Apache Kafka — построение конвейеров данных Kafka Connect

Обзор
Kafka Connect — это инструмент, который помогает нам передавать данные из одного места в другое. Например, если у вас есть веб-сайт и вы хотите перенести пользовательские данные в другое место для анализа, вы можете использовать Kafka Connect для выполнения этой задачи.
Kafka Connect изиспользоватьочень просто。Имеет две основные концепции:source и sink。Source Является ли компонент, который считывает данные из источника данных, приемника? Компонент, который записывает данные в целевую систему. использовать Kafka Подключитесь, вам просто нужно настроить его source и sink Соответствующая информация позволяет автоматически переносить данные из одного места в другое.
Основные понятия
При использовании Kafka Connect для организации потоков данных необходимо учитывать несколько важных концепций:
Connector
- Connectorэто абстракция высокого уровня,Используется для координации потока данных. Он описывает, как читать данные из источника данных.,и перенести его в определенную тему в кластере Kafka или как прочитать данные из определенной темы в кластере Kafka,И запишите его в хранилище данных или другую целевую систему.
Kafka Connect Соединитель определяет, куда и откуда следует копировать данные. Экземпляр соединителя — это логическое задание, отвечающее за управление Kafka и копирование данных между другой системой. Все классы, реализованные или используемые соединителем, определяются в подключаемом модуле соединителя. Экземпляры соединителя и подключаемые модули соединителя можно называть «соединителями».

Kafka Connect упрощает потоковую передачу данных из нескольких источников данных в Kafka и из Kafka в несколько пунктов назначения. Kafka Connect имеет сотни различных соединителей. Среди наиболее популярных:
Более подробная информация об этих разъемах следующая:
Коннектор РСУБД: используется для подключения данных из реляционных баз данных (таких как Oracle, SQL Server, DB2, Postgres и MySQL) и записать их в указанную тему в кластере Kafka или прочитать данные из указанной темы в кластере Kafka и записать их в реляционную библиотеку данных.
Cloud Object Коннектор магазинов: используется для загрузки данных из облачных хранилищ объектов (например, Amazon). S3、Azure Blob StorageиGoogle Cloud Storage) и записать их в указанную тему в кластере Kafka или прочитать данные из указанной темы в кластере Kafka и записать их в облачное объектное хранилище.
Message соединитель очередей: используется для подключения сообщений из очередей сообщений (таких как ActiveMQ, IBM MQиRabbitMQ) и записать его в указанную тему в кластере Kafka, либо прочитать элемент из указанной темы в кластере Kafka и записать его в очередь сообщений.
NoSQL and document Соединитель магазинов: используется для чтения данных из библиотеки данных NoSQL (например, Elasticsearch, MongoDB и Cassandra) и записи их в указанную тему в кластере Kafka или для чтения данных из указанной темы в кластере Kafka и записи их в Данные NoSQL в библиотеке.
Cloud data Коннектор хранилищ: используется для загрузки данных из облачных хранилищ данных (таких как Snowflake, Google BigQueryиAmazon Чтение данных из Redshift) и запись их в указанную тему в кластере Kafka или чтение данных из указанной темы в кластере Kafka и запись их в облачное хранилище данных.
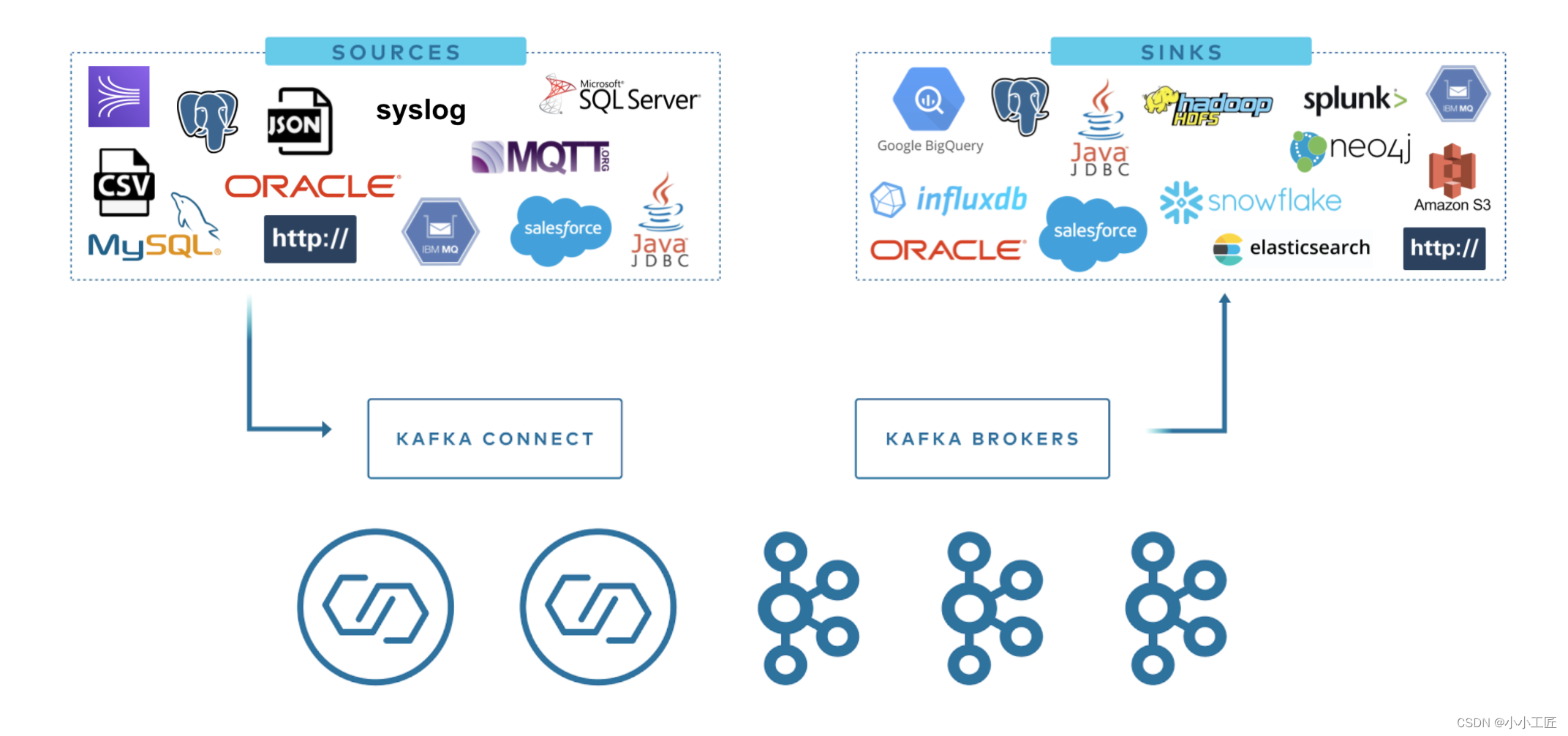
В дополнение к популярным коннекторам, упомянутым выше, Kafka ConnectТакже поддерживает множество другихданныеисточники Цель,включать:
- Hadoopдокументсистема (HDFS)
- Amazon Kinesis
- FTP/SFTP
- Salesforce
- JMS
- Apache HBase
- Apache Cassandra
- InfluxDB
- Apache Druid
Эти соединители позволяют Kafka Connect стать гибким, масштабируемым конвейером данных, который легко передает данные в Kafka из различных источников и в различные места назначения.
Tasks
Задачи являются основным компонентом модели данных Kafka Connect и используются для координации фактического процесса репликации данных. Каждый экземпляр коннектора координирует набор задач, отвечающих за копирование данных из источника в место назначения.
Kafka Connect обеспечивает встроенную поддержку параллелизма и масштабируемости, позволяя соединителю разбивать одно задание на несколько задач. Эти задачи не сохраняют состояние и не хранят информацию о состоянии локально. Вместо этого состояние задачи сохраняется в В Кафке есть две специальные темы config.storage.topic и status.storage.topic, которые управляются соответствующими коннекторами.
Сохраняя статус задачи в Kafka, Kafka Connect обеспечивает эластичные и масштабируемые конвейеры данных. Это означает, что задачи можно запускать, останавливать или перезапускать в любое время без потери информации о состоянии. Кроме того, поскольку статус задачи хранится в Kafka, его можно легко Обмен информацией о состоянии между экземплярами Connect,тем самым достигается высокая доступностьиотказоустойчивость。
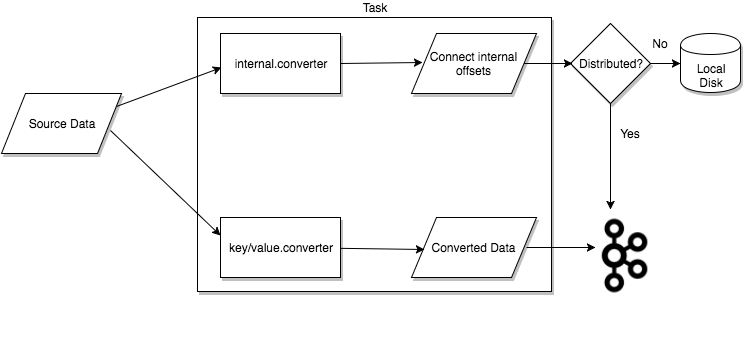
Workes
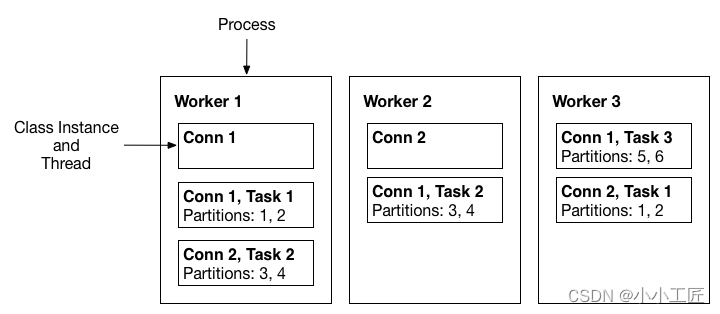
- Workersэто соединитель исполненияи Процесс выполнения задачи。Они начинаются сKafkaЧтение конфигурации задачи для конкретной темы в кластере,и назначьте его задаче экземпляра соединителя.
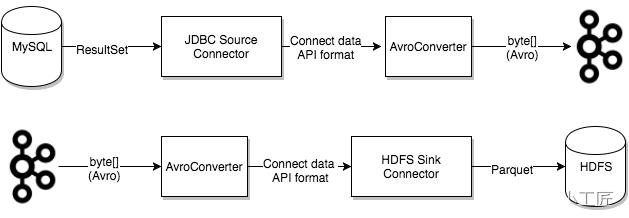
Converters
Конвертеры — это механизм в Kafka Connect для преобразования данных между системами, отправляющими или получающими данные. Они преобразуют данные из одного формата в другой для передачи между различными системами.
В Kafka Connect данные обычно передаются в виде массивов байтов. Преобразователи отвечают за сериализацию объектов Java в массивы байтов и десериализацию массивов байтов в объекты Java. Таким образом, данные можно передавать между различными системами, не беспокоясь о проблемах совместимости форматов данных.
Конвертер Kafka Connect JSON, конвертер Avro и конвертер Protobuf и т. д. Эти преобразователи поддерживают несколько форматов данных и их можно легко настроить ииспользовать.
Кроме того, Kafka Connect также поддерживает пользовательские конвертеры.,Пользователи могут создавать свои собственные преобразователи для удовлетворения конкретных потребностей. Пользовательские конвертеры обычно должны реализовывать интерфейс org.apache.kafka.connect.storage.Converter.,И обеспечить реализацию методов сериализации и десериализации.
Короче говоря, конвертеры — это очень полезный механизм в Kafka Connect, который помогает передавать данные между разными системами и конвертировать форматы данных.
Transforms
Превращает Кафку Connect — это механизм изменения сообщений, который применяет простую логику к каждому сообщению, созданному соединителем или отправленному на него. Преобразования обычно используются в таких сценариях, как очистка данных, преобразование данных и улучшение данных.
Преобразования позволяют применять к каждому сообщению ряд операций преобразования, таких как удаление полей, переименование полей, добавление меток времени или изменение типов данных. Преобразования обычно состоят из набора преобразователей, каждый из которых отвечает за выполнение определенной операции преобразования.
Kafka Connect предоставляет множество встроенных конвертеров.,Например, ExtractField, TimestampConverter иValueToKey и т.д. также,Пользовательские преобразователи также могут быть написаны для удовлетворения конкретных потребностей.
Суммируя,Превращает Кафку Очень полезный механизм в Коннекте.,Это может помочь изменить структуру и содержание сообщения.,Это позволяет выполнять такие функции, как очистка, преобразование и улучшение.
Dead Letter Queue
Dead Letter Очередь - Кафка Connect — это механизм обработки ошибок соединителя. Когда соединитель не может обработать сообщение, он может отправить сообщение в Dead Letter Очередь,проверить позжеииметь дело с。
Dead Letter Очередь обычно представляет собой специальную тему, используемую для хранения сообщений, которые соединитель не может обработать. Эти сообщения нельзя десериализовать, преобразовать или записать в целевую систему, или они могут содержать недопустимые данные. В любом случае отправьте эти сообщения Dead Letter Очередьможет помочь обеспечитьданныенадежность потокаипоследовательность。
Очередь недоставленных писем позволяет легко отслеживать ошибки соединителя и соответствующим образом обрабатывать их. Например, вы можете вручную проверять сообщения в очереди недоставленных писем и попытаться решить проблему, либо написать сценарий или приложение для автоматической проверки и обработки этих сообщений.
Короче говоря, Мертвый Письмо Очередь — важный механизм Kafka Connect для обработки ошибок соединителя.,Это может помочь обеспечить надежность и согласованность потоков данных.,и упростить обработку ошибок.
Основные сценарии использования
Kafka Обычно существует два типа каналов передачи данных. сценарии использования:
- Kafka как конечная точка конвейера данных, источника или назначения。Например,от Kafka Экспортировать данные в S3 или из MongoDB Импортировать данные в Kafka。

- Kafka как промежуточное программное обеспечение между двумя конечными точками в конвейере данных。Например,от xx поток Импортировать данные в Кафка, то начнем с Kafka Экспортировать в Elasticsearch。
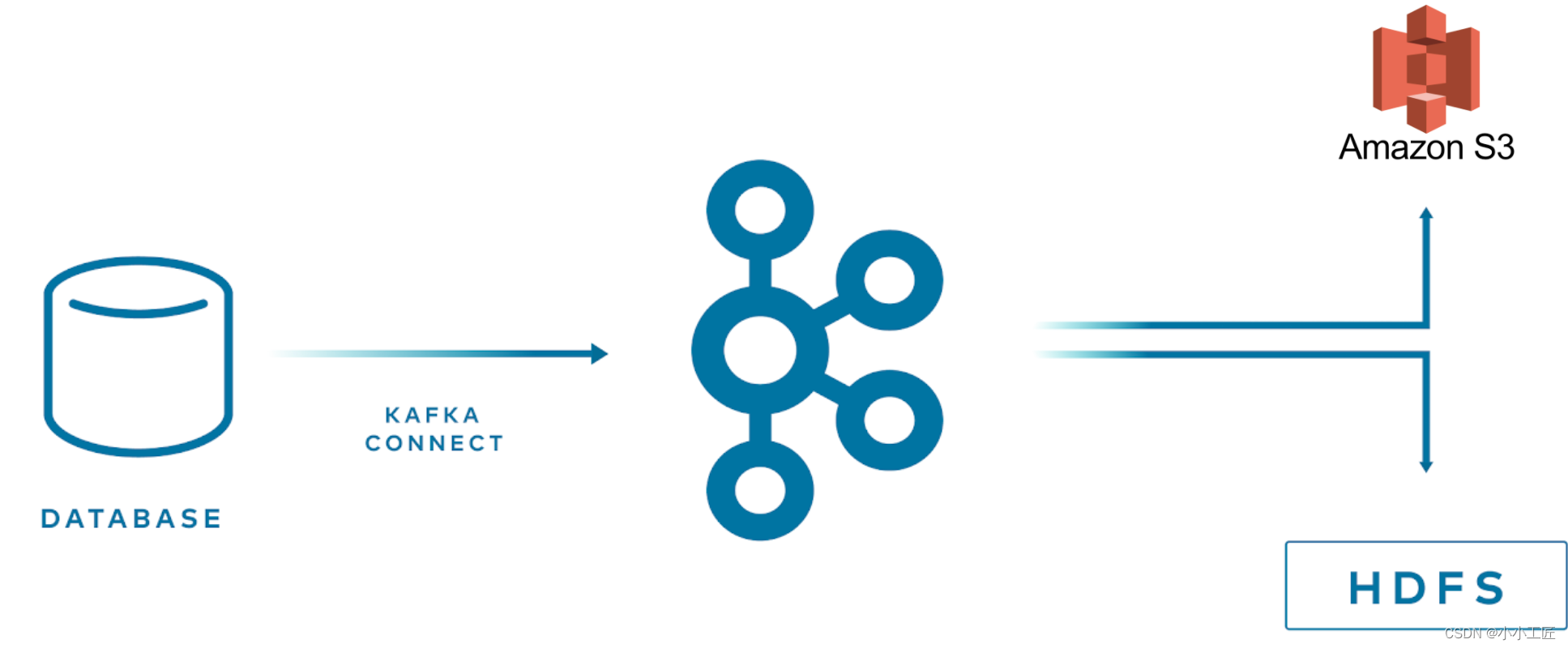
главная ценность
Kafka главная для конвейера данных ценностьлежит в:
- Он может действовать как большой буфер, эффективно разделяя производителей и потребителей.
- Он очень надежен с точки зрения безопасности и эффективности и является лучшим выбором для построения конвейеров данных.
Kafka Connect API против Producer и Consumer API
API Kafka Connect предназначен для решения распространенных проблем интеграции данных.
По сравнению с использованием его напрямую Producer и Consumer API,Kafka Connect API Некоторые из преимуществ:
- Разработка упрощена. Нет необходимости вручную писать логику производителя и потребителя.
- Будьте терпимы к ошибкам. Соединять автоматически перезапустит невыполненные задачи и продолжит синхронизацию данных без потерь.
- Общие источники и места назначения данных уже встроены. Например, разработаны и могут легко использоваться коннекторы для mysql, postgres, elasticsearch и т. д.
- согласованная конфигурацияи Интерфейс управления。проходить REST API Легко настраивается, запускается и останавливается connector Задача.
удалять Kafka Connect API Кроме того,Кафка также может быть интегрирована с другой системой.,Реализуйте интеграцию данных. Например:
- и интеграция Spark Streaming,Для анализа данных в реальном времени и машинного обучения.
- и Flink объединить, реализовать Exactly-Once Семантический поток.
- и Storm United, для создания вычислительных инструментов реального времени.
- и Hadoop Комбинировано для расчетов в реальном времени и пакетных вычислений.
Ключевые вопросы, которые следует учитывать при построении конвейера данных
- Своевременность: поддерживает различные требования к своевременности и может быть перенесена. Кафка Действует как буфер,Разделение производителей и потребителей,Поддерживает обработку в реальном времени и пакетную обработку.
- Надежность. Поддерживается как минимум однократная доставка, и в сочетании с внешней системой может быть достигнута только одна доставка.
- Высокая пропускная возможности и динамическая пропускная способность: поддерживает высокий уровень параллелизма и пакетный трафик. Кафка Высокая пропускная способность,Разделение производителей и потребителей,Может регулироваться динамически.
- формат данных: поддерживает различные форматы,Коннекторы могут конвертировать форматы. Kafka и Connect API не зависят от формата.,используйте подключаемый преобразователь.
- Преобразование:ETL vs ELT。ETL Это может сэкономить место и время, но ограничит последующие операции. ЭЛТ Сохраняйте исходные данные, более гибкие.
- Безопасность: шифрование данных.,Аутентификация и авторизация,Журнал аудита. Кафка Поддержите эти функции безопасности.
- Устранение неполадок: обработка исключений данных,Попробуйте еще раз и исправьте. Потому что Kafka долгосрочное хранение.,Возможна повторная обработка данных истории.
- Соединение и гибкость:
- Избегайте создания отдельных конвейеров данных для каждого приложения.,Увеличение затрат на техническое обслуживание.
- Зарезервированные элементы позволяют изменять схему и избегать жесткой связи производителей и потребителей.
- Обрабатывайте данные как можно меньше,Это дает больше гибкости для последующих клиентов. Чрезмерная обработка может ограничить производительность последующих операций.
Короче говоря, чтобы построить хороший конвейер данных, вам необходимо учитывать все аспекты, такие как время, безопасность, преобразование формата, обработка ошибок и т. д., а также вам необходимо постараться обеспечить слабую связь, чтобы обеспечить максимальную гибкость нижестоящим системам, которые используйте данные.
Kafka Как платформа потоковой обработки, она может хорошо решить эти проблемы и сыграть роль разделения буферов производителя и потребителя. в то же время Kafka Connect Предоставляет общий интерфейс для ввода и вывода данных, упрощая работу по интеграции.
использовать Kafka построен конвейер данных,Может использоваться как в режиме реального времени, так и в сценариях пакетной обработки., с высокой доступностью, Высокая пропускная способность、Высокая масштабируемость и другие характеристики.
ETL VS ELT
Различия в способах интеграции данных
Два разных способа интеграции данных
- ETL:Extract-Transform-Load,То есть извлечь-конвертировать-загрузить. таким образом,данные после извлечения из исходной системы,Сначала будет преобразовано,Затем загрузите его в целевую систему.
- ELT:Extract-Load-Transform,То есть извлечь-загрузить-преобразовать. таким образом,данные после извлечения из исходной системы,Первая загрузка в целевую систему,Затем выполните преобразование и обработку в целевой системе.
- ETL и ELT Основное отличие заключается во времени и месте преобразования данных: ETL Преобразование данных,ELT перед загрузкой заключается в преобразовании данных после загрузки. ETL Преобразование происходит между исходной системой и целевой системой, ELT. Преобразование происходит внутри целевой системы.
ETL и ELT имеют свои преимущества и недостатки:
Преимущества ЭТЛ:
- данные можно фильтровать, агрегировать и выбирать во время процесса загрузки.,Сократите затраты на хранение и вычисления.
- Формат и качество данных можно гарантировать перед загрузкой данных в целевую систему. ETL недостаток:
- Логика преобразования в конвейере смешана, что затрудняет обслуживание и отладку.
- Последующая система может получить доступ только к преобразованным данным, которые имеют низкую гибкость. ELT особенность:
- Предоставьте исходные данные для последующей системы.,Более гибкий.ниже по течениюсистема Может быть настроен в соответствии с потребностямииметь дело си Конвертироватьданные。
- Логика преобразования находится в последующей системе, что упрощает отладку и обслуживание.
- Исходные данные легче отслеживать и повторно обрабатывать.
Недостатки ЭЛТ:
- Целевая система должна обладать мощными возможностями обработки данных.
- Требуется больше места для хранения исходных данных.
- Процесс преобразования может создать большую нагрузку на целевую систему.
Вообще говоря, если нижестоящая система должна быть очень гибкой в обработке данных и иметь сильные возможности обработки данных, ELT зачастую более уместно. В противном случае ЭТЛ Предварительную обработку можно выполнить перед загрузкой данных, чтобы снизить нагрузку на нижестоящую систему. Этот метод будет более эффективным. Во многих случаях он также будет использоваться ETL и ELT Смешанный способ



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
