Автоматизация офиса с искусственным интеллектом: пакетное преобразование аудио в текст с помощью Кими
Уже существует много очень хороших приложений искусственного интеллекта для преобразования речи в текст, таких как Tongyi Listening, Feishu Miaoji и т. д. Однако для больших пакетов и нескольких папок преобразования речи в текст ручное управление более затруднительно. Однако существует программа, которую можно автоматизировать для более удобной работы.
Whisper — это библиотека распознавания речи с открытым исходным кодом, разработанная OpenAI и предназначенная для преобразования аудиоконтента в текст. Он использует модели глубокого обучения для распознавания и расшифровки речи, поддерживая несколько языков и несколько аудиоформатов. С помощью этой бесплатной библиотеки Whisper с открытым исходным кодом можно легко реализовать пакетное преобразование речи в текст.
Введите слово-подсказку в диалоговом окне кимичат:
Вы являетесь экспертом по программированию на Python и хотите выполнить задачу по написанию сценария Python. Конкретные шаги заключаются в следующем:
Откройте папку: D:\CHATGPT Для TikTok TikTok Mastery с CHATGPT
В папке есть несколько подпапок, и в них есть аудиофайлы в формате mp3. Прочитайте все аудиофайлы в подпапках;
Используйте библиотеку openai-whisper, чтобы идентифицировать аудио в формате mp3 как текстовый документ с тем же именем, что и аудио, а затем сохраните его в той же папке, что и аудио в формате mp3;
Примечание. В модели речи «шепот» используется средняя модель, а распознаваемый звук — это контент на английском языке.
Ниже приведен пример использования библиотеки openai-whisper:
import whisper
model = whisper.load_model("medium")
result = model.transcribe("audio.mp3")
print(result["text"])
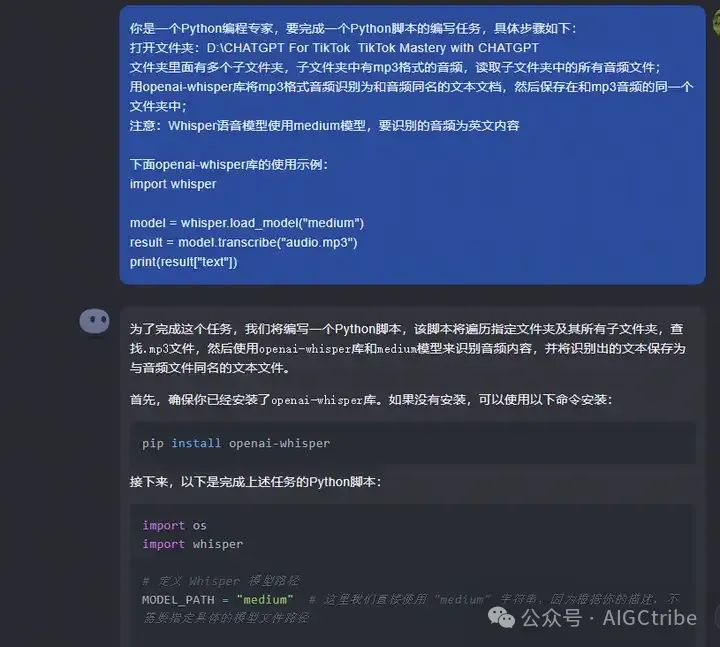
Вот исходный код Python, предоставленный Kimichat:
import os
import whisper
# Определить путь модели Whisper
MODEL_PATH = "medium" # Здесь мы используем непосредственно строку "medium", поскольку по вашему описанию нет необходимости указывать конкретный путь к файлу модели.
# Определить путь к папке аудио
AUDIO_FOLDER = 'D:\\CHATGPT For TikTok TikTok Mastery with CHATGPT'
#Инициализируем модель Whisper
model = whisper.load_model(MODEL_PATH)
# Обход всех подпапок и файлов в папке
for root, dirs, files in os.walk(AUDIO_FOLDER):
for file in files:
# Проверяем, имеет ли файл формат mp3
if file.endswith('.mp3'):
# Создаем полный путь к mp3-файлу
mp3_path = os.path.join(root, file)
# Создаем полный путь к текстовому файлу
text_path = os.path.splitext(mp3_path)[0] + '.txt'
# Используйте модель Whisper для распознавания аудио и генерации текста
try:
result = model.transcribe(mp3_path)
# Сохраняем текст в файл
with open(text_path, 'w', encoding='utf-8') as f:
f.write(result["text"])
print(f'Transcription saved: {text_path}')
except Exception as e:
print(f'Error transcribing audio from {mp3_path}: {e}')
print('Transcription process completed.')
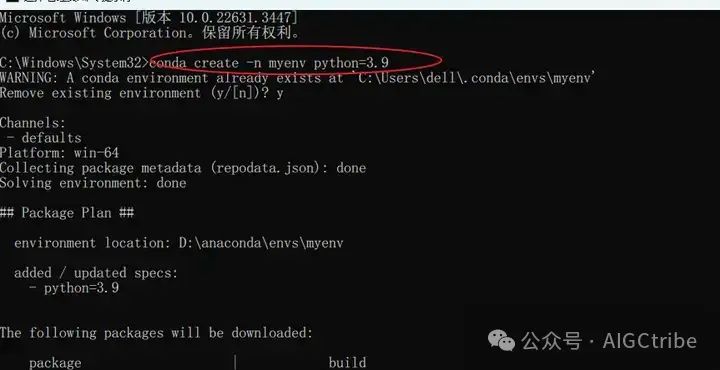
Поскольку библиотека шепота зависит от pyTorch, необходимо установить несколько других библиотек. Эти библиотеки могут конфликтовать из-за проблем совместимости версий, поэтому лучше всего использовать conda для создания виртуальной среды Python, а затем установить ее в этой виртуальной среде.
Используйте conda для создания среды Python версии 3.9: conda create n myenv python=3.9
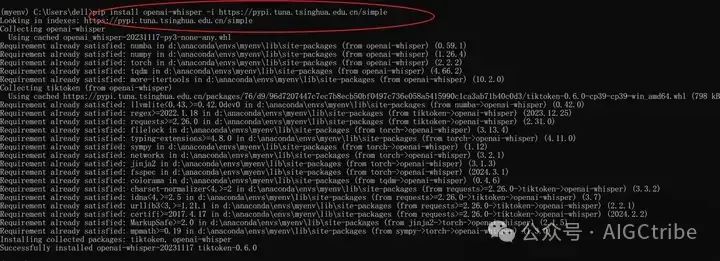
Установите библиотеку шепота в этой виртуальной среде: pip install openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple
Установите библиотеку pytorch: conda install pytorch torchvision torchaudio cpuonly -c pytorch
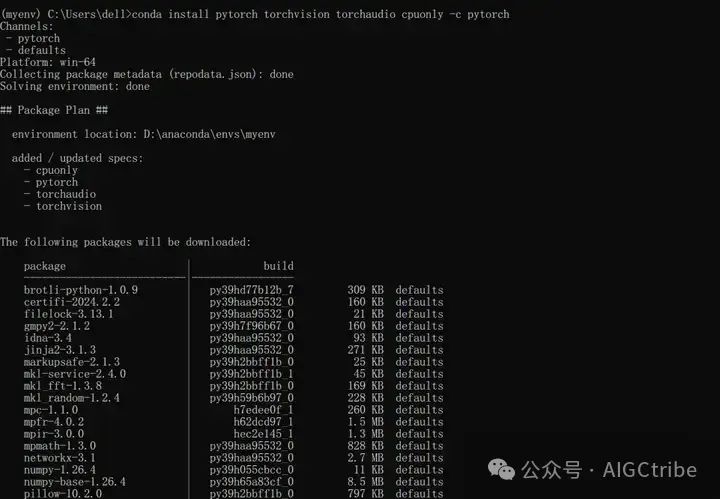
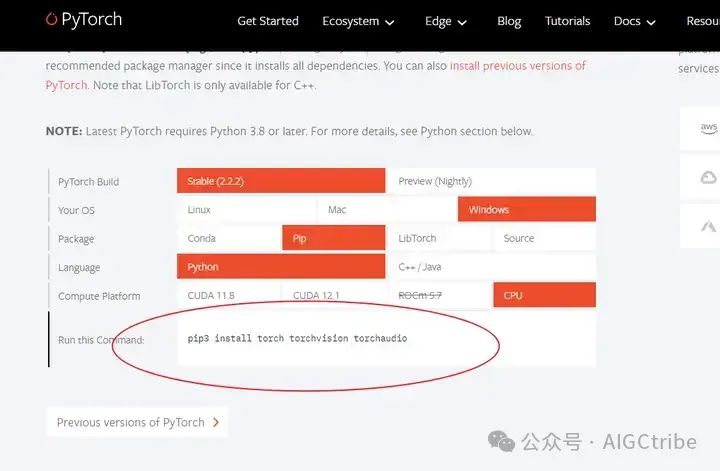
шепот будет использовать ffmpeg при обработке аудиофайлов, его также необходимо установить. Адрес загрузки: https://github.com/BtbN/FFmpeg-builds/releases. После завершения установки измените путь к папке, в которой находится ffmpeg. exe находится в системной среде. Добавьте его в переменную Path в настройках переменной.
Затем настройте виртуальную среду версии Python3.9 в vscode:
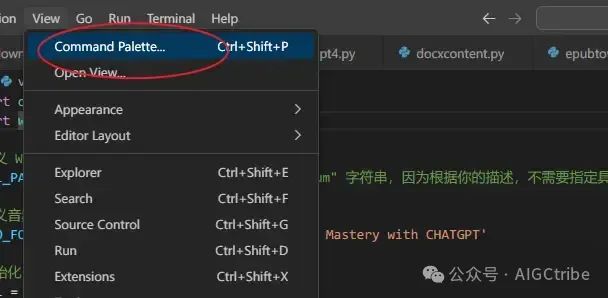
View——command palette——select interpreter——Python3.9.19
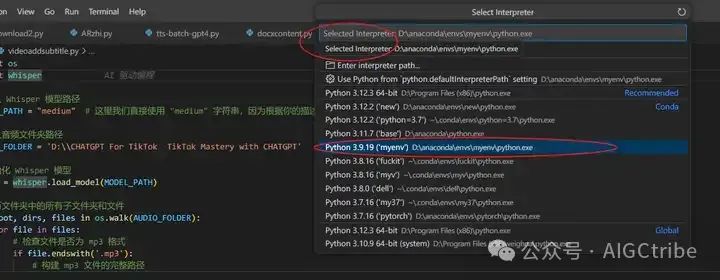
После их настройки вы можете запустить программу Python в виртуальной среде:
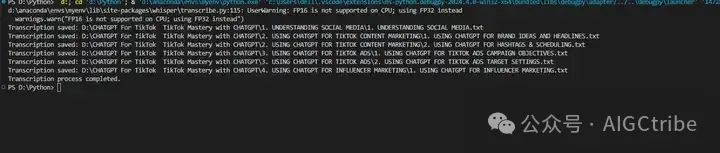
При запуске появляется предупреждение: d:\anaconda\envs\myenv\lib\site-packages\whisper\transcribe.py:115: UserWarning: FP16 не поддерживается на ЦП, вместо этого используется FP32;
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
Это предупреждающее сообщение UserWarning: FP16 не поддерживается на ЦП; вместо этого используется FP32 из-за попытки использовать числа с плавающей запятой половинной точности (FP16) для вычислений на ЦП, но ЦП не поддерживает операции FP16, поэтому он возвращается к использованию. с использованием чисел с плавающей запятой одинарной точности (FP32).
При глубоком обучении FP16 может обеспечить более высокую скорость вычислений и сократить использование памяти, но требует специальной аппаратной поддержки, например графического процессора, поддерживающего операции FP16. Если вы запускаете свой код на ЦП или графический процессор не поддерживает FP16, библиотека автоматически возвращается к использованию FP32, который является полностью совместимым, но более медленным вычислительным вариантом.
Это предупреждение обычно не влияет на работу программы, а просто указывает на то, что производительность может быть неоптимальной. Если вы хотите устранить это предупреждение, вы можете выполнить одно из следующих действий:
Используйте графический процессор с поддержкой FP16. Если у вас есть графический процессор с поддержкой FP16, убедитесь, что в вашей среде правильно установлены и настроены соответствующие драйверы и библиотеки (такие как CUDA и cuDNN). Таким образом, когда вы запускаете свой код на графическом процессоре, вы можете воспользоваться преимуществами повышения производительности FP16.
Игнорировать предупреждение. Если вы не планируете использовать оборудование с поддержкой FP16, вы можете игнорировать это предупреждение. В Python вы можете использовать библиотеку предупреждений, чтобы игнорировать определенные типы предупреждений:
import warnings
warnings.filterignore("UserWarning", message="FP16 is not supported on CPU; using FP32 instead")
Добавьте приведенный выше код в свой скрипт, чтобы игнорировать это конкретное предупреждающее сообщение во время выполнения.
Просто проигнорируйте это предупреждение, и программа будет работать нормально:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
