Audiocraft — исследовательская библиотека глубокого обучения для генерации звука ИИ на основе PyTorch.
Предисловие
В момент бурного развития ИИ появилось большое количество отличных приложений ИИ, в том числе такие мастера в области генерации текста, как ChatGPT, Клод и Вэнь Синьиян, и короли в области рисования ИИ, такие как MidJourney и StableDiffusion. По совпадению, в области ИИ-аудио ИИ Стефани Сан [1] тоже какое-то время была очень популярна, что всех обрадовало. Сегодня я хочу представить еще один популярный в последнее время проект в области AI-аудио — audiocraft[2].
Метод опыта
Без лишних слов, давайте сначала испытаем это.
Этапы опыта:
Шаг 1: Загрузите бесплатный mp3-файл на сайте mp3-ресурса [3]:
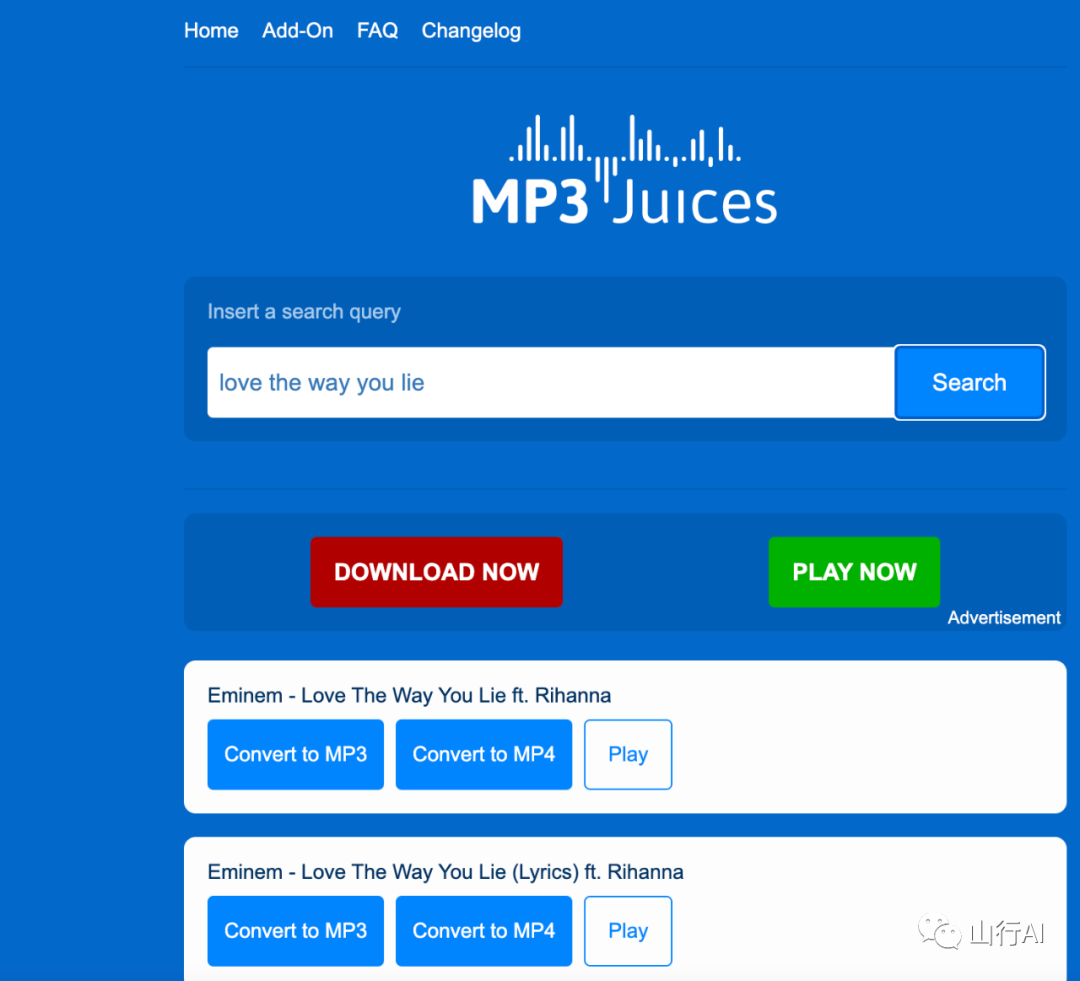
Шаг 2. Чтобы испытать это, перейдите по демо-адресу. Адрес MusicGen — a Hugging Face Space от Facebook[4].
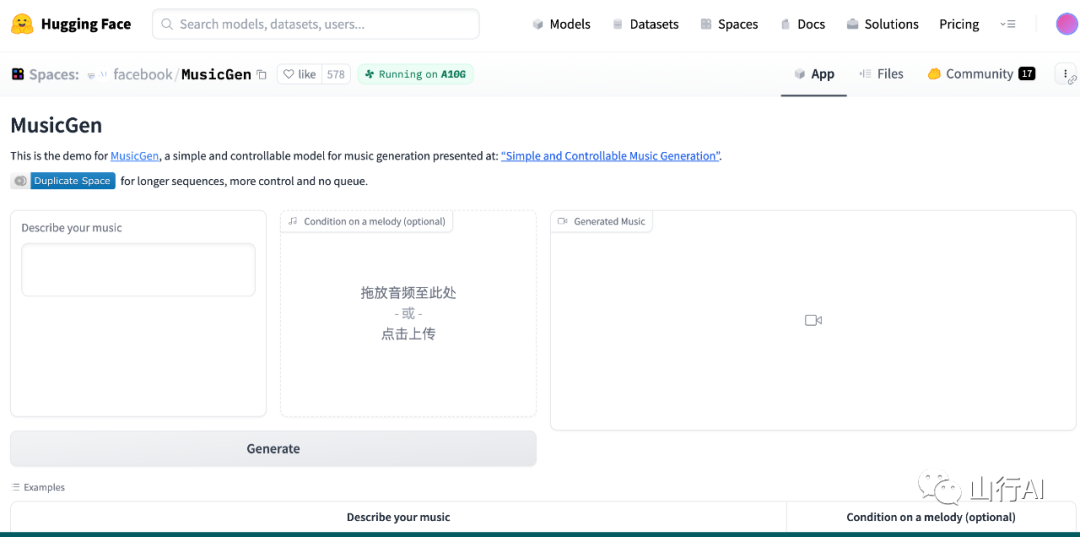
Импортируйте загруженный mp3 и описание для автоматического создания музыки:
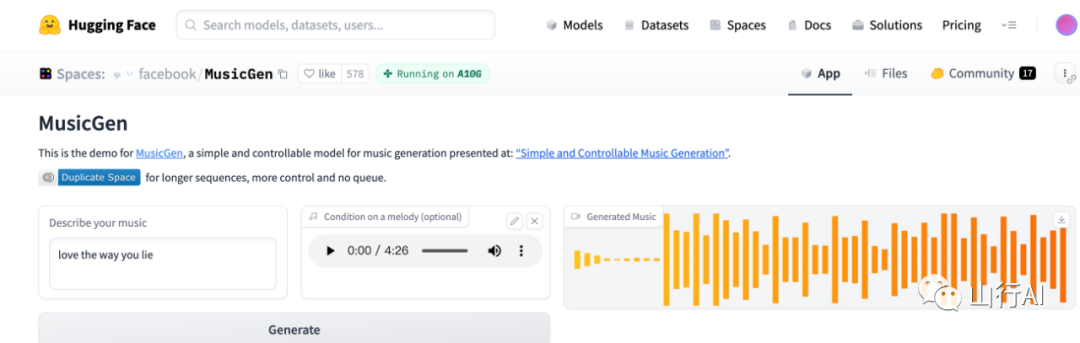
В то же время он также предоставляет множество предварительно обученных моделей, и те, кто заинтересован, могут опробовать их самостоятельно. Адрес проекта на GitHub: https://github.com/facebookresearch/audiocraft. Следующий контент переведен и скомпилирован из проекта.
Audiocraft
Audiocraft — это исследовательская библиотека глубокого обучения для генерации звука на основе PyTorch. В настоящее время он содержит код MusicGen, современной модели для управляемой текстовой генерации музыки.
MusicGen
Audiocraft предоставляет код и модель MusicGen, простую и управляемую модель генерации музыки [5]. MusicGen — это одноэтапная авторегрессионная модель Transformer, обученная с использованием токенизатора EnCodec с частотой 32 к Гц и 4 кодовыми книгами, дискретизированными с частотой 50 Гц. В отличие от существующих методов (таких как MusicLM [6]), MusicGen не требует самоконтролируемого семантического представления и может генерировать все 4 кодовые книги за один проход. Введя небольшую задержку между кодовыми книгами, мы можем прогнозировать их параллельно, так что для генерации звука потребуется всего 50 шагов авторегрессии в секунду. Посетите нашу страницу с примером[7] или протестируйте существующую демо-версию!


Для обучения MusicGen мы использовали 20 000 часов лицензионной музыки. В частности, мы полагаемся на собственный набор данных из 10 000 высококачественных музыкальных треков, а также на музыкальные данные из ShutterStock и Pond5.
Установить
Audiocraft требует Python 3.9, PyTorch 2.0.0 и минимум графического процессора с памятью 16 ГБ (для модели среднего размера). Чтобы установить Audiocraft, вы можете запустить следующую команду:
# Лучше всего сначала убедиться, что вы установили pytorch, особенно перед использованием Xformers.
# Не запускайте эту команду, если у вас уже установлен PyTorch.
pip install 'torch>=2.0'
# Затем выберите один из следующих способов проведения установки.
pip install -U audiocraft # стабильная версия
pip install -U git+https://github.com/facebookresearch/audiocraft#egg=audiocraft # последняя версия
pip install -e . # Или если вы клонировали репозиторий локальноКак использовать
Мы предлагаем несколько способов взаимодействия с MusicGen:
1.Вы можете запустить его локальноdemo.ipynb[8]изJupyter Ноутбук для работы с MusicGen или использование предоставленной совместной работы. notebook[9]。2.Вы можете сделать это, запустивpython app.pyИспользовать локальноgradio demo。3.существоватьfacebook/MusicGen HuggingFace Демо-версия также доступна на Space[10] (особая благодарность команде HF за поддержку). 4. Наконец, вы можете использовать [Colab Запуск Gradio на графическом процессоре демо[11], основано на @camenduru Colab[12] настроен.
API
Мы предоставляем простой API и 4 предварительно обученные модели. Предварительно обученные модели включают в себя:
•small:300MМодель,Поддерживает только текст в музыкуиз Конвертировать - 🤗 Hub[13]•medium:1.5BМодель,Поддерживает только текст в музыкуиз Конвертировать - 🤗 Hub[14]•melody:1.5BМодель,Поддержка текста в музыку и текст+мелодия к музыкеиз Конвертировать - 🤗 Hub[15]•large:3.3BМодель,Поддерживается только преобразование текста в музыку — 🤗 Hub[16]
мы наблюдалисуществоватьmediumилиmelodyМодель Лучший баланс между средним качеством и вычислительными возможностями。для Использовать локальноMusicGen,У вас должен быть графический процессор。Мы рекомендуем использовать16GBиз Память,Но меньшие графические процессоры могут генерировать короткие последовательности,илииспользуетсяsmallМодельгенерировать дольшеизпоследовательность。
Уведомление:существовать Используйте более новую версиюизtorchaudioчас,Пожалуйста, убедитесь, что вы установили Установить Ffmpeg[17]. Вы можете использовать следующую команду Установить:
apt-get install ffmpegВот простой пример использования API:
import torchaudio
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained('melody')
model.set_generation_params(duration=8) # generate 8 seconds.
wav = model.generate_unconditional(4) # generates 4 unconditional audio samples
descriptions = ['happy rock', 'energetic EDM', 'sad jazz']
wav = model.generate(descriptions) # generates 3 samples.
melody, sr = torchaudio.load('./assets/bach.mp3')
# generates using the melody from the given audio and the provided descriptions.
wav = model.generate_with_chroma(descriptions, melody[None].expand(3, -1, -1), sr)
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True)модель карты
См. страницу моделей карт [18]. Сейчас оно организовано следующим образом:
Детали модели
Организации, разработавшие данную модель: Meta Команда AI FAIR.
Дата модели: Дата обучения MusicGen — с апреля 2023 г. по май 2023 г.
Версия модели: Это первая версия модели.
Тип модели: MusicGen включает модель EnCodec для разметки аудио и модель авторегрессионного языка, основанную на архитектуре Transformer для моделирования музыки. Модель поставляется в разных размерах: параметры 300M, 1,5B и 3,3B, а также в двух вариантах: модель для задач преобразования текста в музыку и модель для генерации музыки на основе мелодии;
Документы или ресурсы для получения дополнительной информации: Более подробную информацию можно найти в статье Simple. and Controllable Music Найдено в поколение[19].
Цитировать Подробности: См. нашу статью [20]
лицензия: Код выпускается с использованием лицензии MIT, а вес Модели — с использованием CC-BY-NC. Выпущена лицензия 4.0.
Куда отправлять вопросы или комментарии по модели: Вопросы и комментарии о MusicGen можно отправлять через репозиторий проекта на Github [21] или поднимая проблему.
Использование по назначению
основной Использование по назначению: Основная цель MusicGen — проведение исследований по созданию музыки на основе искусственного интеллекта, в том числе:
• Исследовательские усилия, такие как изучение и лучшее понимание ограничений генеративных моделей, для дальнейшего совершенствования науки. • Создание музыки, управляемой текстом или мелодией, чтобы позволить энтузиастам машинного обучения лучше понять возможности текущих генеративных моделей искусственного интеллекта.
Основные предполагаемые пользователи: Основными предполагаемыми пользователями этой модели являются исследователи в области аудио, машинного обучения и искусственного интеллекта, а также любители, которые хотят лучше понять эти модели.
Варианты использования, не включенные в объем: Эту модель не следует использовать для последующих приложений без дальнейшей оценки рисков и мер по их снижению. Эту модель не следует использовать для намеренного создания или распространения музыкальных произведений, создающих враждебную или отчуждающую среду для людей. Сюда входит создание музыки, которая может показаться людям тревожной, болезненной или оскорбительной, а также контента, пропагандирующего исторические или текущие стереотипы.
индекс
Модельпроизводительностьиндекс: Мы используем следующий объективный индекс для оценки производительности Модели в стандартных музыкальных тестах:
• Расстояние звука по Фреше, рассчитанное на основе признаков, извлеченных из предварительно обученного аудиоклассификатора (VGGish). • Расхождение Кульбака-Лейблера при распределении меток, полученное из предварительно обученного аудиоклассификатора (PaSST). • Встраивание звука, извлеченное из предварительно обученной модели CLAP. Оценка CLAP между встраиваниями текста.
Кроме того, мы провели качественные исследования с участием людей, чтобы оценить эффективность модели в:
• Общее качество музыкального образца. • Соответствие текста предоставленному текстовому вводу. • Степень, в которой мелодия соблюдается при создании музыки на основе мелодии.
Более подробную информацию о производительности и исследованиях на людях см. в статье.
Порог принятия решения: непригодный.
Набор оценочных данных
Модель оценивается на наборе тестов MusicCaps [22] и на оценочном наборе, хранящемся в предметной области, без совпадения исполнителей с обучающим набором.
набор обучающих данных
Модель обучена с использованием лицензионных данных из: звуковой коллекции Meta Music Initiative [23], музыкальной коллекции Shutterstock [24] и музыкальной коллекции Pond5 [25]. Более подробную информацию об обучающем наборе и соответствующей предварительной обработке можно найти в статье.
Количественный анализ
Для получения дополнительной информации см. раздел «Экспериментальная установка» в статье «Простая и управляемая генерация музыки» [26].
Ограничения и отклонения
данные: Источники данных, используемые для обучения модели, созданы профессионалами в области музыки и защищены юридическими соглашениями с правообладателями. Модель была обучена с использованием 20 000 часов данных, и мы считаем, что масштабирование модели на более крупном наборе данных может еще больше повысить ее производительность.
Меры по смягчению последствий: Вокал был удален из источника данных с помощью соответствующих тегов и обработан с использованием усовершенствованного метода разделения музыкальных источников, т. е. с помощью Hybrid с открытым исходным кодом. Transformer for Music Source Separation[27] (HT-Demucs)。
предел:
• Модель не может воспроизводить реалистичные человеческие голоса. •Модель была обучена с использованием английских описаний и может работать не так хорошо на других языках, как английский. • Модель не работает одинаково во всех музыкальных стилях и культурах. • Модель иногда генерирует тихие части в конце песен. •Иногда трудно определить, какой тип текстового описания даст наилучшие результаты генерации. Для получения удовлетворительных результатов может потребоваться подсказка.
отклонение: Источникам данных может не хватать разнообразия, поскольку все музыкальные культуры неравномерно представлены в наборе данных. Модель может по-разному работать в разных музыкальных жанрах. Выборки, созданные моделью, будут отражать смещение обучающих данных. Дальнейшая работа должна включать принятие сбалансированных и непредвзятых подходов к культурному представительству, например, расширение данных обучения с учетом разнообразия и инклюзивности.
Риски и опасности: Предвзятости и ограничения модели могут привести к тому, что созданные выборки будут считаться предвзятыми, неуместными или оскорбительными. Мы считаем, что предоставление кода для воспроизведения исследования и обучения новых моделей поможет расширить приложение до новых, более репрезентативных данных.
Варианты использования: Пользователи должны знать о предвзятости, ограничениях и рисках этой модели. MusicGen — это модель, разработанная для управляемой генерации музыки для исследований искусственного интеллекта. Поэтому его не следует использовать в последующих приложениях без дальнейшего изучения и снижения риска.
Адрес статьи: arxiv[28]: https://arxiv.org/abs/2306.05284
Часто задаваемые вопросы
Будет ли опубликован обучающий код?
Это будет. Скоро мы выпустим обучающий код для MusicGen и EnCodec.
Мне нужна помощь по Windows
@FurkanGozukara снял обучающее видео для полного руководства по Audiocraft/MusicGen в Windows [29].
Цитировать
@article{copet2023simple,
title={Simple and Controllable Music Generation},
author={Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez},
year={2023},
journal={arXiv preprint arXiv:2306.05284},
}лицензия
•Код в этом репозитории выпущен с использованием лицензии MIT.,Подробности см. в файле ЛИЦЕНЗИИ [30]. •Вес модели в этом репозитории выпущен с использованием лицензии CC-BY-NC 4.0.,Подробности смотрите в файле LICENSE_weights [31].
References
[1] ИИ Стефани Сан: https://github.com/svc-develop-team/so-vits-svc
[2] audiocraft: https://github.com/facebookresearch/audiocraft
[3] Веб-сайт ресурса MP3: https://mp3juices.nu/ec6Ac7/
[4] MusicGen - a Hugging Face Space by facebook: https://huggingface.co/spaces/facebook/MusicGen
[5] Простая и управляемая модель генерации музыки: https://arxiv.org/abs/2306.05284
[6] MusicLM: https://arxiv.org/abs/2301.11325
[7] Пример страницы: https://ai.honu.io/papers/musicgen/
[8] demo.ipynb: ./demo.ipynb
[9] colab notebook: https://colab.research.google.com/drive/1fxGqfg96RBUvGxZ1XXN07s3DthrKUl4-?usp=sharing
[10] facebook/MusicGen HuggingFace Space: https://huggingface.co/spaces/facebook/MusicGen
[11] Gradio demo: https://colab.research.google.com/drive/1-Xe9NCdIs2sCUbiSmwHXozK6AAhMm7_i?usp=sharing
[12] @camenduru Colab: https://github.com/camenduru/MusicGen-colab
[13] 🤗 Hub: https://huggingface.co/facebook/musicgen-small
[14] 🤗 Hub: https://huggingface.co/facebook/musicgen-medium
[15] 🤗 Hub: https://huggingface.co/facebook/musicgen-melody
[16] 🤗 Hub: https://huggingface.co/facebook/musicgen-large
[17] ffmpeg: https://ffmpeg.org/download.html
[18] модель страница карты: ./MODEL_CARD.md
[19] Simple and Controllable Music Generation: https://arxiv.org/abs/2306.05284
[20] Наши документы: https://arxiv.org/abs/2306.05284
[21] Репозиторий на Гитхабе: https://github.com/facebookresearch/audiocraft
[22] Набор тестов MusicCaps: https://www.kaggle.com/datasets/googleai/musiccaps
[23] Meta Music Сборник инициативных звуков: https://www.fb.com/sound
[24] Музыкальная коллекция Shutterstock: https://www.shutterstock.com/music
[25] Музыкальная коллекция Pond5: https://www.pond5.com/
[26] Simple and Controllable Music Generation: https://arxiv.org/abs/2306.05284
[27] Hybrid Transformer for Music Source Separation: https://github.com/facebookresearch/demucs
[28] arxiv: https://arxiv.org/abs/2306.05284
[29] Полное руководство по Audiocraft/MusicGen для Windows: https://youtu.be/v-YpvPkhdO4
[30] ЛИЦЕНЗИОННЫЙ файл: LICENSE
[31] Файл LICENSE_weights: LICENSE_weights



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
