Архитектура больших данных: наиболее полная экосистема архитектуры больших данных во всей сети.
Введение
С развитием индустрии больших данных сопутствующие технологии в экосистеме больших данных также постоянно совершенствуются. Автору посчастливилось лично испытать процесс развития отечественной индустрии больших данных с нуля до одного. надеемся помочь каждому быстро построить экосистему больших данных.
Основные технологии в современной экосистеме больших данных обобщены, как показано на рисунке 1, и разделены на следующие 9 категорий, которые представлены ниже.
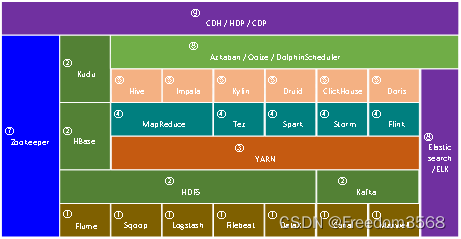
1. Структура технологии сбора данных
Сбор данных также известен как синхронизация данных.
С развитием таких технологий, как Интернет, мобильный Интернет и Интернет вещей, были созданы огромные объемы данных. Эти данные разбросаны повсюду, и нам нужно объединить эти данные, а затем вычислить ценный контент из этих огромных данных. Первый шаг, который вам нужно сделать на этом этапе, — это собрать данные. Сбор данных — основа больших данных. Без сбора данных не бывает больших данных!
Существует несколько технологий сбора данных.
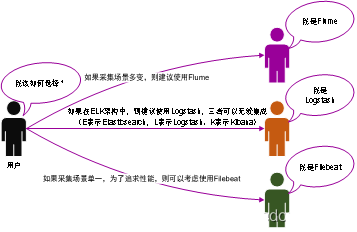
- Flume и LogstashиFileBeat часто используются для мониторинга и сбора логов в реальном времени.,Подробные различия между ними показаны в Таблице 1;
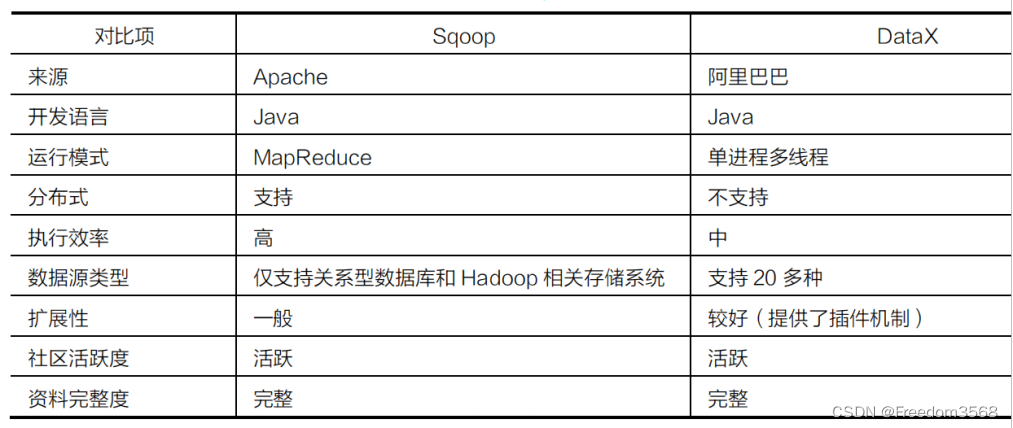
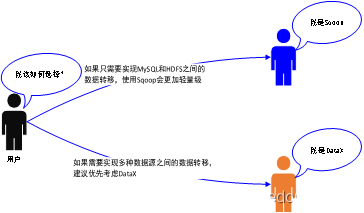
- SqoopиDatax часто используется для автономного сбора данных из реляционных библиотек данных. Подробные различия между ними показаны в Таблице 2;
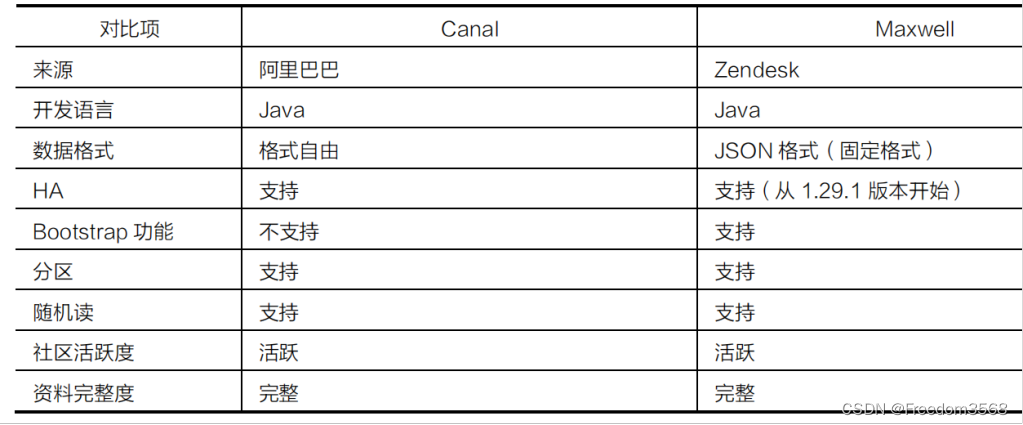
- CannalиMaxwell часто используется для сбора библиотек реляционных данных в реальном времени.,Подробные различия между ними показаны в Таблице 3.
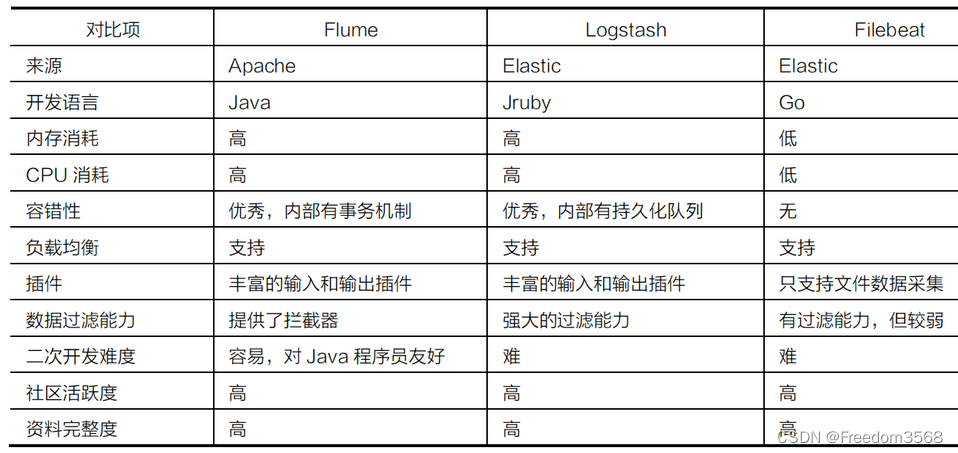
Выбор технологий Flume, Logstash и FileBeat показан на рисунке 2.
Выбор технологии между Sqoop и Datax показан на рисунке 3.
Выбор технологий между Cannal и Maxwell показан на рисунке 4.

2. Структура технологии хранения данных
Быстрый рост объема данных способствовал развитию технологий, и появился ряд отличных систем хранения, поддерживающих распределенное хранение. Платформы технологий хранения данных включают HDFS, HBase, Kudu, Kafka и т. д.
- HDFS может решить проблему хранения больших объемов данных,Но его самым большим недостатком является то, что для отдельных данных не требуется операция модификации.,Потому что это все-таки не библиотека данных.
- HBase — это распределенная библиотека NoSQL, основанная на HDFS. это означает,HBase может использовать преимущества огромной емкости HDFS.,И поддержать операцию модификации. Но HBase не является реляционной библиотекой.,Поэтому он не может поддерживать традиционный синтаксис SQL.
- Kudu — технический компонент между HDFS и HBase.,теперь этоподдерживатьданные Исправлять,Также поддерживается функция анализа данных на основе SQL. Текущее позиционирование Kudu довольно неудобно;,Относится к компромиссному плану,Оно имеет ограниченное применение в практической работе.
- Kafka часто используется для временного буферного хранения огромных объемов данных.,Обеспечьте внешнему миру возможности высокопроизводительного чтения и записи.
3. Структура управления распределенными ресурсами
В традиционной ИТ-сфере ресурсы корпоративных серверов (память, процессор и т. д.) ограничены и фиксированы. Однако сценарии применения серверов гибки и изменчивы. Например, сегодня система временно подключена к сети и требует нескольких серверов. Через несколько дней систему необходимо отключить и очистить эти серверы.
До наступления эпохи больших данных изменения в ресурсах серверов соответствовали переходу системы в режим онлайн и офлайн, и эти изменения были ограничены.
С приходом эпохи больших данных спрос на временные задачи сильно возрос, и эти задачи часто требуют большого количества ресурсов сервера.
Очевидно, что в настоящее время нереально полагаться на персонал по эксплуатации и техническому обслуживанию, который вручную будет обрабатывать изменения в ресурсах сервера.
Поэтому, как того требует время, появились системы управления распределенными ресурсами, к числу распространенных из которых относятся YARN, Kubernetes и Mesos. Их типичные области применения показаны на рисунке 5.

4. Структура расчета данных
Расчет данных делится на расчет данных в автономном режиме и расчет данных в реальном времени.
(1) Расчет данных в автономном режиме
После более чем десяти лет разработки механизм автономных вычислений больших данных претерпел три основных изменения.
- MapReduce можно назвать большим данные Первое в отрасли поколение оффлайнданные Вычислительный двигатель,Он в основном используется для решения распределенных параллельных вычислений крупномасштабных наборов данных. Основная идея вычислительного механизма MapReduce заключается в,Вычислительная логика Воля разделена на два этапа обработки: Map и уменьшает.
- Вычислительный механизм Tez слабо представлен в экосистеме технологий больших данных. В реальной работе Tez редко используется отдельно для разработки вычислительных программ.
- Самая большая особенность Spark — вычисления в памяти: все промежуточные результаты на этапе выполнения задачи помещаются в память.,Нет необходимости читать и записывать диск,Значительно улучшена вычислительная производительность данных. Spark предоставляет большое количество функций высшего порядка (также называемых операторами).,Может реализовывать итерационные вычисления различной сложной логики.,Он очень подходит для применения в быстрых и сложных вычислениях больших объемов данных.
(2) Расчет данных в реальном времени
Наиболее типичным сценарием обработки данных в реальном времени в отрасли является экран больших данных Tmall «Double Eleven».
Индикаторы данных, такие как общая сумма транзакции и общий объем заказа, отображаемые на большом экране данных, рассчитываются в режиме реального времени.
После того, как пользователь приобретет продукт, сумма продукта будет добавлена к общей сумме транзакции на экране больших данных в режиме реального времени.
Для расчета данных в реальном времени используются три основных инструмента:
- Storm в основном используется для реализации распределенных вычислений в реальном времени.
- Flink принадлежит к новому поколению распределенных вычислительных механизмов реального времени, а его вычислительная производительность и экосистема лучше, чем у Storm.
- Компонент SparkStreaming в Spark также может предоставлять возможности распределенных вычислений в реальном времени с точностью до секунд.
Различия между Spark Streaming, Storm и Flink показаны в таблице 4.
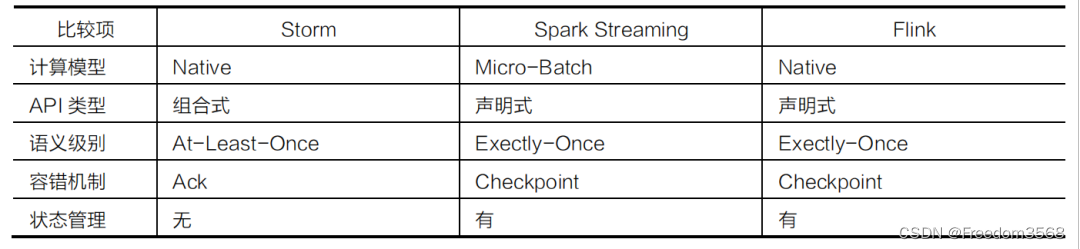
Выбор технологий среди Storm, Spark и Flink показан на рисунке 6.

Раньше Spark в основном использовался для автономных вычислений на предприятиях, а Flink в основном использовался для вычислений в реальном времени.
5. Технологическая основа анализа данных
В число технологий анализа данных входят Hive, Impala, Kylin, Clickhouse, Druid, Drois и т. д. Типичные сценарии их применения показаны на рисунке 7.
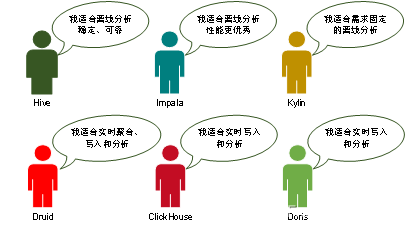
Hive, Impala и Kylin являются типичными механизмами автономного анализа данных OLAP и в основном используются в области автономного анализа данных. Различия между ними показаны в таблице 5.
- Эффективность выполнения Hive средняя, но стабильность чрезвычайно высока;
- Impala может обеспечить отличную эффективность выполнения на основе памяти, но ее стабильность средняя;
- Kylin может предоставить ответ на уровне данных PB за миллисекунды посредством предварительного расчета.

Clickhouse, Druid и Drois являются типичными механизмами анализа данных OLAP в реальном времени и в основном используются в области анализа данных в реальном времени. Различия между ними показаны в таблице 6.
- Druid и Doris могут поддерживать высокий уровень параллелизма, но ClickHouse имеет ограниченные возможности параллелизма; поддержка SQL в Druid ограничена, тогда как Doris поддерживает стандартный SQL и имеет лучшую поддержку SQL.
- Druid и ClickHouse в настоящее время относительно зрелы, а Doris находится на стадии быстрого развития.

6. Технологическая основа планирования задач
Технологические платформы планирования задач включают Azkaban, Ooize, DolphinScheduler и т. д. Они подходят для планирования рутинных задач, которые выполняются в обычное время, а также многоуровневых задач, содержащих сложные зависимости. Они поддерживают распределение и обеспечивают производительность и стабильность системы планирования. Различия между ними показаны в таблице 7.
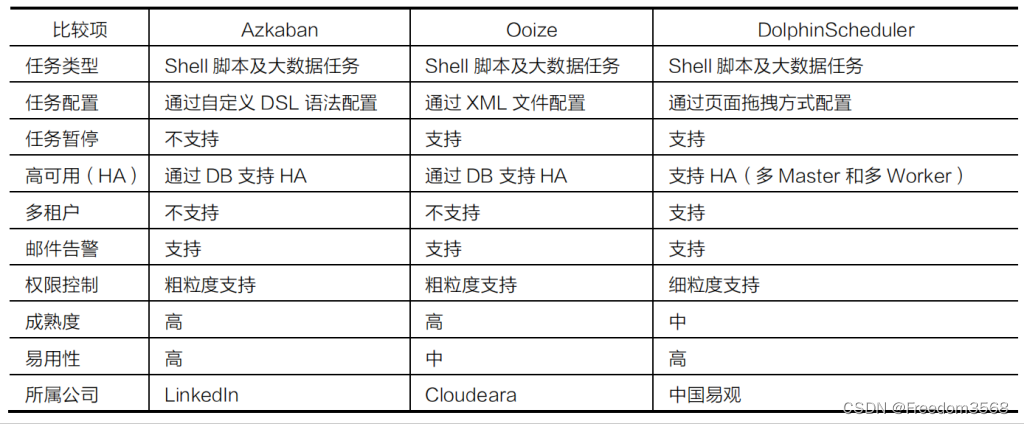
Предыдущий выбор технологии показан на рисунке 8.

7. Большие данные, лежащие в основе базовой технологической структуры
Базовая технологическая основа больших данных в основном относится к Zookeeper. Zookeeper в основном предоставляет часто используемые базовые функции (такие как пространство имен, службы конфигурации и т. д.). Zookeeper используется для запуска таких технических компонентов, как Hadoop (HA), HBase и Kafka, в экосистеме больших данных.
8. Структура технологии поиска данных
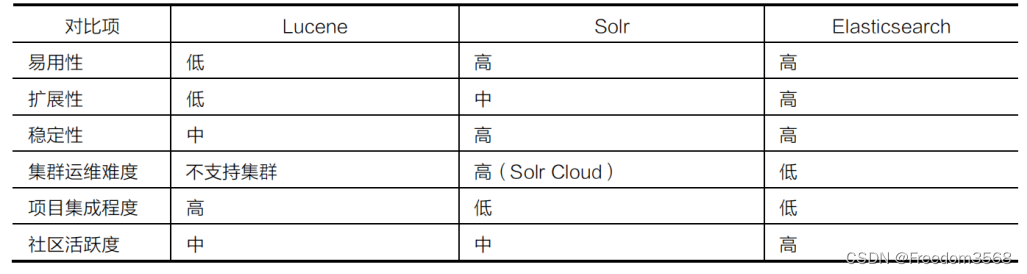
С постепенным накоплением данных на предприятиях требования к статистическому анализу массивных данных будут становиться все более разнообразными: не только анализ, но и быстрые и сложные запросы с множеством условий. Например, функция поиска продуктов на веб-сайтах электронной коммерции и функция поиска информации в различных поисковых системах относятся к категории быстрых и сложных запросов с множеством условий. Выбирая инструмент полнотекстового поиска, вы можете сравнить его по простоте использования, масштабируемости, стабильности, сложности эксплуатации и обслуживания кластера, степени интеграции проекта и активности сообщества. Сравнение Lucene, Solr и Elasticsearch показано в таблице 8.
9. Структура установки и управления кластером больших данных
Если предприятие хочет перейти от традиционной обработки данных к обработке больших данных, первое, что нужно сделать, — это построить стабильную и надежную платформу больших данных. Полноценная платформа больших данных должна включать сбор данных, хранение данных, расчет данных, анализ данных, мониторинг кластера и другие функции, а это означает, что она должна включать Flume, Kafka, Haodop, Hive, HBase, Spark, Flink и другие компоненты. Эти компоненты необходимо развернуть на сотнях или даже тысячах машин.
Если вы полагаетесь на персонал по эксплуатации и техническому обслуживанию для установки каждого компонента по отдельности, рабочая нагрузка будет относительно большой, и необходимо учитывать проблемы соответствия и различные конфликты между версиями, а последующие работы по обслуживанию кластера также окажут большое давление на персонал по эксплуатации и техническому обслуживанию.
Поэтому некоторые зарубежные производители инкапсулировали компоненты в большие данные и предоставили интегрированную платформу больших данных, которую можно использовать для быстрой установки компонентов больших данных. В настоящее время к наиболее распространенным в отрасли относятся CDH, HDP, CDP и т. д.
- ДПН: Полное имя Hortonworks Data Платформа. он состоит из Hortonworks Компания основана на Apache Hadoop инкапсулированный с помощью Ambari Инструмент обеспечивает установку и управление на основе интерфейса, а также интегрирует большие Общие компоненты в данных, Может обеспечить комплексное управление кластером. ДПН Относится к бесплатной версии с открытым исходным кодом. Платформа данных не предоставляет коммерческих услуг;
- CDH: Полное имя Cloudera Distribution Including Apache Хадуп. он состоит из Cloudera Компания основана на Apache Hadoop был коммерциализирован с помощью Cloudera Manager Инструмент обеспечивает установку и управление на основе интерфейса, а также интегрирует большие Общие компоненты в данных,Может обеспечить комплексное управление кластером. CDH Относится к коммерческим сборам платформа данных, доступная для пробной версии по умолчанию 30 небо. После этого, если вы хотите продолжать использовать расширенные функции и коммерческие услуги, вам необходимо заплатить за лицензию. Если вы используете только базовые функции, вы можете продолжать использовать их бесплатно;
- CDP:Cloudera Компания находится в 2018 Год 10 Приобретено за месяц Hortonworks, затем выпустила новое поколение больших продукты платформы данных CDP(Cloudera Data Center)。CDP Номер версии продолжает предыдущий. CDH номер версии. от 7.0 версия запускается, CDP поддерживать Private Облако (частное облако) и Hybrid Облако (гибридное облако). CDP Воля HDP и CDH Были интегрированы наиболее выдающиеся компоненты и добавлены некоторые новые компоненты.
Взаимосвязь между ними показана на рисунке 9.




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
