4000 слов, чтобы понять прошлое, настоящее и будущее хранилищ данных в реальном времени (рекомендуемый сбор)
В 1991 году Билл Инмон опубликовал свою первую книгу о хранилищах данных «Создание хранилища данных», ознаменовав создание концепции хранилища данных.
То, что мы часто называем корпоративным хранилищем данных (EDW), — это система, используемая для агрегирования данных из различных источников (таких как системы транзакций, реляционные базы данных и операционные базы данных), а затем облегчения доступа к данным, анализа и отчетности (например, данных о транзакциях продаж, мобильных данных). данные приложений и данные CRM), пока данные собираются в хранилище данных, все предприятие может получить к ним доступ и использовать их, что упрощает полное понимание бизнеса для всех. Наши инженеры по данным и бизнес-аналитики могут применять соответствующие данные из этих различных источников к таким аспектам, как бизнес-аналитика (BI) и искусственный интеллект (ИИ), чтобы улучшить прогнозы и, в конечном итоге, принять для нас более эффективные бизнес-решения.
Зачем предприятиям нужны хранилища данных реального времени
В традиционном смысле хранилища данных в основном обрабатывают данные T+1, то есть результаты анализа данных, полученные сегодня, можно увидеть только завтра. Концепция T+1 исходит из торговли акциями, которая представляет собой систему торговли акциями, то есть. акции, купленные в тот же день, будут видны только завтра. Их можно будет продать только на следующий торговый день.
С быстрым развитием Интернета и онлайн-бизнеса во многих отраслях объем данных растет беспрецедентными темпами. Важность своевременности данных в деятельности предприятия становится все более заметной. Предприятия предъявляют более высокие требования к обработке больших объемов данных. не структурированная обработка данных, быстрая пакетная обработка, обработка данных в реальном времени, полный анализ данных и т. д. Поскольку традиционные хранилища данных ориентированы на структурированные данные, имеют длинные пути моделирования и ограничены возможности крупномасштабной обработки данных, предприятиям срочно необходимо повысить своевременность обработки больших данных и изучить ценность данных более экономичным способом.
Возможность обработки данных в режиме реального времени также стала для предприятий основным фактором повышения их конкурентоспособности.
Процесс обработки данных
Прежде чем понять, как хранилище данных обрабатывается в реальном времени, давайте сначала разберемся со стратификацией данных. Каждое предприятие можно разделить на разные уровни в соответствии с потребностями его бизнеса, но самая основная идея многоуровневого слоя заключается в том, что данные теоретически делятся на три уровня: уровень источника (ODS), уровень хранилища данных (DW) и уровень обслуживания данных (APP). )./ДВА). На основе этого базового уровня можно удовлетворить различные потребности бизнеса.
- ODS:Operation Data Store,Также называется исходным слоем. Таблица данных исходной системы хранилища данных обычно сохраняется неповрежденной.,Это называется слоем ODS.,Это продолжениеданныесклад Библиотечная обработкаданныеисточник。
- DWданные многослойные,Обычно делится на DWD снизу вверх,DWB,DWS。
- DWD: сведения о хранилище данных, уровень данных,Это уровень изоляции между бизнес-уровнем и библиотекой данныхсклад. В основном выполните некоторую очистку данных на уровне данных ODS (удаление нулевых значений, грязных данных, Превышение предельного диапазона) и стандартизированная работа.
- DWB: базовый уровень данных базы хранилища данных.,То, что хранится, является объективным,Обычно используется в качестве среднего слоя.,Его можно рассматривать как уровень данных большого количества показателей.
- DWS:Data Warehouse Service уровень обслуживания данных,На основе базовых данных DWB.,В основном для легкого агрегирования поведения пользователей.,Интегрируйте и суммируйте данные на уровне обслуживания, который анализирует определенную предметную область.,Обычно это широкий стол. Используется для предоставления последующих деловых запросов.,OLAP-анализ,данные Распространение и т. д.。
- Уровень обслуживания данных/уровень приложений (APP/DWA). Этот уровень в основном предоставляет продукты данных, а также анализ и использование данных.,Передаем отчет, сказав данные,или сказал такие большие широкие часы,Обычно его размещают здесь.
Общие решения для хранилищ данных реального времени
В настоящее время хранилища данных делятся на автономные хранилища данных и хранилища данных в реальном времени. Автономные хранилища данных, как правило, представляют собой традиционные решения ETL данных T + 1, тогда как хранилища данных в реальном времени обычно представляют собой решения ETL минутного или даже второго уровня. Более того, базовая архитектура автономных хранилищ данных и хранилищ данных в реальном времени также различается. Автономные хранилища данных обычно создаются с использованием традиционных моделей архитектуры больших данных, тогда как хранилища данных в реальном времени создаются с использованием Lambda, Kappa и других архитектур.
LAMBDA & KAPPA архитектура реального времени
В настоящее время существуют две типичные архитектуры для обработки в реальном времени: архитектура Lambda и архитектура Kappa. По историческим причинам появление и развитие этих двух архитектур имеют определенные ограничения.
Лямбда-архитектура. Добавление новых ссылок для обработки данных в реальном времени на основе автономной архитектуры больших данных требует поддержки двух наборов кодов для автономной обработки и обработки в реальном времени;
Архитектура Lambda удовлетворяет потребности в данных различных наборов данных путем разложения данных на три уровня: уровень обслуживания, уровень скорости (уровень потоковой обработки) и пакетный уровень. На уровне пакетной обработки в основном обрабатываются автономные данные, а полученные данные предварительно обрабатываются и сохраняются. Запрос выполняется непосредственно на основе результатов предварительной обработки без необходимости полных вычислений и, наконец, предоставляется бизнес-приложениям в виде пакетных представлений.
Развертывание в реальных производственных средах обычно можно увидеть на рисунке ниже. Как правило, для удовлетворения потребностей в реальном времени требуется сложное взаимодействие между рядом различных систем хранения и вычислений (HBase, Druid, Hive, Presto, Redis и т. д.). Кроме того, несколько хранилищ Необходимо поддерживать грубую синхронизацию посредством задач синхронизации данных. Архитектура Lambda чрезвычайно сложна в реальном процессе внедрения, что отнимает много времени при разработке всего бизнеса.

недостаток:
(1) Он состоит из нескольких механизмов и систем. Реализация пакетных, потоковых и объединенных запросов требует использования разных языков разработки, что приводит к высоким затратам на разработку, обслуживание и обучение;
(2) Данные хранятся в нескольких копиях в разных представлениях, что приводит к бесполезной трате места для хранения и затрудняет решение проблемы согласованности данных.
Архитектура Каппа: мы надеемся интегрировать пакетную и потоковую обработку, интегрировать автономную обработку и обработку в реальном времени в набор кодов, а также снизить затраты на эксплуатацию и обслуживание. Архитектура Kappa удаляет уровень пакетной обработки на основе архитектуры Lambda, использует преимущества распределенных характеристик потоковых вычислений, увеличивает временное окно потоковых данных, унифицирует пакетную обработку и потоковую обработку, а обработанные данные могут быть напрямую использованы бизнесом. слой. Поскольку в архитектуре Kappa задания обрабатывают все исторические и текущие данные, полученные результаты называются пакетными представлениями в реальном времени (Realtime_Batch_View).
Система обработки потоков в архитектуре Kappa обычно реализуется с использованием Spark Streaming или Flink, а уровень обслуживания обычно реализуется с использованием MySQL или HBase.

Схема развертывания архитектуры Kappa
недостаток:
(1) Использование очередей сообщений, таких как Kafka, для сохранения всей истории, но Kafka сложно обновлять и исправлять данные. При возникновении сбоя или обновления всю историю необходимо переделывать, что занимает много времени;
(2) Kappa по-прежнему нацелена на неизменяемые данные и не может агрегировать снимки набора данных, сформированные из нескольких источников переменных данных, в реальном времени, что делает ее непригодной для специальных запросов.
Из-за вышеперечисленных недостатков архитектура Каппа редко используется в реальности.
Может ли интеграция озера и склада решить проблемы в реальном времени?
Может ли популярная в настоящее время интеграция озера и склада решить проблемы в реальном времени? Каковы стандарты интеграции озер и складов? Gartner считает, что интегрированное озеро и хранилище представляет собой конвергентную архитектуру, которая сочетает в себе гибкость озера данных с простотой использования, стандартизацией и высокой производительностью хранилища данных без островов данных.
Представляя собой идеальное сочетание озера и хранилища данных, новое поколение интегрированной архитектуры озера и хранилища данных фокусируется на потребностях бизнеса и решает технические трудности, вызванные цифровой трансформацией последних лет, включая следующие аспекты:
- Режим реального времени стал основным средством повышения конкурентоспособности предприятия. текущее озеро、склад、илиlakeсклад разделения основаны на T+1 спроектированный, облицованный T+0 Анализ в режиме реального времени по требованию не может удовлетворить потребности пользователей.
- Все пользователи (пользователи BI, специалисты по данным и т. д.) могут использовать одни и те же данные, чтобы избежать островков данных.
- догонять Высокий параллелизмспособность,Поддержка сотен тысяч пользователей для одновременного доступа к одним и тем же данным с помощью сложных аналитических запросов.
- Традицию Hadoop критиковали за недостатки в поддержке транзакций и других аспектах.,Не смог сохранить свою популярность после быстрого развития.,Продолжать руководить управлением данными,因此事务支持在озеросклад Одно тело Архитектураследует улучшитьипродвигать。
- Собственная облачная библиотека данных постепенно совершенствуется.,На основе технологии разделения хранения и вычислений.,Это может принести пользователям различные преимущества: снижение технических порогов, снижение затрат на обслуживание, улучшение пользовательского опыта и экономию затрат на ресурсы.,已成为了озеросклад Одно тело落地的重要法门。
- Чтобы раскрыть ценность данных, повысьте уровень интеллекта предприятия.,Роли пользователей, такие как специалисты по данным, должны проводить глобальный анализ данных с использованием нескольких типов данных.,включая, помимо прочего, исторические、в реальном времени、онлайн、офлайн、внутренний、внешний、структурированный、Неструктурированные данные.
Облачное хранилище данных + Omegaархитектура реального времени Реализуйте озерный склад в режиме реального времени
Облачная база данных обеспечивает полное разделение хранения и вычислений.
Облачные базы данных, такие как OushuDB и Snowflake, преодолевают ограничения традиционных MPP и Hadoop, обеспечивая полное разделение хранилища и вычислений. Вычисления и хранилища могут быть развернуты в различных физических кластерах и достигать высокого уровня параллелизма за счет технологии виртуальных вычислительных кластеров, обеспечивая при этом транзакцию. поддержка Это стало ключевой технологией для реализации интеграции озер и складов.
Взяв за пример OushuDB, он реализует облачную архитектуру, которая разделяет хранилище и вычисления, а также использует технологию кластера виртуальных вычислений для достижения высокого уровня параллелизма в сверхкрупномасштабном кластере, состоящем из сотен тысяч узлов, обеспечивая поддержку транзакций и предоставляя реальные -временные возможности. В одном фрагменте данных больше нет данных.
Складское решение Lake на основе платформы реального времени Omega
Ранее мы упоминали, что, поскольку Kappa Фактическая реализация архитектуры сложна, Lambda Архитектуре сложно обеспечить согласованность данных, и обеим архитектурам сложно обрабатывать изменяемые данные (например, постоянно меняющиеся данные в реальном времени в реляционных базах данных), поэтому, естественно,необходима новая архитектура для удовлетворения всех потребностей предприятий. это для анализа в реальном времени. Omega Полныйархитектура реального времени,Omega Архитектура предложена Odd Technology на основе ее практики в различных отраслях и одновременно обеспечивает обработку потоков в реальном времени, анализ по запросу в реальном времени и автономный анализ.
Архитектура Omega состоит из системы потоковой обработки данных и хранилища данных реального времени. По сравнению с Lambda и Kappa, в архитектуре Omega впервые представлены концепции хранилища данных в реальном времени и представления моментальных снимков. Представление моментальных снимков представляет собой моментальный снимок T + 0 в реальном времени, сформированный путем сбора изменяемых источников данных и неизменяемых источников данных. Это понятно. зеркало и история всех источников данных в хранилище данных реального времени, которая меняется в реальном времени по мере изменения исходной базы данных.
Таким образом, запросы в реальном времени могут быть реализованы с помощью представлений снимков, хранящихся в хранилище данных реального времени. Сценарии, предоставляемые с помощью снимков в реальном времени, можно разделить на две категории: одна — запрос к нескольким базам данных после агрегирования нескольких исходных баз данных, например представление прав страхового пользователя, другой — аналитический запрос с любой степенью детализации по времени, например; объем транзакций за последние 5 минут, объем открытий кредитных карт за последние 10 минут и т. д.
Кроме того, исторические данные в любой момент времени могут быть получены через снимок T+0 (в целях экономии места снимок T+0 может храниться в хранилище данных ODS реального времени в виде застежки-молнии, поэтому представление моментального снимка можно понимать как молнию в реальном времени), поэтому автономные запросы могут быть завершены в хранилище данных в реальном времени, результаты автономных запросов могут содержать самые последние данные в реальном времени, и нет необходимости использовать традиционные Комбинация разделения склада MPP+Hadoop Lake для обработки пакетных запросов и аналитических запросов в автономном режиме.
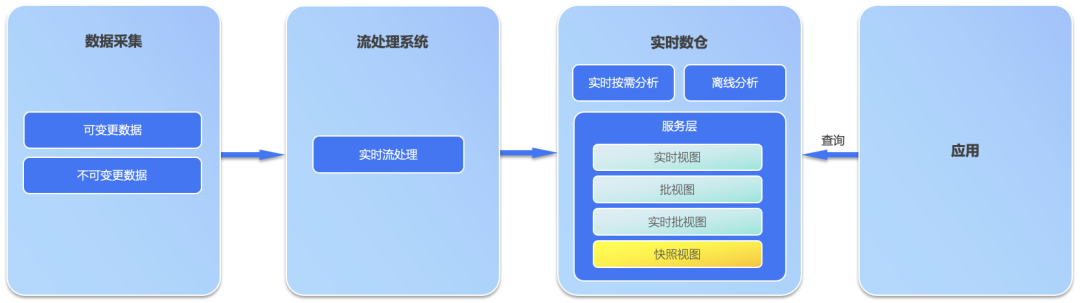
Логическая схема архитектуры Omega
Система потоковой обработки может реализовать либо непрерывную потоковую обработку в реальном времени, либо пакетную потоковую интеграцию в архитектуре Kappa. Однако, в отличие от архитектуры Kappa, хранилище данных OushuDB в реальном времени хранит все исторические данные из Kafka (подробности см. на рисунке ниже). ). В архитектуре Kappa коллекция исходного кода обычно хранится в Kafka.
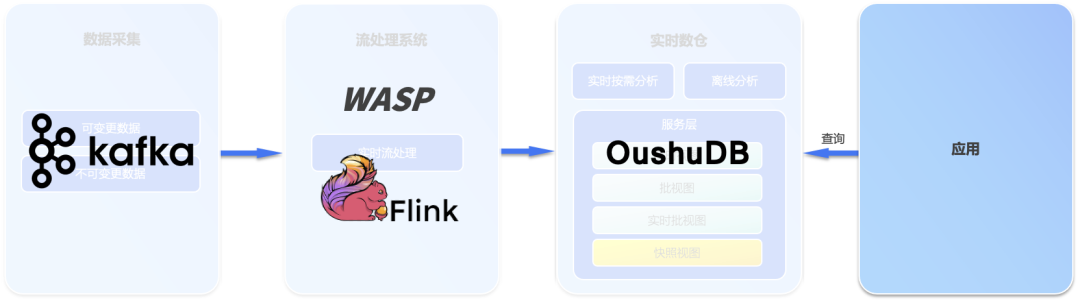
Схема развертывания архитектуры Omega
Поэтому, когда необходимо изменить версию потоковой обработки, механизму потоковой обработки больше не требуется доступ к Kafka. Вместо этого он обращается к хранилищу данных в реальном времени OushuDB для получения всех исторических данных, что позволяет избежать проблемы Kafka с обновлением данных. и исправление ошибок и значительно повышает эффективность. Кроме того, весь уровень обслуживания также может быть реализован в хранилище данных реального времени без необходимости введения дополнительных компонентов, таких как MySQL и HBase, что значительно упрощает архитектуру данных и реализует интеграцию города Хукан (озеро данных, хранилище данных) и рынок). Он реализует интеграцию озер и складов полной архитектуры Omega в реальном времени, которую мы также называем интеграцией озер и складов в реальном времени.
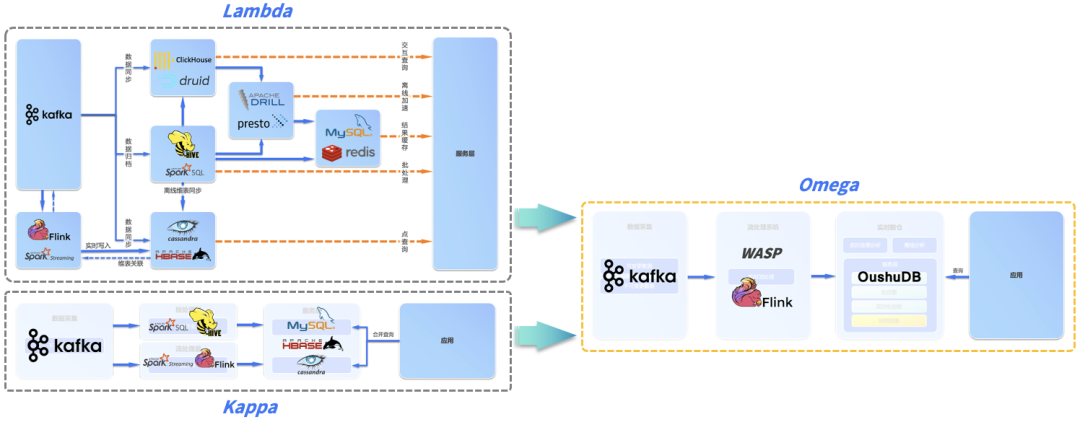
Omega vs. Lambda vs. Kappa
Заключение:
В условиях сложных и постоянно меняющихся новых бизнес-сценариев по мере дальнейшего развития технологий обработки данных будут появляться новые стеки технологий реального времени, а технологии обработки данных также будут подвергаться разделению и интеграции. В настоящее время тенденция интеграции относительно очевидна, например, интеграция озера и хранилища в реальном времени, интеграция возможностей обработки в реальном времени в хранилище данных. Независимо от того, как предприятие выбирает хранилище данных реального времени, построение технологического стека платформы данных обычно должно следовать трем основным принципам:
- Уровень архитектуры должен оставаться гибким и открытым.,Поддерживает сосуществование нескольких технологий. в настоящий момент,предприятие развернуло несколько систем,Иметь свой собственный набор системы Архитектура,При реализации интеграции технологий необходимо максимально использовать исходные ИТ-активы.,Защитите инвестиции клиентов.
- эффективное использование ресурсов,Сократите затраты и повысьте эффективность. Оригинальный стек технологий Традиции.,В расчете участвуют все ресурсы,Вызывает бесполезную трату ИТ-ресурсов. например,Объединение собственных облачных ресурсов,Может реализовать изоляцию ресурсов и динамическое управление.,Обеспечить максимальное использование ресурсов.
- Познакомьтесь с более высоким пользовательским опытом. С точки зрения пользователя,При условии соблюдения технических условий.,Например, высокая производительность, высокий уровень параллелизма и более высокая производительность в реальном времени.,Иметь более сильные возможности обработки информации,Способен удовлетворить различные потребности пользователей в услугах за короткий период времени.,Улучшите пользовательский опыт。
С увеличением числа сценариев анализа в реальном времени будут более широко использоваться продукты и решения с возможностями обработки в реальном времени, такие как хранилища данных в реальном времени.
--end--



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
