3000 слов | Одна статья объясняет сценарии применения Redis при разработке больших данных.
Предисловие
Недавно я написал статью оredisИзделия разной архитектуры:Redis: Расскажи мне, как выдержать давление 20 миллионов запросов в секунду,В основном говорим о ежедневном развитии,Что означает оптимизация,Для повышения эффективности взаимодействия с Redis.
В то же время статья также начинается с точки зрения подключения SparkStreaming к кластеру Redis и описывает, как уменьшить количество взаимодействий с кластером Redis за счет настройки конвейера JedisCluster, тем самым уменьшая задержку обработки данных.
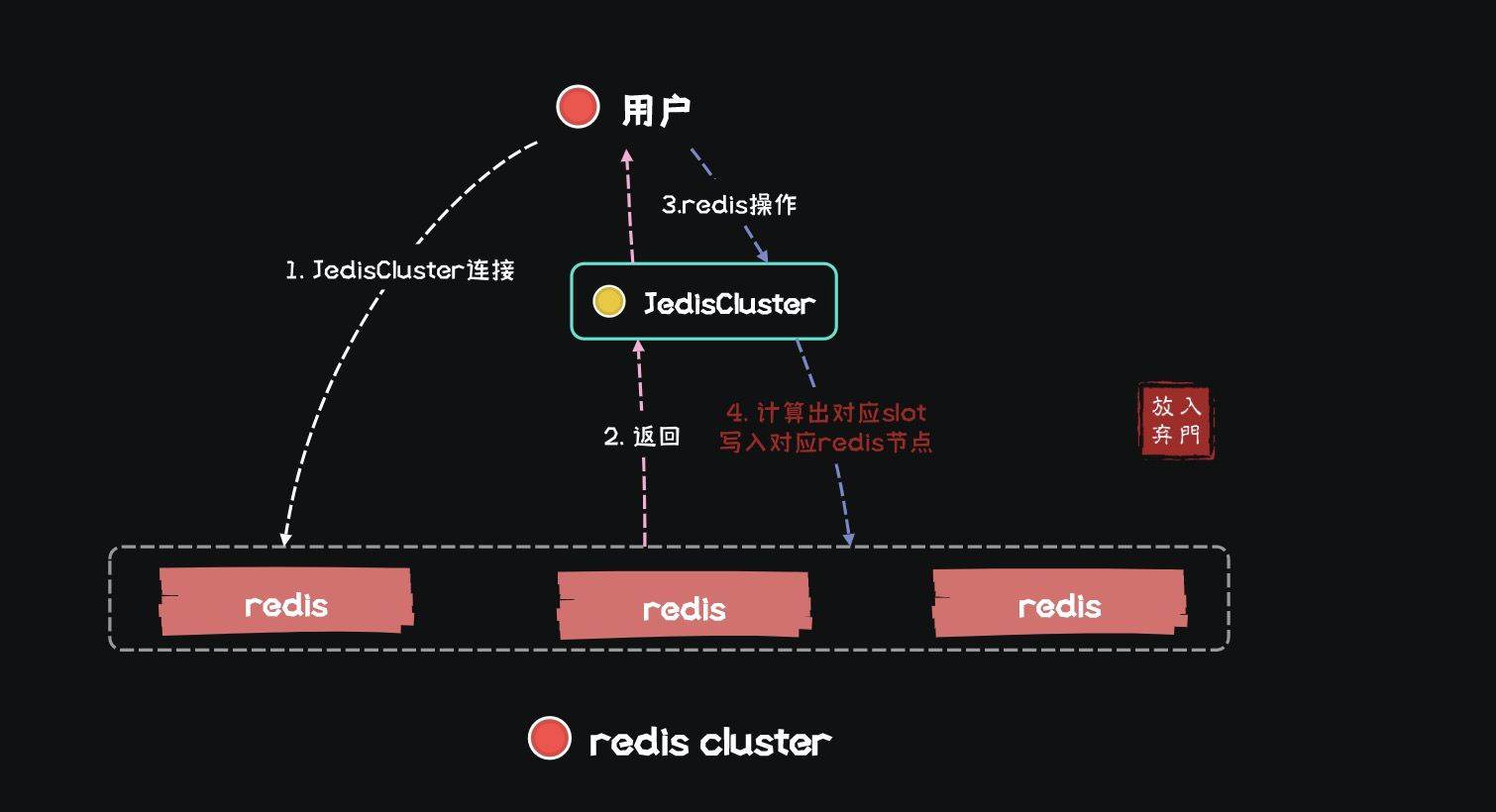
Итак, при каких обстоятельствах Redis будет использоваться в приложениях для обработки больших данных в реальном времени?
сценарии применения Redis
В приложениях реального времени SparkStreaming или Flink Redis обычно имеет два сценария применения:
- Данные таблицы измерений обновляются в автономном режиме, используются для добавления информации об измерениях к потоковым данным, обычно обновляются ежедневно/ежемесячно.
- Применяйте обновления данных о состоянии в режиме реального времени
В первом сценарии приложение реального времени выполняет только операции get и hget на redis, тогда как для второго сценария требуются как операции get, так и set.
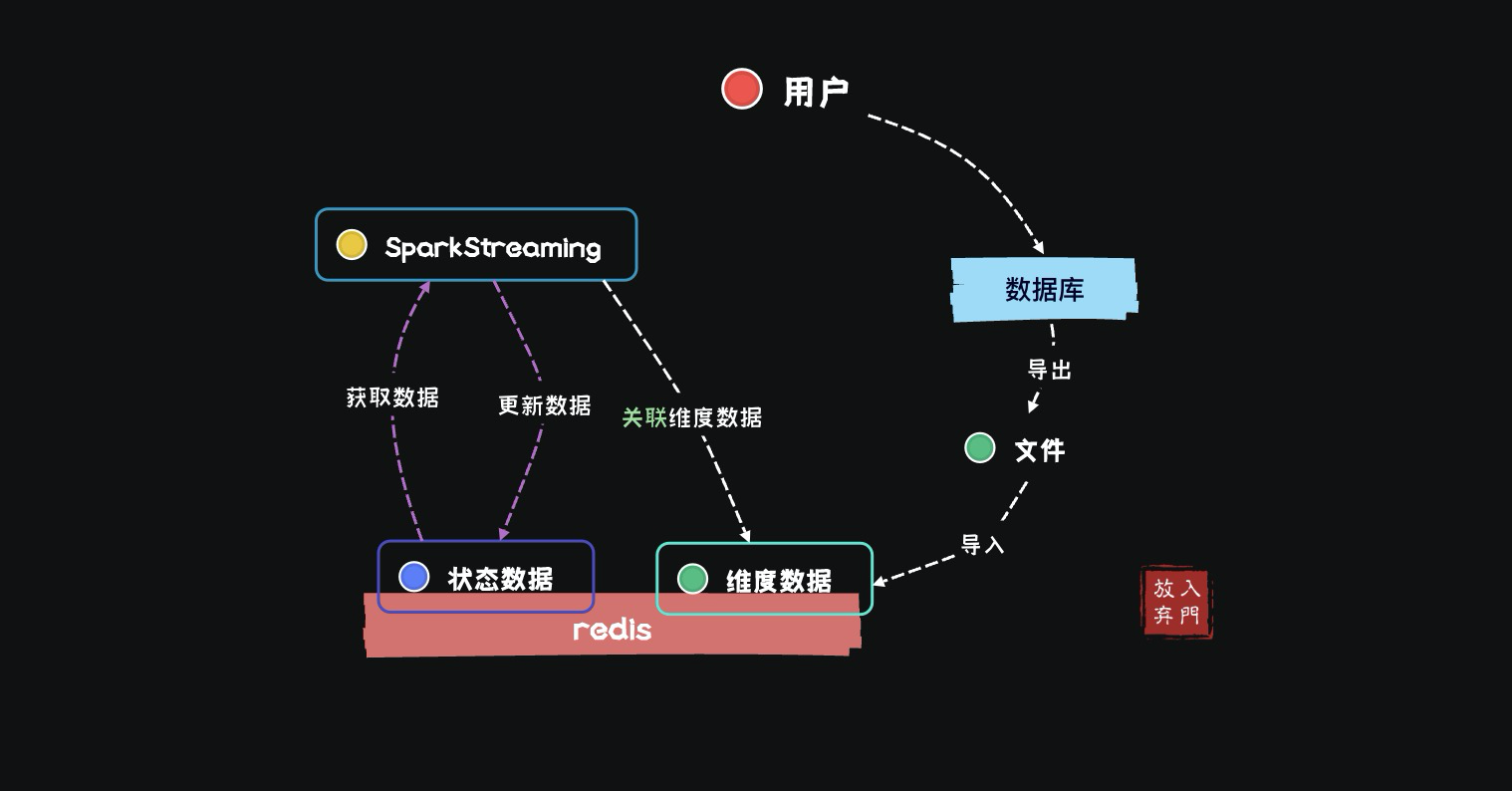
Габаритные данные
В моем ежедневном доступе к данным и разработке в реальном времени,Обычно доступ к данным осуществляется из одноранговой системы в соответствии с согласованным протоколом.,Затем напишите в производство Kafka в режиме реального времени.,Завершить разработку бизнес-сценариев реального времени. в целом,Конечные результаты многих бизнес-сценариев ориентированы на пользователей.,Однако данные, связанные с Kafka, не могут охватить всю информацию о пользователе.,Итак, нам нужно получить его из базы данных.,в соответствии сУникальный идентификатор пользователя для всех данных в системе.Импортировать вredisсередина。
Например,Мы получили доступ к данным пользователей, обращающихся к приложению в Kafka,Эти данные могут иметьID пользователя、Время начала посещения、Продолжительность посещения、Посетите трафики т. д. поля。Но если мы хотим проанализировать,Какой возрастной группе пользователей больше всего нравится это приложение? При сборе пользователей для доступа к приложению,Поле возраста перенести невозможно. так,Вам необходимо найти таблицу информации о пользователе в базе данных.,Чтобы запросить пользователяполе возраста,Затем экспортируйте его в Redis.
Во всем вышеописанном процессе повторного импорта оффлайн-габаритных данных необходимо выполнить следующую работу:
1. Конструкция КВ
мы знаем,Данные в Redis существуют в форме KV.,ключ уникален,Поэтому в качестве ключей обычно используются идентификатор пользователя (номер мобильного телефона, идентификационный номер) и т. д.,Тогда по бизнес-сценарию,Добавьте префикс, чтобы различать разные услуги,Избегайте перезаписи друг друга одним и тем же ключом между неиспользуемыми предприятиями.
В значении обычно используется тип хеша. Даже если имеется только одно поле, необходимо учитывать дальнейшее расширение поля. Поэтому выбор типа хэша является разумным выбором.
2. Габаритные данные Экспорт
Габаритные данныенадеватьMPPсередина,Поэтому я обычно сначала экспортирую файл,Затем импортируйте его в Redis. Если вы не хотите разрабатывать программу,Вот способ быстрого импорта Redis. первый,Просто при экспорте данных,Используйте sql для экспорта данных в формат команды, которая будет выполнена в redis-cli.,Например:
hset 1 age 10
hset 2 age 30
hset 3 age 143. Импортировать Redis
然后直接将文件重定向输入< Чтобы переустановить Cli:
redis-cli [options] < filenameФактическая операция выглядит следующим образом:
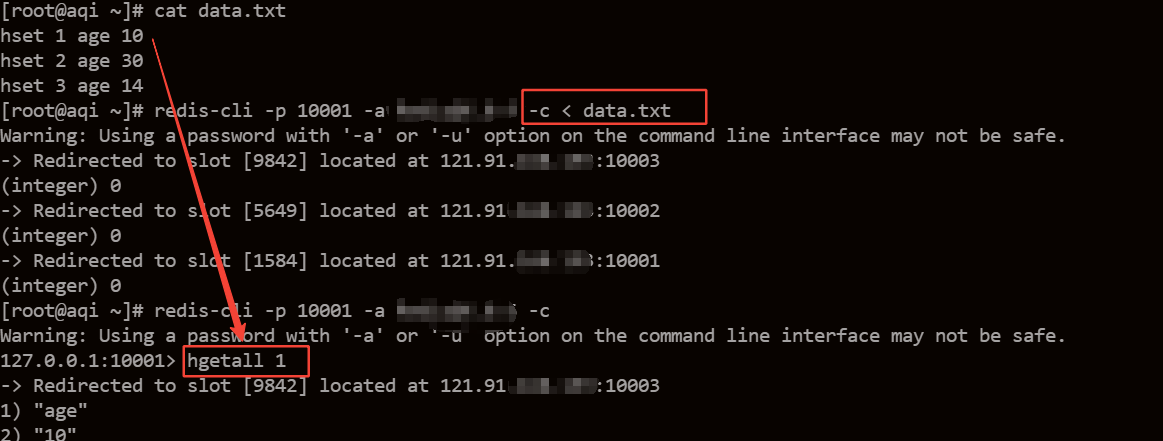
Вы можете видеть, что при перенаправлении ввода данные в файле импортируются в Redis.
4. Оптимизация решения
Вышеупомянутый метод перенаправления оболочки,Даже тот, который я использую чаще всего,Обычно пишут сценарий оболочки,Висеть на диспетчерской платформе,Просто обновляйтесь по ежедневному расписанию.,Самым большим преимуществом этого метода является то, чтоПросто и удобно, низкая стоимость разработки,Я обычно ставлю данные 7000w,На выполнение 7 значений обычно уходит около 8 часов.,Недостаток этого метода в том, что он слишком медленный.
Иногда мне нужно быстро обновить данные, чтобы увидеть результаты программы, поэтому я использую разработанную мной пакетную программу Spark. Я помещаю файл формата csv в HDFS, затем указываю путь к файлу в Spark и использую метод конвейера в Spark. записать данные в Redis.
Это по-прежнему 70 миллионов данных, указанных выше, что составляет около 1 ГБ. Размер блока в нашей HDFS составляет 128 МБ, поэтому этот файл будет автоматически разделен на 8 блоков, и Spark запустит 8 потоков для его обработки.
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
if (args.length != 5) {
print("command arguments less than 5,please check again")
sc.stop()
}
val lines = sc.textFile(args(0))
// 0 путь к файлу 1 IP 2 Port 3 password 4 действовать
val clusterPipeline = sc.broadcast(JedisClusterPool(args(1), args(2).toInt, args(3), -1, -1, 3, 1000, 1000))
val operator = args(4)
lines
.map(_.split(" "))
.foreachPartition(p => {
val poolPipelineMap = new ConcurrentHashMap[JedisPool, Pipeline](1024)
val pipelineCount = new ConcurrentHashMap[Pipeline, Int](1024)
val jedisList = new util.ArrayList[Jedis](1024)
p.foreach(x => {
// Первая версия конвейера JedisCluster была инкапсулирована мной и впоследствии оптимизирована.
val pipeline = clusterPipeline.value.initPipeline(x(0), poolPipelineMap, jedisList, pipelineCount, 512)
if ("hmset".equals(operator)) {
pipeline.hmset(x(0), clusterPipeline.value.file2Map(x))
} else if ("set".equals(operator)) {
pipeline.set(x(0), x(1))
}
})
clusterPipeline.value.pipelineSync(pipelineCount)
clusterPipeline.value.releaseConnection(jedisList)
})использоватьtextFileчитатьHDFSфайлы на,ЧтосерединаclusterPipelineЯ основан наJedisClusterПакет основан наredis В режиме конвейера кластера последние 70 миллионов данных можно импортировать в Redis всего за 1 минуту.
Конечно, в конечном итоге работа кластера переинкапсулируется, чтобы его было проще использовать в Spark.

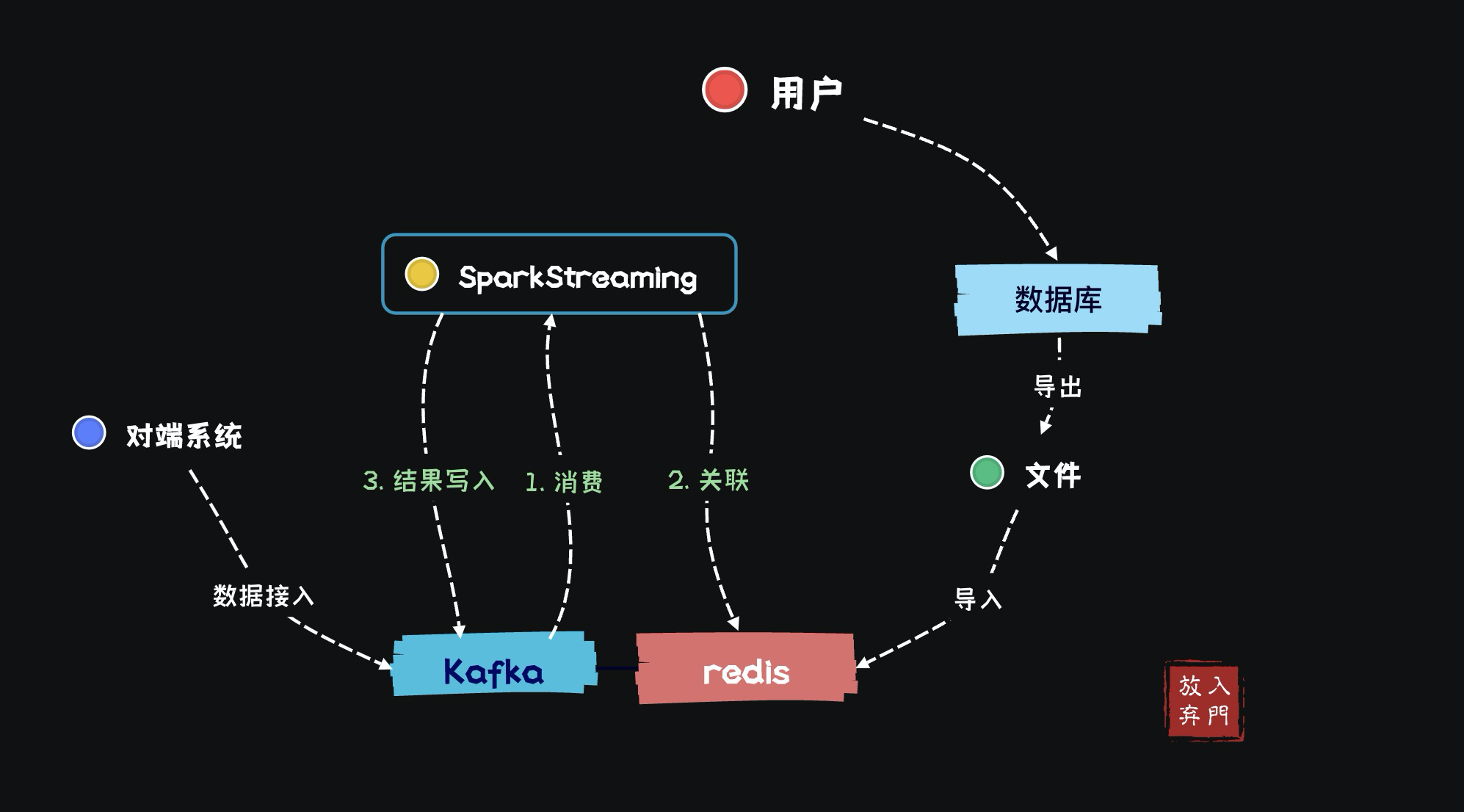
данные о состоянии
Помимо вышеперечисленного в офлайне Габаритные В дополнение к сценариям применения данных, Redis также имеет данные в реальном времени. о состоянииобновленная сцена。Данные, обычно используемые для обновления статуса,Это исходная информация о поле в Kafka. Давайте возьмем пример доступа пользователя к упомянутому выше приложению.,Что, если мы хотим записать, сколько раз пользователь обращается к приложению в день или как долго пользователь обращается к приложению в целом?
мы знаем,Будь то SparkStreaming или Flink,По умолчанию потоковая обработка данныхлицо без гражданства,Каждый фрагмент данных существует независимо,Данные будут отброшены после расчета для получения результата.,и не будет участвовать в следующем расчетесерединаидти。Поэтому нам приходится производить расчеты в реальном времени.обладающий состоянием。
1. расчет состояния mapWithState
SparkStreamingиflinkВсе предоставлено Государственный расчет,Сохранение данных о состоянии в памяти。
val conf = new SparkConf()
val duration = args(3).toInt
val ssc = new StreamingContext(conf, Seconds(duration))
ssc.checkpoint("./tmp")
val streams: DStream[String] = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
).map(_.value)
val result = streams.map(x => x.split("\t"))
.filter(x => x(0).startsWith("1"))
// Генерировать кортежи (k,v)
.map(x => (x(0), Integer.parseInt(x(21)) + Integer.parseInt(x(22)) + Integer.parseInt(x(24))
+ Integer.parseInt(x(25)) + Integer.parseInt(x(30)) + Integer.parseInt(x(31))))
.reduceByKey((x, y) => x + y)
// Государственный расчет
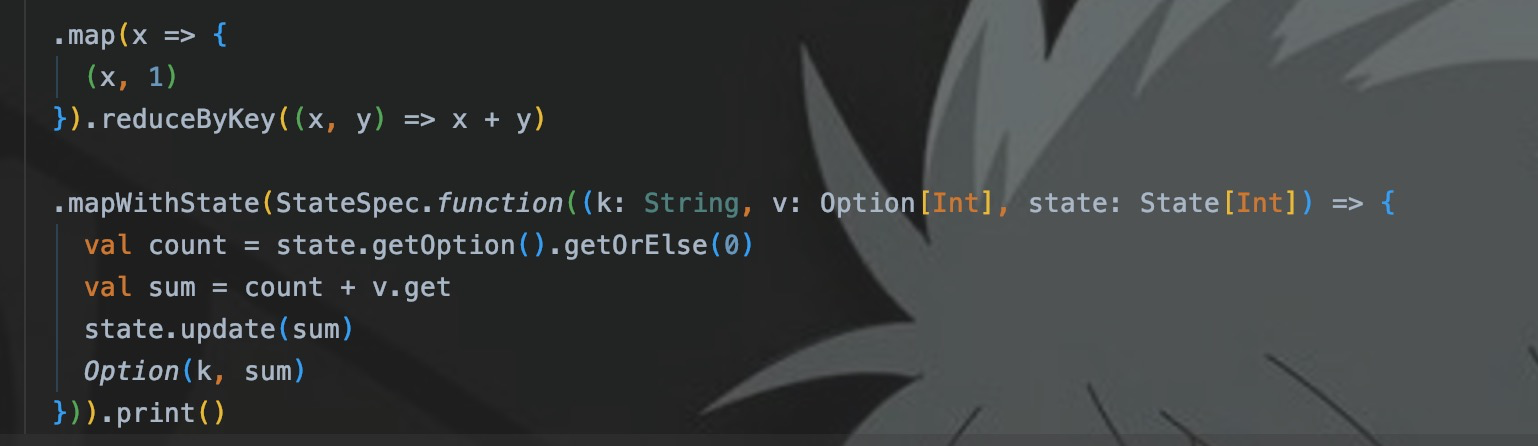
.mapWithState(StateSpec.function((k: String, v: Option[Int], state: State[Int]) => {
val state_flow = state.getOption().getOrElse(0)
var flag = 0
var sum_flow = 0
if (!state.isTimingOut()) {
val flow = v.get
sum_flow = state_flow + flow
val state_flow_M = state_flow / (1024 * 1024)
val sum_flow_M = sum_flow / (1024 * 1024)
if (state_flow_M < 1024 && sum_flow_M >= 1024) {
flag = 3
} else if (state_flow_M < 500 && sum_flow_M >= 500) {
flag = 2
} else if (state_flow_M < 200 && sum_flow_M >= 200) {
flag = 1
}
state.update(sum_flow)
}
Option((k, flag))
}).timeout(Minutes(182))
)В операторе SparkStreaming,предоставилmapWithStateГосударственный расчетоператор,Отформатируйте восходящие данные в кортежи (k, v),затем введитеmapWithStateруководить Государственный расчет,stateвыраженный вданные о состояниисередина,Текущий статус найден на основе k,тогда пройдиupdateОбновите последний статус, рассчитанный самостоятельно。
Здесь я использую MapWithState для реализации демонстрации подсчета:
Источником данных программы является сокетный поток порта 9999. Я записываю данные в порт:

Затем выведитеданные о состоянии:
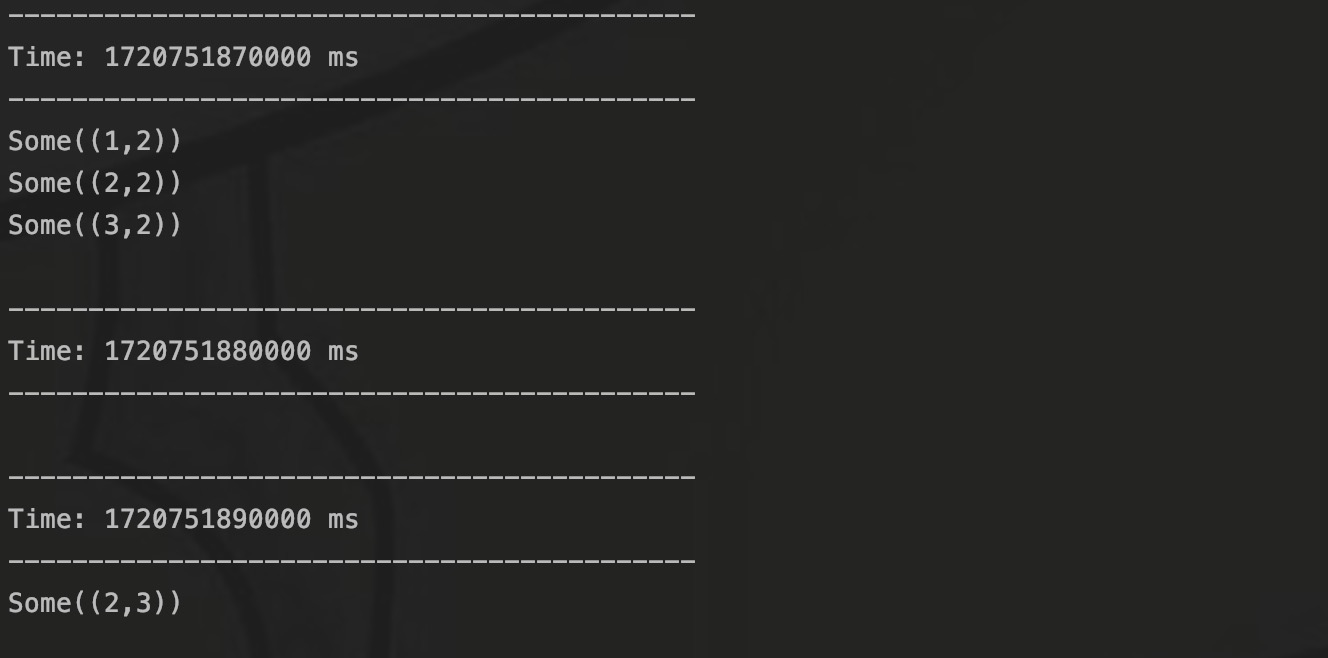
Я записал первые шесть строк данных одновременно, поэтому все эти шесть фрагментов данных находятся в одном СДР, а затем я записал последнюю строку данных. Вы можете видеть, что в третьем СДР число становится равным 2. 3 .
2. Redis реализует расчет статуса.
Но недостатком является то, что в случае сбоя программы,Предыдущие данные о состоянии могут быть утеряны (хотя контрольная точка есть). Более того, срок действия ключа довольно сложно контролировать внутри программы.,Для реализации требуется еще один большой объем логического кода.。так что дляОтделение данных о состоянии от самой программы и простота разработки,Поэтому обычно используется Redis.
val result = p.toList.map(x => {
val userID = x._1
val flow = x._2
val response_date = pipeline.hget(userID, "date")
// Получить трафик текущего пользователя из Redis
val response_flow_codis = pipeline.hget(userID, "flow")
i += 2
if (i % 512 ==0){
pipeline.sync
}
(userID, flow, response_date, response_flow_codis)
})
pipeline.sync
i = 0
result.foreach(x => {
val userID = x._1
// Данные о трафике в текущих данных
var flow = x._2
val date = x._3.get
// Исторические данные о трафике в Redis
val flow_codis = x._4.get
// Это показывает, что поток не сегодняшний и накрыт напрямую.
if (date == null || date != start_date.value) {
pipeline.hset(userID, "flow", String.valueOf(flow))
pipeline.hset(userID, "date", start_date.value)
} else if (flow_codis != "NN" && date == start_date.value) {
// Аккумулируйте текущий трафик данных и исторический трафик Redis, а затем обновите его до Redis.
flow = Integer.parseInt(flow_codis) + flow
pipeline.hset("userID, "flow", String.valueOf(flow))
}
})Приведенный выше код сначала получает исторический трафик текущего пользователя из Redis, затем суммирует его с трафиком пользователя в текущих данных и, наконец, генерирует последние данные о трафике, а затем обновляет их до Redis.
3. Государственный расчетный ключ.
Вы можете видеть, что в приведенном выше коде я поместил поле даты в Redis. Почему?
Эта программа реализуетЕжедневное накопление трафикаСценарии применения。То есть,Ежедневное движение начинается в 00:00.,останется пустым. Я встретил много разработчиков,В этом сценарииkeyРазработан какuserID + yyyymmddформат,Таким образом, каждый пользователь будет генерировать новый ключ в Redis каждый день.,Это приведет к тому, что ключ будет расти бесконечно.,Итак, чтобы решить эту проблему,Разработчик также хочет установить срок действия ключа.,Затем срок действия Redis истекает, и он очищается.
Однако из-за этой проблемы ключ постоянно меняется. Каждый раз, когда вы запрашиваете или устраняете проблему, вам необходимо создать склейку времени в формате ггггммдд. Поэтому, чтобы решить эту проблему, я добавил значение с именем date, которое хранит время в формате ггггммдд.
Каждый раз при доступе к ключу Redis сначала обращайтесь к дате и сравнивайте ее с текущим системным временем, чтобы определить, является ли поток сегодняшним. Если дата не соответствует текущему времени (дата != start_date.value), это означает, что. значение потока не «Сегодня», вам нужно только записать текущий поток данных в наложение потока, а затем обновить текущее время до даты.
Заключение
Выше приведено объяснение двух сценариев применения Redis, основанное на моих личных бизнес-сценариях разработки в реальном времени. В целом, Redis, как компонент распределенного кэша, показал отличную производительность при разработке в реальном времени, но то, как его использовать и как правильно использовать, требует задуматься от самих разработчиков.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
