AAAI2024 | Поделитесь 10 отличными статьями, посвященными актуальным темам, таким как графовые нейронные сети, оптимизация больших моделей, анализ таблиц и т. д.
Тонкая настройка нейронной сети графа
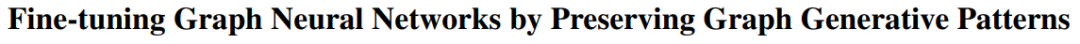
https://arxiv.org/pdf/2312.13583.pdf
В этой статье изучается и решается проблема структурной согласованности предварительного обучения и тонкой настройки графовых нейронных сетей в задачах анализа графов. Авторы обнаружили, что структурные различия между предварительно обученными и точно настроенными графами в основном проистекают из несоответствий в сгенерированных шаблонах. С этой целью автор данной статьи предложил метод G-TUNING, который эффективно поддерживает режим тонкой настройки генерации графа за счет настройки предварительно обученной нейронной сети графа.
Путем теоретического анализа доказано, что существует набор альтернативных баз графов, и их линейная комбинация может использоваться для эффективной аппроксимации режима тонкой настройки генерации графов. В эксперименте по переносу обучения по сравнению с существующим алгоритмом G-TUNING улучшился на 0,5% и 2,6% в полевых условиях и за их пределами соответственно.
Генерация шрифтов китайской каллиграфии

https://arxiv.org/pdf/2312.10314.pdf
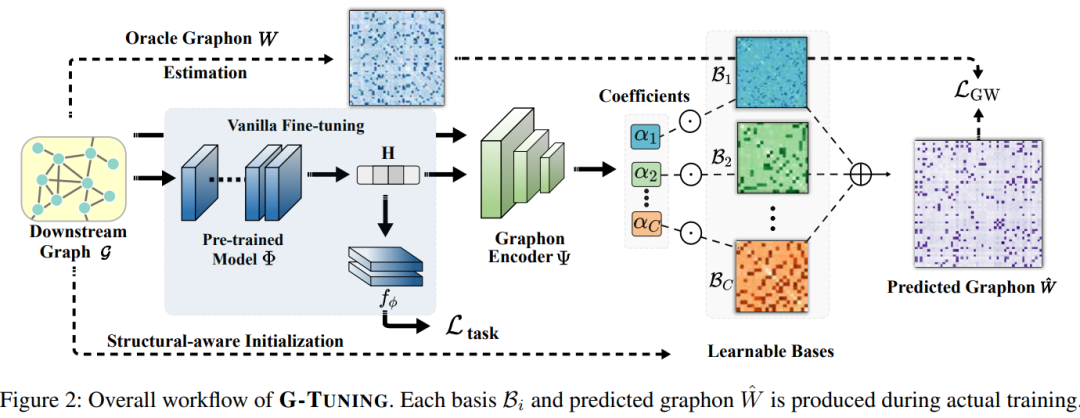
Данное исследование в основном фокусируется на проблеме небольшого размера выборки. В этой статье предлагается новая модель DeepCalliFont, которая обеспечивает синтез шрифтов китайской каллиграфии с несколькими образцами путем интеграции модели двухрежимной генерации.
Конкретно,Модель включает в себя две ветви: синтез изображений и генерацию последовательности.,Генерация последовательных результатов с помощью стратегий обучения бимодальному представлению. Эти две модальности (то есть изображения глифов и последовательности написания) разумно интегрируются посредством модуля реорганизации объектов и функции потерь при растеризации. также,Принять новую стратегию предварительной подготовки,Используя большое количество унимодальныхданныедля улучшения производительности。Качественные и количественные эксперименты доказывают, что этот метод можно использовать на небольших выборках.Генерация шрифтов китайской каллиграфии превосходит другие современные методы решения этой задачи.
RAG уменьшает количество галлюцинаций в исследовании LLM
https://arxiv.org/pdf/2309.01431.pdf
В этой статье основное внимание уделяется проблеме генерации с расширенным поиском (RAG) для смягчения галлюцинаций больших языковых моделей (LLM). В существующих исследованиях отсутствует строгая оценка влияния генерации с расширенным поиском на различные крупномасштабные языковые модели, что затрудняет выявление потенциальных узких мест RAG в возможностях различных LLM. В этой статье систематически исследуется влияние генерации с расширенным поиском на большие языковые модели.
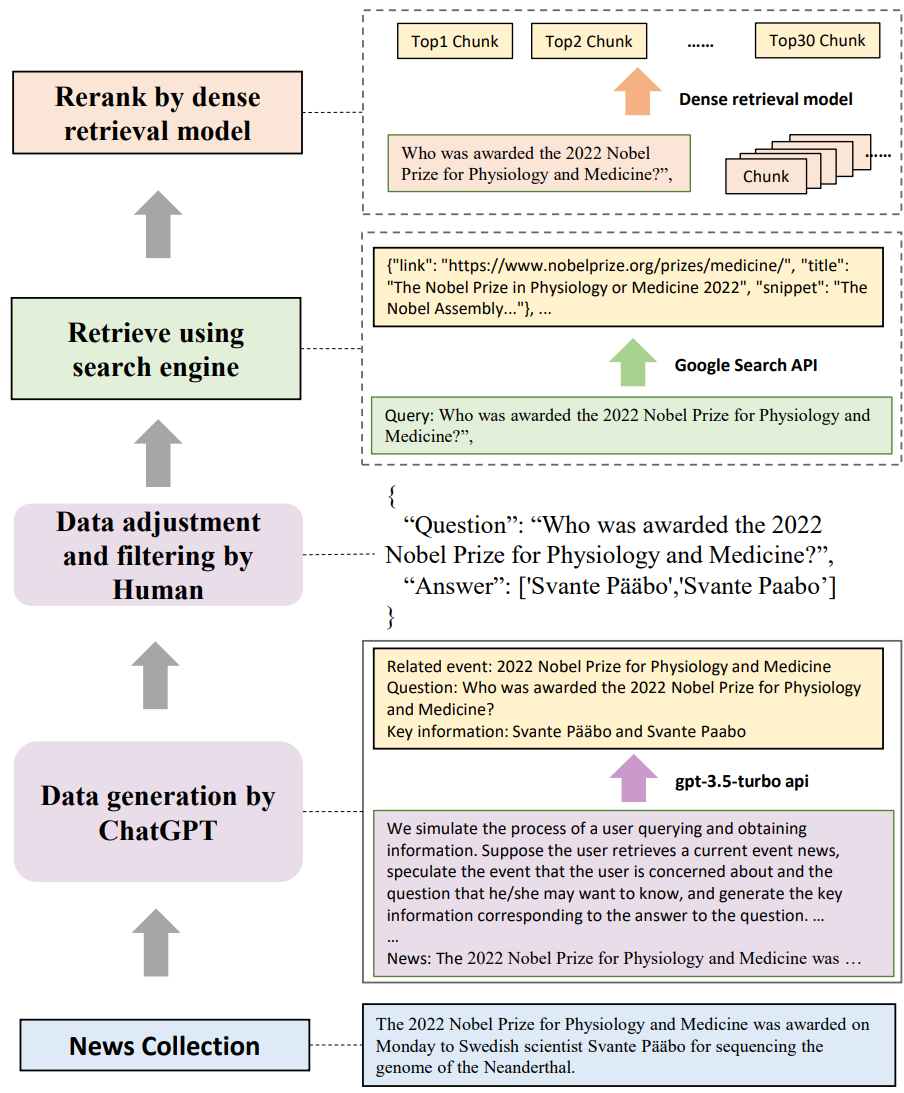
В этой статье анализируется производительность различных крупномасштабных языковых моделей по четырем основным возможностям, необходимым RAG, включая устойчивость к шуму, отклонение отрицательных примеров, интеграцию информации и устойчивость к контрфактам. С этой целью в настоящем документе создается эталонный тест расширенного поколения (RGB) — новый корпус для оценки RAG на английском и китайском языках. RGB делит экземпляры в тесте на 4 независимых набора тестов на основе вышеуказанных основных возможностей, необходимых для решения задачи. Затем мы оцениваем 6 репрезентативных LLM по RGB, чтобы диагностировать проблемы текущих LLM при применении RAG. Оценка показывает, что, хотя LLM в определенной степени устойчивы к помехам, все еще существуют значительные трудности с отклонением отрицательных примеров, интеграцией информации и обработкой ложной информации. Результаты показывают, что по-прежнему существуют значительные проблемы в эффективном применении RAG к LLM.
анализ табличных данных

https://arxiv.org/pdf/2312.13671.pdf
Это исследование в основном сосредоточено на анализе табличных данных Проблемы в поле,Текущие исследования в основном сосредоточены на базовых задачах, таких как Text2SQL и TableQA.,Расширенная аналитика, такая как прогнозирование и создание диаграмм, игнорируется.
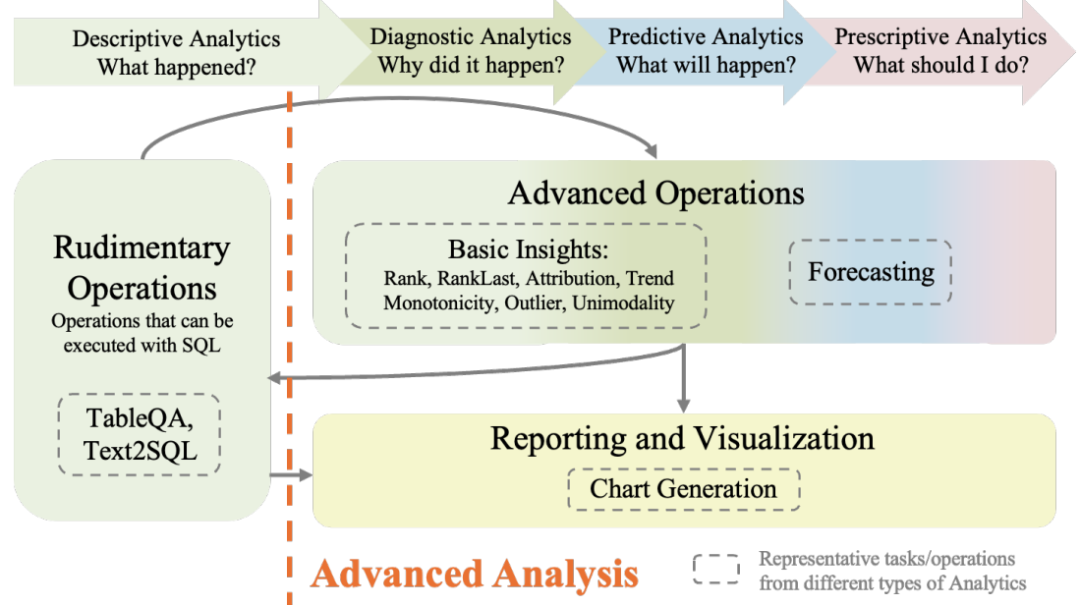
Чтобы восполнить этот пробел, в данной статье предлагается тест Text2Analysis, охватывающий задачи расширенного анализа, выходящие за рамки операций, совместимых с SQL. В этой статье также разрабатываются пять инновационных и эффективных методов аннотирования, которые полностью используют возможности больших языковых моделей и улучшают качество и количество данных. Кроме того, вводятся неопределенные запросы, похожие на реальные проблемы пользователей, чтобы проверить способность модели понимать и решать такие проблемы.
финальный,В этой статье собрано 2249 пар запрос-результат и 347 листов.,Оценка пяти современных моделей с использованием трех различных показателей оценки,Результаты показывают, что эталон этой статьи находится ванализ табличных Область данных ставит серьезные проблемы.
Когнитивный диагноз с нулевой выборкой

https://arxiv.org/pdf/2312.13434.pdf
Исследования в этой статье в основном сосредоточены на Когнитивном уровне. диагноз с нулевой выборкой (DZCD), проблема связана с отсутствием журналов практики студентов в новой области. Недавняя междоменная диагностика оказалась стратегией решения проблемы DZCD, но эти подходы в основном на Как перенести статус студента между полями。Однако,Они могут непреднамеренно включать непередаваемую информацию в представления учащихся.,Тем самым ограничивая эффект передачи знаний.
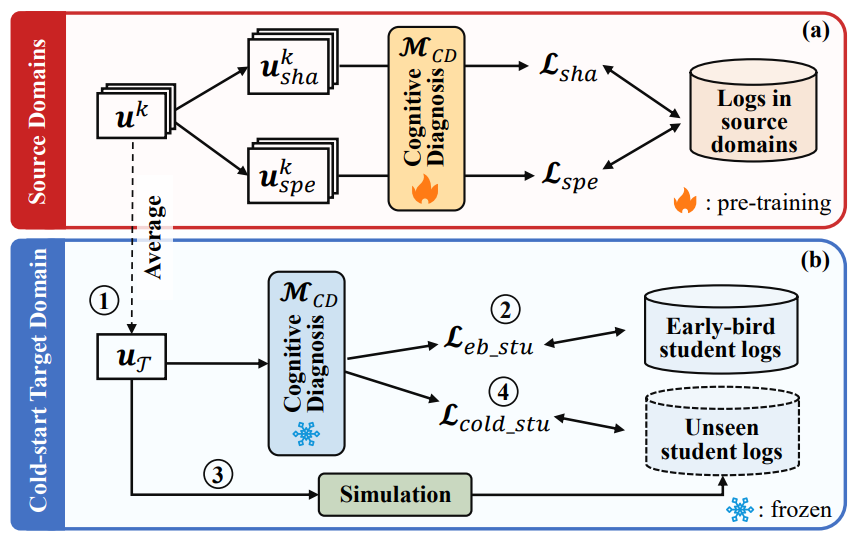
Чтобы решить эту проблему, в данной статье предлагается технология «от нуля до трех», которая реализует передачу когнитивных сигналов в пределах домена и генерацию виртуальных данных через первых учеников, а также эффективно справляется с отсутствием журналов практики студентов в новых областях. Общие когнитивные сигналы могут передаваться в целевое поле, обогащая когнитивные априоры в новом поле и обеспечивая цель распространения когнитивного состояния. Обширные эксперименты на шести реальных наборах данных демонстрируют эффективность нашей модели в DZCD и ее практическое применение в рекомендациях по вопросам.
динамический сетевой подход
https://arxiv.org/pdf/2312.13068.pdf
Исследования в этой статье в основном сосредоточены на движущей силе. сетевой Ограничения подхода при работе с сетями, которые постоянно меняются во времени. В данной статье предлагается новый стохастический процесс, основанный на функциях выживания, для моделирования устойчивости и отсутствия связей во времени. Это формирует новую общую норму правдоподобия, которая явно учитывает прерывистые сети с постоянными границами, а именно GRASP: Граф Representation with Sequential Survival Process。
В данной статье эта структура применяется к ближайшей модели динамического скрытого расстояния непрерывного времени, чтобы охарактеризовать динамику сети как последовательность кусочно-линейных движений узлов в скрытом пространстве. Мы выполняем количественные оценки различных последующих задач, таких как прогнозирование каналов и завершение работы сети, и результаты показывают, что наша система моделирования может эффективно отслеживать внутреннюю траекторию узлов в скрытом пространстве и фиксировать основные характеристики развивающейся сетевой структуры.
Обнаружение ошибок KG
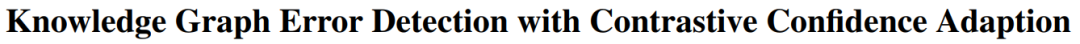
https://arxiv.org/pdf/2312.12108.pdf
Исследования в этой статье в основном сосредоточены на различных проблемах ошибок, существующих в графах знаний (KG). В этой статье предлагается модель обнаружения ошибок KG CCA, которая объединяет информацию о структуре текста и графа посредством тройной реконструкции, чтобы лучше различать семантику.
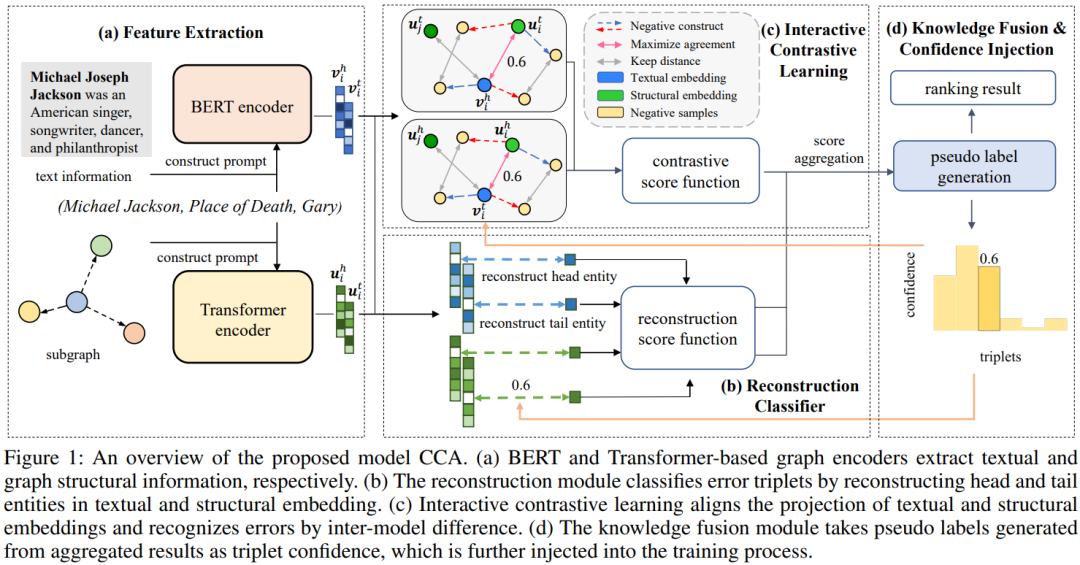
В этой статье используется интерактивное контрастивное обучение, чтобы выявить различия между текстовыми и структурными шаблонами. Кроме того, в этой статье создается реальный набор данных, содержащий шум семантического сходства и шум состязательности. Экспериментальные результаты показывают, что CCA превосходит современные базовые методы в обнаружении шума семантического сходства и состязательного шума.
Генерация интеллект-карт
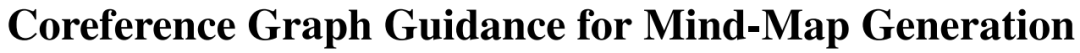
https://arxiv.org/pdf/2312.11997.pdf
Это исследование в основном посвящено Генерации Проблемы в интеллект-карте,То есть, хотя существующие методы могут генерировать интеллект-карты параллельно,,но в основном фокусируется на последовательных функциях,Трудно получить структурную информацию.,В частности, возникают трудности при моделировании долгосрочных семантических связей.
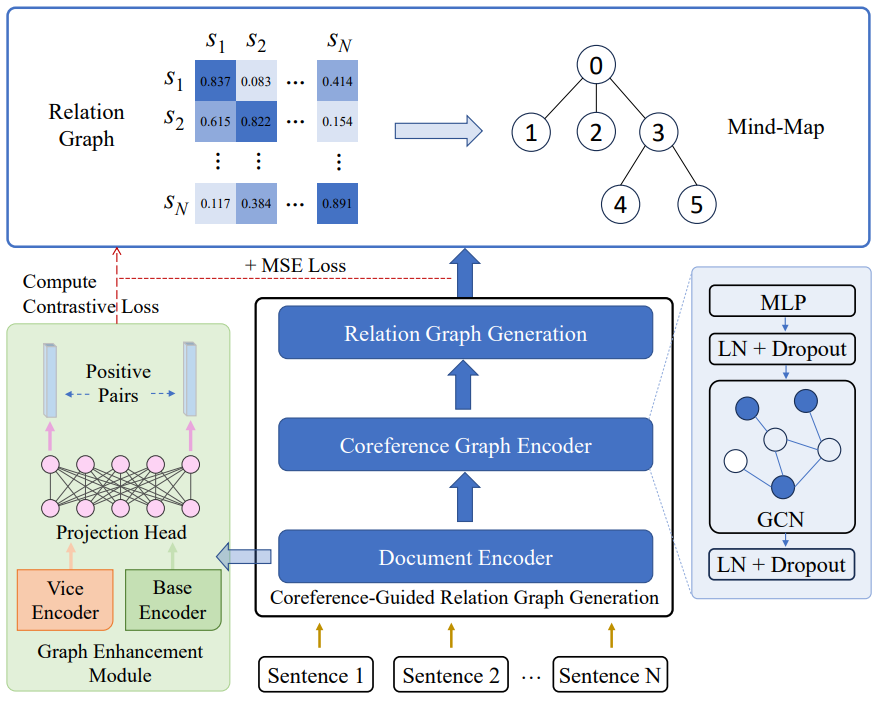
В этой статье предлагается Генерация на основе обозначений. интеллектуальная картографическая сеть (CMGN),ввести внешние структурные знания. Конкретно,В этой статье строится граф анафоры на основе семантических отношений анафоры.,Ввести информацию о структуре графа. Затем,Анализ скрытых связей между предложениями с помощью кодировщика графа кореферентности.
Чтобы устранить шум и лучше использовать информацию, относящуюся к графику, в этой статье используется модуль улучшения графа в методе контрастного обучения. Результаты экспериментов показывают, что наша модель превосходит все существующие методы. Тематическое исследование также доказывает, что наша модель может более точно и лаконично раскрыть структуру и семантику документов.
Подсказка по мультимодальному выравниванию
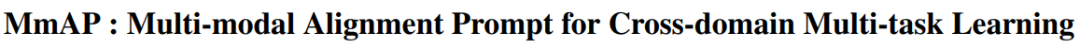
https://arxiv.org/pdf/2312.08636.pdf
Это исследование в основном сосредоточено на проблеме, заключающейся в том, что декодер становится более сложным по мере увеличения количества задач в многозадачном обучении. В этой статье предлагается метод интеграции модели визуального языка CLIP без декодера, которая демонстрирует сильные возможности обобщения с нулевым выстрелом.
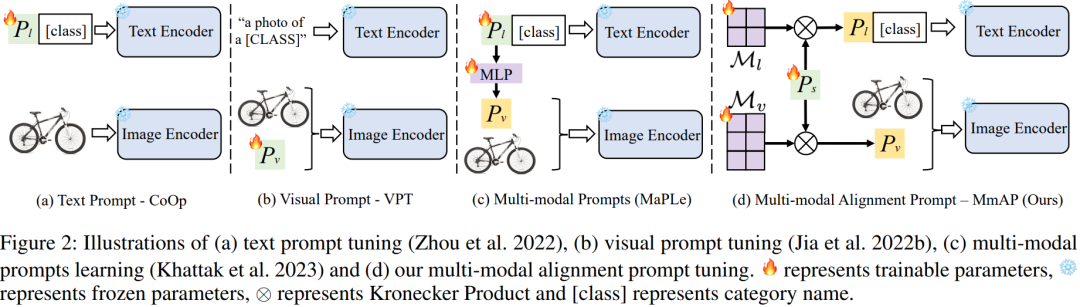
В этой статье впервые предлагается метод Multimodal Alignment Prompt (MmAP) для выравнивания текста и визуальных модальностей во время тонкой настройки. На основе MmAP в этой статье разрабатывается инновационная многозадачная система быстрого обучения. С одной стороны, чтобы максимизировать взаимодополняемость подобных задач, с другой стороны, чтобы сохранить уникальные характеристики каждой задачи, каждой задаче присваивается определенный MmAP;
Комплексные эксперименты с двумя крупномасштабными наборами данных многозадачного обучения показывают, что наш метод обеспечивает значительное улучшение производительности по сравнению с полной точной настройкой, используя при этом только примерно 0,09% обучаемых параметров.
Выравнивание меток для нескольких моделей
https://arxiv.org/pdf/2312.08212.pdf
Это исследование в основном сосредоточено на проблеме успешного переноса предварительно обученных моделей на последующие задачи в области визуального языка (ВЛ). Предыдущие методы в основном фокусировались на создании шаблонов подсказок для текстовых и визуальных входных данных, игнорируя разрыв в представлении меток категорий между моделями VL и последующими задачами.
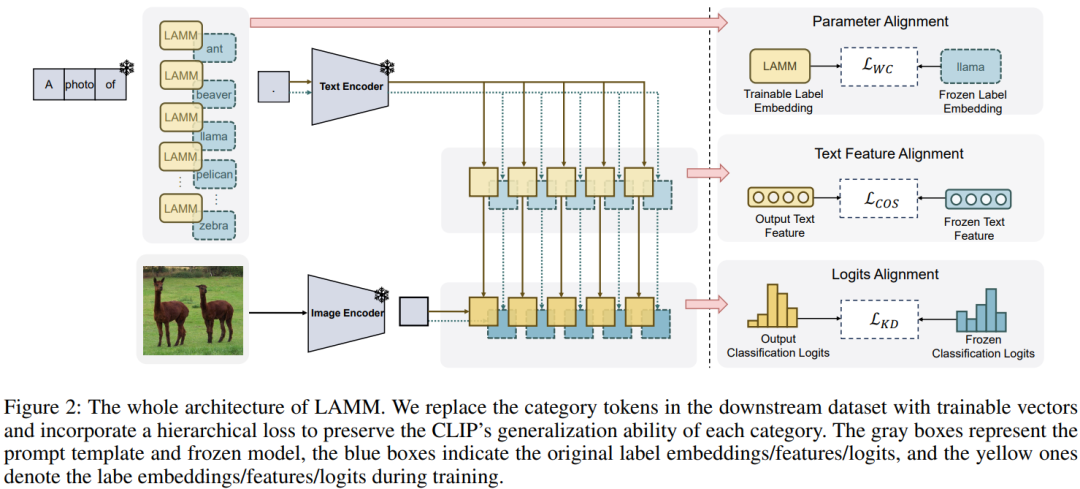
Чтобы решить эту проблему, в этой статье представлен инновационный метод выравнивания меток, называемый LAMM, для динамической корректировки встраивания категорий последующих наборов данных посредством сквозного обучения. Кроме того, чтобы получить более подходящее распределение меток, в этой статье предлагается иерархическая потеря, включая выравнивание пространства параметров, пространства признаков и пространства логитов. Мы проводим эксперименты на 11 последующих наборах визуальных данных, чтобы продемонстрировать, что наш метод значительно улучшает производительность существующих моделей мультимодального обучения сигналам в сценариях с несколькими кадрами, со средней точностью 11 по сравнению с современным методом с 16. изображений Увеличение на 2,31%.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
