Большая модель Qwen2, точная настройка практической задачи распознавания объектов с именем (NER)
Автор: Линь Зейи, доктор философии @XDU, соучредитель SwanLab; Заявление: Эта статья предназначена только для распространения. Авторские права принадлежат оригинальному автору. Нарушающие права личные сообщения будут удалены! Оригинальный текст: https://zhuanlan.zhihu.com/p/704463319 Редактор: Highland Barley AI
Qwen2[1] — это большая языковая модель, исходный код которой недавно был открыт командой Tongyi Qianwen и разработан Alibaba Cloud Tongyi Lab.
Использование Qwen2 в качестве базовой большой модели и выполнение высокоточного распознавания именованных объектов (NER) посредством точной настройки инструкций — очень хорошая задача для изучения вводной тонкой настройки LLM и построения познания большой модели.

Используя метод LoRA для обучения, модель 1.5B не требует большого объема графической памяти и может работать с объемом около 10 ГБ.
В этой статье мы будем использовать модель Qwen2-1.5b-Instruct для выполнения обучения по точной настройке инструкций на китайском наборе данных NER[2], а также использовать SwanLab[3] для мониторинга процесса обучения и оценки эффекта модели.
- • код:Полный код Перейти непосредственно к разделу 5 этой статьи. или Github[4]、Jupyter Notebook[5]
- • Процесс экспериментального журнала: Qwen2-1.5B-NER-Fintune — SwanLab[6]
- • Модель:Modelscope
- • данныенабор:chinese_ner_sft
- • SwanLab:https://swanlab.cn
Пункт знаний 1: Что такое точная настройка инструкций?
Инструкция по доводке больших моделей (Instruction Tuning) — это метод тонкой настройки для больших предварительно обученных языков,Его основная цель — улучшить способность модели понимать и выполнять определенные инструкции, чтобы модель могла точно и надлежащим образом генерировать соответствующие выходные данные или выполнять связанные задачи на основе инструкций на естественном языке, предоставленных пользователем.
Инструкция по тонкой настройке специального фокуса на Ю Шэн Модельсуществоватьследуйте инструкциямпоследовательность и точность,Тем самым расширяя возможности обобщения и практичность Модели в различных сценариях применения.
в практическом применении,Насколько я понимаю,Обновление инструкции по тонкой настройкеДумайте о LLM как о более разумной и мощной традиционной модели НЛП (например, Берта).,для достижения более высокой точностиNLPЗадача。Месток Этот тип Задача Сценарии применения охватываютк ПрошлоеNLPМодельсцена,Многие команды даже используют егоМаркировка интернет-данных。
Пункт знаний 2: Что такое распознавание названного объекта?
Распознавание именованных объектов (NER) — это технология НЛП, в основном используемая для идентификации и классификации важной информации (ключевых слов), упомянутой в тексте. Этими объектами могут быть имена людей, мест, организаций, даты, время, денежные значения и т. д. Цель NER — преобразовать неструктурированную информацию в тексте в структурированную, чтобы ее было легче понять и обработать компьютерами.
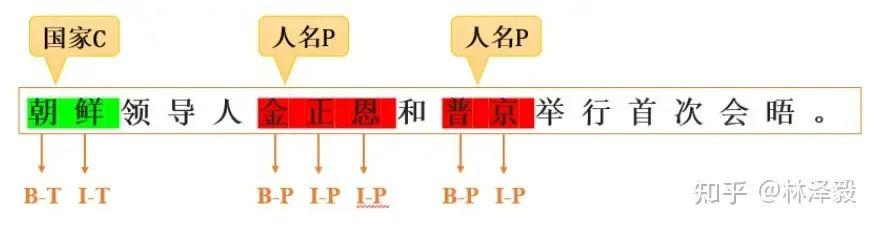
NER также является очень практичной технологией.,включатьсуществовать ИнтернетАннотация данных、поисковая система、Система рекомендаций、График знаний、Он широко используется во многих областях, таких как медицина.
1. Установка среды
Этот случай основан наPython>=3.8,Пожалуйста, установите Python на свой компьютер,И есть видеокарта NVIDIA (требования к памяти не высокие),возможно10GBПросто влево или вправокбегать)。
Нам необходимо установить следующие библиотеки Python. Прежде чем сделать это, убедитесь, что в вашей среде установлены pytorch и CUDA:
swanlab
modelscope
transformers
datasets
peft
accelerate
pandasКоманда установки в один клик:
pip install swanlab modelscope transformers datasets peft pandas accelerateЭтот случай был протестирован на modelscope==1.14.0, Transformers==4.41.2, datasets==2.18.0, peft==0.11.1, ускорении==0.30.1, Swanlab==0.3.11.
2. Подготовьте набор данных
В этом случае используется набор данных chinese_ner_sft на HuggingFace, который в основном используется для обучения моделей распознавания именованных объектов.
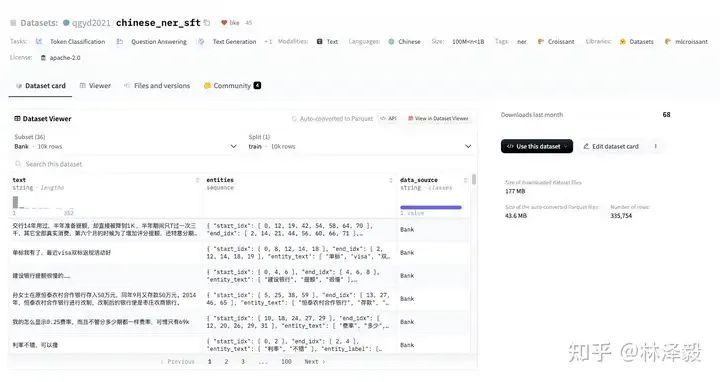
chinese_ner_sft состоит из сотен тысяч данных из разных источников и типов. Это должен быть самый полный набор данных NER для Китая, который я когда-либо видел.
Нам не нужно использовать все его данные для этого обучения. Для обучения мы используем только набор данных CCFBDCI (набор данных для оценки надежности китайского алгоритма распознавания объектов). Этот набор данных включает в себя LOC (местоположение), GPE (географию), There. представляют собой четыре типа сущностей, обозначенных ORG (организация) и PER (имя человека). Примеры каждого фрагмента данных следующие:
{
'text':'Сегодня здесь открылась 12-я министерская встреча АТЭС. На встрече присутствовали министр иностранных дел Китая Тан Цзясюань и министр внешней торговли и экономического сотрудничества Ши Гуаншэн. ',
'entities':[
{
'start_idx':23,
'end_idx':25,
'entity_text':'Китай',
'entity_label':'GPE',
'entity_names':['Геополитическая сущность','Политическая сущность','Географическая сущность','Социальная сущность']},
{
'start_idx':25,
'end_idx':28,
'entity_text':'Министерство иностранных дел',
'entity_label':'ORG',
'entity_names':['организация','группа','учреждение']
},
{
'start_idx':30,
'end_idx':33,
'entity_text':'Тан Цзясюань',
'entity_label':'PER',
'entity_names':['имя','имя']
},
...
],
'data_source':'CCFBDCI'
}Где текст — это входной текст, а объекты — это объекты, извлеченные из текста. Наша цель — надеяться, что точно настроенная большая модель сможет предсказать информацию об объекте в формате json на основе слова-подсказки, состоящего из текста:
входить:АТЭС сегодняорганизовать12-я Министерская конференциясуществовать Открытие здесь,Министр иностранных дел Китая Тан Цзясюань、На встрече присутствовал министр внешней торговли и экономического сотрудничества Ши Гуаншэн.
большой Модельвыход:{'entity_text':'Китай', 'entity_label':'организовать'}{'entity_text':'Тан Цзясюань', 'entity_label':'имя'}...Теперь мы загружаем набор данных в локальный каталог. Способ загрузки — перейти на chinese_ner_sft —huggingface и загрузить ccfbdci.jsonl в корневой каталог проекта:
3. Загрузите модель
Здесь мы используем modelscope для загрузки модели Qwen2-1.5B-Instruct (modelscope находится в Китае, поэтому просто используйте следующий код, чтобы загрузить ее автоматически, не беспокоясь о проблемах со скоростью и стабильностью), а затем загрузите ее в Transformers для обучения:
from modelscope import snapshot_download,AutoTokenizer
from transformers importAutoModelForCausalLM,TrainingArguments,Trainer,DataCollatorForSeq2Seq
model_id ='qwen/Qwen2-1.5B-Instruct'
model_dir ='./qwen/Qwen2-1___5B-Instruct'
# Загрузите QwenModel на modelscope в локальный каталог.
model_dir = snapshot_download(model_id, cache_dir='./',revision='master')
# TransformersЗагрузить вес модели
токенизатор =AutoTokenizer.from_pretrained(model_dir, use_fast=False, trust_remote_code=True)
model =AutoModelForCausalLM.from_pretrained(model_dir, device_map='auto', torch_dtype=torch.bfloat16)
model.enable_input_require_grads() # Этот метод необходимо выполнять, когда включена контрольная точка градиента.4. Настройте инструменты визуализации обучения.
Мы используем SwanLab для мониторинга всего процесса обучения и оценки конечного эффекта модели.
Это реализовано напрямую с помощью интеграции SwanLab и Transformers:
from swanlab.integration.huggingface import SwanLabCallback
swanlab_callback = SwanLabCallback(...)
trainer = Trainer(
...
callbacks=[swanlab_callback],
)Если вы впервые используете SwanLab, вам необходимо зарегистрировать учетную запись на https://swanlab.cn, скопировать свой API-ключ на странице настроек пользователя, а затем вставить его при начале обучения:

5. Полный код
Структура каталогов при начале обучения:
|--- train.py
|--- ccfbdci.jsonltrain.py:
import json
import pandas as pd
import torch
from datasets importDataset
from modelscope import snapshot_download,AutoTokenizer
from swanlab.integration.huggingface importSwanLabCallback
from peft importLoraConfig,TaskType, get_peft_model
from transformers importAutoModelForCausalLM,TrainingArguments,Trainer,DataCollatorForSeq2Seq
import os
import swanlab
def dataset_jsonl_transfer(origin_path, new_path):
'''
Преобразование исходного набора данных в новый набор данных с большой моделью. Точная настройка требуемого формата данных.
'''
messages =[]
# Чтение старых файлов JSONL
with open(origin_path,'r')as file:
for line in file:
# Разобрать jsonданные для каждой строки
data = json.loads(line)
input_text = data['text']
entities = data['entities']
match_names =['Место','Имя человека','Географический объект','Организация']
entity_sentence =''
for entity in entities:
entity_json = dict(entity)
entity_text = entity_json['entity_text']
entity_names = entity_json['entity_names']
for name in entity_names:
if name in match_names:
entity_label = name
break
entity_sentence += f'''{{'entity_text': '{entity_text}', 'entity_label': '{entity_label}'}}'''
if entity_sentence =='':
entity_sentence ='Объект не найден'
message ={
'instruction':'''Вы являетесь экспертом в области распознавания текстовых объектов, и вам нужно извлечь из заданного предложения Место; имя; географический субъект; организовать сущность. к json формат вывода, нравиться {'entity_text': «Нанкин», 'entity_label': 'Географический объект'} Уведомление: 1. Каждая строка вывода должна быть правильной json нить. 2. Если ни одна сущность не найдена, Вывод «Объекты не найдены». ''',
'input': е'текст:{input_text}',
'output': entity_sentence,
}
messages.append(message)
# Сохраните восстановленный файл JSONL.
with open(new_path,'w', encoding='utf-8')as file:
for message in messages:
file.write(json.dumps(message, ensure_ascii=False)+'\n')
def process_func(example):
'''
Предварительная обработка набора данных
'''
MAX_LENGTH =384
input_ids, attention_mask, labels =[],[],[]
system_prompt ='''Вы являетесь экспертом в области распознавания текстовых объектов и вам необходимо извлечь из заданного предложения Место; имя; географический субъект; организовать сущность. к json формат вывода, нравиться {'entity_text': «Нанкин», 'entity_label': 'Географический объект'} Уведомление: 1. Каждая строка вывода должна быть правильной json нить. 2. Если ни одна сущность не найдена, Вывод «Объекты не найдены».'''
instruction = tokenizer(
f'<|im_start|>system\n{system_prompt}<|im_end|>\n<|im_start|>user\n{example['input']}<|im_end|>\n<|im_start|>assistant\n',
add_special_tokens=False,
)
response = tokenizer(f'{example['output']}', add_special_tokens=False)
input_ids = instruction['input_ids']+ response['input_ids']+[tokenizer.pad_token_id]
attention_mask =(
instruction['attention_mask']+ response['attention_mask']+[1]
)
labels =[-100]* len(instruction['input_ids'])+ response['input_ids']+[tokenizer.pad_token_id]
if len(input_ids)> MAX_LENGTH:# сделать усечение
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return{'input_ids': input_ids,'attention_mask': attention_mask,'labels': labels}
def predict(messages, model, tokenizer):
device ='cuda'
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors='pt').to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids =[
output_ids[len(input_ids):]for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
return response
model_id ='qwen/Qwen2-1.5B-Instruct'
model_dir ='./qwen/Qwen2-1___5B-Instruct'
# Загрузите QwenModel на modelscope в локальный каталог.
model_dir = snapshot_download(model_id, cache_dir='./',revision='master')
# TransformersЗагрузить вес модели
токенизатор =AutoTokenizer.from_pretrained(model_dir, use_fast=False, trust_remote_code=True)
model =AutoModelForCausalLM.from_pretrained(model_dir, device_map='auto', torch_dtype=torch.bfloat16)
model.enable_input_require_grads()# Этот метод необходимо выполнять, когда включена контрольная точка градиента.
# Загрузка и обработка наборов данных и тестовых наборов
train_dataset_path ='ccfbdci.jsonl'
train_jsonl_new_path ='ccf_train.jsonl'
ifnot os.path.exists(train_jsonl_new_path):
dataset_jsonl_transfer(train_dataset_path, train_jsonl_new_path)
# Получить обучающий набор
total_df = pd.read_json(train_jsonl_new_path, lines=True)
train_df = total_df[int(len(total_df)*0.1):]
train_ds =Dataset.from_pandas(train_df)
train_dataset = train_ds.map(process_func, remove_columns=train_ds.column_names)
config =LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=['q_proj','k_proj','v_proj','o_proj','gate_proj','up_proj','down_proj'],
inference_mode=False,# режим обучения
r=8,# Lora классифицировать
lora_alpha=32,# Lora алаф, информацию о конкретных функциях см. Lora принцип
lora_dropout=0.1,# Dropout Пропорция
)
model = get_peft_model(model, config)
args =TrainingArguments(
output_dir='./output/Qwen2-NER',
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=2,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to='none',
)
swanlab_callback =SwanLabCallback(
project='Qwen2-NER-fintune',
experiment_name='Qwen2-1.5B-Instruct',
описание = 'Используйте модель Tongyi Qianwen Qwen2-1.5B-Instruct для точной настройки набора данных NER для выполнения ключевых задач распознавания объектов. ',
config={
'model': model_id,
'model_dir': model_dir,
'dataset':'qgyd2021/chinese_ner_sft',
},
)
trainer =Trainer(
model=model,
args=args,
train_dataset=train_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[swanlab_callback],
)
trainer.train()
# Используйте тестовый набор из 20 случайных предметов, тест Модель.
# получить тестовый набор
test_df = total_df[:int(len(total_df)*0.1)].sample(n=20)
test_text_list =[]
for index, row in test_df.iterrows():
instruction = row['instruction']
input_value = row['input']
messages =[
{'role':'system','content': f'{instruction}'},
{'role':'user','content': f'{input_value}'}
]
response = predict(messages, model, tokenizer)
messages.append({'role':'assistant','content': f'{response}'})
result_text = f'{messages[0]}\n\n{messages[1]}\n\n{messages[2]}'
test_text_list.append(swanlab.Text(result_text, caption=response))
swanlab.log({'Prediction': test_text_list})
swanlab.finish()Когда вы увидите индикатор выполнения ниже, начнется обучение:

5. Демонстрация результатов обучения
Посмотреть окончательные результаты обучения на SwanLab:
Видно, что через 2 эпохи потери тонко настроенного qwen2 сократились до хорошего уровня — конечно, для больших моделей реальная оценка эффекта зависит от субъективного эффекта.
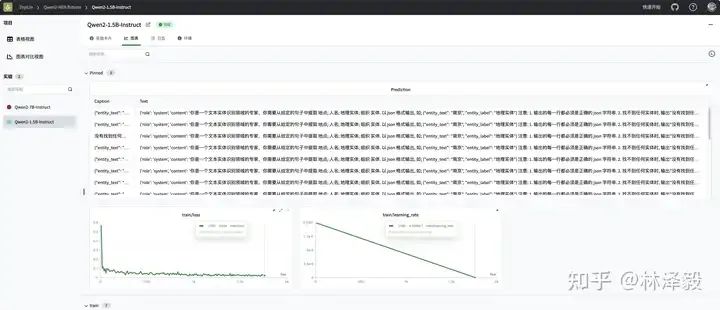
Видно, что на некоторых тестовых образцах точно настроенный qwen2 может давать точные результаты извлечения объектов:
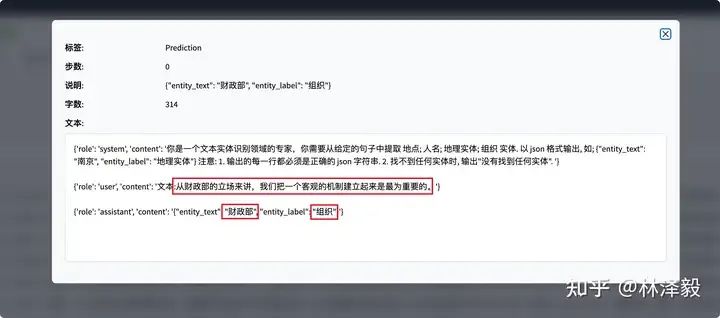

На этом вы завершили обучение тонкой настройке команды qwen2!
6. Сделайте вывод об обученной модели
Обученная модель по умолчанию сохраняется в папке ./output/Qwen2-NER.
Код модели вывода следующий:
import torch
from transformers importAutoModelForCausalLM,AutoTokenizer
from peft importPeftModel
def predict(messages, model, tokenizer):
device ='cuda'
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors='pt').to(device)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)
generated_ids =[output_ids[len(input_ids):]for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
# Загрузите токенизатор и модель исходного пути загрузки.
tokenizer =AutoTokenizer.from_pretrained('./qwen/Qwen2-1___5B-Instruct/', use_fast=False, trust_remote_code=True)
model =AutoModelForCausalLM.from_pretrained('./qwen/Qwen2-1___5B-Instruct/', device_map='auto', torch_dtype=torch.bfloat16)
# Загрузите обученную модель Lora и замените следующее [checkpoint-XXX] фактическим именем файла контрольной точки.
model =PeftModel.from_pretrained(model, model_id='./output/Qwen2-NER/checkpoint-1700')
input_text ='Чэнь Чжимин из Сианьского университета электронных наук и технологий влюбился в Су Чуньхуна из соседнего Северо-Западного политехнического университета. После окончания учебы они согласились поселиться в Сучжоу, Китай. '
test_texts ={
'instruction':'''Вы являетесь экспертом в области распознавания текстовых объектов, и вам нужно извлечь из заданного предложения Место; имя; географический субъект; организовать сущность. к json формат вывода, нравиться; {'entity_text': «Нанкин», 'entity_label': 'Географический объект'} Уведомление: 1. Каждая строка вывода должна быть правильной json нить. 2. Если ни одна сущность не найдена, Вывод «Объекты не найдены». ''',
'input': f'Текст:{input_text}'
}
instruction = test_texts['instruction']
input_value = test_texts['input']
messages =[
{'role':'system','content': f'{instruction}'},
{'role':'user','content': f'{input_value}'}
]
response = predict(messages, model, tokenizer)
print(response)Результат:
{'entity_text':'Сидианский университет','entity_label':'организовать'}
{'entity_text':'Чэнь Чжимин','entity_label':'name'}
{'entity_text':'северо-западная промышленностьбольшойизучать','entity_label':'организовать'}
{'entity_text':'Су Чунхун','entity_label':'имя'}
{'entity_text':'Китай','entity_label':'Географический объект'}
{'entity_text':'Сучжоу','entity_label':'Географический объект'}Справочная ссылка
[1] Qwen2: https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary
[2] Китайский НЭР: https://huggingface.co/datasets/qgyd2021/chinese_ner_sft
[3] SwanLab: https://swanlab.cn/
[4] Github: https://github.com/Zeyi-Lin/LLM-Finetune
[5] Jupyter Notebook: https://github.com/Zeyi-Lin/LLM-Finetune/blob/main/notebook/train_qwen2_ner.ipynb
[6] Qwen2-1.5B-NER-Fintune - SwanLab: https://swanlab.cn/@ZeyiLin/Qwen2-NER-fintune/runs/9gdyrkna1rxjjmz0nks2c/chart



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
