6 шаблонов событийно-ориентированной архитектуры

Автор Натан Сильницкий
Переводчик |
Планирование |
В течение прошлого года я был частью команды Data Flow, отвечающей за инфраструктуру обмена сообщениями Wix, управляемую событиями (на основе Kafka). Эту инфраструктуру используют более 1400 микросервисов. За это время я реализовал или стал свидетелем нескольких ключевых шаблонов проектирования событийно-ориентированных сообщений, которые помогают создать надежную распределенную систему, способную легко справляться с растущими требованиями к трафику и хранилищу.
1Потребление и прогноз
Для услуг, которые настолько широко используются, что стали узкими местами
Этот шаблон может помочь, если у вас есть устаревшая служба, хранящая данные для больших объектов предметной области, которые используются настолько широко, что устаревшая служба становится узким местом.
В Wix мы сталкиваемся с такой ситуацией с нашим сервисом MetaSite, который сохраняет много метаданных для каждого сайта, созданного пользователем Wix, например, версию сайта, владельца сайта и какие приложения установлены на сайте — контекст установленных приложений ( Контекст установленных приложений.).
Эта информация ценна для многих других микросервисов (команд) в Wix, таких как Wix Stores, Wix booking, Wix Restaurants и многих других. Сервис был засыпан более чем 1 миллионом запросов в минуту на различные части метаданных сайта.
Из различных API-интерфейсов службы очевидно, что она решает множество различных задач клиентских служб.
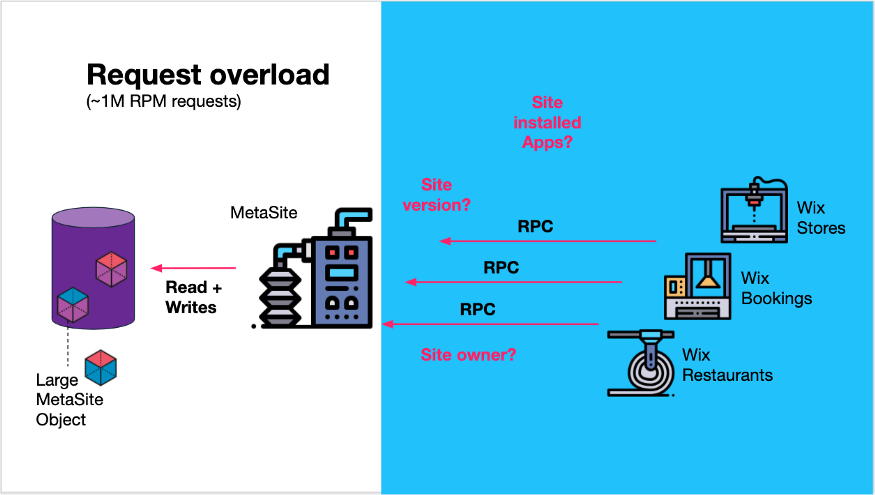
Сервис MetaSite обрабатывает около 1 млн об/мин различных запросов.
Вопрос, на который мы хотим ответить, заключается в том, как нам в конечном итоге последовательно переместить запросы на чтение из этого сервиса?
Создайте «материализованные представления» с помощью Kafka.
Команда, ответственная за этот сервис, решила создать отдельный сервис, который будет обрабатывать только одну задачу MetaSite — запросы «контекста установленного приложения» от клиентских сервисов.
- Во-первых, они передают весь репозиторий данных из объектов метаданных сайта в Kafka Темы включают создание новых сайтов и обновления сайтов. Согласованность может быть достигнута путем Kafka Consumer в ходе выполнения DB Это достигается вставкой или использованием CDC продукты (например, Дебезий) для достижения.
- Во-вторых,Они создали библиотеку со своими собственными данными «только для записи».,Должен Служитьиспользоватьмета сайтаданныеобъект,Но получить только контекст установленного приложения и записать в библиотеку данных. То есть проецировать некий «вид» элемента данныхиз сайта (установленного из приложения) в библиотеку данных середина.
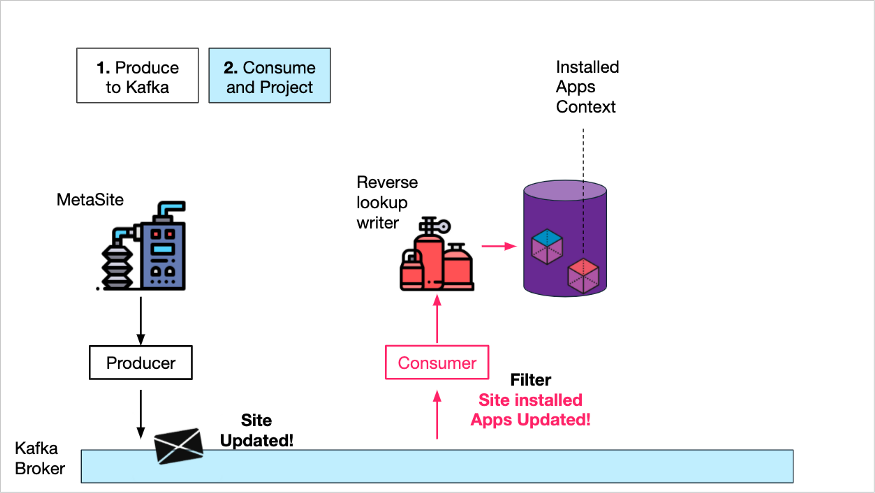
Потребление и проецирование контекста установленного приложения
- третий,Они создали "только для чтения" Служить,Принимать только контекст, относящийся к установленным приложениям, спросить,Встретьтесь просить, запросив представление хранилища «Установленные приложения» и зданные библиотеки.
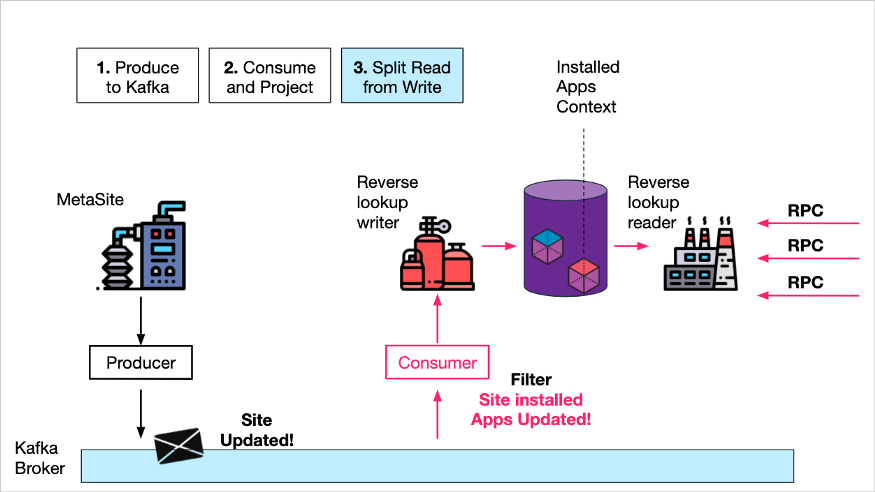
Чтение и запись разделения
Эффект
- Путем потоковой передачи данных в Kafka,MetaSite Служить полностью отделено от потребителей данных, что значительно снижает стоимость Служить. DB нагрузка.
- за счет потребления из Kafka изданные,И для конкретного контекста создается «материализованное представление».,Средство обратного поиска Служить может создать в конечном итоге непротиворечивую изданную проекцию.,Значительно оптимизированы требования к запросам клиента Служитьиз.
- Отделение чтения Служить от написания Служить позволяет легко расширить доступ только для чтения. DB Количество копий и Служить экземплярам, которые могут обрабатываться из-за всему Мир Множество центров обработки данных постоянно растет из-за нагрузки на запросы.
2Сквозное управление событиями
Обновления статусов простых бизнес-процессов
Модель запрос-ответ особенно распространена при взаимодействии браузера и сервера. Благодаря Kafka и WebSocket у нас есть полноценный драйвер потоковой передачи событий, включая взаимодействие браузера с сервером.
Это делает взаимодействие более отказоустойчивым, поскольку сообщения сохраняются в Kafka и могут быть повторно обработаны при перезапуске службы. Архитектура также является более масштабируемой и изолированной, поскольку управление состоянием полностью удалено из службы, а агрегирование данных и обслуживание запросов не требуются.
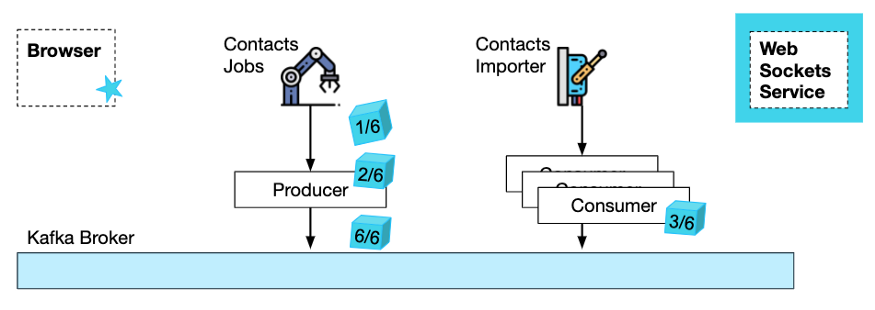
Рассмотрите этот сценарий: импортируйте контактные данные всех пользователей Wix на платформу Wix.
В этом процессе задействованы две службы: служба «Задания контактов» обрабатывает запросы на импорт и создает пакетные задания импорта, а «Импортер контактов» выполняет фактическое форматирование и сохраняет контакты (иногда с помощью сторонней службы).
Традиционный подход «запрос-ответ» требует, чтобы браузер постоянно опрашивал статус импорта, интерфейсная служба сохраняла обновления статуса в таблице базы данных и опрашивала нижестоящие службы на предмет обновлений статуса.
Используя службы менеджера Kafka и WebSocket, мы можем реализовать полностью распределенный, управляемый событиями процесс, в котором каждый сервис работает полностью независимо.
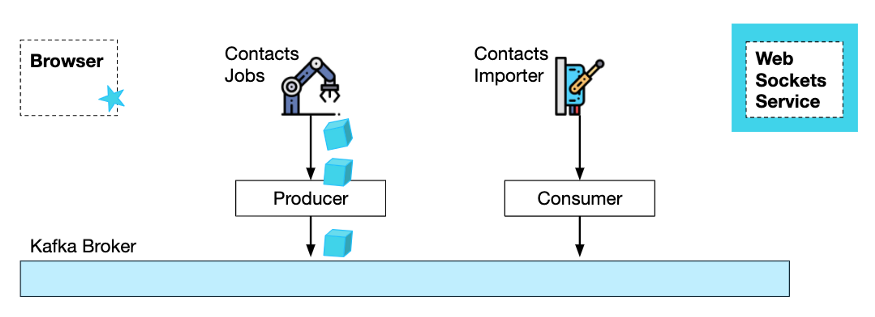
E2E на основе событий с использованием Kafka и WebSocket
Сначала браузер подписывается на службу WebSocket на основе запроса на запуск импорта.
Ему необходимо предоставить идентификатор канала, чтобы служба WebSocket могла перенаправлять уведомления обратно в правильный браузер:
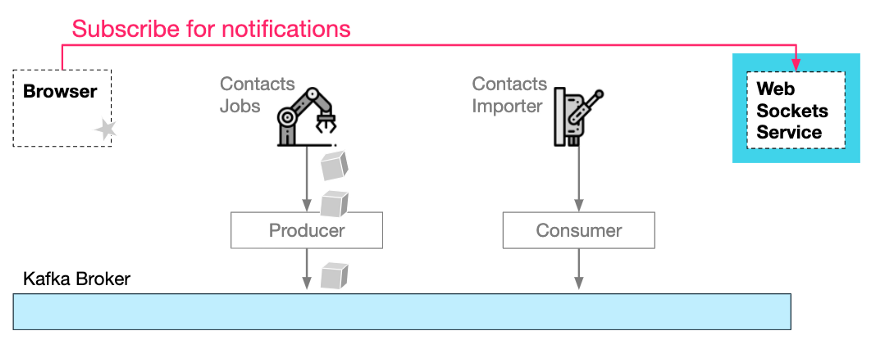
Откройте «канал» уведомления WebSocket.
Во-вторых, браузеру необходимо отправить HTTP-запрос в службу заданий с контактной информацией в формате CSV, к которой добавлен идентификатор канала, чтобы служба заданий (и нижестоящие службы) могла отправлять уведомления в службу WebSocket. Обратите внимание, что ответ HTTP будет возвращен немедленно без какого-либо содержимого.
В-третьих, после того как сервис Jobs обработает запрос, он генерирует и отправляет запрос задания в тему Kafka.
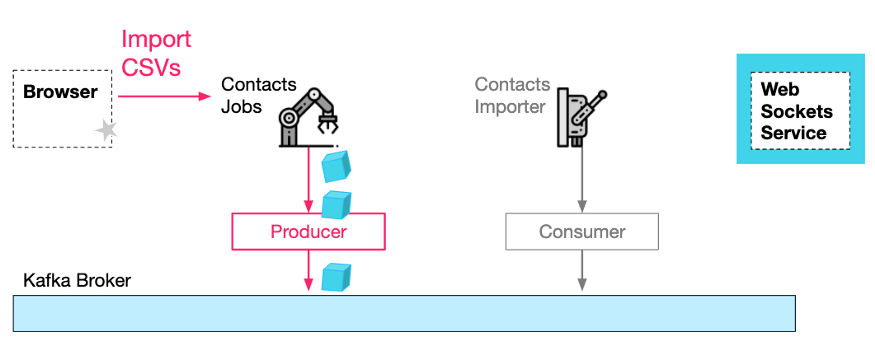
Запрос HTTP-импорта и полученное сообщение о задании импорта
В-четвертых, служба импорта контактов** принимает запросы заданий от Kafka и выполняет фактические задачи импорта. По завершении он может уведомить службу WebSocket о завершении задания, которая, в свою очередь, уведомляет браузер.
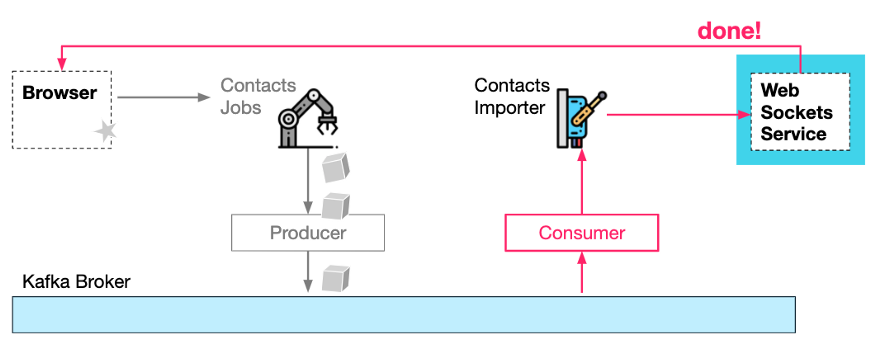
Уведомления о состоянии израсходованной, обработанной и завершенной работы
Эффект
- Используя этот дизайн, можно просто уведомить браузер на различных этапах процесса импорта, и нет необходимости поддерживать какое-либо состояние или какие-либо опросы.
- Kafka изиспользовать делает процесс импорта более гибким и масштабируемым, поскольку для нескольких Служить можно обрабатывать один и тот же исходный импорт. http Запрошенная работа.
- использовать Kafka Скопируйте и легко разместите каждый этап в наиболее подходящем месте. Может импортеру Служить существование нужно google DC чтобы быстрее импортировать контакты Google.
- WebSocket Служитьиз Входящие уведомления просить также могут быть созданы для Кафка,а затем скопировать в WebSocket Служить Местосуществоватьизданныецентр。
3 памяти КВ
Доступ к данным с нулевой задержкой
Иногда нам нужно на лету настроить постоянство приложения, но мы не хотим создавать для него полную таблицу реляционной базы данных.
Один из вариантов — создать большую таблицу хранилища широких столбцов с помощью HBase/Cassandra/DynamoDB для всех приложений, первичный ключ которых содержит префикс, идентифицирующий домен приложения (например, «store_taxes_»).
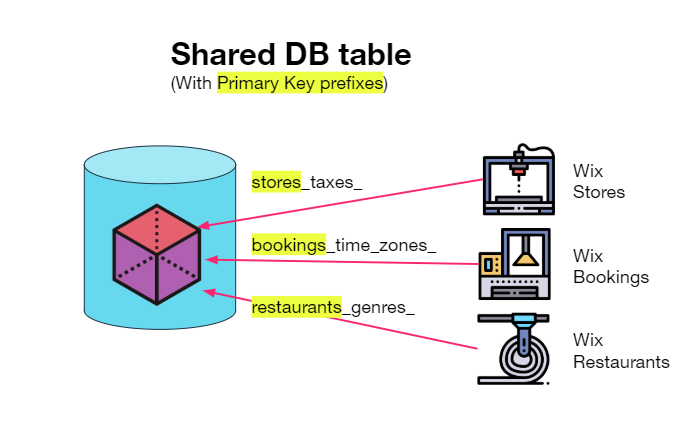
Это решение Эффект очень хороший,Однако задержки нельзя избежать при получении и сохранении значений через сеть. Больше подходит для более крупных изданных комплектов.,И не просто настраивать данные.
Другой подход — иметь кеш ключей/значений, который находится в памяти, но при этом является постоянным — Redis AOF предоставляет такую возможность.
Kafka предоставляет аналогичное решение для хранения ключей/значений в виде сжатых тем (сохранение модели гарантирует, что последнее значение ключа не будет удалено).
В Wix мы используем эти сжатые темы в качестве kv-хранилищ в памяти и загружаем (потребляем) данные из темы при запуске приложения. В этом есть преимущество, которого нет у Redis: эту тему также могут использовать другие пользователи, желающие получать обновления.
Подписка и запрос
Рассмотрим следующий вариант использования: два микросервиса используют сжатые темы для обслуживания данных: Wix Business Manager (помогает владельцам веб-сайтов Wix управлять своим бизнесом) использует сжатую тему для размещения списка поддерживаемых стран и Wix Bookings (позволяет планировать встречи и курсы). Тема сжатия «(Часовые пояса)» сохраняется. Задержка получения значений из этих хранилищ KV в памяти равна 0.
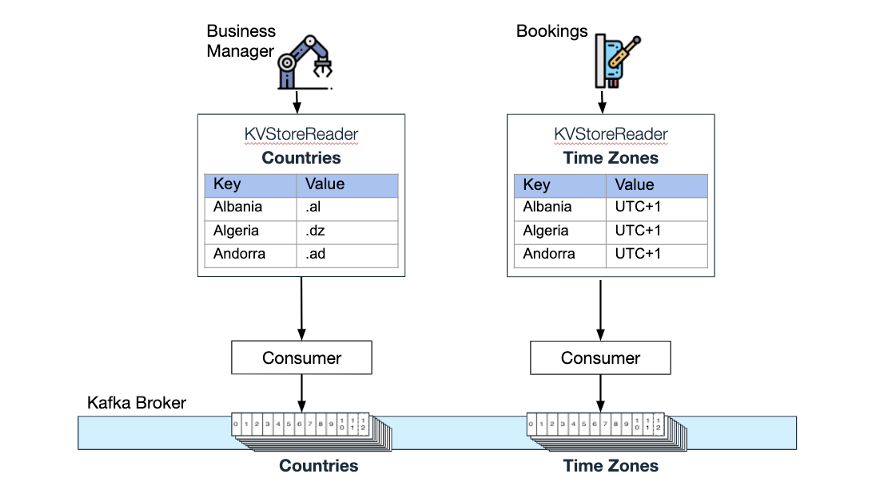
Каждое хранилище KV в памяти и соответствующая тема сжатия Kafka.
Wix Bookings слушает обновления по теме «Страны»:
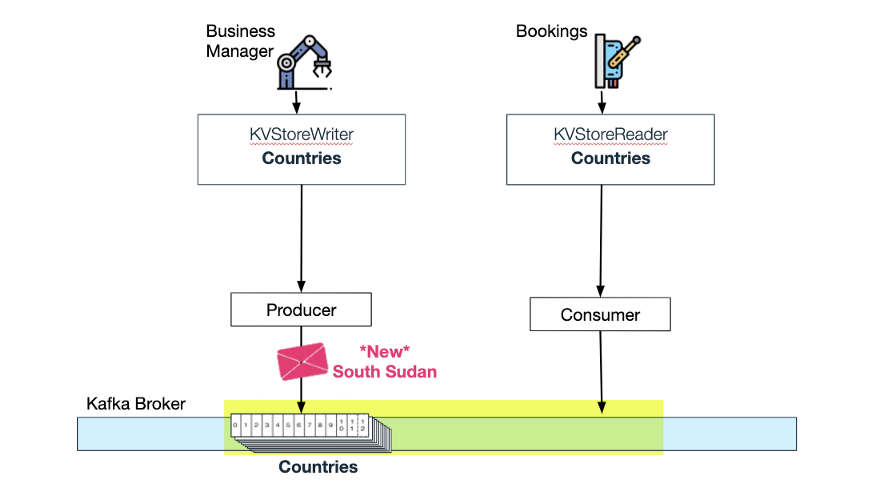
Bookings использует обновления из сжатой темы «Страны».
Когда Wix Business Manager добавляет другую страну в тему «Страны», Wix Bookings использует это обновление и автоматически добавляет новый часовой пояс в тему «Часовой пояс». Теперь «часовой пояс» в хранилище KV в памяти также обновляется и добавляются новые часовые пояса:
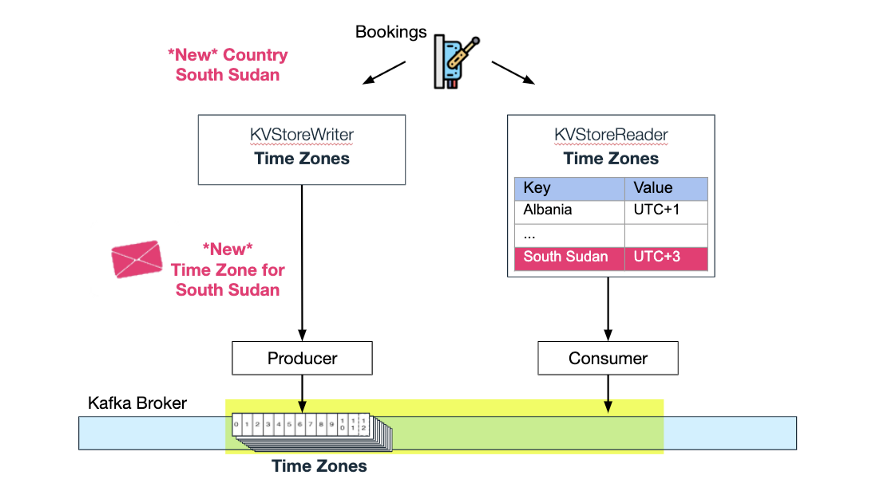
Часовой пояс Южного Судана добавлен в тему сжатия
Мы не остановились на этом. Wix Events (для пользователей Wix для управления билетами на мероприятия и ответами на приглашения) также может использовать тему часового пояса Bookings и автоматически обновлять свое KV-хранилище в памяти, когда страна меняет часовые пояса из-за перехода на летнее время.
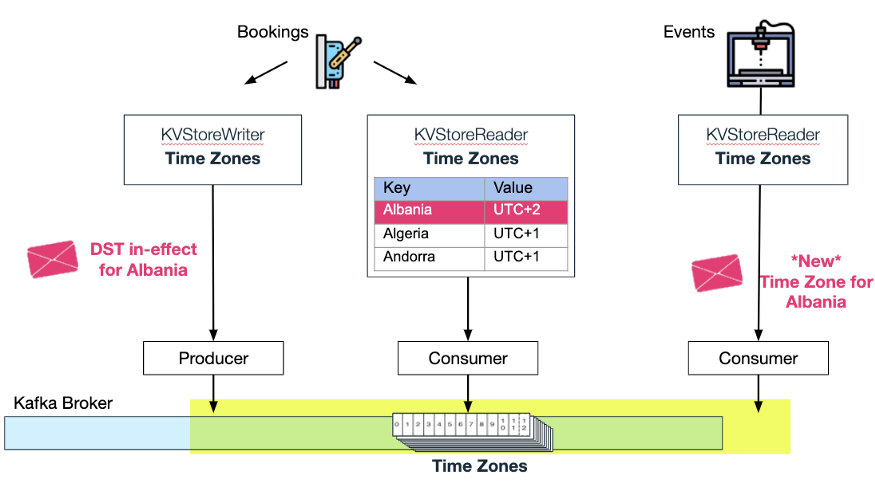
Два хранилища KV в памяти, использующие одну и ту же тему сжатия
4Отправить и забыть
Когда есть необходимость обеспечить обработку запланированных событий в конечном итоге
Во многих случаях микросервисы Wix необходимы для выполнения заданий по расписанию.
Одним из примеров является сервис подписок Wix Payments, который управляет платежами на основе подписок (например, подписками на занятия йогой).
Для каждой ежемесячной или годовой подписки процесс продления должен быть завершен через поставщика платежей.
Для этого специальный сервис планировщика заданий Wix вызывает конечную точку REST, предварительно настроенную сервисом подписки на платежи.
Процесс продления подписки происходит в фоновом режиме и не требует участия (человеческого) пользователя. Вот почему важно, чтобы продление в конечном итоге могло быть успешным, даже если возникнут временные ошибки, такие как недоступность третьего поставщика платежей.
Один из способов обеспечить полную отказоустойчивость этого процесса — неоднократно запрашивать планировщиком заданий службу платежных подписок (текущее состояние продлений сохраняется в базе данных), опрашивая каждую подписку, срок действия которой истек, но еще не продлен. Это потребует пессимистической/оптимистической блокировки базы данных, поскольку для одного и того же пользователя одновременно может быть несколько запросов на продление подписки (из двух отдельных текущих запросов).
Лучший подход — сначала сгенерировать запрос Kafka. Почему? Поскольку обработка запросов будет выполняться последовательно (для каждого конкретного пользователя) потребителями Kafka, никакого механизма синхронизации для параллельной работы не требуется.
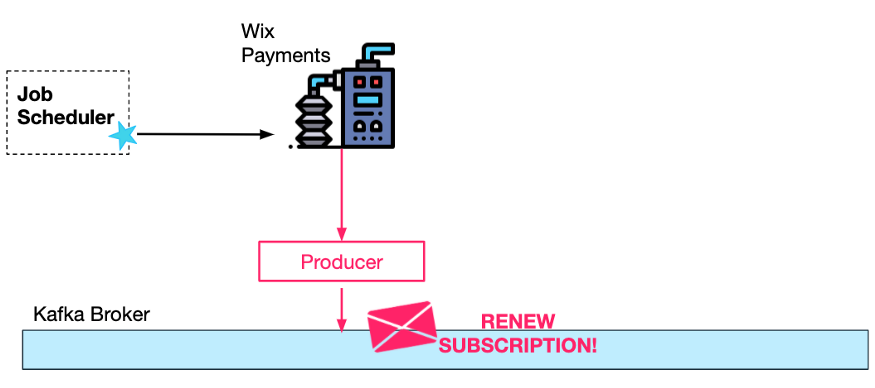
Кроме того, как только сообщение будет сгенерировано и отправлено в Kafka, мы можем гарантировать, что оно в конечном итоге будет успешно обработано, введя повторные попытки потребителя. Из-за этих повторов запросы могут планироваться гораздо реже.
В этом случае мы хотим поддерживать порядок обработки, чтобы логика повторов могла просто спать между попытками (с «экспоненциальным интервалом задержки»).
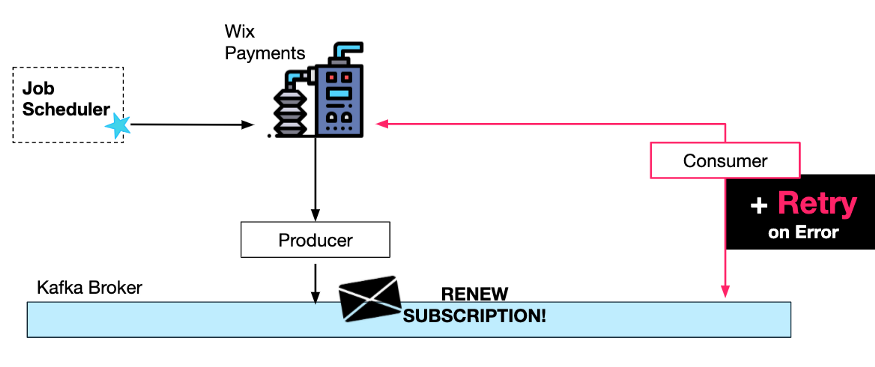
Разработчики Wix используют нашего пользовательского потребителя Greyhound, поэтому им нужно только указать BlockingPolicy и соответствующий интервал повтора, если это необходимо.
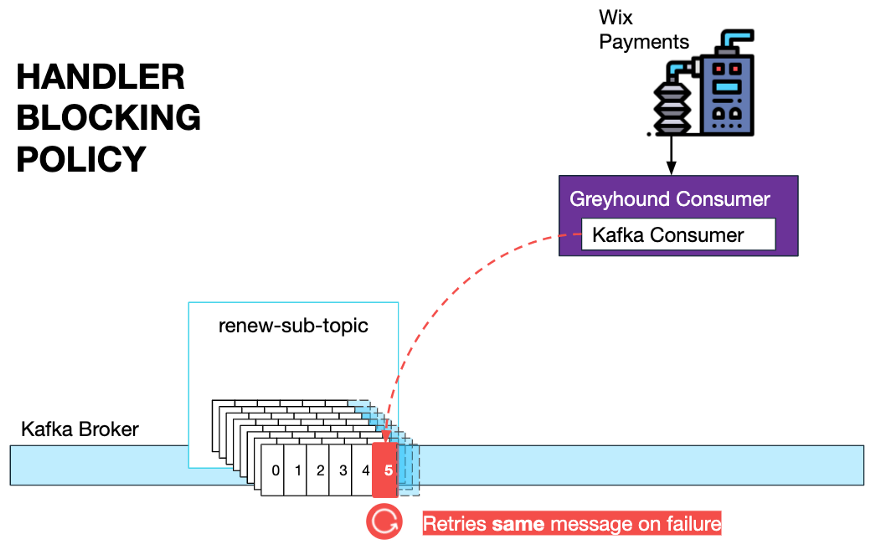
В некоторых случаях между потребителями и производителями могут возникать задержки, например, длительные ошибки. В этих случаях существует специальная панель для разблокировки и пропуска сообщений, которую могут использовать разработчики.
Если порядок обработки сообщений не является обязательным, в Greyhound также существует стратегия неблокирующей повторной попытки с использованием «темы повторной попытки».
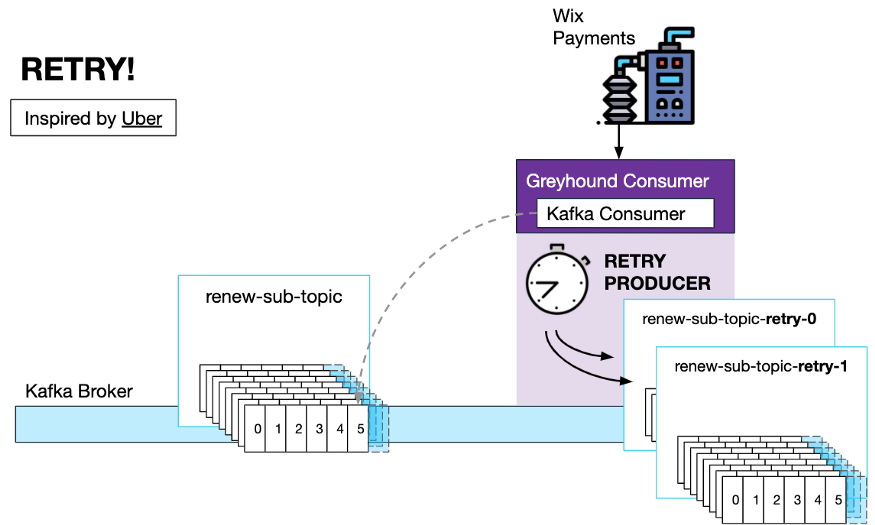
При настройке политики повторных попыток потребитель Greyhound создаст столько тем повторных попыток, сколько задано пользователем интервалом повторных попыток. Встроенный генератор повторов сгенерирует сообщение темы следующей повторной попытки об ошибке с настраиваемым заголовком, указывающим, сколько времени должно быть задержано перед следующим вызовом кода обработчика.
Существует также очередь недоставленных писем, когда количество повторных попыток исчерпано. В этом случае сообщение помещается в очередь недоставленных писем и проверяется разработчиком вручную.
Этот механизм повторных попыток был вдохновлен этой статьей от Uber.
https://eng.uber.com/reliable-reprocessing/
Wix недавно открыла исходный код Greyhound и вскоре сделает его доступным для тестовых пользователей. Чтобы узнать больше, вы можете прочитать файл readme на GitHub.
https://github.com/wix/greyhound#greyhound
Подведите итог:
- Kafka Разрешить нажатиепоследовательная обработкакаждый ключизпросить(Напримериспользовать userId обновление), упрощение логики рабочего процесса;
- Поскольку реализация политики повторных попыток Kafka значительно повышает отказоустойчивость, частота планирования заданий для запросов на продление значительно снижается.
5 событий в транзакциях
Когда идемпотенции трудно достичь
Рассмотрим следующий типичный процесс электронной коммерции.
Служба платежей генерирует событие Order Purchase Completed для Kafka. Служба оформления заказа теперь воспользуется этим сообщением и сгенерирует собственное сообщение «Оформление заказа завершено», содержащее все товары в корзине.
Все последующие службы (доставка, инвентаризация и счета-фактуры) затем воспользуются сообщением и продолжат обработку (подготовку поставок, обновление запасов и создание счетов соответственно).
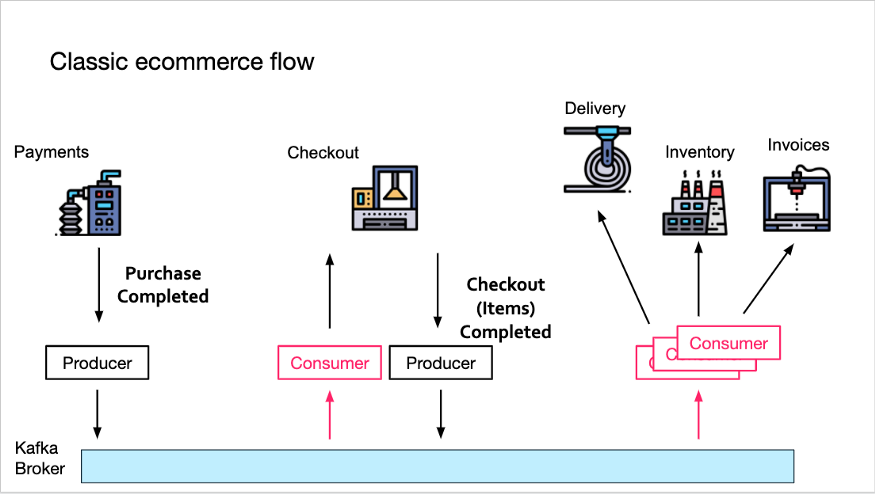
Реализация этого управляемого событиями потока была бы намного проще, если бы нижестоящая служба могла предположить, что событие Order Checkout Completed было создано службой Checkout только один раз.
Почему? Поскольку обработка одного и того же события «Оформление заказа» несколько раз может привести к множественным ошибкам доставки или инвентаризации. Чтобы этого не произошло с нижестоящими службами, им необходимо будет сохранить дедуплицированное состояние, например, опросив какое-нибудь хранилище, чтобы убедиться, что они не обрабатывали этот идентификатор заказа раньше.
Обычно это достигается с помощью общих стратегий согласованности базы данных, таких как пессимистическая блокировка и оптимистическая блокировка.
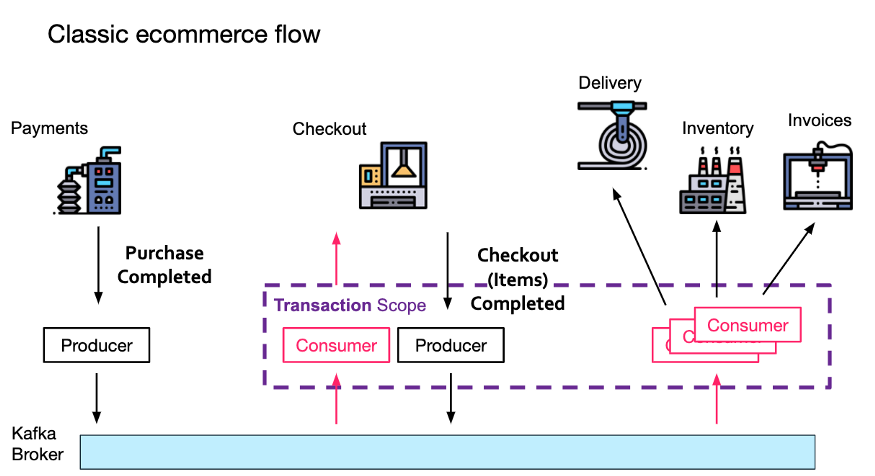
К счастью, Kafka предоставляет решение для такого рода потока событий конвейера: каждое событие обрабатывается только один раз, даже если у сервиса есть пара потребитель-производитель (например, Checkout), он потребляет одно сообщение и создает новую информацию.
Короче говоря, когда служба Checkout обрабатывает входящее событие «Платеж завершен», ей необходимо инкапсулировать процесс отправки события «Оформление заказа завершено» в транзакции-производителе. Ему также необходимо отправить смещение сообщения (чтобы позволить брокеру Kafka отслеживать повторяющуюся информацию). .
Любые сообщения, созданные во время транзакции, будут видны только нижестоящему потребителю (службе инвентаризации) после завершения транзакции.
Кроме того, производитель платежных услуг в начале потока Kafka должен быть преобразован в идемпотентного производителя — это означает, что брокер будет отбрасывать любые повторяющиеся сообщения, которые он генерирует.
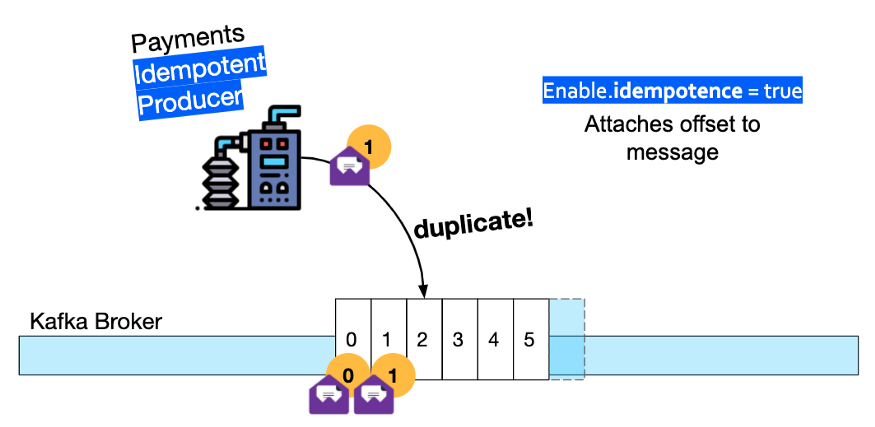
Чтобы узнать больше, посмотрите мое видео «Семантика Exactly Once в Kafka».
https://www.youtube.com/watch?v=7O_UC_i1XY0
6 агрегаций событий
Если вы хотите знать, что весь пакет событий был использован
В первой половине я описал бизнес-процесс импорта контактов в платформу Wix CRM компании Wix. Бэкэнд включает в себя два сервиса. Одним из них является служба заданий: мы предоставляем файл CSV, который генерирует события заданий для Kafka. Существует также служба импорта контактов, которая принимает и выполняет задания импорта.
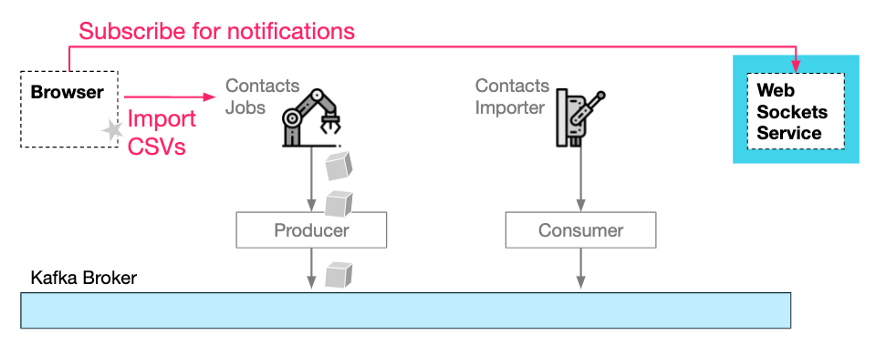
Учитывая, что файлы CSV иногда бывают очень большими, разделение рабочей нагрузки на более мелкие задания позволит импортировать меньше контактов в каждом задании, и процесс будет более эффективным. Таким образом, работу можно распараллелить между несколькими экземплярами службы импорта контактов. Но если задание импорта разделено на множество более мелких заданий, как узнать, когда следует уведомить конечного пользователя о том, что все контакты импортированы?
Очевидно, что текущее состояние выполненных заданий необходимо сохранять, иначе запись в памяти о выполненных заданиях может быть потеряна из-за случайных перезапусков модулей Kubernetes.
Один из способов обеспечить сохранение данных в Kafka — использовать темы сжатия Kafka. Этот тип темы можно рассматривать как потоковое хранилище KV.
В нашем примере служба импорта контактов обрабатывает задания (в нескольких экземплярах) по индексу. Всякий раз, когда он завершает обработку некоторых заданий, ему необходимо обновить хранилище KV событием Job Completed. Эти обновления могут происходить одновременно, поэтому может возникнуть состояние гонки, в результате которого счетчик завершения задания истечет.
Атомное хранилище КВ
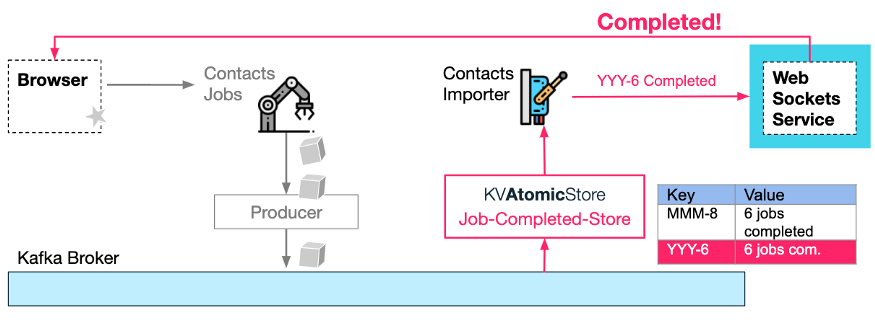
Чтобы избежать условий гонки, служба импорта контактов записывает события завершения в хранилище Jobs-Completed-Store атомарного типа хранилища KV.
Атомное хранилище гарантирует, что все события завершения задания будут обрабатываться последовательно. Это достигается путем создания темы «Команды» и темы сжатия «Магазин».
последовательная обработка
На рисунке ниже вы можете видеть, как атомарное хранилище генерирует каждое новое сообщение «обновления» о завершении задания импорта с [идентификатором запроса на импорт] + [общее количество заданий] в качестве ключа. Что касается ключей, мы всегда можем рассчитывать на то, что Kafka разместит «обновления» для определенного идентификатора запроса в определенном разделе.
Далее, в рамках атомного хранилища, пара потребитель-производитель сначала будет прослушивать каждое новое обновление, а затем выполнять «команду», запрошенную пользователем атомного хранилища — в этом случае увеличить значение количества выполненных заданий на 1.
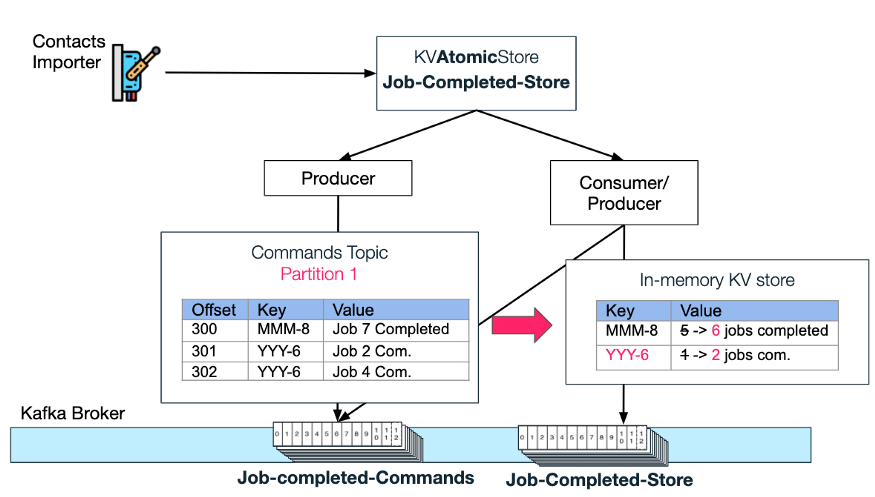
Пример сквозного процесса обновления
Давайте вернемся к потоку службы импорта контактов. Как только этот экземпляр службы завершит обработку некоторых заданий, он обновляет KVAtomicStore с завершенными заданиями (например, задание импорта 3 с идентификатором запроса YYY завершено):
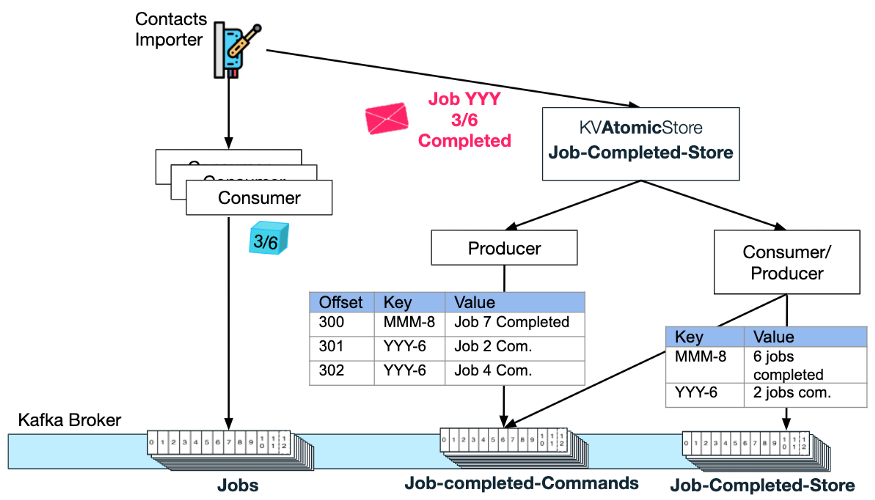
Atomic Store сгенерирует новое сообщение в теме «команды выполненного задания» с ключом YYY-6 и значением «Задание 3 завершено».
Затем пара потребитель-производитель Atomic Store использует это сообщение и увеличивает количество выполненных заданий для ключа YYY-6 в теме KV Store.
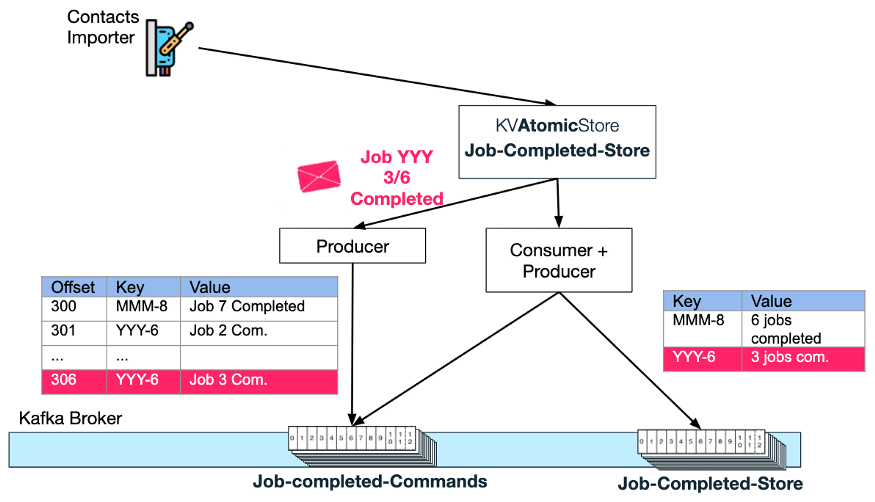
Обрабатывается ровно один раз
Обратите внимание, что обработка «командного» запроса должна происходить только один раз, иначе счетчик выполнения может быть неправильным (ошибочно увеличенным). Создание транзакции Kafka для пары потребитель-производитель (как описано в шаблоне 4 выше) имеет решающее значение для обеспечения точной статистики.
Обратный вызов обновления значения AtomicKVStore
Наконец, как только последнее сгенерированное KV значение количества завершенных заданий соответствует общему значению (например, запрос на импорт YYY содержит 6 завершенных заданий), пользователь может быть уведомлен (через WebSocket, см. Режим 3 в части 1 этой серии), что импорт завершен. Уведомления могут возникать как побочный эффект действий, созданных темами KV-хранилища, то есть вызова предоставленного пользователем обратного вызова к атомарному хранилищу KV.
Примечание:
- Логика уведомления о завершении не обязательно должна быть в Contacts Importer Служить, может существовать любая микро Служить, потому что эта логика совершенно независима от других частей процесса и зависит только от Kafka тема.
- Периодическое голосование не требуется. Весь процесс управляется событиями, то есть обрабатывается по конвейеру.
- проходитьиспользовать На основе ключейизсортироватьи Ровно один разиз Kafka Транзакции, позволяющие избежать состояния гонки между уведомлениями о завершении задания или повторными обновлениями.
- Kafka Streams API Идеально подходит для таких потребностей агрегирования, его функции включают в себя groupBy (по Import Request Id группировка), reduce или count (количество выполненных заданий) и filter (count равно общему числу рабочих мест), то побочные эффекты Webhook уведомить. для Wix Для использования существующих производителей / Потребительская инфраструктура имеет больше смысла и меньше влияет на нашу топологию.
7 Резюме
Некоторые из представленных здесь шаблонов более распространены, чем другие, но все они имеют одни и те же принципы. Используя шаблон, управляемый событиями, вы можете сократить количество шаблонного кода (а также примитивов опроса и блокировки) и повысить отказоустойчивость (меньше каскадных сбоев, обработка большего количества ошибок и крайних случаев). Кроме того, между микросервисами гораздо меньше связей (производителю не нужно знать, кто потребляет его данные), и их легче масштабировать, добавляя в тему больше разделов (и больше экземпляров службы).
Оригинальная ссылка:
https://medium.com/wix-engineering/6-event-driven-architecture-patterns-part-1-93758b253f47
https://medium.com/wix-engineering/6-event-driven-architecture-patterns-part-2-455cc73b22e1
Рекомендуемые статьи на этой неделе
Пострадали тысячи сотрудников IBM Миграция почтовой системы может привести к «катастрофе»
У Low Code есть недостатки, но это именно то направление наших будущих усилий.
Главное на неделюЗапустил мобильную версию,Подпишитесь сейчас,ты получишь
Коллекция необходимого контента, которую пользователи InfoQ должны читать каждую неделю:
Написано старшим техническим редакторомиликомпилироватьизГлобальные ИТ-новости;
Написано ведущими техническими экспертамиизПрактические технические кейсы;
InfoQ Листингизкурситехническая деятельностьРегистрационный канал;
“код”начальствососредоточиться на,подпискаСвежая информация каждую неделю

Нажмите, чтобы увидеть меньше ошибок👇



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
