AI: Введение и практика архитектуры Transformer
1. Три типа применения трансформаторов
Приложения машинного перевода: кодировщик и декодер используются вместе. Используйте только сторону кодировщика — классификацию текста BERT и классификацию изображений VIT. Используйте только сторону декодера — генерируйте модели классов
2. Базовая структура
Общую архитектуру Transformer можно разделить на 4 части:

1. Входная часть содержит:
- Исходный слой внедрения текста (Входное внедрение) и его кодировка позиции (кодировка позиции)
- Целевой слой внедрения текста и его кодировщик положения

Роль слоя внедрения текста: независимо от того, является ли это внедрением исходного текста или внедрением целевого текста, он заключается в преобразовании числового представления слов в тексте (слово для индексирования) в вектор (например, «горячий», но не здесь). Представление Есть надежда, что таким образом многомерное пространство фиксирует отношения между словами.
Роль кодировщика позиции: поскольку в структуре кодировщика Transformer нет обработки информации о позиции слова, необходимо добавить кодировщик позиции после слоя внедрения, чтобы добавить информацию, которая может создавать различную семантику с разными позициями слов для встраивания слов. .тензор, чтобы восполнить недостаток информации о местоположении.
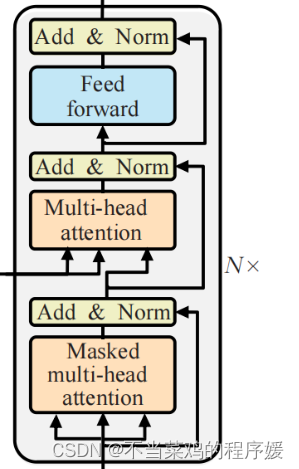
2. Часть кодера:
- Сложено N слоя кодимилятора Каждый уровень кодировщика состоит из двух подуровней, соединяющих структуры.
- Первый подуровень соединения включает в себя подуровень самообслуживания с несколькими головками и уровень стандартизации, а также остаточное соединение.
- Второй подуровень соединения включает в себя подуровень полного соединения с прямой связью (линейный), уровень стандартизации и остаточный уровень соединения.

2.1 Тензор маски
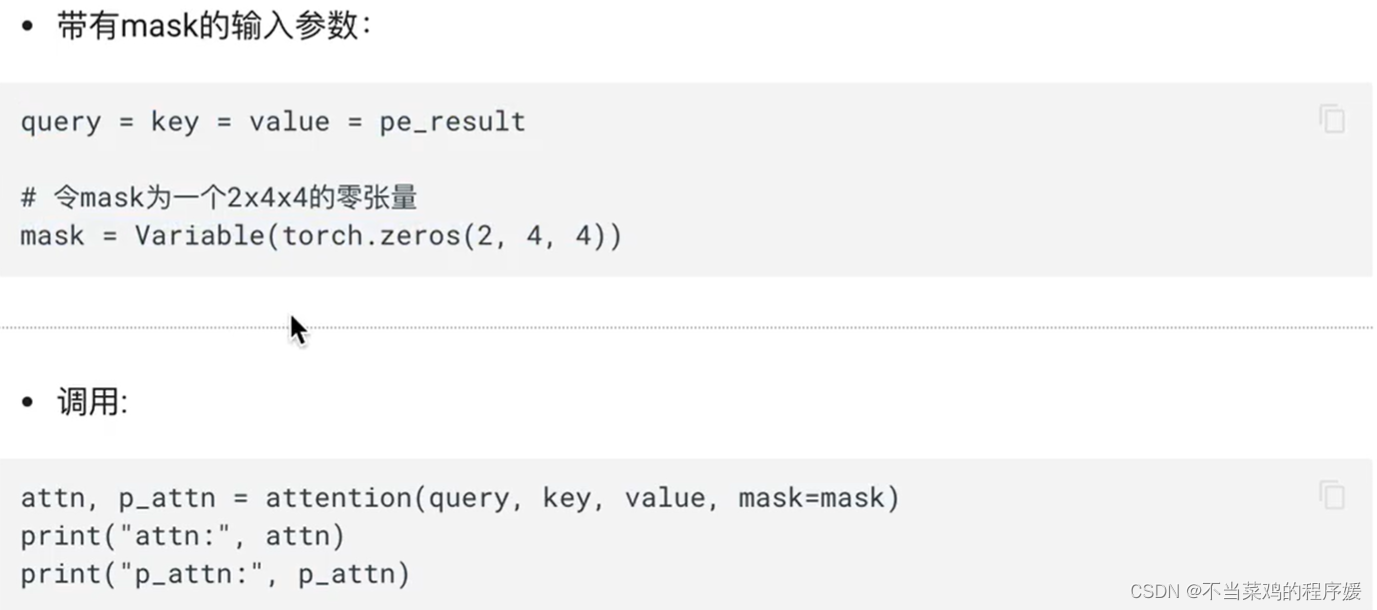
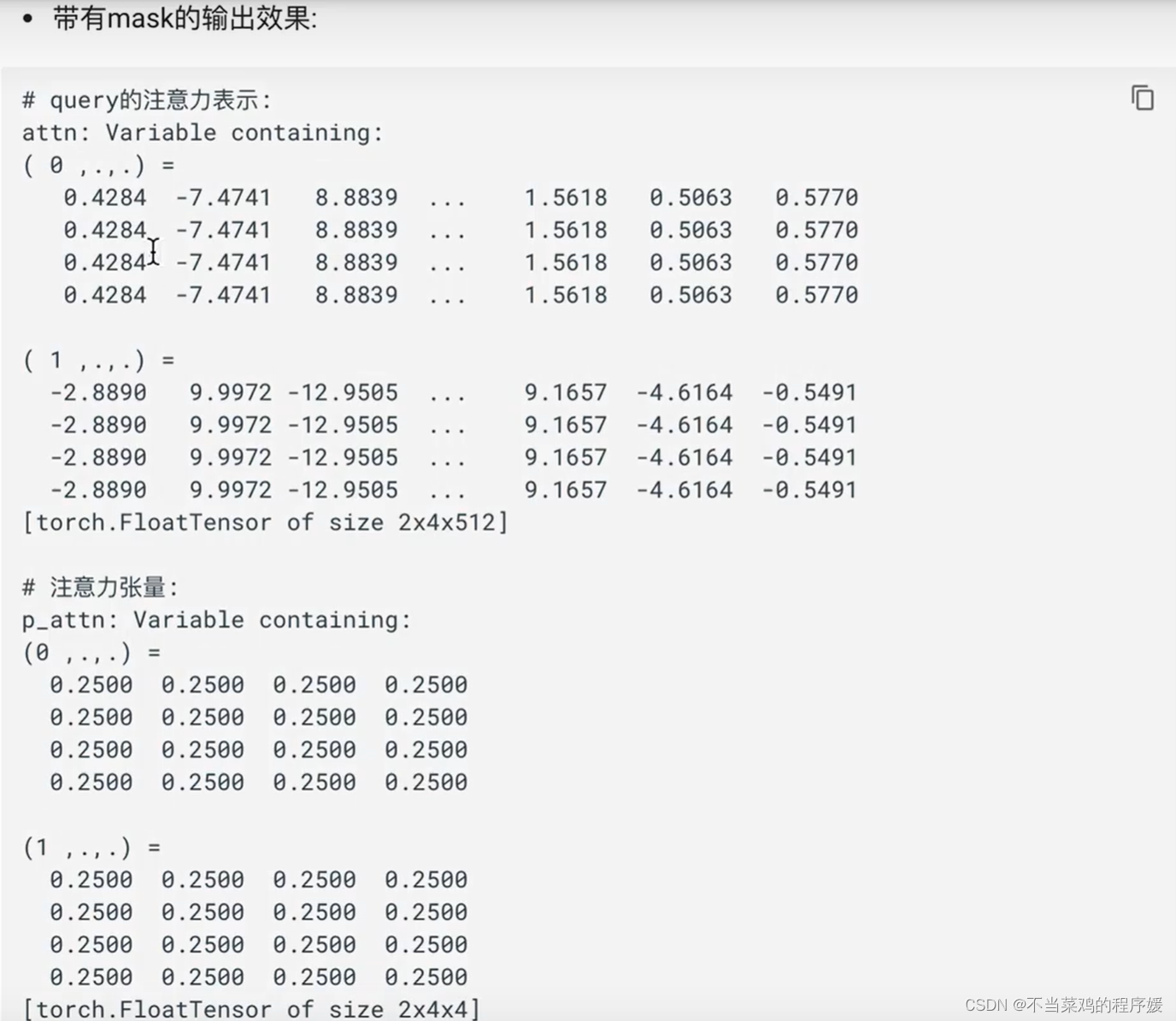
Тензор маски: Маска означает маскирование, а код — это значение в нашем тензоре. Его размер обычно является переменным. Обычно в нем есть только элементы 1 и 0, которые определяют, является ли позиция маскируемой или нет. замаскировано или замаскировано положение 1. Его можно настроить, поэтому его функция состоит в том, чтобы замаскировать некоторые значения в другом тензоре, который также можно назвать заменой.
Роль тензора маски. В преобразователе основная роль тензора маски заключается в применении внимания (будет объяснено в следующем разделе). Некоторые значения в сгенерированном тензоре внимания могут быть рассчитаны на основе известного будущего. Информация о будущем видна, потому что весь выходной результат встраивается сразу во время обучения. Однако теоретически выходные данные декодера не выдают окончательный результат за один раз, а снова и снова синтезируются из предыдущего результата. , следовательно, будущая информация может быть использована заранее. Итак, будем маскировать. Соответствующие знания о декодерах будут объяснены в последующих главах.
Изучена и реализована функция тензора маски, генерирующая обратную маску: next_mask. Ее вход — size, который представляет размер тензора маски. Выход — нижняя треугольная матрица, последние два измерения которой образуют квадратную матрицу, равную 1. Наконец, для. Сгенерированный тензор маски был визуально проанализирован, чтобы лучше понять его назначение.
[Передача изображения по внешней ссылке не удалась. Исходный сайт может иметь механизм защиты от кражи. Рекомендуется сохранить изображение и загрузить его напрямую (img-BVK9nF03-1688015009276) (C:\Users\86186\AppData\Roaming\Typora\. typora-user-images\ image-20230629103101500.png)]
# np.triu Демо
>>> np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]], k=-1) #k=-1 означает, что элементы на главной диагонали (1,5,9) сдвинуты вниз на единицу, а все опущенные элементы равны 0.
>>> array([[ 1, 2, 3],
>>> [ 4, 5, 6],
>>> [ 0, 8, 9],
>>> [ 0, 0, 12]])
>>> np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]], k=0) #k=0 означает, что главный диагональный элемент и элементы ниже него равны 0.
>>> array([[1, 2, 3],
>>> [0, 5, 6],
>>> [0, 0, 9],
>>> [0, 0, 0]])
>>> np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]], k=1) #k=1 означает, что после того, как главный диагональный элемент переместится на одну ступень вверх, следующие элементы будут иметь значение 0.
>>> array([[0, 2, 3],
>>> [0, 0, 6],
>>> [0, 0, 0],
>>> [0, 0, 0]])2.2 Механизм внимания
Что такое внимание: Когда мы наблюдаем за чем-то, причина, по которой мы можем быстро что-то судить (конечно, суждение может быть неправильным), заключается в том, что наш мозг может быстро сосредоточиться на наиболее идентифицируемой части предмета и вынести суждение. Мы можем вынести суждение не только после наблюдения чего-либо от начала до конца. Именно на основе этой теории родился механизм внимания.
Правила расчета внимания, которые мы здесь используем:

Метафорическое объяснение Q, K, V: Если у нас есть проблема: дан фрагмент текста, используйте несколько ключевых слов, чтобы описать его! Чтобы облегчить унификацию правильного ответа, для вас могут быть заранее написаны некоторые ключевые слова в качестве подсказок к этому вопросу. Данные подсказки можно рассматривать как ключи, а вся текстовая информация эквивалентна запросу. Значение значения более абстрактно и может быть сопоставлено с информацией ответа, которая приходит на ум после того, как вы увидите эту текстовую информацию. Здесь мы предполагаем, что все. поначалу были не очень умны. Когда они впервые прочитали этот текст, они подумали: По сути, единственная информация, которая появляется в субтитрах, — это подсказка, поэтому ключ и значение в основном одинаковы, но по мере того, как мы глубже понимаем эту проблему, тем больше вещей мы можем придумать в ходе своего мышления, и мы можем start Для нашего запроса, которым является этот текст, извлеките ключевую информацию для его представления. Это процесс внимания. Благодаря этому процессу ценность нашего мозга со временем меняется. В соответствии с ключом подсказки генерируется метод представления запроса по ключевым словам, который является еще одним методом представления объекта. Мы только что упомянули, что ключ и значение по умолчанию одинаковы и отличаются от запроса. Это наша общая форма ввода внимания, но есть особый случай, когда наш запрос совпадает с ключом и значением. В этом случае мы называем это. механизм самообслуживания, как в нашем примере. Использование общего механизма внимания заключается в использовании ключевых слов, отличных от данного текста, для его представления. Механизм самообслуживания должен использовать сам данный текст для выражения себя, а это означает, что вам нужно извлечь ключевые слова из данного текста, чтобы выразить его, что эквивалентно извлечению признаков самого текста.
Простой:
- Вопрос: Информация, которую мы хотим запросить, например, мужской свитер с высоким воротником (запросить отношения с другими)
- K: запрашиваемая информация, например, пожилой возраст, мужчины, свитер (удостоверение личности).
- v: Содержимое запроса (представление функции)
Или понять:
- Q — текст, который нужно резюмировать;
- К – данная подсказка;
- V — это расширение сигнала К в мозгу.
Когда Q=K=V, это называется механизмом самовнимания. (Я дал вам основную идею статьи, а вы сказали, что нужна ссылка, но в результате получилось «нет ссылки», то есть ссылка, данная вам, представляла собой статью, точно такую же, как оригинальная статья. )
Что такое механизм внимания: Механизм внимания является носителем сети глубокого обучения, к которой могут применяться правила расчета внимания. В дополнение к правилам расчета внимания он также включает в себя некоторые необходимые полносвязные слои и соответствующую тензорную обработку для его интеграции. сеть приложений как одно тело. Механизм внимания, использующий правила расчета собственного внимания, называется механизмом собственного внимания.
Графическое представление механизма внимания, реализованного в сети:

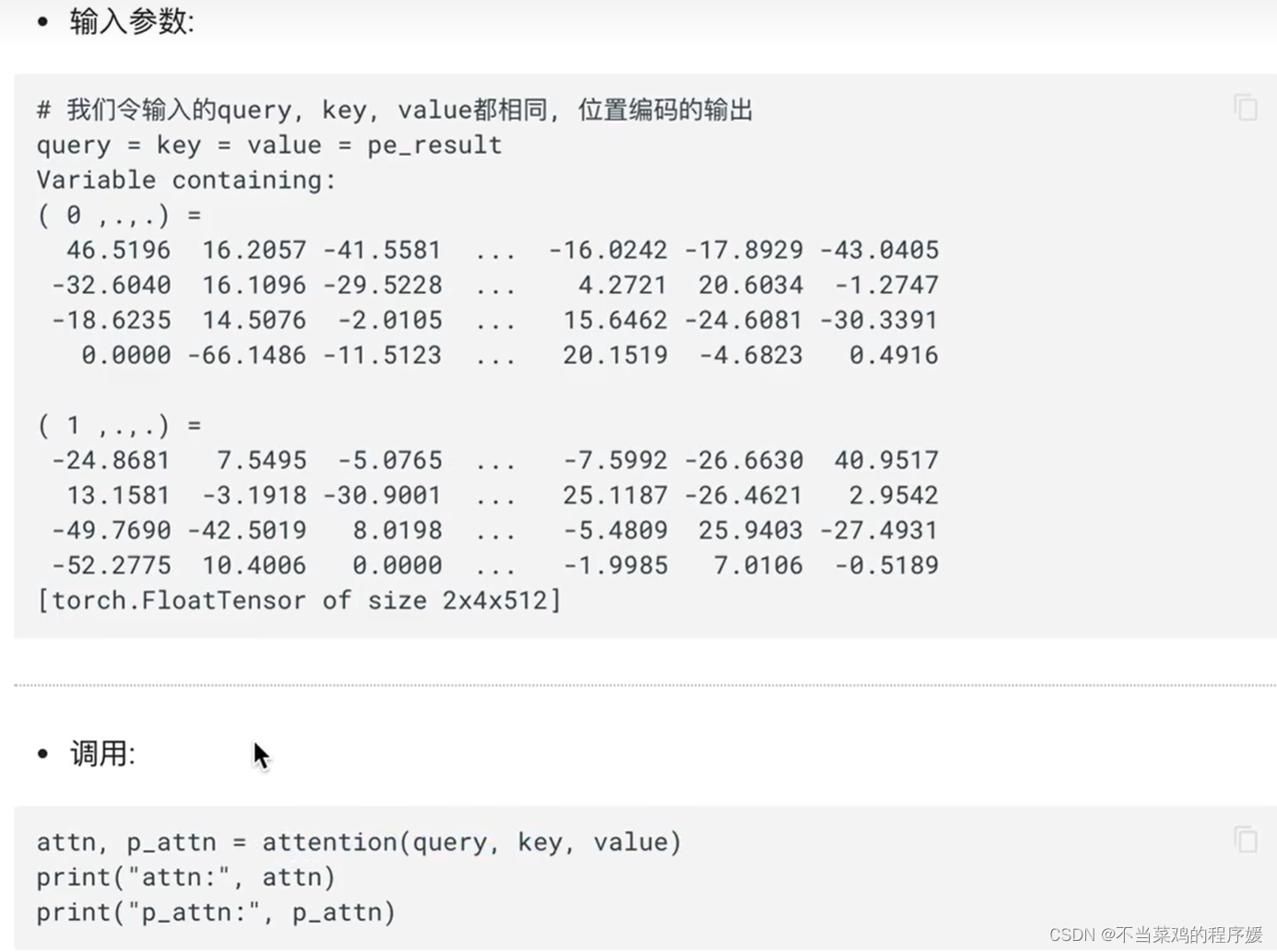
Функция правила расчета внимания: внимание, его вход — Q, K, V, маска и отсев, маска используется для маскировки, а отсев используется для случайной установки 0. Его выходные данные имеют два: представление запроса (размерность встраивания слова) и тензор внимания.

демонстрация заполнения маски:


2.3 Многоголовочный механизм внимания
Что такое многоголовый механизм внимания: Из структурной диаграммы многоголового внимания кажется, что так называемые множественные головы относятся к множеству наборов слоев линейного преобразования. На самом деле это не так, я использовал только один набор слоев линейного изменения, то есть. три тензора преобразования для Q, K и V соответственно. Выполните линейные преобразования. Эти преобразования не изменят размер исходного тензора, поэтому каждая матрица преобразования представляет собой квадратную матрицу. начинает появляться бык. , каждая голова начинает сегментировать выходной тензор с уровня значения слова, то есть каждая голова хочет получить набор Q, K, v для расчета механизма внимания, но получает только часть представления каждого слова в предложение, то есть только вектор встраивания слов последнего измерения, делится. Это так называемая многоголовка. Входные данные, полученные каждой головкой, отправляются в механизм внимания для формирования механизма многоглавого внимания.
Структурная схема механизма многоголового внимания:
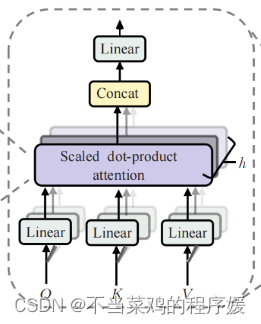
Роль механизма внимания с несколькими головами: такая структурная конструкция позволяет каждому механизму внимания оптимизировать различные части каждого слова, тем самым уравновешивая возможные отклонения, вызванные одним и тем же механизмом внимания, позволяя значениям слов иметь более разнообразные выражения. Эксперименты показывают, что. это может улучшить производительность модели.
- Часть декодера:
- Сложено N слоями декодера Каждый уровень декодера состоит из трех подуровней соединяющих структур.
- Первый подуровень соединения включает в себя подуровень самообслуживания с несколькими головками и уровень стандартизации, а также остаточное соединение.
- Второй подуровень соединения включает в себя подуровень многоголового внимания и уровень стандартизации, а также остаточный уровень соединения.
- Структура соединения третьего подуровня включает в себя подуровень полного соединения с прямой связью и уровень стандартизации, а также остаточное соединение.
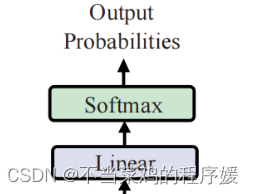
4. Раздел вывода содержит:
- Линейный слой (получить размер вывода)
- процессор softmax (найти максимальную вероятность)
Это перекомбинация основных входных векторов для получения более совершенных функций. Ссылка: Сверхподробная интерпретация Vision Transformer (анализ принципов + интерпретация кода) (1) — Zhihu (zhihu.com)
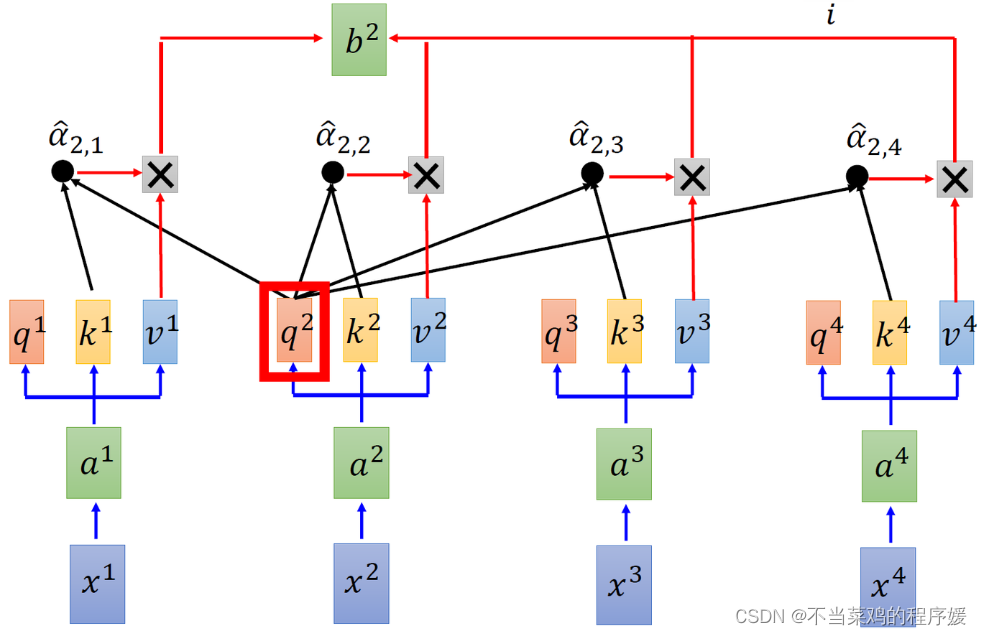
Введите последовательность x1, x2, x3, x4 и извлеките объекты из x1~x4. Исследуйте взаимосвязь между x1, x2, x3 и x4, используя три вспомогательных вектора Q, K и V.
Каждый токен соответствует 3 векторам Q, K, V; Q: Проверка отношений между собой и другими, K: Вы являетесь субъектом проверки, ключом удостоверения личности, V: Выражение признака (x1 выражается через v1, за которым следует x1. Не имеет значения, вместо этого используйте v1)
Благодаря этой операции получается весовой член, а затем признаки рекомбинируются.

другой
ссылка:Анализ базовой структуры и реализации Transformer_Program Блог Юаня-CSDN Блог



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
