4 удивительных проекта искусственного интеллекта с открытым исходным кодом!
Всем привет, сегодня мы продолжим говорить о том, что происходит в технологическом кругу.
1. Чемпион
Контролируемый и последовательный проект создания анимации изображения человека, основанный на трехмерных параметрах. Все, что вам нужно, это фотография, чтобы заставить людей на фотографии двигаться.
Учитывая экшн-видео, Champ может позволить разным людям воспроизвести одно и то же действие.
Давайте сначала посмотрим на эффект фотографий реальных людей:
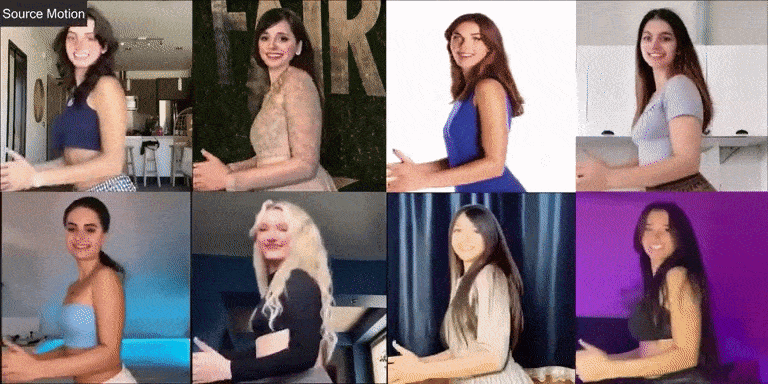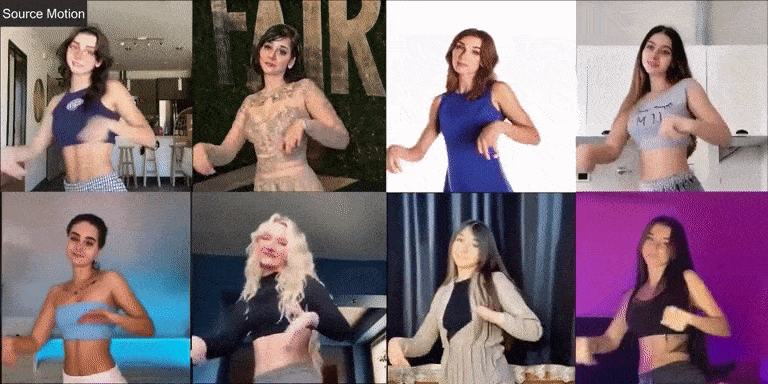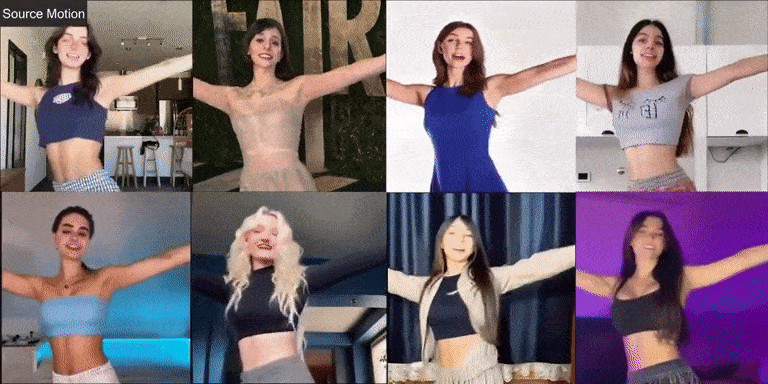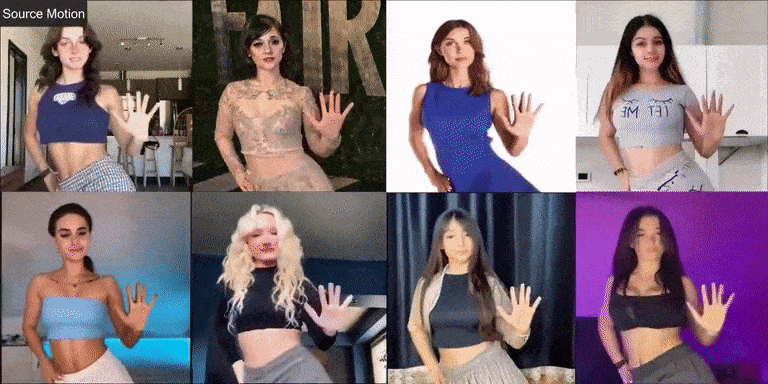
Champ также хорошо справляется с виртуальными персонажами и фотографиями разных стилей:


Проект в основном опирается на модель восстановления человеческой сетки для извлечения параметрической трехмерной модели человеческой сетки из входного видео. SMPL Последовательность рендеринга различной информации управляет генерацией видео.
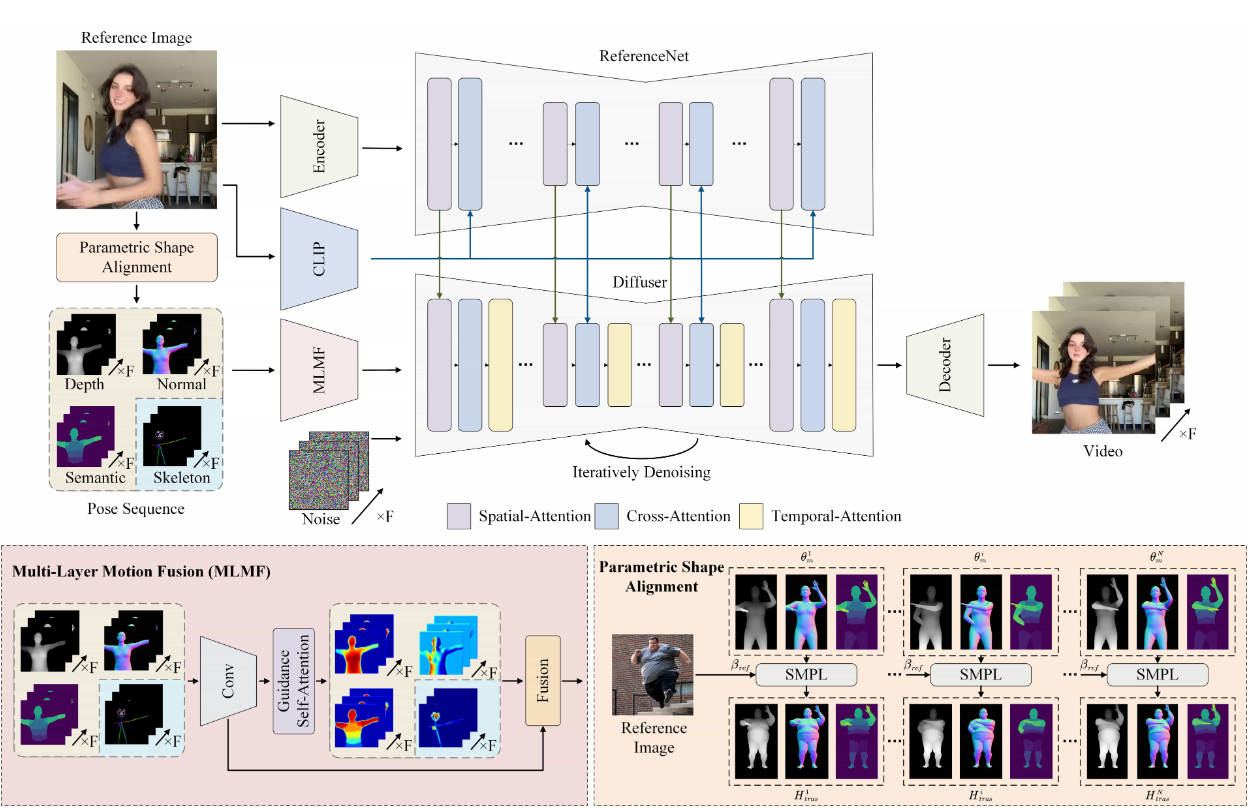
На диаграмме структуры проекта мы видим, что Чамп Многослойный модуль объединения движений (MLMF) используется для управления детальной генерацией видео с помощью глубины, костей, масок, нормалей и семантики, что делает его более реалистичным и гибким. Эти пять частей информации также можно получить через comfy Пример создания рабочего процесса для узлов.
Кроме того, Чемп использовать SMPL Форма тела персонажей в сгенерированном видео сохраняется единообразной. Выравнивая параметры формы тела, Champ Превосходит других в сохранении позы и движений персонажа. SOTA Работа.

Сравнение эффектов
Проект предоставляет демонстрационную версию. Если требуется локальное развертывание, видеопамять будет занята в соответствии с сгенерированным разрешением. Чем выше разрешение, тем больше используется видеопамять, что требует определенной аппаратной поддержки. Заинтересованные партнеры также могут попробовать сегментированную генерацию. .
Адрес проекта:
https://github.com/fudan-generative-vision/champ
2. Музе В
Проект создания виртуального человеческого видео бесконечной длины и высокой точности, основанный на параллельном шумоподавлении визуальных условий.
В этом проекте мы можем увидеть:
- Перемещение Ёне и Джинкс


- Учитель Ду Фу, который много лет моргал своими большими глазами

MuseV — проект создания виртуального человеческого видео. 在Создать сценуиз Есть и хорошие стороныиз Производительность。

MuseV поддерживает следующие методы генерации: изображение в видео, текст в изображение в видео и видео в видео. Кроме того, он совместим с экосистемой Stable Diffusion.
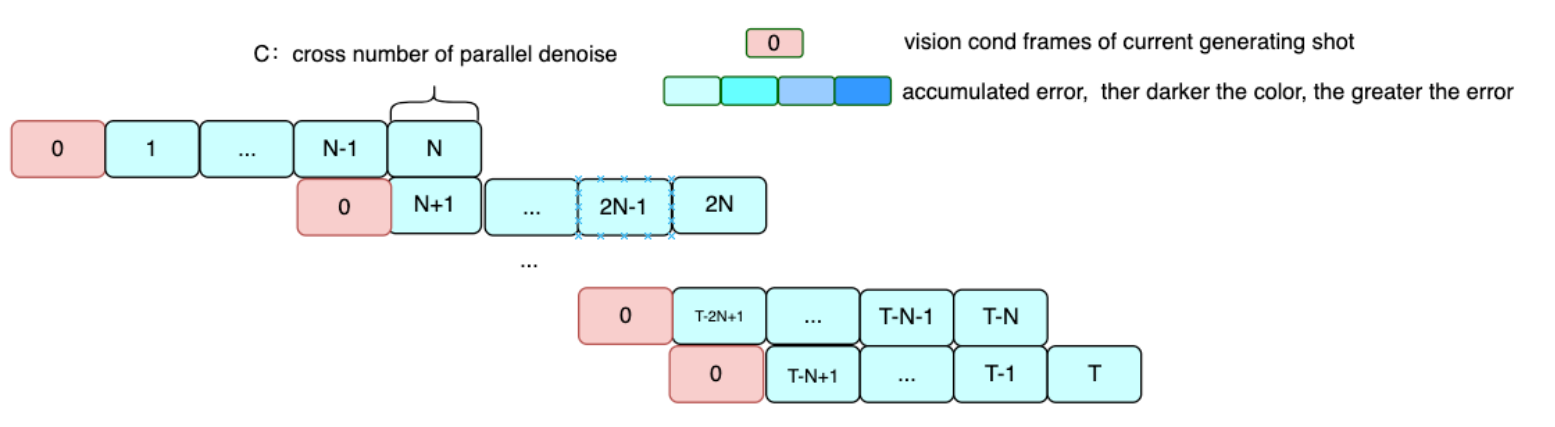
Параллельное шумоподавление
Для текущей схемы генерации, если условия первого кадра видео и изображения не совпадают, информация первого кадра может быть уничтожена, поэтому MuseV обычно имеет следующий процесс использования:
- ОК, ссылка на видео
- Используйте ссылкувидеоизпервый кадрДелайте снимки, чтобы делать снимки、controlnetпроцесс,Можно использовать MJ и другие платформы.
- Используйте 2 китайских из для создания изображений и просмотра видео. MuseV 生成видео
Из-за ограниченного типа обучающих данных MuseV имеет больший диапазон движения при более низких разрешениях, но более низкое качество видео при более высоких разрешениях; он имеет лучшее качество изображения, но меньший диапазон движения; Также может потребоваться использование большего количества типов данных для обучения, таких как наборы высококачественных видеоданных с высоким разрешением.
В недавнем обновлении команда авторов обновила графический интерфейс Huggingface, чтобы его можно было использовать онлайн.
Обнимающий адрес:
https://huggingface.co/spaces/AnchorFake/MuseVDemo
На домашней странице команды авторов также упоминается, что их предстоящий MuseTalk (высококачественная модель синхронизации губ в реальном времени, демо-версия была представлена на домашней странице проекта MuseV) можно использовать в сочетании с MuseV, и полученные результаты будут лучше. Вы можете рассчитывать на одну руку.
Адрес проекта:
https://github.com/TMElyralab/MuseV
3. Браш Нет
Модель закрашивания изображения с разложенной двухветвевой диффузией. Что касается области маски на экране (маска, отсутствуют части), BrushNet может ее восстановить. Кроме того, BrushNet может работать по принципу «подключи и работай» с любой предварительно обученной диффузионной моделью.

Отображение эффектов
Модель выводит ненарисованное изображение с учетом входных данных маски и замаскированного изображения. Сначала маска субдискретизируется, чтобы соответствовать размеру скрытого пространства, а изображение маски подается в кодер VAE для выравнивания распределения скрытого пространства. Затем задержка шума, задержка изображения маски и маска понижающей дискретизации объединяются в качестве входных данных. Затем из модели извлекаются признаки. После шумоподавления сгенерированное изображение и изображение маски смешиваются с маской размытия для создания изображения.
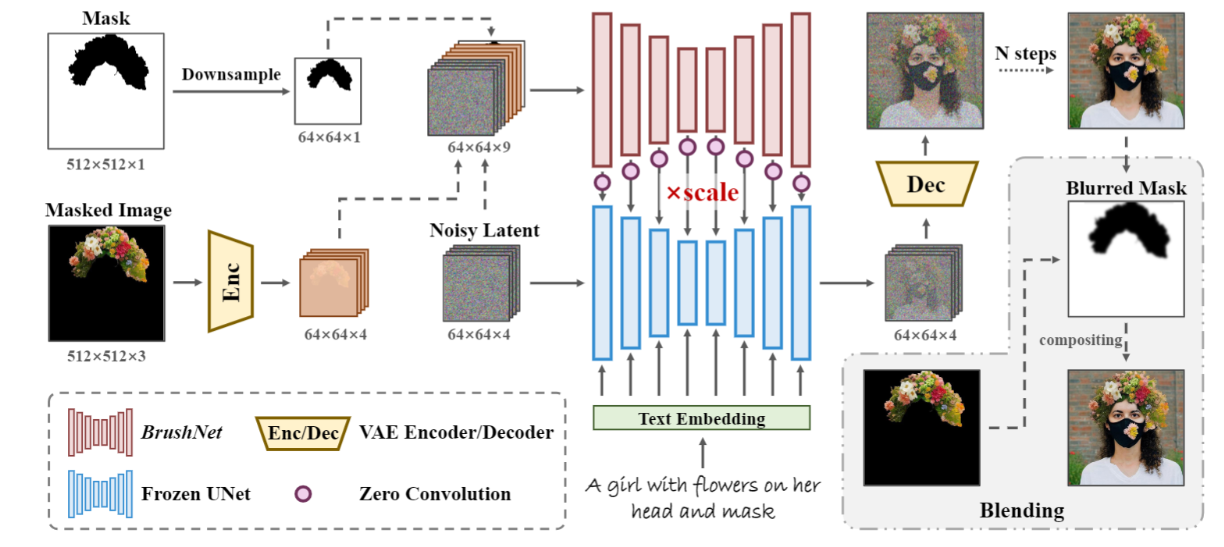
BrushNet не изменяет веса предварительно обученной модели диффузии, может регулировать масштаб сохранения и дополнительно настраивать коэффициент сохранения областей без маски. Это делает BrushNet очень гибким и легко подключаемым.
Команда авторов также продемонстрировала возможность сочетать BrushNet с различными моделями диффузии, в том числе:
- DreamShaper (DS)
- epiCRealism (ER)
- Henmix_Real (HR)
- MeinaMix (MM)
- Realistic Vision (RV)

Эффекты под разные модели
В соответствии с личными потребностями пользователя уже обученная модель SD может быть гибко выбрана для интеграции, и вам останется только выбрать тот эффект, который вас устраивает.
Адрес проекта:
https://github.com/TencentARC/BrushNet
4. Медиа Кроулер
Это проект сканера с открытым исходным кодом, используемый для сканирования видео, изображений, комментариев, лайков, репостов и другой информации из Xiaohongshu, Douyin, Kuaishou, Bilibili и Weibo.
MediaCrawler строит мост на основе библиотеки драматурга, сохраняет контекстную среду браузера после успешного входа в систему и получает некоторые зашифрованные параметры путем выполнения выражений JS. Таким образом, нет необходимости воспроизводить основной JS-код шифрования, а сложность обратного проектирования значительно снижается. Создание проекта в среде Python также значительно улучшает масштабируемость проекта и имеет неограниченный потенциал.

В проекте есть следующие три состояния входа:
- QRCode (login_by_qrcode)
- Номер мобильного телефона (login_by_mobile)
- Cookie (login_by_cookies)
Автор также объясняет подготовку к входу в систему, чтобы пользователям было проще пользоваться.

Более того, MediaCrawler имеет модульную конструкцию, и пользователи могут определять ключевые слова для сканирования, назначенные каталоги и т. д. в соответствии со своими потребностями. Возможна «частная настройка» стратегий сканирования.
Кстати, автор лично удалил этот проект, получивший за несколько дней 10к+ звезд. Когда мы увидели это снова, на главной странице появилось много новых заявлений об отказе от ответственности. Надо полагать, сам автор не хочет, чтобы этот краулерный проект с такими удобными функциями приносил ему какие-либо неприятности.
Адрес проекта:
https://github.com/NanmiCoder/MediaCrawler
Ладно, на этом выпуске всё, увидимся в следующем!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
