2080 Ti может запускать большие модели 70B, а новая платформа может увеличить скорость вывода LLM в 11 раз.
Предоставлено лабораторией IPADS Шанхайского университета Цзяо Тонг. Кубиты | Публичный аккаунт QbitAI
Для работы, для которой изначально требовался 80G A100 стоимостью 160 000 юаней, теперь требуется только 24G 4090 стоимостью менее 20 000 юаней!
PowerInfer, платформа вывода с открытым исходным кодом, запущенная лабораторией IPADS Шанхайского университета Цзяо Тонг, ускоряет вывод больших моделей в 11 раз.
А без квантования просто используйте точность FP16 для запуска модели 40B на персональном компьютере. Если добавить квантование, 2080 Ti также сможет плавно запускать модель 70B;

Сочетая уникальные характеристики больших моделей и гибридные вычисления между ЦП и ГП, PowerInfer может обеспечить быстрый вывод на персональных компьютерах с ограниченной видеопамятью.
По сравнению с llama.cpp PowerInfer обеспечивает ускорение до 11 раз, позволяя модели 40B выводить десять токенов в секунду на персональный компьютер.
Наиболее знакомый нам ChatGPT иногда дает сбой из-за чрезмерного трафика. С другой стороны, существуют и проблемы с безопасностью данных.

Модель с открытым исходным кодом может лучше решить эти две проблемы, но без высокопроизводительной видеокарты скорость работы часто бывает очень впечатляющей:
Появление PowerInfer как раз решает этот болевой вопрос.
PowerInfer вызвал восторженный отклик сразу после выхода. Менее чем за 24 часа он получил более 500 звезд, в том числе одну от Герганова, автора llama.cpp.
В настоящее время исходный код и документы PowerInfer опубликованы. Давайте посмотрим, насколько силен его эффект ускорения.
Скорость вывода до 11 раз
На аппаратной платформе потребительского уровня, оснащенной процессором x86 и графическим процессором NVIDIA, компания PowerInfer протестировала скорость сквозного вывода PowerInfer на основе серии моделей LLM с размерами параметров от 7 до 175 байт и сравнила ее с лучшей производительностью. на той же платформе сравнивалась среда вывода llama.cpp.
Для прецизионных моделей FP16, оснащенных процессорами Intel 13-го поколения. Core i9 и одиночный RTX На высокопроизводительном ПК 4090 (PC-High) PowerInfer добился среднего увеличения скорости в 7,23 раза, в том числе на Falcon. 40Bреализовано наДо 11,69 разувеличение скорости。
Во всех тестовых случаях PowerInfer достиг в среднем 8,32 токенов/с с максимальными значениями 16,06 токенов/с и 12,94 токенов/с на OPT 30B и Falcon 40B соответственно.
С PowerInfer,Сегодняшние платформы потребительского уровня могутРаботает плавно 30-40В.уровеньLLM,и работает с приемлемой скоростью70BуровеньLLM。
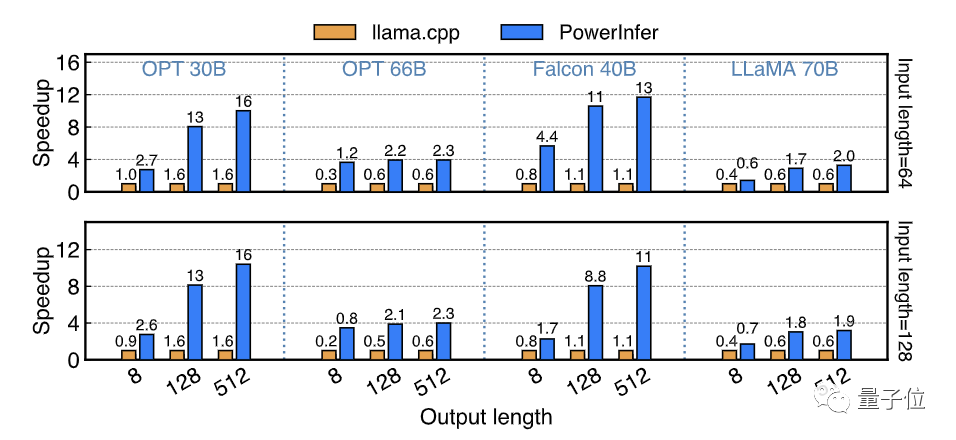
△ PowerInfer в среднем генерирует графики тестирования скорости токена при различной длине вывода в разных моделях. По оси ординат отображается коэффициент ускорения. Число, отмеченное на каждой гистограмме, представляет количество токенов, которые могут быть сгенерированы в секунду.
Квантование модели — это очень распространенная технология конечного вывода LLM, и PowerInfer также поддерживает вывод квантованных моделей INT4.
PowerInfer протестировал скорость вывода серии квантованных моделей INT4 на ПК высокого класса (PC-High) и ПК среднего и низкого уровня (PC-Low), оснащенных одной RTX 2080Ti.
на ПК-Высокий,PowerInferможетЗапускайте модели масштаба 40–70B на высокой скорости.,Самый высокий достигнутый29.09 Скорость вывода токенов/с и достигнуто увеличение средней скорости в 2,89 раза и максимальной в 4,28 раза.
В то же время модели размером с OPT-175B также можно запускать на оборудовании потребительского уровня.
На ПК среднего и низкого уровня, таких как PC-Low,PowerInferМожетПлавно ходовые модели масштаба 30-70В.,и достиг среднего показателя 5,01x,Увеличение скорости до 8,00 раз,Это происходит главным образом из-заINT4Количественная После зарядки большая часть тепловых нейронов помещалась в видеопамять.
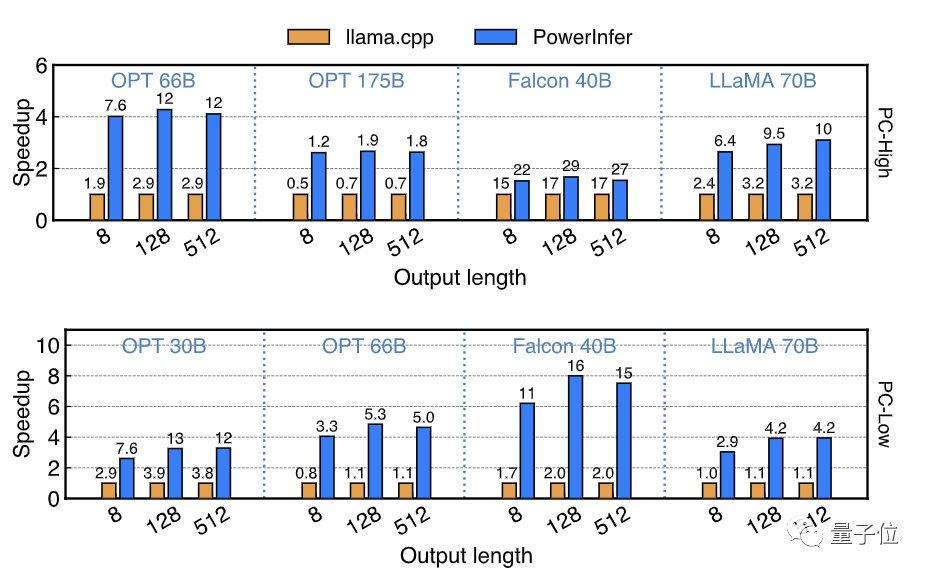
△ Скорость вывода PowerInfer в количественной модели INT4. По оси ординат отображается коэффициент ускорения. Число, отмеченное на каждой гистограмме, представляет количество токенов, которые могут быть сгенерированы в секунду.
Наконец, PowerInfer сравнил скорость сквозного вывода при запуске PowerInfer на ПК-High с лучшей картой облачных вычислений A100, работающей под управлением SOTA framework vLLM. Тестовыми моделями были OPT-30B и Falcon-40B (ReLU) с точностью FP16.
Когда длина входных данных равна 64, разрыв в скорости между PowerInfer и A100 сокращается с 93%-94% до 28%-29% в сценарии чистой генерации с длиной входных данных 1, этот разрыв дополнительно сокращается до минимального значения; 18% .
Это означает, что PowerInfer значительно сократил разрыв в скорости вывода между видеокартами потребительского уровня и топовыми серверными вычислительными картами за счет разреженной активации и гибридного вывода CPU/GPU.

△PowerInferсуществовать4090иvLLMсуществоватьA100Сравнение производительности
Итак, как PowerInfer достигает высокоскоростного вывода на оборудовании потребительского уровня?
Воспользуйтесь всеми преимуществами модели и аппаратных возможностей
Секрет PowerInfer для достижения высокоскоростного вывода,существоватьв полной мере использовать преимущества плотного МодельжитьсуществоватьизВысоко локализованные редкие активации,И он полностью интегрирован с вычислительными характеристиками процессора и графического процессора.
Что такое «разреженная активация»?
Недавно большая модель Mixtral MoE взорвала весь круг ИИ, а разреженная модель вновь вошла в поле зрения каждого.
Интересным фактом является то, что LLM, который рассматривается как плотная модель, такая как OPT и LLaMA (ReLU), также обладает характеристиками разреженной активации.
Что такое разреженная активация плотных моделей?
Как и в модели MoE, входному токену достаточно активировать только один или два экспертных модуля в слое FFN. Если взять в качестве примера плотный слой FFN модели OPT, требуется лишь небольшая часть (эксперименты показывают около 10%) нейронов. активировать для обеспечения корректности вывода.
Хотя в расчетах участвуют и другие нейроны, они не вносят существенного вклада в результат.
другими словами,Каждый нейрон в плотной модели является экспертом.!
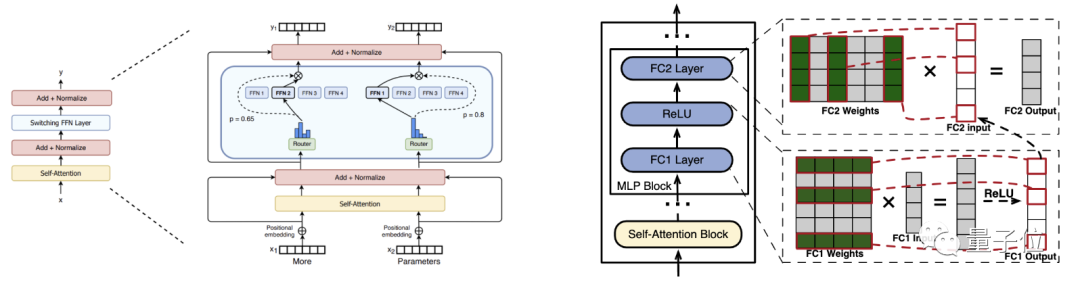
△ Фотография слева от Александра. Бумага Кларка (номер aRXiv: 2101.03961)
Модель MoE может распределять входные данные одному или двум экспертам через модуль маршрутизации перед экспертным слоем FFN для расчета, так как же маршрутизировать редкие активации в плотной модели или узнать, какие экспертные нейроны будут способствовать результату перед расчетом Шерстяная ткань?
Ответ плотный МодельДобавить модуль прогнозирования маршрута。
Прежде чем модель начнет обслуживаться, PowerInfer сначала проведет автономный анализ модели, получит соответствие между входными данными каждого слоя и активированными нейронами, выведя модель из общего набора данных, а затем обучит небольшую модель для каждого слоя плотной модели. Модуль прогнозирующей маршрутизации прогнозирует нейроны, которые будут активированы для каждого входа, и подсчитывает только нейроны, активированные маршрутом (эксперты).
В тестах на нескольких последующих задачах модуль маршрутизации PowerInfer практически не выявил дополнительных потерь точности.
Локальность вывода, вызванная редкой активацией
Еще один интересный факт о разреженной активации заключается в том, что, хотя существуют различия в распределении активированных нейронов для разных входных токенов, если вывод выполняется на достаточном количестве данных и распределение каждой активации накладывается, PowerInfer находит небольшое количество нейронов. Общая вероятность активация выше.
Другими словами, в статистическом смысле активация крупных модельных нейронов соответствует степенному закону распределения (степенной закон распределения — это статистический закон, который указывает на то, что небольшое количество событий происходит гораздо чаще, чем большое количество других событий).
Как показано на рисунке (а) ниже, для определенного уровня сетей FFN в моделях OPT-30B и LLaMA(ReGLU)-70B статистически 26% и 43% нейронов внесли 80% активации соответственно.
В масштабе всей модели, как показано на (b) ниже, 17% и 26% нейронов способствуют 80% активации.
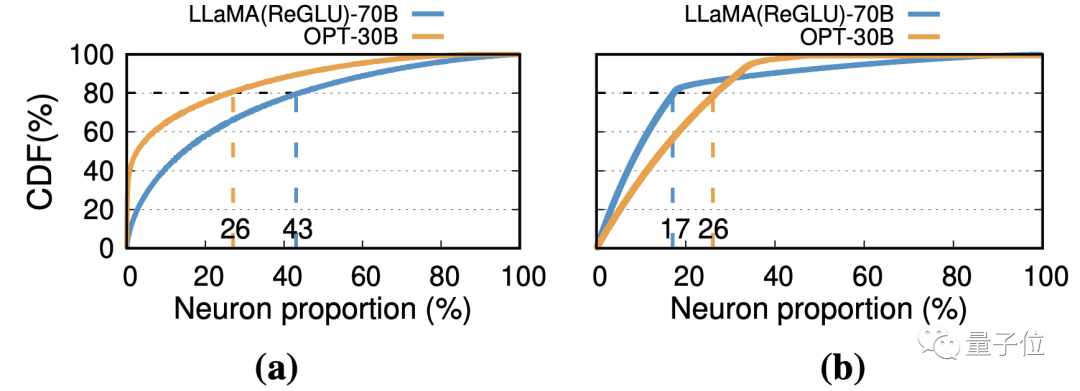
Следовательно, когда рассматриваются только операции, которые способствуют окончательной активации, LLM страдает от локальности вывода: доступ к весам имеет тенденцию концентрироваться в определенной области, а не равномерно распределяться по всем нейронам.
В логических операциях это проявляется как локальность программы: доступ к пространству памяти имеет тенденцию концентрироваться в определенной области, а не равномерно распределяться по пространству памяти.
В обычных персональных компьютерах,GPUиметьМеньше видеопамяти и больше вычислительной мощности,Подходит для решения часто используемых и ресурсоемких задач.;иCPUиметьБольший объем памяти, но относительно слабая вычислительная мощность,Подходит для задач с малым доступом и низкой вычислительной интенсивностью.
Поэтому в идеале небольшое количество часто используемых нейронов должно храниться в видеопамяти, в то время как более крупные и менее часто используемые нейроны более подходят для хранения в памяти и вычислений ЦП.
Это вдохновило PowerInfer на разработку гибридной системы вывода CPU/GPU, основанной на особенностях местности.
Гибридный дизайн вывода CPU/GPU
На основе степенного закона вышеупомянутых нейронов и полученной локальности PowerInfer заранее статически анализирует горячие и холодные свойства каждого нейрона, загружает небольшое количество горячих нейронов в память графического процессора, а оставшиеся холодные нейроны загружает в память графического процессора. ЦП в памяти.
Смешанная загрузка моделей с детализацией нейронов приведет к тому, что некоторые нейроны в слое будут находиться на графическом процессоре, а некоторые — на процессоре.
С этой целью PowerInfer разработал детальный гибридный механизм вывода CPU/GPU.
Например, на рисунке ниже для входных данных определенного слоя PowerInfer сначала прогнозирует, что входные данные активируют нейроны 3, 4 и 5.
Затем ЦП и ГП будут выполнять вычисления с нейронами, расположенными в их памяти, на основе прогнозной информации.
В частности, например, на рисунке ниже, четвертый нейрон будет рассчитан на ЦП, третий и пятый нейроны будут рассчитаны на графическом процессоре, а затем результаты вычислений обеих сторон будут объединены на графическом процессоре.
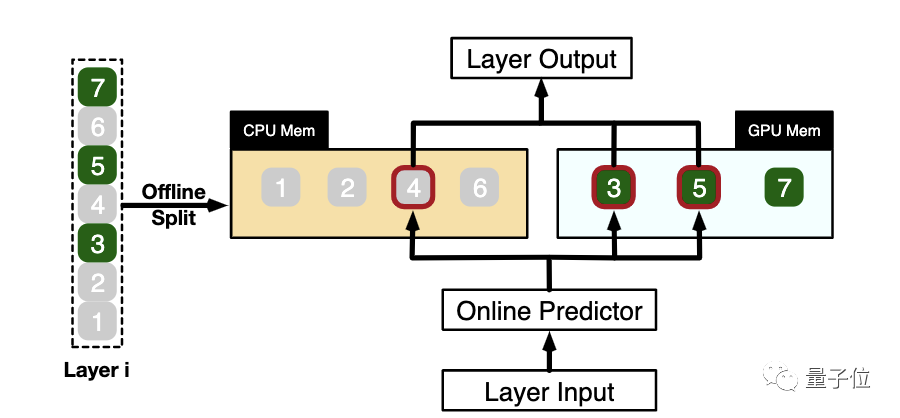
△PowerInferГибридный вычислительный подход
Общая архитектура PowerInfer
В целом, PowerInfer разработала инновационную гибридную систему вывода CPU/GPU, использующую разреженную активацию на основе плотных моделей и свойств локальности, которые она вводит.
При подключении к большой языковой модели (LLM) PowerInfer сначала обучает модуль прогнозирующей маршрутизации модели на автономном этапе и проводит углубленный анализ функций активации модели.
В то же время оптимальная стратегия размещения нейронов рассчитывается на основе ключевой информации, такой как пропускная способность и мощность целевого оборудования.
На основании этих результатов PowerInfer оптимально распределит нейроны в памяти или видеопамяти.
На этапе онлайн-вывода ЦП и графический процессор отдельно обрабатывают нейроны, хранящиеся в их памяти, а результаты этих независимых вычислений впоследствии эффективно объединяются на графическом процессоре.
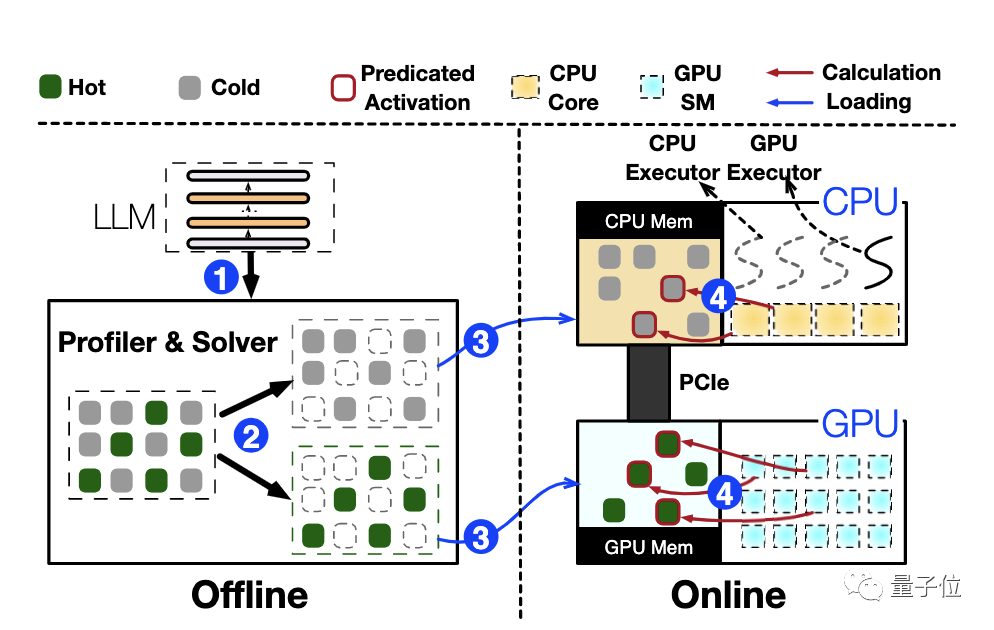
△ Общая схема архитектуры PowerInfer
Резюме и перспективы
Для конечных пользователей эффективная система рассуждений PowerInfer открывает новые возможности.
Во-первых, он позволяет пользователям ПК запускать сложные крупномасштабные языковые модели локально без необходимости использования дорогостоящего специализированного оборудования.
Это не только способствует популяризации приложений искусственного интеллекта, но и открывает беспрецедентные возможности для энтузиастов, исследователей и малого бизнеса.
С точки зрения развертывания в облаке PowerInfer также имеет огромный потенциал.
Существующие облачные процессоры также поддерживаются мощными вычислительными блоками AMX. Используя преимущества гетерогенных характеристик процессоров и графических процессоров, мы можем быть уверены в том, что PowerInfer сможет использовать меньше высокопроизводительных вычислительных карт для достижения более высокой пропускной способности обслуживания.
Бумажный адрес: https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf
— над —



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
