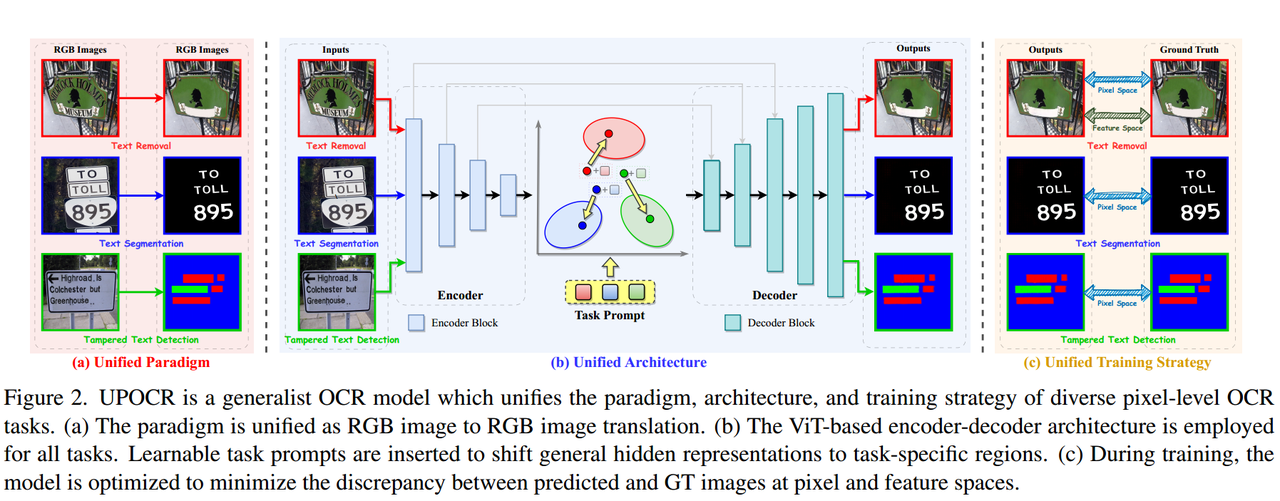
После обучения модели ее можно напрямую использовать для последующих задач.,Незачем, а затем провести специальную доводку,Модель в основном изучается с трех аспектов: единыйпарадигма, единая архитектура и единая стратегия обучения.
1.2.1、Unified Paradigm единый парадигма
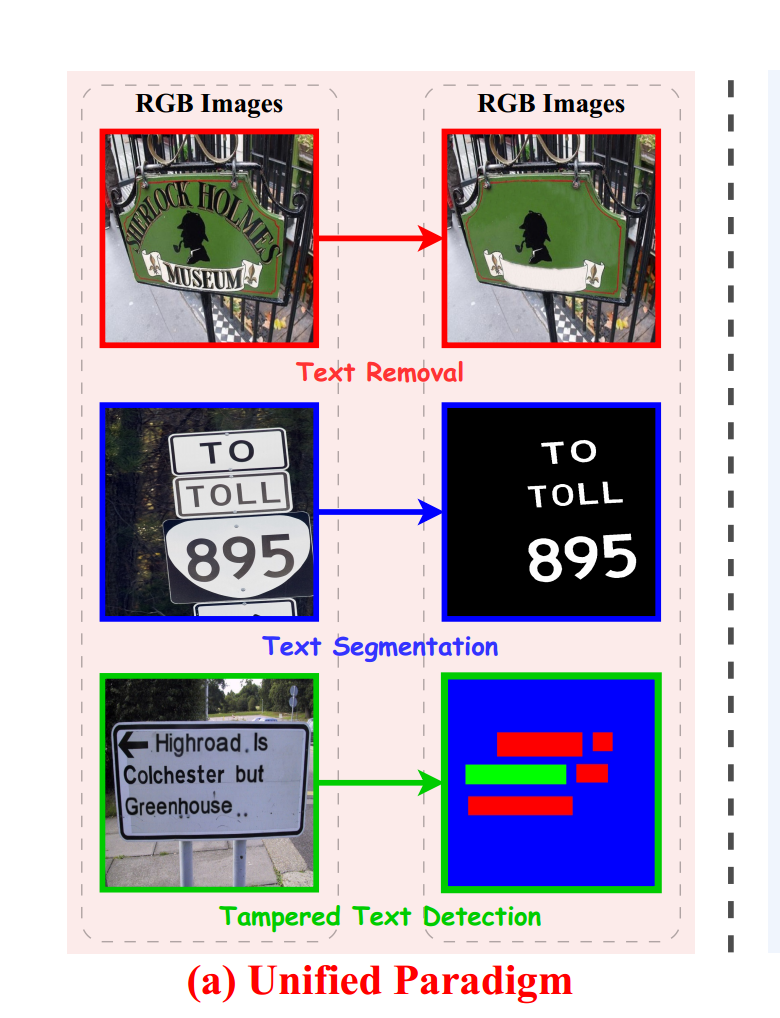
Как показано на картинке,Автор предложил задачу оптического распознавания символов единаяпарадигма.,Он преобразует различные задачи OCR на уровне пикселей в задачи преобразования RGB в RGB. Хотя цели этих задач разные (например, генерация изображений и сегментация),Но их всех можно рассматривать как действующие в общем пространстве функций:
- Задача стирания текста:для Задача стирания текста,Выходные данные представляют собой изображение с удаленным текстом, соответствующее входным данным.,Принадлежит задаче RGBtoRGB.
- задача сегментации текста:текстразделение Стремится назначить каждый пиксель на передний план(Прямо сейчастекстудары)или фон,Парадигма перевода изображений в изображения для единого,UPOCR предсказывает RGB-изображение с белым и черным цветом,Категория определяется путем сравнения расстояния сгенерированного значения RGB с предопределенным значением RGB переднего плана.
- Задача обнаружения поддельного текста:Воля Задача обнаружения поддельного текст определяется как попиксельная классификация подделанного текста, реального текста и категорий фона, а затем UPOCR присваивает красный цвет подделанному тексту, реальному тексту и фону соответственно (255, 0, 0), зеленый (0, 255, 0) и синий (0, 0, 255) Цвет. Во время вывода класс каждого пикселя определяется путем сравнения расстояния прогнозируемого значения RGB до этих трех цветов.
1.2.2、Unified Архитектура Единый Архитектура
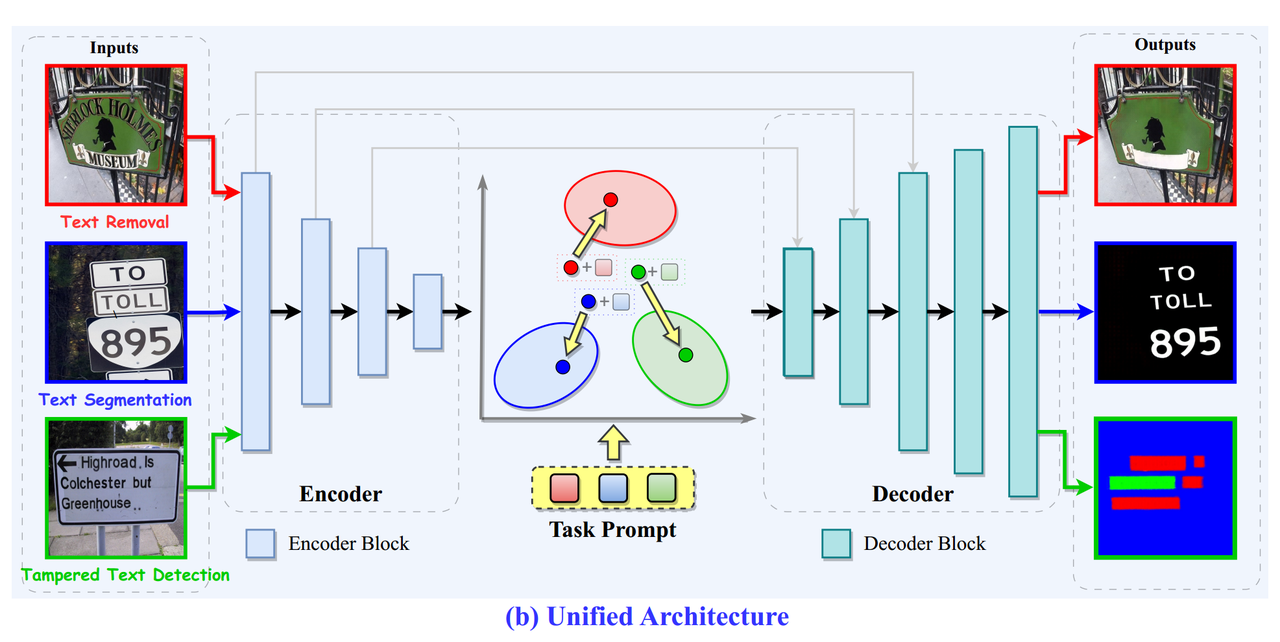
Как показано на картинке,Автор реализует парадигму перевода изображения в изображение, приняв кодер-декодер на основе ViT для решения различных задач OCR на уровне пикселей. в,Архитектура кодировщика-декодера использует ViTERaser в качестве магистральной сети.,Кодировщик состоит из четырех последовательных блоков.,Каждый блок кодера содержит слой внедрения блоков для понижающей дискретизации и Swin. Transformer блок v2. Часть декодера состоит из пяти последовательных блоков, каждый блок декодера содержит слой разделения блоков для повышения дискретизации и Swin. Transformer блок v2. Кроме того, авторы вводят обучаемые подсказки задач в архитектуру кодировщика-декодера, и соответствующие подсказки добавляются к каждому пикселю скрытых функций, генерируемых кодировщиком, перемещая общие представления, связанные с распознаванием текста, сгенерированные кодировщиком, в область, специфичную для задачи. . Затем декодер преобразует скорректированные скрытые функции в выходные изображения для конкретной задачи. Основываясь на этой архитектуре, UPOCR может просто и эффективно выполнять несколько задач одновременно с минимальными параметрами и вычислительными затратами.
1.2.3、Unified Training Strategy единый Стратегия обучения
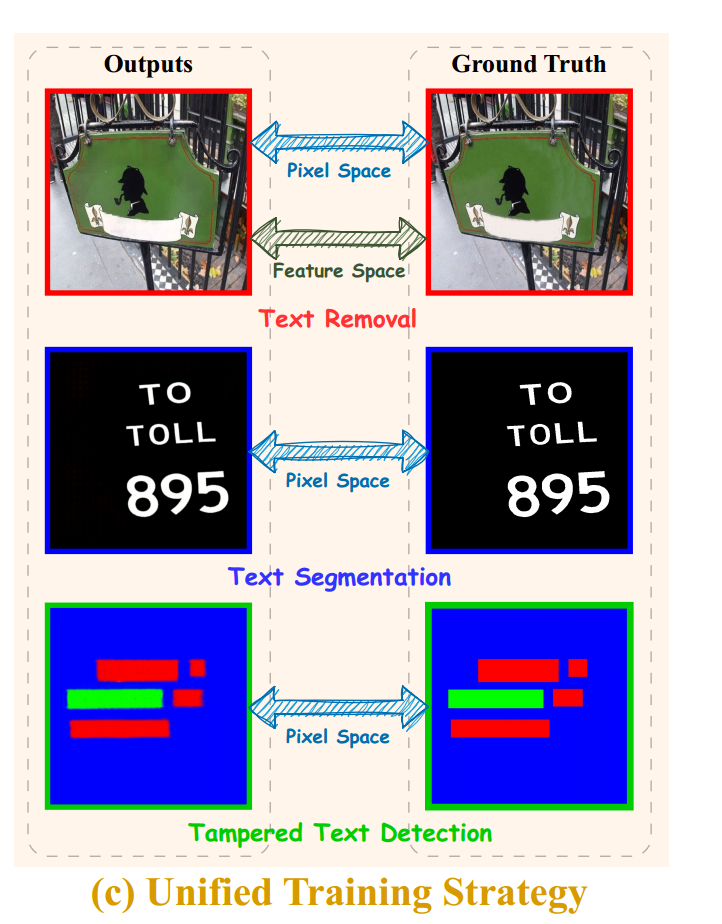
Поскольку модель обучается с использованием парадигмы преобразования изображений в изображения.,Итак, в процессе обучения,Цель оптимизации модели должна учитывать только минимизацию разницы между сгенерированным прогнозируемым изображением и реальным изображением в пространстве пикселей и пространстве признаков.,без учета различий между задачами.

1.3. Насколько эффективен УПЦР?

Результаты эксперимента показаны в трех таблицах выше.,Таблица в левом верхнем углу представляет собой сравнение экспериментов по стиранию текста.,Даже по сравнению с точно настроенными моделями стирания, специфичными для конкретной предметной области.,Модель UPOCRЕдиный также опережает метод SOTA в данной области по большинству показателей. Таблица в правом верхнем углу представляет собой сравнение экспериментов по сегментации текста и изображений;,можно увидеть,UPOCR лучше однозадачных методов сегментации по всем показателям: таблица в левом нижнем углу — обнаружение несанкционированного доступа к тексту;,УПЦР также добился хороших результатов. На рисунке 5 показано, что подсказки, связанные с задачами, разработанные с помощью модели UPOCR, также могут хорошо различать разные задачи.,Изображение нижетекст Стереть、разделение、И наглядная сравнительная таблица обнаружения несанкционированного доступа и методов SOTA для существующих подзадач.

В итоге,UPOCR предлагает простой и эффективный интерфейс OCR на уровне пикселей.,Он использует кодер-декодер на базе ViT.,Решайте различные задачи с помощью обучаемых подсказок,существоватьтекстудалять、текстразделениеивмешиватьсятекст Тестирование и т. д.Задача Отличная производительность на обоих。
2. Краткий обзор передовых исследований унифицированных моделей OCR.
2.1、Donut:Незачем OCR для понимания документа Модель трансформера
Бумажный адрес:https://link.springer.com/chapter/10.1007/978-3-031-19815-1_29
Адрес проекта:https://github.com/clovaai/donut
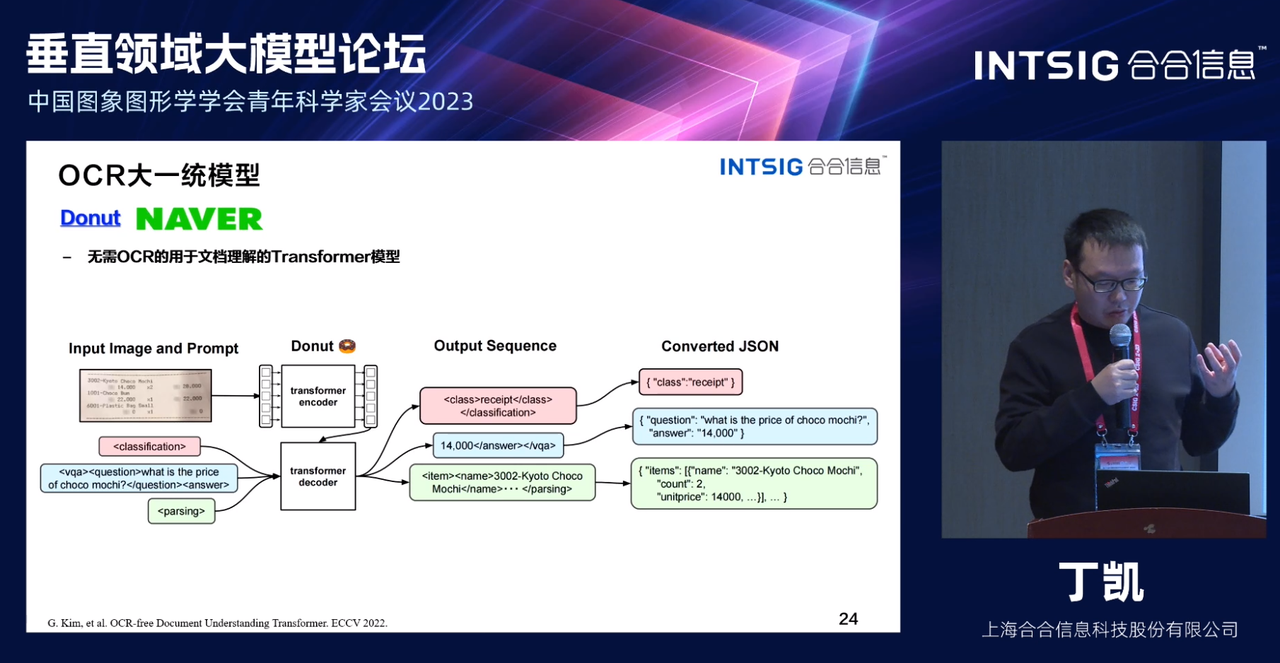
Модель Donut — это новая модель VDU без оптического распознавания символов, основанная на архитектуре Transformer. Модель Donut сначала генерирует макет с помощью простого правила, а затем применяет некоторые методы рендеринга изображений для имитации реальных документов, что выполняется в два этапа предварительной обработки. -обучение и доводка поезда. На этапе предварительного обучения модель использует набор данных IIT-CDIP для моделирования визуального языка и учится читать текст с изображений. На этапе тонкой настройки модель обучается генерировать выходные данные в формате JSON для решения последующих задач, таких как классификация документов, извлечение информации о документе и визуальный ответ на вопросы документа. По сравнению с другими моделями на основе OCR, Donut не нуждается в механизме OCR и поэтому имеет более высокую скорость и меньший размер модели. Эксперименты с несколькими общедоступными наборами данных показывают, что Donut демонстрирует повышенную производительность в задачах классификации документов.
2.2、NouGAT:Внедрить изображение документа в вывод последовательности документов
Бумажный адрес:https://arxiv.org/abs/2308.13418
Адрес проекта:https://github.com/facebookresearch/nougat
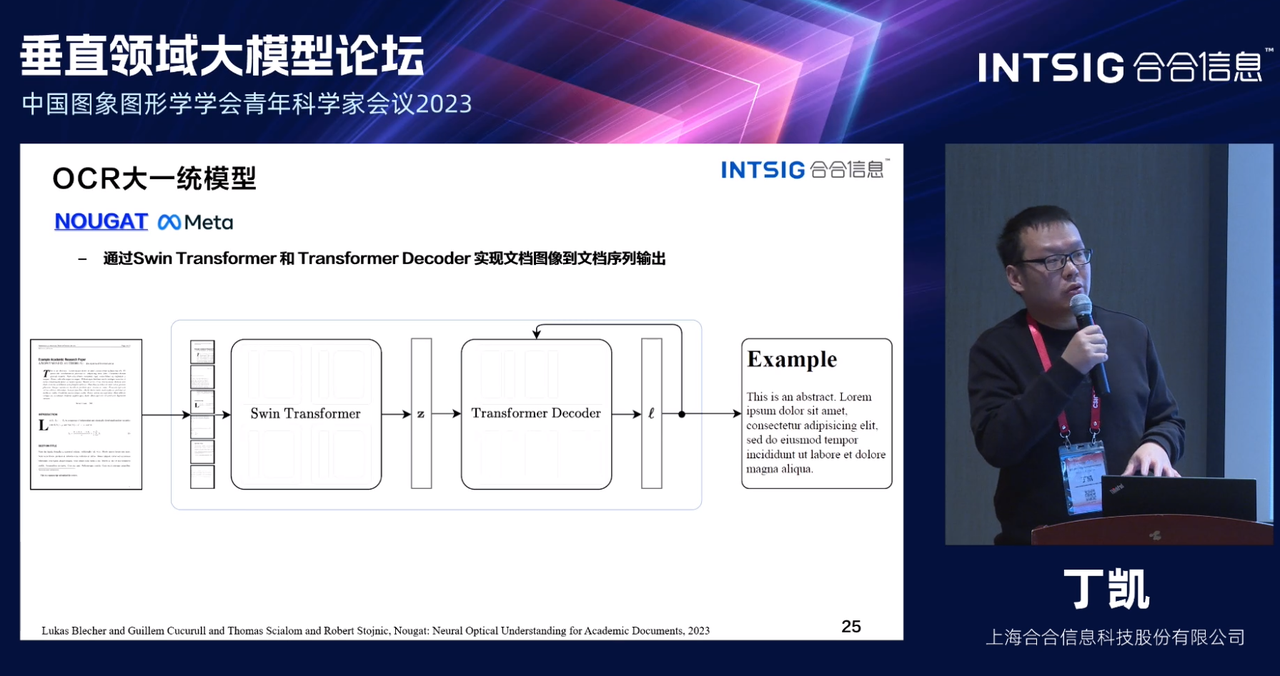
Модель Nougat — это модель оптического распознавания символов, которая реализует изображение документа для вывода последовательности документов с помощью Swing Transformer и Transformer Decoder. Модель использует метод сквозного обучения, основанный на преобразователе без оптического распознавания символов, и обучается с использованием предварительного обучения и точной обработки. тюнинг. На этапе предварительного обучения Donut проходит предварительное обучение с использованием изображений документов и их текстовых аннотаций, обучаясь чтению текста путем объединения изображения и предыдущего текстового контекста для прогнозирования следующего слова. На этапе тонкой настройки Donut учится понимать весь документ на основе последующих задач. Обширные оценки различных задач и наборов данных VDU демонстрируют сильные способности Donut к пониманию.
2.3. SPTS v3: унифицированная модель оптического распознавания символов на основе SPTS.
Бумажный адрес:https://arxiv.org/abs/2112.07917
Адрес проекта:https://github.com/shannanyinxiang/SPTS
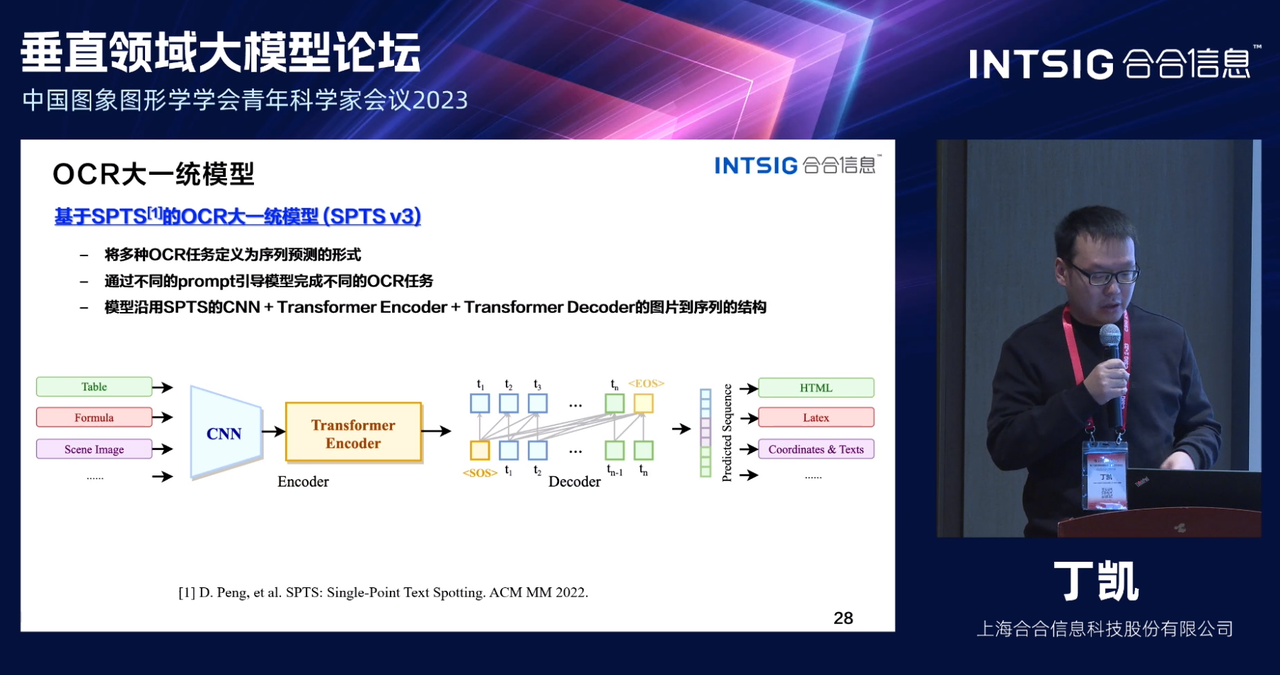
SPTS, полное название Single-Point Text Spotting, представляет собой технологию одноточечного распознавания текста. Ее главное нововведение заключается в том, что метод использует чрезвычайно недорогие одноточечные аннотации для обучения и формализует задачу обнаружения текста в задачу моделирования языка. Для обучения модели распознавания текста сцены необходимо пометить каждый экземпляр текста в одной точке. SPTS основан на авторегрессионной платформе Transformer, которая просто генерирует результаты в виде последовательных токенов, что позволяет избежать сложных этапов постобработки или эксклюзивных этапов выборки. Основываясь на такой краткой структуре, SPTS демонстрирует повышенную производительность на различных наборах данных.
3. Интеллектуальные приложения для обработки документов в эпоху больших моделей
3.1 Применение LLM и анализ распознавания документов.
Модель большого языка может понимать текст на естественном языке и понимать контекст. В приложениях для распознавания и анализа документов работа, связанная с пониманием документов, передается модели большого языка, а автоматическое понимание и анализ документов на уровне глав может помочь. система для лучшего понимания содержания документа, включая связи в контексте, распознавание объектов, анализ настроений и т. д. В настоящее время наиболее распространенные приложения включают расширенную генерацию поиска (RAG), вопросы и ответы по документам, а также анализ макета.
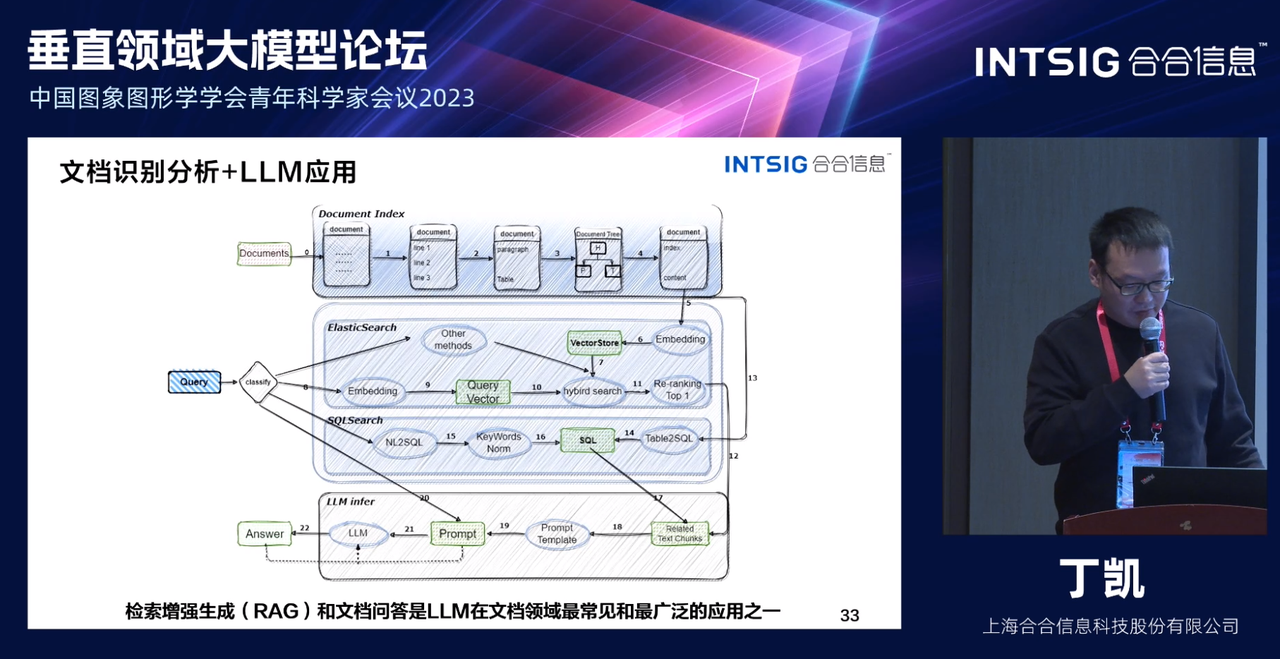
- Генерация улучшений поиска:Уже существуют крупные языковые модели, предназначенные для извлечения актуальной информации из больших объемов документов.,и давать более подробные и точные ответы в генеративной манере. Это имеет важное прикладное значение в сценариях поиска информации.
- Документация: вопросы и ответы:LLMМожет использоваться непосредственно для создания Документация: вопросы и ответысистема,Разрешить пользователям задавать вопросы для получения соответствующей информации в документе.,Может применяться для толкования юридических документов, Запрос технического руководства、Понимание базы знаний и других сценариев.
3.2. Прикладные продукты для интеллектуальной обработки документов.
Интеллектуальная обработка документов (IDP) использует технологию искусственного интеллекта и машинного обучения для автоматического анализа и понимания документов. Она улучшает бизнес-процессы путем идентификации, анализа, понимания содержания документов и преобразования его в полезные данные или информацию. Степень автоматизации повышает эффективность работы и повышает эффективность работы. снижает затраты. Доктор Дин Кай также представил нам Hehe Information, распознавание изображений документов и обмен продуктами для анализа. На основе такой интеллектуальной технологии обработки документов продукт может быстро и точно обрабатывать большое количество документов, помогая банкам, страхованию, логистике, цепочке поставок и клиентам. service Цифровая трансформация во многих областях, включая цифровую трансформацию, для достижения более эффективного и надежного управления бизнес-процессами.
Хотя технология мультимодальных больших моделей, представленная GPT4-V, значительно способствовала технологическому прогрессу в области распознавания и анализа документов, она не полностью решила проблемы, с которыми сталкиваются в области обработки документов-изображений. Есть еще много проблем, заслуживающих нашего внимания. Как объединить Способность больших моделей лучше решать проблемы ВПЛ заслуживает большего размышления и изучения.




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
