AI Framework: введение в 9 основных платформ распределенного глубокого обучения
Предисловие
Перепечатайте и переведите на Medium статью о распределенных платформах глубокого обучения. https://medium.com/@mlblogging.k/9-libraries-for-parallel-distributed-training-inference-of-deep-learning-models-5faa86199c1fmedium.com/@mlblogging.k/9-libraries-for-parallel-distributed-training-inference-of-deep-learning-models-5faa86199c1f
1. Основы обучения больших моделей
Большим моделям глубокого обучения требуется большой объем памяти для хранения таких параметров, как промежуточные активации и веса во время обучения. В результате некоторые модели можно обучить только на одном графическом процессоре с использованием очень небольшого размера пакета или даже невозможно обучить на другом процессоре. один графический процессор, что делает обучение модели очень неэффективным и в некоторых случаях невозможным.
Существует основная парадигма крупномасштабного обучения модели глубокого обучения:
- параллелизм данных
- Модель параллель
Мы обсудим основные концепции крупномасштабного обучения моделей глубокого обучения, а также последние достижения и улучшения в обучении моделей, а затем поделимся некоторыми доступными библиотеками, реализующими эти методы.
1. Параллелизм данных
Наиболее распространенный сценарий применения параллелизма данных — это когда размер модели может быть размещен в памяти графического процессора, а размер пакета данных увеличивает сложность обучения модели. Решение состоит в том, чтобы разные экземпляры модели запускались на разных графических процессорах и разных пакетах данных, как показано на изображении ниже.
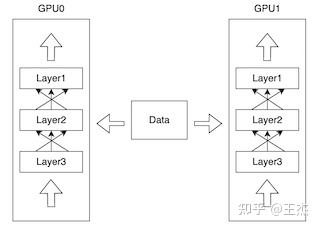
Каждый экземпляр модели инициализируется с одинаковыми параметрами, но во время прямого прохода в каждую модель отправляются разные пакеты данных. Соберите градиенты из каждого экземпляра модели и вычислите обновления градиента. , затем обновляет параметры модели и отправляет их как обновления каждому экземпляру модели.
2. Модельный параллелизм
Параллелизм моделей становится необходимым, когда один графический процессор не может вместить размер модели и для обучения необходимо разделить модель на несколько графических процессоров.
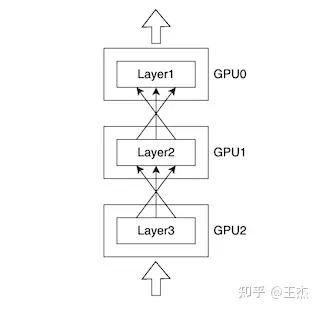
Разделив большую модель на несколько GPU При обучении размер модели может быть больше одного Обучение модели глубокого обучения памяти графического процессора. Проблема с этим подходом заключается в том, что вычисления не очень эффективны, поскольку в любой момент времени существует только один GPU являютсяиспользовать,идругой GPU В состоянии простоя.
2. Продвинутая эволюция
Вышеупомянутые две парадигмы параллельного обучения имеют различные методы оптимизации и улучшения, позволяющие сделать обучение/вывод эффективным, включая следующие:
3. Основная структура
1. Megatron-LM
Megatron — это крупномасштабная языковая модель Transformer, разработанная исследовательской группой NVIDIA по приложениям глубокого обучения и используемая для изучения крупномасштабного обучения больших языковых моделей. Megatron поддерживает параллелизм моделей (тензор, последовательность и конвейер) и предварительное обучение нескольких узлов моделей трансформаторов, а также поддерживает такие модели, как BERT, GPT и T5.
2.DeepSpeed

DeepSpeed — это библиотека глубокого обучения Microsoft, которая использовалась для обучения Megatron-Turing NLG 530B и BLOOMЖдите больших Модель。DeepSpeedиз Инновации отражаются в трех аспектах:тренироваться , рассуждение , сжатие
DeepSpeed имеет следующие преимущества:
- Обучение/вывод с миллиардами или триллионами параметров из плотной или разреженной модели
- Достигните выдающейся пропускной способности системы и эффективно масштабируйтесь до тысяч графических процессоров.
- Обучение/выводы по системам графических процессоров с ограниченными ресурсами
- Достигните беспрецедентно низкой задержки и высокой пропускной способности для вывода
- Экстремальное сжатие по низкой цене,Достигните беспрецедентной задержки вывода и уменьшения размера.
3. FairScale

FairScale(Зависит от Facebook Research) — инструмент для высокопроизводительного и масштабного обучения. PyTorch Расширить библиотеку. FairScale Видение следующее:
- Удобство использования: пользователи должны иметь возможность понимать ииспользовать с минимальными когнитивными затратами. FairScale API。
- Модификация: Пользователи должны иметь возможность беспрепятственно объединять несколько API Fairscale в часть учебного цикла.
- Производительность: airScale API Обеспечивает наилучшую производительность с точки зрения масштабирования и эффективности.
FairScale поддерживает Fully Sharded Data Parallel (FSDP), который является рекомендуемым способом масштабирования обучения крупных нейронных сетей.
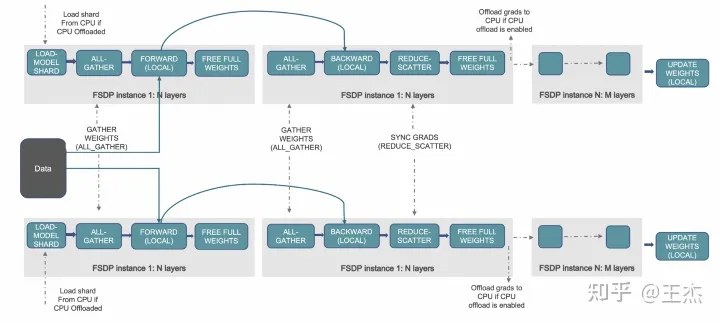
FSDP workflow from https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/
4. ParallelFormers

Parallelformers основан на Megatron-LM библиотека. это связано с Huggingface Библиотеки хорошо интегрированы. Huggingface Модели в библиотеке можно распараллелить с помощью одной строки кода. В настоящее время он поддерживает только вывод.
from transformers import AutoModelForCausalLM, AutoTokenizer
from parallelformers import parallelize
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B")
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
parallelize(model, num_gpus=2, fp16=True, verbose='detail')5. ColossalAI

Colossal-AIПредоставляет набор параллельных компонентов.,Может использоваться для индивидуального распределенного/параллельного обучения.,Содержит следующие стратегии распараллеливания и улучшения:
- Data Parallelism
- Pipeline Parallelism
- **1D,2D,2.5D,****3D**Tensor Parallelism
- Sequence Parallelism
- Zero Redundancy Optimizer (ZeRO)
- Heterogeneous Memory Management (PatrickStar)
- For Inference**Energon-AI**
6. Alpa
Alpaэто длятренироватьсяи Обслуживание крупномасштабных нейронных сетейизсистема,Он имеет следующие характеристики:
- Автоматическое распараллеливание: Альпа на основе данных、Механизм параллелизма операторов и конвейеров автоматизирует распараллеливание кода одного устройства в распределенном кластере.
- Идеальное исполнение: Альпа реализует обучение по многомиллиардным параметрам. Модельиз линейного масштабирования на распределенном кластере.
- Тесная интеграция с экосистемой машинного обучения: Alpa работает на основе открытого исходного кода.、Высокопроизводительные и готовые к работе библиотеки (например, Jax、XLA и Рэй) оказывает поддержку.
7. Hivemind
Hivemindесть один в Интернетеиспользовать Pytorch Будьте децентрализованы обучениебиблиотека. Основной сценарий его обслуживания — обучение масштабной программы на сотнях компьютеров из разных университетов, компаний и волонтеров.
Его основные особенности:
- Отсутствие распределенного обучения главного узла: распределенная хеш-таблица позволяет соединять компьютеры в децентрализованную сеть.
- Отказоустойчивое обратное распространение ошибки: проходы вперед и назад успешны, даже если некоторые узлы не отвечают или отвечают слишком долго.
- Рассредоточенное усреднение параметров: итеративно агрегируйте обновления от нескольких рабочих процессов.,и Нет необходимости синхронизировать по всей сети(бумага)。
- тренироватьсялюбой размеризнейронная сеть:онииз Некоторые слои рассеяны поиз Экспертная смесь(бумага)распределяется между участниками。
8. OneFlow
OneFlow это более глубокий обучениерамка, разработанная, чтобы быть удобной, масштабируемой и эффективной. использовать С OneFlow это легко:
- использоватьпохожий PyTorch из API писать Модель
- использовать Global View API Масштабировать модель до n Габаритно-параллельное/распределенное исполнение
- устройство Статическая диаграмма Компилятор Ускоряет/развертывание Модель.
9. Mesh-Tensorflow
в соответствии с github страница:Mesh TensorFlow (mtf) — это язык распределенного глубокого обучения, способный определять широкий класс распределенных тензорных вычислений. «Сетка» здесь относится к взаимосвязанной сети процессоров или вычислительных устройств.
другой
1. Цитата
- Survey on Large Scale Neural Network Training
- Dive into Big Model Training
- How to Train Really Large Models on Many GPUs?
- https://github.com/qhliu26/BM-Training
- https://huggingface.co/docs/transformers/v4.17.0/en/parallelism
- https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
- https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
- https://pytorch.org/tutorials/i
2.Справочник
https://zhuanlan.zhihu.com/p/582498905



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
