Apache Kyuubi & Celeborn (Incubating) Помощь Spark Используйте возможности облака
Эта статья составлена на основе того, чем поделился Пан Ченг, инженер-программист NetEase Shufan, на конференции ASF CommunityOverCode Asia 2023 (Пекин). Содержание этой статьи в основном следующее: 1) Преимущества и проблемы облачной среды Spark 2) Как создать единый шлюз задач Spark на основе Apache Kyuubi 3) Как создать службу Shuffle Service на основе Apache Celeborn (Incubating 4); ) Другие аспекты NetEase Spark по улучшению решений Kubernetes.

За последние несколько лет NetEase провела значительные исследования в области облачных технологий для больших данных. В этой статье основное внимание уделяется тому, как на основе Apache Kyuubi & Celeborn и другие технологии с открытым исходным кодом для создания корпоративного уровня Spark on Kubernetes Платформа облачных автономных вычислений развернута, включая выбор технологий, проектирование архитектуры, опыт и извлеченные уроки, устранение дефектов, снижение затрат и повышение эффективности и т. д., а также обеспечивает углубленный анализ результатов исследований NetEase в этой области.
01 Преимущества и проблемы Spark в Kubernetes
Apache Spark, являющийся фактическим стандартом в сегодняшней области автономных вычислений больших данных, широко используется в коммерческих продуктах, таких как внутренние и промежуточные платформы NetEase. В настоящее время Spark на YARN является наиболее распространенным и зрелым методом использования в отрасли. Однако с ростом популярности облачных технологий, представленных Kubernetes, Spark на K8s отдается предпочтение все большему количеству пользователей.
NetEase изучает технологию Spark на K8s с 2018 года. По сравнению со Spark на YARN, Spark на K8s имеет значительные преимущества во многих аспектах, в то же время, будучи более новой технологией, она не так совершенна, как Spark на YARN, по некоторым функциям; Ниже мы проведем простое сравнение некоторых наиболее важных частей:
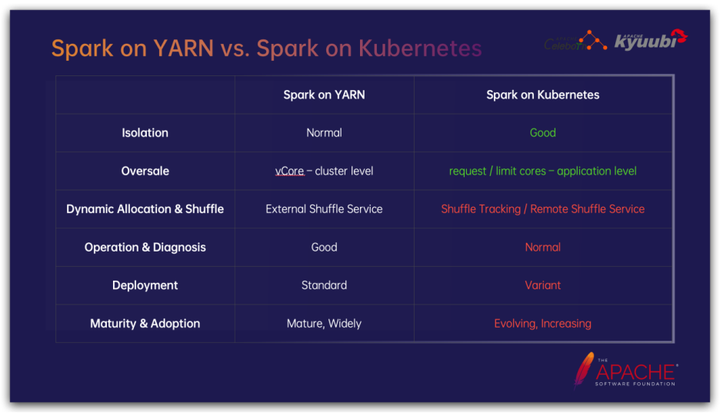
С точки зрения изоляции, благодаря поддержке контейнерной технологии, Spark на K8s имеет значительные преимущества перед механизмом изоляции заданий на уровне процессов YARN. С одной стороны, контейнеризация значительно упрощает управление зависимостями заданий Spark, особенно зависимостями Python и динамически подключаемыми библиотеками, которые в то же время хорошо изолированы, контейнеризация и механизм cgroup позволяют более строго и тонко ограничивать ресурсы заданий;
В стратегии управления ресурсами на уровне кластера приложения часто не используют 100 % запрошенных ресурсов. Овербукинг является распространенной стратегией улучшения использования ресурсов кластера. Если взять в качестве примера ЦП, YARN может установить соотношение виртуального ядра к физическому ядру на уровне кластера, то есть коэффициент переподписки ЦП, но K8s может поддерживать коэффициент переподписки ЦП на уровне задания. Задачи в кластере имеют разные коэффициенты использования; ЦП, для многих задач с большим объемом операций ввода-вывода, связанных с передачей данных, установка более высокого коэффициента переподписки ЦП может значительно сэкономить ресурсы ЦП.
Динамическое распределение ресурсов — очень важная функция заданий Spark, позволяющая улучшить использование ресурсов. В Spark на YARN служба внешнего перемешивания находится в каждом процессе NodeManager в виде подключаемого модуля, предоставляющего услуги чтения для перемешиваемых данных текущего узла. Исполнитель может выйти в любой момент, не принимая во внимание, как нижестоящая задача сокращения считывает данные перемешивания, однако на K8s соответствующий компонент отсутствует, а вместо этого существует множество дополнительных решений, которые будут подробно обсуждаться позже;
Spark на YARN предоставляет множество вспомогательных функций. Например, YARN, естественно, имеет концепцию приложения, предоставляет службы агрегирования журналов, поддерживает агенты пользовательского интерфейса Spark Live и т. д. Они недоступны в Spark на K8s.
Что касается решений по развертыванию, Spark on YARN предоставляет стандартизированные решения; однако Spark на K8s имеет различные способы игры, такие как упомянутое выше решение в случайном порядке и использование в качестве примера отправки задач, представленных решениями для отправки YAML и Spark. собственные решения искровой подачи появляются одно за другим.
В то же время мы сталкиваемся с очень общей проблемой: у пользователей разные инфраструктуры Kubernetes. Как мы можем максимально эффективно использовать их соответствующие характеристики и максимизировать преимущества, поддерживая различные инфраструктуры?
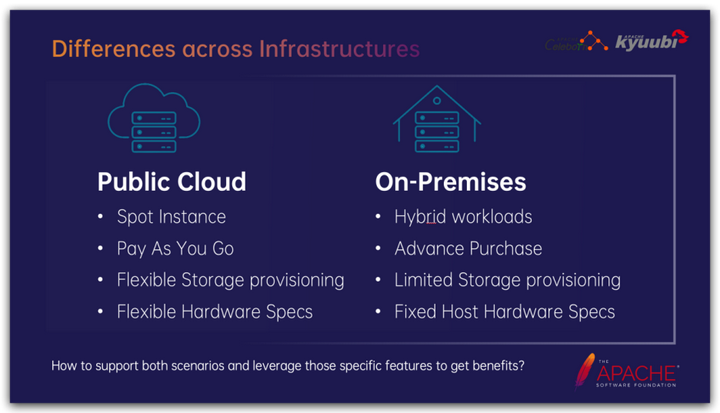
Например, существуют существенные различия между инфраструктурой, представленной публичным облаком, и частным развертыванием: На основе принципа снижения затрат и повышения эффективности с точки зрения затратных преимуществ:
- Помимо поддержки выкупа по времени, общедоступное облако также предлагает модель оплаты по мере использования. В зависимости от типа ресурса общая скорость использования обычно ниже общего времени. 30%~60% изслучай,Выставление счетов с оплатой по мере использования может значительно снизить затраты. Инстансы для ставок в общедоступном облаке значительно конкурентоспособны по цене;,Но он полон неопределенности и риска быть упрежденным в любой момент;
- Оборудование, развернутое в частном порядке, естественно, не так гибко, как публичное облако, и его, как правило, необходимо приобретать заранее. Чтобы максимизировать использование ресурсов, мы часто начинаем с автономного микширования. Обычно пик онлайн-бизнеса приходится на дневное время, а пик офлайн-задач — на ночь. Гибридное развертывание и передача ресурсов могут улучшить использование ресурсов кластера и снизить общие затраты.
Память — важный объект, влияющий на Spark на K8s. В общедоступном облаке обычно могут быть предоставлены сетевые диски различных спецификаций для удовлетворения различных требований к удаленному монтажу, в то время как сценарии частного развертывания часто сильно ограничены и в основном основаны на локальных дисках, привязанных к физическим узлам, соответственно, с одинаковой производительностью и емкостью ввода-вывода. , местное оборудование, как правило, стоит дешевле.
Другое оборудование, такое как сетевые карты, процессоры и память, аналогично. Публичные облака обычно могут гибко предоставлять различные конфигурации; частные развертывания в основном ограничены конкретными спецификациями и моделями, но цена за единицу часто ниже.
02 Как создать единый шлюз задач Spark на базе Apache Kyuubi
В NetEase размещаются все службы Spark. Мы используем Apache Kyuubi в качестве единого шлюза отправки задач Spark. Kyuubi предоставляет несколько пользовательских интерфейсов и поддерживает несколько типов задач Spark. Типичные сценарии использования включают: пользователи могут использовать JDBC/BeeLine и различные инструменты BI для подключения для интерактивного анализа данных; использовать RESTful API для отправки пакетных заданий SQL/Python/Scala/Jar в Kyuubi.

Будучи шлюзом больших данных корпоративного уровня, Kyuubi также полностью поддерживает мультиарендность и безопасность. Например, Kyuubi внес глубокие изменения в поддержку Kerberos, такие как упрощение для клиентов JDBC использования аутентификации Kerberos; поддержка одновременного включения Kerberos/LDAP, и клиент может выбрать любой метод аутентификации, поддерживающий; Механизм пользовательского агента Hadoop. Обеспечивая безопасность, он устраняет необходимость управления большим количеством пользовательских клавишных таблиц, поддерживает обновление токена делегирования Hadoop для удовлетворения требований аутентификации резидентных задач Spark и т. д.
В сообществе Kyuubi много пользователей и участников из компаний, занимающихся финансовыми ценными бумагами, а также европейских и американских компаний. У них более строгие требования к безопасности. Например, внутренние коммуникации между компонентами службы также должны быть зашифрованы, поддерживать контроль разрешений, аудит SQL и т. д. очень строго относится к таким сценариям. Тоже компетентный.
В дополнение к своей основной функции шлюза, Kyuubi также предоставляет серию плагинов Spark, которые можно использовать независимо, предоставляя функции корпоративного уровня, такие как управление небольшими файлами, Z-порядок, извлечение происхождения SQL и ограничение объема данные запроса сканируются.
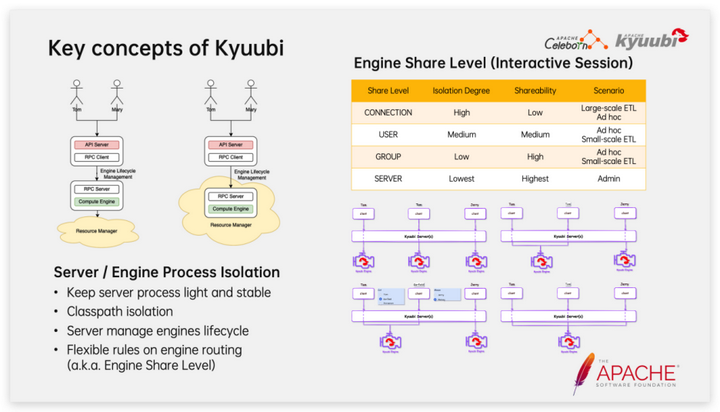
С архитектурной точки зрения двумя важными компонентами Kyuubi являются сервер и движок. Сервер — это облегченная резидентная служба, а Engine — это приложение Spark, которое запускается и останавливается по требованию. После подключения клиента сервер Kyuubi будет искать подходящий механизм на основе правил маршрутизации. Если совпадение не найдено, будет вызвана искровая отправка для загрузки нового приложения Spark, когда приложение Spark простаивает в течение определенного периода времени. , он будет активно выходить для освобождения ресурсов. Кьюби решил использовать собственный метод Spark для подключения к Kubernetes вместо режима оператора Spark. Этот выбор позволяет Кьюби более последовательно использовать команду spark-submit для подключения к различным системам управления ресурсами, таким как YARN, Mesos и Standalone. Этот дизайн больше подходит предприятиям с существующей инфраструктурой больших данных, позволяющим плавно перейти к облачной архитектуре больших данных.
Для интерактивных сеансов Кьюби творчески предлагает концепцию уровней совместного использования движка. Существует четыре встроенных варианта: ПОДКЛЮЧЕНИЕ, ПОЛЬЗОВАТЕЛЬ, ГРУППА и СЕРВЕР. Изоляция постепенно снижается, а степень совместного использования постепенно увеличивается. Комбинации могут встречаться различными. сценарии загрузки. Например, уровень общего доступа CONNECTION подтягивает отдельное приложение Spark для каждого сеанса, эффективно обеспечивая изоляцию между сеансами, и обычно используется для крупномасштабных задач планирования ETL. Уровень общего доступа USER позволяет одному и тому же пользователю повторно использовать одно и то же приложение Spark; , как ускоряет запуск новых сеансов, так и гарантирует, что другие не будут затронуты в случае неожиданного завершения работы приложения Spark (например, OOM, вызванного запросом большого набора результатов). Для пакетных задач поддерживается только семантика уровня совместного использования, такая как CONNECTION, и в этот момент Kyuubi ведет себя больше как система планирования задач.
Сервер Kyuubi спроектирован как облегченный шлюз. Напротив, Kyuubi Engine немного менее стабилен и может вызвать OOM из-за больших наборов результатов, возвращаемых запросами. Конструкция разделения процессов сервера и механизма хорошо обеспечивает стабильность сервера. Стабильность и дизайн уровня совместного использования двигателя хорошо контролируют масштаб воздействия сбоя двигателя.

С точки зрения конкретной внутренней реализации интерактивный сеанс Кьюби имеет две важные концепции: сеанс и операция. Эти две концепции соответствуют соединению и оператору в JDBC, а также SparkSession и QueryExecution в Spark соответственно.
Выше приведен типичный код, который подключает Kyuubi для выполнения Spark SQL через драйвер JDBC. Вы можете четко видеть соответствие между клиентским вызовом JDBC и стороной механизма Spark. В частности, при получении набора результатов набор результатов возвращается клиенту из драйвера Spark через сервер Kyuubi в виде микропакета, что эффективно снижает нагрузку на память сервера Kyuubi и обеспечивает стабильность сервера Kyuubi; последняя версия 1.7. В этой версии Kyuubi поддерживает метод сериализации набора результатов на основе Apache Arrow, что значительно повышает эффективность передачи сценариев с большим набором результатов.
03 Как создать службу Shuffle Service на основе Apache Celeborn (инкубация)
Как упоминалось выше, решение для перемешивания играет решающую роль в динамическом распределении ресурсов Spark на K8s. Исполнитель может быть выпущен только в том случае, если оно гарантирует, что данные перемешивания нижестоящего чтения не будут затронуты. В последние годы сообщество и крупные компании разработали бесконечное количество способов использования тасованных решений. Вот краткое введение в некоторые из наиболее распространенных методов.
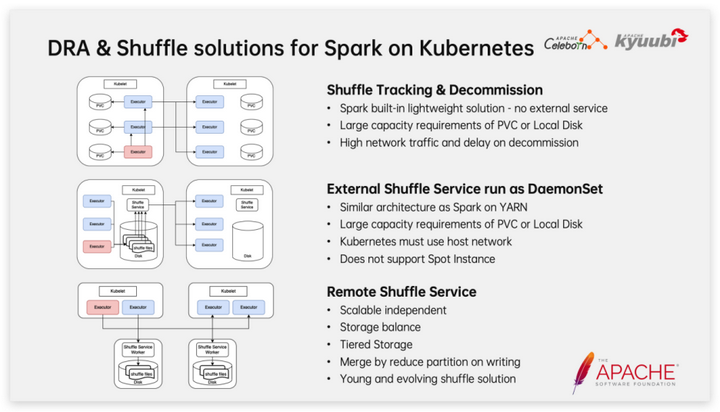
Первый — Shuffle Tracking в сочетании с выводом из эксплуатации, который представляет собой облегченное решение, встроенное в Spark и не требующее обслуживания дополнительных сервисов. Отслеживание перемешивания отслеживает происхождение RDD, анализирует, какие данные перемешивания могут быть использованы в дальнейшем, а затем предотвращает выход этих исполнителей, чтобы гарантировать предоставление услуг чтения данных перемешивания. Очевидно, что отложенный выход приведет к определенной трате ресурсов и не сможет справиться с ситуацией, когда Исполнитель OOM. Вывод из эксплуатации является дополнительным методом. Когда Исполнитель простаивает в течение определенного периода времени, данные в случайном порядке будут перемещены на Исполнитель, время которого еще не истекло. перед выходом. Согласно нашей практике, это решение не работает должным образом, когда объем данных велик и нагрузка на кластер высока.
Другая естественная идея — воспроизвести решение YARN на K8s, то есть запустить процесс внешней службы перемешивания на каждом узле K8s через DaemonSet, чтобы предоставить услуги чтения в случайном порядке. Это решение полностью соответствует Spark на YARN с точки зрения производительности и надежности и в определенных масштабах использовалось на заре NetEase. Но у него также есть определенные недостатки, например, он не подходит для спотовых экземпляров (можно использовать только поды, а DaemonSet нельзя запускать на узле), и требуется хост-сеть.
В последние год или два решение Remote Shuffle Service пользуется популярностью у все большего числа пользователей. С развитием технологии сетевых карт разница в эффективности чтения и записи по сети и чтения и записи с диска постепенно уменьшилась. Теоретически преобразование чтения и записи локальных дисков в режиме Shuffle, используемого Spark, в сетевое чтение и запись не обязательно приведет к снижению производительности. . Самое главное, что развертывание Shuffle Service как отдельной службы и масштабирование по требованию больше соответствует концепции облачного хранилища, в то же время мы также можем иметь больше рабочего пространства, например, улучшая использование за счет балансировки пространства хранения; узлов и с помощью иерархий. Хранилище обеспечивает производительность, одновременно снижая потребность в высокопроизводительной дисковой емкости. Однако нам должно быть ясно, что с момента создания проекта Spark перемешивание постоянно улучшалось как основная функция; Remote Shuffle Service, как относительно новой технологии, еще предстоит пройти долгий путь с точки зрения стабильности, корректности и производительности. . Ходить.
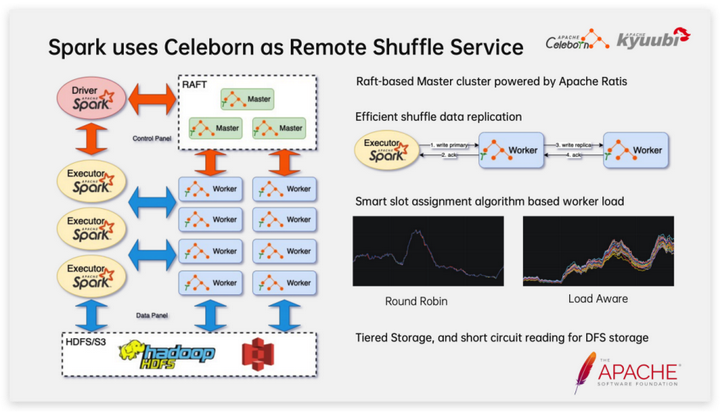
В рамках выбора технологии Remote Shuffle Service компания NetEase решила создать внутреннюю платформу Shuffle Service на базе Apache Celeborn (Incubating). Основные функции, на которых мы фокусируемся, включают в себя:
- Celeborn Сервер содержит Master и Worker Две роли. в Master Он играет координирующую роль и является Raft Кластер обладает хорошими возможностями аварийного восстановления и поддерживает последовательные обновления Worker; Доступен как узел данных shuffle Службу чтения и записи данных можно расширить или сократить в любое время в зависимости от нагрузки, а механизмы проверки работоспособности и работоспособности между компонентами позволяют быстро обнаруживать и устранять неисправности; Worker узел;
- Celeborn предоставляет асинхронный и эффективный механизм копирования, который мало влияет на производительность при включении. Клиенту нужно только успешно записать данные на основной рабочий узел, а затем вернуться. Основной рабочий узел будет асинхронно копировать данные в случайном порядке на резервный рабочий узел. ;
- Разделы в случайном порядке могут быть разумно распределены в зависимости от нагрузки Worker, чтобы сделать нагрузку на кластер более сбалансированной. Это крайне важно для развертывания рабочих дисков на гетерогенных узлах. Например, некоторые узлы используют SSD, а некоторые — жесткие диски. Например, различия в производительности разных рабочих дисков вызваны сочетанием старых и новых серверов и устаревшим оборудованием.
- Поддерживает иерархическое хранилище, а при распределенном хранилище Клиент может напрямую считывать данные из системы хранения, снижая нагрузку на Worker.
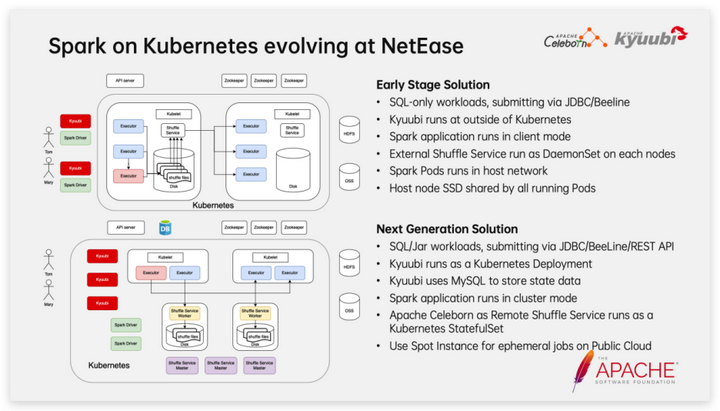
Подведем итог эволюции Spark в Kubernetes в NetEase:
Ранние планы:
1. Поддерживает отправку задач SQL только через JDBC и Би Лайн. 2. Кластер Kyuubi развертывается на узле физической машины вне кластера K8s.
3. Задания Spark выполняются в клиентском режиме.
4. Запускаем службу внешнего перемешивания в виде DaemonSet на каждом узле.
5. Задания Spark, ESS и т. д. выполняются в режиме хост-сети. 6. Установите SSD на каждый узел и смонтируйте его к модулю в режиме HostPath.
Улучшенный план:
1. Поддерживает отправку задач SQL/Jar через JDBC, BeeLine и RESTful. 2. Kyuubi развертывается в кластере K8s в виде StatefulSet.
3. Kyuubi использует MySQL для хранения данных о состоянии. 4. Задания Spark выполняются в режиме кластера. 5. Развертывание Celeborn как StatefulSet в кластере K8s в качестве службы удаленного перемешивания.
6. В общедоступном облаке используйте модули спотовых инстансов для предоставления вычислительных ресурсов для заданий Spark. В частности, спотовые инстансы обладают преимуществами чрезвычайно низкой стоимости и играют решающую роль в сокращении затрат и повышении эффективности.
04 Улучшения NetEase в Spark в Kubernetes в других аспектах
Как упоминалось ранее, Spark в Kubernetes изначально не предоставляет сервисы агрегирования журналов, такие как YARN, что очень неудобно для анализа заданий Spark и устранения неполадок.
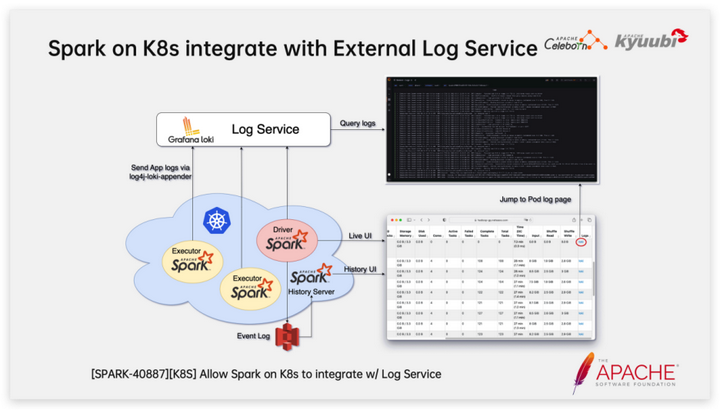
Мы используем следующие методы, чтобы позволить Spark в Kubernetes получить возможность перехода по журналам, аналогичную Spark в YARN:
1. Используйте Grafana Loki для создания хранилища журналов и службы запросов, а также настройте Grafana в качестве службы отображения журналов.
2. Используйте log4j-loki-appender для записи журналов приложения Spark в службу удаленного журнала.
3. В SPARK-40887 мы улучшили Spark для поддержки добавления ссылок перехода к внешним службам журналов в пользовательском интерфейсе Spark посредством конфигурации; ссылки могут быть шаблонами, например, такие переменные, как POD_NAME, можно использовать в качестве запросов в условных ссылках перехода. Стратегия распределения модулей — еще одна интересная тема. Например, в следующих двух сценариях нам необходимо использовать разные стратегии распределения.

В сценариях частного развертывания для некоторых тяжелых задач сети и ввода-вывода, если на одном узле запланировано большое количество исполнителей, это может привести к образованию горячих точек и возникновению узких мест в производительности оборудования. В этой ситуации мы можем использовать антисходство, чтобы ExecutorPod мог быть максимально разбросан по всем узлам при его выделении.
В сценарии смешанного автономного развертывания мы предпочитаем использовать стратегию распределения модулей с упаковкой контейнеров, чтобы сосредоточить модули-исполнители на небольшом количестве узлов, насколько это возможно, чтобы при перемещении узлов можно было быстро освободить машины и влияние на задачи Spark уменьшено.

Разработчики из NetEase и сообщества Kyuubi также внесли множество важных улучшений в Spark на K8s. Из-за ограничений по времени и пространству мы не можем подробно описать их один за другим. Вы можете найти соответствующий запрос на включение в сообществе в соответствии с рабочим заданием JIRA. . Мы также очень благодарны разработчикам из сообщества Spark за помощь в проверке кода и других аспектах!
Живые вопросы и ответы
Q:у нас естьсуществовать K8s Развернуто на Kyuubi Раньше ходил в K8s Отправить Spark задача, дальше мы планируем использовать Kyuubi тоже иди YARN представлять на рассмотрение Spark и Flink Задача. Рекомендуется ли в этом сценарии развертывать отдельный набор для каждой нагрузки? Kyuubi сервис, по-прежнему использовать тот же набор Kyuubi А что насчет обслуживания?
A:Прежде всего, должно быть ясноиз Одна вещь,одинокий Kyuubi Экземпляры или кластеры поддерживают управление несколькими Spark Версии, использование нескольких вычислительных механизмов для разных систем управления ресурсами на обработка Задачаиз. Как упоминалось ранее, Кьюби Server Это легкий и стабильный сервис. В реальных сценариях мы также рекомендуем использовать одиночный сервис. Kyuubi Server Кластер управляет несколькими механизмами для достижения Unified Шлюз. Мы рекомендуем только в том случае, если у пользователя чрезвычайно высокий SLA Выполняйте независимое развертывание в сценариях, где требуется физическая изоляция или она должна быть физически изолирована из соображений безопасности или соответствия требованиям. Kyuubi кластер.
Q:Упоминается при обмене,Celeborn Поддержка непрерывного обновления, я тестировал, Келеборн Worker После перезапуска узла задача не будет выполнена. В чем может быть проблема?
A:Celeborn Он предназначен для поддержки последовательного перезапуска. Владелец узел представляет собой Raft Кластеры, естественно, поддерживают последовательные обновления. существовать Celeborn 0.3.0 Келеборн Присоединился к паре Worker Функция плавного завершения работы узла используется для поддержки последовательных обновлений. В частности, когда Worker Когда узел отправляет сигнал корректного завершения работы: запись client будет ощущаться в обратной информации Worker В состоянии выключения запись в текущий раздел приостанавливается, и revive Механизм пожалуйста новый slot Используется для записи последующих данных после отключения всех запросов на запись, Worker; Это изменит состояние данных памяти само по себе. flush на диск, затем выходим из чтения; клиент, автоматически переключится на replica Узел читает данные; После перезапуска состояние восстанавливается с диска и услуги чтения данных могут продолжать предоставляться. Подводя итог, необходимо поддержать Worker Для последовательного обновления вы должны соответствовать: версии 0.3.0 или выше; включите репликацию данных; включите плавное завершение работы;



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
