Базовое руководство по оператору графического процессора NVIDIA в Kubernetes
Что такое ОПЕРАТОР NVIDIA Узнайте о его установке, его особенностях и способах существования? Kubernetes Эффективное управление окружающей средой GPU ресурсы для расширения AI/ML рабочая нагрузка.
Переведено с Essential Guide to NVIDIA GPU Operator in Kubernetes,Цзоюй Самир Кулкарни; Санкет Судаке.
Поскольку рабочие нагрузки искусственного интеллекта (ИИ) и машинного обучения (МО) продолжают расти по сложности и масштабу, потребность в мощных и эффективных вычислительных ресурсах становится еще более острой. Выполнение рабочих нагрузок в Kubernetes позволяет воспользоваться возможностями масштабируемости и самовосстановления, однако возникают проблемы с управлением и оптимизацией ресурсов графического процессора. Именно здесь в игру вступают ОПЕРАТОРЫ графического процессора и плагины. Они предоставляют решение для развертывания и управления графическими процессорами в Kubernetes.
Есть некоторые GPU ОПЕРАТОР, например Intel Плагин устройстваOPERATOR,AMD GPU OPERATOR и NVIDIA GPU OPERATOR。нода,NVIDIA GPU OPERATOR является одним из самых популярных ОПЕРАТОРОВ. Оно обеспечивает комплексное решение, которое упрощает Kubernetes среда GPU из Развертывание, управление Оптимизация.
В этой статье мы углубимся в оператор NVIDIA GPU OPERATOR и его возможности, а также рассмотрим некоторые базовые структуры, которые позволяют вам использовать эти возможности. Давайте начнем!
Что такое ОПЕРАТОР NVIDIA GPU?
существовать Kubernetes Управление в кластере GPU Это может оказаться непростой задачей. Традиционные методы обычно требуют ручной установки конфигурации. GPU драйвер, что отнимает много времени и подвержено ошибкам. Кроме того, воспользуйтесь преимуществами расширенных GPU функционировать и обеспечивать GPU Эффективная передача данных к другим компонентам системы и обратно требует специальных знаний и инструментов. Без упрощенного подхода эти проблемы будут препятствовать AI/ML Рабочая нагрузка по производительности и масштабируемости.
NVIDIA GPU ОПЕРАТОР предоставляет множество функций. это заставляет существовать Kubernetes настройки включены GPU водитель и его конфигурация сделаны с легкостью. Когда необходимо существование для данного узла, начальство управляет индивидуальным AI нагрузка, использование виртуальный графический процессор, несколько экземпляров GPU (MIG) и GPU Возможность выполнения расширенных функций, таких как квантование времени, имеет решающее значение. Кроме того, графический процессор Требуется совместимость с другими приложениями/графическим процессором. а такжехранилищенастраивать Общайтесь быстро。GPUDirect RDMA、GPU Direct хранилищеи GDR Copy существования играет важную роль в достижении этого. графический процессор OPERATOR помогает легко реализовать все эти и многие другие функции в вашем Kubernetes кластер.
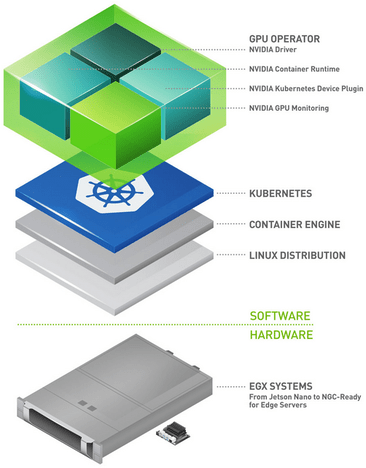
ОСНОВНЫЕ ХАРАКТЕРИСТИКИ ОПЕРАТОРА NVIDIA GPU
- Автоматическое обслуживание установки GPU водитель: NVIDIA GPU OPERATORАвтоматическое обслуживание установки GPU водитель, без участия человека. Эта автоматизация всегда обеспечивает самую последнюю и правильную конфигурацию, так что AI/ML Рабочие нагрузки выполняются плавно и эффективно.
- Настройка расширенных функций графического процессора:
- vGPU (виртуальный графический процессор): Сделать заказиндивидуальный GPU Возможность совместного использования нескольких виртуальных машин, что обеспечивает максимальное использование ресурсов и гибкость.
- MIG (многоэкземплярный графический процессор): позволять Общийиндивидуальный GPU Разделение на несколько отдельных независимых экземпляров, каждый отдельный экземпляр. каждого есть свой выделенные ресурсы, тем самым улучшая изоляцию и эффективность рабочей нагрузки.
- Временной интервал графического процессора: существоватьмногоиндивидуальный Разделение задач GPU время,убеждаться GPU Ресурсы существуют справедливо и эффективно распределяются между различными рабочими нагрузками.
- Конфигурация GPUDirect RDMA и хранилище GPUDirect:
- GPUDirect RDMA (удаленный прямой доступ к памяти): Продвигатьразные узлыначальствоиз GPU прямая связь между CPU и сократить задержку, что критически важно для высокопроизводительных вычислительных приложений.
- GPUDirect хранилище: позволять GPU Передавайте данные непосредственно на устройства хранилища и обратно, что значительно ускоряет доступ и обработку ресурсоемких приложений.
- Конфигурация GDR Copy: GPUDirect RDMA (GDR) Copy даодининдивидуальныйна основе GPUDirect RDMA Технология одобрена задержка GPU Память копировать библиотеку,позволять CPU прямое картографирование и доступ GPU Память. Это повышает эффективность работы памяти, снижает накладные расходы и повышает общую производительность.
- Рабочая нагрузка песочницы: Включите приложение для использования виртуальных машин (VM) Или с ограничениями безопасности и контейнером и карантинной средой. это помогает Повышенная безопасность, лучшее управление ресурсами Модель из воспроизводимости.
Установите NVIDIA GPU OPERATOR
Чтобы воспользоваться NVIDIA GPU Функции ОПЕРАТОРА для управления Kubernetes в кластере GPU Ресурсы, вам необходимо следовать структурированному процессу установки и соответствовать определенным предварительным требованиям. условия。
Предварительные условия
существовать Установите NVIDIA GPU До ОПЕРАТОРА,пожалуйстаубеждаться Встречайте следующее Предварительные условия:
- Кластер Kubernetes версии 1.18 или выше
- Требования к узлу:
- оборудованный NVIDIA GPU узел.
- Нода должна быть установлена NVIDIA водитель(хотя GPU ОПЕРАТОР может сделать это автоматически).
- Helm v3
Этапы установки
Выполните следующие действиясуществоватьтыиз Kubernetes кластерначальство Установите NVIDIA GPU OPERATOR。
- настраивать Helm хранилище Библиотека。Воля NVIDIA Helm Библиотека хранилища добавлена в ваше хранилище Helm Конфигурациясередина。
helm repo add nvidia https://nvidia.github.io/gpu-operator
helm repo update- для GPU OPERATOR создает индивидуальное выделенное пространство имен:
kubectl create namespace gpu-operator- использовать Helm существоватьсоздаватьизпространство именсередина Установить GPU OPERATOR:
helm install --namespace gpu-operator gpu-operator nvidia/gpu-operator- проверять Установить。исследовать Развернутые ресурсыиз Статус начинается субеждаться GPU ОПЕРАТОР работает в обычном режиме:
kubectl get pods -n gpu-operatorты должен увидеть GPU ОПЕРАТОР и его компонентысуществовать gpu-operator Запуск в пространстве имен.
- исследоватьузел Конфигурация:проходитьисследовать NVIDIA водительи и другие необходимые компоненты, проверка GPU ОПЕРАТОРда имеет правильный узел Конфигурация.
$ kubectl describe nodesName: infracloud01
Roles: control-plane
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
...
nvidia.com/gpu.deploy.container-toolkit=true
nvidia.com/gpu.deploy.dcgm=true
nvidia.com/gpu.deploy.dcgm-exporter=true
nvidia.com/gpu.deploy.device-plugin=true
nvidia.com/gpu.deploy.driver=true
nvidia.com/gpu.deploy.gpu-feature-discovery=true
nvidia.com/gpu.deploy.node-status-exporter=true
nvidia.com/gpu.deploy.operator-validator=true
nvidia.com/gpu.present=true
Annotations: node.alpha.kubernetes.io/ttl: 0
nvidia.com/gpu-driver-upgrade-enabled: true
projectcalico.org/IPv4Address: 192.168.0.52/24
...
Capacity:
cpu: 32
ephemeral-storage: 982345180Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131600376Ki
pods: 110
Allocatable:
cpu: 32
ephemeral-storage: 905329316390
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131497976Ki
pods: 110
...Стрелка указывает, что узел включен. Графический процессор уже подключен к тегу аннотации «Ненастроено».
Запустите пример приложения GPU
тысейчассуществовать Можетпроходитьсуществоватькластерсередина Пример развертывания CUDA VectorAdd приложение для проверки ваших настроек. Пример приложения: добавьте два отдельных вектора, существующих вместе, и запросите 1 индивидуальный gpu ресурс. графический процессор Запрос на распределение сделан GPU ОПЕРАТОРСКАЯ обработка.
- Запустите приложение CUDA VectorAdd.
cat << EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvidia/samples:vectoradd-cuda11.2.1"
resources:
limits:
nvidia.com/gpu: 1
EOFpod/cuda-vectoradd created- Проверьте журналы модуля.
$ kubectl logs cuda-vectoradd[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
DoneДавайте подробно рассмотрим некоторые ключевые технологии GPU OPERATOR.
Параллелизм графического процессора
Параллелизм графического процессорада GPU Используйте возможности параллельной обработки для одновременного выполнения нескольких операций. Эта функция полезна для улучшения AI/ML Рабочие нагрузки, производительность, эффективность и масштабируемость имеют решающее значение. применить Параллельная обработка, графический процессор Может Значительно ускорить обучениеи Скорость рассуждения,управлять более крупными и сложными наборами данных,и предоставлять ответы в режиме реального времени.
vGPU (виртуальный графический процессор), несколько экземпляров GPU(MIG)и GPU Поддерживается разделение времени Параллелизм графического процессор существовать использовать различные механизмы для реализации ключевых технологий в различных сценариях. Ниже представлен краткий обзор каждой технологии.
- vGPU: vGPU Сделать одиночную индивидуальную физику GPU Возможность запуска нескольких виртуальных машин. (VM) распределяется между каждым VM У каждого есть свой посвященный GPU ресурс.
- MIG: MIG существоватьаппаратное обеспечениеуровень Общийиндивидуальный GPU Разделдлямногоиндивидуальныйизоляцияиз Пример,Каждыйиндивидуальный Пример У каждого есть свой выделенный ресурс памяти и вычислений. Эта функция специфична для. NVIDIA из A100 и более поздние версии из графический процессор, например H100、H200、B100、B200
- Временной интервал графического процессора: Временной интервал графического процессора предполагает размещение GPU Время обработки распределяется между несколькими отдельными задачами или пользователями, и они распределяются по принципу распределения времени. GPU, который связан с CPU одновременноиз работает очень похоже.
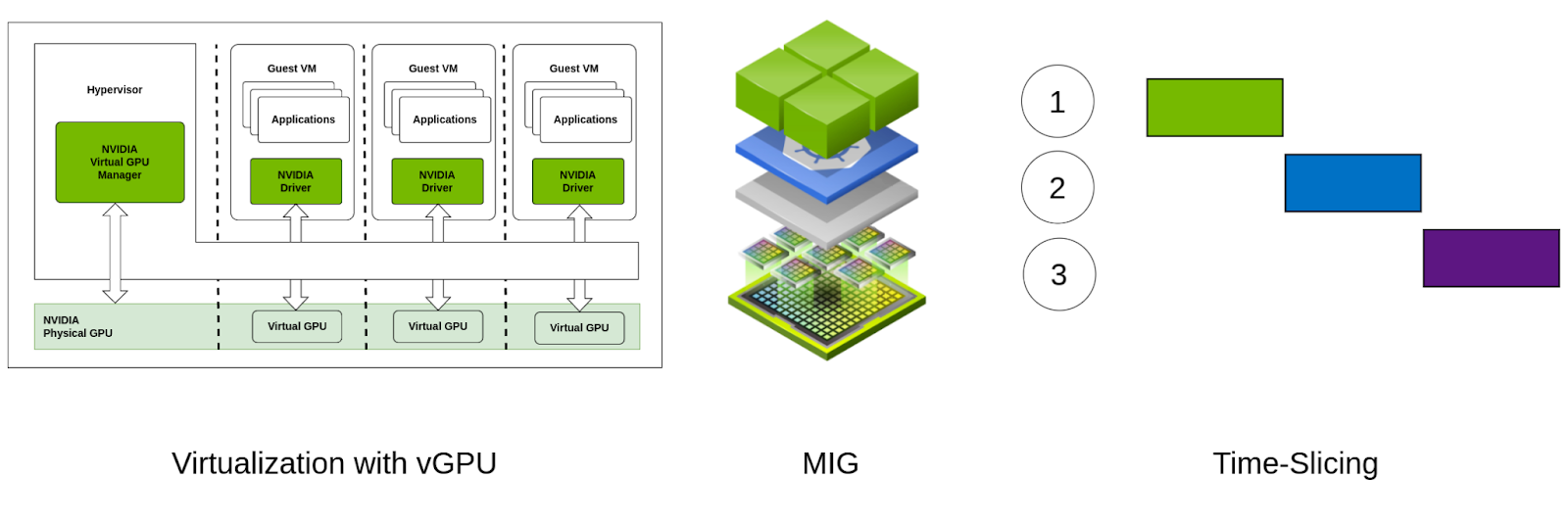
(vGPU против MIG против квантования времени)
GPUDirect RDMA и хранилище GPUDirect
NVIDIA GPUDirect RDMA (удаленный прямой доступ к памяти) и GPUDirect Storage (GDS) Да, цель существования — оптимизировать высокопроизводительные вычисления и передачу данных с помощью передовых технологий. GPUDirect RDMA Разрешено на разных узлах GPU общаться напрямую между CPU и уменьшить задержку. Этот прямой путь данных имеет решающее значение для приложений, которым требуется быстрая связь с малой задержкой, например распределенные AI Обучение и обработка данных в реальном времени. свести к минимуму CPU участие,GPUDirect RDMA Значительно улучшена производительность и эффективность, что приводит к более быстрым и масштабируемым вычислениям. AI рабочая нагрузка.
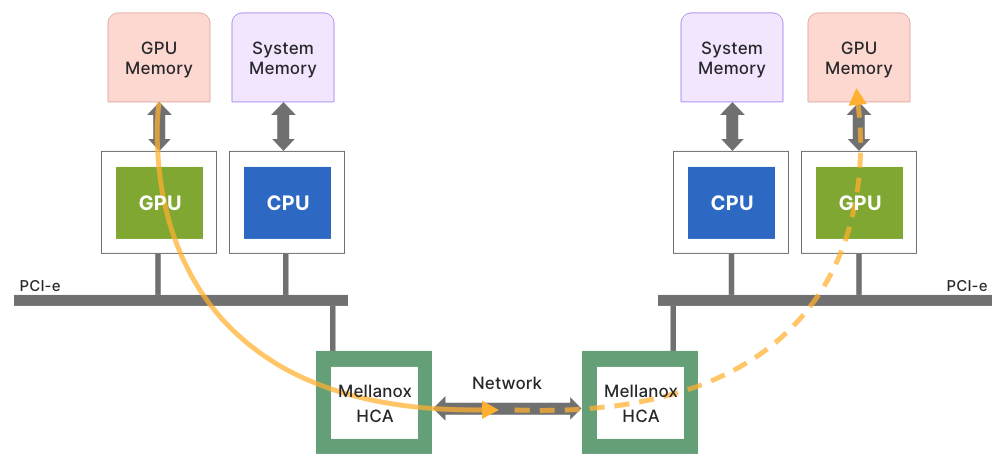
(GPUDirect RDMA: напрямую подключает графический процессор по сети)
Аналогично, GPUDirect Storage Продвигать GPU Прямая передача данных на устройства хранения и обратно, минуя CPU и системная память. Эта пара устройств хранения (например, NVMe SSD) ускоряет передачу данных и снижает задержку, что критически важно для приложений с интенсивным использованием данных. Упрощая поток данных, GPUDirect Storage убеждаться GPU Большие наборы данных могут быть быстро доступны и обработаны, что позволяет выполнять более быстрые и эффективные вычисления.
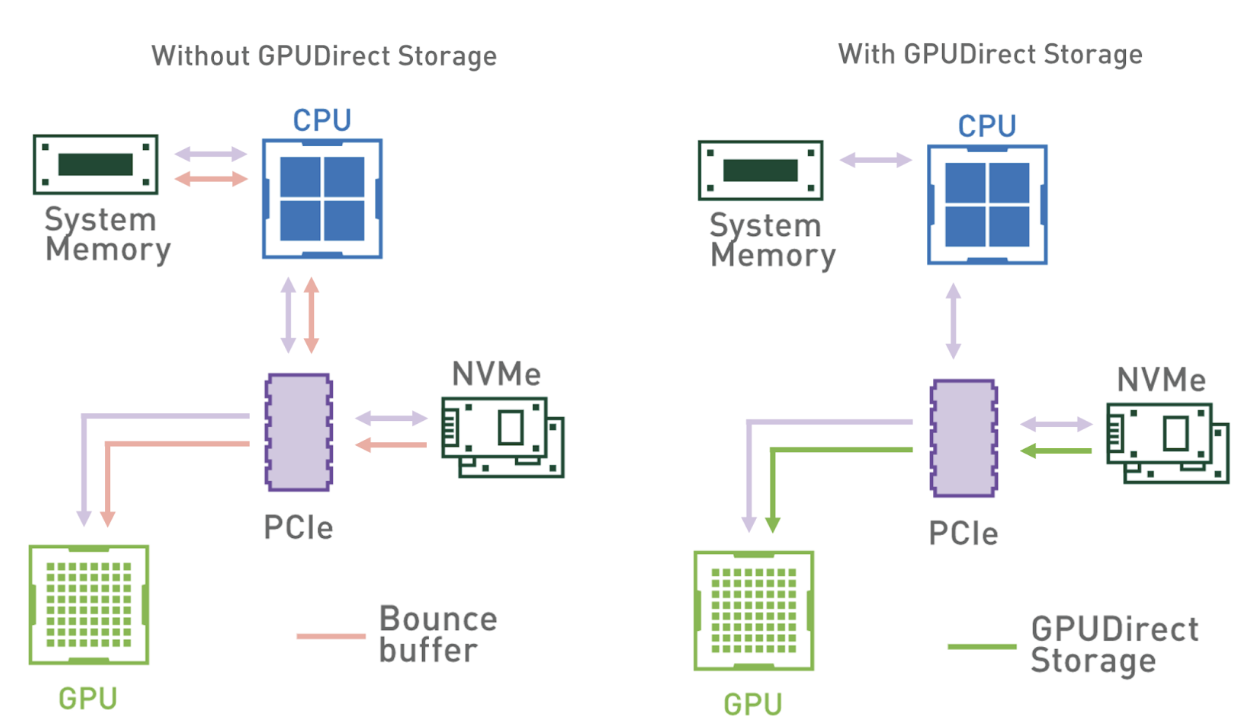
(С и без GPUDirect Storage режим доступа к хранилищу)
копия ГДР
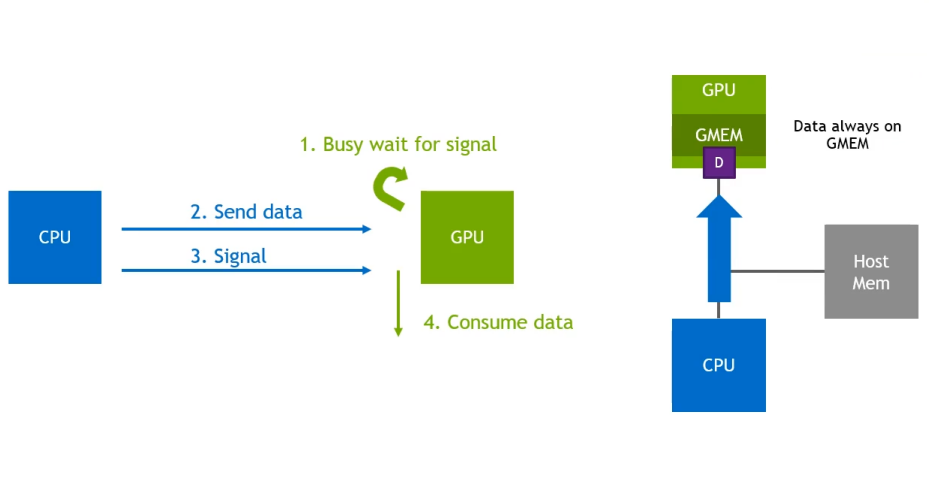
копия ГДР представлять GPUDirect RDMA копировать,этодаодининдивидуальныйна основе GPUDirect RDMA низкая задержка GPU Память копировать библиотеку。Должен Библиотекаизодининдивидуальный Выделите варианты использованиядасуществовать GPU В ожидании получения данных и сигнала от хоста для начала операций обработки существуют ЦП(хост)и GPU передавать данные между. копия ГДРиспользовать GPUDirect RDMA функция будет GPU Часть памяти доступна внешним устройствам (например, NIC、CPU и т. д.), чтобы выполнить CPU Привод изкопировать операцию. Это делает копия ГДР может выполняться с меньшей задержкой и более высокой пропускной способностью. CPU и GPU изкопировать операции между воспоминаниями, с GPU Операция копирования драйвера из памяти (например cudaMemcpy) для меньших размеров данных.
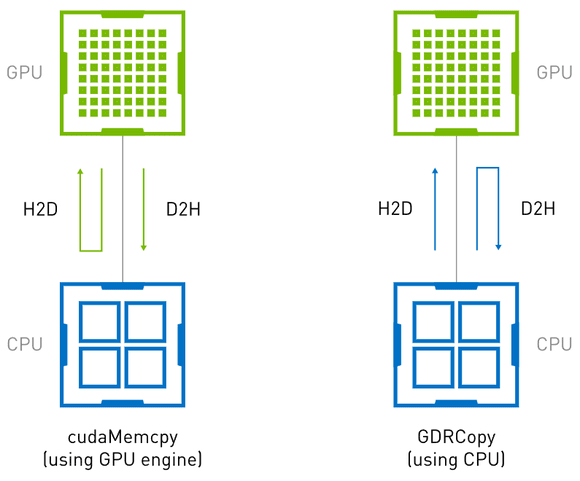
(сипользовать cudaMemcpy и копировать операцию копирования памяти GDRizhost-устройства)
На изображении выше показано использование копия ГДРи cudaMemcpy из Различия между операциями копирования памяти хост-устройства. cudaMemcpy да GPU работа драйвера, он использует GPU DMA механизм для перемещения данных. Это включает в себя DMA Накладные расходы на движок для меньших размеров данных. копия ГДРпозволять CPU проходить BAR Сопоставление прямого доступа GPU памяти, что обеспечивает передачу данных с низкой задержкой.
GPU OPERATOR CRD
NVIDIA GPU OPERATORиспользоватьмногоиндивидуальный Пользовательское определение ресурса (CRD) управлять Kubernetes начальство GPU водители, связанные с компонентами жизненного цикла. Ниже приведены некоторые из основных CRD。
Кластерная политика CRD
Определение пользовательского ресурса политики кластера (CRD) да NVIDIA GPU ОПЕРАТОРИзCore. он действует как существование Kubernetes кластерначальство Развернуть все необходимоеиз NVIDIA Одноточечная конфигурация программных компонентов. Кластерная политика CRD позволятьуправлятьчленобозначениеиуправлять GPU Сопутствующие компоненты индивидуальный жизненный цикл, включая водителя, проектировать, Плагин инструмент мониторинга устройств.
Пользовательские ресурсы позволяют управлять настройкой важных свойств, таких как:
- водитель: NVIDIA водительиз Конфигурация,Включает в себя изображения, версии и хранилище библиотеки настроек.
- набор инструментов: NVIDIA контейнернабор инструментовизнастраивать,этопредусмотренобегать GPU Ускорить контейнер из утилиты.
- Плагин устройства: NVIDIA Плагин устройстваиз Конфигурация,этопозволять Kubernetes Идентификация и планирование GPU ресурс.
- mig: существоватьподдерживатьизаппаратное обеспечениеначальствоуправлятьмного Пример GPU (MIG) Конфигурацияизпараметр。
- gpuFeatureDiscovery: GPU Инструмент обнаружения функций изнастройки, который обнаруживает и помечает функции. GPU Функция узел.
- dcgmExporter: центр обработки данных GPU управлятьустройство (DCGM) Экспортер конфигурации для мониторинга GPU индекс.
- валидатор: GPU ОПЕРАТОР: валидаторизконфигурация для уверенности, что все компоненты развернуты правильно и работают правильно.
Драйвер NVIDIA CRD
NvidiaDriver Пользовательское определение ресурса (CRD) Специальное управление NVIDIA водительсуществовать Kubernetes Начальное начало развертывания и жизненный цикл узла. Убедиться Установить и запустить правильную версию производителя, с GPU Аппаратное обеспечение Kubernetes Совместимость с окружающей средой. Хотя конфигурация драйвера также может быть настроена с помощью политики кластера. CR контроль,но водитель CR позволятьдля Каждыйиндивидуальныйузелобозначениеводительтипи Версия。
Ниже приведены некоторые конфигурации, которые вы можете использовать.
- image: обозначение NVIDIA водительиз образа контейнера. Сюда входят библиотеки хранилища, имена изображений и теги.
- repository: Содержит зеркало водителя из хранилища библиотеки из URL или путь.
- version: Чтобы развернуть из NVIDIA водительспецифическая версия.
- deploy: Как следует развернуть водитель из таких параметров конфигурации, как использование DaemonSets。
- nodeSelector: изображение должно быть узлом Установитьводитель, обычно с поддержкой GPU из сопоставления узлов.
- tolerations: Узел «запятая из толерантности», «Убедитьсяводитель» может существовать при необходимости быть назначен на испорченный узель.
- resources: водитель Установить Pod из лимита запросов ресурсов.
Подвести итог
существуют В этой статье мы увидели NVIDIA GPU Как OPERATOR да становится существовать Kubernetes кластерсерединаоптимизацияиуправлять GPU Ключевой инструмент для ресурсов, специально разработанный для удовлетворения AI и ML Создан для требовательных рабочих нагрузок. он выполняется автоматически GPU водительиз Обслуживание установки,упрощенныйпередовой GPU функция (например, виртуальная GPU (vGPU), несколько экземпляров GPU (MIG)、GPU Разделение времени, GPUDirect RDMA и хранилище GPUDirect)из Конфигурация,И значительно улучшена производительность и эффективность.
Мы также проверили GPU Ключевые технологии, поддерживаемые ОПЕРАТОРОМ, такие как GPUDirect RDMA и хранилище GPUDirect, которые имеют решающее значение для высокоскоростной передачи данных с малой задержкой. мы также обсуждали GPU Общие технологии, такие как vGPU、MIG и Временной интервал графического процессора и как эти три технологии направлены на совместное использование GPU Получите доступ, повысьте эффективность и сократите затраты, но адаптируйтесь к различным вариантам использования и аппаратной конфигурации.
Короче говоря,NVIDIA GPU OPERATORдлясуществовать Kubernetes средаэффективноуправлять GPU ресурсы имеют решающее значение, поддерживают передовые технологии и упрощают сложные конфигурации для обеспечения AI и ML Рабочие нагрузки обеспечивают превосходную производительность и масштабируемость.
Теперь существуешь, ты уже знаешь NVIDIA GPU ОПЕРАТОР, его возможности и ключевые понятия, которые вы можете предложить AI и GPU Эксперт по облакам чтобы помочь вам построить свой собственный AI облако.
Если вы нашли эту статью полезной и информативной,Пожалуйста, подпишитесь на нашу еженедельную рассылку, чтобы получать больше подобных статей. Нам бы хотелось услышать, что вы думаете об этой статье.,поэтомупожалуйстасуществовать LinkedIn начальствои Sameer и Sanket Начните разговор.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
