2.7K Star Local высокоточное распознавание текста! OCR с открытым исходным кодом на базе GPT-4o-mini!

Если высуществовать寻找一款高精度、Запускать локально、поддерживатьсложныймакетиз OCR инструмент, то Zerox OCR Несомненно, отличный выбор.
Zerox OCR Сначала будет PDF файлы преобразуются в изображения, которые затем GPT-4o-miniМодель Определить и вывести Markdown и, наконец, все страницы, соответствующие Markdown Результаты, собранные вместе, образуют полную Markdown документ.
Он не только поддерживает распознавание текста с нулевой выборкой, но также может легко обрабатывать сложные макеты, такие как таблицы и диаграммы. Он также выводит результаты распознавания в формате Markdown, оптимизируя удобство извлечения информации.
Основные преимущества
1、Оптическое распознавание текста с нулевой выборкой
использовать GPT-4o-mini Модель выполняет распознавание текста и может обрабатывать совершенно незнакомые Типы документов, такие как PDF, изображения и т. д.,Никакие данные о предварительном обучении не требуются,Готов предоставитьВысокоточные результаты оптического распознавания символов。
2、Markdown Выходной формат
существовать OCR В процессе конвертации Zerox Преобразуйте каждую идентифицированную страницу в краткую Markdown формат для облегчения постобработки и организации текста.
Для разработчиков или обработчиков документов этот формат чрезвычайно практичен и его легко импортировать в другие системы.
3、поддерживать сложный документ
Zerox может обрабатывать не только простой текст, но и файлы, содержащие сложные макеты, такие как таблицы, диаграммы и т. д. Независимо от того, являются ли они отсканированными PDF-файлами или другими форматами, Zerox может распознать их и создать точный текстовый контент.
4、Запускать локально с помощью API поддерживать
поддерживатьЗапускать локально,Не нужно беспокоиться об утечке конфиденциальности. также,Он также обеспечивает API Интерфейс, легко интегрируемый в ваше приложение, повысит автоматизацию и эффективность бизнес-процессов.
стек технологий
- • Python
- • JavaScript
- • TypeScipt
Рабочий процесс
- • Подать документы:поддерживатьиз文件格式包括 PDF, DOCX, изображения и т. д., вы можете легко отправлять файлы в различных форматах для OCR иметь дело с.
- • Файл в изображение:Сначала документ будет Конвертироватьдля изображений,для последующего распознавания изображений.
- • Преобразование GPT-4o-мини:每个生成из图像将одеяло发送至 GPT-4o-mini Модель выполняет распознавание текста.
- • Сводная уценка:所有页面из Markdown результатодеяло Краткое содержание в полную Markdown Документация для дальнейшей обработки и анализа.
Как установить и использовать Zerox?
Помимо предоставления демо-версии существования и использования, Zerox OCR также предоставляет пакеты API Node и Python для вызова.
Загрузка не требуется, вы можете испытать мощные возможности оптического распознавания символов Zerox онлайн.
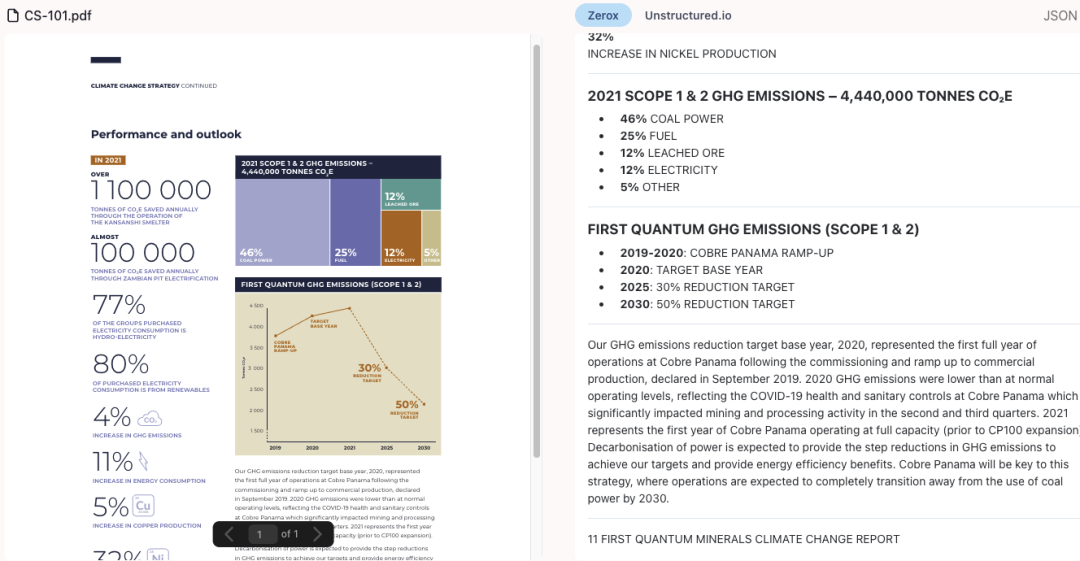
Ниже приведен метод установки и пример использования пакета Python.
pip install py-zeroxИспользование (сначала необходимо настроить необходимые параметры, такие как GPT API):
from pyzerox import zerox
import os
import json
import asyncio
async def main():
file_path = "https://omni-demo-data.s3.amazonaws.com/test/cs101.pdf" ## local filepath and file URL supported
## process only some pages or all
select_pages = None ## None for all, but could be int or list(int) page numbers (1 indexed)
output_dir = "./output_test" ## directory to save the consolidated markdown file
result = await zerox(file_path=file_path, model=model, output_dir=output_dir,
custom_system_prompt=custom_system_prompt,select_pages=select_pages, **kwargs)
return result
# run the main function:
result = asyncio.run(main())
# print markdown result
print(result)результат:
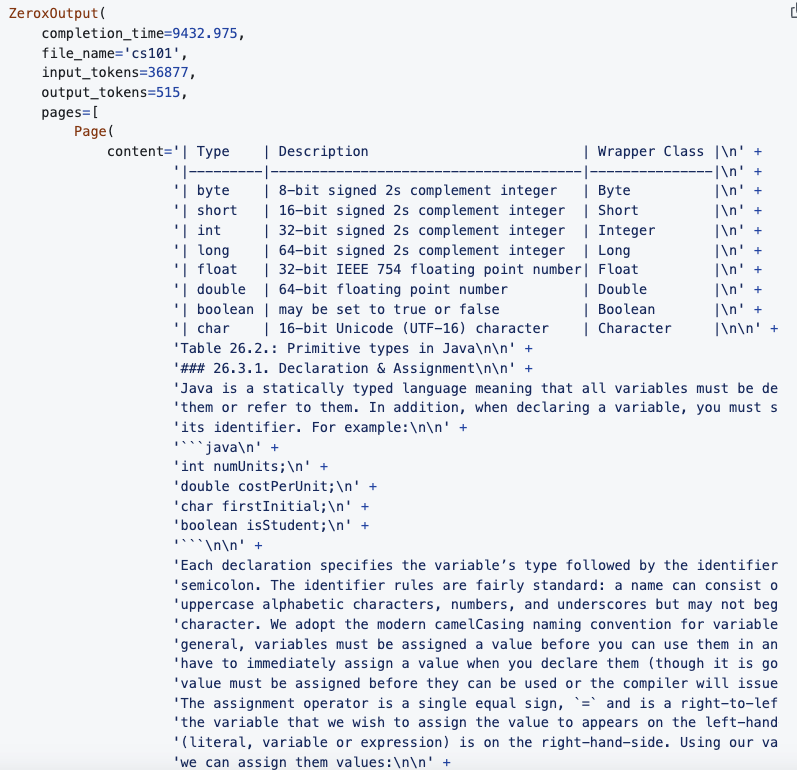
Заключение
Zerox OCR это мощный локальный инструмент с открытым исходным кодом, основанный на GPT-4o-mini может эффективно обрабатывать сложные документы и Markdown Формат вывода, подходящий для точного OCR Обработанный пользователь. Независимо от того, являетесь ли вы разработчиком или профессионалом, которому необходимо иметь дело с большими объемами документов, Zerox OCR Оба решения стоит попробовать.
Загрузите сейчас и попробуйте,Или испытайте онлайн-версию существования,Откройте больше возможностей в обработке документов!
Адрес проекта: https://github.com/getomni-ai/zerox
существоватьонлайн-опыт:https://getomni.ai/ocr-demo



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
