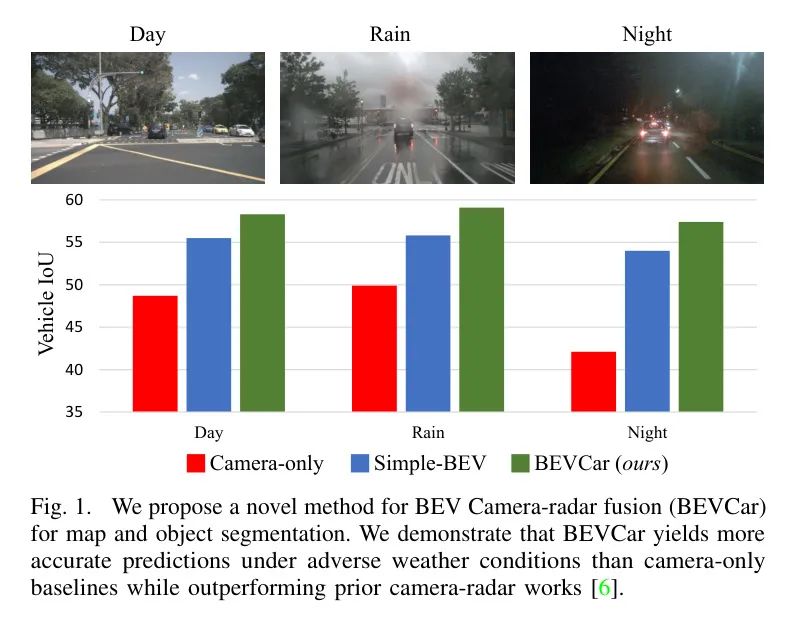
BEVCar | Слияние радаров меняет сегментацию зрения роботов ночью и в плохую погоду!

Семантическая сегментация сцены с высоты птичьего полета (BEV) играет ключевую роль в планировании и принятии решений мобильных роботов. Хотя последние методы, основанные только на зрении, позволили добиться значительного улучшения производительности, они часто плохо работают в условиях сурового освещения, например, в дождливые дни или ночью. Хотя активные датчики предлагают решение этой проблемы, высокая стоимость лидара остается ограничивающим фактором. Объединение данных камеры с автомобильным радаром является более экономичной альтернативой, но в предыдущих исследованиях ей уделялось меньше внимания. В этой работе мы стремимся продвигать это многообещающее направление исследований, представляя BEVCar, новый метод совместной сегментации целей и карт BEV. Основная инновация авторского метода заключается в том, чтобы сначала изучить точечное кодирование исходных радиолокационных данных, а затем использовать его для эффективной инициализации функций изображения, которые будут перенесены в пространство BEV. Авторы проводят обширные эксперименты с набором данных nuScenes и демонстрируют, что BEVCar превосходит современные технологии. Кроме того, авторы показывают, что объединенная радиолокационная информация значительно повышает надежность в сложных условиях окружающей среды и улучшает эффективность сегментации удаленных целей. Для облегчения будущих исследований автор приводит выше погодное разделение набора данных nuScenes, использованного в экспериментах автора, а также авторский код и модель обучения. Подпишитесь на официальный аккаунт и отправьте личное сообщение «код», чтобы получить его.
I Introduction
Мобильные роботы, такие как автономные транспортные средства, во многом полагаются на точное и надежное восприятие окружающей среды. Поэтому роботизированные платформы обычно оснащаются различными датчиками [1, 2, 3], каждый датчик предоставляет дополнительную информацию. Например, объемный просмотр обеспечивает плотные изображения RGB, тогда как лидарные или радиолокационные системы обеспечивают редкие измерения глубины. Однако, поскольку структуры этих разных модальностей по своей сути различны, объединение этих модальностей представляет собой серьезную проблему. Распространенным подходом к решению этой проблемы является принятие представления «с высоты птичьего полета» (BEV) в качестве общей структуры ссылок [4, 5, 6, 7, 8, 9]。
В то время как данные лидара и радара могут быть преобразованы непосредственно в пространство вида с высоты птичьего полета (BEV), информацию с камеры необходимо преобразовать из плоскости изображения в вид сверху. Поэтому были предложены различные стратегии повышения эффективности [4, 10, 11], которые значительно улучшают производительность только методов, основанных на зрении, а некоторые из них были расширены для объединения лидарных данных [5, 7]. Хотя лидар способен генерировать высокоточные трехмерные облака точек, его пригодность для крупномасштабного развертывания остается спорной из-за его гораздо более высокой стоимости по сравнению с автомобильным радаром. Однако слиянию камеры и радара уделяется относительно мало внимания в исследовательском сообществе и обычно изучаются только с добавлением лидарных данных [12, 8]. Напротив, радар подвергался критике как слишком редкий, чтобы его можно было эффективно использовать в автономном режиме [12].
В этой работе авторы подчеркивают ключевую роль радара в повышении надежности восприятия роботов. В частности, авторы фокусируются на сегментации целей и карты с высоты птичьего полета (BEV), подчеркивая уникальные преимущества радара в условиях окружающей среды с ослабленным зрением. Хотя в предыдущих исследованиях изучалось объединение камер и радаров для сегментации BEV, некоторые методы требуют дополнительного лидарного наблюдения во время обучения [9] или полагаются на конкретные метаданные радара [8, 6], которые могут быть недоступны для моделей разных производителей. Чтобы устранить эти ограничения, авторы предлагают новый подход, который работает независимо от этих ограничений. Архитектура BEVCar, предложенная автором, включает в себя два кодировщика для конкретных датчиков и два модуля, ориентированных на внимание, для улучшения изображения и объединения камеры и радара BEV соответственно. Затем авторы вводят объединенные функции в многозадачную головку для создания карт и карт сегментации объектов. Наш метод тщательно оценивается на наборе данных nuScenes [1] и демонстрирует, что он обеспечивает самые современные характеристики при объединении камеры и радара в сложных условиях освещения.
Основные вклады заключаются в следующем:
Авторы представляют совершенно новый BEVCar для картографирования BEV и сегментации объектов по данным камер и радаров.
- Автор предлагает новую схему улучшения изображения, основанную на внимании, которая использует редкие радиолокационные точки. Query инициализация.
- Авторы показывают, что обучение на основе радиолокационного кодирования превосходит использование примитивных данных.
- Авторы подробно сравнивают BEVCar с предыдущими работами в сложных условиях окружающей среды. Baseline Проведено сравнение и продемонстрированы преимущества использования радиолокационных измерений.
Автор обнародовал сегментацию данных «день/ночь/дождливый день», используемую в nuScenes [1], и опубликовал код и модель обучения.
II Related Work
В этом разделе авторы представляют обзор подхода «только зрение с высоты птичьего полета» (BEV) и рассматривают предыдущие подходы к восприятию на основе радара.
Восприятие BEV с помощью камеры: Текущие исследования в области восприятия BEV с помощью камеры направлены на устранение разницы в обзоре между пространством изображения и пространством BEV. Существующие методы обычно используют архитектуру кодера-декодера и включают уникальный модуль преобразования представления для обработки пространственных изменений между изображением и плоскостью BEV. В ранних работах использовались вариационные автоэнкодеры для прямого декодирования объектов в двухмерную декартову систему координат вида сверху [13]. Напротив, VPN [14] использует многоуровневый персептрон (MLP) для моделирования зависимости пространственного местоположения между изображениями и картами объектов BEV, обеспечивая глобальный охват при преобразовании представления. Роддик и др. [15] усовершенствовали эти работы, введя более явное геометрическое моделирование. В частности, они предложили пирамидальную сеть занятости, оснащенную поуровневым модулем плотного преобразования для изучения сопоставления между столбцами в представлении изображения и лучами на карте BEV. PoBEV [16] расширяет эту концепцию и дополнительно повышает производительность за счет обработки плоских и вертикальных элементов с помощью различных модулей преобразования соответственно.
Современные методы можно разделить на механизмы, основанные на подъеме сил, и механизмы, основанные на внимании. Методы повышения используют либо модуль неявного распределения глубины [10] для проецирования функций в скрытое пространство, либо модуль явной оценки глубины для генерации промежуточных 3D-выходных данных, например, для задач обнаружения объектов [17] или завершения сцены [18]. Методы, основанные на внимании, формулируют преобразование вида как последовательность-последовательность перевода из пространства изображений в вид с высоты птичьего полета (BEV). TIIM [19] применяет межплоскостное внимание между полярными лучами в пространстве BEV и вертикальными столбцами изображения и сочетает самовнимание к каждому соответствующему полярному лучу с методами, основанными на глубине, такими как LSS [10], производительность была значительно улучшена. улучшено.
Недавние разработки включают в себя методы измерения BEV с полным круговым обзором, такие как CVT [20], в котором используется преобразователь перекрестного обзора с встраиванием изученного положения, чтобы избежать явного геометрического моделирования. Напротив, BEVFormer [4] и BEVSegFormer [21] явно используют параметры калибровки камеры для моделирования геометрии и предлагают пространственный модуль перекрестного внимания, основанный на деформируемом внимании [22] для обратной проекции обзора. BEVFormer [4] также использует модуль временного внимания для временного агрегирования карт BEV на основе собственного движения транспортного средства, что представляет собой новейшую технологию обнаружения трехмерных объектов. Временная агрегация также применялась в BEVerse [11], которая расширяет существующие методы за счет добавления головок прогнозирования движения и показывает, что предлагаемая многозадачная сеть превосходит однозадачную сеть, что указывает на существование прямой передачи между задачами.
Вышеупомянутые методы часто комбинируются с новыми методами увеличения данных [23], которые учитывают различия точек зрения между изображениями и BEV путем поддержания пространственной согласованности между отдельными промежуточными вложениями. Наконец, SkyEye [24] предложил менее ограничительный подход к изучению семантических карт BEV по помеченным изображениям фронтального вида путем временной реконструкции семантических изображений. В работе авторов используются последние достижения в области монокулярного восприятия BEV и методы радиолокации для более геометрически осуществимых проекций обзора. Это достигается за счет новой схемы улучшения изображения на основе внимания с использованием Radar Query. Кроме того, авторы предлагают дополнительно упорядочить ветви, специфичные для модальности, используя существующие скелеты изображений, которые были предварительно обучены с помощью контрастного обучения.
Основы радиолокационного восприятия: Радар измеряет расстояние до цели, используя разницу во времени между передачей радиоволны и приемом ее отражения. Публично опубликованные наборы радиолокационных данных для робототехнических приложений включают в себя различные типы радаров, такие как вращающийся радар [2], автомобильный радар [1] или радар с 4D-изображением [3]. В данной работе авторы уделяют внимание автомобильному радару. Поскольку радар является относительно недорогой технологией, которая напрямую измеряет расстояние, его использовали для улучшения трехмерного обнаружения целей на основе визуального зрения. Хотя ClusterFusion [27] объединяет данные радара и камеры только в пространстве изображений, но SparseFusion3D [28] выполнили объединение датчиков как в пространстве изображений, так и в пространстве с высоты птичьего полета (BEV).
В области сегментации первоначальная работа изучала семантическую сегментацию облаков точек радара [29], которая не требовала дополнительного визуального ввода. В последнее время все большее внимание уделяется исследованиям мультимодального обзора с высоты птичьего полета (BEV) и сегментации объектов. Авторы плодотворной работы «FISHING Net» [12] предложили стратегию улучшения функций камеры на основе MLP. Чтобы объединить эти функции с радиолокационными данными, закодированными сетью, подобной UNet, FISHING Net использует пул приоритетов на основе классов. Напротив, Simple-BEV [6] обрабатывает необработанные радиолокационные данные в растеризованном формате BEV и объединяет их с характеристиками изображения, усиленными билинейной выборкой. Хотя Simple-BEV нацелен на объектно-независимую сегментацию транспортных средств, его обучение опирается на дополнительную информацию об экземплярах.
Поскольку слияние, основанное исключительно на сшивании, может страдать от плохого пространственного выравнивания, CRN [9] уделяет внимание деформированию [22] для объединения изображений и радиолокационных характеристик. Однако этот метод использует LSS [10] для улучшения характеристик изображения и требует, чтобы LiDAR контролировал глубокую распределительную сеть во время процесса обучения. Наконец, BEVGuide [8] во время развертывания не использует другие знания, кроме существующих. С помощью метода, основанного на гомографической проекции, объекты из магистральной сети изображений EfficientNet [30] преобразуются в немасштабированное нисходящее представление. Данные радара преобразуются в пространство BEV, а затем кодируются двумя сверточными слоями. В отличие от предыдущей работы, BEVGuide предлагает подход повышения эффективности «снизу вверх», получая встраивания для конкретных датчиков из унифицированных функций датчика Query в пространстве BEV, а затем объединяя их. В этой работе авторы развивают эти идеи и используют более совершенный радиолокационный кодер, вдохновленный лидарной обработкой [26]. Кроме того, авторы предлагают новую схему повышения, которая явно использует радиолокационные точки как мощное предварительное знание.
III Technical Approach
В этом разделе авторы предлагают метод BEVCar для сегментации объектов с высоты птичьего полета (BEV) и карты с камер кругового обзора и автомобильных радаров. Как показано на рисунке 2, BEVCar включает в себя два кодировщика для конкретных датчиков: один для изображения, а другой для радиолокационных данных. Автор переносит особенности изображения в пространство BEV посредством деформируемого внимания и использует данные радара для инициализации Query в процессе. После принятия стратегии промежуточного слияния авторы затем используют модуль перекрестного внимания, чтобы объединить улучшенное представление изображения с изученными функциями радара. Наконец, автор уменьшает пространственное разрешение в операции с узкими местами и использует одну многоклассовую головку для одновременного выполнения сегментации BEV на транспортных средствах и картах. В следующих подразделах авторы предоставляют более подробную информацию о каждом этапе.
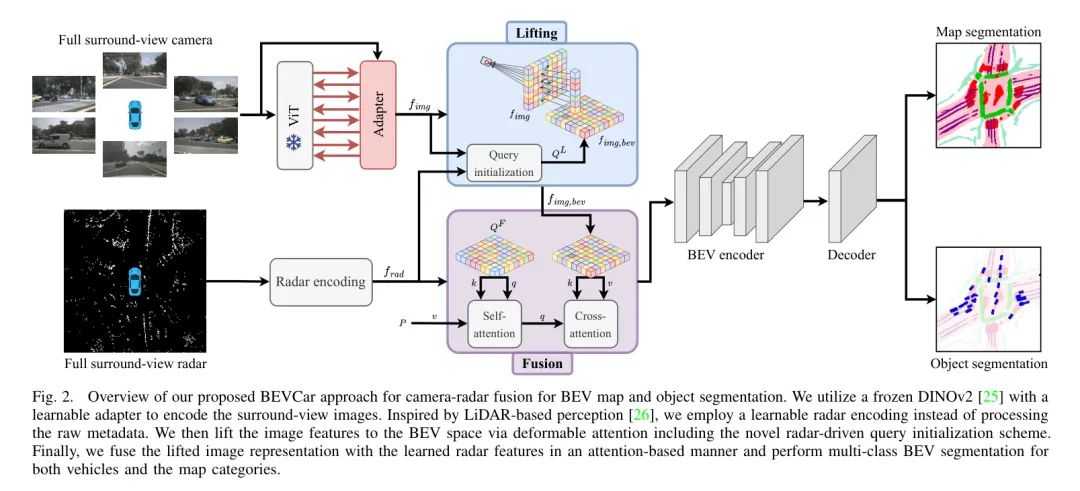
Sensor Data Encoding
Как показано на рисунке 2, авторы обрабатывают необработанные данные двух модальностей в двух независимых кодировщиках.
камера: Для кодирования данных камеры авторы использовали замороженный DINov2. ViT-B/14 [25], представление изображения которого захватывает больше семантической информации, чем скелетная сеть на основе ResNet [31]. Следуйте общепринятым методам [32, 33], авторы использовали ViT с обучаемыми весами. Adapter [34]. Чтобы охватить объемное зрение, автор каждой временной метки должен быть откуда-то.
Объедините изображения с каждой камеры, чтобы сформировать измерение
вход, где
и
Представляет изображение по высоте и ширине соответственно. Для последующей обработки адаптер ViT имеет выходные данные.
многомасштабные карты признаков каналов, эти карты признаков соответствуют

Радар: данные радара представлены облаком точек, каждая точка имеет несколько характеристик. В отличие от предыдущих работ [6, 8] авторы подчеркивают, что использование встроенной постобработки конкретной радиолокационной модели снижает общность метода. Поэтому, как и в случае с SparseFusion3D [28], авторы используют только радиолокационные точки.
Основные функции: 3D-позиционирование
, некомпенсированная скорость
и сечение радиолокационного рассеяния _RCS_, которое отражает обнаруживаемость поверхности. Вместо использования необработанных данных [6] авторы предлагают изучить радиолокационное представление, основанное на закодированных облаках точек LiDAR [26]. Во-первых, автор за основу взял радиолокационную точку размером
из Voxel Они сгруппированы по пространственному положению в сетке, что Voxel Сетка соответствует пространственному разрешению BEV и высоте дискретизации. Чтобы ограничить требования к памяти и снизить потребность в высокой плотности Voxel из предвзятости, автор содержит более
радарные точки Voxel Производится случайная выборка. Каждая точка и ее элементы затем вводятся посредством кодирования точечных объектов, показанного на рисунке 3, где FCN относится к полностью связному слою. Обратите внимание, что кодирование точечных объектов не накапливается из нескольких Voxel из информации. В дальнейшем автор рассмотрел каждый Voxel Примените максимальное объединение, чтобы получить размер
из Один собственный вектор. Наконец, автор будет Voxel Характеристики передаются на основе CNNиз Voxel космоскодированиеустройство,Сжатие объектов по высоте,ПОЛУЧИТЕ ОБЩЕЕ изRADAR BEVкодирование
。
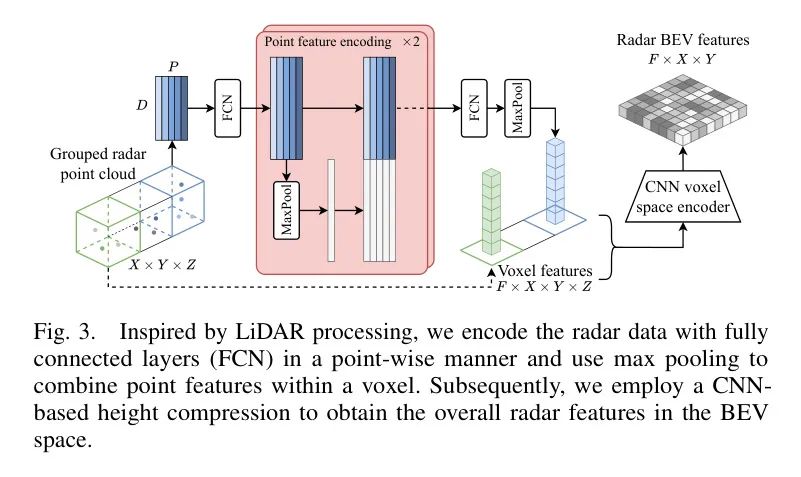
Image Feature Lifting
Автор использует метод обучения для модернизации кодирования визуальных признаков с плоскости 2D-изображения в пространство BEV. Подчиняется BEVFormer [4] Вдохновленный из, автор использовал деформируемое внимание [22], но предложил роман из Query Схема инициализации, в которой используются редкие радиолокационные точки.
Query Инициализация: предложено автором из Query Схема инициализациииз Основной мотивацией является использование радара для измеренияиз3Dинформация,Функции 2D-изображений изначально обновляются до пространства BEV. Как показано на рисунке 4.,Автор сначала создает файл размером
из Voxel пространство, которое определяется разрешением BEV
, дополнительные высокодискретизированные
А также положение лицом вперед из центра камеры определяется. Во-вторых, автор делит каждое изображение по полю зрения камеры. Voxel Назначается на одну или две камеры. В-третьих, авторы перемещают визуальные особенности из плоскости 2D-изображения в 3D посредством лучевой проекции. Voxel пространстве, то есть вдоль каждого лучевого конуса Voxel Содержит те же функции изображения. В частности, авторы использовали шкалу

особенности изображения. Если поля зрения двух камер перекроются, на автора повлияют эффекты Voxel.
Сверточный слой удаляет компонент высоты и получает
тематический канал из
Voxel Сетка. Обратите внимание, что на этом этапе особенности изображения все еще распределены равномерно и понятие глубины отсутствует. Поэтому авторы используют деформируемое внимание, управляемое редкими облаками радиолокационных точек [22], для фильтрации карт объектов, таким образом получая инициализацию Query
, его размер
。

Улучшение: на следующем этапе автор предоставит драйвер из исходного запроса.
с обучаемыми вложениями позиций
В сочетании для достижения инвариантности перестановок и изучения обучаемого вида с высоты птичьего полета (BEV) Query
[4, 6]:
Используя механизм деформируемого внимания [22], автор построил
из3D Voxel пространство для извлечения визуальных кодировок из изображений. и Query По сравнению с инициализацией авторы теперь выбирают смещения в плоскости изображения, а не в пространстве BEV. После шести каскадов Transformer После модуля автор получил итоговую карту объектов.
,Его размеры такие же, как при кодировании данных заднего радара.,Прямо сейчас
。
Sensor Fusion
Чтобы объединить характеристики усиленного изображения с кодированием данных радара, авторы использовали схему, аналогичную этапу повышения. Под влиянием TransFusion [7] Эта статья, вдохновленная лидаром Камераи для трехмерного обнаружения целей, объединена автором. Query Особенности изображения вокруг точки радара,и извлекать числовые значения посредством деформируемого внимания [22]. Аналогично уравнению (1),Автор кодированиеизRADAR данных
, можете узнать из положения кодирование
и обучается с помощью запроса с высоты птичьего полета (BEV)
Добавлено для формирования исходного запроса:
важно это,на этапе перекрестного внимания,Функции изображения Boost только в виде ключей и значений. В общем,Автор использует шесть Transformer Блок из каскада. Наконец, автор передает последний блок вывода через ResNet-18. [31] Структура узкого места обрабатывается для общего кодирования двух модальных характеристик.
BEV Segmentation Head
Автор использует один Head Выполните многоклассовую сегментацию с высоты птичьего полета (BEV). В частности, автор использует два сверточных слоя с функцией активации ReLU, за которыми следует финальный слой.
Сверточный слой для вывода целевой категории
категория карты. Принимая во внимание пространственное разрешение BEV, сегментация Head Производит размер продукции
. поэтому,Пиксель может не только одновременно фиксировать прогноз класса икарты автомобиля.,Также может быть назначен нескольким категориям карт.
Целевая сегментация: при сегментации цели,Автор рассматривает все подобные транспортные средства из сущностей,Например, легковые и грузовые автомобили. Отличается от предыдущих работ[6],Автор подчеркивает, что в процессе обучения,Независимая от цели сегментация не должна полагаться на информацию, связанную с экземпляром.,Потому что это сделает применение метода менее гибким. поэтому,Авторы контролируют целевой канал в головке сегментации только посредством потери двоичной кросс-энтропии:
В формуле
это для каждого пикселя
Определяется как:
Бинарные метки истинности
Указано количество пикселей
Принадлежит ли он к категории транспортных средств. для
из Используется соответствующая вероятность прогнозирования
выражать.
_карта сегментации:_Хотя большинство предыдущих методов [4, 8, 9] прогнозирует только дороги и иногда разделители полос, но авторы дополнительно включают такие категории, как пешеходные переходы и тротуары. Подробный список см. в разделе IV-A. Контролировать сегментацию во время обучения Head канал изкарта, автор принял
- Сбалансированная потеря фокуса в многоклассовом варианте [35]:
В этом тексте
Относится к из – семантическая категория, а
— параметр фокусировки, используемый для различения простых и сложных образцов. кроме того,
определяется аналогично согласно уравнению (4):
Имеет регулируемые параметры
Решить проблему дисбаланса между передним и задним планом.
IV Experimental Evaluation
в этом разделе,Авторы описывают экспериментальную установку,И сравнил авторский метод изBEVCar с различными Baselines. Далее автор анализирует влияние каждого компонента авторского метода.,Он также демонстрирует преимущества радиолокационных измерений по сравнению с использованием исключительно визуальных методов в неблагоприятных условиях.
Experimental Settings
Автор представляет используемый набор метрик оценки и предоставляет дополнительные детали реализации.
Набор данных и метрики оценки: авторы оценивают авторов по методу BEVCar в Сингапуре и Бостоне, штат Массачусетс и по набору данных nuScenes для автономного городского вождения [1], который является единственным общедоступным требуемым данными датчиков. GT аннотация карты изданный набор. Набор данных nuScenes включает пять автомобильных радаров и объемное зрение из шести камер RGB, а также предоставляет информацию о картах BEV. При обучении и оценке авторы используют официальное разделение обучения/валидации, которое содержит 28 130 и 6 019 образцов соответственно. Далее автор разделил сцену проверки на сцены дневного времени (4449 образцов), дождливого дня (968 образцов) и ночи (602 образца) и включил это разделение в авторский релиз. Для целевой сегментации авторы объединили все подкатегории категории «транспортные средства». Для сегментации карты авторы рассматривают все доступные категории, а именно: «зона проезда», «зона парковки», «переход», «тротуар», «стоп-линия», «разделитель дороги» и «разделитель полосы движения». Автор сообщил об индивидуальной метрике пересечения-объединения (IoU) [36], включающей эти категории, в предыдущей работе и назвал средний IoU всех категорий «картой». Чтобы меньше совмещать BEVCar с прогнозируемой категорией Baseline Для сравнения авторы указывают «транспортное средство», «проходимую площадь» и среднее значение «млн».
Детали реализации: и сопутствующие исследования[6, 8, 9] Аналогичным образом, автор сетки с высоты птичьего полета (BEV) описывает
площадь и
ячейки дискретизированы. Далее автор построил систему от земли до
Высота из верхнего и нижнего диапазона,и дискретизировать его на восемь уровней. Результирующий трехмерный тензор ориентирован относительно системы координат передней камеры как ссылка. Для обучения и вывода,Автор изменил размеры шести изображений Камераиз на
пикселей в соответствии с используемым изViT Adapter по запросу эта настройка основана на Harley et al.[6]из Анализ результатов。Опубликовано в рамках того же исследованияизкод,В качестве входных данных авторы собрали пять радиолокационных сканирований. во время тренировки,Автор будетFocal Функция потерь (см. формулу (5)) и параметры устанавливаются равными
и
。
Quantitative Results
Авторы сравнивают BEVCar с различными базовыми методами в Таблице 1. в частности,Авторы сообщают о работе метода синтеза Камера-радар.,Включает Simple-BEV [6],BEVGuide [8],иCRN [9] эти методы используют информацию о глубине от лидара во время обучения. На момент подачи свои исходники опубликовали только авторы Simple-BEViz. Автор использовал этот код для разработки расширенной версии Simple-BEV++iz, добавив задачу сегментации BEVкарты, удалив лишние данные элементов радара (см. раздел III-A) и игнорировав потерю восприятия экземпляра (см. раздел III-D). ). Чтобы продемонстрировать преимущества радиолокационного измерения, автор далее сравнивает BEVCar с базовым методом CVT, основанным только на зрении. [20],BEVFormer [4] и Simple-BEV [6] и были сопоставлены предложенные автором варианты BEVCar.
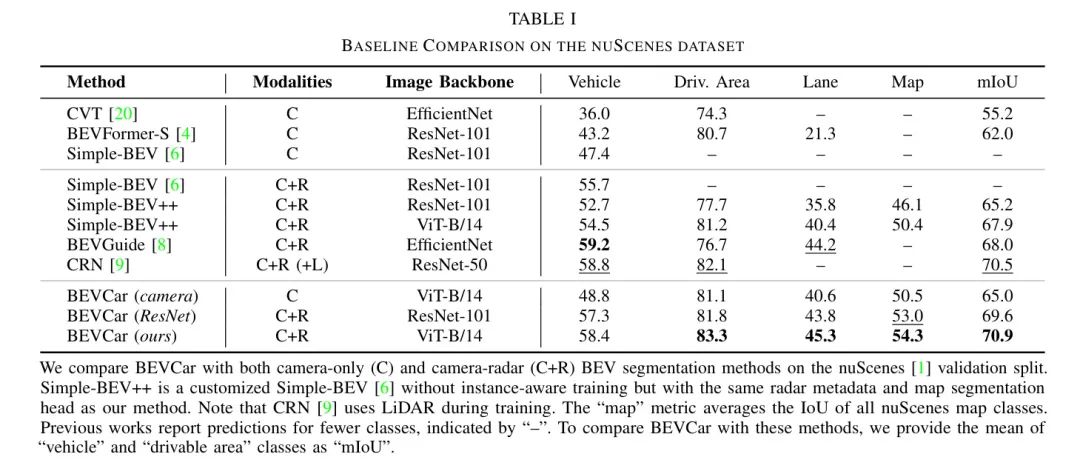
Что касается последнего, то автор использует камеру только из версии BEVCar в категории «Транспортное средство», чем Simple-BEV(C). Производительность базовой версии немного ограничена(
IoU), который также улучшен по сравнению со статической версией BEVFormerиз в категории «зона вождения» (
Ио У). Такое улучшение зрительного диапазона автор в основном связывает только с DINOv2. [25] Основа семантически обогащена представлением изображений.
Комплексная радиолокационная информация, предложенная автором метода,Результаты прогнозирования транспортных средств были существенно улучшены (IoU увеличен на +9,6).,И добились заметных улучшений в сегментации карт (mIoU увеличился на +3,8). поэтому,Авторы предполагают, что использование радара в восприятии роботов значительно улучшит производительность.,И это утверждение далее анализируется с различных аспектов в Разделе IV-C.
Для задач сегментации транспортных средств,Производительность BEVCarиз лучше, чем у Simple-BEV (на 2,7 IoU выше),Сопоставимо с BEVGuide (ниже 0,8 IoU) и CRN (ниже 0,4 IoU). О ЦРН,Важным фактором, который следует учитывать, является,Этот метод основан на использовании LiDAR на этапе обучения, чтобы научиться измерять глубину. Для сегментации карт,BEVCar предоставляет больше информации о семантических категориях и в то же время,улучшилось все Baseline метод. По комбинированной оценке двух задач BEVCar получила наивысший балл по общей производительности: на 2,9 млн выше, чем у BEVGuide, и на 0,4 млн выше, чем у CRN. Далее автор сравнивает BEVCar с упомянутым выше Simple-BEV++. чтобы устранить различия Backbone Сеть из воздействия, автор интегрировал ResNet-101 в оба метода. [13] иDINov2 ViT-B/14 [25]. Следует отметить, что многозадачное обучение Simple-BEV++ приводит к более низкой производительности, чем Simple-BEV, при выполнении задачи сегментации транспортных средств. Baseline . Хотя авторы заметили, что DINov2 Backbone Сеть также улучшает результаты Simple-BEV++из, но авторский метод изBEVCar по-прежнему использует два изображения. Backbone Сеть ResNet-101 (выше на 4,4 млн) и ВИТ-Б/14 (выше на 3,0 млн) превосходят Simple-BEV++, что доказывает инновационность авторского метода.
На рисунке 5,Автор исправляет ошибку, сравнивая BEVCar с Simple-BEV++из.,Это наблюдение подчеркнуто。Далее автор демонстрирует GT BEV нацелен на сегментацию икарты и обеспечивает только Baseline Simple-BEV++ и авторский метод визуального прогнозирования BEVCar. Подробный анализ различных погодных условий и условий освещения см. в следующем разделе.
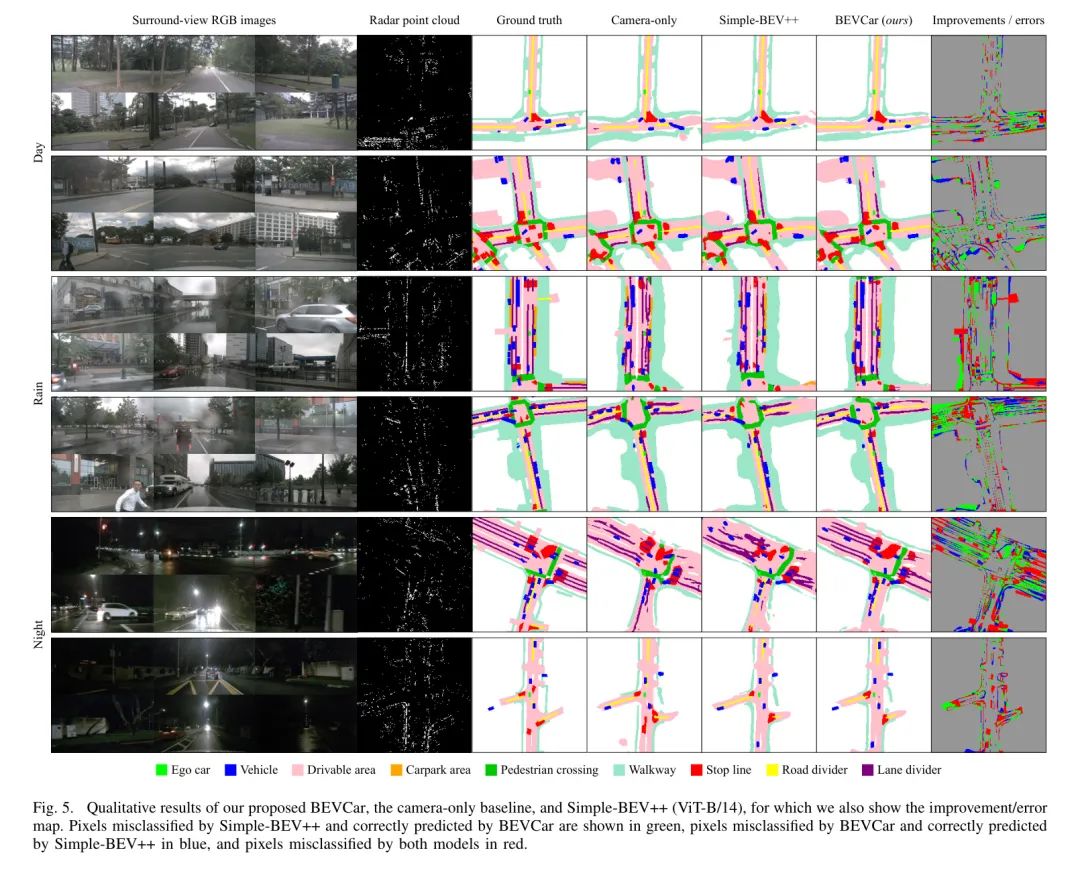
Ablations and Analysis
Для дальнейшего анализа автор предлагает метод изBEVCar.,Авторы провели абляционные исследования его компонентов.,и оценил производительность в сложных условиях по сравнению с Baseline Метод повышения производительности.
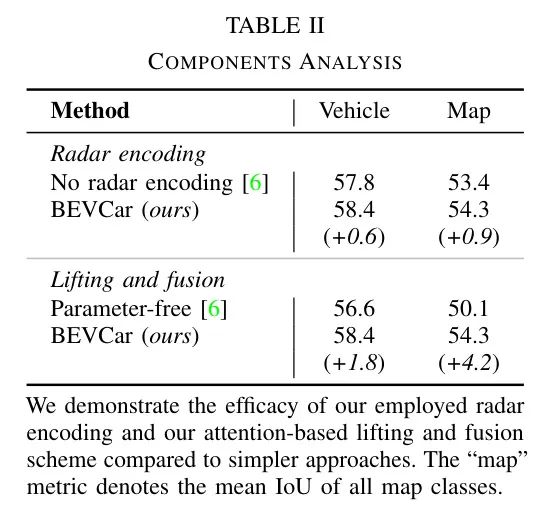
Анализ компонентов: Авторы оценили влияние двух ключевых компонентов BEV Car, а именно предлагаемого кодирования радиолокационной точки и нового драйвера радара и улучшения функций изображения, и сообщили в Таблице 2 относительно тех, на которые повлиял Simple-BEV. [6]Вдохновение из Baseline из Улучшения. Прежде всего, по сравнению с прямым использованием исходных данных радара без использования метода обучения, авторский метод достиг роста 0,6 млн и роста 0,9 млн соответственно в задаче сегментации икарты транспортного средства. Во-вторых, несмотря на Baseline использует без параметровиз将Особенности изображения提升到BEVкосмосизплан,Однако авторская схема, основанная на внимании, уже на стадии усовершенствования использовала радиолокационную информацию. по сравнению с,Это улучшает сегментацию транспортных средств на 1,8 IoU.,При сегментации карт изmIoU увеличился на 4,2.
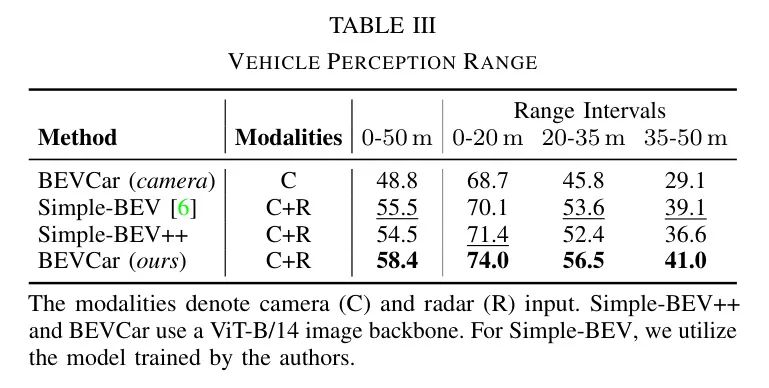
Целевая сегментация по расстоянию: В Таблице 3 авторы анализируют только вариант BEVCar, Камераиз, Simple-BEV. [6] и Simple-BEV++ обеспечивают качество сегментации транспортных средств в трех различных интервалах расстояний, включая
-
、
-
и
-
. Следует отметить, что из,После повторного запуска исходного кода автора для включения оценки исходного кода на основе диапазона,Общая производительность Simple-BEV немного ниже, чем производительность, указанная в таблице 1. Аналогично предыдущему эксперименту,Автор отмечает, что только Камераиз Baseline Имеются существенные различия в результатах при разных критериях оценки. Хотя в
-
Диапазон изIoU сравним с Simple-BEV, но в
-
в пределах досягаемости,Его производительность вдвое ниже, чем у оригинала. Хотя все методы Камера-радара по общим тенденциям схожи.,А вот эффект от BEVCarиз наименее серьезный. Суммируя,Эксперименты автора доказали, что использование радиолокационных измерений позволяет сохранить преимущество в эффективности сегментации целей на больших расстояниях.
Устойчивость к погодным условиям и свету, адаптируемость: помимо предоставления дополнительной информации,т.е. плотные изRGBданные или разреженные для измерения расстояния и скорости,Основное различие между радарами заключается в источнике энергии, используемом их соответствующими датчиками. В то время как пассивные датчики, такие как Камераиз, полагаются на внешнюю энергию,как солнце,Но активные датчики, такие как радар, обеспечивают свою собственную энергию. поэтому,Пассивные датчики страдают в сложных условиях освещения,Например, в дождливые дни или ночью. поэтому,Автор подчеркивает,Особенно в таких ситуациях крайне важно оценить автомобильные системы восприятия.,чтобы полностью понять его эффективность.
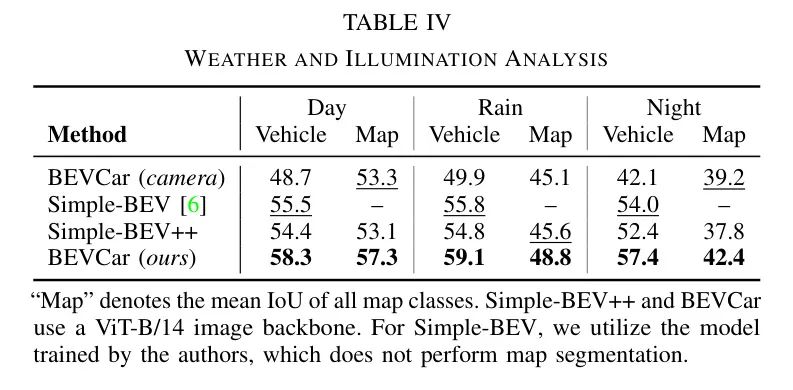
В таблице 4 и на рисунке 5 авторы сравнивают ранее сообщенный показатель BEVCariz и тот же диапазон восприятия, что и в исследовании. Baseline Делится на _день_, _дождливый_ и _ночь_. Автор отмечает, что используя только Камераиз Baseline Сегментация транспортных средств в ночное времяизIoU(коэффициент пересечения)подвергся значительной деградации。В сравнении,Все методы Камера-радара сохраняют свою работоспособность.,И BEVCar достигает высочайшей производительности. с другой стороны,сегментация карты изmIoU (среднее соотношение пересечений и объединений) падает в дождливые дни,и еще больше снижается ночью,Это касается всех методов обследования. Результаты показывают,Радар наиболее полезен для обнаружения целей,Для картирования BEV это менее важно.,Этого следовало ожидать,Потому что из пространства 2D-изображений в пространство BEV из категории плоских карт в обучении картографии,Информация о глубине не так важна, как определение параметров высоты, ширины и глубины и отображение объектов.
V Conclusion
в этой работе,Автор представил BEVCar,Решить задачу с высоты птичьего полета (BEV), сегментацию целевых карт и задачу объединения камеры и радара. BEVCar включает в себя новую систему обучения кодированию радиолокационных точек.,И раннее использование радиолокационной информации на этапе переноса визуальных функций из плоскости изображения в пространство BEV. Авторы показывают, что при совместном рассмотрении карт и сегментации объектов,BEVCar превосходит предыдущие методы применения камеры-радара. Авторы тщательно оценили производительность в сложных погодных условиях и условиях освещения.,Были проанализированы различные диапазоны чувствительности и надежность. Результаты автора наглядно демонстрируют преимущества использования автомобильного радара на основе кругового обзора. В целях содействия дальнейшим исследованиям в этом направлении,В общедоступную версию включена авторская проверка набора данных nuScenes [1] с разделением на дневное время/дождливый день/ночь. будущее,Авторы изучат вопрос устойчивости датчика в случае частичного или полного отказа датчика.,Например,Используя кросс-модальную дистилляцию во время обучения.
ссылка
[1].BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
