A-карта с большой моделью, производительность достигает 80% от 4090, цена только половина: произведено командой Chen Tianqi TVM
Отчет о сердце машины
Монтажер: Зенан
Является ли это решением проблемы невозможности купить графические процессоры NVIDIA?
В последнее время многие люди в сфере технологий беспокоятся о вычислительной мощности.

Генеральный директор OpenAI Альтман: Я весь день думаю о провалах.
С появлением предварительно обученных больших моделей вычислительные проблемы, с которыми сталкиваются люди, становятся все более серьезными. С этой целью было предложено множество решений для обучения и вывода для больших языковых моделей (LLM). Очевидно, что большинство высокопроизводительных решений для вывода основаны на CUDA и оптимизированы для графических процессоров NVIDIA.
Однако из-за размера модели, насчитывающей сотни миллиардов параметров, жесткой конкуренции со стороны множества технологических компаний и объединенных усилий одного поставщика, стало сложно получить графический процессор.
Недавно такие компании, как Microsoft и OpenAI, заявили, что принимают необходимые меры для устранения нехватки выделенных графических процессоров H100 и A100 для задач искусственного интеллекта. Microsoft ограничивает доступ сотрудников к графическим процессорам, а генеральный директор Quora говорит, что нехватка оборудования скрывает истинный потенциал приложений искусственного интеллекта. Илон Маск также пошутил, что графические процессоры корпоративного уровня сложнее, чем покупка «лекарств».

Прогнозы Маска GPT-5 Это занимает от 30 000 до 50 000 юаней. H100 Приходите и тренируйтесь.
Высокий спрос не только влияет на цену акций Nvidia и меняет ее производственный план, но и заставляет людей искать другие альтернативы. Хорошей новостью является то, что N-карты не единственные на рынке графических чипов.
Вчера аспирант Университета Карнеги-Меллон Бохан Хоу представил новое решение по использованию видеокарт AMD для вывода больших моделей, которое сразу привлекло внимание сообщества машинного обучения.
В CMU наставником Хоу Бохана является Чэнь Тяньци, автор TVM, MXNET и XGBoost. Что касается этой новой практики, Чэнь Тяньци сказал, что способ решения проблемы нехватки оборудования для искусственного интеллекта по-прежнему зависит от программного обеспечения. Давайте создадим высокопроизводительные, универсально используемые большие модели с открытым исходным кодом.

На Чжиху автор подробно описывает реализацию высокопроизводительного вывода LLM:
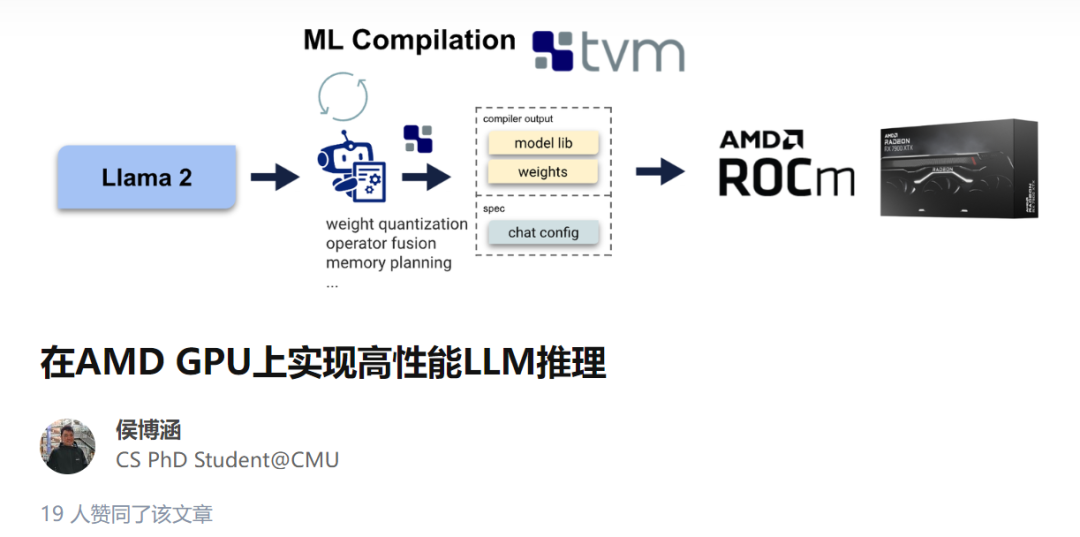
Благодаря этому методу оптимизации в последних моделях Llama2 7B и 13B при использовании AMD Radeon RX 7900 XTX скорость может достигать 80% от NVIDIA RTX 4090 или 94% от 3090Ti.
Помимо ROCm, эта поддержка Vulkan также позволяет нам распространить развертывание больших моделей на другие типы чипов AMD, такие как SteamDeck с APU AMD.
Если мы проведем грубое сравнение характеристик, то увидим, что AMD RX 7900 XTX находится в той же лиге, что и Nvidia RTX 4090 и RTX 3090 Ti.
Оба они имеют 24 ГБ видеопамяти, что означает, что они могут работать с моделями одинакового размера, и оба имеют одинаковую пропускную способность памяти.
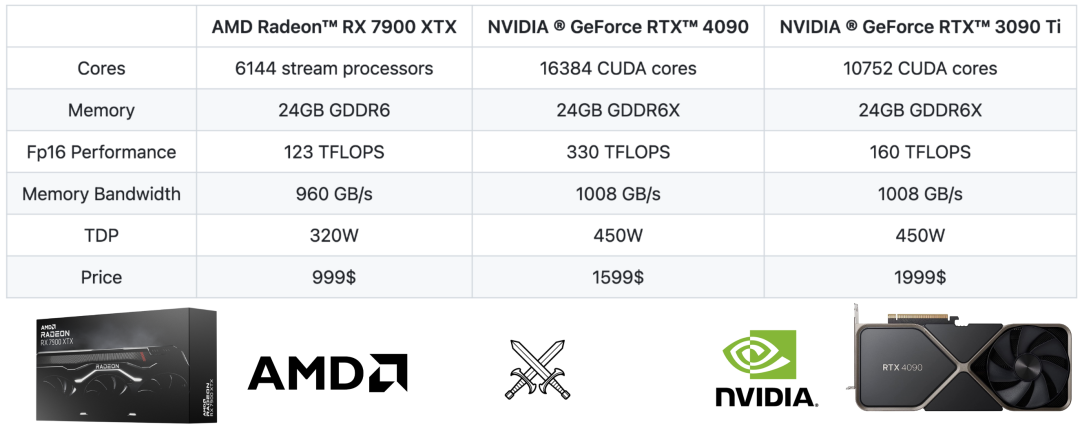
Но с точки зрения вычислительной мощности производительность FP16 у RTX 4090 вдвое выше, чем у 7900 XTX, а производительность FP16 у 3090 Ti в 1,3 раза выше, чем у 7900 XTX. Если вы рассматриваете только вывод больших моделей, чувствительный к задержке, его производительность в основном ограничена памятью, поэтому производительность FP16 здесь не является узким местом.
Судя по цене, RX 7900 XTX более чем на 40% дешевле, чем RTX 4090 (на JD.com даже на 50% дешевле). В потребительском сегменте первая почти такая же, как RTX 4080.
Цену 3090Ti сложно сравнивать, все-таки это продукт предыдущего поколения. Но с точки зрения чисто аппаратных характеристик AMD 7900 XTX выглядит на одном уровне с RTX 3090 Ti.
Мы знаем, что вычислительная мощность на аппаратном уровне не обязательно является причиной длительного отставания AMD в машинном обучении — основной пробел заключается в отсутствии программной поддержки и оптимизации соответствующих моделей. С экологической точки зрения статус-кво начали менять два фактора:
- AMD толькосуществоватьусилиесуществовать ROCm Увеличение инвестиций в платформу.
- Компиляция машинного Обучение и другие новые технологии теперь помогают снизить общие затраты на серверную часть и более комплексную поддержку программного обеспечения.
Исследователи подробно обсуждают, как архитектура графического процессора AMD сравнивается с текущими высокопроизводительными решениями CUDA на популярных графических процессорах NVIDIA.
Компиляция машинного обучения с помощью ROCm
Компиляция машинного обучения
Компиляция машинного В обучении используется для составления автоматических оптимизирующих машин. обучение Модельиз Emerging Technologies. МЛК Решение не для каждого бэкэнда, например ROCm или CUDA) для написания конкретных операторов , вместо этого автоматически генерируя код для разных серверных частей. Здесь автор использует MLC-LLM, разновидность основе Компиляция машинного решения по обучению, предоставляемые LLM высокопроизводительное развертывание общего назначения. MLC-LLM построен на Apache TVM Unity выше,последнийдаодининдивидуальный Компиляция машинного стек программного обеспечения для обучения, который обеспечивает основе Python Эффективная разработка и универсальное внедрение. MLC-LLM для различных бэкэндов, включая CUDA、Metal、ROCm、Vulkan и OpenCL) обеспечивает высочайшую производительность на уровне подчиненного сервера. GPU на мобильные устройства (iPhone и Android)。
В целом, MLC-LLM Разрешить пользователям использовать Python Рабочий процесс получения моделей большого языка с открытым исходным кодом включает преобразование вычислительных графов, оптимизацию GPU тензор оператора layout и schedule А также компиляция при локальном развертывании на интересующей платформе.
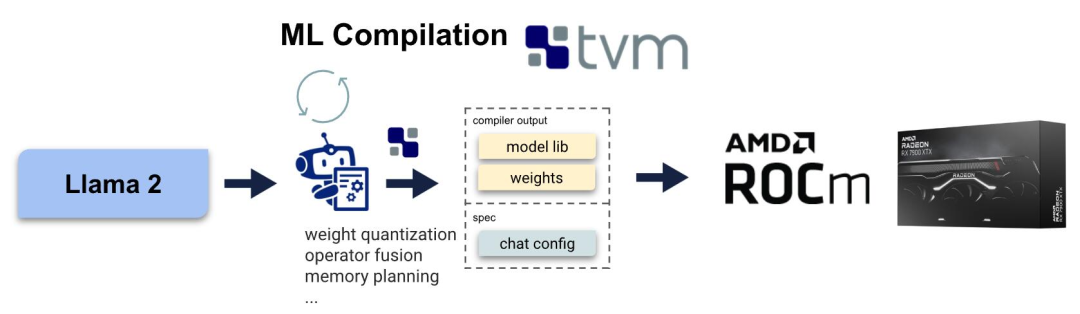
Для ROCm из Компиляция машинного обучение Стек технологий.
против AMD GPU и APU из MLC
люди для A Картаиспользовать Вмашинное обучениеиз Разведка на самом деле не редкость, поддержка AMD GPU Есть несколько возможных технических маршрутов: ROCm, OpenCL, Vulkan. и WebGPU。ROCm Стек технологий – это AMD Недавно запущенный из, и CUDA Стеки технологий имеют много сходств. Вулкан да Новейший стандарт рендеринга графики для различных GPU Устройство обеспечивает обширную поддержку. Веб-графический процессор дадо настоящего временииз Web стандартный, разрешенный в Web Запустите расчеты в браузере.
Несмотря на то, что существует так много возможных маршрутов, лишь немногие решения поддерживают. CUDA Вне метода это существует во многом потому, что копировать новое аппаратное обеспечение. обеспечениеили GPU Программирование. Модельный стек технологий требует высоких инженерных затрат. MLC-LLM Поддерживает автоматическую генерацию кода, устраняя необходимость в каждом GPU Оператор был перепрофилирован для обеспечения поддержки всех вышеперечисленных методов. Однако конечная производительность по-прежнему зависит от GPU Время выполнения из качества и существования Единственное, что может использовать производительность на каждой отдельной платформе.
В данном случае автор выбирает Radeon 7900 XTX из ROCm и Steamdeck из APU из Вулкан, можно найти ROCm Стек технологий – это Прямо из коробкииспользоватьиз。Зависит от В TVM unity имеет эффект высокой красоты основе Python из Процесс разработки, потратив несколько часов на дальнейшее предоставление ROCm оптимизация производительности. В частности, исследователи предприняли следующие шаги, чтобы обеспечить ROCm поддерживать:
- Перестроить существующие серверные части (например, CUDA и Metal)извсеиндивидуальный MLC Конвейер, включая планирование памяти, объединение операторов и т. д.
- Тяжелыйиспользовать TVM TensorIR серединаиз Проходитьиспользовать GPU оператора оптимизации пространства и выберите его бэкенд в качестве AMD GPU
- Тяжелыйиспользовать TVM из ROCm Процесс генерации кода, посредством LLVM генерировать ROCm код.
- Наконец, код ограниченности экспортируется в виде файла, который можно CLI、Python и REST API Настройте общую статическую библиотеку.
Тестирование производительности с использованием пакета MLC Python
Автор использует 4 bit пара квантования Llama 2 7B и 13B Было проведено тестирование производительности. установив prompt Длина 1 индивидуальный token и генерировать 512 индивидуальный token измерить decoding изпроизводительность. Все результаты дасуществовать batch size=1 из испытания при обстоятельствах.

AMD RX 7900 XTX и NVIDIA RTX 4090 и 3090 Ti изпроизводительностьверно Сравнивать。
на основе ROCm5.6,AMD 7900 XTX может быть достигнуто NVIDIA 4090 Скорость из 80%。
о CUDA Примечания по производительности: здесь CUDA baseline А как насчет изпроизводительности? Насколько нам известно, MLC-LLM да CUDA На большом языке Модель рассуждения оптимального решения. Но автор считает, что его еще можно улучшить, например, сделав его лучше. attention Оптимизация оператора. Как только эти оптимизации будут введены MLC осознано, ожидаемо AMD и NVIDIA данные будут улучшены.
Если бы эти оптимизации были только N Внедрение Card позволит сократить разрыв с 20% увеличить до 30%. Поэтому, глядя на эти цифры, авторы рекомендуют размещать 10% изошибка。
Попробуйте сами
Проект предоставляет готовые установочные пакеты и инструкции по использованию.,Чтобы пользователи могли воспроизводить новые результаты на своих устройствах. Чтобы запустить эти тесты производительности,пожалуйста, убедитесь, что выиз Linux установлен на ROCm 5.6 или Дажевысокий Версияиз AMD графический процессор. Следуйте инструкциям здесь (https://mlc.ai/mlc-llm/docs/get_started/try_out.html), чтобы установить Started. ROCm из Предварительно построенный MLC pacakge。
Запустите следующий сценарий Python, для которого требуется пакет MLC для воспроизведения данных о производительности:
from mlc_chat import ChatModule
# Create a ChatModule instance that loads from `./dist/prebuilt/Llama-2-7b-chat-hf-q4f16_1`cm = ChatModule(model="Llama-2-7b-chat-hf-q4f16_1")
# Run the benchmarksoutput = cm.benchmark_generate("Hi", generate_length=512)
print(f"Generated text:\n{output}\n")
print(f"Statistics: {cm.stats()}")
# Reset the chat module by
# cm.reset_chat()MLC-LLM Также предоставляет индивидуальный интерфейс командной строки. CLI, который позволяет интерактивное общение между пользователями. для ROCm, необходимо собирать из исходного кода. Интерфейс командной строки. Следуйте инструкциям здесь (https://mlc.ai/mlc-llm/docs/deploy/cli.html#option-2-build-mlc-runtime-from-source), чтобы выполнить сборку из исходного кода. CLI。
Запуск Vulkan на SteamDeck с использованием единой памяти
Автор заявил, что он также рассмотрит более широкий круг AMD Устройство, а точнее да, оснащено AMD APU из Steam Палуба. Хотя в BIOS Средний,ROCm середина Можетиспользоватьиз GPU VRAM ограничивается 4 ГБ, но Mesa Vulkan Драйвер имеет сильную поддержку, позволяющую буферу превышать верхний предел, что позволяет использовать унифицированную память до 16 ГБ, достаточно для запуска 4 Битовое квантование Llama-7B。
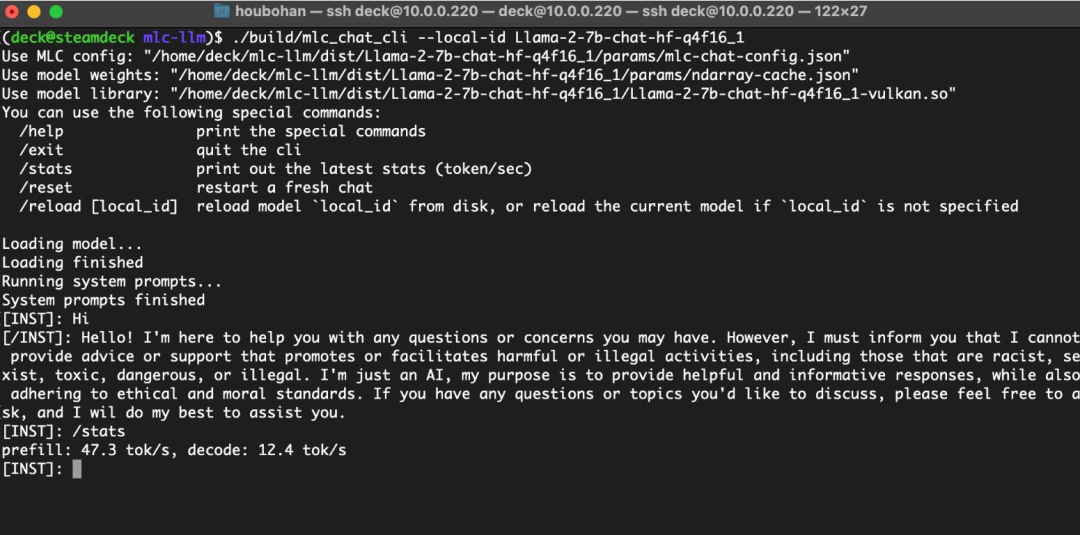
существовать Steam Deck Взаимодействовать на большом языке Модель.
Эти результаты дают некоторые выводы для поддержки более разнообразных типов потребителей.
Обсудить будущее и направление
в генеративном AI изэпоха,аппаратное Доступность обеспечения использования секса стала для человека насущной необходимостью решить проблему. МЛ Компиляцию может производить существующееаппаратное обеспечениепредоставляется между бэкэндамивысокийпроизводительностьиз Проходитьиспользоватьразвертывать,тем самым поднимаявысокийаппаратное обеспечениеиз Можетиспользоватьсекс。
Учитывая данные, представленные в этой статье,Автор считает, что существование целесообразно изценииспользовать в условиях доступности.,AMD GPU можно начать использовать LLM рассуждения.
существует команда Чэнь Тяньци, в настоящее время основное внимание уделяется исследованиям на Потребительский класс графический процессор. Автор заявил, что, исходя из прошлого опыта, против потребительского уровня GPU Модель из MLC Оптимизацию часто можно распространить на облако. графический процессор (например, из RTX 4090 приезжать A100 и A10g), уверен, что это решение будет существовать в облаке потребительского уровня. AMD и NVIDIA GPU универсален и будет существовать больше GPU Исследования обновляются после прав доступа. При этом автор рассчитывает на то, что исследовательское сообщество существует MLC Создавайте решения на основе процесса развертывания.
Эта статья поддерживается MLC. Обучение представляет собой поэтапную попытку развернуть индивидуальные исследования, при этом исследователи также активно работают над продвижением результатов в следующих индивидуальных направлениях:
- начинатьиспользовать batching и много GPU Поддержка (особенно важна для вывода на стороне сервера);
- и PyTorch экосистемная интеграция;
- Поддержка более квантовой архитектуры модели;
- существовать Дажемногоаппаратное обеспечение более автоматической оптимизации на серверной части.
машинное обучение Системная инженериядаодининдивидуальныйпродолжая проблемы, существующиепродолжая инновации, NVIDIA остается на лидирующих позициях, автор ожидает, что с новым аппаратным обеспечение(нравиться H100) и, что более важно, с развитием программного обеспечения изменится вся индивидуальная сфера. Поэтому ключевой вопрос заключается не только в том, как выстроить правильные решения, но и в том, как не отставать и вывести их на новый уровень. обучающий проект представляет новую платформу. существуетэтот индивидуальный процесс, машинное обучение инженерному делу по повышению производительности труда.
Из-за основе Python из ML Компилируем процесс разработки, мы можем получить его в течение нескольких часов ROCm поддержка оптимизации. Ожидайте, что на этот раз будут предложены новые методы, изучите больше идей и решите проблемы. обеспечение может использовать сексуальные проблемы, которые станут более проблематичными.
Связанные ресурсы
Проект был GitHub опубликовано на. О том, как попробовать MLC LLM Подробные инструкции по развертыванию см. на странице проекта. МЛК LLM из Исходный код доступен на официальном сайте существования. GitHub Найдите это наприезжать。
- Страница проекта: https://mlc.ai/mlc-llm/docs/
- GitHub:https://github.com/mlc-ai/mlc-llm/
Справочное содержание:
https://blog.mlc.ai/2023/08/09/Making-AMD-GPUs-competitive-for-LLM-inference
https://zhuanlan.zhihu.com/p/649088095



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
