AI: классификация текста с помощью модели BERT с использованием pytorch
Введение
BERT — мощная языковая модель по крайней мере по двум причинам: она предварительно обучена с использованием неразмеченных данных, извлеченных из BooksCorpus (в котором 800 миллионов слов) и Википедии (в которой 2,5 миллиарда слов). Он предварительно обучается с использованием двунаправленной природы стека кодировщика. Это означает, что BERT изучает информацию из последовательностей слов не только слева направо, но и справа налево.
Модель BERT требует в качестве входных данных последовательности токенов (слов). В каждой последовательности токенов BERT ожидает, что входные данные будут иметь два специальных токена: [CLS]: это первый токен каждой последовательности, представляющий токен классификации. [SEP]: это токен, который позволяет BERT узнать, какой токен принадлежит какой последовательности. Это специальное представление в основном используется для задач прогнозирования следующего предложения или задач вопросов и ответов. Если у нас есть только одна последовательность, то этот токен будет добавлен в конец последовательности.
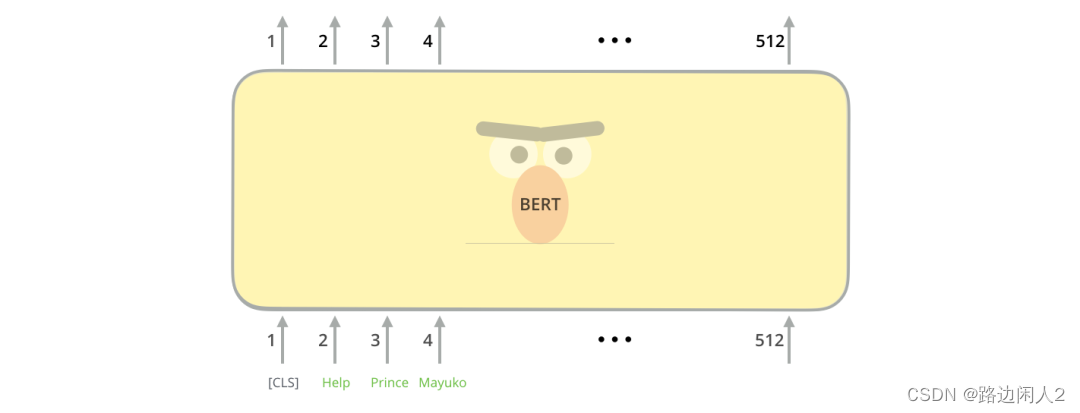
Как и обычный кодер Transformer, BERT принимает на вход последовательность слов, идущих вверх. Каждый уровень применяет самообладание и передает результаты через сеть прямой связи, которая затем передает их следующему кодировщику.
Вывод BERT: каждая позиция выводит вектор размера Hidden_size (768 в базе BERT). В примере классификации предложений, который мы видели выше, мы сосредоточились только на выводе первой позиции (передавая в эту позицию специальный токен [CLS]).
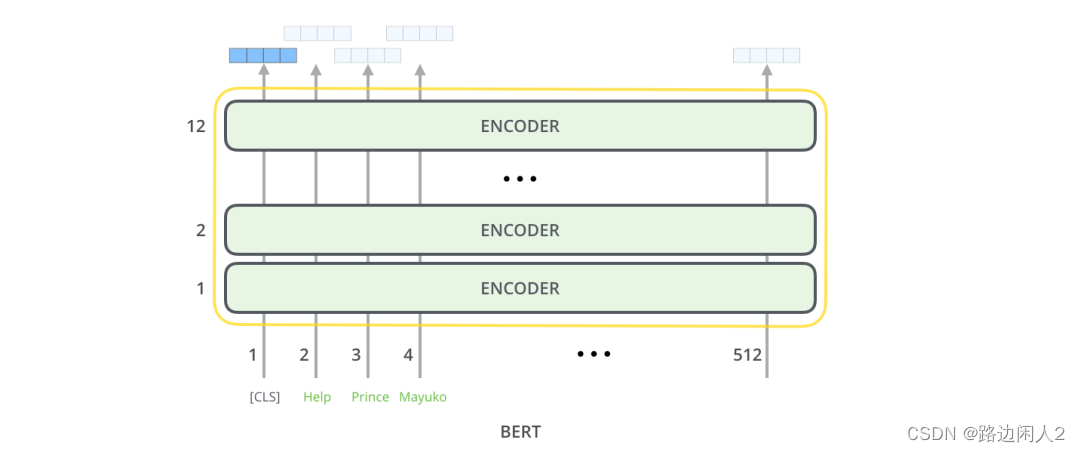
Теперь этот вектор можно использовать в качестве входных данных для выбранного нами классификатора. В этой статье были достигнуты хорошие результаты, используя в качестве классификатора только однослойную нейронную сеть.
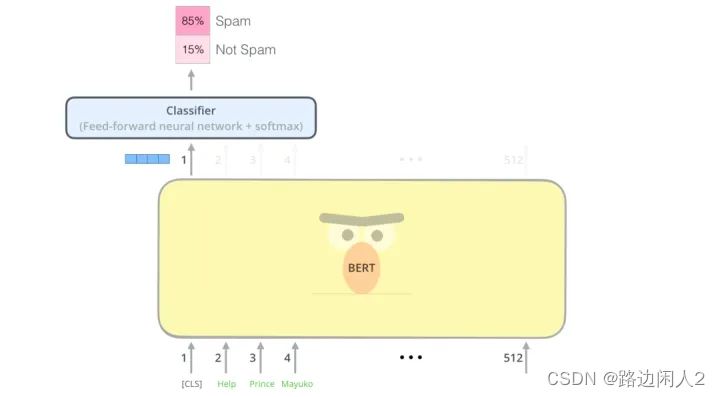
Классификация текста с использованием BERT
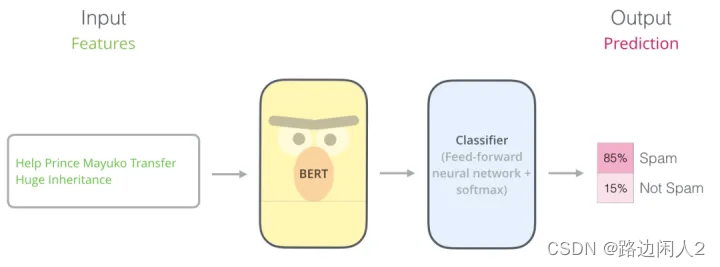
Темой этой статьи является классификация текста с использованием BERT. В этой статье мы будем использовать набор классификационных данных BBC News на Kaggle. Набор данных уже находится в формате CSV, он содержит 2126 различных текстов, каждый текст помечен в одной из 5 категорий: спорт, бизнес, политика, технологии, развлечения (развлечения).
Загрузка модели https://huggingface.co/bert-base-cased/tree/main
Загрузка набора данных bbc-news https://huggingface.co/datasets/SetFit/bbc-news/tree/main
Есть 4 файла размером более 400 МБ, а модель pytorch соответствует файлу размером 436 МБ.
Необходимо установить библиотеку преобразований
pip install transforms Все коды процессов:
# Все коды процессов
import numpy as np
import torch
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
labels = {'business':0,
'entertainment':1,
'sport':2,
'tech':3,
'politics':4
}
class Dataset(torch.utils.data.Dataset):
def __init__(self, df):
self.labels = [labels[label] for label in df['category']]
self.texts = [tokenizer(text,
padding='max_length',
max_length = 512,
truncation=True,
return_tensors="pt")
for text in df['text']]
def classes(self):
return self.labels
def __len__(self):
return len(self.labels)
def get_batch_labels(self, idx):
# Fetch a batch of labels
return np.array(self.labels[idx])
def get_batch_texts(self, idx):
# Fetch a batch of inputs
return self.texts[idx]
def __getitem__(self, idx):
batch_texts = self.get_batch_texts(idx)
batch_y = self.get_batch_labels(idx)
return batch_texts, batch_y
# подготовка набора данных
# Разделите обучающий набор, набор проверки и набор тестов. 8:1:1
import pandas as pd
bbc_text_df = pd.read_csv('./bbc-news/bbc-text.csv')
# bbc_text_df.head()
df = pd.DataFrame(bbc_text_df)
np.random.seed(112)
df_train, df_val, df_test = np.split(df.sample(frac=1, random_state=42), [int(.8*len(df)), int(.9*len(df))])
print(len(df_train),len(df_val), len(df_test))
# 1780 222 223
# Модель сборки
from torch import nn
from transformers import BertModel
class BertClassifier(nn.Module):
def __init__(self, dropout=0.5):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-cased')
self.dropout = nn.Dropout(dropout)
self.linear = nn.Linear(768, 5)
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids= input_id, attention_mask=mask,return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer
#Как видно из приведенного выше кода, BERT Classifier Модель выводит две переменные:
#1. Первая переменная_, указанная в приведенном выше коде, содержит все имена в последовательности. token из Embedding векторный слой.
#2. Именованный из Второй индивидуальныйпеременныйpooled_output содержит [CLS] token из Embedding вектор. Для задач классификации текста используйте это Embedding В качестве входных данных для классификатора этого достаточно.
# Переменнаяpooled_output затем передается на линейный уровень с функцией активации ReLU. В линейном слое выходной размер равен 5 извектор,Каждыйиндивидуальныйвектор对应于标签类别(спорт、Бизнес、политика、 развлечения и технологии).
from torch.optim import Adam
from tqdm import tqdm
def train(model, train_data, val_data, learning_rate, epochs):
# Получите наборы обучения и проверки через класс Dataset.
train, val = Dataset(train_data), Dataset(val_data)
# DataLoader получает данные на основе размера пакета и выбирает шифрование выборок во время обучения.
train_dataloader = torch.utils.data.DataLoader(train, batch_size=2, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2)
# Определите, следует ли использовать графический процессор
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
# Определить функцию потерь и оптимизатор
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)
if use_cuda:
model = model.cuda()
criterion = criterion.cuda()
# Начните входить в тренировочный цикл
for epoch_num in range(epochs):
# Определение второеиндивидуальныйпеременная,Используется для хранения обучающего набора из-за точности и потерь.
total_acc_train = 0
total_loss_train = 0
# Функция индикатора выполнения tqdm
for train_input, train_label in tqdm(train_dataloader):
train_label = train_label.to(device)
mask = train_input['attention_mask'].to(device)
input_id = train_input['input_ids'].squeeze(1).to(device)
# Получите результат по модели
output = model(input_id, mask)
# Рассчитать потери
batch_loss = criterion(output, train_label)
total_loss_train += batch_loss.item()
# Точность расчета
acc = (output.argmax(dim=1) == train_label).sum().item()
total_acc_train += acc
# Модель更新 model.zero_grad()
batch_loss.backward()
optimizer.step()
# ------ Проверить модель -----------
# Определение второеиндивидуальныйпеременная,Используется для хранения набора проверки.из Точность и потери
total_acc_val = 0
total_loss_val = 0
# Нет необходимости рассчитывать градиенты
with torch.no_grad():
# Цикл для получения набора данных,Используйте и тренируйтесь хорошоиз Модель进行验证
for val_input, val_label in val_dataloader:
# Если у вас есть графический процессор,ноиспользоватьGPU,Далее операция аналогична обучению
val_label = val_label.to(device)
mask = val_input['attention_mask'].to(device)
input_id = val_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, val_label)
total_loss_val += batch_loss.item()
acc = (output.argmax(dim=1) == val_label).sum().item()
total_acc_val += acc
print(
f'''Epochs: {epoch_num + 1}
| Train Loss: {total_loss_train / len(train_data): .3f}
| Train Accuracy: {total_acc_train / len(train_data): .3f}
| Val Loss: {total_loss_val / len(val_data): .3f}
| Val Accuracy: {total_acc_val / len(val_data): .3f}''')
#мы провели на Модель 5 индивидуальный epoch изтренироваться,насиспользовать Adam в качестве оптимизатора, а скорость обучения установлена на 1e-6.
#Поскольку в этом случае речь идет о задачах многоклассовой классификации.,ноиспользовать分类交叉熵作为насизфункция потерь。
EPOCHS = 5
model = BertClassifier()
LR = 1e-6
train(model, df_train, df_val, LR, EPOCHS)
# тест Модель
def evaluate(model, test_data):
test = Dataset(test_data)
test_dataloader = torch.utils.data.DataLoader(test, batch_size=2)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
if use_cuda:
model = model.cuda()
total_acc_test = 0
with torch.no_grad():
for test_input, test_label in test_dataloader:
test_label = test_label.to(device)
mask = test_input['attention_mask'].to(device)
input_id = test_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
total_acc_test += acc
print(f'Test Accuracy: {total_acc_test / len(test_data): .3f}')
# тестовый набор с тестданными
evaluate(model, df_test)EPOCHS = 5
model = BertClassifier()
LR = 1e-6
train(model, df_train, df_val, LR, EPOCHS)Этот этап обучения будет очень трудоемким. Даже если он будет ускорен с помощью графического процессора, он займет около 39 минут, поскольку сама модель BERT является относительно большой моделью со многими параметрами.
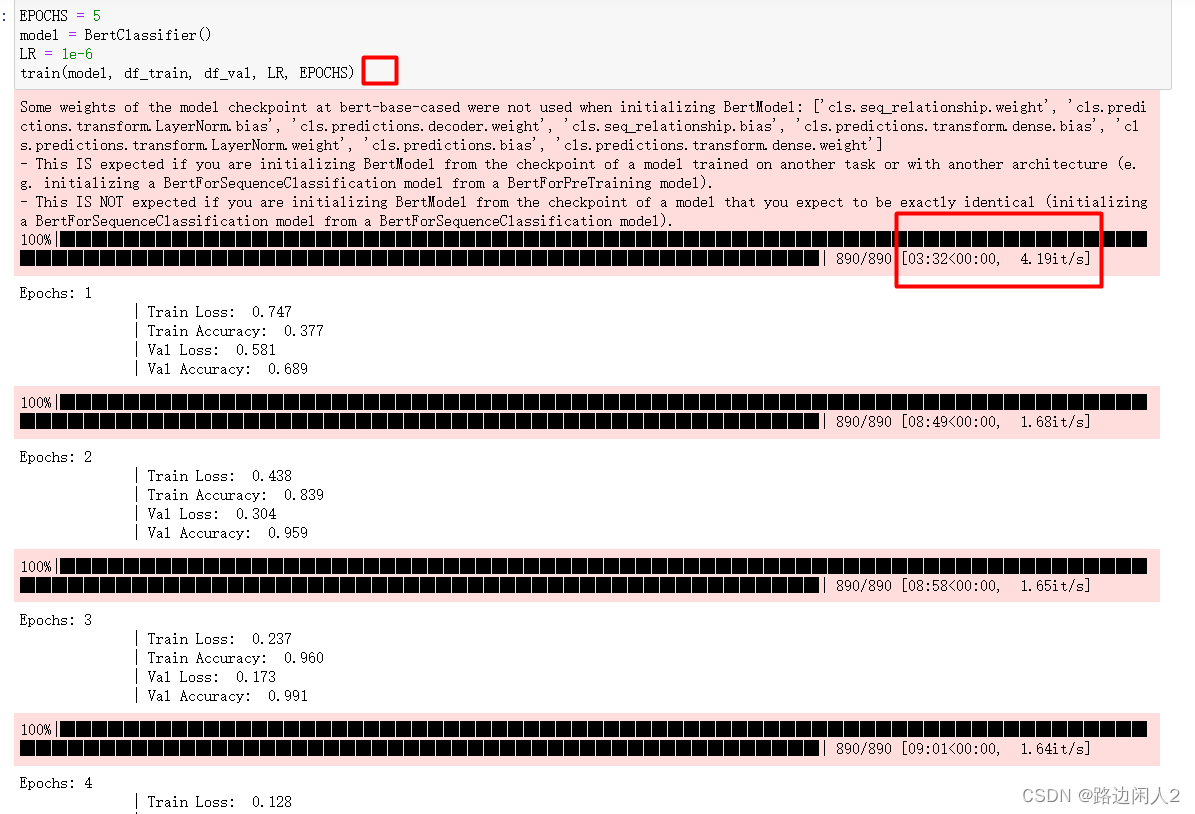
На последнем этапе тестирования точность теста все еще была относительно высокой. Достигните 99,6%

Сохраните модель. В оригинальном тексте об этом не упоминается. Если мы не сохраним модель, на обучение которой потратили много времени, не будет ли ее переобучение в следующий раз отнимать много времени и усилий?
# держать Модель
torch.save(model.state_dict(),"bertMy.pth")
# load Загрузка модели
model = BertClassifier()
model.load_state_dict(torch.load("bertMy.pth"))Вы можете использовать следующий код для просмотра модели в модели.
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())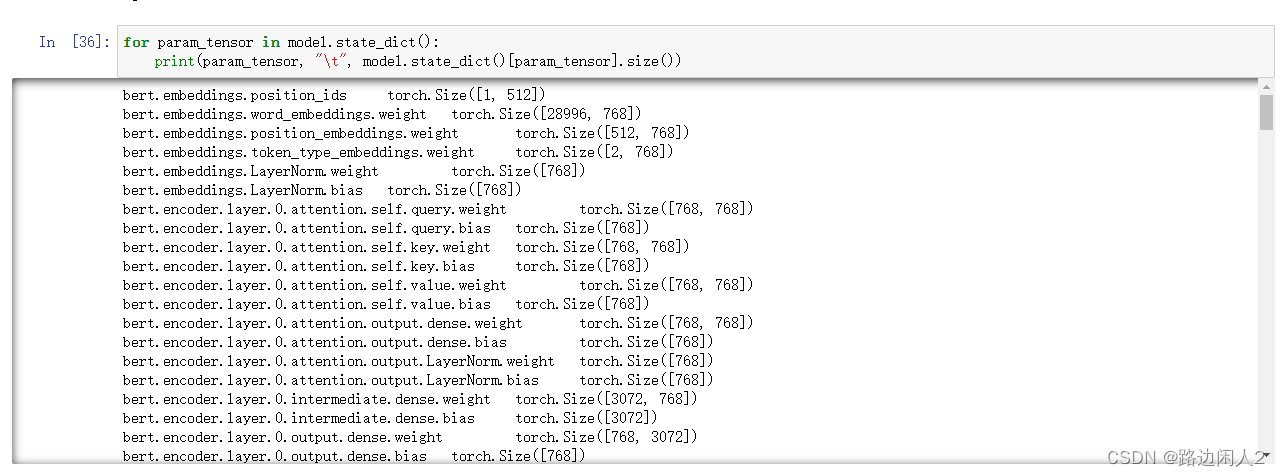
Вы также можете загрузить сохраненный файл модели bertMy.pth на веб-сайт netron для визуализации модели. Нетрон https://netron.app/
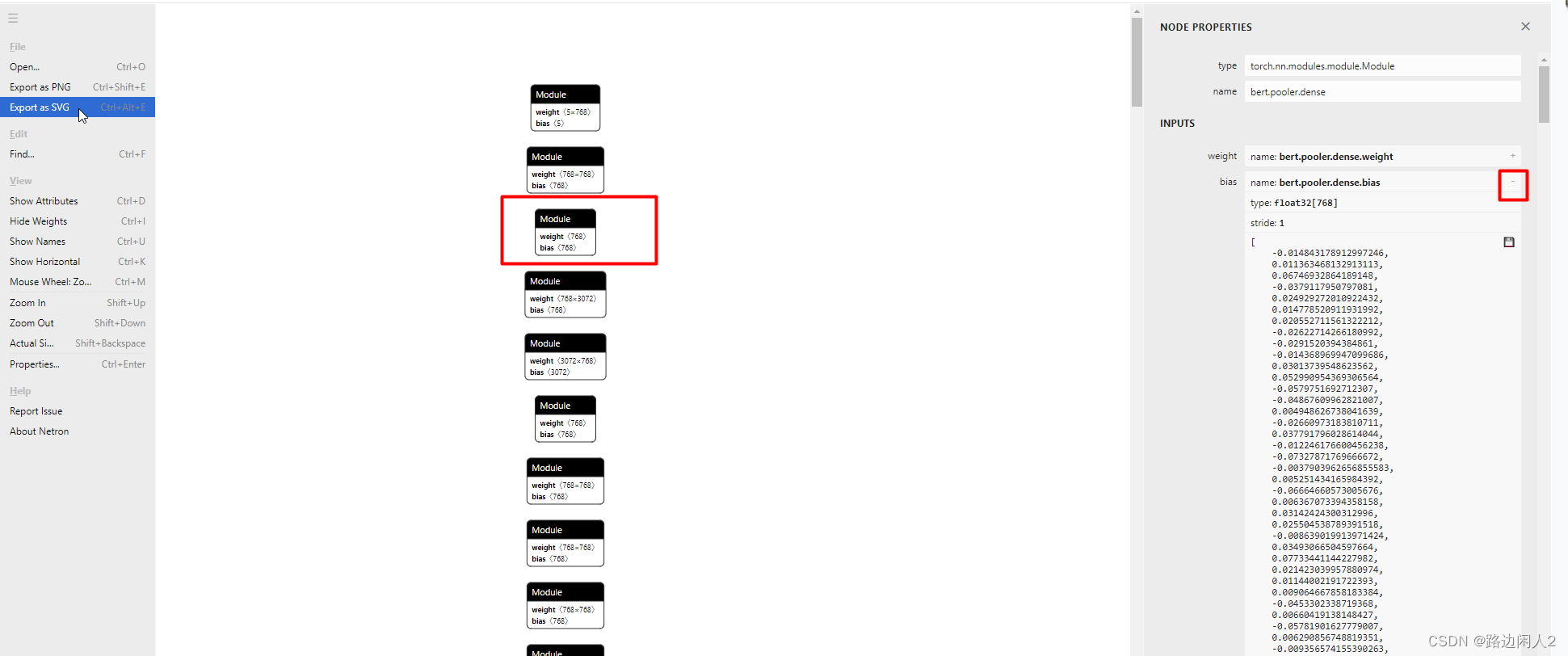
другой
ссылка:Использование pytorch для классификации текста BERT_Блог Roadside Idle Man 2 — Блог CSDN



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
