Big Data NiFi (19): импортируйте данные журнала Json в реальном времени в Hive.
Импортируйте данные журнала Json в реальном времени в Hive.
Случай: используйте NiFi для импорта файлов журналов типа JSON, созданных в определенном каталоге, в Hive. Здесь данные сначала анализируются в атрибуты данных Json через NiFi, а затем вручную задается формат данных и данные импортируются в HDFS. Hive устанавливает путь сопоставления таблиц для импорта внешних данных в Hive.
Используемые процессоры: «TailFile», «EvaluateJsonPath», «ReplaceText» и «PutHDFS».
1. Настройте процессор TailFile.
Процессор TailFile «отслеживает» файл или список файлов и принимает данные из файла по мере их записи в файл. Отслеживаемые файлы имеют текстовый формат, и данные принимаются при записи новых строк. Если файл, который вы хотите отслеживать, регулярно «переворачивается» (что часто случается с файлами журналов), вы можете использовать дополнительный «Шаблон смены имен файлов» для извлечения данных из свернутого файла. Прокрутка происходит, когда NiFi не работает. Файлы по-прежнему будут отслеживаться после перезапуска NiFi. Рекомендуется установить план работы на несколько секунд и не использовать для запуска 0 секунд по умолчанию, иначе этот процессор будет потреблять много ресурсов. Этот процессор не поддерживает мониторинг сжатых файлов.
Описание конфигурации «Свойства» процессора «TailFile» следующее:
Элементы конфигурации | значение по умолчанию | разрешенные значения | описывать |
|---|---|---|---|
Режим хвоста (режим монитора) | Single file | ▪Single file ▪Multiple files | Один файл будет содержать только один файл, а несколько файлов будут содержать список файлов. В многофайловом режиме необходимо настроить «Базовый каталог». |
Файл(ы) в Tail (файл мониторинга) | В режиме одного файла — полный путь к файлу конфигурации. Если вы используете режим нескольких файлов, настройте здесь регулярное выражение, соответствующее файлу, который будет отслеживаться в базовом каталоге. Если для параметра «Рекурсивный поиск» установлено значение true, регулярное выражение будет использоваться для сопоставления рекурсивного поиска по пути, начиная с «Базового». каталог». . | ||
Прокручивающийся шаблон имени файла (скользящее совпадение имен файлов) | Настройте имя совпадающего файла, поддерживающее подстановочные знаки * и ? , поддерживает атрибут ${filename} для указания режима. Если NiFi перезапускается, уже прокрутленные файлы можно отслеживать с того места, где они были остановлены. | ||
Базовый каталог (Основной каталог) | Базовый каталог, используемый для поиска файлов, которые необходимо отслеживать. Требуется при использовании многофайлового режима. | ||
Начальная стартовая позиция (Исходное положение мониторинга) | Beginning of File | Когда процессор впервые начинает отслеживать данные, это свойство указывает, где процессор должен начать считывать данные. После того, как процессор извлекает данные из файла, он продолжит отслеживать данные с последней позиции полученных данных. Доступны следующие варианты: ▪Начало файла ▪Начало времени ▪Начало файла ▪Текущее время | |
Государство Местоположение (местоположение данных) | Local | ▪Local ▪Remote | Укажите, где состояние находится локально или в кластере, чтобы состояние можно было хранить надлежащим образом и данные не дублировались. |
Рекурсивный поиск | false | ▪Local ▪Remote | При использовании режима «несколько файлов» это свойство определяет, нужно ли рекурсивно перечислять файлы в базовом каталоге. |
Частота поиска | 10 minutes | Используется только в режиме «несколько файлов». Он определяет минимальное время ожидания процессора перед перечислением файлов, которые необходимо снова отслеживать. | |
Максимальный возраст (максимальное время) | 24 hours | Используется только в режиме «несколько файлов». Если время, прошедшее с момента последнего изменения файла, превышает этот настроенный период времени, файл не будет отслеживаться. |
Шаги настройки следующие:
1. Создайте процессор TailFile.
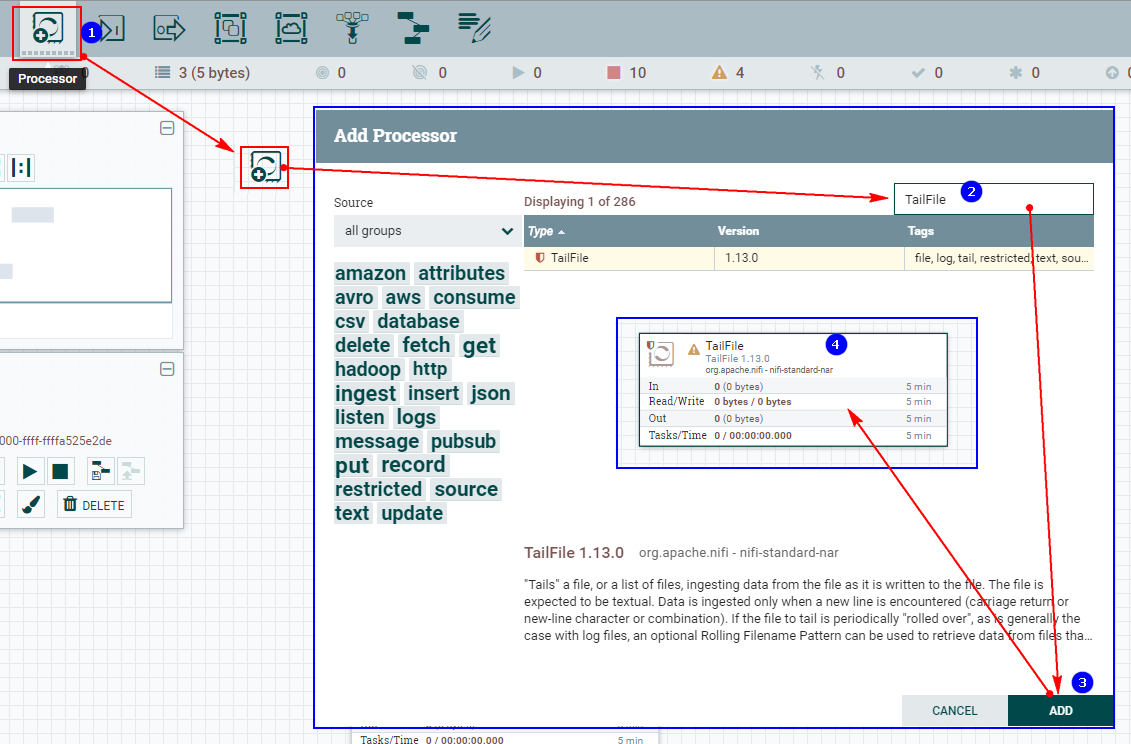
2. Настройте «СВОЙСТВА»
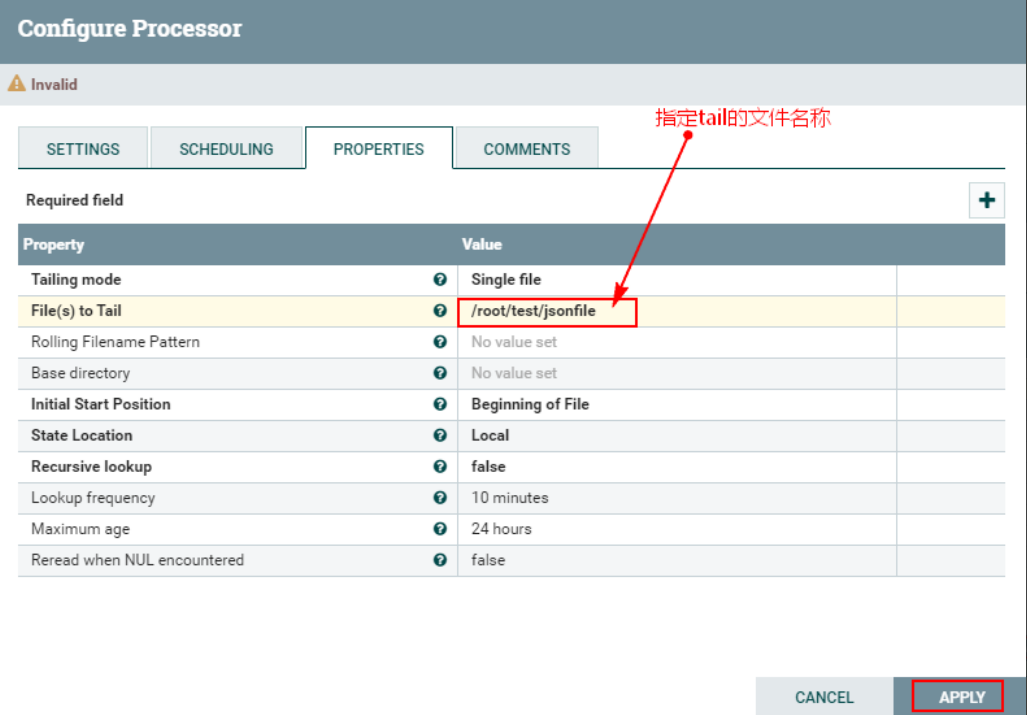
Уведомление:Вышеупомянутое должно быть вNiFiСоздается на каждом узле кластера“/root/test/jsonfile”документ,«jsonfile» — это файл,а не каталог.
2. Настройте процессор EvaluateJsonPath.
Процессор EvaluateJsonPath оценивает одно или несколько выражений JsonPath на основе содержимого FlowFile. В зависимости от конфигурации процессора результаты этих выражений присваиваются свойствам FlowFile или записываются в содержимое самого FlowFile.
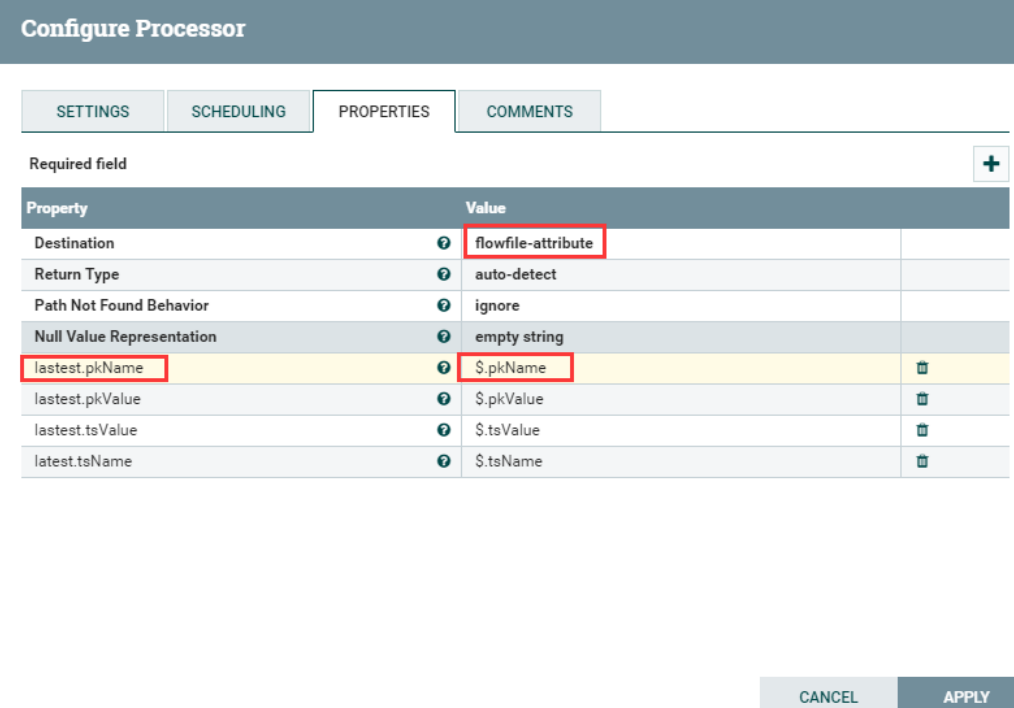
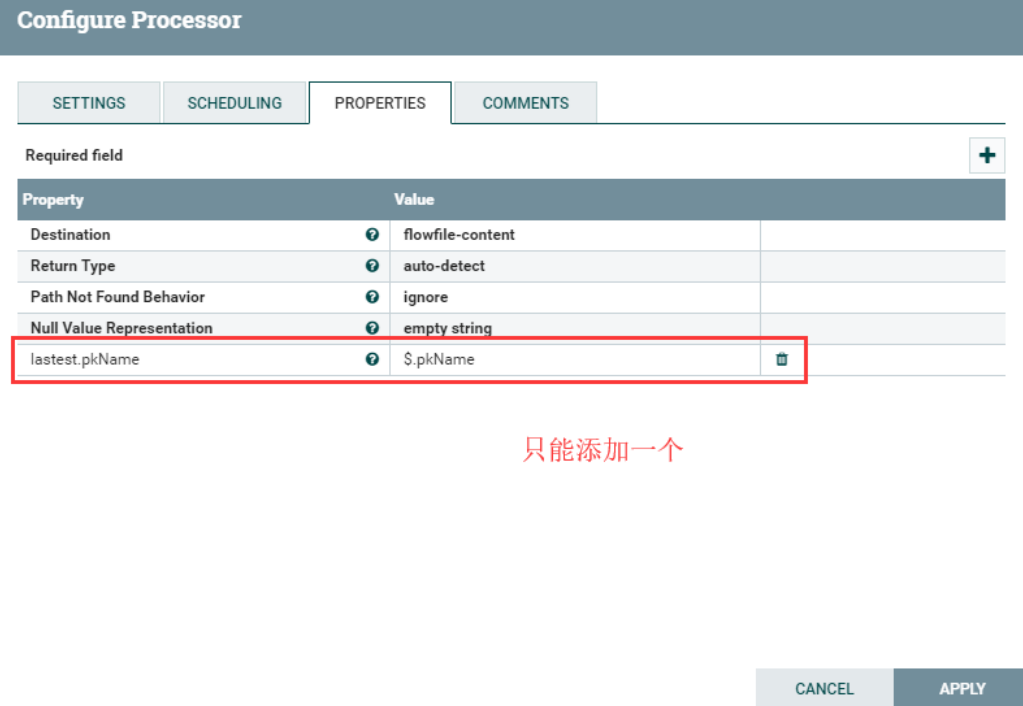
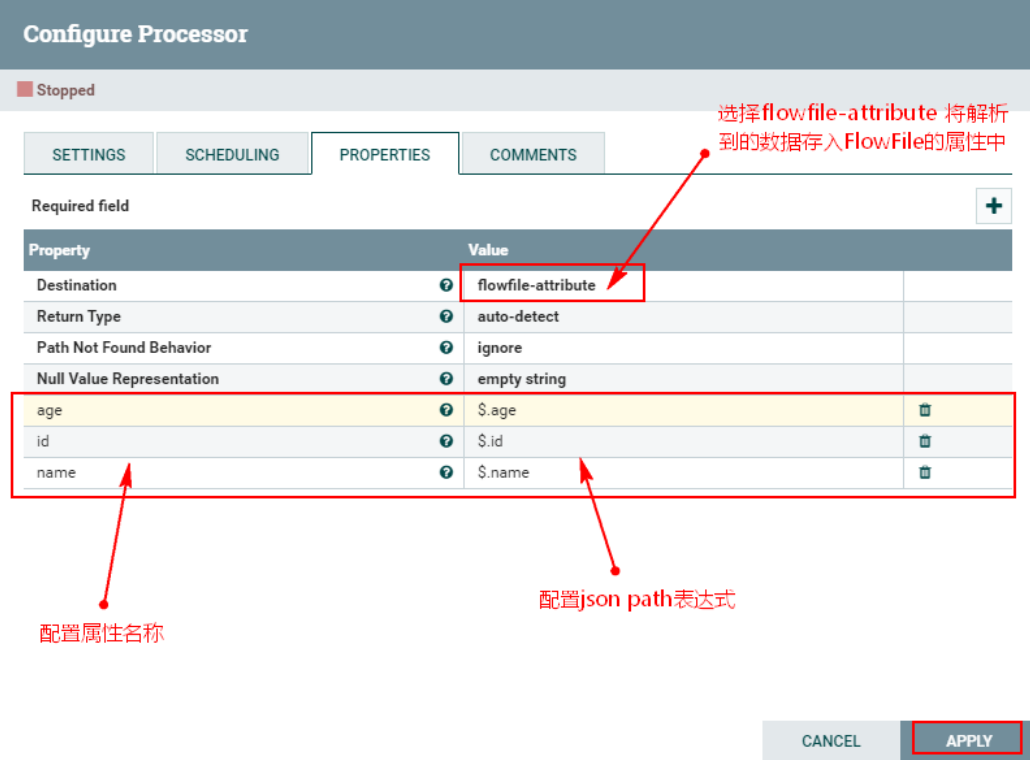
Введите Jsonpath, добавив определенные пользователем атрибуты. Имя добавленного атрибута сопоставляется с именем атрибута в выходном потоке. Значение атрибута должно быть допустимым выражением JsonPath (например: $.name). Тип возвращаемого значения «автоопределение» будет определяться на основе настроенной цели. Если для параметра «Destination» установлено значение «flowfile-attribute», будет использоваться «скалярный» тип возвращаемого значения. Если для параметра «Destination» установлено значение «flowfile-content», будет использоваться тип возвращаемого значения «JSON».
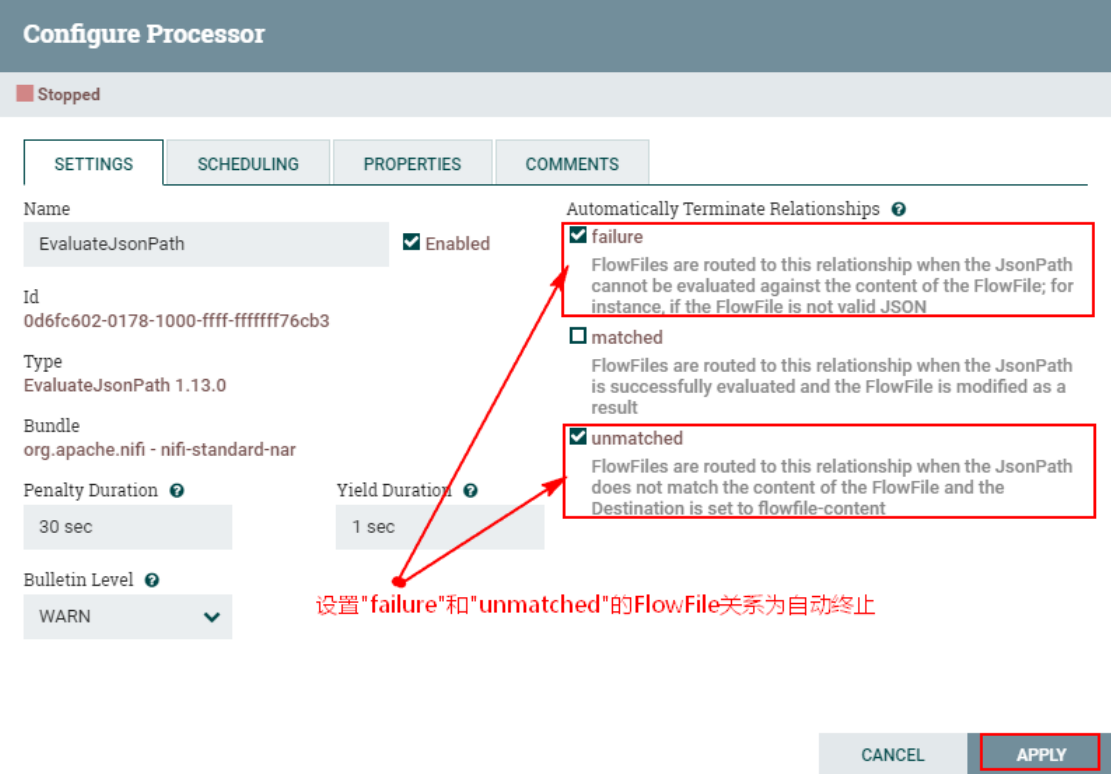
Если JsonPath оценивается как массив JSON или объект JSON и для типа возвращаемого значения установлено значение «скалярный», файл потока не будет изменен и будет перенаправлен на сбой. Тип возвращаемого значения JSON может возвращать «скаляр», если предоставленный JsonPath оценивается как указанное значение. Если целью является «flowfile-content» и JsonPath не вычисляет соответствующее значение, то файл потока будет перенаправлен в «unmatched» без изменения его содержимого. Если целью является «flowfile-attribute» и выражение ничему не соответствует, то в качестве значения атрибута будет использоваться пустая строка, а FlowFile всегда будет перенаправляться на «соответствующий».
Описание конфигурации «Свойства» процессора «EvaluateJsonPath» следующее:
Элементы конфигурации | значение по умолчанию | разрешенные значения | описывать |
|---|---|---|---|
Место назначения (Цель) | flowfile-content | ▪flowfile-content ▪flowfile-attribute | Указывает, записываются ли результаты вычислений JsonPath в содержимое FlowFile или в атрибут FlowFile. При использовании атрибута flowfile необходимо указать имя атрибута. Если установлено значение flowfile-content, можно указать только один JsonPath, а имя свойства игнорируется. |
Тип возврата (тип возвращаемого значения) | auto-detect | ▪auto-detect ▪json ▪scalar | Указывает ожидаемый тип возвращаемого значения выражения пути JSON. Выберите «автоматическое обнаружение», тип возвращаемого значения «flowfile-content» автоматически устанавливается на «json», а тип возвращаемого значения «flowfile-attribute» автоматически устанавливается на «скалярный» скаляр. |
Поведение «Путь не найден» (путь не найден) | ignore | ▪warn ▪ignore | Указывает, как обрабатывать отсутствующие выражения пути JSON при установке для параметра Destination значения «flowfile-attribute». Если выбрать «Предупреждать», будет выдано предупреждение, если выражение пути JSON не найдено. |
Представление нулевого значения (Нулевое значение указывает) | empty string | ▪empty string ▪the string 'null' | Указывает желаемое представление выражения пути JSON, которое возвращает нулевое значение. |
Пример описания:
- Извлечь содержимое файла потока в формате JSON,Как свойство выходного потока. (Уведомление: Когда выходные данные выбирают атрибут flowfile,Даже если jsonpath не соответствует значению,Потоковые файлы также будут перенаправлены на соответствующие)
Введите json следующим образом:
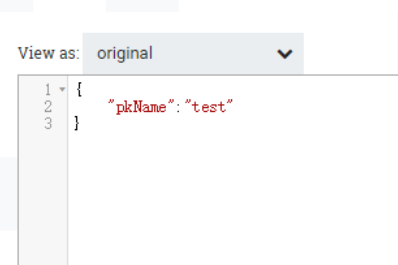
Вывод следующий:
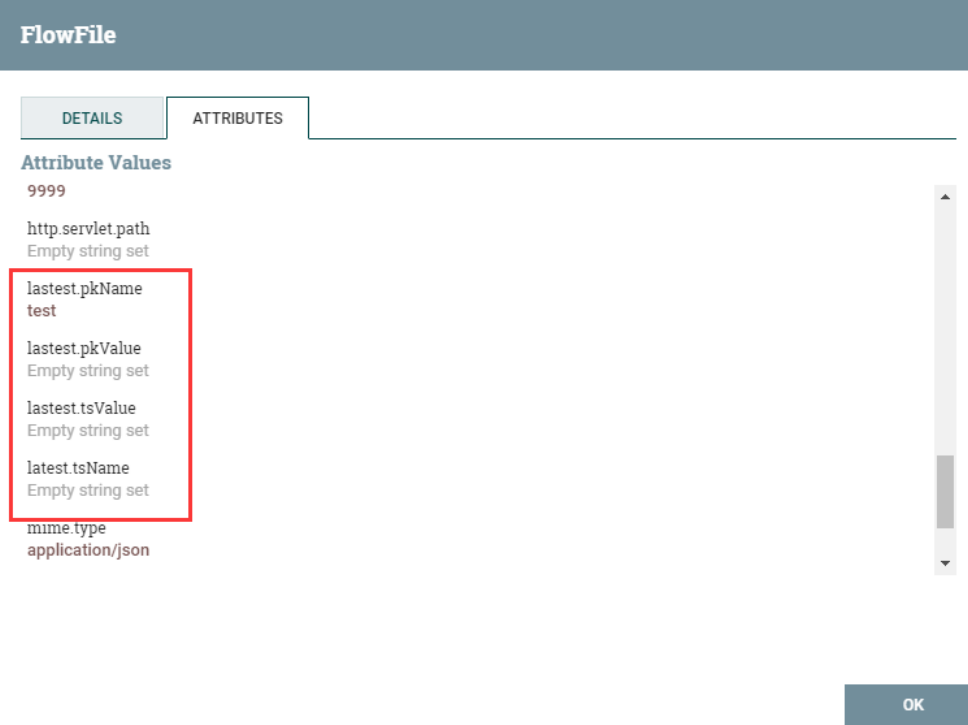
- Извлечь содержимое файла потока в формате JSON,как содержимое выходного потока. (Уведомление: если выбрано содержимое потокового файла,Пользователи могут добавить только один пользовательский атрибут, если jsonPath не соответствует;,будет перенаправлено на непревзойденный)
Содержимое выходного потока:
После ознакомления с тем, как использовать «EvaluateJsonPath»,Далее для настройки,Шаги настройки следующие:
1. Создайте процессор EvaluateJsonPath.
2. Настройте «СВОЙСТВА»
3. Соедините процессор TailFile и процессор EvaluateJsonPath.

3. Настройте процессор «ReplaceText».
Процессор «ReplaceText» заменит содержимое FlowFile, соответствующее регулярному выражению, и создаст новое содержимое FlowFile. Здесь мы используем процессор «ReplaceText» для замены каждого содержимого FlowFile, обработанного предыдущим процессором «EvaluateJsonPath», настраиваемым содержимым. Здесь пользовательское содержимое — это значение, полученное из свойств FlowFile в соответствии с «\t». Разделяйте их символами табуляции. для облегчения последующего хранения в HDFS и сопоставления таблиц Hive.
Шаги настройки следующие:
1. Создайте новый процессор «ReplaceText» и настройте процессор «PROPERTIES».
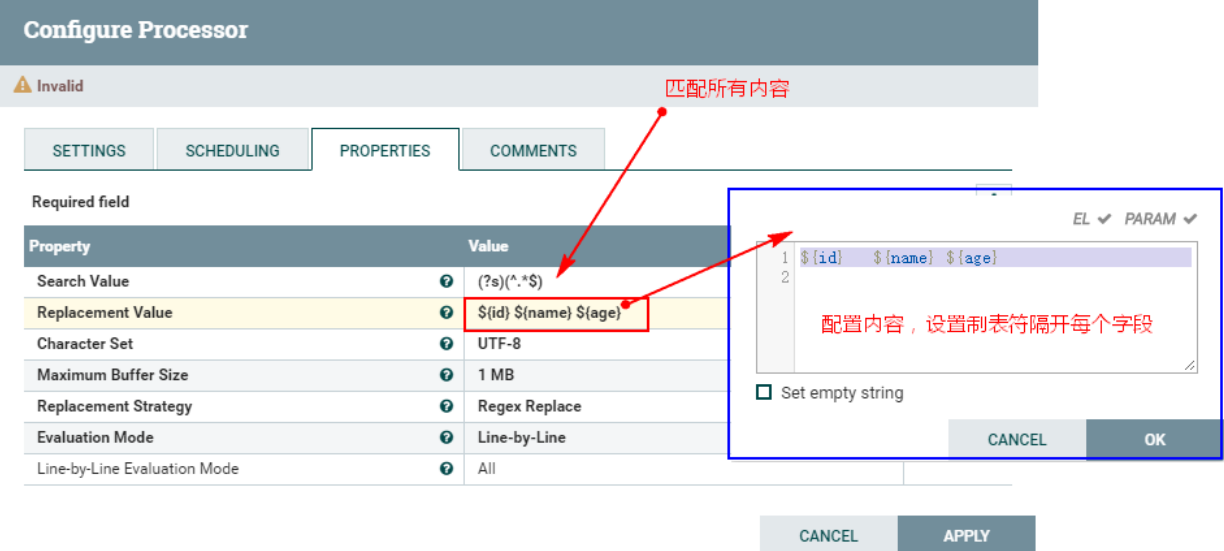
2. Соедините процессор «EvaluateJsonPath» и процессор «ReplaceText» и установите
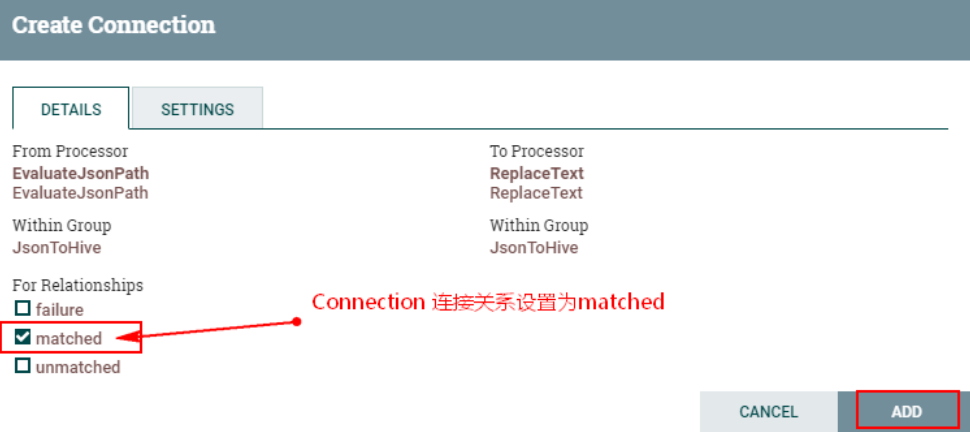
Установите отношение доставки между «сбой» и «несоответствие» в «EvaluateJsonPath» для автоматического прекращения:
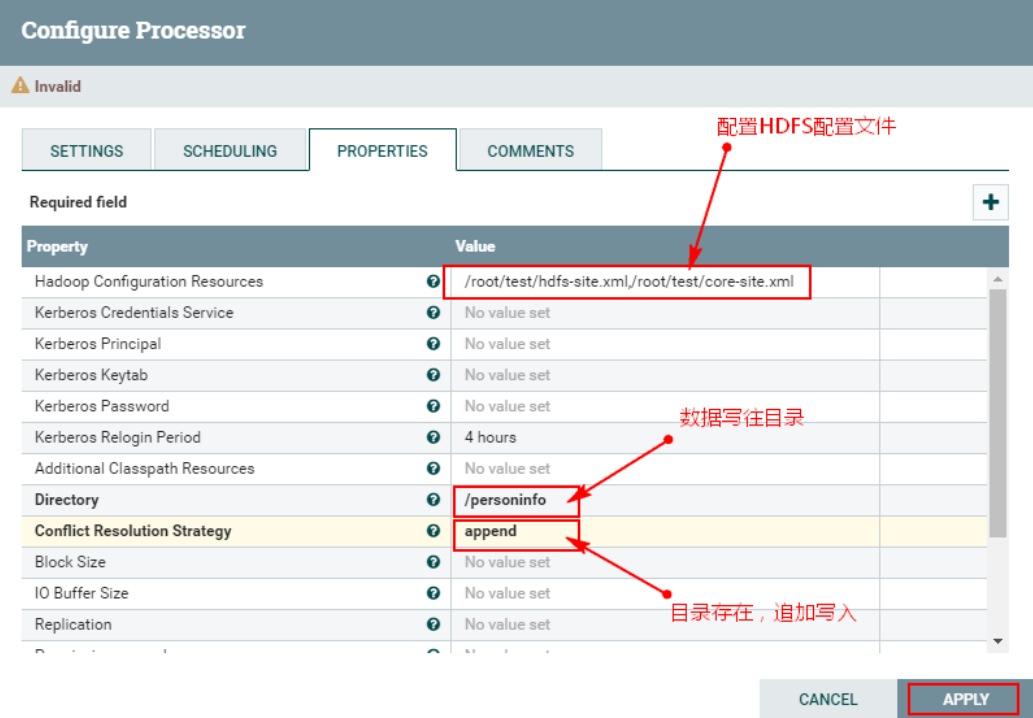
4. Настройте процессор «PutHDFS».
Здесь создается процессор «PutHDFS» для записи данных, обработанных восходящим потоком, в каталог HDFS. Шаги настройки следующие:
1. Создайте и настройте процессор «PutHDFS».
2. Соедините процессор «ReplaceText» и процессор «PutHDFS» и настройте


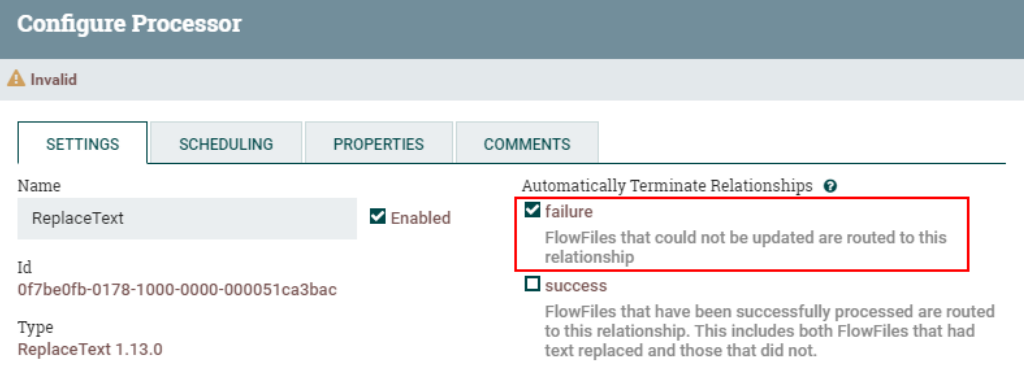
Настройте отношение передачи FlowFile при «сбое» процессора «ReplaceText» для автоматического завершения:
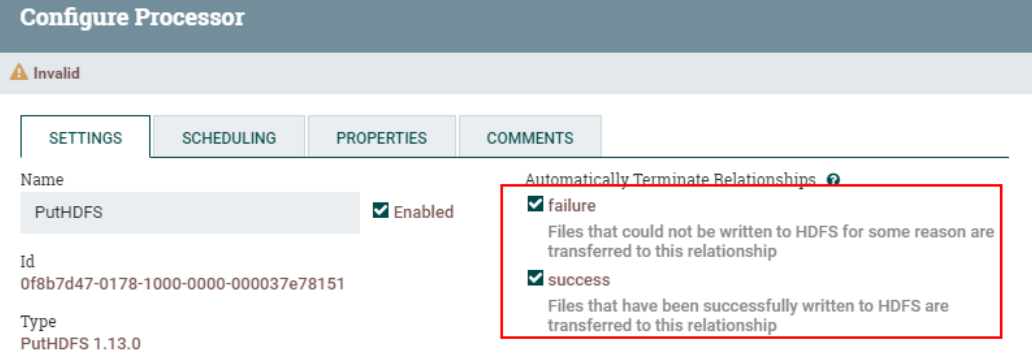
Настройте отношения доставки FlowFile для процессоров «PutHDFS» «сбой» и «успех» для автоматического завершения:
5. Запустите тест
1. Создайте внешний вид personinfo в Hive. Создайте внешний вид personinfo в Hive.
CREATE TABLE personinfo(
id int,
name string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/mycluster/personinfo'2. Запустите процесс обработки данных NiFi и обработайте данные.
Запишите следующие данные в любой файл node/root/test/jsonfile NiFi:
echo "{\"id\":1,\"name\":\"zhangsan\",\"age\":18}" >> /root/test/jsonfile
echo "{\"id\":2,\"name\":\"lisi\",\"age\":19}" >> /root/test/jsonfile
echo "{\"id\":3,\"name\":\"wangwu\",\"age\":20}" >> /root/test/jsonfile
echo "{\"id\":4,\"name\":\"maliu\",\"age\":21}" >> /root/test/jsonfile
echo "{\"id\":5,\"name\":\"tianqi\",\"age\":22}" >> /root/test/jsonfile3. Просмотрите результаты
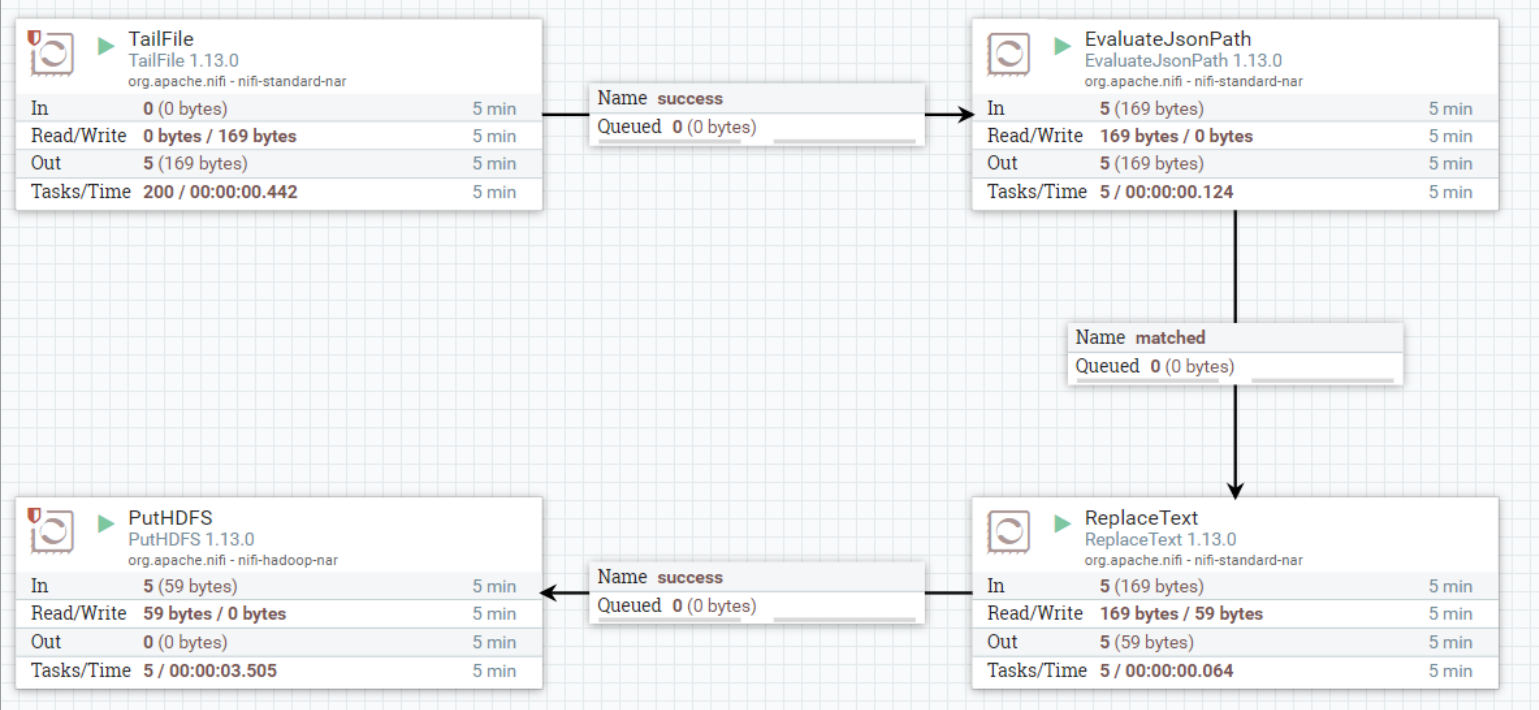
Страница Ни Фи:
Результаты в улье:
вопрос:Когда мы идем к кому-то сразуNiFiУзловой“/root/test/jsonfile”документсередина При записи данных,В настоящее время «EvaluateJsonPath» будет содержать несколько фрагментов данных JSON в FlowFile.,При получении атрибутов json,Будут получены только атрибуты, соответствующие первому json. Когда данные передаются в нижестоящий процессор «ReplaceText»,Поскольку каждая строка настроена на замену строкой в указанном формате.,В это время все строки данных в этом пакете будут заменены первой строкой данных формата JSON. Как показано ниже:

При одновременном вводе нескольких фрагментов данных в хвостовой файл мы не хотим, чтобы все строки json заменялись первой строкой json. Тогда данные, обработанные процессором TailFile, можно напрямую передать в ConvertRecord. " процессор, а данные обрабатываются с помощью json. Формат преобразуется в данные пользовательского текстового формата, а затем передается процессору "PutHDFS". Таким образом, чтобы решить вышеуказанные проблемы, мы можем повторно использовать предыдущие процессоры "TailFile" и "PutHDFS". здесь. Далее нам нужно настроить только "ConvertRecord" Только процессор.
6. Настройте процессор ConvertRecord.
«ConvertRecord» преобразует записи из одного формата данных в другой на основе настроенного устройства чтения записей и контроллера записи записей.
Описание конфигурации «Свойства» процессора «ConvertRecord» следующее:
Элементы конфигурации | значение по умолчанию | разрешенные значения | описывать |
|---|---|---|---|
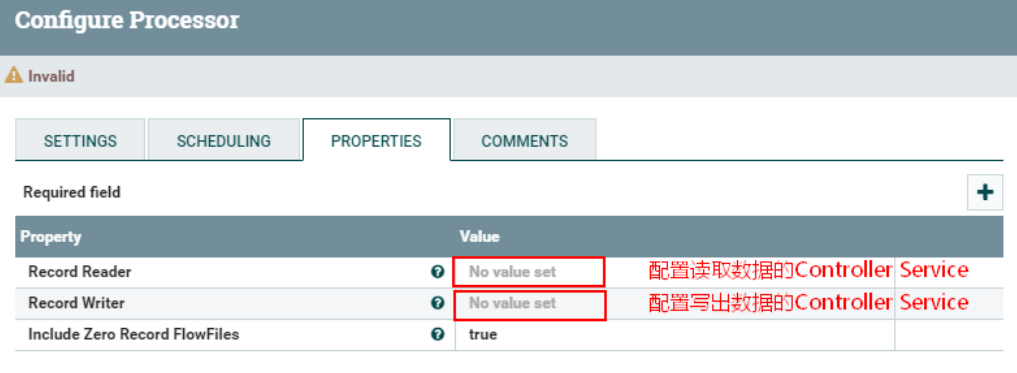
Читатель записей (считыватель пластинок) | Укажите службу контроллера, которая считывает данные. | ||
Автор пластинок (запись написана) | Укажите службу контроллера, которая записывает данные. | ||
Включить файлы FlowFiles с нулевой записью (без записанных файлов FlowFiles) | true | ▪true ▪false | Если при преобразовании входящего файла потока данные не создаются, это свойство указывает, отправляется ли файл потока в соответствующую связь. |
Шаги настройки следующие:
1. Создайте процессор ConvertRecord.
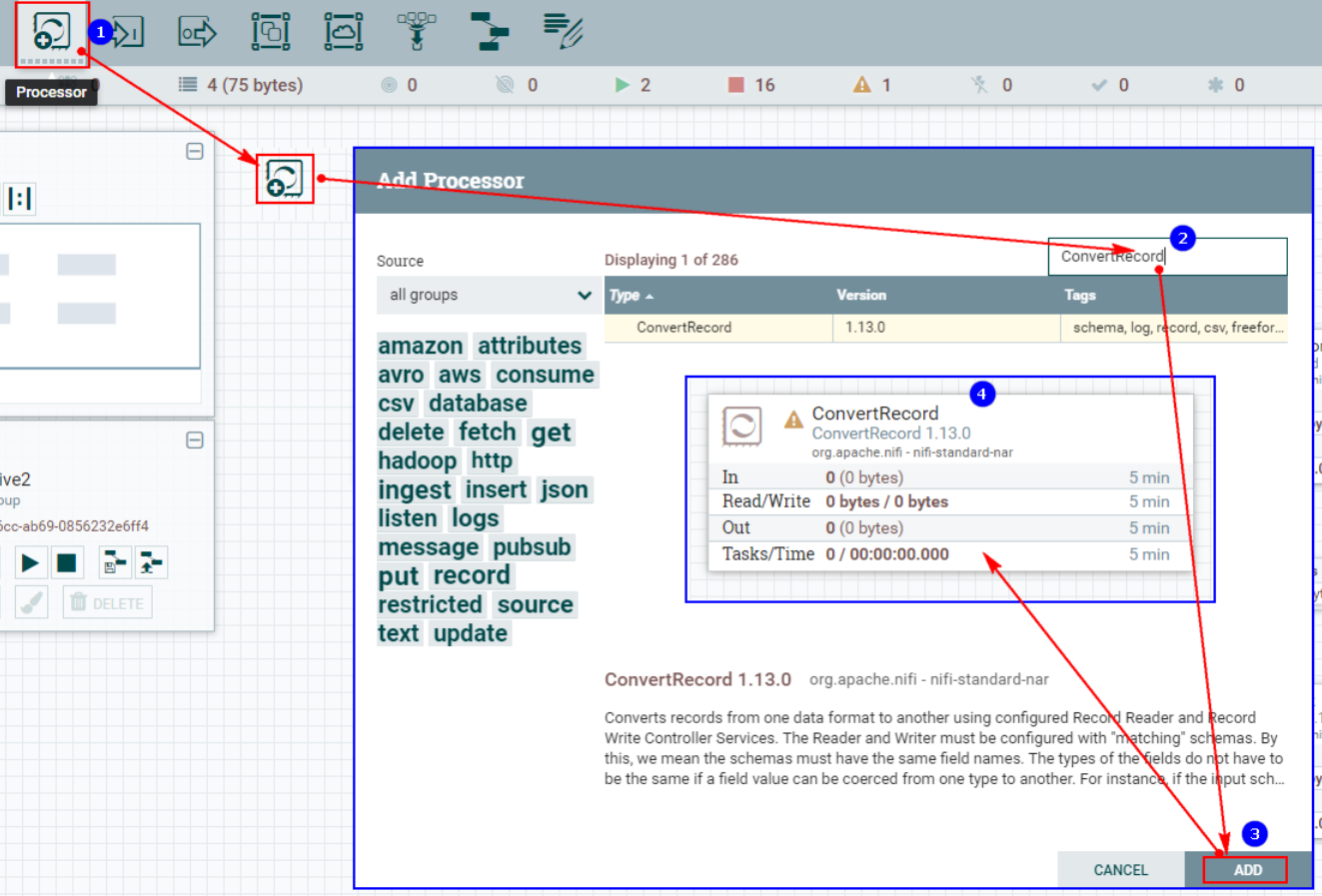
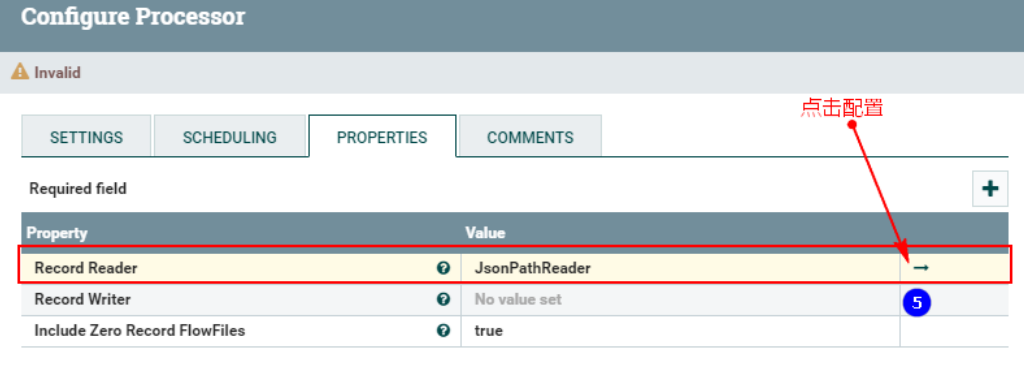
2. Настройте «СВОЙСТВА»середина“Record Конфигурация «Читатель»
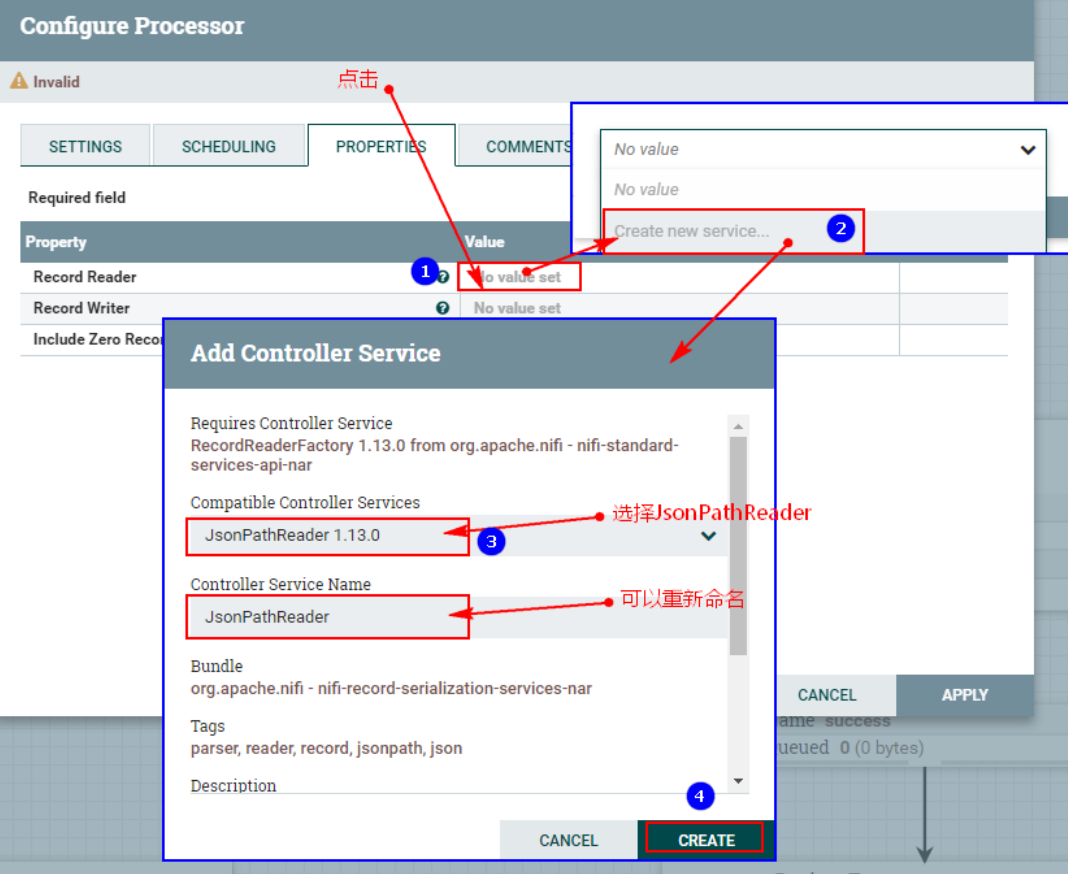
После нажатия выше введите конфигурацию:
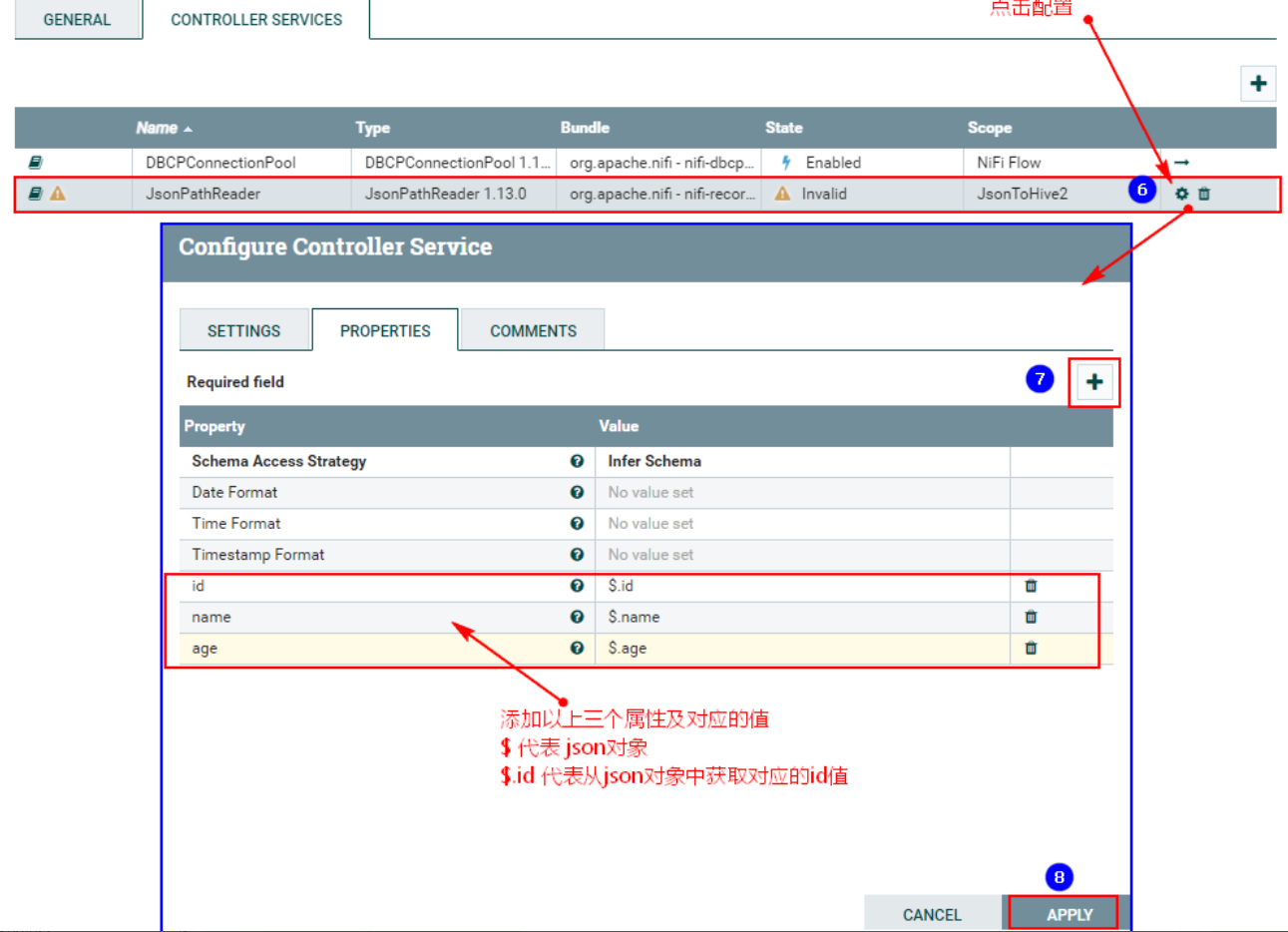
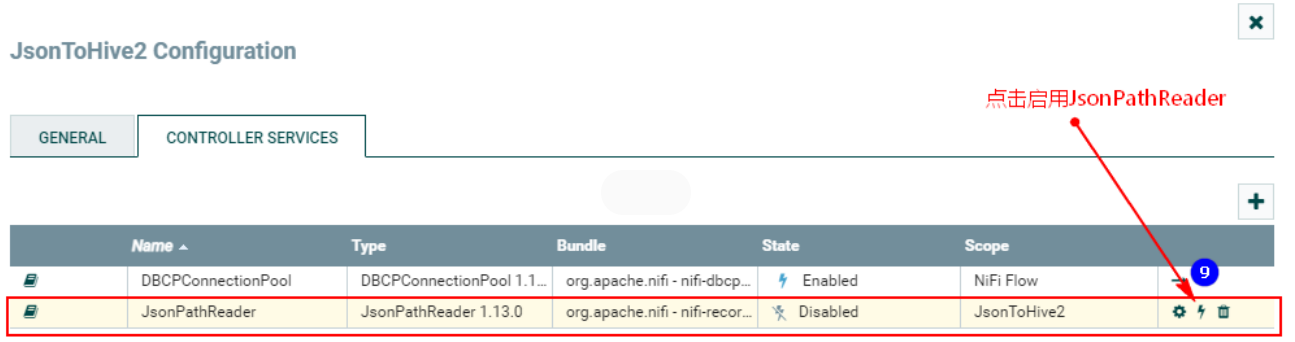
После настройки вышеперечисленного необходимо приступить к:
3. Поместите «Записывающее устройство» в «СВОЙСТВА»:
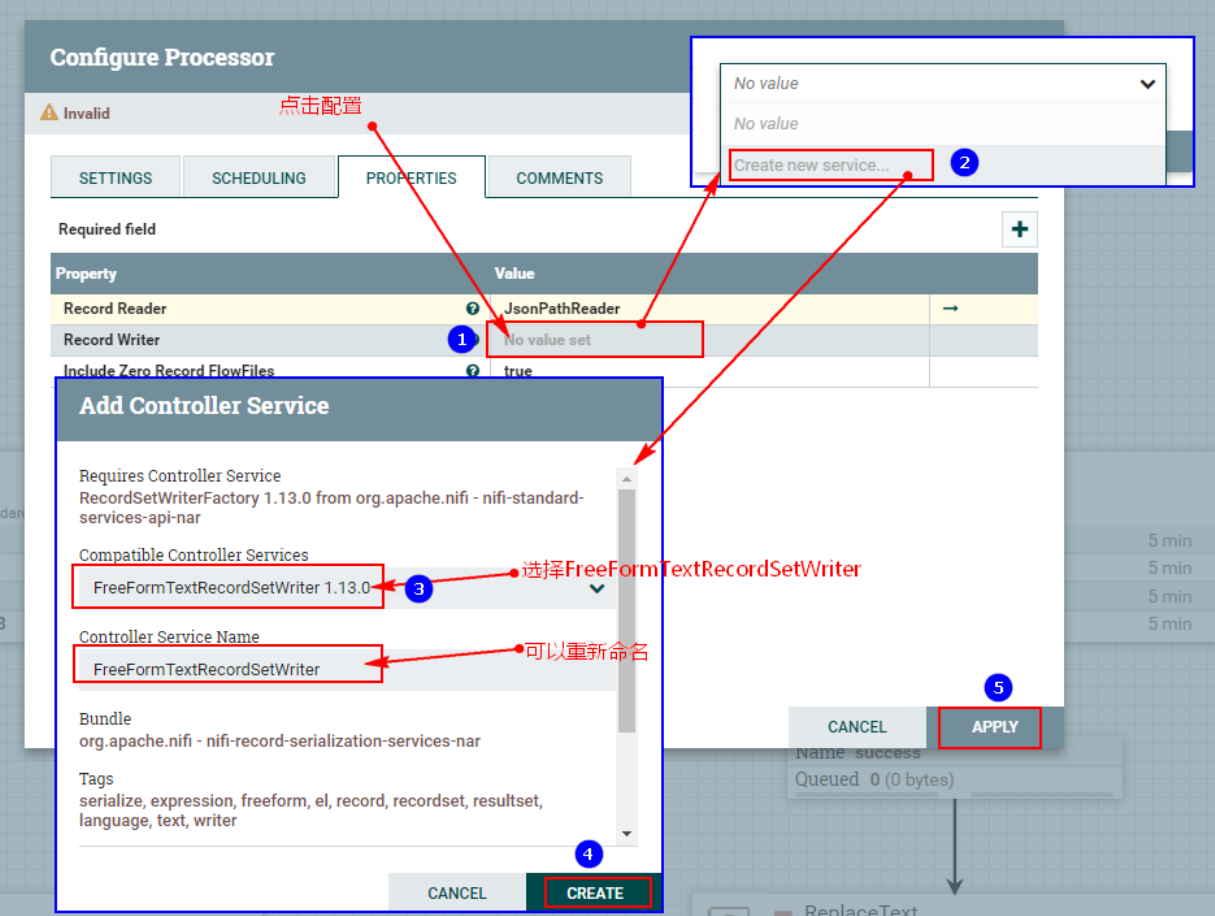
Нажмите выше, чтобы войти в конфигурацию:
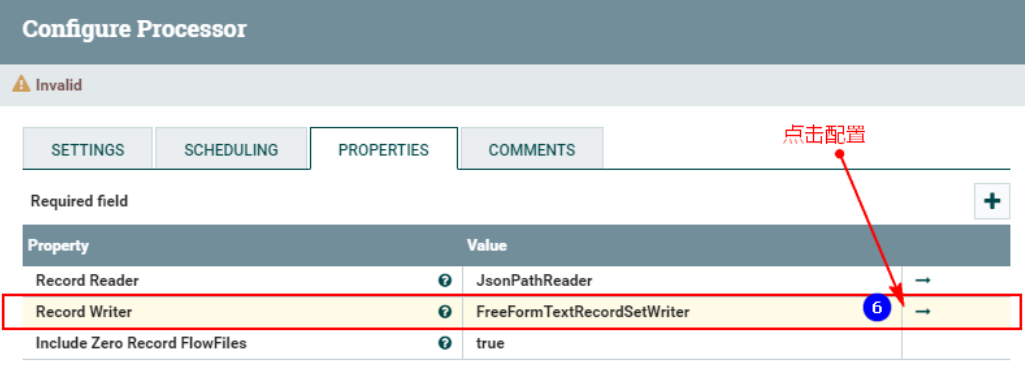
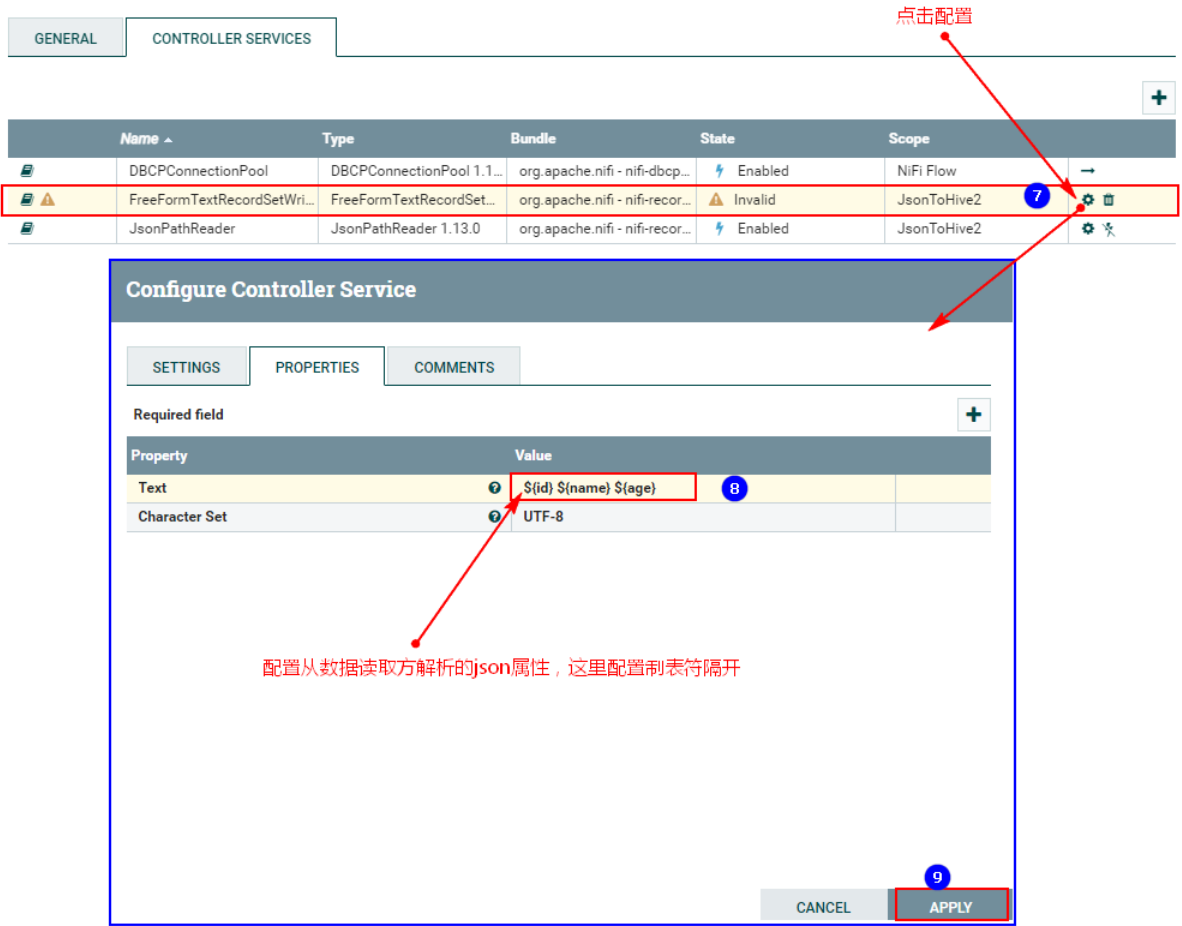
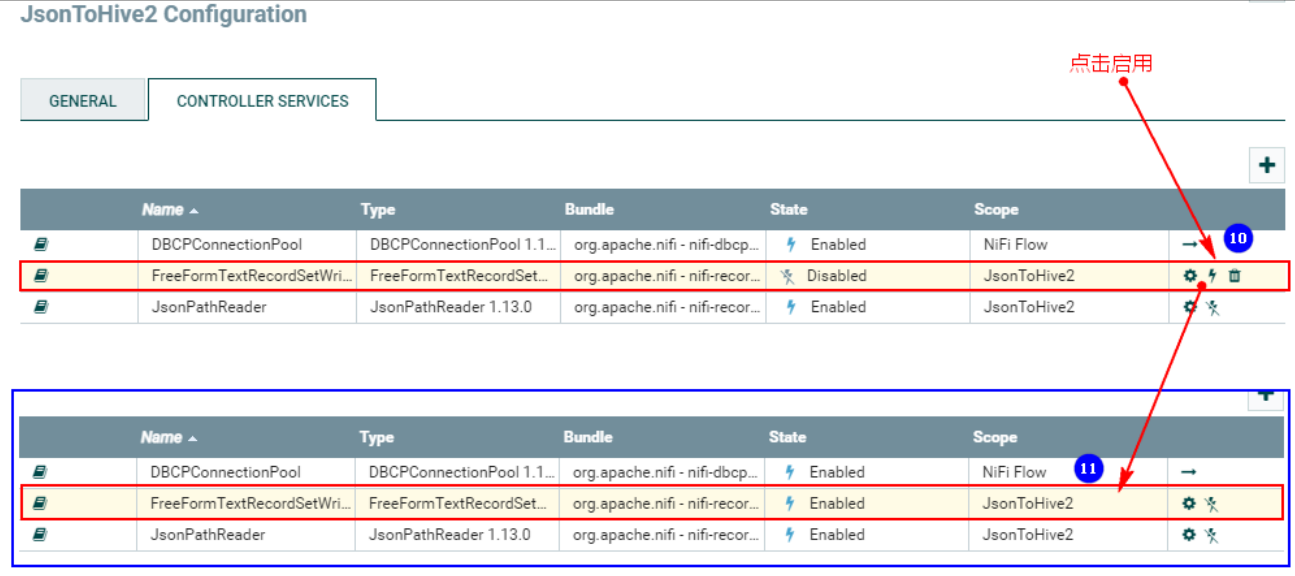
4. Соедините процессор TailFile и процессор ConvertRecord.
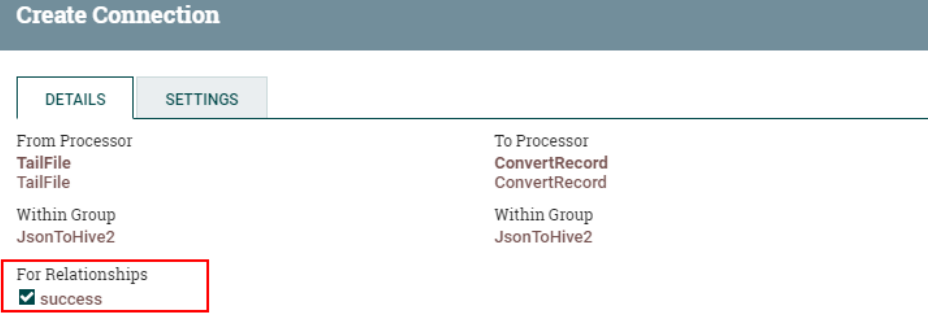
5. Соедините процессор «ConvertRecord» и процессор «PutHDFS».

В то же время установите отношение «сбой» обработки «ConvertRecord» для автоматического завершения:
7. Запустите тест
Удалите исходный путь «/personinfo» в HDFS, запустите процесс обработки данных NiFi и обработайте данные:
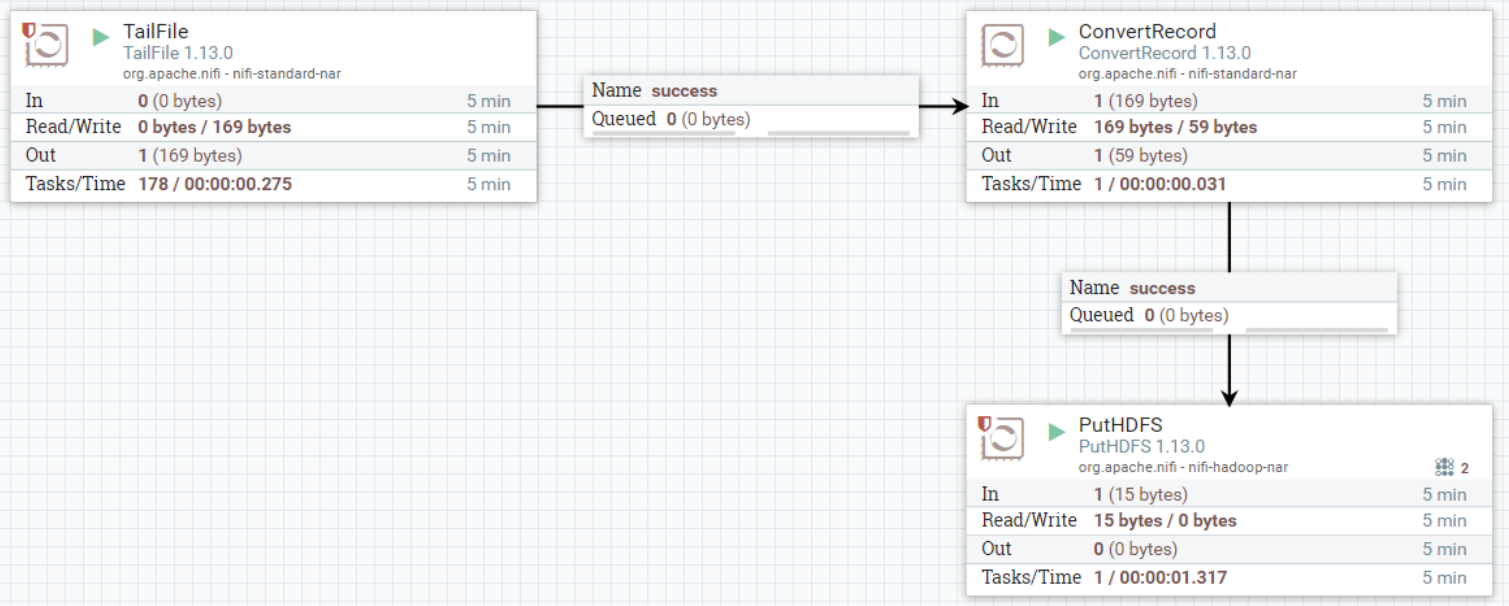
Запишите следующие данные в любой узел кластера NiFi «/root/test/jsonfile» за один раз:
echo "{\"id\":1,\"name\":\"zhangsan\",\"age\":18}" >> /root/test/jsonfile
echo "{\"id\":2,\"name\":\"lisi\",\"age\":19}" >> /root/test/jsonfile
echo "{\"id\":3,\"name\":\"wangwu\",\"age\":20}" >> /root/test/jsonfile
echo "{\"id\":4,\"name\":\"maliu\",\"age\":21}" >> /root/test/jsonfile
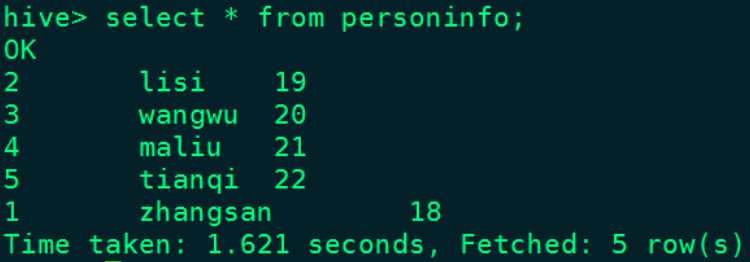
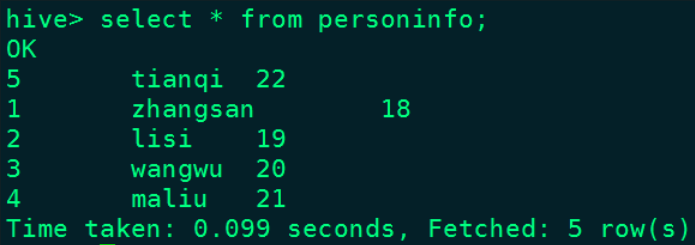
echo "{\"id\":5,\"name\":\"tianqi\",\"age\":22}" >> /root/test/jsonfileЗапросить данные personinfo таблицы Hive:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
