19,7 тысяч звезд! Потрясающе, лучший инструмент распознавания текста с открытым исходным кодом OCR!

В повседневной работе, например, при проведении автоматизированного тестирования, часто задействуются некоторые сценарии распознавания кода проверки, распознавания текста и распознавания изображений. Хотя на рынке существует множество инструментов распознавания, качество и точность различаются.
Сегодня я рекомендую вам Открытый исходный кодOCRпроект:Umi-OCR,Очень мощная функция,Его также можно использовать в автономном режиме,Сейчас у него 19,7 тыс.+ звезд,Это говорит о популярности данного проекта.
1. Представление проекта

Этот проект разработан на основе PaddleOCR и написан на Python. В настоящее время он поддерживает работу только на платформе Windows, а кроссплатформенность все еще находится в стадии подготовки.
Адрес проекта:
https://github.com/hiroi-sora/Umi-OCR
https://gitee.com/mirrors/Umi-OCR.git
Структура проекта:
Umi-OCR
├─ Umi-OCR.exe
└─ UmiOCR-data
├─ main.py **
├─ version.py **
├─ site-packages
│ └─ пакет Python
├─ runtime
│ └─ интерпретатор Python
├─ qt_res **
│ └─ Ресурсы проекта qt, включая значки и исходный код qml.
├─ py_src **
│ └─ Исходный код проекта на Python
├─ plugins
│ └─ плагин
└─ i18n **
└─ Перевести файлы
Особенности проекта:
- Бесплатно: Все коды для этого проекта Открытый исходный код, совершенно бесплатно.
- Удобно: распакуйте и используйте, работайте в автономном режиме, подключение к сети не требуется.
- Эффективность: он оснащен высокоэффективным автономным механизмом оптического распознавания символов и встроенными библиотеками распознавания нескольких языков.
- Гибкость: поддержка командной строки, HTTP-интерфейс и другие методы вызова.
- Функция:Скриншот оптического распознавания символов / Пакетное распознавание текста / Распознавание PDF-файлов / QR-код / Распознавание формулы
2. Использование проекта
Выберите подходящую версию прямо в релизах, и скачать ее можно следующими способами:
GitHub https://github.com/hiroi-sora/Umi-OCR/releases/latest
Лань Цзоюнь https://hiroi-sora.lanzoul.com/s/umi-ocr
Source Forge https://sourceforge.net/projects/umi-ocr
Это программное обеспечение не требует установки. После распаковки нажмите Umi-OCR.exe, чтобы запустить программу.
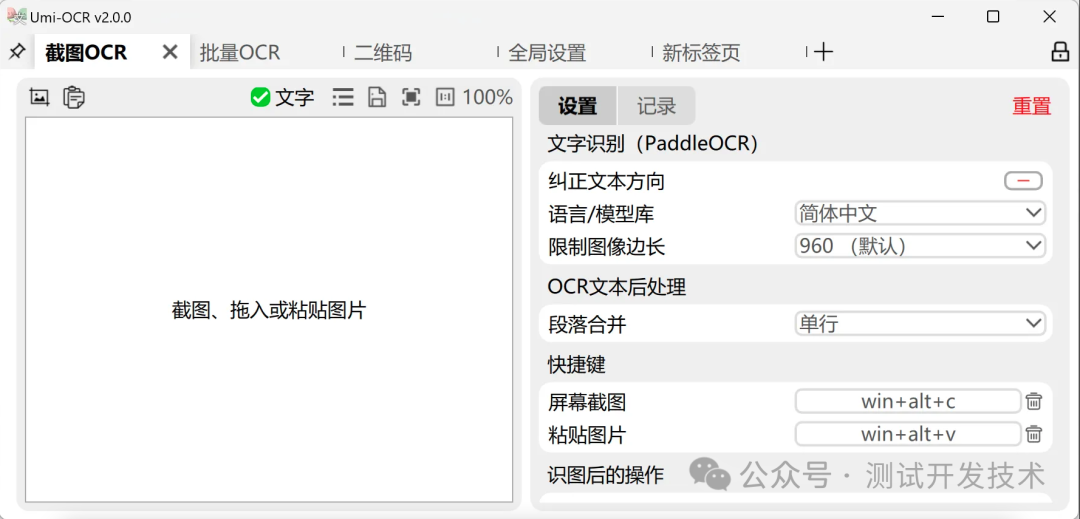
Скриншот оптического распознавания символов
Эта функция очень удобна для использования на некоторых веб-страницах, которые невозможно скопировать. Она работает очень быстро и имеет высокую точность.
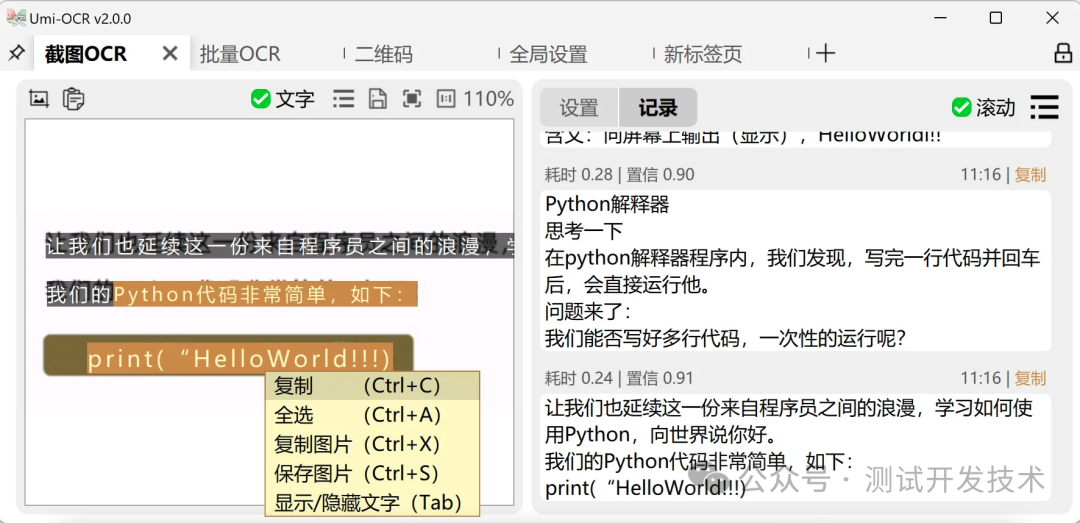
Скриншот оптического распознавания символов: откройте эту страницу,Вы можете использовать сочетания клавиш для вызова снимков экрана,Определите текст на картинке.
- Панель предварительного просмотра изображения слева,Вы можете напрямую использовать мышь, чтобы выбрать копировать.
- Столбец идентификационной записи справа,Можно редактировать текст,Позволяет выбрать несколько записей, копировать.
- Также поддерживаю в другом месте копировать фотографии,Вставьте в Umi-OCR для распознавания.
Пакетное распознавание текста
Если вам нужно идентифицировать несколько изображений одновременно, стоит использовать эту функцию. Просто импортируйте все изображения и нажмите «Начать задачу», чтобы выполнить пакетную идентификацию.
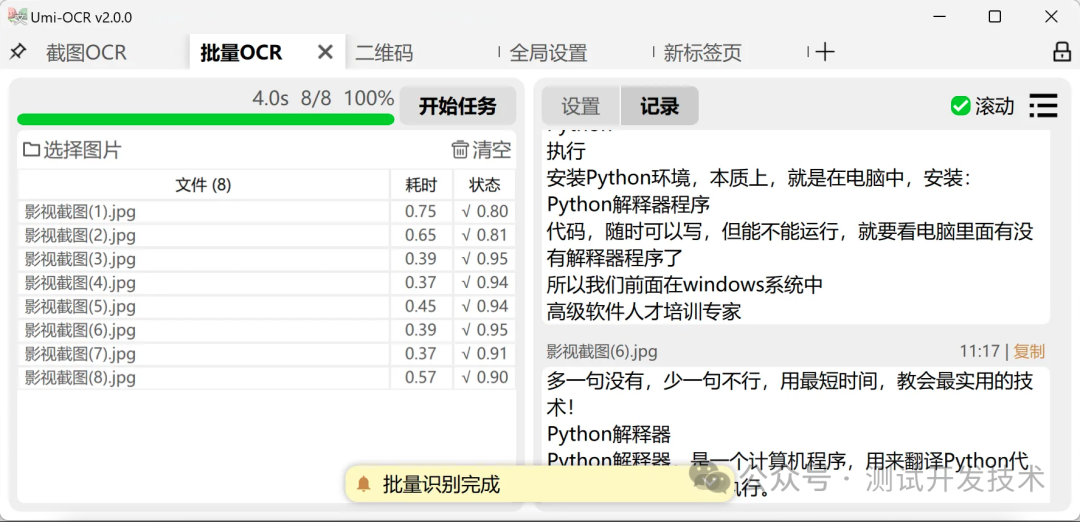
Пакетное распознавание текста: Эта страница поддерживает пакетный импорт локальных изображений и идентифицирует их.
- Распознанный контент можно сохранить в различных форматах, например txt/jsonl/md/csv(Excel).
- и Скриншот оптического распознавания символы те же,поддержка функции постобработки текста,Организуйте форматирование и порядок текста OCR.
- Поддержка зоны игнорирования.
- Верхнего ограничения на количество нет, и для задач можно одновременно импортировать сотни изображений.
Настраиваемые области игнорирования
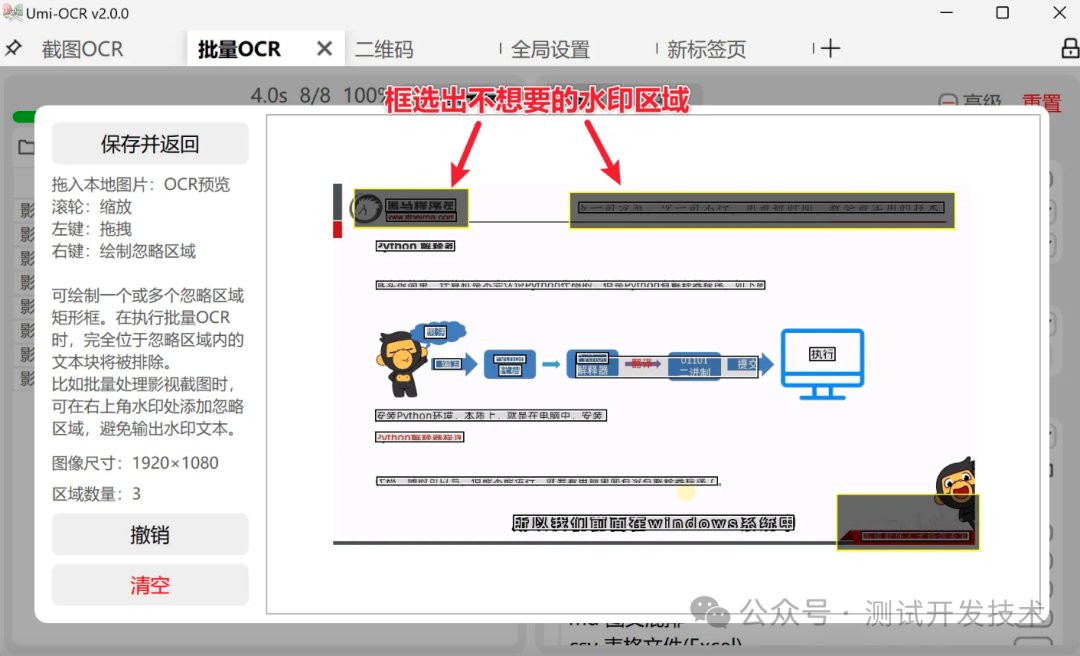
Соседняя область: специальная функция в Пакетном распознавании текста, предназначенная для исключения нежелательного текста из изображений.
Распознавание документов
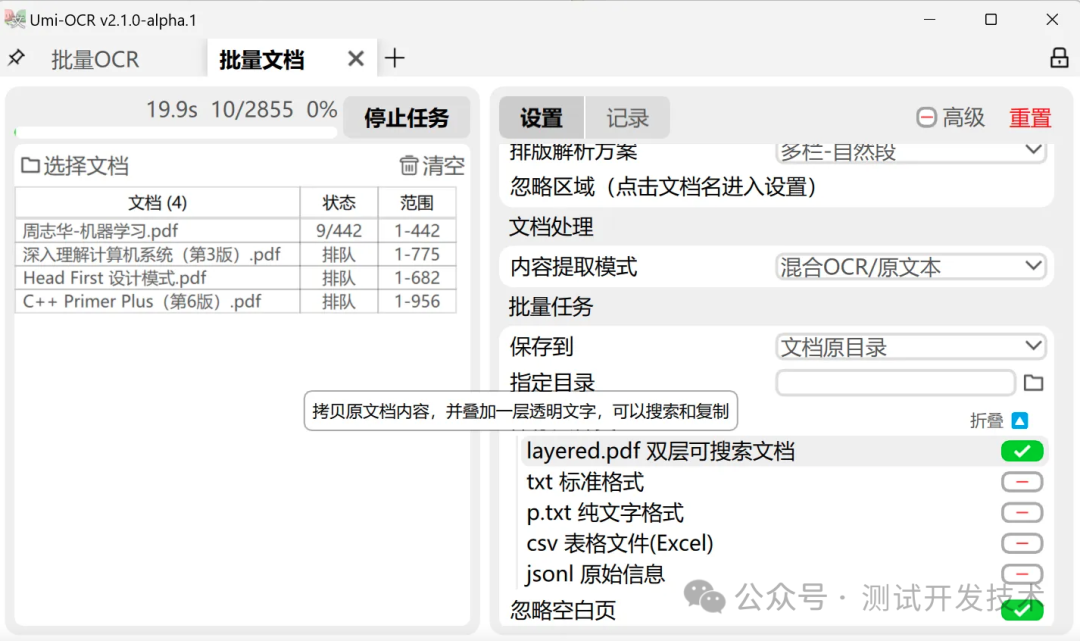
Распознавание документов:
- Поддерживает импорт файлов в форматах pdf, xps, epub, mobi, fb2, cbz.
- Выполните распознавание текста на отсканированных документах или извлеките исходный текст. Можно экспортировать в виде двухслойного PDF-файла с возможностью поиска.
- Поддержка настройки области игнорирования, которую можно использовать для исключения текста верхнего и нижнего колонтитула.
- Вы можете настроить его на автоматическое выключение/переход в спящий режим после завершения задачи.
Поддержка командной строки и вызова интерфейса
Поддерживает вызов через командную строку или интерфейс HTTP. Вход для вызова командной строки — это основная программа Umi-OCR.exe.
Использование командной строки OCR:
Скриншот: Umi-OCR.exe --screenshot
Вставить изображение: Umi-OCR.exe --clipboard
Указанный адрес: Umi-OCR.exe --path "D:/xxx.png"
Вывод результата: Umi-OCR.exe --screenshot --> test.txt
Все команды OCR могут возвращать результаты распознавания на консоль. Пожалуйста, подождите терпеливо и не вводите следующую команду до конца одной команды. Все команды можно заменить несколькими первыми буквами. Например, --screenshot и --clipboard можно сократить до --sc и --cl соответственно. Вы можете попробовать это сами.
Интерфейс HTTP. Сначала необходимо включить службу HTTP.

Службе HTTP должно быть разрешено использовать интерфейс HTTP (включено по умолчанию). Если вам нужно разрешить доступ из локальной сети, переключите хост на любой доступный адрес.
Примеры следующие:
import requests
import json
url = "http://127.0.0.1:1224/api/ocr"
data = {
"base64": "iVBORw0KGgoAAAANSUhEUgAAAC4AAAAXCAIAAAD7ruoFAAAACXBIWXMAABnWAAAZ1gEY0crtAAAAEXRFWHRTb2Z0d2FyZQBTbmlwYXN0ZV0Xzt0AAAHjSURBVEiJ7ZYrcsMwEEBXnR7FLuj0BPIJHJOi0DAZ2qSsMCxEgjYrDQqJdALrBJ2ASndRgeNI8ledutOCLrLl1e7T/mRkjIG/IXe/DWBldRTNEoQSpgNURe5puiiaJehrMuJSXSTgbaby0A1WzLrCCQCmyn0FwoN0V06QONWAt1nUxfnjHYA8p65GjhDKxcjedVH6JOejBPwYh21eE0Wzfe0tqIsEkGXcVcpoMH4CRZ+P0lsQp/pWJ4ripf1XFDFe8GHSHlYcSo9Es31t60RdFlN1RUmrma5oTzTVB8ZUaeeYEC9GmL6kNkDw9BANAQYo3xTNdqUkvHq+rYhDKW0Bj3RSEIpmyWyBaZaMTCrCK+tJ5Jsa07fs3E7esE66HzralRLgJKp0/BD6fJRSxvmDsb6joqkcFXGqMVVFFEHDL2gTxwCAaTabnkFUWhDCHTd9iYrGcAL1ZnqIp5Vpiqh7bCfua7FA4qN0INMcN1+cgCzj+UFxtbmvwdZvGIrI41JiqhZBWhhF8WxorkYPpQwJiWYJeA3rXE4hzcwJ+B96F9zCFHC0FcVegghvFul7oeEE8PvHeJqC0w0AUbbFIT8JnEwGbPKcS2OxU3HMTqD0r4wgEIuiKJ7i4MS16+og8/+bPZRPLa+6Ld2DSzcAAAAASUVORK5CYII=",
# Дополнительные параметры
# Режим лопастного двигателя
# "options": {
# "ocr.language": "models/config_chinese.txt",
# "ocr.cls": False,
# "ocr.limit_side_len": 960,
# "tbpu.parser": "multi_para",
# "data.format": "text",
# }
# Режим быстрого двигателя
# "options": {
# "ocr.language": «Упрощенный китайский»,
# "ocr.angle": False,
# "ocr.maxSideLen": 1024,
# "tbpu.parser": "multi_para",
# "data.format": "text",
# }
}
headers = {"Content-Type": "application/json"}
data_str = json.dumps(data)
response = requests.post(url, data=data_str, headers=headers)
if response.status_code == 200:
res_dict = json.loads(response.text)
print("Словарь возвращаемых значений\n", res_dict)
Для более подробной информации об использовании, пожалуйста, обратитесь к:
- https://gitee.com/mirrors/Umi-OCR/blob/main/docs/README_CLI.md
- https://gitee.com/mirrors/Umi-OCR/blob/main/docs/README_HTTP.md
Если статья вам полезна, подписывайтесь, ставьте лайки, смотрите и делитесь ею с друзьями!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
