Анализ исходного кода Redis: как выполняется команда Redis?
Redis (Remote Dictionary Server) — это база данных с открытым исходным кодом в памяти, соответствующая протоколу BSD. Она обеспечивает высокопроизводительную систему хранения значений ключей и обычно используется в таких сценариях приложений, как кэширование, очереди сообщений и хранилище сеансов. В этой статье в основном рассказывается об основных концепциях и процессах Redis. Я надеюсь проанализировать с вами процесс выполнения команды с точки зрения исходного кода. Я надеюсь, что это поможет студентам-разработчикам освоить детали реализации Redis и улучшить свой уровень программирования. и дизайнерские идеи.
1. Структура исходного кода
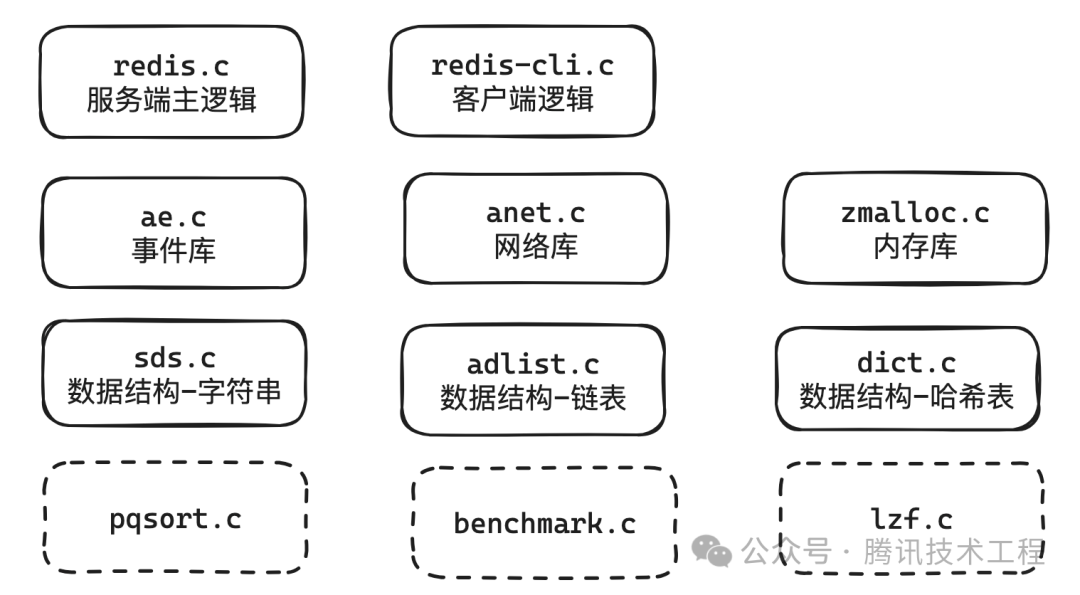
Прежде чем изучать исходный код Redis, нам необходимо иметь представление об общей архитектуре кода Redis. На основе исходного кода redis1.0 мы перечислили следующие файлы исходного кода, относящиеся к основному процессу.
2. Основная структура данных
2.1 redisServer
redisServer — это структура, в которой хранится информация о работе сервера Redis.,Инициализация будет завершена при запуске,Структура следующая,В основном это включает в себя мониторингsocketСоответствующие параметрыportиfd;переписываться Хранить данныеизсписок связанных клиентов RedisDb;clients;событиецикл*el
struct redisServer {
int port; // Порт, который прослушивает сервер
int fd; // Дескриптор файла, соответствующий сокету, запущенному сервером.
redisDb *db; // redis список БД, в реальной производственной среде обычно используется только один
// 3-lines
list *clients; // Список серверов
// 2 lines
aeEventLoop *el; // событиецикл
// 36 lines
};
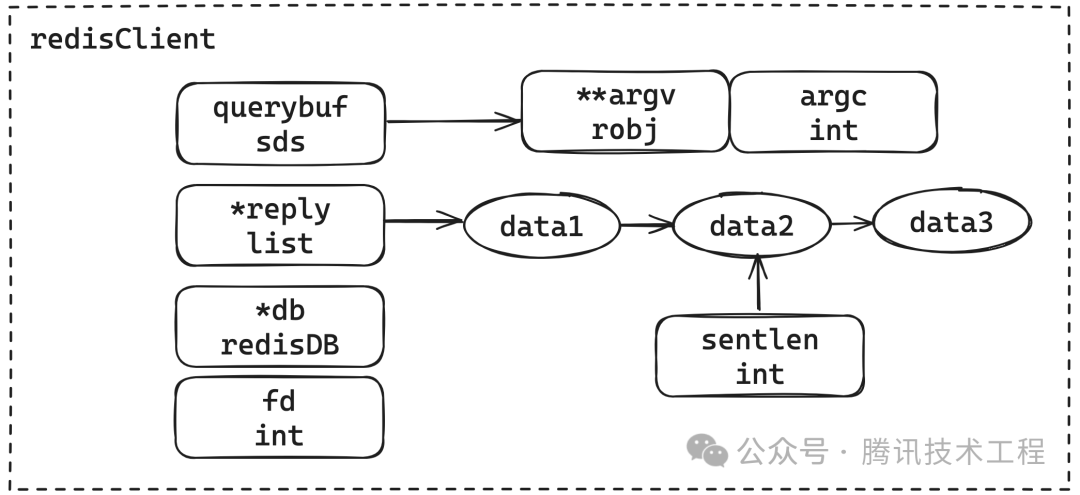
2.2 redisClient
redisClient — это информация о состоянии, хранимая клиентом на стороне сервера.,Когда каждый раз клиент подключается к серверу,будет вновь созданredisClientструктура дляredisServer->clientsв списке。
typedef struct redisClient {
int fd; // клиент Дескриптор файла сокета для отправки команд и получения результатов.
redisDb *db; // Соответствующая БД
// 1-line
sds querybuf; // Буфер хранения команд запроса
robj **argv; // Запросите параметры команды, преобразованные в
int argc; // Количество параметров
// 1-lines
list *reply; // Результатом ответа после выполнения команды является список.
int sentlen; // Длина отправленного результата
// 8-lines
} redisClient;
Мы также используем простую схематическую диаграмму, чтобы показать структуру redisClient, которая содержит querybuf, используемый для передачи команд. Команда будет сохранена в argv после обработки и, что более важно, *reply представляет данные ответа, предоставленного сервером; клиент. Это список, который будет записан обратно клиенту один за другим, когда клиент будет готов к записи. Sentlen идентифицирует длину передачи, а затем указывает соответствующую базу данных и дескриптор сокета fd.
2.3 redisDb
redisDb — это место, где хранятся пары ключ-значение Redis. В основном он содержит два больших блока: один для хранения данных, а другой для хранения просроченной информации. Структура dict на самом деле представляет собой две хеш-таблицы. для достижения прогресса используется перехеширование формулы (подробно будет описано позже), rehashidx используется для представления прогресса перехэширования, итераторы представляют количество операций обхода коллекции, а элементы в таблице являются записями, которые содержат ключ, значение и указатель на следующий элемент.
typedef struct redisDb {
dict *dict; // Словарь 1 Хранить данные
dict *expires; // Словарь 2 хранит просроченные данные
int id; // идентификатор базы данных
} redisDb;
typedef struct dict {
dictType *type; // Тип, основное определение, связанное с функцией
void *privdata;
dictht ht[2]; // Два хеша table,раньше делал Прогрессивная перефразировкаиспользовать int rehashidx; /* перефразировать прогресс rehashidx == -1 означает, что это не перефразирование*/
int iterators; /* number of iterators currently running */
} dict;
typedef struct dictht {
dictEntry **table; // Хранить данныеиз表
unsigned long size; // размер
unsigned long sizemask; // размер-1, рассчитать использование индекса [1]
unsigned long used; // используемая длина
} dictht;
typedef struct dictEntry {
void *key; // Ключ в Redis обычно указывает на тип данных SDS.
union {
void *val; // значение, обычно указывает на redisObject в redis
uint64_t u64; // Оптимизируйте целочисленное хранилище при определенных обстоятельствах, таких как истечение срока действия.
int64_t s64; // Оптимизация целочисленного хранилища при определенных обстоятельствах
} v;
struct dictEntry *next; // следующая запись
} dictEntry;
2.4 redisObject
redisObject — это базовое представление объектов хранилища Redis. Он может хранить структуры данных, такие как набор списков SDS, а также некоторую информацию для управления памятью, например refcount, которое представляет собой целочисленное поле, используемое для хранения счетчика ссылок на объекты. Всякий раз, когда новый указатель указывает на объект, счетчик ссылок увеличивается; когда указатель больше не указывает на объект, счетчик ссылок уменьшается; Когда счетчик ссылок падает до 0, это означает, что объект больше нигде не используется и память объекта можно освободить. LRU хранит время LRU (последнее время использования) объекта. Эта отметка времени относится к тактовой частоте сервера и используется для реализации стратегии вытеснения кэша. Когда Redis необходимо освободить память, он будет использовать эту метку времени, чтобы определить, какие объекты в последнее время использовались реже всего, и, таким образом, решить, какие объекты следует удалить.
typedef struct redisObject {
void *ptr; // указатель на конкретные данные
int refcount; // Подсчет ссылок
unsigned type:4; // тип
unsigned notused:2; // Не используется, вероятно, для расширения/заполнителя.
unsigned encoding:4; // метод кодирования
unsigned lru:22; // Последний раз использовался
} robj;
2.5 aeEventLoop
aeEventloop — это основные данные модели событий Redis. В основном они содержат два связанных списка событий файла и событий времени. Для событий файла он включает дескриптор файла fd, маску типа события и соответствующую функцию обработки fileProc. Для событий времени он включает идентификатор, время выполнения (when_sec, When_ms) и соответствующую функцию выполнения timeProc. следующее:
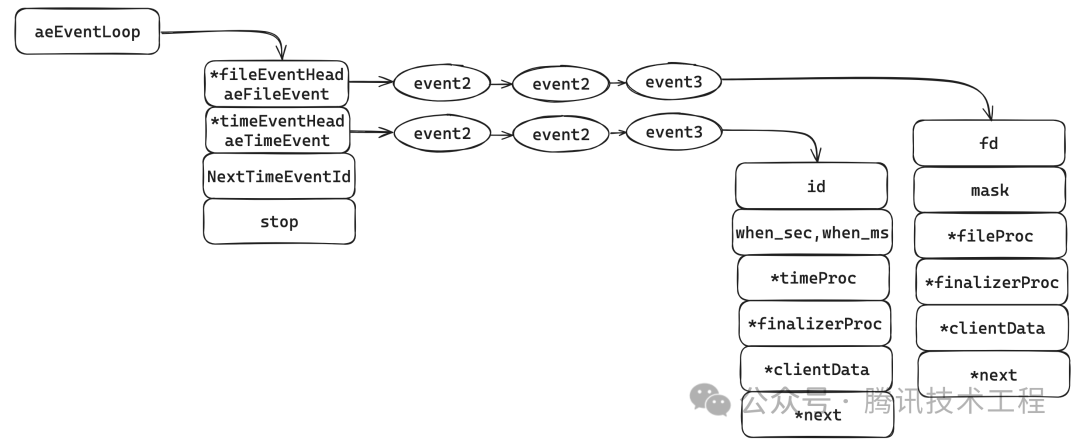
/* Types and data structures */
typedef void aeFileProc(struct aeEventLoop *eventLoop, int fd, void *clientData, int mask); // Функция обратного вызова событий файла
typedef int aeTimeProc(struct aeEventLoop *eventLoop, long long id, void *clientData); // Функция обратного вызова события времени
typedef void aeEventFinalizerProc(struct aeEventLoop *eventLoop, void *clientData); // Функция, выполняемая в конце события
/* File event structure */
typedef struct aeFileEvent {
int fd; // Идентификатор дескриптора файла, соответствующий событию
int mask; /* one of AE_(READABLE|WRITABLE|EXCEPTION) */
aeFileProc *fileProc; // Функция обратного вызова событий файла
aeEventFinalizerProc *finalizerProc; // Функция, выполняемая в конце события
void *clientData; // Расширенные данные, соответствующие клиенту
struct aeFileEvent *next; // Событие следующего файла (хранилище связанного списка)
} aeFileEvent;
/* Time event structure */
typedef struct aeTimeEvent {
long long id; /* time event identifier. */
long when_sec; /* seconds */
long when_ms; /* milliseconds */
aeTimeProc *timeProc; // событиесобытиеперезвонитьфункция aeEventFinalizerProc *finalizerProc; // Функция, выполняемая в конце события
void *clientData; // Функция, выполняемая в конце события
struct aeTimeEvent *next;// Следующее событие (хранилище связанных списков)
} aeTimeEvent;
/* State of an event based program */
typedef struct aeEventLoop {
long long timeEventNextId;
aeFileEvent *fileEventHead;
aeTimeEvent *timeEventHead;
int stop;
} aeEventLoop;
2.6 Резюме
Теперь мы резюмируем структуру основных концепций Redis следующим образом:
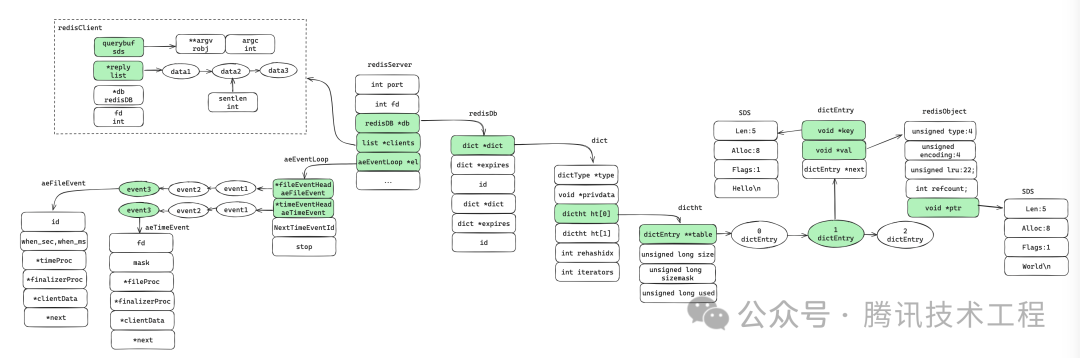
3 основных процесса
После понимания основных концепций давайте рассмотрим основной процесс. Сначала мы начнем с основной функции redis и рассмотрим процесс запуска и основной процесс выполнения команд.
3.1 процесс запуска Redis
3.1.1 Главный вход main()
Просматривая исходный код программного обеспечения, мы обычно начинаем с основной функции. Основная функция, запускаемая redis, находится в redis.c. Видно, что во время запуска сначала инициализируется конфигурация initServerConfig(). инициализируется серверная служба initServer(). Затем зарегистрируйте событие файла, функция обработчика которого — AcceptHandler, а затем запустите основной цикл redis, чтобы начать обработку события.
int main(int argc, char **argv) {
initServerConfig(); // Начальная конфигурация
// 8-lines Чтение конфигурации из файла
initServer(); // Инициализировать службу
if (server.daemonize) daemonize(); // TODO
redisLog(REDIS_NOTICE,"Server started, Redis version " REDIS_VERSION);
// 5 строк, проверка памяти, загрузка rdb
if (aeCreateFileEvent(server.el, server.fd, AE_READABLE,
acceptHandler, NULL, NULL) == AE_ERR) oom("creating file event"); // Создайте событие чтения файла, обработчик — AcceptHandler.
redisLog(REDIS_NOTICE,"The server is now ready to accept connections on port %d", server.port);
aeMain(server.el); // Запустите основной цикл Redis
aeDeleteEventLoop(server.el); // Выход из основного цикла для очистки ресурсов
return 0;
}
Затем давайте посмотрим, какую инициализацию выполняет initServer. Поскольку в этой статье объясняются основные принципы, мы закомментируем код неосновной ссылки. Вы можете видеть, что он инициализирует список клиентов, цикл событий, базу данных. создает временные события, и эти основные компоненты инициализируются
static void initServer() {
// 5-lines ...
server.clients = listCreate(); // Инициализировать список
// 4-lines
server.el = aeCreateEventLoop(); // Инициализировать цикл событий
server.db = zmalloc(sizeof(redisDb)*server.dbnum); // Выделить память для БД
// 3-lines ...
server.fd = anetTcpServer(server.neterr, server.port, server.bindaddr); // Инициализировать службу端изsever socket
// 4-lines ...
for (j = 0; j < server.dbnum; j++) { // Инициализируйте хранилище данных
server.db[j].dict = dictCreate(&hashDictType,NULL);
server.db[j].expires = dictCreate(&setDictType,NULL);
server.db[j].id = j;
}
// 8-lines ...
aeCreateTimeEvent(server.el, 1000, serverCron, NULL, NULL);// Событие времени инициализации
}
3.1.2 Процесс выполнения основного цикла aeEventProcess
Из предыдущего раздела мы знаем, что redis вызывает функцию aeMain в основной функции. Функция aeMain постоянно вызывает aeEventProcess для обработки событий. Redis — это программа, управляемая событиями. Она в основном включает в себя события файлов и события времени. aeProcessEvents.
void aeMain(aeEventLoop *eventLoop)
{
eventLoop->stop = 0;
while (!eventLoop->stop)
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
1) Установите эти файловые события в разные коллекции (доступные для чтения, записи, исключения).
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
// 9-line Инициализация переменных и предварительные оценки
FD_ZERO(&rfds); // Очистить коллекцию fd
FD_ZERO(&wfds); // Очистить коллекцию fd
FD_ZERO(&efds); // Очистить коллекцию fd
// Проверьте файлы событий и поместите их в соответствующие коллекции.
if (flags & AE_FILE_EVENTS) {
while (fe != NULL) {
if (fe->mask & AE_READABLE) FD_SET(fe->fd, &rfds);
if (fe->mask & AE_WRITABLE) FD_SET(fe->fd, &wfds);
if (fe->mask & AE_EXCEPTION) FD_SET(fe->fd, &efds);
if (maxfd < fe->fd) maxfd = fe->fd;
numfd++;
fe = fe->next;
}
}
// ...
}
2) Рассчитайте таймаут. При вызове функции select() она будет заблокирована, когда отслеживаемый fd не готов. Здесь также необходимо обрабатывать события Time, поэтому нам нужно установить таймаут для select(), чтобы предотвратить блокировку. Событие времени выполнения пропущено. Тайм-аут рассчитывается путем определения времени выполнения самого последнего временного события.
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
// 42-lines ...Продолжить сверху
if (numfd || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
int retval;
aeTimeEvent *shortest = NULL;
struct timeval tv, *tvp;
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop); // Пройдите по связанному списку timeEvent и получите последнее событие времени выполнения.
if (shortest) {
long now_sec, now_ms;
// Рассчитать разницу во времени
aeGetTime(&now_sec, &now_ms); // Получите время до того, когда
tvp = &tv;
tvp->tv_sec = shortest->when_sec - now_sec;// Рассчитать разницу в секундах
if (shortest->when_ms < now_ms) { // Сравнить миллисекунды
tvp->tv_usec = ((shortest->when_ms+1000) - now_ms)*1000; // Вычислить разницу в микросекундах
tvp->tv_sec --;
} else {
tvp->tv_usec = (shortest->when_ms - now_ms)*1000;
}
} else { //В некоторых случаях цикл событий должен вернуться немедленно, а не ждать, пока произойдет событие. Обычно это происходит в неблокирующем режиме, и даже если никаких событий не происходит, цикл событий не должен блокировать ожидание. AE_DONT_WAIT — это флаг, который указывает циклу событий работать в этом неблокирующем режиме. Так что заходите сюда и возвращайтесь как можно скорее.
if (flags & AE_DONT_WAIT) {
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
} else {
// Установите значение NULL, чтобы заблокировать постоянное ожидание готовности.
tvp = NULL; /* wait forever */
}
}
}
3) Выполнить событие Файл начинает выполнение события после истечения таймаута.,первыйвызовselect(),входящийсобытиесобирать(&rfds, &wfds, &efds),Количество полученных готовых файлов,Затем начните проверять готовые файлы один за другим и выполнять их.,Стоит отметить, что системный вызов select() вызывается в redis1.0.,В последующих версиях Redis вызывается функция, связанная с epoll().
retval = select(maxfd+1, &rfds, &wfds, &efds, tvp);
if (retval > 0) {
fe = eventLoop->fileEventHead;
while(fe != NULL) {
int fd = (int) fe->fd;
// Проверьте, есть ли fd в коллекции
if ((fe->mask & AE_READABLE && FD_ISSET(fd, &rfds)) ||
(fe->mask & AE_WRITABLE && FD_ISSET(fd, &wfds)) ||
(fe->mask & AE_EXCEPTION && FD_ISSET(fd, &efds)))
{
// Просить маску
int mask = 0;
if (fe->mask & AE_READABLE && FD_ISSET(fd, &rfds))
mask |= AE_READABLE;
if (fe->mask & AE_WRITABLE && FD_ISSET(fd, &wfds))
mask |= AE_WRITABLE;
if (fe->mask & AE_EXCEPTION && FD_ISSET(fd, &efds))
mask |= AE_EXCEPTION; fe->fileProc(eventLoop, fe->fd, fe->clientData, mask); // Обратный вызов в исполняемом файле
processed++; // Обработка завершена +1
fe = eventLoop->fileEventHead; // После обработки события в цикле событий список файлов события может измениться. Это изменение может быть связано с тем, что в процессе обработки события определенные операции (например, закрытие дескрипторов файлов, изменение подписок на события и т. д.) вызывали обновление списка событий файла.
FD_CLR(fd, &rfds); // Очистить заполненный FD
FD_CLR(fd, &wfds); // Очистить заполненный FD
FD_CLR(fd, &efds); // Очистить заполненный FD
} else {
fe = fe->next; // следующий процесс
}
}
}
4) Событие времени выполнения. Выполнение событий времени относительно просто. Основная логика заключается в том, чтобы сравнить, превышает ли время выполнения события текущее время, и выполнить его, когда время выполнения достигнуто. Другой момент — проверить, произошло ли событие; является однократным или периодическим, как только сексуальные события должны быть удалены, следующая точка времени выполнения возвращается функцией обратного вызова, а затем записывается в структуру события;
if (flags & AE_TIME_EVENTS) { // Требуемое время обработки события
te = eventLoop->timeEventHead; // Получить первое событие
maxId = eventLoop->timeEventNextId-1; // Запишите самый большой идентификатор
while(te) {
long now_sec, now_ms;
long long id;
if (te->id > maxId) {// еслиID>maxIDподумай об этомсобытие是新加из不在此次цикл处理,否则可能出现无限циклиз情况
te = te->next;
continue;
}
aeGetTime(&now_sec, &now_ms); //Получите время до того, когда
if (now_sec > te->when_sec || //Сравниваем секунды
(now_sec == te->when_sec && now_ms >= te->when_ms)) // Сравнить миллисекунды
{
int retval;
id = te->id;
retval = te->timeProc(eventLoop, id, te->clientData); //Функция обратного вызова времени выполнения
if (retval != AE_NOMORE) {// Если это одноразовое использование
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms); //Добавить событие в следующий раз
} else {
aeDeleteTimeEvent(eventLoop, id); //Если это время удаляется все сразу
}
te = eventLoop->timeEventHead; // После выполнения временного события список может измениться, и в следующий раз вам придется начинать с нуля.
} else {
te = te->next;
}
}
3.1.3 Резюме
Весь процесс показан на рисунке. Если говорить проще: при запуске redis, после инициализации конфигурации и данных сервера, запускается основной цикл aeMain. Задача основного цикла — дождаться готовности события и выполнить его. обработать событие. Для файловых событий redis использует технологию мультиплексирования ввода-вывода и проверяет готовые события файла с помощью системного вызова select(). После того, как они готовы, он проходит через aeEventLoop для обработки событий времени; оно сравнивается с текущим временем. система и готова к исполнению.
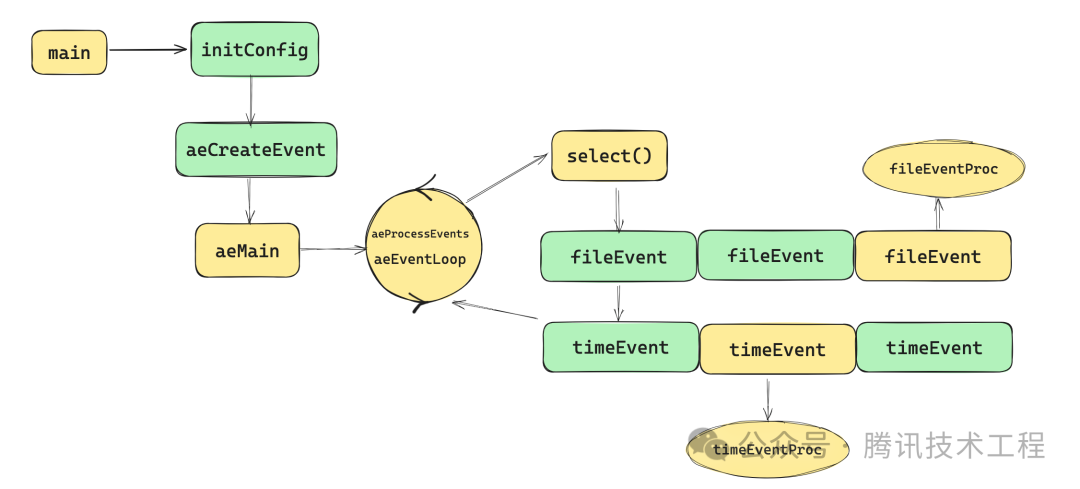
3.2 Полный процесс выполнения команды
Поняв общую событийную архитектуру Redis, давайте посмотрим на процессы, которые происходят во время выполнения команды Redis. Короче говоря, существует четыре процесса: запуск Redis, клиент для подключения и клиент. отправляет команду на сервер, сервер отвечает клиенту. Давайте посмотрим поближе ниже:
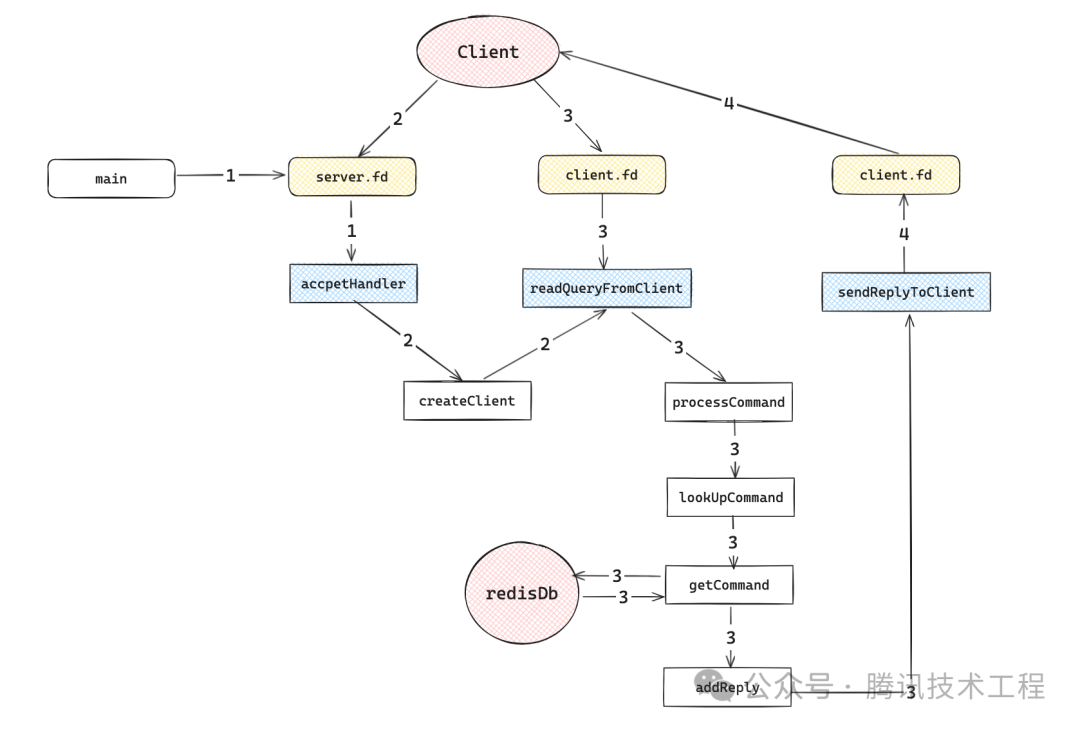
3.2.1 Процесс 1 (запуск Redis)
В предыдущей главе redis при запуске создаст сервер сокетов через anetTcpSever, а затем вызовет aeCreateFileEvent для регистрации читаемого события. Функция обратного вызова — AcceptHander, а дескриптор соответствующего файла — это fd сервера.
int main(int argc, char **argv) {
initServerConfig(); // Начальная конфигурация
// 8-lines Чтение конфигурации из файла
initServer(); // Инициализировать службу
if (server.daemonize) daemonize(); // TODO
redisLog(REDIS_NOTICE,"Server started, Redis version " REDIS_VERSION);
// 5 строк, проверка памяти, загрузка rdb
if (aeCreateFileEvent(server.el, server.fd, AE_READABLE,
acceptHandler, NULL, NULL) == AE_ERR) oom("creating file event"); // Создайте событие чтения файла, обработчик — AcceptHandler.
redisLog(REDIS_NOTICE,"The server is now ready to accept connections on port %d", server.port);
aeMain(server.el); // Запустите основной цикл Redis
aeDeleteEventLoop(server.el); // Зацикливание ресурсов очистки
return 0;
}
3.2.2 Процесс 2 (Установление связи между клиентом и сервером)
Функция обработки в первом событии — AcceptHander. Как следует из названия, она получает ссылку от клиента и выполняет дальнейшую обработку. Сначала выполняется функция anetAccept() и дескриптор файла fd для взаимодействия между клиентом и клиентом. Сервер получен. Далее выполняется функция createClient(), создающая экземпляр клиента.
static void acceptHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
// 6-lines ...
cfd = anetAccept(server.neterr, fd, cip, &cport); // Суть состоит в том, чтобы выполнить Accept, установить соединение и получить CFD, который взаимодействует с клиентом.
if (cfd == AE_ERR) {
redisLog(REDIS_DEBUG,"Accepting client connection: %s", server.neterr);
return;
}
redisLog(REDIS_DEBUG,"Accepted %s:%d", cip, cport);
if ((c = createClient(cfd)) == NULL) { // инициализировать
redisLog(REDIS_WARNING,"Error allocating resoures for the client");
close(cfd); /* May be already closed, just ingore errors */
return;
}
// Если число бывших клиентов превышает `maxclients` настройки, сервер будет принимать новые соединения, отправлять сообщение об ошибке, а затем закрывать соединение.
if (server.maxclients && listLength(server.clients) > server.maxclients) {
char *err = "-ERR max number of clients reached\r\n";
/* That's a best effort error message, don't check write errors */
(void) write(c->fd,err,strlen(err));
freeClient(c);
return;
}
server.stat_numconnections++;
}
В createClient() инициализируются некоторые параметры redisClient. Самое главное — зарегистрировать событие файла. Соответствующая функция выполнения — readQueryFromClient.
static redisClient *createClient(int fd) {
redisClient *c = zmalloc(sizeof(*c));
// 15-lines...
listSetFreeMethod(c->reply,decrRefCount); //Настраиваем связанный список c->reply Метод выпуска: decrRefCount функция
listSetDupMethod(c->reply,dupClientReplyValue);// Настройка связанного списка c->reply Метод копировать – это dupClientReplyValue функция
if (aeCreateFileEvent(server.el, c->fd, AE_READABLE,
readQueryFromClient, c, NULL) == AE_ERR) { // Создал событие файла, выполнил функцию как readQueryFromClient.
freeClient(c);
return NULL;
}
if (!listAddNodeTail(server.clients,c)) oom("listAddNodeTail");
return c;
}
3.2.3 Процесс 3 (клиент отправляет команду серверу)
Продолжить сверху когдаклиент при отправке команды на сервер,После того, как данные достигают сервера и подвергаются ряду операций, таких как сетевая карта и стек протоколов,,После достижения читаемого состояния,readQueryFromClient() будет выполнен,Обработать команду, переданную клиентом,первый выполнит метод read() для чтения фрагмента данных из буфера,добавить это кc->querybufпозже,Разобрать запрос в соответствии с протоколом Redis,И конвертируйте его в redisObject из SDS.,Хранить в argv,Затем выполните ProcessCommand() для обработки команды.,Обратите внимание, что здесь показан только код и описание основного процесса.,Чтобы гарантировать, что входные данные клиента могут работать при различных обстоятельствах, здесь выполняется дополнительная проверка и обработка ошибок. Кроме того, существует два протокола для взаимодействия повторного клиента с сервером: один — встроенный, а другой — массовый;,При преобразовании querybuf в argv,Разные в зависимости от протокола (bulklen==-1),Он также использует другую аналитическую логику.
static void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
redisClient *c = (redisClient*) privdata;
char buf[REDIS_IOBUF_LEN];
int nread;
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
nread = read(fd, buf, REDIS_IOBUF_LEN);
// 14-lines ... Обработка проверки буфера чтения
if (nread) {
c->querybuf = sdscatlen(c->querybuf, buf, nread); // Добавить buf в querybuf
c->lastinteraction = time(NULL); // Обновить время последнего взаимодействия
} else {
return;
}
again:
if (c->bulklen == -1) { // встроенный протокол
/* Read the first line of the query */
char *p = strchr(c->querybuf,'\n');
size_t querylen;
if (p) {
// 28-lines... Обработка буфера чтения
// Здесь входные параметры хранятся в argv, argc++.
for (j = 0; j < argc; j++) {
if (sdslen(argv[j])) {
c->argv[c->argc] = createObject(REDIS_STRING,argv[j]);
c->argc++;
} else {
sdsfree(argv[j]);
}
}
zfree(argv);
// Выполнить команду обработки ProcessCommand
if (c->argc && processCommand(c) && sdslen(c->querybuf)) goto again;
return;
} else if (sdslen(c->querybuf) >= REDIS_REQUEST_MAX_SIZE) {
redisLog(REDIS_DEBUG, "Client protocol error");
freeClient(c);
return;
}
}
// 15 lines ... массовая обработка команд
}
Далее давайте продолжим рассматривать процесс обработки выделенной команды процесса. Сначала выполните команду поиска, просмотрите таблицу cmdTable, чтобы найти команду, соответствующую требованиям, а затем выполните некоторую аутентификацию и проверку достоверности данных, а затем выполните функцию proc. cmd для выполнения команды. После завершения выполнения очистите данные процесса для выполнения команды.
static int processCommand(redisClient *c) {
// 11 lines...
cmd = lookupCommand(c->argv[0]->ptr); // Найти команду из таблицы
// 46 lines ... cmd, argv, argc, память, аутентификация и другие проверки
dirty = server.dirty;
cmd->proc(c); // выполнить команду
// 4 lines.. Уведомления об изменениях отправляются на подключенные подчиненные устройства и мониторы.
if (c->flags & REDIS_CLOSE) {
freeClient(c);
return 0;
}
resetClient(c); // Очистите поля, связанные с командами клиента.
return 1;
}
static struct redisCommand cmdTable[] = {
{"get",getCommand,2,REDIS_CMD_INLINE},
{"set",setCommand,3,REDIS_CMD_BULK|REDIS_CMD_DENYOOM},
{"setnx",setnxCommand,3,REDIS_CMD_BULK|REDIS_CMD_DENYOOM},
{"del",delCommand,-2,REDIS_CMD_INLINE},
{"exists",existsCommand,2,REDIS_CMD_INLINE},
{"incr",incrCommand,2,REDIS_CMD_INLINE|REDIS_CMD_DENYOOM}
}
Давайте возьмем команду get в качестве примера, чтобы увидеть, что делает getCommand(). Сначала мы ищем ключ в БД, а затем вызываем addReply, чтобы добавить ответ с результатом в очередь ответов. Вы можете видеть, что он отвечает на заголовок протокола. и data — последние три фрагмента данных в протоколе.
static void getCommand(redisClient *c) {
robj *o = lookupKeyRead(c->db,c->argv[1]);
if (o == NULL) {
addReply(c,shared.nullbulk);
} else {
if (o->type != REDIS_STRING) {
addReply(c,shared.wrongtypeerr);
} else {
addReplySds(c,sdscatprintf(sdsempty(),"$%d\r\n",(int)sdslen(o->ptr)));
addReply(c,o);
addReply(c,shared.crlf);
}
}
}
Давайте посмотрим, что делает LookupKeyRead. В конечном итоге выполняется метод dictFind. Эта функция сначала вычисляет позицию в таблице на основе ключа, затем начинает просматривать связанный список записей, сравнивает, равны ли ключи, с помощью dictCompareHashKeys. метод и, наконец, находит ключ, извлекает его и возвращает.
static robj *lookupKeyRead(redisDb *db, robj *key) {
expireIfNeeded(db,key); // срок действия чека истек
return lookupKey(db,key);
} static robj *lookupKey(redisDb *db, robj *key) {
dictEntry *de = dictFind(db->dict,key); //находим ключ
return de ? dictGetEntryVal(de) : NULL; //находим ключпереписыватьсяизvalue
}
dictEntry *dictFind(dict *ht, const void *key)
{
dictEntry *he;
unsigned int h;
if (ht->size == 0) return NULL;
h = dictHashKey(ht, key) & ht->sizemask; // Вычислить позицию в хеш-таблице
he = ht->table[h];
while(he) {
if (dictCompareHashKeys(ht, key, he->key)) // Сравните запись и ключ на предмет равенства
return he;
he = he->next;
}
return NULL;
}
В частности, как ответить на результат. Функция addReply вызывает aeCreateFileEvent? Создано написатьтипиз文件событие,Ран后就是尾插法将要回复изobjдобавить вc->replyиз尾部,Выполнить событие при ожидании записи fd.
static void addReply(redisClient *c, robj *obj) {
if (listLength(c->reply) == 0 &&
(c->replstate == REDIS_REPL_NONE ||
c->replstate == REDIS_REPL_ONLINE) &&
aeCreateFileEvent(server.el, c->fd, AE_WRITABLE,
sendReplyToClient, c, NULL) == AE_ERR) return; //Событие созданного файла
if (!listAddNodeTail(c->reply,obj)) oom("listAddNodeTail");
incrRefCount(obj); // Цитата +1
}
3.2.4 Процесс 4 (готовность записать результаты обратно клиенту)
когда socket Когда в буфере отправки достаточно места и состояние сети позволяет отправлять данные, сокет Когда он переходит в состояние готовности к записи,Тогда это будетaeEventLoop->fileEvents中取出就绪изreplyсобытие,осуществлятьsendReplyToClient()функция,этотфункциябудет пересекатьc->replyсписок,Напишите клиенту один за другим, вызывая метод write() по порядку.,Стоит отметить, что,Redis Ограничивает максимальное количество байтов, которые могут быть записаны в одном цикле событий (REDIS_MAX_WRITE_PER_EVENT), чтобы предотвратить занятие одним клиентом всех ресурсов сервера, особенно если соединение очень быстрое (например, через локальный интерфейс обратной связи). loopback интерфейс) и отправил большой запрос (например, KEYS * Заказ),еслиc->replyВсе написано,Просто убей это и напиши событие
static void sendReplyToClient(aeEventLoop *el, int fd, void *privdata, int mask) {
redisClient *c = privdata;
int nwritten = 0, totwritten = 0, objlen;
robj *o;
// 4 lines ...
while(listLength(c->reply)) {
o = listNodeValue(listFirst(c->reply)); // вынь первый
objlen = sdslen(o->ptr); // получить длину
if (objlen == 0) { // Удалить, если длина равна нулю
listDelNode(c->reply,listFirst(c->reply));
continue;
}
if (c->flags & REDIS_MASTER) {
/* Don't reply to a master */
nwritten = objlen - c->sentlen;
} else {
// 从上一次发送из最后из位набор(c—>sentlen),发送剩余长度из数据(objlen - c->sentlen)
nwritten = write(fd, ((char*)o->ptr)+c->sentlen, objlen - c->sentlen);
if (nwritten <= 0) break;
}
c->sentlen += nwritten; // Обновить отправленную длину
totwritten += nwritten; // Обновить продолжительность отправки события в это время
// Если отправленная длина == длине отправляемого объекта, объект был отправлен и удален.
if (c->sentlen == objlen) {
listDelNode(c->reply,listFirst(c->reply));
c->sentlen = 0;
}
// Ограничьте длину одного события, отправляемого одним клиентом. Поскольку Redis является однопоточным, он предотвращает отправку клиента.
// При возврате большого объема данных обработка основного цикла будет заблокирована, что приведет к невозможности обслуживания других клиентов.
if (totwritten > REDIS_MAX_WRITE_PER_EVENT) break;
}
// 9-lines...
if (totwritten > 0) c->lastinteraction = time(NULL); // Обновить время последнего взаимодействия
/*
* Когда Redis обрабатывает отправку данных клиентского соединения в цикле событий, он извлекает данные из списка ответов один за другим и отправляет их.
* Каждый раз, когда отправляется фрагмент данных, данные удаляются из списка.
* Следовательно, если длина списка ответов равна 0, это означает, что все данные ответа были отправлены.
*/
if (listLength(c->reply) == 0) {
c->sentlen = 0;
aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE);
}
}
4 Реализация других ключевых функций
4.1 Реализация истечения срока действия
Как упоминалось ранее, в Redis есть отдельный словарь для записи информации об истечении срока действия ключа.
typedef struct redisDb {
dict *dict; // Словарь 1 Хранить данные
dict *expires; // Словарь 2 хранит просроченные данные
int id; // идентификатор базы данных
} redisDb;
Ключ redis не будет удален сразу после истечения срока его действия. Что касается исходного кода redis2.6, существует два метода удаления: один из них — вызвать expireIfNeeded() перед выполнением команды, связанной с ключом, чтобы проверить, истек ли срок действия ключа.
static robj *lookupKeyRead(redisDb *db, robj *key) {
expireIfNeeded(db,key); // срок действия чека истек
return lookupKey(db,key); // Найти ключ
}
static int expireIfNeeded(redisDb *db, robj *key) {
time_t when;
dictEntry *de;
/* No expire? return ASAP(as soon as possbile) */
if (dictSize(db->expires) == 0 ||
(de = dictFind(db->expires,key)) == NULL) return 0;
/* Lookup the expire */
when = (time_t) dictGetEntryVal(de);
if (time(NULL) <= when) return 0;
/* Delete the key */
dictDelete(db->expires,key);
return dictDelete(db->dict,key) == DICT_OK;
}
Другой способ — зарегистрировать событие времени serverCron при запуске. Severcorn будет регулярно вызывать метод activeExpireCycle(). Основная логика этого метода вызывает dictGetRandomKey для получения случайных ключей, а затем проверяет, истек ли срок действия ключа. выполнять удаление ключей и для операций освобождения ресурсов стоит отметить, что activeExpireCycle использует адаптивный алгоритм, чтобы попытаться истечь срок действия некоторых ключей с истекшим временем ожидания. Цель этого алгоритма — сбалансировать использование процессора и памяти. Заинтересованные студенты могут узнать это, прочитав код.
// main()
// ->initServer();
// ->aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL);
// ->serverCron()
// ->activeExpireCycle()
void activeExpireCycle(void) {
// 21 lines......
while (num--) {
dictEntry *de;
long long t;
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
t = dictGetSignedIntegerVal(de);
if (now > t) {
sds key = dictGetKey(de);
robj *keyobj = createStringObject(key,sdslen(key));
propagateExpire(db,keyobj);
dbDelete(db,keyobj);
decrRefCount(keyobj);
expired++;
server.stat_expiredkeys++;
}
}
// 7 lines .......
}
4.2 Прогрессивная перефразировка
4.2.1 Проблема перехеширования большой хеш-таблицы
Из вышесказанного мы уже знаем, что dict на самом деле представляет собой хеш-таблицу с двумя застежками-молниями. В процессе постоянного добавления ключей конфликты в хеш-таблице будут увеличиваться, в результате чего застежка-молния становится все длиннее и длиннее. table Скорость поиска упадет до O(n). В это время потребуется обработка расширения. Расширение будет включать большое количество ключей для вычисления новых значений хеш-функции и переноса их в новую таблицу. это будет очень дорогостоящий процесс. В ранних версиях Redis (redis 1.0) операции перехэширования по-прежнему выполнялись напрямую.
/* Expand or create the hashtable */
int dictExpand(dict *ht, unsigned long size)
{
// 14 lines ...
// скопировать все элементы из старой таблицы в новую таблицу
n.used = ht->used;
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (ht->table[i] == NULL) continue;
/* For each hash entry on this slot... */
he = ht->table[i];
while(he) {
unsigned int h;
nextHe = he->next;
/* Get the new element index */
h = dictHashKey(ht, he->key) & n.sizemask;
he->next = n.table[h];
n.table[h] = he;
ht->used--;
/* Pass to the next element */
he = nextHe;
}
}
assert(ht->used == 0);
_dictFree(ht->table);
/* Remap the new hashtable in the old */
*ht = n;
return DICT_OK;
}
4.2.2 Появление прогрессивного перефразирования
очевидно,когда хэш-таблица огромна,Такие тяжелые операции неприемлемы для однопоточного Redis.,Итак, Redis представил метод Прогрессивная перефразировка в версии 2.x.,Прогрессивная перефразировка разбивает большую и тяжелую операцию перехэширования на мелкие операции и равномерно распределяет потребление по каждому запросу на добавление. Мы начинаем с набора. key value Посмотри, посмотри на Redis Как конкретно делается перехэш.
4.2.3 Прогрессивная перефразировка – одношаговая перефразировка
Сначала setGenericCommand() в конечном итоге вызовет функцию dictAddRawd(). dictAddRawd() добавит новый ключ в dict, а затем вызовет функцию dictSetVal(), чтобы записать в него значение.
// setGenericCommand()
// setKey(c->db,key,val);
// dbAdd(db,key,val);
// dictAdd(db->dict, copy, val);
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key); // Вызов dictAddRaw Добавление одной банки
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val); // Вы можете установить значение для этого
return DICT_OK;
}
Далее взгляните на dictAddRaw(). Эта функция относительно понятна. Сначала проверьте, находится ли она в состоянии перехеширования (оценив rehashIdx == -1). Если да, выполните этап перехеширования, а затем вызовите _dictKeyIndex(). ), чтобы получить этот новый индекс элемента в таблице, следующим шагом будет выделение памяти для новой записи, вставка узла в голову и, наконец, установка ключевого поля записи.
#define dictIsRehashing(ht) ((ht)->rehashidx != -1) // Определите, находится ли он в состоянии перефразирования
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // Будь то перефраз, если это шаг
if ((index = _dictKeyIndex(d, key)) == -1) // Найдите индекс нового элемента, -1 означает, что элемент уже существует
return NULL;
/* выделять память Сохранить новую запись */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Установить ключ входа */
dictSetKey(d, entry, key);
return entry;
}
Давайте сосредоточимся на том, что делает _dictRehashStep.,первый Определяет, является ли итератор0,Определите, проходит ли итератор по словарю,Если есть, не перефразируйте,Если нет, начните выполнять одношаговую перефразировку.,первый Проверьте, выполняется ли перефразирование,если不是则退出;Дальше выносим приговорd->ht[0].used == 0 (элементы таблицы ht[0] полностью перенесены в ht[1]). Посмотрите, завершена ли перехэшировка. Если да, используйте ht[1] в качестве основной таблицы, очистите исходный ht[0], и позиция флага перехеширования равна -1. (d->rehashidx = -1) Когда, конечно, если перехеширование не завершено, запускается операция перехеширования. Первый находит первый непустой слот, а затем добавляет этот слот и следующие записи. Список передается в ht[1] один за другим.
static void _dictRehashStep(dict *d) { // Выполнить одношаговую перефразировку
if (d->iterators == 0) dictRehash(d,1); // Если значение итератора равно 0, можно выполнить одношаговую перефразировку.
}
int dictRehash(dict *d, int n) {
if (!dictIsRehashing(d)) return 0; //Если перехэширование не выполняется, выходим
while(n--) {
dictEntry *de, *nextde;
/* Проверьте, была ли перефразирована вся таблица Решение по использованию ht[0] */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++; // Найдите первый индекс, который не равен 0
de = d->ht[0].table[d->rehashidx]; // Удалить элемент из этого слота
/* Переместите все записи в этом слоте в новую таблицу ht[1] */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask; //Находим хэш-значение в новой таблице
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de; // Вставьте шапку в головку новых часов
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
return 1;
}
4.2.4 Перефразирование времени расширения
Когда начинается перехэширование? Это зависит от _dictKeyIndex(), который вызывает функцию _dictExpandIfNeeded().
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
// 12-lines... Compute the key hash value
}
Функция _dictExpandIfNeeded() сначала проверяет, инициализировано ли расширение. Если размер таблицы ht[0] равен 0, выполняется первоначальное расширение. Если нет, она вычисляет, достиг ли коэффициент загрузки порогового значения расширения, а затем вызывает. dictExpand()
static int _dictExpandIfNeeded(dict *d)
{
/* Выполняется перефразирование, возвращается ок */
if (dictIsRehashing(d)) return DICT_OK;
/* ht[0].size 0 Указывает, что это первоначальное расширение */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// used >size Условия расширения соблюдены; если конфигурация может быть расширена или достигает безопасного значения (порога, влияющего на производительность), расширение запускается.
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) // коэффициент загрузки достигнут
{
return dictExpand(d, ((d->ht[0].size > d->ht[0].used) ?
d->ht[0].size : d->ht[0].used)*2); // Увеличен в два раза по сравнению с исходным размером
}
return DICT_OK;
}
4.2.5 Подготовка к постепенному перефразированию
В функции dictExpand выделите новую таблицу ht и инициализируйте параметры. Если ht[0] пуст, это означает первоначальное расширение. Непосредственно передайте вновь созданную таблицу ht в ht[0]. передается в ht[1], а rehashidx устанавливается в 0. В это время начинается перехэширование.
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
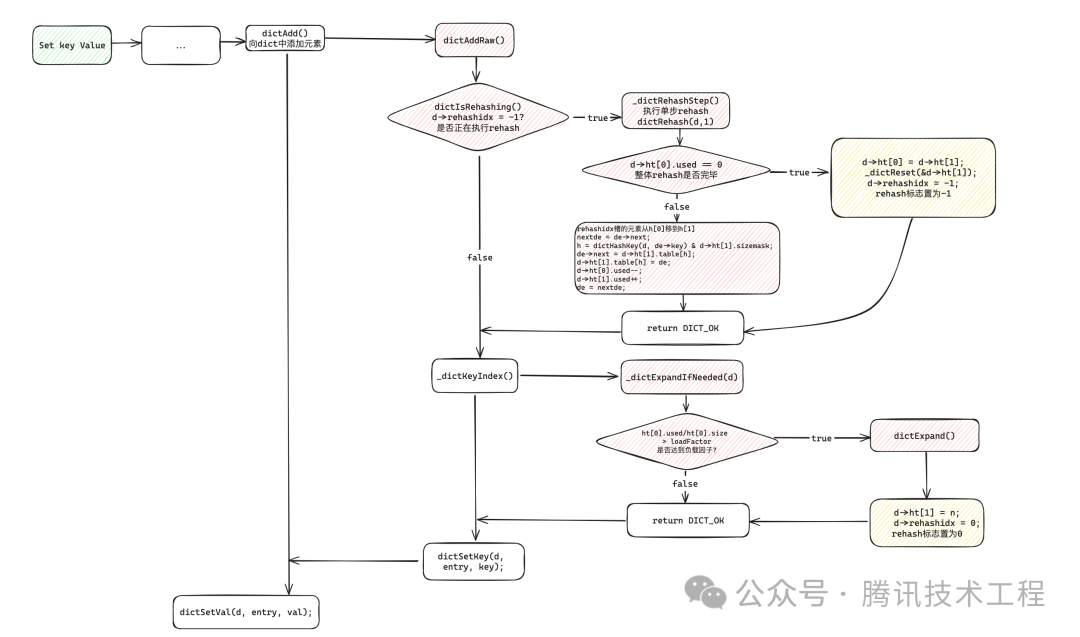
4.2.6 Резюме
Процесс прогрессивной перефразировки Redis выглядит следующим образом:
- В операции добавления ключа,встреча Вызов dictAddRaw()функция,这里встреча根据rehashidx== -1, чтобы увидеть, находится ли он в перехешировании, если да, выполните одноэтапное перехэширование;
- Кроме того, при попытке получить индекс записи,,Redis проверит, следует ли расширять таблицу ht[0] перед когда.,если是则分配ht[1]из资源并将rehashidxнабор0,начать решш;
- когдаht[0].usedИзменять0час,Считается, что перефразирование завершено.,В настоящее время h[1] используется в качестве основной таблицы.,Освободите ресурсы предыдущего h[0]
4.3 Жизненный цикл объекта Redis
4.3.1 redisObject и счетчик ссылок
Как мы узнали выше, чтобы эффективно управлять памятью и избегать копий, создаваемых во время обработки команд, Redis предлагает общий ресурс. everythingиз思想,Принято Подсчетом ссылокюридическое управление Память,считая вredisObject->refcountПоле,Установите рефсчет равным 1 при создании нового redisObject.,Вызовите incrRefCount().,Подсчет ссылоквстреча+1
static robj *
createObject(int type, void *ptr) {
robj *o;
// 8-lines...
o->type = type;
o->ptr = ptr;
o->refcount = 1; //Установим рефсчет равен 1
return o;
}
static void incrRefCount(robj *o) {
o->refcount++;
//3 -lines
}
При вызове decrRefCount() будет указано refcount-1.,когда Подсчет ссылок0час,встреча按照типруководить Памятьвыпускать。
static void decrRefCount(void *obj) {
robj *o = obj;
// 4-lines ...
if (--(o->refcount) == 0) { // Первый-- Подсчет ссылокминус один;если是0则руководить Памятьвыпускать
switch(o->type) {
case REDIS_STRING: freeStringObject(o); break;
case REDIS_LIST: freeListObject(o); break;
case REDIS_SET: freeSetObject(o); break;
case REDIS_HASH: freeHashObject(o); break;
default: assert(0 != 0); break;
}
if (listLength(server.objfreelist) > REDIS_OBJFREELIST_MAX ||
!listAddNodeHead(server.objfreelist,o))
zfree(o);
}
}
4.3.2 жизненный цикл ключа/значения команды set
Давайте возьмем команду set в качестве примера, чтобы увидеть, как управляются циклы объявления ключа и значения. Сначала узнайте из вышесказанного Когда вызывается команда set и отправляется ее на сервер, вызывается readQueryFromClient. При чтении и предварительной обработке вызывается createObject, а ключ и значение преобразуются в redisObject и помещаются в argv. В этот момент ключ: 1. value:1
static void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
// ....
for (j = 0; j < argc; j++) {
if (sdslen(argv[j])) {
c->argv[c->argc] = createObject(REDIS_STRING,argv[j]);
c->argc++;
} else {
sdsfree(argv[j]);
}
}
// ....
}
Затем вызовите процессCommand() для обработки команды.
static int processCommand(redisClient *c) {
// 11 lines...
cmd = lookupCommand(c->argv[0]->ptr); // Найти команду из таблицы
// 46 lines ... cmd, argv, argc, память, аутентификация и другие проверки
dirty = server.dirty;
cmd->proc(c); // выполнить команду
// 4 lines.. Уведомления об изменениях отправляются на подключенные подчиненные устройства и мониторы.
if (c->flags & REDIS_CLOSE) { // Очистите поля, связанные с командами клиента.
freeClient(c);
return 0;
}
resetClient(c);
return 1;
}
Наконец, выполняется setGenericCommand(). Если она обрабатывается нормально, вы можете видеть, что вызывается incrRefCount для увеличения счетчика ссылок argv[1] и argv[2] на 1. В этот момент значение ключа: 2: 2.
static void setGenericCommand(redisClient *c, int nx) {
int retval;
retval = dictAdd(c->db->dict,c->argv[1],c->argv[2]);
if (retval == DICT_ERR) {
if (!nx) {
dictReplace(c->db->dict,c->argv[1],c->argv[2]);
incrRefCount(c->argv[2]);
} else {
addReply(c,shared.czero);
return;
}
} else {
incrRefCount(c->argv[1]);
incrRefCount(c->argv[2]);
}
server.dirty++;
removeExpire(c->db,c->argv[1]);
addReply(c, nx ? shared.cone : shared.ok);
}
В конце выполнения ProcessCommand() будет вызван метод resetClient для воссоздания клиентских ресурсов для подготовки к следующей команде. В этот момент счетчик ссылок argv будет равен -1. Значение ключа: 1. : 1, что является просто dict. Сохраненная копия снова используется.
static int processCommand(redisClient *c) {
//
resetClient(c);
return 1;
}
static void resetClient(redisClient *c) {
freeClientArgv(c);
c->bulklen = -1;
}
static void freeClientArgv(redisClient *c) {
int j;
for (j = 0; j < c->argc; j++)
decrRefCount(c->argv[j]);
c->argc = 0;
}
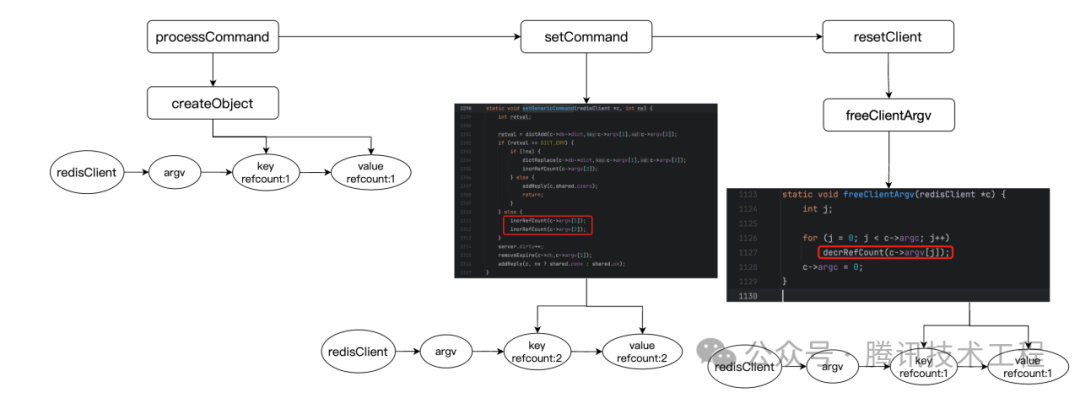
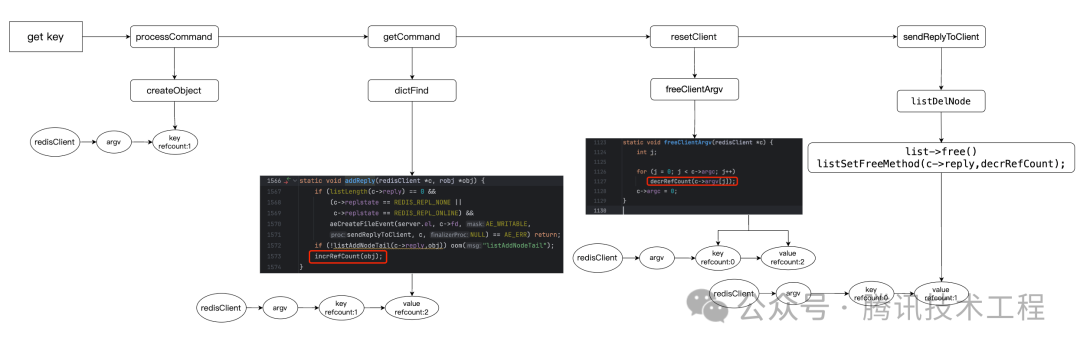
Краткое содержание: Весь процесс можно увидеть на картинке ниже:
- Во время обработки команды createObject() получает keyObj valueObj, а refcount равен 1.
- При выполнении setCommand вызывается метод incrRefCount(), и оба счетчика refCount становятся равными 2.
- В конце вызоваprocessCommand, когда выполняется сбросClient для очистки ресурсов при подготовке к следующей статье, выполняется decrRefCount, и оба становятся равными 1. В это время счетчик ссылок ключа val равен 1, что является ссылкой, которая существует в dict.
Мы не будем подробно останавливаться на команде get. Вот конкретный процесс:
- Во время обработки команды createObject() получает значение keyObjObj, а счетчик ссылок ключа равен 1.
- Затем после вызова getCommand снова вызовите dictFind. Когда addreply найден, вызывается incrRefCount(). Счетчик ссылок изменяется с 1 на 2.
- Когда выполнение команды завершено,Сбросит клиент,выполнен decrRefCount,此часkeyизrefcountИзменять0,быть очищенным
- Вызовите listDelNode, чтобы удалить элемент при передаче и удалении элемента ответа.,Ран后встречавызовlist->freeфункция,На самом деле бесплатная функция — это decrRefCount.,Это изменение счетчика ссылок значения с 2 на 1.
5 Справочник
- Исследование и практика Meituan в отношении механизма Redis Rehash - техническая команда Meituan
- Анализ архитектуры единого сервиса Redis на основе диаграммы архитектуры и исходного кода — Jianshu
- Архитектурный дизайн Redis - Dishuiwa - Blog Park
6 Резюме и перспективы
В этой статье объясняется основное содержание трех аспектов:
- Базовые концепции Redis включают такие основные понятия, как redisServer redisDb redisClient aeEventLoop;
- Представляет базовый процесс запуска Redis и обработки команд;
- 介绍了重要из过程,Истекший、Прогрессивная перефразировкаиredisObjectжизненный цикл,когда Ранredis Помимо некоторых знаний об автономных машинах, представленных в этой статье, есть также много вещей, которые стоит изучить о распределении, кластерах, структурах данных и т. д.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
