2000 слов, обсуждающих происхождение окна расчета окна SparkStreaming.
Предисловие
Разработка потоковой передачи больших данных в режиме реального времени.,Обычно используемые технологии — SparkStreaming и Flink. Когда вы впервые изучаете методы обработки данных в реальном времени,всегда рядомОбработка данных в режиме реального времени,Давайте сравним разные технологии.
Однако в реальных сценариях разработки приложений часто требуются оконные операции, а это означает, что данные не обрабатываются во время «процесса формирования» окна. При формировании окна будет запущен расчет окна. Таким образом, обработка в реальном времени в настоящее время становится микропакетной обработкой на основе окон.
Об окнах
Spark рассчитывается на основе RDD (Resilient Distributed Dataset) — это коллекция данных, поэтому сам SparkStreaming основан на микропакетном вычислении. Интервал пакета задается при построении SparkContext, а минимальное значение составляет 50 миллисекунд. Пакет здесь можно понимать как окно
Когда будет достигнуто время установки пакета, Spark начнет выполнять логику вычислений на основе RDD. Таким образом, у SparkStreaming есть собственное «окно», а логика вычислений реализована на основе RDD.
Вычисление данных в Flink управляется событиями. Здесь событие относится к одному элементу данных в потоке данных, поэтому каждое событие в Flink может запускать соответствующую логику обработки, а не обрабатывать через фиксированные интервалы времени. Поэтому, если вы хотите реализовать обработку окон во Flink, вы должны использовать для этого оконные функции.
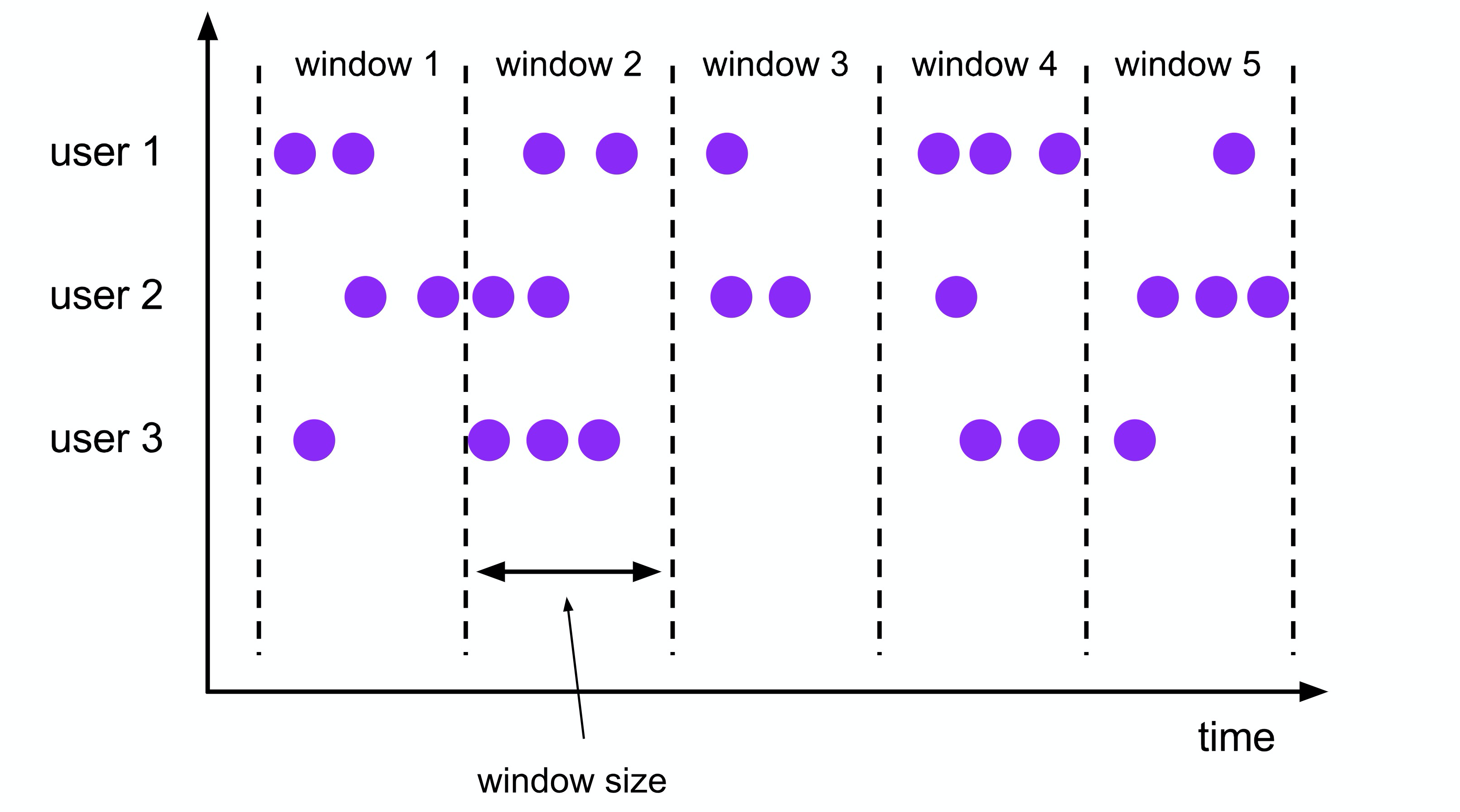
В каких сценариях используется расчет окна?
Например, такие операции, как дедупликация данных за одну минуту (reduceByKey), подсчет (count) и ассоциация (join), требуют использования оконных вычислений. Сегодня давайте посмотрим, как поэкспериментировать с оконными операциями SparkStreaming.
Расчет окна SparkStreaming
У SparkStreaming, описанного выше, есть собственное временное окно. RDD в пакете представляет собой окно, а вычисление RDD — это вычисление окна, поэтому SparkStreaming не предоставляет обычных оконных операторов.
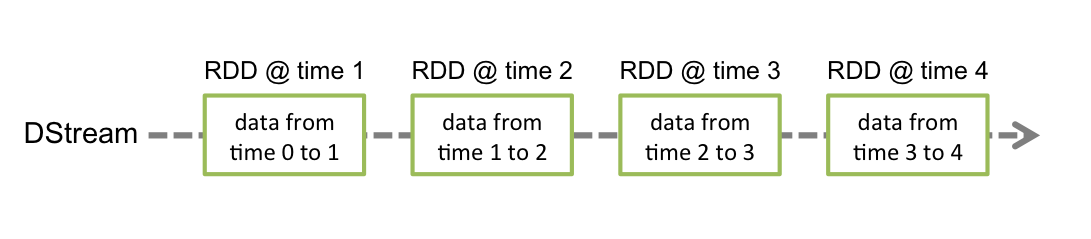
Как показано на рисунке, время сбора данных в RDD 0 to 1 — временное окно,Интервал передачи данных установленинтервал партии。теперь этоSparkStreamingПолучил все этоRDDэтот”временное окно“Понятно,Так о каком еще окне может идти речь?
В расчете RDD,Окно обычно может вычислять данные только одного СДР.,После расчета этой партии RDD,,По умолчанию он будет переработан,Затем извлеките данные следующего пакета времени, чтобы сгенерировать RDD для расчета. Когда нам нужно вычислить несколько RDD, то есть несколько временных окон,Необходимо использоватьраздвижное окнооператор для реализации。
раздвижное окно
В SparStreaming предусмотрено раздвижное окноwindowОператоры используются для расчета данных из нескольких окон одновременно.。
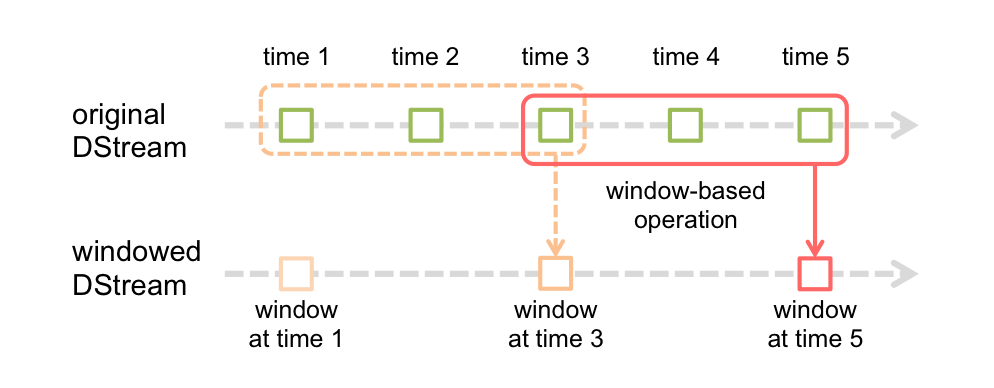
Как показано на рисунке, time1 и time2 в исходном Dstream представляют собой RDD, сгенерированные на основе установленного нами времени пакета, которое является «собственным окном». Каждое окно следующего окна Dstream генерируется посредством операторов.
При запуске программы первое окно будет сгенерировано на основе первого RDD. Что касается формирования последующих окон, то каждое окно содержит несколько RDD. Давайте посмотрим на определение оконного оператора.
оконный оператор
оконный предусмотрен в SparkStreaming оператор, используемый для определения раздвижного окно。
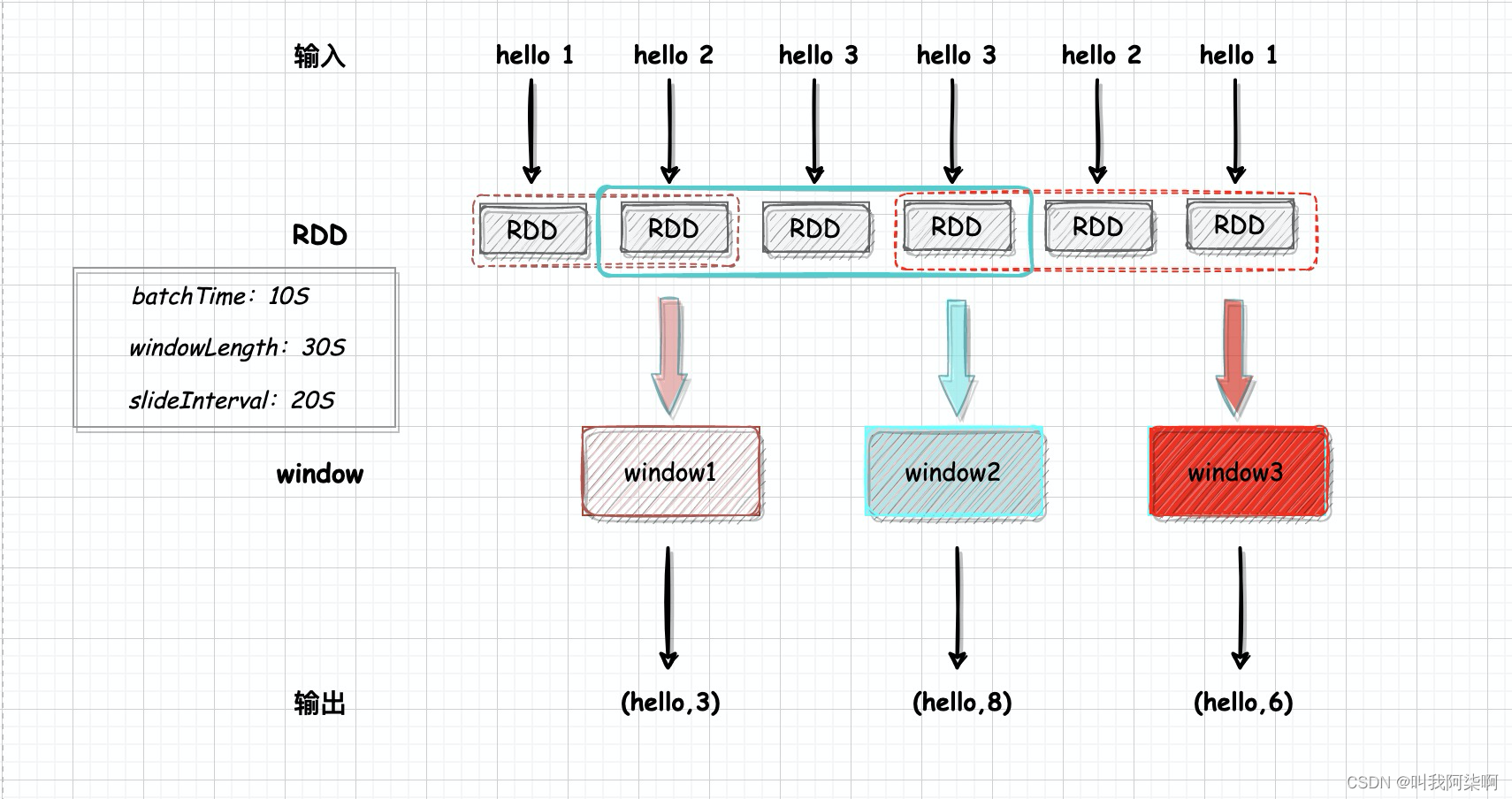
window(windowLength, slideInterval)оконный оператор требует два аргумента,windowLengthПредставляет длину окна,То есть окно должно содержать несколькоRDD。slideIntervalУказывает интервал между сдвигом окон.,Срабатывает при каждом пролистыванииwindowпоколение。windowLength и SlideInterval должны быть кратны времени пакета.
Если время генерации RDD равно 1, windowLength на рисунке выше равно 3, поэтому каждое окно содержит 3 RDD, а слайд Интервал равен 2. Каждые два сгенерированных RDD будут сдвигаться, образуя окно. Поскольку windowLength - слайд Интервал = 1, два окна на рисунке будут повторно вычислять СДР времени3.
тестирование кода
развиватьПодсчитать количество вхождений слов в единицу времени (windowLength)изSparkStreamingТестирование программыоконный оператор。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("windows")
val ssc = new StreamingContext(conf, Seconds(10))
val streams = ssc.socketTextStream("localhost", 9999)
streams.print
streams.window(Seconds(30), Seconds(20))
.map(x => {
val s = x.split(" ")
(s(0), s(1).toInt)
})
.reduceByKey((x, y) => x + y)
.print
ssc.start
ssc.awaitTermination
}использоватьsocketTextStreamкак источник данных в реальном времени,Слушайте порт 9999. 10 с за партию,windowLength установлен на 30 секунд.,То есть три РДД,для слайда Interval установлено значение 20 с.,То есть интервал между двумя СДР сдвигается один раз.
Запускаем порт через nc и вводим "hello Данные формата 1" считываются SparkStreaming, а затем оконным оператор Создать окно,И преобразуется в (k, v) форму,проходитьreduceByKeyПодсчитайте количество слов в окне。
Мы вводим фрагмент данных каждые 10 секунд в nc.

проходитьstreams.printвыходSparkStreamingв каждомRDDизценить,Затем выведите результат расчета окна после обработки окна.

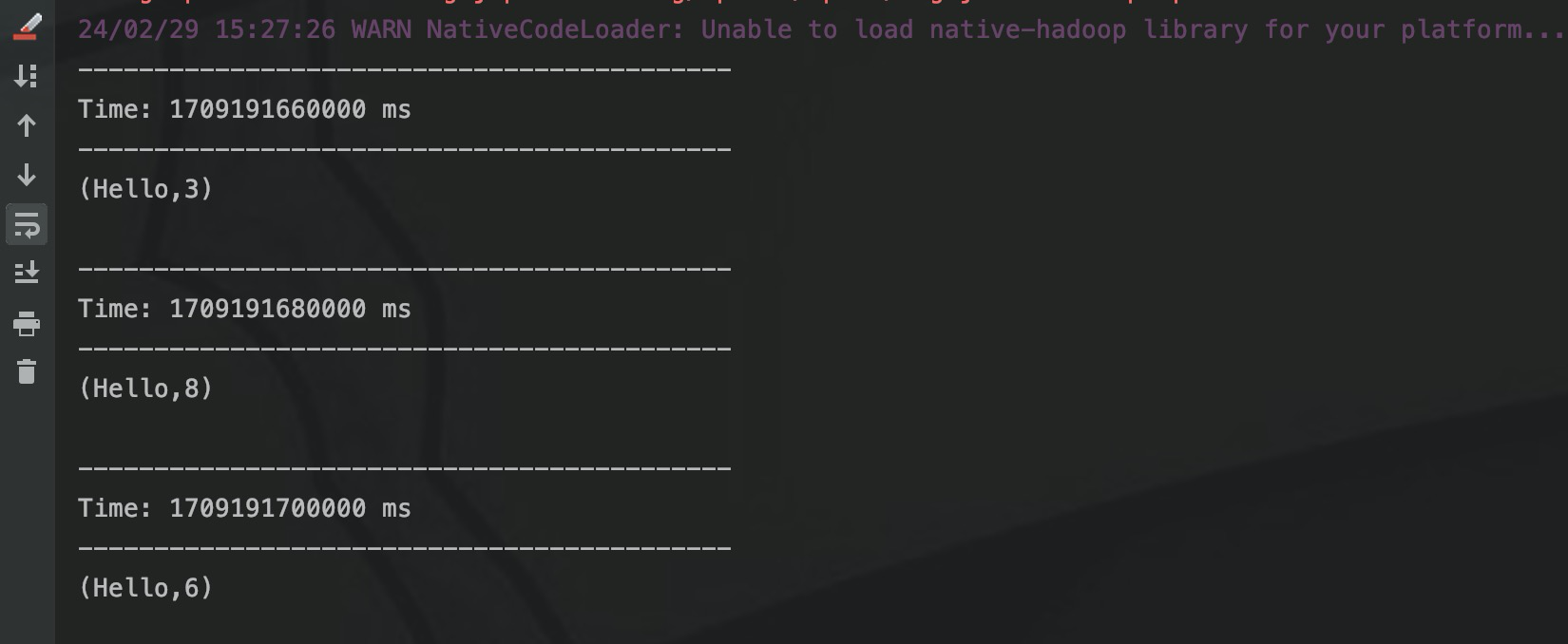
Первый СДР выводит «привет 1», а второй СДР выводит «привет 2». Время двух СДР равно 20 с = слайд Интервал, поэтому скользящее окно генерации запускает расчет, но в этот момент существует только два СДР, поэтому для RDD1 Данные RDD2 накапливаются с помощью уменьшенияByKey, и выводится «(привет,3)».
И RDD3, и RDD4 выводят «привет 3», и окно генерируется путем скольжения за 20 секунд. На данный момент всего имеется 4 RDD, а для параметра windowLength установлено значение 30, поэтому необходимо вычислить 3 RDD и указать значение. совокупный вывод — «(привет, 8)».
Следующие окна следуют последовательно. В каждом окне вычисляются 3 СДР, а в соседних окнах вычисляется повторный СДР.
Выше представлена схема архитектуры, построенная на основе вышеуказанной программы. Аналогично, логику вычислений окна можно увидеть через веб-интерфейс DAG SparkStreaming.
на работе 0 (т. е. RDD1),Просто позвониmakeRDDсоздавать ПонятноRDD,Никаких расчетов не производилось.
на работе 1 (RDD2), RDD1 и RDD2. В это время задание делится на два этапа с помощью сокращения.
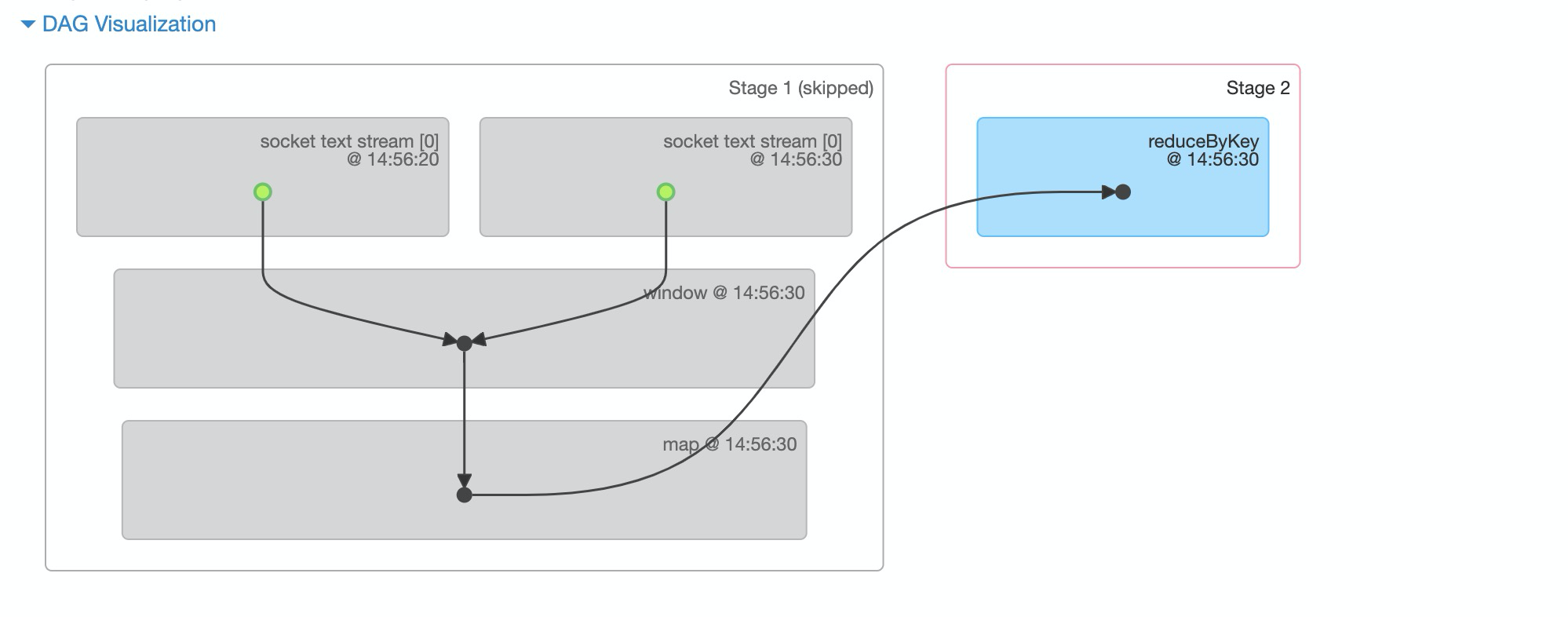
По временной метке вы можете увидеть время создания RDD. на работе В течение 3 часов окно расчета выполняется на RDD2, 3 и 4.
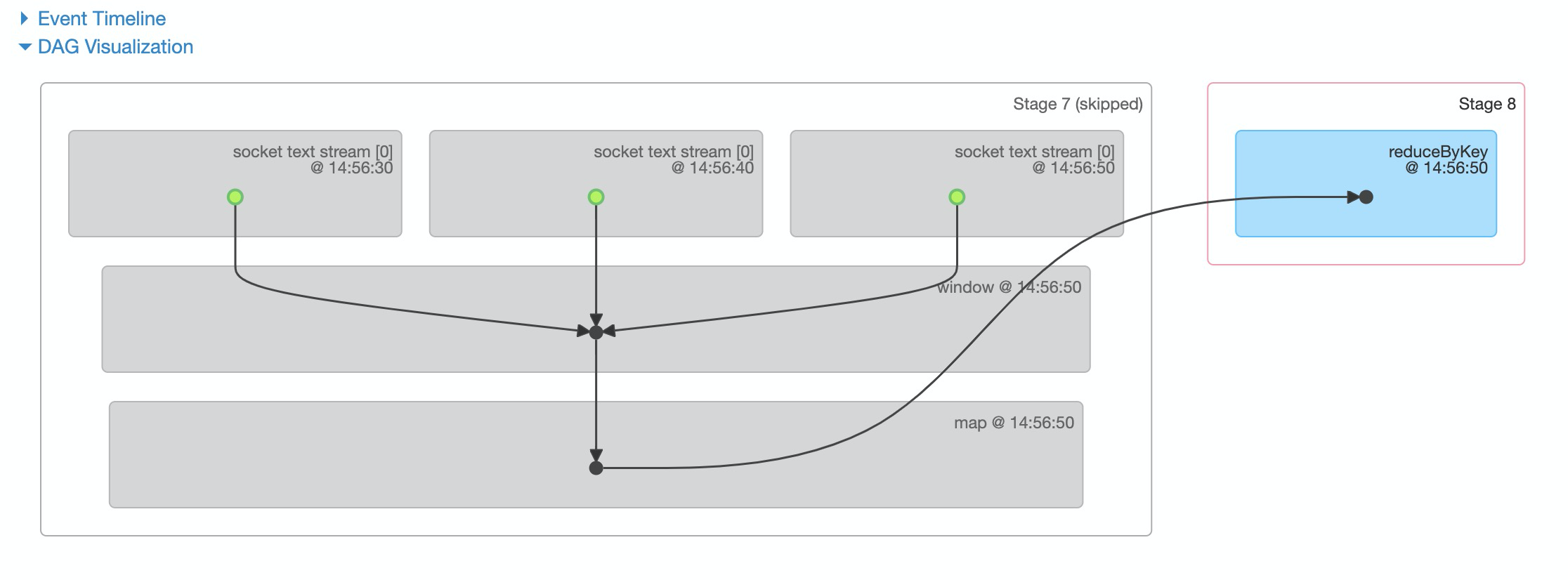
Как вы можете видеть на фотографиях выше,job1 и job2 не запускают вычисления окна,И job1, и job3 рассчитали RDD в 14:46:30. Затем СДР в 14:46:30 будет пересчитано для карты за окном, и каждые два последующих окна будут пересчитываться СДР.
Таким образом, приведенный выше код можно изменить,Поместите всю грубую обработку данных перед окном,Таким образом, RDD не будет повторять предыдущий расчет при использовании в разных окнах.
оптимизация
На основе предыдущего кода поместите оператор карты перед окном.
val conf = new SparkConf().setMaster("local[4]").setAppName("windows")
val ssc = new StreamingContext(conf, Seconds(10))
ssc.socketTextStream("localhost", 9999)
.map(x => {
val s = x.split(" ")
(s(0), s(1).toInt)
})
.window(Seconds(30), Seconds(20))
.reduceByKey((x, y) => x + y)
.printТогда посмотрите на DAG.
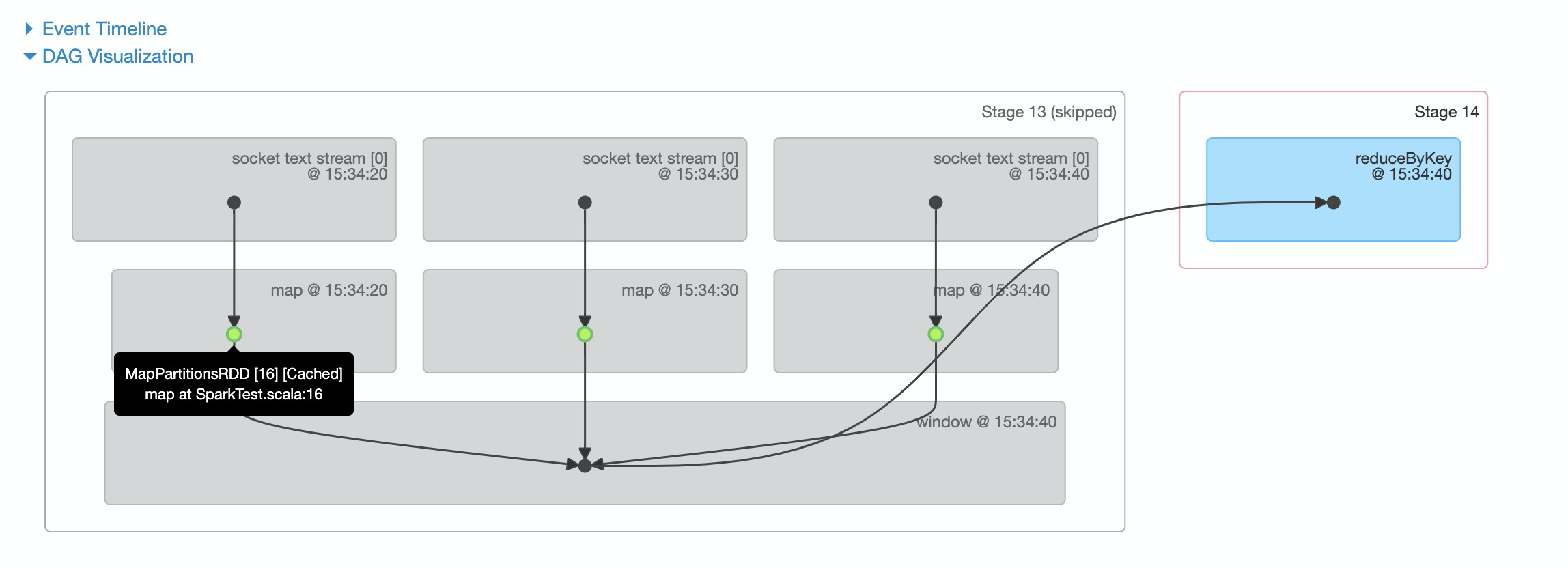
Зеленые точки на рисунке обозначают,Исходный RDD обрабатывается оператором карты.,генерироватьMapPartitionsRDD,Затем он кэшируется кешем. так,СДР рассчитывается в текущем окне,Если используется в следующем окне,MapPartitionsRDD будет извлечен из кеша и помещен в окно.,Это позволяет избежать расчета карты.
Оглядываясь назад на предыдущую группу DAG,cacheизоригинальноBlockRDD,И расчет карты идет после окна,Поэтому каждый раз, когда РДД помещается в окно,Расчет карты будет пересчитан.
Эта идея состоит в том, чтобы выполнить предварительную обработку данных на уровне RDD и выполнить агрегацию и другие операции в окне. Если его использовать в вычислительных сценариях с большими объемами данных и сложной логикой, это повысит эффективность обработки и в определенной степени сэкономит вычислительные ресурсы.
такой же,Продуманная функция SparkStreaming также предоставляет несколько окон для составных операторов.,НапримерreduceByKeyAndWindow、reduceByWindow、countByValueAndWindowждать。ВотreduceByKeyAndWindowНапример。
reduceByKeyAndWindow
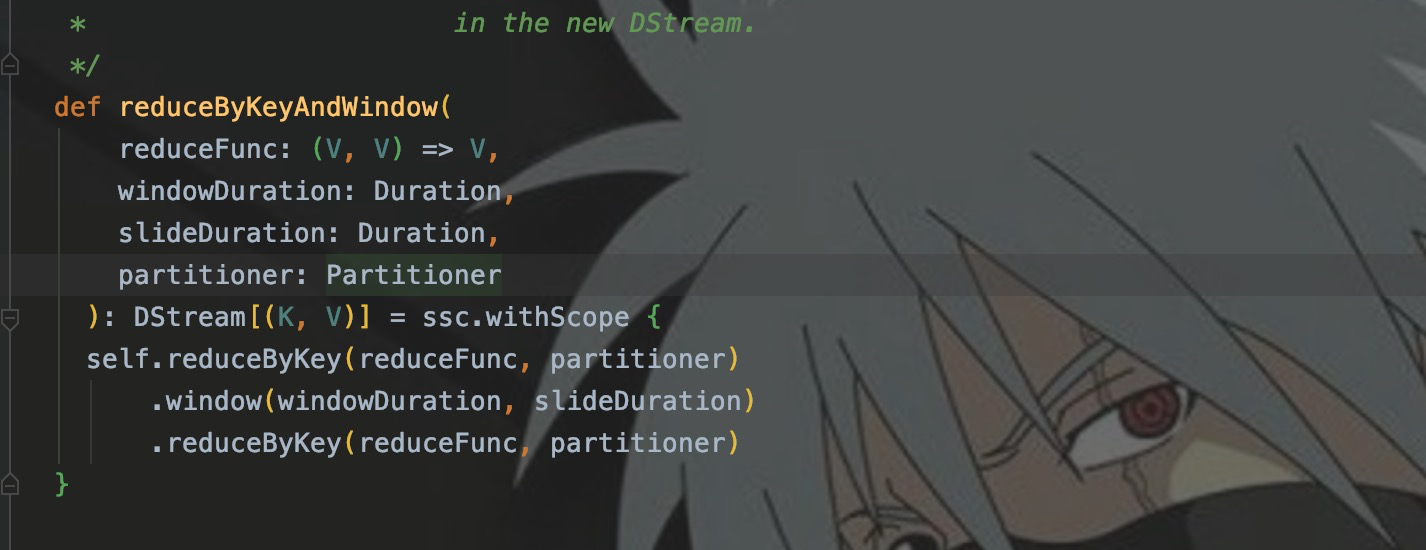
В предыдущем коде мы использовали операторы window и сокращениеByKey для реализации статистики слов. Используя сокращениеByKeyAndWindow, вы можете заменить окно и уменьшитьByKey.
ssc.socketTextStream("localhost", 9999)
.map(x => {
val s = x.split(" ")
(s(0), s(1).toInt)
})
.reduceByKeyAndWindow((x:Int, y:Int) => x + y, Seconds(30), Seconds(20))
.printИспользуя тот же входной тест, что и раньше, выходные данные:
Если вы посмотрите исходный код сокращенияByKeyAndWindow, вы обнаружите, что на самом деле это интеграция нескольких операторов.
Заключение
Эта статья в основном начинается с концепции окон и сценариев приложений для обработки данных в реальном времени и подробно описывает, как использовать SparkStreaming в сочетании с программным кодом. Использование оператора. Статью о расчете окна Флинком добавлю позже.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
