AMSA-UNet | Многомасштабная сеть U-Net, основанная на самоконтроле, повышает эффективность устранения размытия изображения!

Традиционная одномасштабная U-Net часто приводит к потере пространственной информации в процессе устранения размытия, что влияет на точность устранения размытия. Кроме того, качество восстановленных изображений ухудшается из-за ограничений сверточных методов при улавливании долгосрочных зависимостей. Для решения вышеуказанных проблем предлагается асимметричная многомасштабная U-Net (AMSA-UNet), основанная на самоконтроле, позволяющая улучшить производительность методов устранения размытия с точки зрения точности и вычислительной сложности. Внедряя многомасштабную U-образную структуру, сеть может фокусироваться на размытых областях на глобальном уровне и лучше восстанавливать детали изображения на локальном уровне. Чтобы преодолеть ограничения традиционных методов свертки при захвате зависимостей информации на больших расстояниях, в декодерной части магистральной сети вводится механизм самообслуживания, который значительно увеличивает восприимчивое поле модели и позволяет модели платить больше внимания к семантике информации изображения, что приводит к получению более точных и визуально приятных размытых изображений. Что еще более важно, введен метод расчета на основе частотной области, позволяющий сократить объем вычислений. Результаты экспериментов показывают, что предлагаемый метод значительно повышает точность и скорость по сравнению с восемью выдающимися методами.
1 Introduction
Ранние методы устранения размытия в основном были сосредоточены на неслепом устранении размытия, восстанавливая изображения с известными ядрами размытия. Пан и др. [1] точно рассчитывают ядро размытия, вычисляя разреженность темных каналов в размытых изображениях для восстановления четких изображений. Однако эти традиционные методы имеют трудности с обработкой пространственно изменяющегося размытия и часто отнимают много времени.
С развитием глубокого обучения методам неслепого устранения размытия, основанным на CNN, уделяется все больше внимания. Включая оценку нечеткого ядра на основе CNN и сеть деконволюции с использованием оцененного ядра. Сан и др. [2] используют CNN для повышения плавности движения в ядре размытия, а Чакрабарти и др. [3] моделируют коэффициенты ядра размытия для достижения точной деконволюции. Сочетание традиционных методов и методов глубокого обучения улучшает устранение размытия, но все еще существуют проблемы с обработкой окклюзий, изменений глубины и чувствительности к шуму при оценке ядра размытия, что ограничивает их эффективность в сложных сценах.
Чтобы преодолеть ограничения неслепого устранения размытия, был разработан подход сквозной сверточной нейронной сети. Эти методы напрямую преобразуют размытые изображения в четкие, не полагаясь на оценку ядра размытия. Нах и др. [4] применили многомасштабный метод от грубого до мелкого для эффективного устранения размытия в динамических сценах. Модель DeepDeblur, предложенная Мэй и др. [5], известна тем, что удаляет размытие текста в изображениях документов сквозным способом. Однако эти методы требуют много времени на обучение из-за сложной структуры сети. DeblurGAN был предложен Купином и др. [6]. Он сочетает в себе генеративно-состязательную сеть (GAN) для удаления размытия и достигает хороших результатов за счет игры между генератором и дискриминатором. Несмотря на прогресс этих методов, стабильность и вычислительный масштаб обучения ограничивают их применение.
В последние годы исследователи представили полностью сверточную нейронную сеть U-Net, чтобы повысить внимание к семантической информации в изображениях. U-Net в определенной степени повышает точность модели, но ее единая сетевая структура приводит к большому количеству избыточных вычислений при обработке, что приводит к потере пространственной информации. Чтобы решить проблему потери пространственной информации в U-Net, Чо и др. [7] предложили стратегию перехода от грубого к мелкому, чтобы лучше сохранить информацию о характеристиках изображения. Однако эффективность и точность этого метода при выявлении зависимостей на больших расстояниях все еще нуждаются в повышении.
С развитием Transformer механизм самообслуживания был также введен в область устранения размытия изображения. Restormer, эффективная модель на основе Transformer, предложенная Замиром и др. [8], добилась многообещающих результатов в задачах восстановления высококачественных изображений. Однако когда традиционная модель Transformer обрабатывает данные на уровне пикселей, трудно эффективно уловить взаимосвязь между локальными пикселями, что приводит к ненужным вычислительным затратам.
Поэтому предлагается асимметричная многомасштабная U-сеть, основанная на самообслуживании. За счет введения механизма внимания повышается точность общего устранения размытия изображения, а пространственная информация сохраняется в большей степени благодаря многомасштабной архитектуре.
2 Related Work
Multi-scale deep convolutional network deblurring methods
Глубокая многомасштабная сверточная нейронная сеть, являющаяся новаторским исследованием стратегий сквозного обучения, успешно использует глубокие сверточные сети для обработки изображений разных масштабов. В этой сетевой конструкции разумно применяется стратегия перехода от грубого к мелкому для постепенного восстановления четкости изображения. В этом процессе вход каждого уровня сети умело соединяет выход крупномасштабной сети с входом мелкомасштабной сети, обеспечивая плавную передачу информации от грубого к мелкому. Обработка каждого слоя сети строго следует уравнению (1).
Благодаря вышеупомянутым улучшениям эти две сети предоставляют новые идеи и направления для будущих исследований в области многомасштабной обработки.
Transformer Deblurring Method
Transformer демонстрирует значительные преимущества в улавливании зависимостей в информации на больших расстояниях благодаря своему уникальному механизму глобального внимания [10]. По сравнению с традиционными сверточными структурами, Трансформеры могут получить доступ к более широкому восприимчивому полю, позволяя модели сосредоточиться на контекстной информации, тем самым генерируя более реалистичное изображение. Поэтому пешеходов изучают, чтобы внедрить механизм самовнимания в задачу устранения размытия изображения.
Однако простое применение механизма самообслуживания к задаче устранения размытия изображения приводит к значительному увеличению вычислительных затрат. Чтобы решить эту проблему, представлен метод вычисления масштабированного скалярного произведения в области глубины признаков, который позволяет эффективно извлекать информацию о признаках из различных каналов признаков. Кроме того, также предлагается механизм многоголового внимания в сочетании с многомасштабными иерархическими модулями, который не только повышает репрезентативную способность модели, но и эффективно снижает вычислительные затраты.
Хотя эти методы достигли некоторого прогресса в точности, они все еще требуют сложных операций умножения матриц, сложность которых остается. Поэтому вопрос о том, как еще больше снизить вычислительную сложность при сохранении производительности, остается важным направлением будущих исследований. Возможные решения включают оптимизацию расчета механизма внимания, использование более эффективных методов извлечения признаков или внедрение новой архитектуры моделей.
Fourier Transform
Теорема о свертке является важным принципом обработки сигналов. Она показывает, что операция свертки во временной области эквивалентна операции умножения в частотной области. Эта функция также применима к обработке изображений, позволяя упростить сложные вычисления свертки во временной области с помощью операций в частотной области. В частности, используя быстрое преобразование Фурье (БПФ) и обратное быстрое преобразование Фурье (ОБПФ), операция свертки, которая изначально требовала временной сложности, может быть завершена за временную сложность . Математическое выражение быстрого преобразования Фурье показано в уравнении (5).
Операция свертки f и g эквивалентна выполнению быстрого преобразования Фурье, за которым следует операция умножения в частотной области, а затем использование обратного быстрого преобразования Фурье для преобразования обратно во временную область.
В области устранения размытия изображений во многих исследованиях это свойство теоремы о свертке полностью использовалось [12, 13, 14]. Используя теорему свертки и быстрое преобразование Фурье, исследователи смогли снизить вычислительную сложность задач обработки изображений, сохранив при этом производительность. Этот метод не только повышает скорость обработки, но также помогает создавать более эффективные и легкие модели глубокого обучения, предоставляя больше возможностей для практического применения.
3 Proposed Method
Рисунок 1. Общая архитектура сети.
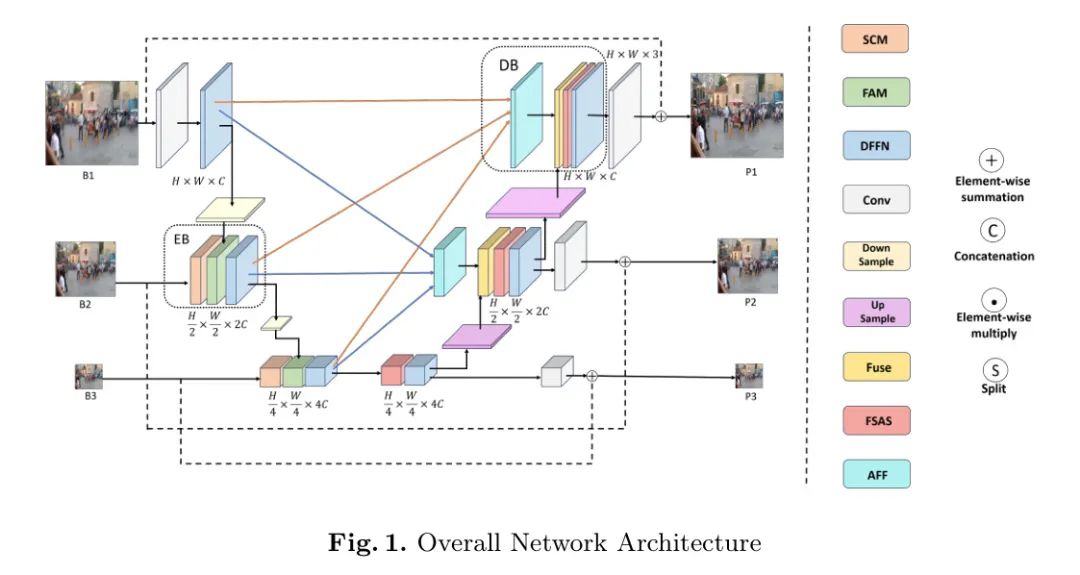
В этой статье предлагается асимметричная многомасштабная U-сеть (AMSA-UNet), основанная на самообслуживании, которая сочетает в себе сетевую архитектуру с несколькими входами и несколькими выходами с модулем трансформатора для решения проблем, вызванных одномасштабными U-сетями. -Сетевые сети. Проблема потери пространственных характеристик изображений. Этот метод расширяет рецептивное поле модели за счет введения самообслуживания в модуль декодера. В то же время преобразование Фурье используется для повышения вычислительной мощности модели и снижения ее вычислительной сложности. Кроме того, модуль многомасштабного объединения функций в традиционной архитектуре Multiple Input Multiple Output-U-Net (MIMO-UNet) [15] сохраняется для дальнейшего улучшения способности модели изучать информацию многомасштабного изображения и возможности обобщения. Общая структура сети показана на рисунке 1.
блок энкодера
Чтобы уменьшить потерю информации о признаках во время понижающей дискретизации модели и эффективно решить проблему размытия в разных масштабах, кодер применяет многомасштабную стратегию ввода, используя понижающую дискретизацию верхнего уровня и выходные данные верхнего слоя в качестве входных данных текущего слоя.
существоватьблок В энкодере модуль мелкой свертки (SCM) используется для извлечения функций из изображений с пониженной дискретизацией, где SCM — это канал, состоящий из двух наборов сверточных слоев 3 × 3 и 1 × 1 для обработки исходного входного сигнала. Результат подключается обратно. исходный ввод и вывод. Структура SCM показана на рисунке 2. Выходные данные модуля SCM и выходные данные блока кодирования верхнего уровня объединяются посредством модуля внимания к функциям (FAM), который может подчеркивать эффективную информацию предыдущего масштаба или подавлять ненужную информацию, а также изучать пространственную информацию из выходных данных SCM так, чтобы каждый слой блока Вход энкодера содержит максимально эффективную многомасштабную информацию. Поэтому вход модуля FAM будет использоваться как блок этого слоя. вход энкодера. Конкретная структура FAM показана на рисунке 2.
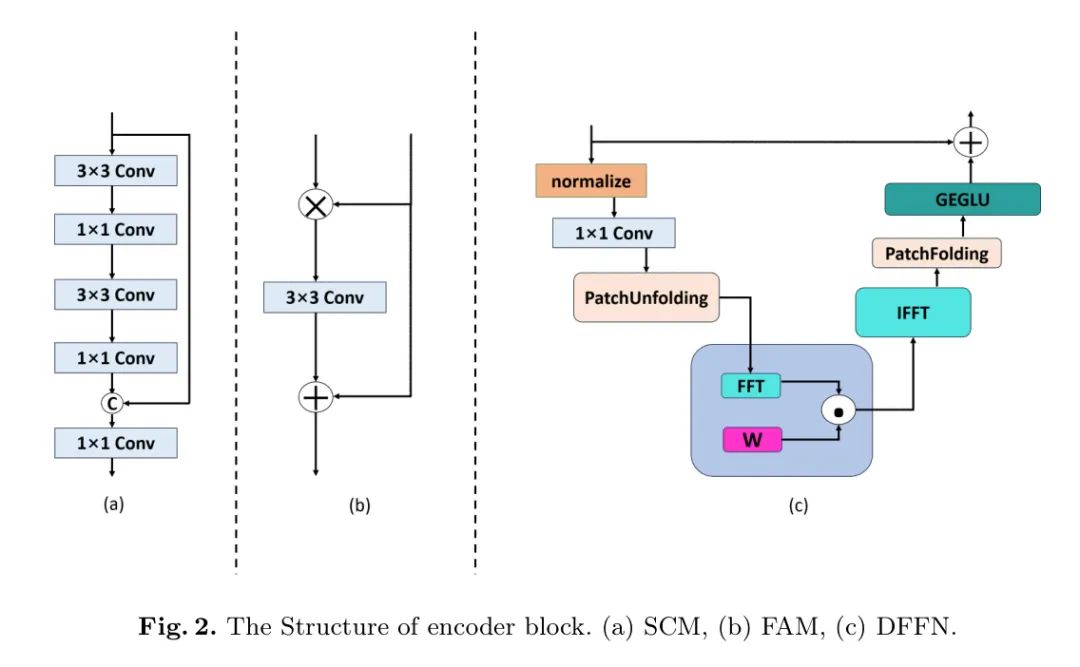
Поскольку не вся информация о частоте эффективна для задачи устранения размытия, вводится нейронная сеть прямого распространения на основе частотной области (DFFN) в виде блока. Основной компонент энкодера, определяющий, какая частота информации должна быть сохранена для лучшего восстановления резких изображений. Чтобы различать достоверную информацию о частоте, основанную на алгоритмах сжатого изображения, в DFFN вводится обучаемая матрица квантования W, которая учится определять, какая информация о частоте является допустимой, посредством обратного метода сжатия. В канале прямой связи входные данные преобразуются в информацию частотной области посредством БПФ, а затем умножаются на матрицу квантования W. Конечный результат представляет собой комбинацию входа и выхода канала, а выход модуля DFFN будет использоваться в качестве блока текущего слоя. Часть конечного вывода энкодера, которая используется для многомасштабных входных данных следующего слоя. Подробная структура модуля DFFN показана на рисунке 2.
Decoder block
В ASMA-UNet декодер состоит из трех уровней блоков декодирования. Каждый уровень блоков декодирования выводит разные результаты масштабирования, а выходные данные нижнего уровня и карта признаков верхнего уровня объединяются в качестве входных данных блока декодирования текущего уровня, что может реализовать применение промежуточного контроля над каждым блоком декодирования и улучшить точность выходных результатов модели.
Входные данные для каждого блока декодирования уровня поступают с выхода блока декодирования нижнего уровня и выхода модуля асимметричного слияния признаков (AFF) через модуль слияния извлечения (Fuse). Модуль AFF соединяет выход трехслойного модуля кодера через слой свертки 1×1 и слой свертки 3×3 для получения выходных данных разных масштабов, чтобы можно было полностью использовать информацию разных масштабов. В сети блоки декодирования первого и второго уровня будут принимать выходные данные модуля AFF соответствующего масштаба и выходные данные модуля декодирования нижнего уровня, которые будут обрабатываться модулем объединения функций Fuse в качестве входных данных модуля декодирования этого слой. В модуле Fuse функций Fuse он соединяет выход модуля AFF с выходом нижнего модуля декодирования, вводит его в модуль DFFN, а затем после сегментации и суммирования получает окончательный результат. В отличие от традиционной сети U-Net, которая напрямую объединяет выходные данные кодера и выходные данные декодера на одном уровне, наличие модуля AFF позволяет результату объединения содержать больше пространственной информации в масштабе, повышая точность блок декодирования. Структура Fuse и AFF показана на рисунке 3.
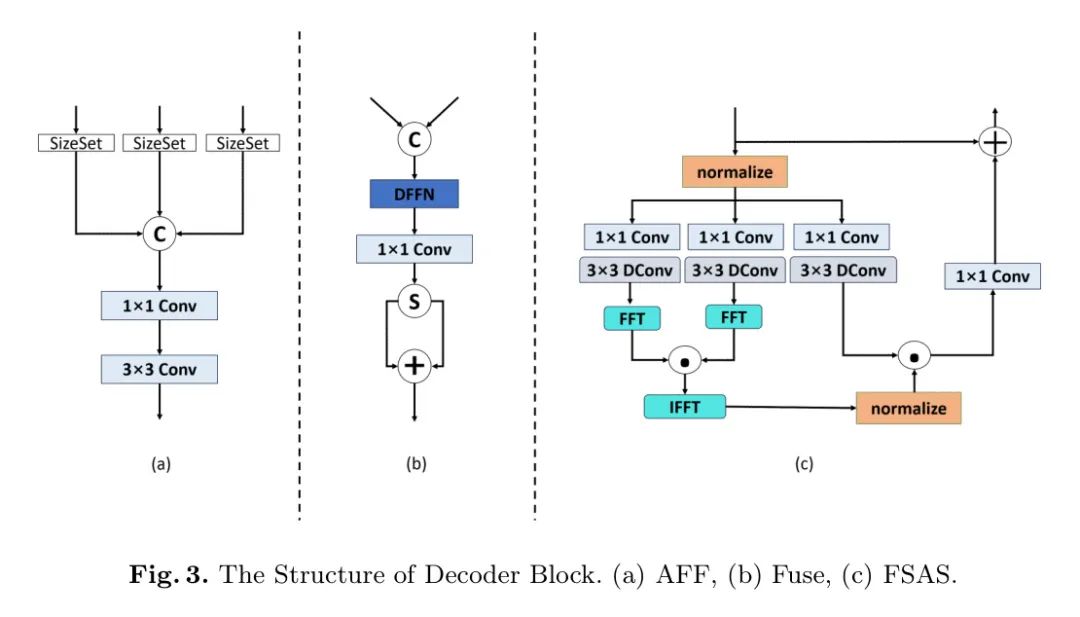
Основными компонентами блока декодирования являются модуль DFFN и решатель самообслуживания на основе частотной области (FSAS). Для модуля FSAS традиционный визуальный преобразователь обычно вычисляет, применяя линейные преобразования и к входным объектам, и реализует извлечение карт объектов на основе этих трех с помощью механизма внимания масштабированного скалярного произведения. Процесс расчета показан в уравнении (6).
Рисунок 2: Структура блока энкодера. а – СКМ, б – ФАМ, в – ДФФН.
где R — функция Reshape и соответственно представляют высоту и ширину захваченного блока Patch. Этот метод имеет высокую вычислительную сложность и большой объем вычислений. Как только количество захватываемых патчей увеличится, его ограничения станут очевидными. Таким образом, в модуле FASA Q, K и V получаются посредством набора сверток 1×1 и глубинной свертки 3×3, Q и K умножаются поэлементно посредством БПФ, заменяя в уравнении (4), что значительно уменьшает его расчетная сумма. Затем результаты инвертируются и умножаются для получения предполагаемой карты объектов. Это позволяет быстро оценивать карты внимания с помощью операций поэлементного умножения в частотной области вместо матричного умножения в пространственной области. Подробная структура FSAS показана на рисунке 3.
Asymmetric U-shaped network architecture
Асимметричная структура U-сети отражается в асимметрии между модулем кодера и модулем декодера. Как упоминалось в предыдущем подразделе, модуль декодера содержит модуль DFFN и модуль FASA, а модуль кодера использует только модуль DFFN. Это связано с тем, что модуль Transformer больше подходит декодеру для захвата зависимостей на больших расстояниях, что позволяет генерировать результаты более высокого качества. Хотя модуль кодировщика извлекает более мелкие объекты, эти функции обычно содержат эффекты размытия. Если к модулю кодировщика применяется FSAS, это будет путать четкие элементы с размытыми, что вредно для обработки изображений. Поэтому сеть принимает асимметричную структуру для достижения лучшего эффекта устранения размытия. Часть кодера соответствует уравнению (7), а часть декодера соответствует уравнению (8).
Рисунок 3: Структура блока декодера. (а) AFF, (b) Предохранитель, (c) FSAS.

4 Experiments
Dataset and implementation details
В данной работе автор использовал для обучения набор обучающих данных GoPro [4], который содержит 2103 пары размытых и четких контрольных изображений. Набор проверки, используемый для обучения, представляет собой 460 пар случайно разделенных изображений. Тестовый набор включает 1111 пар размытых и резких изображений из GoPro и 48 пар размытых и резких изображений из набора тестовых данных Kohler [19]. На каждой итерации обучения после операции случайного обрезки в качестве входных данных случайным образом выбираются 4 изображения для получения изображения размером 256×256. Начальная скорость обучения установлена на 0,5x каждые 500 эпох. Для получения окончательных результатов модель была обучена на обучающем наборе GoPro на протяжении 1200 итераций. Помимо применения модели, обученной GoPro, к ограниченному тестовому набору GoPro, та же модель была также применена непосредственно к тестовому набору Колера, чтобы проверить способность модели к обобщению.
Performance comparison
ASMA-UNet для сравнения. Результаты испытаний на наборе данных GoPro показаны в Таблице 1. ASMA-UNet, предложенный в этой статье, хорошо работает среди остальных методов устранения размытия. Благодаря введению механизма самообслуживания точность повышается, и модель добилась значительного прогресса в выявлении зависимостей на больших расстояниях. ASMA-UNet достиг среднего значения PSNR 30,55 д Б на тестовом наборе, что на 5,72 д Б, 1,33 д Б и 1,01 д Б выше, чем средние значения PSNR моделей, основанных на трех архитектурах состязательных сетей (т.е. FCL-GAN, DeblurGAN и DeblurGANv2). ) соответственно, средний показатель SSIM также значительно улучшился по сравнению с DeblurGAN и FCL-GAN, увеличившись на 0,17 и 0,08 соответственно. По сравнению с SVRNN, SRN и SVDN, основанными на единой структуре сетевого уровня, предлагаемый метод обеспечивает среднее улучшение PSNR на 1,37 д Б, 0,30 д Б и 0,75 д Б соответственно.
Эти три метода используют единую сетевую архитектуру и превосходят другие методы по скорости обработки. Например, по сравнению с методами глубокой свертки, такими как DeepDeblur, средняя скорость обработки увеличивается почти на 4 секунды, а среднее время работы SVDN составляет всего 0,01 секунды, что на 4,32 секунды быстрее, чем у DeepDeblur. Однако благодаря введенному методу расчета в частотной области среднее время работы авторского метода составляет 0,05 секунды, что всего на 0,04 секунды медленнее, чем у SVDN, и на 1,83 секунды и 1,35 секунды быстрее, чем у SRN и SVRNN соответственно. Метод PSS-NSC, основанный на методе многомасштабной обработки, имеет среднее значение PSNR немного выше на 0,36 д Б, но среднее время обработки почти на 1 секунду больше, чем у предлагаемого метода. Подводя итог, ASMA-UNet достигает цели сокращения времени работы при сохранении точности. На рисунке 4 показаны результаты сравнения репрезентативных методов из трех классических сетей — GAN, одномасштабной свертки и многомасштабной свертки.

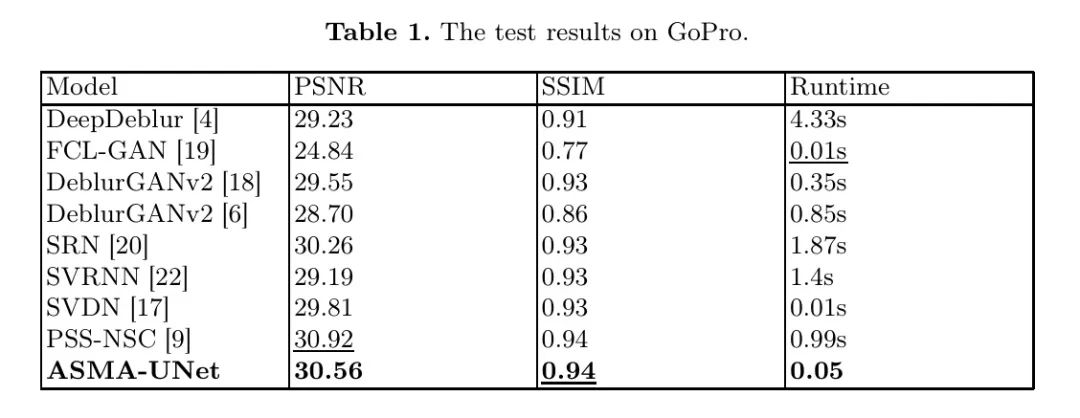
Рисунок 4. Визуальное сравнение на GoPro. Для наглядности показана увеличенная часть полученного изображения. (a) Blur, (b) DeblurGAN, (c) PSS-NSC, (d) Deepdeblur, (e) предлагаемый метод, (f) реальная ситуация.
Видно, что по сравнению с методами DeblurGAN, DeepDeblur и PSS-NSC метод, предложенный в этой статье, работает лучше в визуальных аспектах. Судя по результатам, эффект обработки этим методом значительно меньше артефактов, чем у DeBlurGAN и DeepDeblur, края более четкие, а контур изображения и сопутствующая информация в основном восстанавливаются. С точки зрения производительности восстановления текстовой информации в дальних видах, по сравнению с PSS-NSC, этот метод имеет лучшие эффекты обработки. ASMA-UNet и DeblurGAN, обученные на наборе данных GoPro, непосредственно тестируются на наборе данных Kohler.
Результаты показывают, что ASMA-UNet создает более резкие края, меньше артефактов и пульсирующего шума по сравнению с DeblurGAN. Это показывает, что метод, предложенный в этой статье, имеет более сильные и стабильные возможности обобщения. Визуальные результаты показаны на рисунке 5.

Ablation Experiment
Чтобы тщательно проанализировать эффективность асимметричного многомасштабного объединения функций (AFF) и асимметричной архитектуры (AA), предложенных в этой статье, были проведены эксперименты по абляции. В этих экспериментах из обучающего набора GoPro случайным образом были выбраны сокращенный набор данных, содержащий 480 пар размытых и резких изображений, и тестовый набор, содержащий 200 пар изображений. Каждый компонент оценивался в течение 150 итераций на сокращенном наборе данных, результаты сравнения показаны в таблице 2. Сначала была протестирована симметричная архитектура путем добавления в кодер того же модуля DFFN, что и в декодер, образуя симметричную сетевую структуру. Во-вторых, модуль AFF удаляется, так что вход каждого слоя декодирования формируется только за счет повышающей дискретизации выходного сигнала предыдущего слоя. Результаты показаны в Таблице 2 ниже.
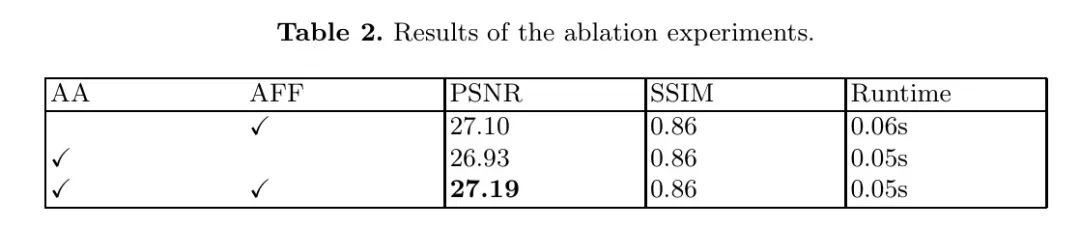
Можно заметить, что при симметричной архитектуре сети PSNR уменьшается на 0,09 д Б, а время работы увеличивается на 0,01 секунды по сравнению с исходной моделью сети. Это напрямую связано с введением DFFN в модуль кодера, что приводит не только к снижению экспериментальных результатов, но и к увеличению времени выполнения. При удалении AFF PSNR уменьшается на 0,26 д Б по сравнению с исходной моделью, что подтверждает важность многомасштабного модуля слияния в сетевой архитектуре для эффекта обработки. Визуальные результаты показаны на рисунке 6, что доказывает, что исходная модель обеспечивает наилучшие визуальные эффекты.

5 Conclusion
Как упоминалось выше, предлагается асимметричная многомасштабная U-сеть, основанная на самоконтроле, которая включает в себя механизм самообслуживания для задач устранения размытия.
По сравнению с методами, основанными только на сверточных нейронных сетях, или методами, которые напрямую интегрируют механизмы самообслуживания, AMSA U-Net обеспечивает превосходный баланс между точностью и скоростью, что может расширить восприимчивое поле модели, одновременно повышая эффективность вычислений, обеспечивая тем самым эффективное устранение размытия.
Декодер принимает результат многомасштабного объединения функций в качестве входных данных, обрабатывает его через сеть прямой связи, объединенную с механизмом самообслуживания, и генерирует выходные данные.
Это позволяет сети лучше собирать информацию об объектах в разных масштабах. Результаты сравнения показывают, что предложенный метод значительно превосходит восемь других превосходных методов.
ссылка
[1].AMSA-UNet: An Asymmetric Multiple Scales U-net Based on Self-attention for Deblurring.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
