AIсмотретьвидеоНайти автоматически“момент высокой энергии”|байт&Китайская академия наукавтоматизацияМесто@AAAI 2024
Менгчен родом из храма Ао Фэй. Кубиты | Публичный аккаунт QbitAI
Вы когда-нибудь использовали функцию «Выделить момент» при просмотре видео?
Зрители могут прыгнуть с парашютом прямо в захватывающие моменты, а ведущие также могут оценить свое выступление по длительным живым записям.

ByteDance и Институт автоматизации Китайской академии наук предложили новый метод, который использует искусственный интеллект для быстрого обнаружения ярких фрагментов в видео. Он чрезвычайно гибок в зависимости от длины входного видео и продолжительности извлечения ярких моментов. соответствующие документы были включены в AAAI 2024.

Тестовое решение, основанное на обучении прототипов
Проблема непрерывного обучения хорошо разработана в области распознавания изображений, эффективно смягчая катастрофическую проблему забывания, с которой сталкиваются модели глубокого обучения. Однако большинство существующих технологий подходят для области изображений, и существует относительно немного связанных с ними методов, которые исследуют непрерывное обучение в области видео. Анализируя причины, можно выделить в основном две трудности: одна — отсутствие наборов видеоданных и стандартов оценки для поэтапного обучения; другая — отсутствие эталонного метода, подходящего для поэтапного обучения в области видео.
принять этот вызов,ByteDance и Институт автоматизации Китайской академии наук отметили коллекцию видеоданных о еде LiveFood для поэтапного обучения предметной области,и на этом основании,предложенный Тестовое решение, основанное на обучении прототипов:Global Prototype Encoding(GPE)。
GPE преодолевает многие недостатки существующих решений для поэтапного обучения. Оценивая на уровне кадра изображения, он помогает быстро обнаруживать яркие сегменты в видео. Он обладает чрезвычайно высокой гибкостью в отношении длины входного видео и длины выделенных фрагментов, которые, как ожидается, будут извлечены. .
Определение проблемы и сбор данных
Чтобы решить проблему обнаружения ярких моментов видео в условиях непрерывного обучения, нельзя избежать двух ключевых моментов: один — это набор данных, а другой — постановка задачи.
Учитывая, что видео о еде — это сейчас горячая тема.,Эта статья начинается с видео о еде,Чтобы получить более широкий спектр применения. В категории гурманов,В этой статье определяются четыре домена,Они есть:Подготовка ингредиентов(ingredients),приготовление пищи(cooking),Дисплей готовой продукции(presentation),а такжеНаслаждайтесь вкусной едой(eating)。
Эти четыре домена могут в основном охватывать основные моменты видеороликов о еде. На этой основе автор собрал более 5100 видеоданных о еде, чтобы сформировать набор данных LiveFood. Аннотатор вручную сделал подробные аннотации для набора данных, указав время начала и окончания выделенных сегментов и соответствующих доменов. Процесс аннотации был проверен дважды, чтобы гарантировать точность аннотации. Основная информация набора данных LiveFood следующая:
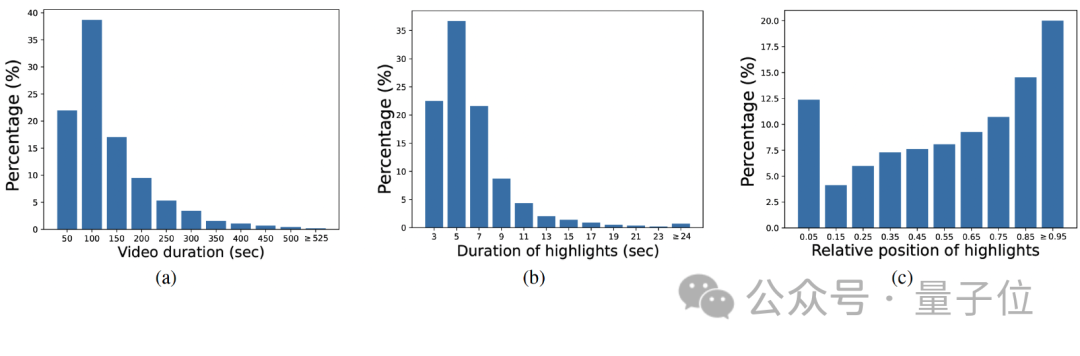
△ Изображение 1
Изображение 1(а) отражает видео в LiveFood, большинство из которых продолжительностью до 200 секунд и относятся к категории коротких видео; 1(b) отражает аннотацию основных моментов в LiveFood, в основном продолжительностью менее 9 секунд; 1(c) показывает, что основные моменты видео в LiveFood более равномерно распределены по всему видео, что может эффективно препятствовать тому, чтобы Модель изучала ярлыки.
Авторы отмечают, что при распознавании изображений, поскольку каждое изображение в основном содержит только один домен (стиль), задачу поэтапного обучения домену легче определить, но в задачах с видео эта предпосылка больше не верна. Например, в LiveFood видео может содержать несколько полей еды.
На основании этого,Ограничения автора:На текущем этапе обучения видео не может содержать комбинации доменов, появившиеся на предыдущем этапе обучения.
Например, на первом этапе обучения все видео содержат только поле «Еда-шоу», а на втором этапе обучения добавляется поле «Наслаждение едой». Затем каждого видео, появляющегося на втором этапе, существует два. комбинации доменов, одна — только «Наслаждение едой», другая — одновременно «Демонстрация еды и наслаждение едой».
«Наслаждение от еды», появившееся на первом этапе, уже не может появиться само по себе. Видео в оценочном наборе имеют все аннотации доменов. На соответствующем этапе обучения оцениваются только домены, которые появляются на этапе обучения и предыдущем этапе, а домены, которые не появляются, в оценке не участвуют. Индексом оценки является карта обнаружения ярких моментов. В следующей таблице показаны некоторые сравнения LiveFood с существующими данными, что указывает на то, что LiveFood больше подходит для постепенного обучения:

△лист1
Путь технологических инноваций
существующийРешения для поэтапного обучения можно условно разделить на три большие категории:К:
Первый — это воспроизведение данных, в котором используется определенный механизм скрининга для сохранения репрезентативных данных на каждом этапе обучения. Эти данные будут участвовать в последующих этапах обучения, тем самым замедляя явление забывания модели;
Второй — регуляризация параметров, которая ограничивает изменения параметров модели и поддерживает реакцию на контент, изученный на предыдущем этапе;
Третий — модельный рост, то есть использование разных моделей для решения задач на разных этапах обучения и использование изоляции для облегчения феномена забывания.
ГПО предназначен для достижения следующих целей:
Во-первых, воспроизведение данных не используется явно, поскольку выбрать репрезентативные данные непросто, а хранение и чтение видеоданных сопряжено с определенными затратами;
Во-вторых, избегайте проблемы, связанной с тем, что в схеме регуляризации параметров в модели доминирует небольшое количество параметров;
В-третьих, он не использует рост модели и поддерживает одну и ту же структуру модели, поэтому один и тот же план развертывания можно повторно использовать на разных этапах обучения.
Основываясь на этом, GPE использует решение для обучения прототипа ярких моментов для выполнения задачи двоичной классификации на уровне видеокадра, чтобы определить, является ли видеокадр ярким или неярким.
Во-первых, GPE использует сеть ConvNeXt для извлечения характеристик видеокадров и использует кодер для объединения этих характеристик во временные ряды для получения контекстной информации. Расстояния от объектов после временного слияния до ярких точек прототипа и неярких точек прототипа рассчитываются. Эти расстояния отображаются в вероятностную форму с использованием функции Softmax для задач двоичной классификации.
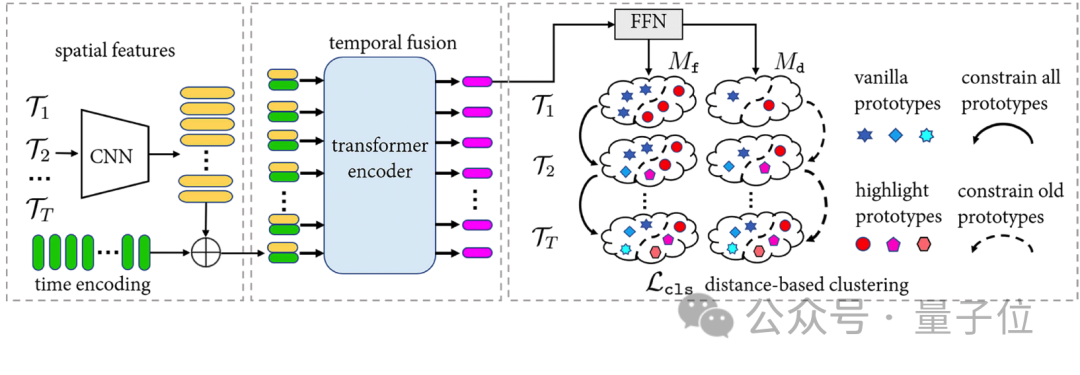
△ Изображение 2
GPE предотвращает катастрофическое забывание моделей глубокого обучения, ограничивая изменения в точках прототипа между различными этапами обучения. Используйте θ, φ и π для представления параметров CNN, параметров кодировщика и обучаемых точек прототипа выделения/невыделения соответственно. Цель оптимизации GPE — минимизировать потерю классификации ярких и не ярких моментов при условии, что изменение π не превышает γ между соседними этапами обучения. Для решения задач ограниченной оптимизации мы используем метод Лагранжа, где двойственное выражение Лагранжа имеет следующий вид:
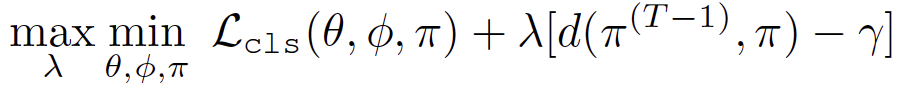
Используя эвристическое мышление, когда условия ограничения установлены, уменьшение штрафного коэффициента λ является множителем Лагранжа, и необходимо обеспечить, чтобы он был больше нуля. В процессе обучения используйте данные обучения каждой партии для поочередной оптимизации вышеуказанных параметров:
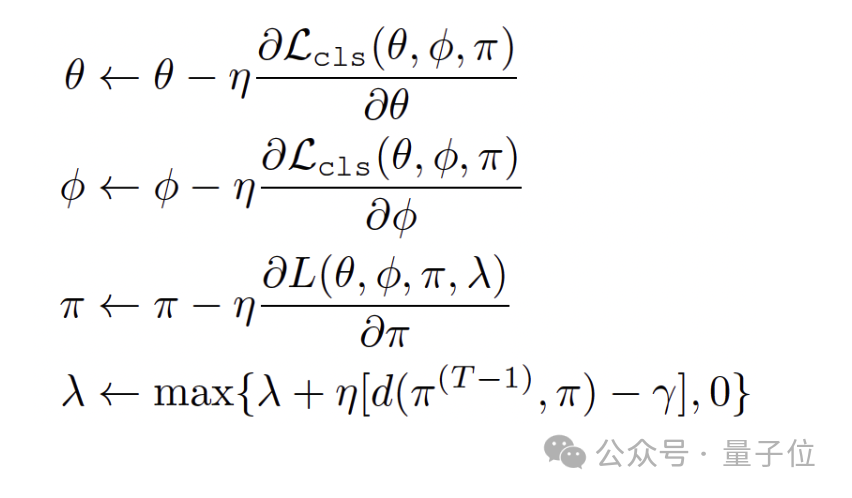
Результаты тестов
GPE достигает хороших показателей обнаружения ярких моментов на LiveFood и может обеспечить высокую реакцию на основные моменты еды на начальном этапе обучения. Решения, участвующие в сравнении, включают: нижнюю границу производительности (Lb), верхнюю границу производительности (Ub), SI, oEWC, ER, DER и т. д.
GPE имеет два варианта,ЧтоMfотносится к динамическому увеличениюпрототипколичество очков,На каждом этапе обучения ограничиваются только изменения исходных точек прототипа.,Новые точки прототипа можно изучать свободно. Методы, отмеченные звездочкой (*), используют случайное воспроизведение данных. В таблице 2 показаны различные этапы обучения.,Способность GPE обнаруживать основные моменты еды (mAP).

△лист2
Визуализация обнаружения основных продуктов питания. В процессе обучения порядок появления доменов следующий: презентация, прием пищи, ингредиенты и, наконец, приготовление. На рисунке 3 видно, что после завершения четвертого этапа обучения (Т4, оранжевый) ГПО по-прежнему имеет высокую реакцию на предъявление предметной области на первом этапе, превышающую реакцию DER на предъявление на четвертом этапе.

△картина3
Визуализация зеркальных и незеркальных точек прототипа. На рисунке 4 показано состояние распределения ярких точек прототипа и неосновных точек прототипа на разных этапах обучения. Учитывая, что большинство неосновных сегментов являются бессмысленными сегментами со схожими характеристиками, добавляются только основные точки прототипа (80 на каждом этапе обучения), а неосновные точки прототипа не добавляются на разных этапах обучения. На рисунке 4 показано, что даже несмотря на то, что этап обучения продолжает увеличиваться, основные точки прототипа и неосновные точки прототипа все еще могут быть хорошо разделены моделью, что также показывает, что GPE обладает сильной способностью сопротивляться забвению.

△картина4
Ссылка на проект: https://foreverps.github.io/
— над —



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
