4090 на замену А100? Скорость генерации токенов всего на 18% ниже, чем у A100, а большой механизм вывода популярен.
Отчет о сердце машины
Редакция «Машинное сердце»
PowerInfer повышает эффективность работы искусственного интеллекта на оборудовании потребительского уровня.
Команда Шанхайского университета Цзяо Тонг недавно запустила PowerInfer, сверхмощную высокоскоростную систему вывода LLM CPU/GPU.
PowerInfer и llama.cpp все работают на одном и том же оборудовании и в полной мере используют преимущества RTX 4090 на VRAM。
Насколько быстро работает эта машина вывода? При использовании LLM на одном графическом процессоре NVIDIA RTX 4090 средняя скорость генерации токенов PowerInfer составляет 13,20 токенов/с с пиковой скоростью 29,08 токенов/с, что всего на 18 % ниже, чем у топового серверного графического процессора A100, и может применяться к различным LLM.
Мало того, по сравнению с самой совершенной локальной структурой вывода LLM llama.cpp, PowerInfer запускает Falcon (ReLU)-40B-FP16 на одном RTX 4090 (24G), достигая более чем 11-кратного ускорения при сохранении точности модели. секс.
В частности, PowerInfer — это высокоскоростной механизм вывода для локального развертывания LLM. В отличие от тех, кто использует многоэкспертные системы (MoE), PowerInfer умело разрабатывает гибридный механизм вывода GPU-CPU, используя высокую степень локальности вывода LLM.
Это работает следующим образом: часто активируемые нейроны (т. е. активируемые в горячем режиме) предварительно загружаются в графический процессор для быстрого доступа, тогда как редко активируемые нейроны (т. е. активируемые в холодном состоянии) (на которые приходится большая часть большинства) рассчитываются в ЦП.
Такой подход существенно снижает GPU Памятьнуждатьсяи CPU-GPU Передача данных.

- Адрес проекта: https://github.com/SJTU-IPADS/PowerInfer.
- Адрес статьи: https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf.
PowerInfer Может быть оснащен одним устройством потребительского класса. GPU из PC Бегите на высокой скорости Магистр права. Теперь пользователи могут PowerInfer и Llama 2 и Faclon 40B Используется в сочетании, да Mistral-7B из Поддержка также появится в ближайшее время。
один деньизвремя,PowerInfer Только что понял 2K звезда.
Прочитав это исследование, пользователи сети были взволнованы и сказали: «Одна карта». 4090 бегать 175B Большие модели больше не мечта.
Архитектура PowerInfer
PowerInfer Ключом к дизайну является использование LLM Выводу присуща высокая степень локальности, характеризующаяся степенным законом распределения активации нейронов. Такое распределение предполагает, что небольшая подгруппа нейронов, называемая горячими нейронами, активируется последовательно при разных входных сигналах, тогда как большинство холодных нейронов варьируются в зависимости от конкретных входных сигналов. PowerInfer Разработан с использованием этого механизма GPU-CPU Гибридный механизм вывода.
Изображение ниже 7 показал PowerInfer Обзор архитектуры, включая оффлайн и онлайн компоненты. Автономная обработка компонентов LLM Активация редкая, что отличает горячие нейроны от холодных. На онлайн-этапе машина вывода загружает два типа нейронов в систему проживания. GPU и CPU , обслуживается с низкой задержкой во время выполнения LLM просить.
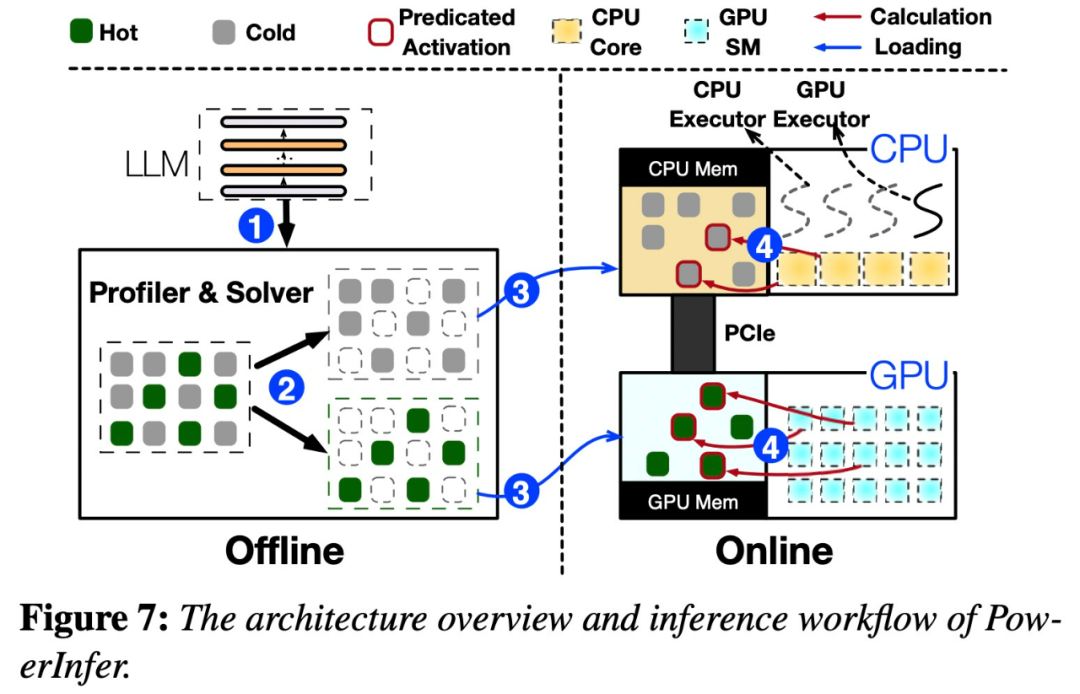
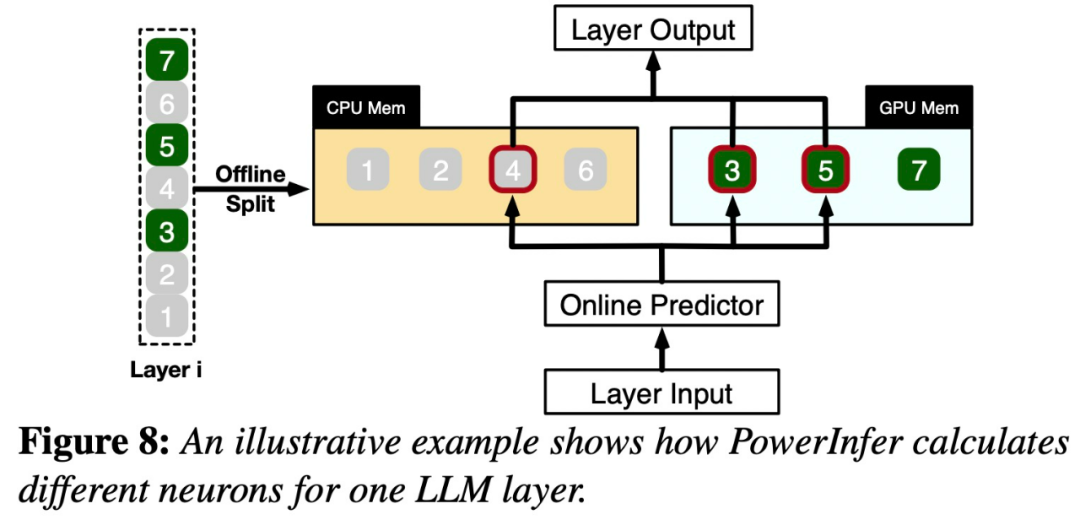
картина 8 объяснил PowerInfer Как координировать GPU и CPU Для обработки нейронов между слоями. PowerInfer Чтобы классифицировать нейроны на основе автономных данных, термически активированных нейронов (например, индекс 3, 5, 7) присвоены GPU памяти, выделить другие нейроны для CPU Память.
Как только приехать, будут получены данные,Предиктор определяет, какие нейроны текущего слоя могут быть активированы. Стоит отметить, что,Идентификация термически активированных нейронов с помощью автономного статистического анализа, которые могут иметь противоречивое поведение при активации во время выполнения. Например,нейрон 7 Несмотря на то, что он помечен как активируемый при нагревании, это не так. Затем процессор и GPU Активированные нейроны будут обработаны, а неактивированные нейроны будут проигнорированы. графический процессор вычислительные нейроны 3 и 5, в то время как CPU обрабатывающие нейроны 4. нейрон 4 После завершения расчета из его результаты будут отправлены приехать. GPU Интегрируйте результаты.
эксперимент
В исследовании использовались различные параметры: OPT Модель проведенного эксперимента, параметры из 6.7B приезжать 175B Неважно, оно также включает в себя Falcon (ReLU)-40B и LLaMA (ReGLU)-70B Примечательна модель 175B. Параметры Модельиз размеров GPT-3 Модель сопоставима.
Эта статья также будет PowerInfer и llama.cpp Было проведено сравнение, llama.cpp Самый продвинутый из местных LLM рамки рассуждения. Для облегчения сравнения исследование также расширило llama.cpp поддерживать OPT Модель.
Так как в этой статье основное внимание уделяется настройкам задержки Низкий.,Поэтому метрикой оценки является скорость сквозной генерации.,Количественно, как генерируется в секунду token из Количество (токенов/ов).
В исследовании впервые сравнили PowerInfer и llama.cpp изEND приезжать END вывод производительность, размер партии 1。
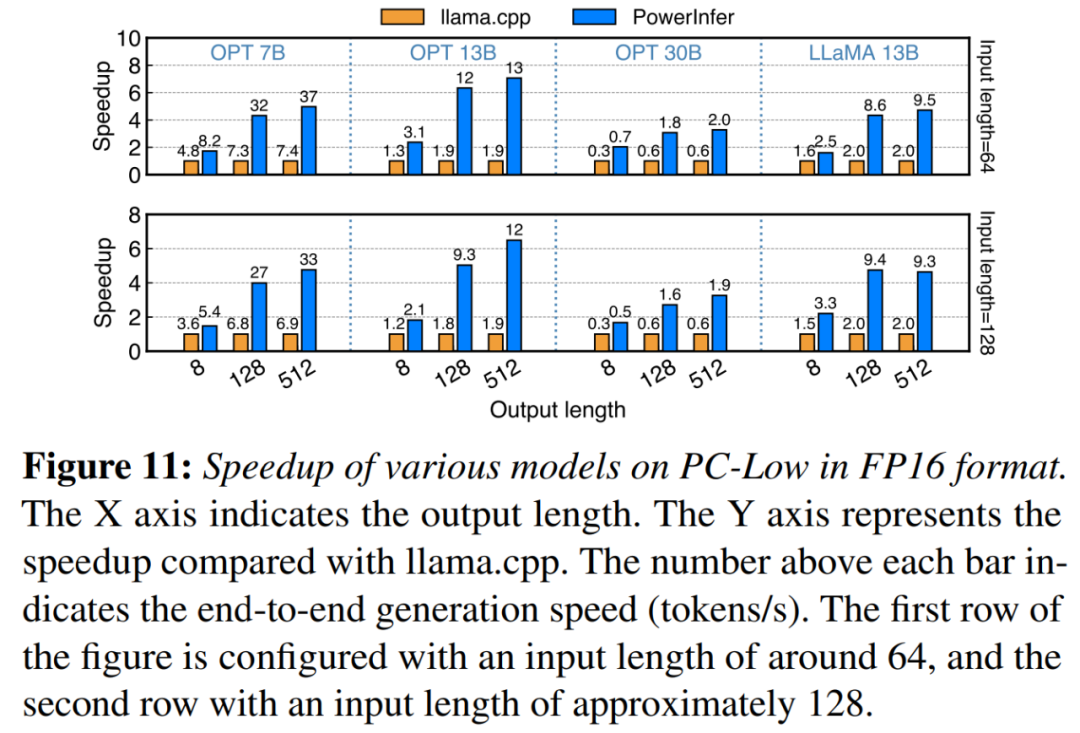
картина 10 показанный оборудован NVIDIA RTX 4090 из PC-High На различных моделях входных и выходных конфигураций скорости генерации. В среднем PowerInfer Осуществленный 8.32 tokens/s из Скорость генерации, до 16.06 tokens/s, значительно лучше, чем llama.cpp, чем llama.cpp улучшенный 7.23 раз, соотношение Falcon-40B улучшенный 11.69 раз.
С выходом token Увеличение количества, PowerInfer Преимущество становится еще более очевидным, поскольку фаза генерации играет более важную роль в общем времени вывода. На этом этапе процессор и GPU активирует небольшое количество нейронов, и llama.cpp По сравнению с этим сокращаются ненужные вычисления. Например, в OPT-30B В случае из каждый раз, когда жетон, всего ок. 20% нейронов активируются, большинство из них в GPU обработка - это PowerInfer Нейрональное перцептивное мышление из Преимущества.

картина 11 показать, в PC-Low Вкл., PowerInfer все еще лучше, чем llama.cpp Получено значительное среднее ускорение производительности 5.01 раз, максимальное значение 7.06 раз. PC-High Эти улучшения меньше по сравнению с PC-Low из 11GB GPU Ограничение памяти. Этот предел влияет на то, что может быть назначено GPU из Количество нейронов, особенно у тех, у кого ок. 30B параметр или несколько параметров, что приводит к большей зависимости от CPU обрабатывать большое количество активированных нейронов.
картина 12 Показан PowerInfer и llama.cpp из CPU и GPU Распределение нагрузки между нейронами. Стоит отметить, что в PC-High Вкл., PowerInfer значительно увеличился GPU из доли нагрузки нейронов, от средней 20% Добавить проживание 70%. Это показывает GPU Обработано 70% из активирует нейроны. Однако спрос на «Модельиз Память» намного превышает GPU Емкость из корпуса, например в 11GB 2080Ti GPU беги дальше 60GB модель, графический процессор из Нейронная нагрузка снизится до Низкого 42%. Это снижение обусловлено GPU из Память ограничена и недостаточна для размещения всех термически активированных нейронов, поэтому необходимо CPU Посчитайте эти нейроны по частям.

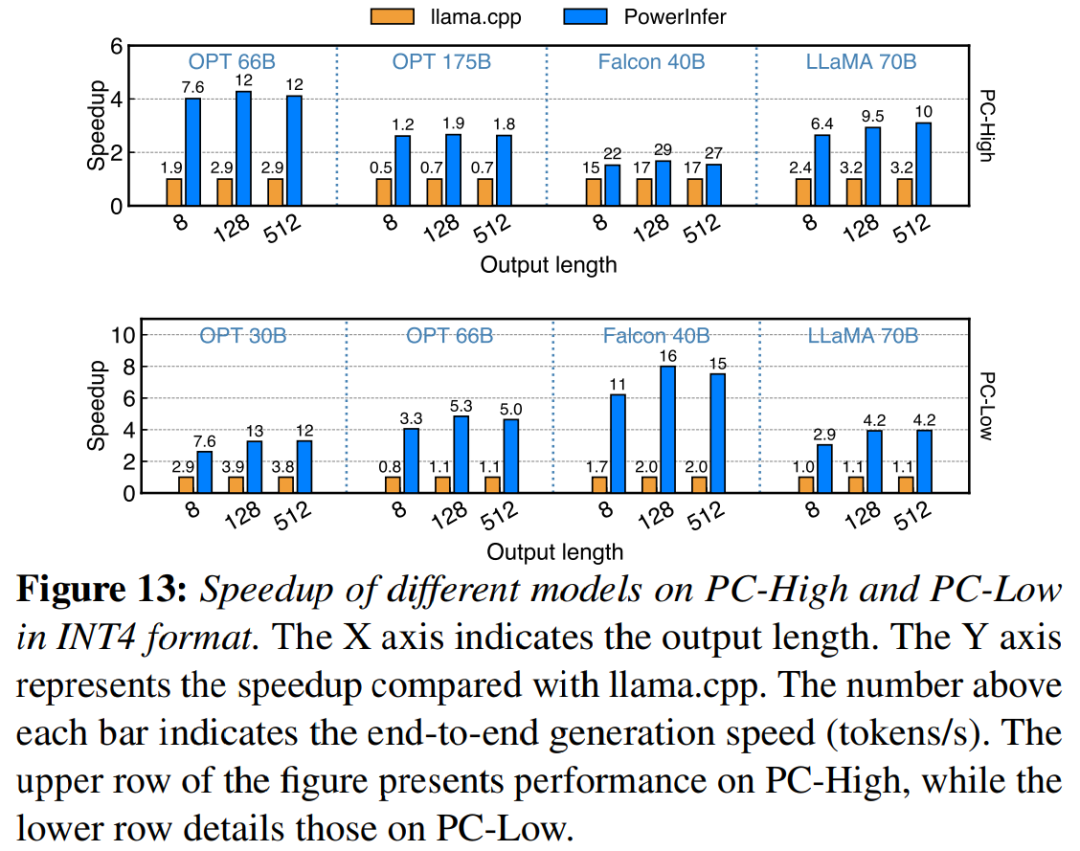
картина 13 иллюстрировать PowerInfer Эффективная поддержка использования INT4 Квантование сжатия Магистр права. существовать PC-High Вкл., PowerInfer Средняя скорость ответа 13.20 токенов/с, пиковое значение может достигать 29.08 tokens/s。и llama.cpp По сравнению со средним ускорением 2.89 раз, максимальное ускорение 4.28 раз.at PC-Low выше, среднее ускорение равно 5.01 раз, максимальное значение 8.00 раз.сокращение спроса из-за количественного определения PowerInfer Уметь более эффективно управлять более крупными моделями. Например, в. PC-High Использовать на OPT-175B Модельруководитьизэкспериментсередина,PowerInfer Почти два в секунду жетон, более чем llama.cpp 2.66 раз.
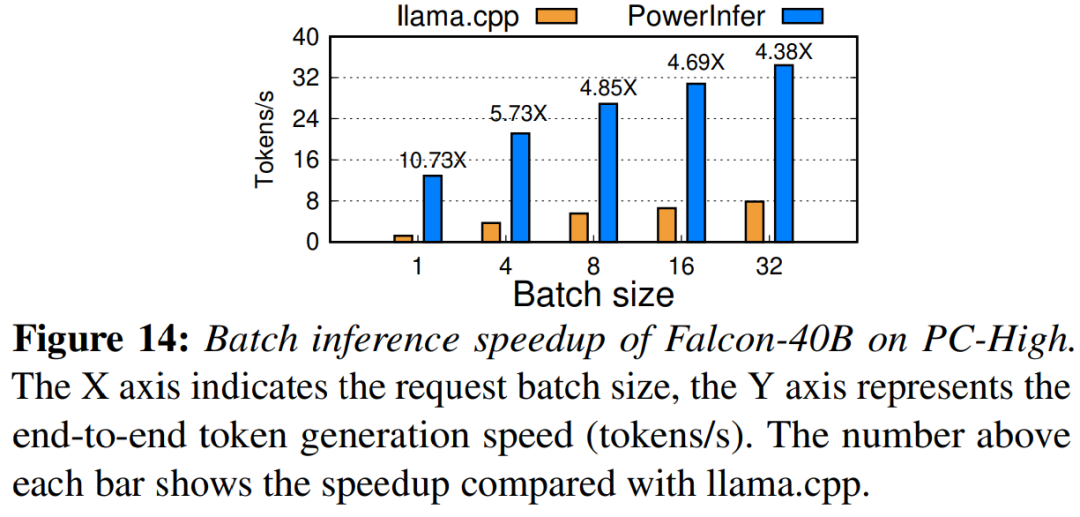
Наконец, исследование также оценило PowerInfer Комплексное обоснование производительности при различных размерах партий, например, картина 14 показано. Когда размер партии меньше 32 Когда, PowerInfer Продемонстрировали значительные преимущества, и лама по сравнению с,производительностьсреднийулучшенный 6.08 раз.По мере увеличения размера пакета PowerInfer При этом коэффициент ускорения уменьшится. Однако даже если размер пакета установлен на 32,PowerInfer По-прежнему сохраняет значительное ускорение.
Ссылка на ссылку: https://weibo.com/1727858283/NxZ0Ttdnz
Для получения дополнительной информации, пожалуйста, просмотрите оригинальную статью.
© THE END
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.
Публикуйте статьи или ищите освещение: content@jiqizhixin.com



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
