Архитектура больших данных Lambda-Architect (шестьдесят девять)
сейчас
день
один
код
С развитием технологий в информационную эпоху быстрое увеличение объема данных постепенно достигло поразительного уровня. А технологии сбора и обработки данных все еще совершенствуются и ускоряются. В больших данных на структурированные данные приходится около 15%, а остальные 85% — это неструктурированные данные. Они существуют в больших количествах в таких областях, как социальные сети, Интернет и электронная коммерция.
Характеристики одной большой архитектуры системы данных
1. Надежный и отказоустойчивый
В крупномасштабных распределенных системах машины могут выходить из строя, но система должна быть надежной и работать правильно, даже если она сталкивается с машинными ошибками. Как машинные, так и человеческие ошибки существуют и неизбежны каждый день.
2. Возможности чтения и обновления с низкой задержкой.
Некоторым требуется возможность обновления в течение миллисекунд, а некоторые допускают задержку обновлений на несколько часов. Пока требуется низкая задержка, система должна обеспечивать надежность.
3. Горизонтальное расширение
Когда нагрузка увеличивается, вы обычно можете выполнить масштабирование, добавив больше компьютеров.
4. Универсальность
Для поддержки подавляющего большинства приложений, включая финансовую, социальную и электронную коммерцию.
5. Расширяемость
При возникновении новых потребностей в систему можно добавить новые функции.
6. Возможность запроса
Пользователи могут запрашивать информацию в соответствии со своими потребностями, что может принести более высокую ценность.
7. Минимальные возможности обслуживания.
Большую часть времени система остается сбалансированной, что является важным способом сокращения времени обслуживания системы.
8. Регулируемость
система работает,Каждая произведенная ценность,Все можно отследить и отладить.
2. Лямбда-архитектура
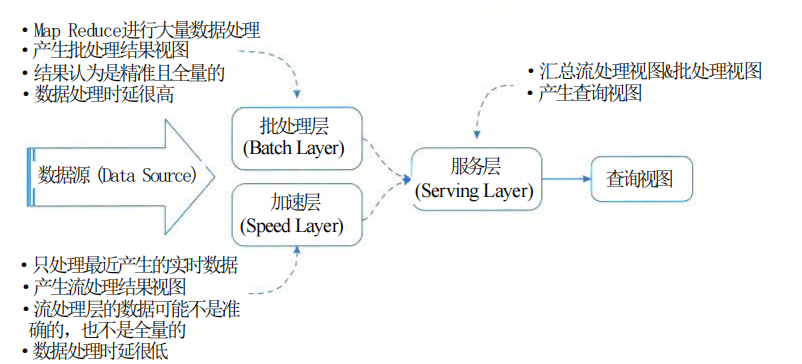
Архитектура Lambda в основном разделена на три уровня: уровень пакетной обработки, уровень ускорения и уровень обслуживания.
(1) Пакетный уровень: хранит наборы данных, предварительно рассчитывает функции запросов и создает представления, соответствующие запросам. Пакетный уровень подходит для пакетной обработки автономных данных. Когда многие сценарии требуют запроса в реальном времени, требуется Speed Layer.
(2) Уровень скорости: пакетный уровень обрабатывает все данные, а уровень скорости обрабатывает дополнительные данные. Уровень скорости будет постоянно обновлять представление в реальном времени после получения данных.
(3) Уровень обслуживания: уровень обслуживания используется для объединения наборов данных результатов в пакетном представлении и представлении в реальном времени в окончательный набор данных.
1. Пакетная обработка
Пакетная обработка имеет две основные функции: хранение наборов данных и создание пакетных представлений. Этот уровень в основном отвечает за основной набор данных, который имеет следующие три атрибута:
(1) Данные оригинальные
(2) Данные неизменяемы.
(3) Данные всегда верны
2. Слой ускорения
Он хранит представления в реальном времени и передает потоки данных для обновления этих представлений.
Какая между ними разница?
(1) Данные, обрабатываемые на уровне скорости, представляют собой инкрементальные данные, а пакетный уровень — это общие данные.
(2) В целях эффективности уровень скорости обновляет представление в реальном времени при получении данных, в то время как пакетный уровень напрямую получает пакетное представление на основе всех автономных данных.
Каковы преимущества разделения на уровни ускорения и пакетной обработки?
Отказоустойчивость: при перерасчете уровня скорости текущее представление в реальном времени можно отбросить, а пакетное представление также пересчитывается.
Изоляция сложности. Пакетную обработку автономных данных легко освоить, а уровень ускорения обрабатывает дополнительные данные, чтобы изолировать их.
Масштабирование: горизонтальное расширение, расширение за счет добавления машин вместо увеличения производительности машин.
3. Сервисный уровень
Используется для ответа на запросы пользователей и объединения наборов результатов в пакетном представлении и представлении в реальном времени для получения окончательного набора данных.
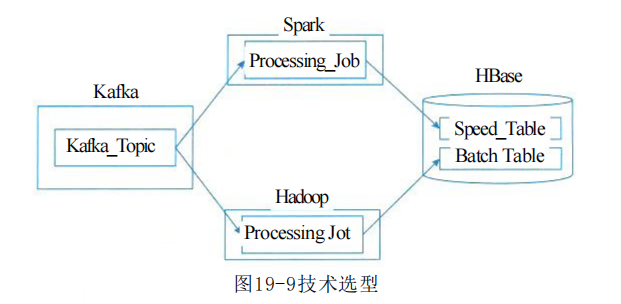
Реализация архитектуры Lambda?
Hadoop (HDFS) используется для хранения наборов данных, Spark (или Storm) формирует уровень скорости, HBase служит уровнем обслуживания, а Hive создает представления с возможностью запроса.
Hadoop предназначен для работы в распределенной файловой системе общего назначения (Distributed File System),Имеет много общего с текущей распределенной системой.,HDFS — это высокоотказоустойчивая база данных.,Может предоставить данные доступа к пропускной способности.
Apache Spark — это быстрый вычислительный механизм, специально разработанный для больших данных.
База данных HBase-Hadoop — это высокодоступная、высокая производительность、столбчатый、Масштабируемая распределенная система.
Преимущества лямбды:
1. Хорошая отказоустойчивость: при возникновении ошибки начните с исправления алгоритма или вычислений с нуля.
2. Высокая гибкость запросов: пакетная обработка позволяет временно запрашивать любые данные.
3. Простота масштабирования. Все пакетные процессы, уровень ускорения и уровень обслуживания легко расширяются.
4. Расширение: добавлять представления легко, просто добавьте новые функции к основным данным.
недостаток:
1. Полное покрытие сцены требует дополнительных затрат на программирование.
2. Переподготовка для конкретных сценариев приносит мало пользы.
3. Затраты на перераспределение и миграцию высоки.
Сравнение архитектуры Lambda с другими архитектурами:
1. Источник событий и лямбда-архитектура
Вся система управляется событиями, а бизнес-данные представляют собой представление, созданное событиями.
2. CQRS и лямбда-архитектура
Архитектура CQRS разделяет операции чтения и записи данных, а также отделяет команды изменения состояния модели данных от запросов состояния модели.
сосредоточиться на Я...сопровождаю вас учиться и добиваться прогресса каждый день



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
